使用 AutoClass 加载预训练实例
由于存在如此多的不同Transformer架构,为您的检查点创建一个可能会很有挑战性。作为🤗 Transformers核心哲学的一部分,为了使库易于使用、简单且灵活,AutoClass会自动从给定的检查点推断并加载正确的架构。from_pretrained()方法允许您快速加载任何架构的预训练模型,因此您不必花费时间和资源从头开始训练模型。生成这种与检查点无关的代码意味着,如果您的代码适用于一个检查点,它将适用于另一个检查点——只要它是为类似任务训练的——即使架构不同。
记住,架构指的是模型的骨架,而检查点是给定架构的权重。例如,BERT 是一种架构,而 google-bert/bert-base-uncased 是一个检查点。模型是一个通用术语,可以指架构或检查点。
在本教程中,学习:
- 加载一个预训练的分词器。
- 加载一个预训练的图片处理器
- 加载一个预训练的特征提取器。
- 加载一个预训练的处理器。
- 加载一个预训练模型。
- 加载一个模型作为骨干。
AutoTokenizer
几乎每个NLP任务都从分词器开始。分词器将您的输入转换为模型可以处理的格式。
使用AutoTokenizer.from_pretrained()加载一个分词器:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")然后按照以下方式对输入进行标记化:
>>> sequence = "In a hole in the ground there lived a hobbit."
>>> print(tokenizer(sequence))
{'input_ids': [101, 1999, 1037, 4920, 1999, 1996, 2598, 2045, 2973, 1037, 7570, 10322, 4183, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}AutoImageProcessor
对于视觉任务,图像处理器将图像处理为正确的输入格式。
>>> from transformers import AutoImageProcessor
>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")AutoBackbone
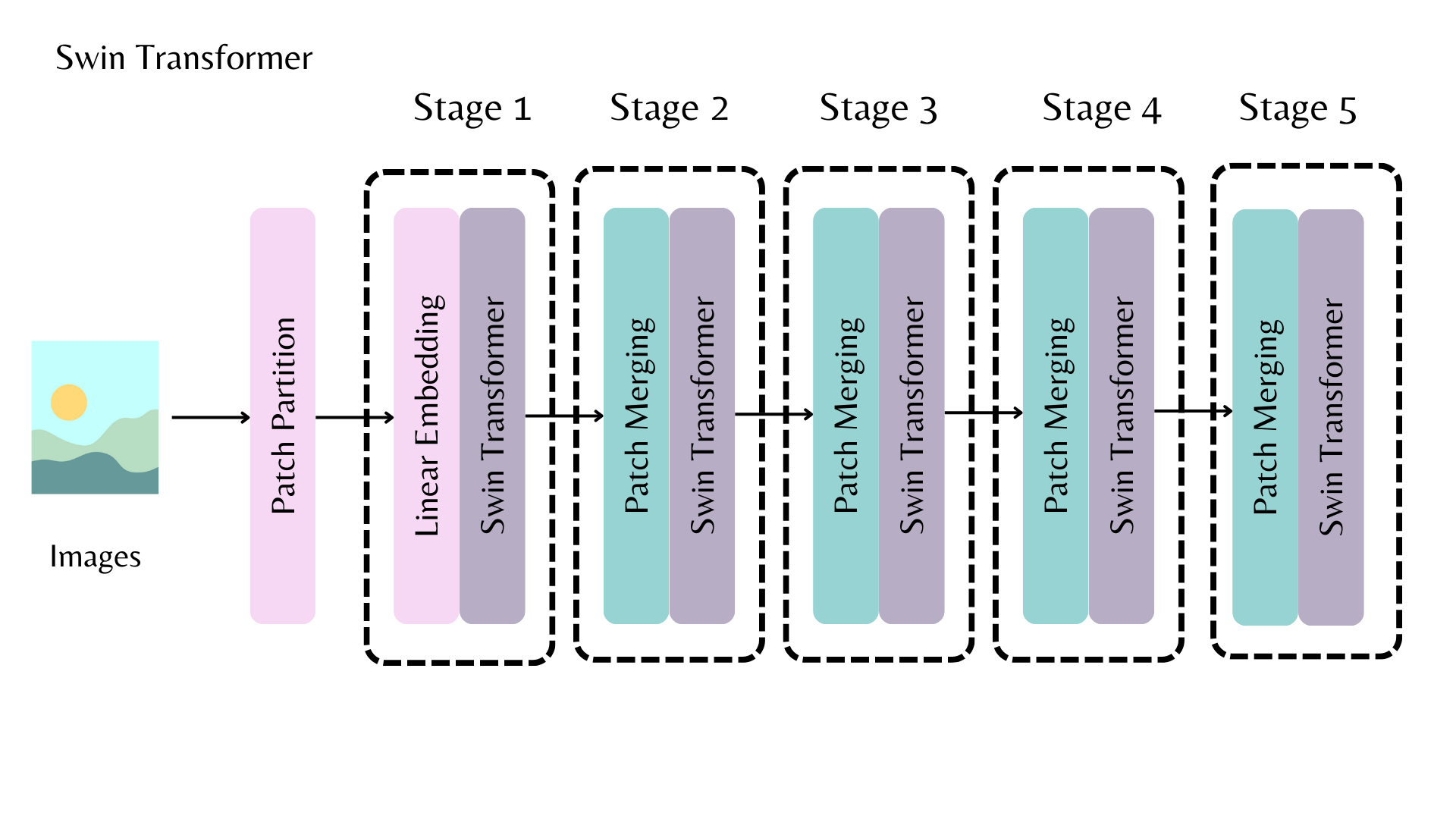
AutoBackbone 允许您使用预训练模型作为骨干网络,从骨干网络的不同阶段获取特征图。您应该在 from_pretrained() 中指定以下参数之一:
out_indices是你想要获取特征图的层的索引out_features是您想要获取特征图的层的名称
这些参数可以互换使用,但如果你同时使用它们,请确保它们彼此对齐!如果你不传递任何这些参数,骨干网络将返回最后一层的特征图。
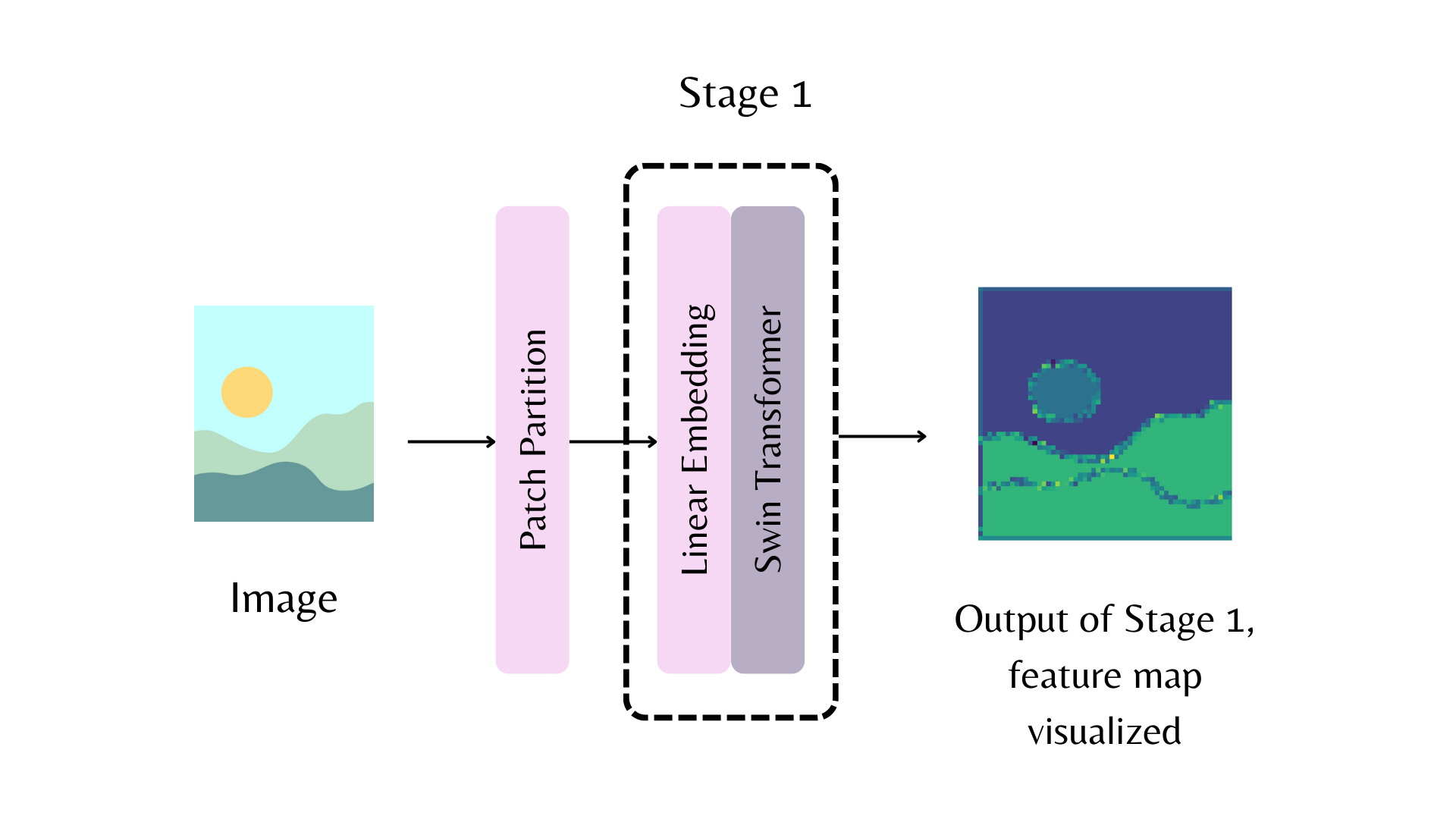
例如,在上图中,要从Swin骨干网络的第一阶段返回特征图,你可以设置out_indices=(1,):
>>> from transformers import AutoImageProcessor, AutoBackbone
>>> import torch
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> processor = AutoImageProcessor.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
>>> model = AutoBackbone.from_pretrained("microsoft/swin-tiny-patch4-window7-224", out_indices=(1,))
>>> inputs = processor(image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> feature_maps = outputs.feature_maps现在你可以从主干的第一个阶段访问 feature_maps 对象:
>>> list(feature_maps[0].shape)
[1, 96, 56, 56]AutoFeatureExtractor
对于音频任务,特征提取器将音频信号处理为正确的输入格式。
使用AutoFeatureExtractor.from_pretrained()加载特征提取器:
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained(
... "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
... )自动处理器
多模态任务需要一个结合两种预处理工具的处理器。例如,LayoutLMV2 模型需要一个图像处理器来处理图像和一个分词器来处理文本;处理器将两者结合在一起。
使用AutoProcessor.from_pretrained()加载处理器:
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")AutoModel
AutoModelFor 类允许您为给定任务加载预训练模型(请参阅此处以获取可用任务的完整列表)。例如,使用AutoModelForSequenceClassification.from_pretrained()加载用于序列分类的模型。
默认情况下,权重以全精度(torch.float32)加载,无论权重实际存储的数据类型是什么,例如torch.float16。设置torch_dtype="auto"以加载模型config.json文件中定义的数据类型,以自动加载最节省内存的数据类型。
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased", torch_dtype="auto")轻松重用相同的检查点来加载不同任务的架构:
>>> from transformers import AutoModelForTokenClassification
>>> model = AutoModelForTokenClassification.from_pretrained("distilbert/distilbert-base-uncased", torch_dtype="auto")对于PyTorch模型,from_pretrained()方法使用torch.load(),该方法内部使用pickle,已知是不安全的。一般来说,永远不要加载可能来自不可信来源的模型,或者可能被篡改的模型。对于托管在Hugging Face Hub上的公共模型,这种安全风险部分得到了缓解,这些模型在每次提交时都会扫描恶意软件。请参阅Hub文档以了解最佳实践,例如使用GPG进行签名提交验证。
TensorFlow 和 Flax 的检查点不受影响,并且可以通过使用 from_tf 和 from_flax 参数在 PyTorch 架构中加载,以规避此问题。
通常,我们建议使用AutoTokenizer类和AutoModelFor类来加载预训练的模型实例。这将确保每次都能加载正确的架构。在接下来的教程中,学习如何使用新加载的分词器、图像处理器、特征提取器和处理器来预处理数据集以进行微调。
最后,TFAutoModelFor 类允许你加载一个预训练模型用于给定任务(查看 这里 获取可用任务的完整列表)。例如,使用 TFAutoModelForSequenceClassification.from_pretrained() 加载一个用于序列分类的模型:
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")轻松重用相同的检查点来加载不同任务的架构:
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert/distilbert-base-uncased")通常,我们建议使用AutoTokenizer类和TFAutoModelFor类来加载预训练的模型实例。这将确保每次都能加载正确的架构。在接下来的教程中,学习如何使用新加载的分词器、图像处理器、特征提取器和处理器来预处理数据集以进行微调。