Swin2SR
概述
Swin2SR模型由Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte在Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration中提出。 Swin2SR通过引入Swin Transformer v2层改进了SwinIR模型,缓解了训练不稳定性、预训练和微调之间的分辨率差距以及数据需求等问题。
论文的摘要如下:
压缩在通过带宽受限系统(如流媒体服务、虚拟现实或视频游戏)高效传输和存储图像和视频方面起着重要作用。然而,压缩不可避免地会导致伪影和原始信息的丢失,这可能会严重降低视觉质量。因此,压缩图像的质量增强已成为一个热门的研究课题。虽然大多数最先进的图像恢复方法基于卷积神经网络,但其他基于变压器的方法(如SwinIR)在这些任务中表现出色。 在本文中,我们探索了新颖的Swin Transformer V2,以改进SwinIR用于图像超分辨率,特别是压缩输入场景。使用这种方法,我们可以解决训练变压器视觉模型中的主要问题,如训练不稳定性、预训练和微调之间的分辨率差距以及数据需求。我们在三个代表性任务上进行了实验:JPEG压缩伪影去除、图像超分辨率(经典和轻量级)以及压缩图像超分辨率。实验结果表明,我们的方法Swin2SR可以改善SwinIR的训练收敛性和性能,并且在“AIM 2022压缩图像和视频超分辨率挑战赛”中名列前五。
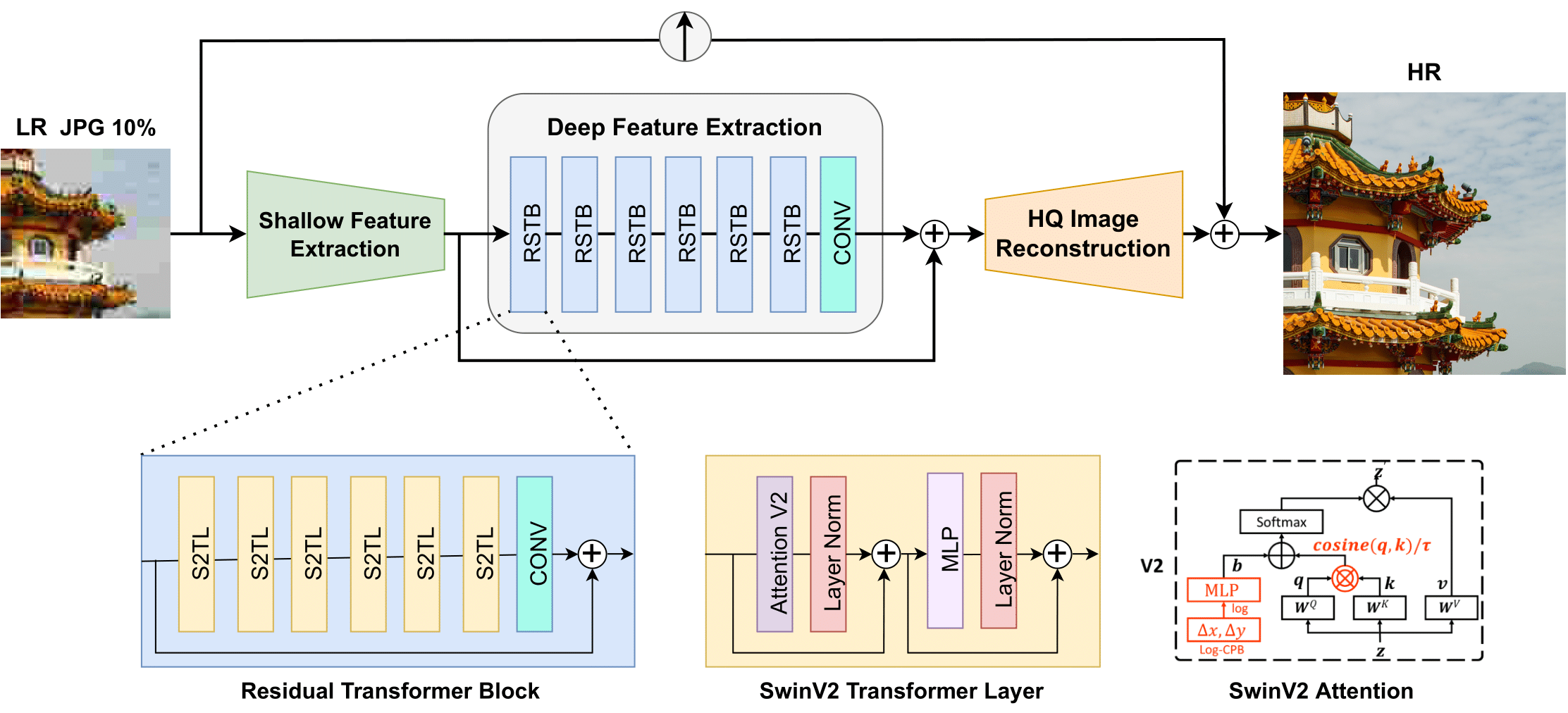 Swin2SR architecture. Taken from the original paper.
Swin2SR architecture. Taken from the original paper. 资源
Swin2SR的演示笔记本可以在这里找到。
一个使用SwinSR进行图像超分辨率的演示空间可以在这里找到。
Swin2SRImageProcessor
类 transformers.Swin2SRImageProcessor
< source >( do_rescale: bool = True rescale_factor: typing.Union[int, float] = 0.00392156862745098 do_pad: bool = True pad_size: int = 8 **kwargs )
构建一个Swin2SR图像处理器。
预处理
< source >( images: typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), typing.List[ForwardRef('PIL.Image.Image')], typing.List[numpy.ndarray], typing.List[ForwardRef('torch.Tensor')]] do_rescale: typing.Optional[bool] = None rescale_factor: typing.Optional[float] = None do_pad: typing.Optional[bool] = None pad_size: typing.Optional[int] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None data_format: typing.Union[str, transformers.image_utils.ChannelDimension] =
参数
- 图像 (
ImageInput) — 要预处理的图像。期望输入单个或批量的图像,像素值范围在0到255之间。如果传入的图像像素值在0到1之间,请设置do_rescale=False. - do_rescale (
bool, optional, defaults toself.do_rescale) — 是否将图像值缩放到 [0 - 1] 之间。 - rescale_factor (
float, 可选, 默认为self.rescale_factor) — 如果do_rescale设置为True,则用于重新缩放图像的重新缩放因子。 - do_pad (
bool, 可选, 默认为True) — 是否对图像进行填充以使高度和宽度可被window_size整除. - pad_size (
int, 可选, 默认为 32) — 局部注意力的滑动窗口大小。 - return_tensors (
str或TensorType, 可选) — 返回的张量类型。可以是以下之一:- 未设置:返回一个
np.ndarray列表。 TensorType.TENSORFLOW或'tf':返回一批类型为tf.Tensor的张量。TensorType.PYTORCH或'pt':返回一批类型为torch.Tensor的张量。TensorType.NUMPY或'np':返回一批类型为np.ndarray的张量。TensorType.JAX或'jax':返回一批类型为jax.numpy.ndarray的张量。
- 未设置:返回一个
- data_format (
ChannelDimension或str, 可选, 默认为ChannelDimension.FIRST) — 输出图像的通道维度格式。可以是以下之一:"channels_first"或ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。"channels_last"或ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。- 未设置:使用输入图像的通道维度格式。
- input_data_format (
ChannelDimension或str, 可选) — 输入图像的通道维度格式。如果未设置,则从输入图像推断通道维度格式。可以是以下之一:"channels_first"或ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。"channels_last"或ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。"none"或ChannelDimension.NONE: 图像格式为 (height, width)。
预处理一张图像或一批图像。
Swin2SRConfig
类 transformers.Swin2SRConfig
< source >( image_size = 64 patch_size = 1 num_channels = 3 num_channels_out = None embed_dim = 180 depths = [6, 6, 6, 6, 6, 6] num_heads = [6, 6, 6, 6, 6, 6] window_size = 8 mlp_ratio = 2.0 qkv_bias = True hidden_dropout_prob = 0.0 attention_probs_dropout_prob = 0.0 drop_path_rate = 0.1 hidden_act = 'gelu' use_absolute_embeddings = False initializer_range = 0.02 layer_norm_eps = 1e-05 upscale = 2 img_range = 1.0 resi_connection = '1conv' upsampler = 'pixelshuffle' **kwargs )
参数
- image_size (
int, optional, defaults to 64) — 每张图片的大小(分辨率)。 - patch_size (
int, optional, defaults to 1) — 每个补丁的大小(分辨率)。 - num_channels (
int, optional, 默认为 3) — 输入通道的数量。 - num_channels_out (
int, 可选, 默认为num_channels) — 输出通道的数量。如果未设置,将设置为num_channels. - embed_dim (
int, optional, 默认为 180) — 补丁嵌入的维度. - depths (
list(int), optional, defaults to[6, 6, 6, 6, 6, 6]) — Transformer编码器中每一层的深度。 - num_heads (
list(int), 可选, 默认为[6, 6, 6, 6, 6, 6]) — Transformer编码器每一层中的注意力头数。 - window_size (
int, optional, defaults to 8) — 窗口大小. - mlp_ratio (
float, optional, defaults to 2.0) — MLP隐藏维度与嵌入维度的比率。 - qkv_bias (
bool, optional, defaults toTrue) — 是否应该向查询、键和值添加可学习的偏置。 - hidden_dropout_prob (
float, optional, 默认为 0.0) — 嵌入层和编码器中所有全连接层的 dropout 概率。 - attention_probs_dropout_prob (
float, optional, defaults to 0.0) — 注意力概率的丢弃比例。 - drop_path_rate (
float, optional, 默认为 0.1) — 随机深度率. - hidden_act (
str或function, 可选, 默认为"gelu") — 编码器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu","relu","selu"和"gelu_new". - use_absolute_embeddings (
bool, optional, defaults toFalse) — 是否将绝对位置嵌入添加到补丁嵌入中。 - initializer_range (
float, 可选, 默认值为 0.02) — 用于初始化所有权重矩阵的 truncated_normal_initializer 的标准差。 - layer_norm_eps (
float, optional, defaults to 1e-05) — 层归一化层使用的epsilon值。 - upscale (
int, optional, defaults to 2) — 图像的放大倍数。2/3/4/8用于图像超分辨率,1用于去噪和压缩伪影减少 - img_range (
float, optional, 默认为 1.0) — 输入图像值的范围。 - resi_connection (
str, optional, defaults to"1conv") — 在每个阶段中,残差连接之前使用的卷积块。 - 上采样器 (
str, 可选, 默认为"pixelshuffle") — 重建模块。可以是‘pixelshuffle’/‘pixelshuffledirect’/‘nearest+conv’/None.
这是用于存储Swin2SRModel配置的配置类。它用于根据指定的参数实例化一个Swin Transformer v2模型,定义模型架构。使用默认值实例化配置将产生类似于Swin Transformer v2 caidas/swin2sr-classicalsr-x2-64架构的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import Swin2SRConfig, Swin2SRModel
>>> # Initializing a Swin2SR caidas/swin2sr-classicalsr-x2-64 style configuration
>>> configuration = Swin2SRConfig()
>>> # Initializing a model (with random weights) from the caidas/swin2sr-classicalsr-x2-64 style configuration
>>> model = Swin2SRModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configSwin2SRModel
类 transformers.Swin2SRModel
< source >( config )
参数
- config (Swin2SRConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的Swin2SR模型转换器输出原始隐藏状态,没有任何特定的头部。 这个模型是一个PyTorch torch.nn.Module 子类。使用 它作为常规的PyTorch模块,并参考PyTorch文档以获取与一般使用和行为相关的所有事项。
前进
< source >( pixel_values: FloatTensor head_mask: typing.Optional[torch.FloatTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.BaseModelOutput 或 tuple(torch.FloatTensor)
参数
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用AutoImageProcessor获取。详情请参见 Swin2SRImageProcessor.call(). - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。
返回
transformers.modeling_outputs.BaseModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(Swin2SRConfig)和输入。
-
last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
Swin2SRModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, Swin2SRModel
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image", trust_remote_code=True)
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("caidas/swin2SR-classical-sr-x2-64")
>>> model = Swin2SRModel.from_pretrained("caidas/swin2SR-classical-sr-x2-64")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 180, 488, 648]Swin2SRForImageSuperResolution
类 transformers.Swin2SRForImageSuperResolution
< source >( config )
参数
- config (Swin2SRConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
Swin2SR 模型转换器,顶部带有上采样器头,用于图像超分辨率和恢复。
该模型是一个PyTorch torch.nn.Module 子类。将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( pixel_values: typing.Optional[torch.FloatTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.ImageSuperResolutionOutput 或 tuple(torch.FloatTensor)
参数
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用AutoImageProcessor获取。详情请参见 Swin2SRImageProcessor.call(). - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。
返回
transformers.modeling_outputs.ImageSuperResolutionOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.ImageSuperResolutionOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(Swin2SRConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,), 可选, 当提供labels时返回) — 重建损失。 -
reconstruction (
torch.FloatTensor形状为(batch_size, num_channels, height, width)) — 重建的图像,可能进行了放大。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每个阶段的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每个阶段输出的隐藏状态 (也称为特征图)。 -
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每个层一个)形状为(batch_size, num_heads, patch_size, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
Swin2SRForImageSuperResolution 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import torch
>>> import numpy as np
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoImageProcessor, Swin2SRForImageSuperResolution
>>> processor = AutoImageProcessor.from_pretrained("caidas/swin2SR-classical-sr-x2-64")
>>> model = Swin2SRForImageSuperResolution.from_pretrained("caidas/swin2SR-classical-sr-x2-64")
>>> url = "https://huggingface.co/spaces/jjourney1125/swin2sr/resolve/main/samples/butterfly.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> # prepare image for the model
>>> inputs = processor(image, return_tensors="pt")
>>> # forward pass
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> output = outputs.reconstruction.data.squeeze().float().cpu().clamp_(0, 1).numpy()
>>> output = np.moveaxis(output, source=0, destination=-1)
>>> output = (output * 255.0).round().astype(np.uint8) # float32 to uint8
>>> # you can visualize `output` with `Image.fromarray`