ConvNeXT
概述
ConvNeXT模型由Zhuang Liu、Hanzi Mao、Chao-Yuan Wu、Christoph Feichtenhofer、Trevor Darrell和Saining Xie在A ConvNet for the 2020s中提出。 ConvNeXT是一个纯卷积模型(ConvNet),受到Vision Transformers设计的启发,声称能够超越它们。
论文的摘要如下:
视觉识别的“咆哮20年代”始于Vision Transformers(ViTs)的引入,它迅速取代了ConvNets成为最先进的图像分类模型。然而,普通的ViT在应用于一般计算机视觉任务(如目标检测和语义分割)时面临困难。正是分层Transformers(例如,Swin Transformers)重新引入了几个ConvNet的先验知识,使得Transformers作为通用视觉骨干变得实际可行,并在各种视觉任务中表现出色。然而,这种混合方法的有效性仍然主要归功于Transformers的内在优势,而不是卷积的固有归纳偏差。在这项工作中,我们重新审视了设计空间,并测试了纯ConvNet可以达到的极限。我们逐步“现代化”一个标准的ResNet,朝着视觉Transformer的设计方向前进,并在此过程中发现了几个关键组件,这些组件对性能差异有贡献。这次探索的结果是一系列名为ConvNeXt的纯ConvNet模型。完全由标准ConvNet模块构建的ConvNeXts在准确性和可扩展性方面与Transformers竞争,达到了87.8%的ImageNet top-1准确率,并在COCO检测和ADE20K分割上优于Swin Transformers,同时保持了标准ConvNets的简单性和效率。
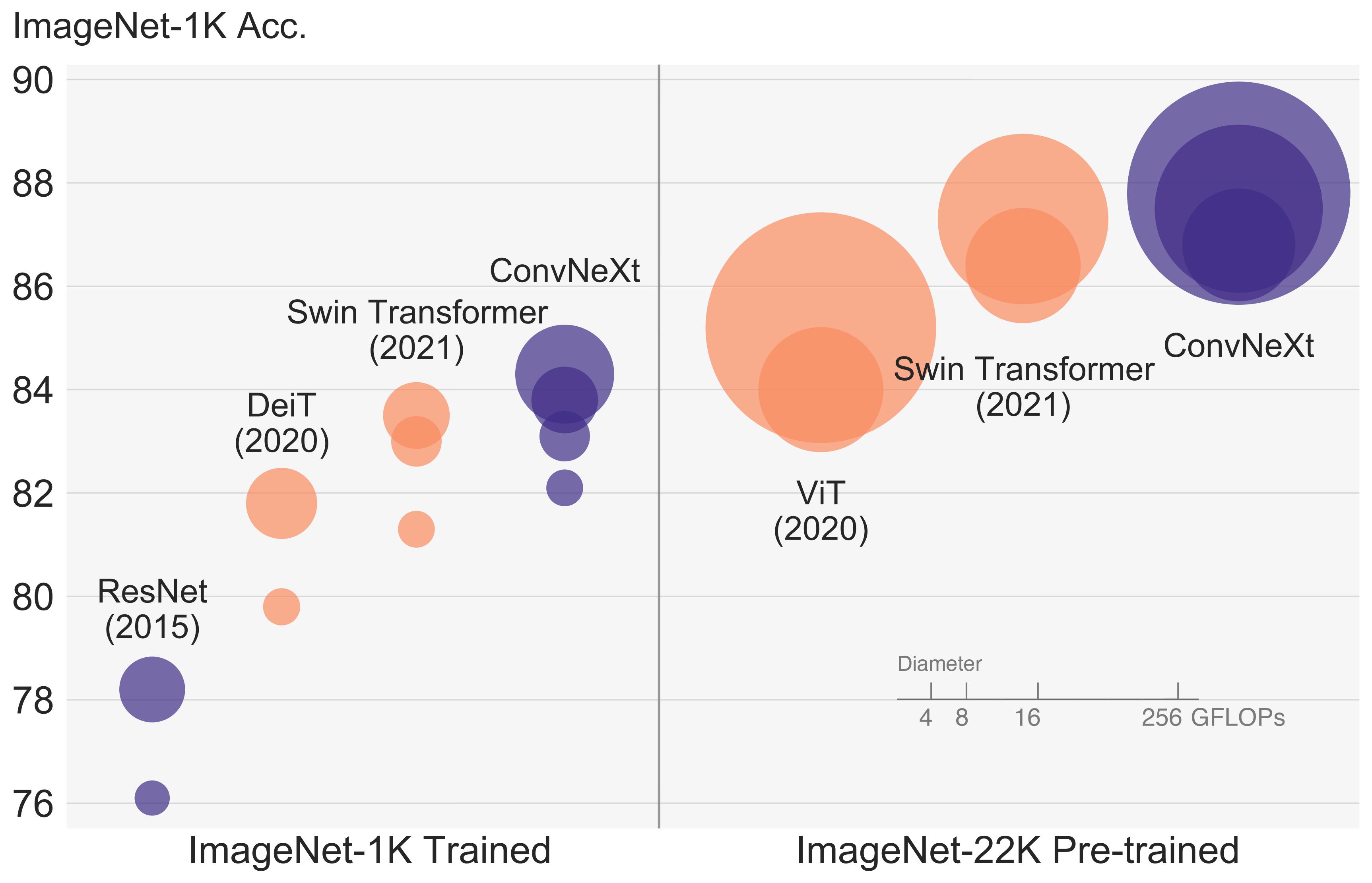 ConvNeXT architecture. Taken from the original paper.
ConvNeXT architecture. Taken from the original paper. 该模型由nielsr贡献。模型的TensorFlow版本由ariG23498、gante和sayakpaul(同等贡献)贡献。原始代码可以在这里找到。
资源
一份官方的 Hugging Face 和社区(由🌎表示)资源列表,帮助您开始使用 ConvNeXT。
- ConvNextForImageClassification 由这个 示例脚本 和 笔记本 支持。
- 另请参阅:图像分类任务指南
如果您有兴趣提交资源以包含在此处,请随时打开一个 Pull Request,我们将进行审核!理想情况下,资源应展示一些新内容,而不是重复现有资源。
ConvNextConfig
类 transformers.ConvNextConfig
< source >( num_channels = 3 patch_size = 4 num_stages = 4 hidden_sizes = None depths = None hidden_act = 'gelu' initializer_range = 0.02 layer_norm_eps = 1e-12 layer_scale_init_value = 1e-06 drop_path_rate = 0.0 image_size = 224 out_features = None out_indices = None **kwargs )
参数
- num_channels (
int, optional, defaults to 3) — 输入通道的数量。 - patch_size (
int, optional, 默认为 4) — 在补丁嵌入层中使用的补丁大小。 - num_stages (
int, optional, defaults to 4) — 模型中的阶段数。 - hidden_sizes (
List[int], optional, 默认为 [96, 192, 384, 768]) — 每个阶段的维度(隐藏大小)。 - depths (
List[int], 可选, 默认为 [3, 3, 9, 3]) — 每个阶段的深度(块的数量)。 - hidden_act (
str或function, 可选, 默认为"gelu") — 每个块中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu","relu","selu"和"gelu_new". - initializer_range (
float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 - layer_norm_eps (
float, optional, defaults to 1e-12) — 层归一化层使用的epsilon值。 - layer_scale_init_value (
float, optional, defaults to 1e-6) — 层比例的初始值。 - drop_path_rate (
float, optional, defaults to 0.0) — 随机深度的丢弃率。 - out_features (
List[str], 可选) — 如果用作骨干网络,输出特征的列表。可以是"stem","stage1","stage2"等。 (取决于模型有多少个阶段)。如果未设置且out_indices已设置,将默认为相应的阶段。如果未设置且out_indices也未设置,将默认为最后一个阶段。必须与stage_names属性中定义的顺序相同。 - out_indices (
List[int], 可选) — 如果用作骨干网络,输出特征的索引列表。可以是0、1、2等(取决于模型有多少个阶段)。如果未设置且out_features已设置,将默认为相应的阶段。 如果未设置且out_features也未设置,将默认为最后一个阶段。必须与stage_names属性中定义的顺序相同。
这是用于存储ConvNextModel配置的配置类。它用于根据指定的参数实例化ConvNeXT模型,定义模型架构。使用默认值实例化配置将产生类似于ConvNeXT facebook/convnext-tiny-224架构的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import ConvNextConfig, ConvNextModel
>>> # Initializing a ConvNext convnext-tiny-224 style configuration
>>> configuration = ConvNextConfig()
>>> # Initializing a model (with random weights) from the convnext-tiny-224 style configuration
>>> model = ConvNextModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configConvNext特征提取器
ConvNextImageProcessor
类 transformers.ConvNextImageProcessor
< source >( do_resize: bool = True size: typing.Dict[str, int] = None crop_pct: float = None resample: Resampling =
参数
- do_resize (
bool, 可选, 默认为True) — 控制是否将图像的(高度,宽度)尺寸调整为指定的size。可以在preprocess方法中通过do_resize进行覆盖。 - size (
Dict[str, int]可选, 默认为{"shortest_edge" -- 384}): 应用resize后输出图像的分辨率。如果size["shortest_edge"]>= 384,图像将被调整为(size["shortest_edge"], size["shortest_edge"])。否则,图像的较小边将匹配到int(size["shortest_edge"]/crop_pct),之后图像将被裁剪为(size["shortest_edge"], size["shortest_edge"])。仅在do_resize设置为True时有效。可以在preprocess方法中被size覆盖。 - crop_pct (
float可选, 默认为 224 / 256) — 裁剪图像的百分比。仅在do_resize为True且大小小于 384 时有效。可以在preprocess方法中被crop_pct覆盖。 - resample (
PILImageResampling, 可选, 默认为Resampling.BILINEAR) — 如果调整图像大小,使用的重采样过滤器。可以在preprocess方法中通过resample覆盖。 - do_rescale (
bool, 可选, 默认为True) — 是否通过指定的比例rescale_factor重新缩放图像。可以在preprocess方法中被do_rescale覆盖。 - rescale_factor (
int或float, 可选, 默认为1/255) — 如果重新缩放图像,则使用的缩放因子。可以在preprocess方法中被rescale_factor覆盖。 - do_normalize (
bool, 可选, 默认为True) — 是否对图像进行归一化。可以在preprocess方法中通过do_normalize参数进行覆盖。 - image_mean (
float或List[float], 可选, 默认为IMAGENET_STANDARD_MEAN) — 如果对图像进行归一化,则使用的均值。这是一个浮点数或与图像通道数长度相同的浮点数列表。可以通过preprocess方法中的image_mean参数进行覆盖。 - image_std (
float或List[float], 可选, 默认为IMAGENET_STANDARD_STD) — 如果对图像进行归一化,则使用的标准差。这是一个浮点数或与图像通道数长度相同的浮点数列表。可以通过preprocess方法中的image_std参数进行覆盖。
构建一个ConvNeXT图像处理器。
预处理
< source >( images: typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), typing.List[ForwardRef('PIL.Image.Image')], typing.List[numpy.ndarray], typing.List[ForwardRef('torch.Tensor')]] do_resize: bool = None size: typing.Dict[str, int] = None crop_pct: float = None resample: Resampling = None do_rescale: bool = None rescale_factor: float = None do_normalize: bool = None image_mean: typing.Union[float, typing.List[float], NoneType] = None image_std: typing.Union[float, typing.List[float], NoneType] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None data_format: ChannelDimension =
参数
- 图像 (
ImageInput) — 要预处理的图像。期望输入单个或批量的图像,像素值范围在0到255之间。如果传入的图像像素值在0到1之间,请设置do_rescale=False. - do_resize (
bool, optional, defaults toself.do_resize) — 是否调整图像大小. - size (
Dict[str, int], 可选, 默认为self.size) — 应用resize后输出图像的大小。如果size["shortest_edge"]>= 384,图像 将被调整为(size["shortest_edge"], size["shortest_edge"])。否则,图像的较小边将 匹配到int(size["shortest_edge"]/ crop_pct),然后图像将被裁剪为(size["shortest_edge"], size["shortest_edge"])。仅在do_resize设置为True时有效。 - crop_pct (
float, optional, defaults toself.crop_pct) — 如果尺寸小于384,裁剪图像的百分比。 - resample (
int, 可选, 默认为self.resample) — 如果调整图像大小,则使用的重采样过滤器。这可以是PILImageResampling过滤器之一。只有在do_resize设置为True时才会生效。 - do_rescale (
bool, optional, defaults toself.do_rescale) — 是否将图像值缩放到 [0 - 1] 之间。 - rescale_factor (
float, 可选, 默认为self.rescale_factor) — 如果do_rescale设置为True,则用于重新缩放图像的重新缩放因子。 - do_normalize (
bool, 可选, 默认为self.do_normalize) — 是否对图像进行归一化处理. - image_mean (
float或List[float], 可选, 默认为self.image_mean) — 图像均值. - image_std (
floatorList[float], optional, defaults toself.image_std) — 图像标准差. - return_tensors (
str或TensorType, 可选) — 返回的张量类型。可以是以下之一:- 未设置:返回一个
np.ndarray列表。 TensorType.TENSORFLOW或'tf':返回一个类型为tf.Tensor的批次。TensorType.PYTORCH或'pt':返回一个类型为torch.Tensor的批次。TensorType.NUMPY或'np':返回一个类型为np.ndarray的批次。TensorType.JAX或'jax':返回一个类型为jax.numpy.ndarray的批次。
- 未设置:返回一个
- data_format (
ChannelDimension或str, 可选, 默认为ChannelDimension.FIRST) — 输出图像的通道维度格式。可以是以下之一:"channels_first"或ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。"channels_last"或ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。- 未设置:使用输入图像的通道维度格式。
- input_data_format (
ChannelDimension或str, 可选) — 输入图像的通道维度格式。如果未设置,则从输入图像推断通道维度格式。可以是以下之一:"channels_first"或ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。"channels_last"或ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。"none"或ChannelDimension.NONE: 图像格式为 (height, width)。
预处理一张图像或一批图像。
ConvNextModel
类 transformers.ConvNextModel
< source >( config )
参数
- config (ConvNextConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸ConvNext模型输出原始特征,没有任何特定的头部。 该模型是PyTorch torch.nn.Module 的子类。将其用作常规的PyTorch模块,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( pixel_values: FloatTensor = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.BaseModelOutputWithPoolingAndNoAttention 或 tuple(torch.FloatTensor)
参数
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用AutoImageProcessor获取。详情请参见 ConvNextImageProcessor.call(). - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPoolingAndNoAttention 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithPoolingAndNoAttention 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(ConvNextConfig)和输入。
-
last_hidden_state (
torch.FloatTensor形状为(batch_size, num_channels, height, width)) — 模型最后一层输出的隐藏状态序列。 -
pooler_output (
torch.FloatTensor形状为(batch_size, hidden_size)) — 在空间维度上进行池化操作后的最后一层隐藏状态。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, num_channels, height, width)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
ConvNextModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, ConvNextModel
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image", trust_remote_code=True)
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("facebook/convnext-tiny-224")
>>> model = ConvNextModel.from_pretrained("facebook/convnext-tiny-224")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 768, 7, 7]ConvNextForImageClassification
类 transformers.ConvNextForImageClassification
< source >( config )
参数
- config (ConvNextConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
ConvNext 模型,顶部带有图像分类头(在池化特征之上的线性层),例如用于 ImageNet。
该模型是一个PyTorch torch.nn.Module 子类。将其用作常规的PyTorch模块,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( pixel_values: FloatTensor = None labels: typing.Optional[torch.LongTensor] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.ImageClassifierOutputWithNoAttention 或 tuple(torch.FloatTensor)
参数
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用AutoImageProcessor获取。详情请参见 ConvNextImageProcessor.call(). - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - labels (
torch.LongTensor形状为(batch_size,), 可选) — 用于计算图像分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.ImageClassifierOutputWithNoAttention 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.ImageClassifierOutputWithNoAttention 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(ConvNextConfig)和输入。
- loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 分类(或回归,如果 config.num_labels==1)损失。 - logits (
torch.FloatTensor形状为(batch_size, config.num_labels)) — 分类(或回归,如果 config.num_labels==1)得分(在 SoftMax 之前)。 - hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每个阶段的输出)形状为(batch_size, num_channels, height, width)。模型在每个阶段输出的隐藏状态(也称为特征图)。
ConvNextForImageClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, ConvNextForImageClassification
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image", trust_remote_code=True)
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("facebook/convnext-tiny-224")
>>> model = ConvNextForImageClassification.from_pretrained("facebook/convnext-tiny-224")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
tabby, tabby catTFConvNextModel
类 transformers.TFConvNextModel
< source >( config *inputs add_pooling_layer = True **kwargs )
参数
- config (ConvNextConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸ConvNext模型输出原始特征,没有任何特定的头部。 该模型继承自TFPreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入大小、修剪头部等)。
该模型也是一个keras.Model子类。可以将其作为常规的TF 2.0 Keras模型使用,并参考TF 2.0文档以了解与一般使用和行为相关的所有事项。
TensorFlow 模型和层在 transformers 中接受两种格式作为输入:
- 将所有输入作为关键字参数(如PyTorch模型),或
- 将所有输入作为列表、元组或字典放在第一个位置参数中。
支持第二种格式的原因是,Keras 方法在将输入传递给模型和层时更喜欢这种格式。由于这种支持,当使用像 model.fit() 这样的方法时,事情应该“正常工作”——只需以 model.fit() 支持的任何格式传递你的输入和标签!然而,如果你想在 Keras 方法之外使用第二种格式,比如在使用 Keras Functional API 创建自己的层或模型时,有三种方法可以用来将所有输入张量收集到第一个位置参数中:
- 仅包含
pixel_values的单个张量,没有其他内容:model(pixel_values) - 一个长度不定的列表,包含一个或多个输入张量,顺序与文档字符串中给出的顺序一致:
model([pixel_values, attention_mask])或model([pixel_values, attention_mask, token_type_ids]) - 一个字典,包含一个或多个与文档字符串中给出的输入名称相关联的输入张量:
model({"pixel_values": pixel_values, "token_type_ids": token_type_ids})
请注意,当使用子类化创建模型和层时,您不需要担心这些,因为您可以像传递任何其他Python函数一样传递输入!
调用
< source >( pixel_values: TFModelInputType | None = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: bool = False ) → transformers.modeling_tf_outputs.TFBaseModelOutputWithPooling 或 tuple(tf.Tensor)
参数
- pixel_values (
np.ndarray,tf.Tensor,List[tf.Tensor]`Dict[str, tf.Tensor]orDict[str, np.ndarray]and each example must have the shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用AutoImageProcessor获取。详情请参见 ConvNextImageProcessor.call(). - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。此参数只能在eager模式下使用,在graph模式下将使用配置中的值。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。这个参数可以在eager模式下使用,在graph模式下该值将始终设置为True.
返回
transformers.modeling_tf_outputs.TFBaseModelOutputWithPooling 或 tuple(tf.Tensor)
一个 transformers.modeling_tf_outputs.TFBaseModelOutputWithPooling 或一个 tf.Tensor 元组(如果
return_dict=False 被传递或当 config.return_dict=False 时),包含根据配置(ConvNextConfig)和输入的各种元素。
-
last_hidden_state (
tf.Tensor形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。 -
pooler_output (
tf.Tensor形状为(batch_size, hidden_size)) — 序列的第一个标记(分类标记)的最后一层隐藏状态,经过线性层和 Tanh 激活函数进一步处理。线性层的权重是在预训练期间通过下一个句子预测(分类)目标训练的。这个输出通常不是输入语义内容的一个好的总结,通常更好的做法是对整个输入序列的隐藏状态序列进行平均或池化。
-
hidden_states (
tuple(tf.Tensor), 可选, 当output_hidden_states=True被传递或当config.output_hidden_states=True时返回) —tf.Tensor元组(一个用于嵌入的输出 + 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(tf.Tensor), 可选, 当output_attentions=True被传递或当config.output_attentions=True时返回) —tf.Tensor元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
TFConvNextModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, TFConvNextModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("facebook/convnext-tiny-224")
>>> model = TFConvNextModel.from_pretrained("facebook/convnext-tiny-224")
>>> inputs = image_processor(images=image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateTFConvNextForImageClassification
类 transformers.TFConvNextForImageClassification
< source >( config: ConvNextConfig *inputs **kwargs )
参数
- config (ConvNextConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
ConvNext 模型,顶部带有图像分类头(在池化特征之上的线性层),例如用于 ImageNet。
该模型继承自 TFPreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个keras.Model子类。可以将其作为常规的TF 2.0 Keras模型使用,并参考TF 2.0文档以了解与一般使用和行为相关的所有事项。
TensorFlow 模型和层在 transformers 中接受两种格式作为输入:
- 将所有输入作为关键字参数(如PyTorch模型),或
- 将所有输入作为列表、元组或字典放在第一个位置参数中。
支持第二种格式的原因是,Keras 方法在将输入传递给模型和层时更喜欢这种格式。由于这种支持,当使用像 model.fit() 这样的方法时,事情应该“正常工作”——只需以 model.fit() 支持的任何格式传递你的输入和标签!然而,如果你想在 Keras 方法之外使用第二种格式,比如在使用 Keras Functional API 创建自己的层或模型时,有三种方法可以用来将所有输入张量收集到第一个位置参数中:
- 仅包含
pixel_values的单个张量,没有其他内容:model(pixel_values) - 一个长度不定的列表,包含一个或多个输入张量,顺序与文档字符串中给出的顺序一致:
model([pixel_values, attention_mask])或model([pixel_values, attention_mask, token_type_ids]) - 一个字典,包含一个或多个与文档字符串中给出的输入名称相关联的输入张量:
model({"pixel_values": pixel_values, "token_type_ids": token_type_ids})
请注意,当使用子类化创建模型和层时,您不需要担心这些,因为您可以像传递任何其他Python函数一样传递输入!
调用
< source >( pixel_values: TFModelInputType | None = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None labels: np.ndarray | tf.Tensor | None = None training: Optional[bool] = False ) → transformers.modeling_tf_outputs.TFSequenceClassifierOutput 或 tuple(tf.Tensor)
参数
- pixel_values (
np.ndarray,tf.Tensor,List[tf.Tensor]`Dict[str, tf.Tensor]orDict[str, np.ndarray]and each example must have the shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用AutoImageProcessor获取。详情请参见 ConvNextImageProcessor.call(). - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。此参数只能在急切模式下使用,在图形模式下将使用配置中的值。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。此参数可以在eager模式下使用,在graph模式下该值将始终设置为True. - labels (
tf.Tensor或np.ndarray形状为(batch_size,), 可选) — 用于计算图像分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_tf_outputs.TFSequenceClassifierOutput 或 tuple(tf.Tensor)
一个 transformers.modeling_tf_outputs.TFSequenceClassifierOutput 或一个 tf.Tensor 的元组(如果
return_dict=False 被传递或当 config.return_dict=False 时)包含各种元素,具体取决于
配置 (ConvNextConfig) 和输入。
-
loss (
tf.Tensor形状为(batch_size, ), 可选, 当提供labels时返回) — 分类(或回归,如果 config.num_labels==1)损失。 -
logits (
tf.Tensor形状为(batch_size, config.num_labels)) — 分类(或回归,如果 config.num_labels==1)得分(在 SoftMax 之前)。 -
hidden_states (
tuple(tf.Tensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) —tf.Tensor的元组(一个用于嵌入的输出 + 一个用于每层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(tf.Tensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) —tf.Tensor的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
TFConvNextForImageClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, TFConvNextForImageClassification
>>> import tensorflow as tf
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("facebook/convnext-tiny-224")
>>> model = TFConvNextForImageClassification.from_pretrained("facebook/convnext-tiny-224")
>>> inputs = image_processor(images=image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_class_idx = tf.math.argmax(logits, axis=-1)[0]
>>> print("Predicted class:", model.config.id2label[int(predicted_class_idx)])