🤗 Transformers 如何解决任务
在What 🤗 Transformers can do中,您了解了自然语言处理(NLP)、语音和音频、计算机视觉任务以及它们的一些重要应用。本页将深入探讨模型如何解决这些任务,并解释背后的原理。解决给定任务的方法有很多,一些模型可能采用某些技术,甚至从新的角度来处理任务,但对于Transformer模型来说,总体思路是相同的。由于其灵活的架构,大多数模型都是编码器、解码器或编码器-解码器结构的变体。除了Transformer模型,我们的库还包含几个卷积神经网络(CNNs),这些网络至今仍用于计算机视觉任务。我们还将解释现代CNN的工作原理。
为了解释任务是如何解决的,我们将逐步了解模型内部是如何运作以输出有用的预测的。
- Wav2Vec2 用于音频分类和自动语音识别 (ASR)
- Vision Transformer (ViT) 和 ConvNeXT 用于图像分类
- DETR 用于目标检测
- Mask2Former 用于图像分割
- GLPN 用于深度估计
- BERT 用于使用编码器的NLP任务,如文本分类、标记分类和问答
- GPT2 用于使用解码器的自然语言处理任务,如文本生成
- BART 用于使用编码器-解码器的自然语言处理任务,如摘要和翻译
在继续之前,最好对原始Transformer架构有一些基本的了解。了解编码器、解码器和注意力机制的工作原理将有助于你理解不同Transformer模型的工作方式。如果你刚开始学习或需要复习,请查看我们的课程以获取更多信息!
语音和音频
Wav2Vec2 是一个自监督模型,预训练于未标记的语音数据,并在标记数据上进行微调,用于音频分类和自动语音识别。
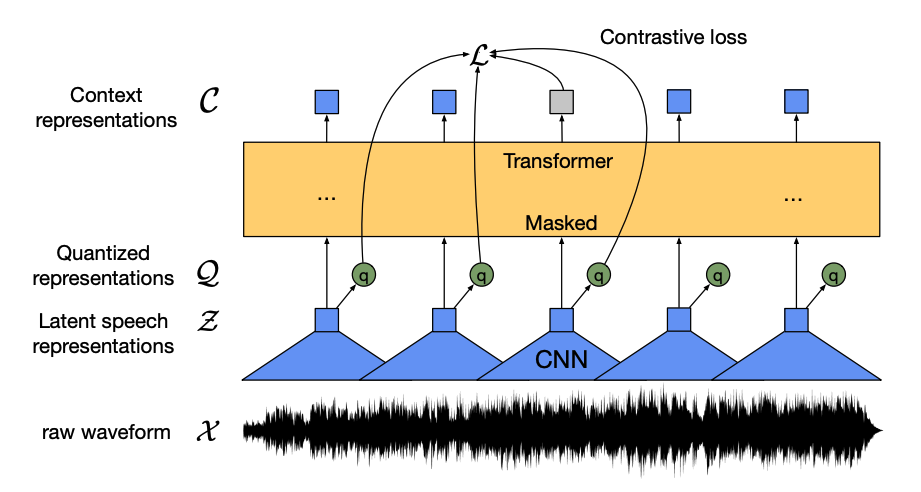
该模型有四个主要组成部分:
一个特征编码器接收原始音频波形,将其归一化为零均值和单位方差,并将其转换为每个20毫秒长的特征向量序列。
波形本质上是连续的,因此它们不能像文本序列可以分割成单词那样被分成独立的单元。这就是为什么特征向量被传递到一个量化模块,该模块旨在学习离散的语音单元。语音单元是从一组码字中选择的,这组码字被称为码本(你可以将其视为词汇表)。从码本中,选择最能代表连续音频输入的向量或语音单元,并通过模型进行传递。
大约一半的特征向量被随机掩码,掩码后的特征向量被输入到一个上下文网络中,这是一个Transformer编码器,它还添加了相对位置嵌入。
上下文网络的预训练目标是一个对比任务。模型必须从一组错误的量化语音表示中预测出被掩码预测的真实量化语音表示,从而鼓励模型找到最相似的上下文向量和量化语音单元(目标标签)。
现在wav2vec2已经预训练好了,你可以在你的数据上对其进行微调,用于音频分类或自动语音识别!
音频分类
要使用预训练模型进行音频分类,请在基础Wav2Vec2模型之上添加一个序列分类头。分类头是一个线性层,它接受编码器的隐藏状态。隐藏状态表示从每个音频帧中学习到的特征,这些帧的长度可能不同。为了创建一个固定长度的向量,首先对隐藏状态进行池化,然后将其转换为类别标签的logits。在logits和目标之间计算交叉熵损失,以找到最可能的类别。
准备好尝试音频分类了吗?查看我们的完整音频分类指南,学习如何微调Wav2Vec2并使用它进行推理!
自动语音识别
要使用预训练模型进行自动语音识别,请在基础Wav2Vec2模型之上添加一个语言建模头,用于连接时序分类(CTC)。语言建模头是一个线性层,它接受编码器的隐藏状态并将其转换为logits。每个logit代表一个标记类(标记的数量来自任务词汇表)。CTC损失在logits和目标之间计算,以找到最可能的标记序列,然后将其解码为转录文本。
准备好尝试自动语音识别了吗?查看我们的完整自动语音识别指南,学习如何微调Wav2Vec2并使用它进行推理!
计算机视觉
有两种方法可以处理计算机视觉任务:
- 将图像分割成一系列补丁,并使用Transformer并行处理它们。
- 使用现代的CNN,如ConvNeXT,它依赖于卷积层但采用现代网络设计。
第三种方法将Transformers与卷积混合(例如,Convolutional Vision Transformer 或 LeViT)。我们不会讨论这些,因为它们只是结合了我们在这里探讨的两种方法。
ViT 和 ConvNeXT 通常用于图像分类,但对于其他视觉任务,如目标检测、分割和深度估计,我们将分别研究 DETR、Mask2Former 和 GLPN;这些模型更适合这些任务。
图像分类
ViT 和 ConvNeXT 都可以用于图像分类;主要区别在于 ViT 使用注意力机制,而 ConvNeXT 使用卷积。
Transformer
ViT 完全用纯Transformer架构取代了卷积。如果你熟悉原始的Transformer,那么你已经大部分理解了ViT。

ViT 引入的主要变化在于如何将图像输入到 Transformer 中:
图像被分割成不重叠的正方形小块,每个小块被转换为一个向量或小块嵌入。小块嵌入是通过一个卷积2D层生成的,该层创建了适当的输入维度(对于基础Transformer来说,每个小块嵌入有768个值)。如果你有一个224x224像素的图像,你可以将其分割成196个16x16的图像小块。就像文本被分词成单词一样,图像被“分词”成一系列小块。
一个可学习的嵌入 - 一个特殊的
[CLS]标记 - 被添加到补丁嵌入的开头,就像BERT一样。[CLS]标记的最终隐藏状态被用作附加分类头的输入;其他输出被忽略。这个标记帮助模型学习如何编码图像的表示。最后需要添加到补丁和可学习嵌入中的是位置嵌入,因为模型不知道图像补丁是如何排序的。位置嵌入也是可学习的,并且与补丁嵌入的大小相同。最后,所有的嵌入都被传递给Transformer编码器。
输出,特别是仅带有
[CLS]标记的输出,被传递到多层感知器头(MLP)。ViT的预训练目标仅仅是分类。与其他分类头一样,MLP头将输出转换为类标签上的logits,并计算交叉熵损失以找到最可能的类别。
准备好尝试图像分类了吗?查看我们的完整图像分类指南,学习如何微调ViT并使用它进行推理!
CNN
本节简要解释了卷积,但如果事先了解它们如何改变图像的形状和大小会更有帮助。如果您不熟悉卷积,请查看Convolution Neural Networks chapter来自fastai书籍的章节!
ConvNeXT 是一种采用新颖且现代的网络设计以提高性能的CNN架构。然而,卷积仍然是模型的核心。从高层次的角度来看,卷积是一种操作,其中较小的矩阵(内核)与图像像素的小窗口相乘。它从中计算一些特征,例如特定的纹理或线条的曲率。然后它滑动到下一个像素窗口;卷积移动的距离被称为步幅。

你可以将这个输出传递给另一个卷积层,随着每一层的传递,网络会学习到更复杂和抽象的事物,比如热狗或火箭。在卷积层之间,通常会添加一个池化层来减少维度,并使模型对特征位置的变化更加稳健。

ConvNeXT 以五种方式现代化了 CNN:
更改每个阶段中的块数,并使用更大的步幅和相应的内核大小对图像进行“分块”。这种非重叠的滑动窗口使这种分块策略类似于ViT将图像分割成块的方式。
一个瓶颈层会减少通道的数量,然后再恢复它,因为进行1x1卷积更快,并且可以增加深度。一个反向瓶颈则相反,它会扩展通道的数量然后再缩小它们,这样更节省内存。
将瓶颈层中典型的3x3卷积层替换为深度卷积,它对每个输入通道分别应用卷积,然后在最后将它们堆叠在一起。这扩大了网络的宽度以提高性能。
ViT 具有全局感受野,这意味着由于其注意力机制,它可以一次看到图像的更多部分。ConvNeXT 试图通过将内核大小增加到 7x7 来复制这种效果。
ConvNeXT 还进行了几层设计更改,模仿了 Transformer 模型。激活和归一化层更少,激活函数从 ReLU 切换为 GELU,并且使用 LayerNorm 代替 BatchNorm。
卷积块的输出被传递到分类头,分类头将输出转换为logits并计算交叉熵损失,以找到最可能的标签。
目标检测
DETR, DEtection TRansformer, 是一个结合了CNN和Transformer编码器-解码器的端到端目标检测模型。
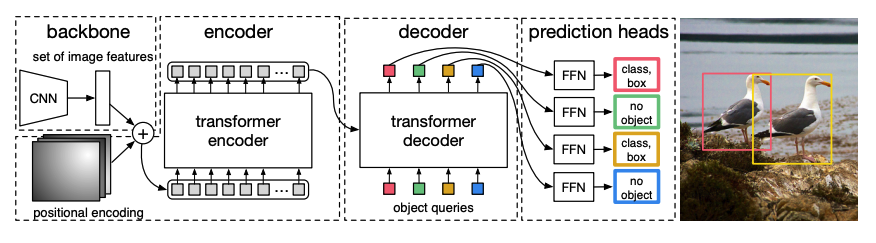
一个预训练的CNN 骨干网络接收一张图像,由其像素值表示,并生成其低分辨率特征图。对特征图应用1x1卷积以降低维度,并生成具有高级图像表示的新特征图。由于Transformer是一个序列模型,特征图被展平为一系列特征向量,并与位置嵌入相结合。
特征向量被传递给编码器,编码器使用其注意力层学习图像表示。接下来,编码器的隐藏状态与解码器中的对象查询结合。对象查询是学习的嵌入,专注于图像的不同区域,并且它们在通过每个注意力层时更新。解码器的隐藏状态被传递给前馈网络,该网络预测每个对象查询的边界框坐标和类别标签,如果没有对象,则预测为
no object。DETR并行解码每个对象查询以输出N个最终预测,其中N是查询的数量。与一次预测一个元素的典型自回归模型不同,对象检测是一个集合预测任务(
bounding box,class label),它一次性做出N个预测。DETR在训练过程中使用二分匹配损失来比较固定数量的预测与固定的一组真实标签。如果在N个标签的集合中真实标签较少,则用
no object类进行填充。这种损失函数鼓励DETR在预测和真实标签之间找到一对一的分配。如果边界框或类别标签不正确,就会产生损失。同样,如果DETR预测了一个不存在的对象,它也会受到惩罚。这鼓励DETR在图像中找到其他对象,而不是只关注一个非常突出的对象。
在DETR的顶部添加了一个目标检测头,用于查找类别标签和边界框的坐标。目标检测头有两个组成部分:一个线性层,用于将解码器的隐藏状态转换为类别标签的logits,以及一个MLP,用于预测边界框。
准备好尝试物体检测了吗?查看我们的完整物体检测指南,学习如何微调DETR并使用它进行推理!
图像分割
Mask2Former 是一个用于解决所有类型图像分割任务的通用架构。传统的分割模型通常针对图像分割的特定子任务进行定制,例如实例分割、语义分割或全景分割。Mask2Former 将每个任务都视为一个掩码分类问题。掩码分类将像素分组为N个片段,并为给定图像预测N个掩码及其对应的类别标签。我们将在本节中解释 Mask2Former 的工作原理,然后你可以在最后尝试微调 SegFormer。

Mask2Former 有三个主要组件:
一个Swin骨干网络接受一张图像,并通过3个连续的3x3卷积生成一个低分辨率的图像特征图。
特征图被传递给一个像素解码器,该解码器逐渐将低分辨率特征上采样为高分辨率的逐像素嵌入。像素解码器实际上生成了多尺度特征(包含低分辨率和高分辨率特征),其分辨率为原始图像的1/32、1/16和1/8。
这些不同尺度的特征图依次被送入一个Transformer解码器层,以便从高分辨率特征中捕捉小物体。Mask2Former的关键在于解码器中的掩码注意力机制。与可以关注整个图像的交叉注意力不同,掩码注意力只关注图像的某个区域。这更快且能带来更好的性能,因为图像的局部特征足以让模型学习。
与DETR类似,Mask2Former也使用学习的对象查询,并将它们与像素解码器的图像特征结合,以进行集合预测(
class label,mask prediction)。解码器的隐藏状态通过线性层传递,并转换为类标签的logits。在logits和类标签之间计算交叉熵损失,以找到最可能的一个。掩码预测是通过将像素嵌入与最终解码器隐藏状态结合生成的。在logits和真实掩码之间计算sigmoid交叉熵和dice损失,以找到最可能的掩码。
准备好尝试图像分割了吗?查看我们的完整图像分割指南,学习如何微调SegFormer并使用它进行推理!
深度估计
GLPN, 全局-局部路径网络, 是一个用于深度估计的Transformer,它结合了SegFormer编码器和一个轻量级解码器。

与ViT类似,图像被分割成一系列小块,只不过这些图像块更小。这对于分割或深度估计等密集预测任务更为有利。图像块被转换为块嵌入(有关如何创建块嵌入的更多详细信息,请参见图像分类部分),然后输入到编码器中。
编码器接受补丁嵌入,并将它们通过多个编码器块传递。每个块由注意力层和Mix-FFN层组成。后者的目的是提供位置信息。在每个编码器块的末尾是一个补丁合并层,用于创建层次表示。每组相邻补丁的特征被连接起来,并对连接后的特征应用线性层,以将补丁数量减少到1/4的分辨率。这成为下一个编码器块的输入,整个过程重复进行,直到获得分辨率为1/8、1/16和1/32的图像特征。
一个轻量级的解码器从编码器获取最后一个特征图(1/32比例)并将其上采样到1/16比例。从这里,特征被传递到一个选择性特征融合(SFF)模块,该模块从每个特征的注意力图中选择和组合局部和全局特征,然后将其上采样到1/8比例。这个过程重复进行,直到解码后的特征与原始图像的大小相同。输出通过两个卷积层,然后应用sigmoid激活函数来预测每个像素的深度。
自然语言处理
Transformer最初是为机器翻译设计的,从那时起,它实际上已成为解决所有NLP任务的默认架构。一些任务适合Transformer的编码器结构,而另一些任务则更适合解码器。还有一些任务则利用了Transformer的编码器-解码器结构。
文本分类
BERT 是一个仅包含编码器的模型,并且是第一个有效实现深度双向性的模型,通过关注文本两侧的单词来学习更丰富的文本表示。
BERT使用WordPiece分词来生成文本的标记嵌入。为了区分单个句子和句子对,添加了一个特殊的
[SEP]标记来区分它们。在每个文本序列的开头添加了一个特殊的[CLS]标记。带有[CLS]标记的最终输出用作分类任务的分类头的输入。BERT还添加了一个段嵌入来表示标记是否属于句子对中的第一个或第二个句子。BERT通过两个目标进行预训练:掩码语言建模和下一句预测。在掩码语言建模中,输入标记的某些百分比被随机掩码,模型需要预测这些被掩码的部分。这解决了双向性的问题,即模型可能会作弊并看到所有单词并“预测”下一个单词。预测的掩码标记的最终隐藏状态被传递到一个前馈网络,通过词汇表上的softmax来预测被掩码的单词。
第二个预训练目标是下一句预测。模型必须预测句子B是否跟随句子A。一半的时间句子B是下一句,另一半的时间,句子B是一个随机句子。预测结果,无论是否是下一句,都会传递给一个前馈网络,该网络对两个类别(
IsNext和NotNext)进行softmax处理。输入的嵌入通过多个编码器层传递,以输出一些最终的隐藏状态。
要使用预训练模型进行文本分类,请在基础BERT模型之上添加一个序列分类头。序列分类头是一个线性层,它接受最终的隐藏状态并执行线性变换以将其转换为logits。在logits和目标之间计算交叉熵损失,以找到最可能的标签。
准备好尝试文本分类了吗?查看我们的完整文本分类指南,学习如何微调DistilBERT并将其用于推理!
Token分类
要将BERT用于命名实体识别(NER)等标记分类任务,请在基础BERT模型之上添加一个标记分类头。标记分类头是一个线性层,它接受最终的隐藏状态并执行线性变换以将其转换为logits。在logits和每个标记之间计算交叉熵损失,以找到最可能的标签。
准备好尝试一下标记分类了吗?查看我们的完整标记分类指南,学习如何微调DistilBERT并使用它进行推理!
问答
要使用BERT进行问答,请在基础BERT模型之上添加一个span分类头。这个线性层接受最终的隐藏状态,并执行线性变换以计算与答案对应的span开始和结束的logits。在logits和标签位置之间计算交叉熵损失,以找到与答案对应的最可能的文本span。
准备好尝试问答了吗?查看我们的完整问答指南,学习如何微调DistilBERT并使用它进行推理!
💡 注意,一旦BERT经过预训练,使用它来完成不同任务是多么容易。你只需要在预训练模型上添加一个特定的头部,就可以将隐藏状态转换为你想要的输出!
文本生成
GPT-2 是一个仅解码器模型,预训练于大量文本上。它可以根据提示生成令人信服(尽管不总是真实!)的文本,并完成其他自然语言处理任务,如问答,尽管它并未明确接受过这些任务的训练。
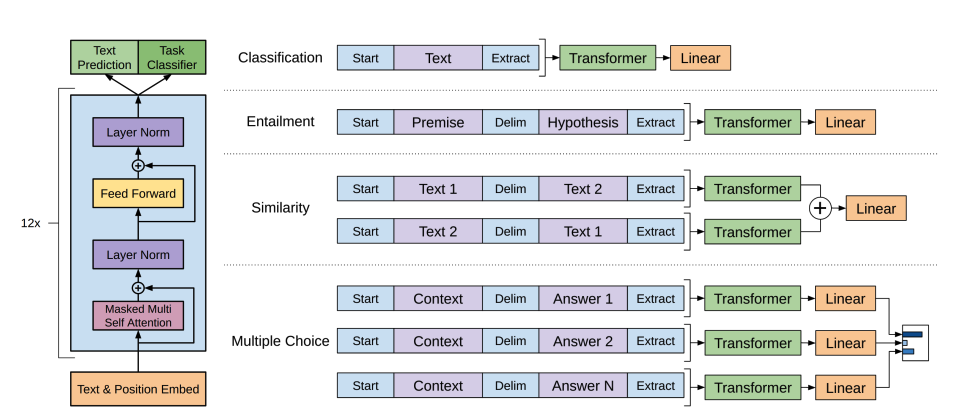
GPT-2 使用 字节对编码 (BPE) 来对单词进行分词并生成词嵌入。位置编码被添加到词嵌入中,以指示每个词在序列中的位置。输入嵌入通过多个解码器块传递,以输出一些最终的隐藏状态。在每个解码器块中,GPT-2 使用了一个掩码自注意力层,这意味着 GPT-2 不能关注未来的词。它只能关注左侧的词。这与 BERT 的
mask标记不同,因为在掩码自注意力中,使用注意力掩码将未来词的分数设置为0。解码器的输出被传递给语言建模头,该头执行线性变换以将隐藏状态转换为logits。标签是序列中的下一个标记,这是通过将logits向右移动一位来创建的。在移动的logits和标签之间计算交叉熵损失,以输出下一个最可能的标记。
GPT-2的预训练目标完全基于因果语言建模,即预测序列中的下一个单词。这使得GPT-2在涉及生成文本的任务中表现得尤为出色。
准备好尝试文本生成了吗?查看我们的完整因果语言建模指南,学习如何微调DistilGPT-2并将其用于推理!
有关文本生成的更多信息,请查看文本生成策略指南!
总结
像BART和T5这样的编码器-解码器模型是为摘要任务的序列到序列模式设计的。我们将在本节中解释BART的工作原理,然后你可以在最后尝试微调T5。
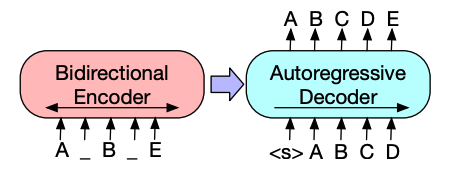
BART的编码器架构与BERT非常相似,并接受文本的标记和位置嵌入。BART通过破坏输入然后使用解码器重建来进行预训练。与其他具有特定破坏策略的编码器不同,BART可以应用任何类型的破坏。不过,文本填充破坏策略效果最好。在文本填充中,多个文本片段被替换为一个单一的
mask标记。这很重要,因为模型必须预测被遮蔽的标记,并且它教会模型预测缺失标记的数量。输入嵌入和被遮蔽的片段通过编码器传递以输出一些最终的隐藏状态,但与BERT不同,BART在最后没有添加一个前馈网络来预测单词。编码器的输出传递给解码器,解码器必须从编码器的输出中预测被掩码的标记和任何未损坏的标记。这为解码器提供了额外的上下文,以帮助其恢复原始文本。解码器的输出传递给语言建模头,该头执行线性变换以将隐藏状态转换为logits。在logits和标签之间计算交叉熵损失,标签只是向右移动的标记。
准备好尝试摘要生成了吗?查看我们的完整摘要指南,学习如何微调T5并使用它进行推理!
有关文本生成的更多信息,请查看文本生成策略指南!
翻译
翻译是另一个序列到序列任务的例子,这意味着你可以使用像BART或T5这样的编码器-解码器模型来完成它。我们将在本节中解释BART的工作原理,然后你可以在最后尝试微调T5。
BART通过添加一个单独随机初始化的编码器来适应翻译任务,该编码器将源语言映射到可以解码为目标语言的输入。这个新编码器的嵌入被传递给预训练的编码器,而不是原始的词嵌入。源编码器通过更新源编码器、位置嵌入和输入嵌入来训练,使用模型输出的交叉熵损失。在第一步中,模型参数被冻结,所有模型参数在第二步中一起训练。
BART 随后被多语言版本 mBART 所跟进,旨在用于翻译并在许多不同语言上进行了预训练。
准备好尝试翻译了吗?查看我们的完整翻译指南,学习如何微调T5并使用它进行推理!
有关文本生成的更多信息,请查看文本生成策略指南!