优化
.optimization 模块提供:
- 一个带有固定权重衰减的优化器,可用于微调模型,以及
- 多个继承自
_LRSchedule的计划对象形式的计划: - 一个梯度累积类,用于累积多个批次的梯度
AdamW (PyTorch)
类 transformers.AdamW
< source >( params: typing.Iterable[torch.nn.parameter.Parameter] lr: float = 0.001 betas: typing.Tuple[float, float] = (0.9, 0.999) eps: float = 1e-06 weight_decay: float = 0.0 correct_bias: bool = True no_deprecation_warning: bool = False )
参数
- params (
Iterable[nn.parameter.Parameter]) — 要优化的参数的可迭代对象或定义参数组的字典。 - lr (
float, optional, 默认为 0.001) — 使用的学习率。 - betas (
Tuple[float,float], 可选, 默认为(0.9, 0.999)) — Adam的betas参数 (b1, b2)。 - eps (
float, optional, defaults to 1e-06) — 用于数值稳定性的Adam的epsilon值。 - weight_decay (
float, optional, 默认为 0.0) — 应用解耦权重衰减。 - correct_bias (
bool, 可选, 默认为True) — 是否在Adam中纠正偏差(例如,在Bert TF仓库中他们使用False)。 - no_deprecation_warning (
bool, 可选, 默认为False) — 用于禁用弃用警告的标志(设置为True以禁用警告)。
实现了Adam算法,并加入了权重衰减修复,如解耦权重衰减正则化中所述。
执行单个优化步骤。
AdaFactor (PyTorch)
类 transformers.Adafactor
< source >( params lr = 无 eps = (1e-30, 0.001) clip_threshold = 1.0 decay_rate = -0.8 beta1 = 无 weight_decay = 0.0 scale_parameter = 真 relative_step = 真 warmup_init = 假 )
参数
- params (
Iterable[nn.parameter.Parameter]) — 要优化的参数的可迭代对象或定义参数组的字典。 - lr (
float, optional) — 外部学习率. - eps (
Tuple[float, float], 可选, 默认为(1e-30, 0.001)) — 分别用于平方梯度和参数尺度的正则化常数 - clip_threshold (
float, optional, defaults to 1.0) — 最终梯度更新的均方根阈值 - decay_rate (
float, optional, 默认为 -0.8) — 用于计算平方的运行平均值的系数 - beta1 (
float, optional) — 用于计算梯度运行平均值的系数 - weight_decay (
float, optional, defaults to 0.0) — 权重衰减(L2惩罚) - scale_parameter (
bool, optional, defaults toTrue) — 如果为True,学习率将通过均方根进行缩放 - relative_step (
bool, optional, defaults toTrue) — 如果为True,则计算时间依赖的学习率而不是外部学习率 - warmup_init (
bool, optional, 默认为False) — 时间依赖的学习率计算取决于是否使用了预热初始化
AdaFactor pytorch 实现可以作为 Adam 原始 fairseq 代码的替代品: https://github.com/pytorch/fairseq/blob/master/fairseq/optim/adafactor.py
论文: Adafactor: 具有次线性内存成本的自适应学习率 https://arxiv.org/abs/1804.04235 请注意
此优化器内部会根据scale_parameter、relative_step和
warmup_init选项调整学习率。要使用手动(外部)学习率调度,您应设置scale_parameter=False和
relative_step=False。
此实现处理低精度(FP16,bfloat)值,但我们尚未进行彻底测试。
推荐的T5微调设置 (https://discuss.huggingface.co/t/t5-finetuning-tips/684/3):
不建议在没有LR预热或clip_threshold的情况下进行训练。
- use scheduled LR warm-up to fixed LR
- use clip_threshold=1.0 (https://arxiv.org/abs/1804.04235)
禁用相对更新
使用 scale_parameter=False
不应将梯度裁剪等额外的优化器操作与Adafactor一起使用
示例:
Adafactor(model.parameters(), scale_parameter=False, relative_step=False, warmup_init=False, lr=1e-3)其他人报告以下组合效果良好:
Adafactor(model.parameters(), scale_parameter=True, relative_step=True, warmup_init=True, lr=None)当使用lr=None与Trainer时,您很可能需要使用AdafactorSchedule
调度器如下:
from transformers.optimization import Adafactor, AdafactorSchedule
optimizer = Adafactor(model.parameters(), scale_parameter=True, relative_step=True, warmup_init=True, lr=None)
lr_scheduler = AdafactorSchedule(optimizer)
trainer = Trainer(..., optimizers=(optimizer, lr_scheduler))用法:
# replace AdamW with Adafactor
optimizer = Adafactor(
model.parameters(),
lr=1e-3,
eps=(1e-30, 1e-3),
clip_threshold=1.0,
decay_rate=-0.8,
beta1=None,
weight_decay=0.0,
relative_step=False,
scale_parameter=False,
warmup_init=False,
)执行单个优化步骤
AdamWeightDecay (TensorFlow)
类 transformers.AdamWeightDecay
< source >( learning_rate: typing.Union[float, tf_keras.src.optimizers.schedules.learning_rate_schedule.LearningRateSchedule] = 0.001 beta_1: float = 0.9 beta_2: float = 0.999 epsilon: float = 1e-07 amsgrad: bool = False weight_decay_rate: float = 0.0 include_in_weight_decay: typing.Optional[typing.List[str]] = None exclude_from_weight_decay: typing.Optional[typing.List[str]] = None name: str = 'AdamWeightDecay' **kwargs )
参数
- learning_rate (
Union[float, LearningRateSchedule], 可选, 默认为 0.001) — 使用的学习率或学习率计划。 - beta_1 (
float, optional, 默认为 0.9) — Adam 中的 beta1 参数,这是第一动量估计的指数衰减率。 - beta_2 (
float, optional, 默认为 0.999) — Adam 中的 beta2 参数,它是第二动量估计的指数衰减率。 - epsilon (
float, optional, 默认为 1e-07) — Adam 中的 epsilon 参数,这是一个用于数值稳定性的小常数。 - amsgrad (
bool, 可选, 默认为False) — 是否应用此算法的AMSGrad变体,参见 On the Convergence of Adam and Beyond. - weight_decay_rate (
float, optional, 默认为 0.0) — 应用的权重衰减。 - include_in_weight_decay (
List[str], 可选) — 要应用权重衰减的参数名称(或正则表达式模式)列表。如果没有传递任何参数,默认情况下权重衰减将应用于所有参数(除非它们在exclude_from_weight_decay中)。 - exclude_from_weight_decay (
List[str], 可选) — 要排除在权重衰减之外的参数名称(或正则表达式模式)列表。如果传递了include_in_weight_decay,其中的名称将优先于此列表。 - name (
str, optional, defaults to"AdamWeightDecay") — 应用梯度时创建的操作的可选名称。 - kwargs (
Dict[str, Any], 可选) — 关键字参数。允许的参数包括 {clipnorm,clipvalue,lr,decay}。clipnorm是通过范数裁剪梯度;clipvalue是通过值裁剪梯度,decay是为了向后兼容,允许学习率的时间逆衰减。lr是为了向后兼容,建议使用learning_rate代替。
Adam 在梯度上启用了 L2 权重衰减和 clip_by_global_norm。仅仅将权重的平方添加到损失函数中不是使用 L2 正则化/权重衰减与 Adam 的正确方法,因为这会以奇怪的方式与 m 和 v 参数交互,如解耦权重衰减正则化所示。
相反,我们希望以一种不与m/v参数交互的方式衰减权重。这相当于在使用普通(非动量)SGD时,将权重的平方添加到损失中。
从其配置创建一个带有WarmUp自定义对象的优化器。
transformers.create_optimizer
< source >( init_lr: float num_train_steps: int num_warmup_steps: int min_lr_ratio: float = 0.0 adam_beta1: float = 0.9 adam_beta2: float = 0.999 adam_epsilon: float = 1e-08 adam_clipnorm: typing.Optional[float] = None adam_global_clipnorm: typing.Optional[float] = None weight_decay_rate: float = 0.0 power: float = 1.0 include_in_weight_decay: typing.Optional[typing.List[str]] = None )
参数
- init_lr (
float) — 在预热阶段结束时所需的学习率。 - num_train_steps (
int) — 训练步骤的总数. - num_warmup_steps (
int) — 预热步骤的数量。 - min_lr_ratio (
float, 可选, 默认为 0) — 线性衰减结束时的最终学习率将为init_lr * min_lr_ratio. - adam_beta1 (
float, optional, 默认为 0.9) — 在 Adam 中使用的 beta1 值。 - adam_beta2 (
float, optional, 默认为 0.999) — 在 Adam 中使用的 beta2 值。 - adam_epsilon (
float, optional, 默认为 1e-8) — 在 Adam 中使用的 epsilon 值。 - adam_clipnorm (
float, 可选, 默认为None) — 如果不是None,则将每个权重张量的梯度范数裁剪到此值。 - adam_global_clipnorm (
float, 可选, 默认为None) — 如果不是None,则将梯度范数裁剪到此值。使用此参数时,范数是针对所有权重张量计算的,就像它们被连接成一个单一向量一样。 - weight_decay_rate (
float, optional, defaults to 0) — 使用的权重衰减率。 - power (
float, 可选, 默认为 1.0) — 用于PolynomialDecay的幂值。 - include_in_weight_decay (
List[str], 可选) — 要应用权重衰减的参数名称(或正则表达式模式)列表。如果未传递任何参数,则权重衰减将应用于除偏置和层归一化参数之外的所有参数。
创建一个带有学习率计划的优化器,使用预热阶段后跟线性衰减。
日程安排
学习率调度器 (PyTorch)
类 transformers.SchedulerType
< source >( value names = 无 module = 无 qualname = 无 type = 无 start = 1 )
参数 lr_scheduler_type 在 TrainingArguments 中的调度器名称。
默认情况下,它使用“linear”。在内部,这会从 Trainer 中检索 get_linear_schedule_with_warmup 调度器。
调度器类型:
- “linear” = get_linear_schedule_with_warmup
- “cosine” = get_cosine_schedule_with_warmup
- “cosine_with_restarts” = get_cosine_with_hard_restarts_schedule_with_warmup
- “多项式” = get_polynomial_decay_schedule_with_warmup
- “constant” = get_constant_schedule
- “constant_with_warmup” = get_constant_schedule_with_warmup
- “inverse_sqrt” = get_inverse_sqrt_schedule
- “reduce_lr_on_plateau” = get_reduce_on_plateau_schedule
- “cosine_with_min_lr” = get_cosine_with_min_lr_schedule_with_warmup
- “warmup_stable_decay” = get_wsd_schedule
transformers.get_scheduler
< source >( name: typing.Union[str, transformers.trainer_utils.SchedulerType] optimizer: Optimizer num_warmup_steps: typing.Optional[int] = None num_training_steps: typing.Optional[int] = None scheduler_specific_kwargs: typing.Optional[dict] = None )
参数
- name (
str或SchedulerType) — 要使用的调度程序的名称。 - optimizer (
torch.optim.Optimizer) — 将在训练期间使用的优化器。 - num_warmup_steps (
int, optional) — 预热步骤的数量。并非所有调度器都需要此参数(因此该参数是可选的),如果未设置且调度器类型需要它,函数将引发错误。 - num_training_steps (`int`, 可选) — 要进行的训练步骤数。并非所有调度器都需要此参数(因此该参数是可选的),如果未设置且调度器类型需要它,函数将引发错误。
- scheduler_specific_kwargs (
dict, 可选) — 用于调度器的额外参数,例如带重启的余弦调度器。不匹配的调度器类型和调度器参数将导致调度器函数引发 TypeError.
统一的API,通过名称获取任何调度程序。
transformers.get_constant_schedule
< source >( optimizer: 优化器 last_epoch: int = -1 )
使用优化器中设置的学习率创建一个恒定学习率的计划。
transformers.get_constant_schedule_with_warmup
< source >( optimizer: 优化器 num_warmup_steps: 整数 last_epoch: 整数 = -1 )
创建一个学习率恒定的计划,前面有一个预热期,在此期间学习率在0和优化器中设置的初始学习率之间线性增加。
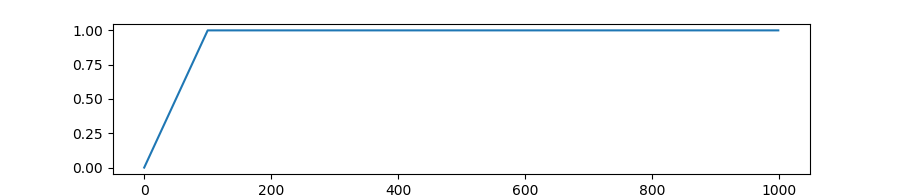
transformers.get_cosine_schedule_with_warmup
< source >( optimizer: 优化器 num_warmup_steps: 整数 num_training_steps: 整数 num_cycles: 浮点数 = 0.5 last_epoch: 整数 = -1 )
创建一个学习率调度,该调度在学习率预热期间从0线性增加到优化器中设置的初始学习率,之后学习率按照余弦函数的值从优化器中设置的初始学习率逐渐减少到0。
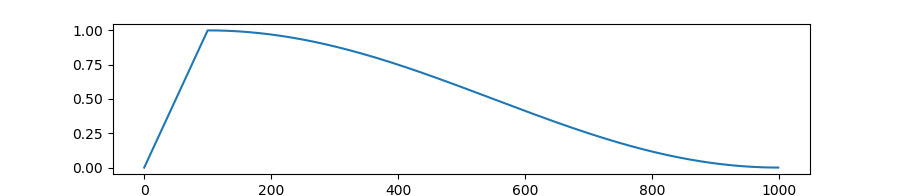
transformers.get_cosine_with_hard_restarts_schedule_with_warmup
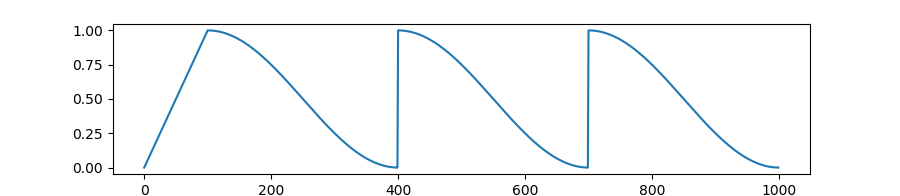
< source >( optimizer: 优化器 num_warmup_steps: 整数 num_training_steps: 整数 num_cycles: 整数 = 1 last_epoch: 整数 = -1 )
创建一个学习率调度,该调度在学习率预热期间线性增加,从0增加到优化器中设置的初始学习率,然后在预热期结束后,学习率按照余弦函数的值从优化器中设置的初始学习率逐渐减少到0,期间会有几次硬重启。
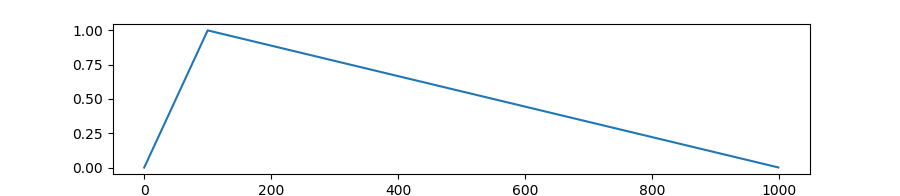
transformers.get_linear_schedule_with_warmup
< source >( optimizer num_warmup_steps num_training_steps last_epoch = -1 )
创建一个学习率调度器,该调度器在预热期间从0线性增加到优化器中设置的初始学习率,之后从优化器中设置的初始学习率线性减少到0。
transformers.get_polynomial_decay_schedule_with_warmup
< source >( optimizer num_warmup_steps num_training_steps lr_end = 1e-07 power = 1.0 last_epoch = -1 )
创建一个学习率调度器,该调度器的学习率从优化器中设置的初始学习率开始,经过一个预热期后,以多项式衰减的方式降低到由lr_end定义的最终学习率。在预热期内,学习率从0线性增加到优化器中设置的初始学习率。
注意:power 默认值为 1.0,与 fairseq 实现中的一致,而 fairseq 又是基于原始 BERT 实现的,具体实现位于 https://github.com/google-research/bert/blob/f39e881b169b9d53bea03d2d341b31707a6c052b/optimization.py#L37
transformers.get_inverse_sqrt_schedule
< source >( optimizer: 优化器 num_warmup_steps: 整数 timescale: 整数 = 无 last_epoch: 整数 = -1 )
创建一个具有反平方根学习率的调度器,从优化器中设置的初始学习率开始,经过一个预热期,该预热期将学习率从0线性增加到优化器中设置的初始学习率。
transformers.get_wsd_schedule
< source >( optimizer: 优化器 num_warmup_steps: 整数 num_stable_steps: 整数 num_decay_steps: 整数 min_lr_ratio: 浮点数 = 0 num_cycles: 浮点数 = 0.5 last_epoch: 整数 = -1 )
参数
- optimizer (
~torch.optim.Optimizer) — 用于调度学习率的优化器。 - num_warmup_steps (
int) — 预热阶段的步骤数。 - num_stable_steps (
int) — 稳定阶段的步骤数。 - num_decay_steps (
int) — 余弦退火阶段的步数。 - min_lr_ratio (
float, optional, defaults to 0) — 最小学习率与初始学习率的比率。 - num_cycles (
float, optional, defaults to 0.5) — 余弦调度中的波数(默认值是从最大值减少到0,遵循半余弦)。 - last_epoch (
int, optional, defaults to -1) — 恢复训练时的最后一个周期的索引。
创建一个具有三个阶段的学习率计划:
- 从0线性增加到初始学习率。
- 常数学习率(等于初始学习率)。
- 按照余弦函数的值从优化器中设置的初始学习率减少到初始学习率的一部分。
预热 (TensorFlow)
类 transformers.WarmUp
< source >( initial_learning_rate: float decay_schedule_fn: typing.Callable warmup_steps: int power: float = 1.0 name: str = None )
在给定的学习率衰减计划上应用预热计划。
梯度策略
梯度累加器 (TensorFlow)
梯度累积工具。当与分布式策略一起使用时,累加器应在副本上下文中调用。梯度将在每个副本上本地累积,无需同步。用户应随后调用.gradients,如果需要则缩放梯度,并将结果传递给apply_gradients。
重置当前副本上累积的梯度。