ViTMatte
概述
ViTMatte模型由Jingfeng Yao、Xinggang Wang、Shusheng Yang和Baoyuan Wang在Boosting Image Matting with Pretrained Plain Vision Transformers中提出。 ViTMatte利用普通的Vision Transformers进行图像抠图任务,即准确估计图像和视频中的前景对象的过程。
论文的摘要如下:
最近,普通的视觉Transformer(ViTs)在各种计算机视觉任务中表现出色,这得益于其强大的建模能力和大规模预训练。然而,它们尚未攻克图像抠图问题。我们假设图像抠图也可以通过ViTs得到提升,并提出了一种新的高效且稳健的基于ViT的抠图系统,名为ViTMatte。我们的方法利用(i)一种混合注意力机制与卷积颈结合,帮助ViTs在抠图任务中实现出色的性能与计算权衡。(ii)此外,我们引入了细节捕捉模块,该模块仅由简单的轻量级卷积组成,以补充抠图所需的详细信息。据我们所知,ViTMatte是第一个通过简洁的适应释放ViT在图像抠图潜力的工作。它继承了ViT在抠图中的许多优越特性,包括各种预训练策略、简洁的架构设计和灵活的推理策略。我们在Composition-1k和Distinctions-646这两个最常用的图像抠图基准上评估了ViTMatte,我们的方法实现了最先进的性能,并大幅超越了之前的抠图工作。
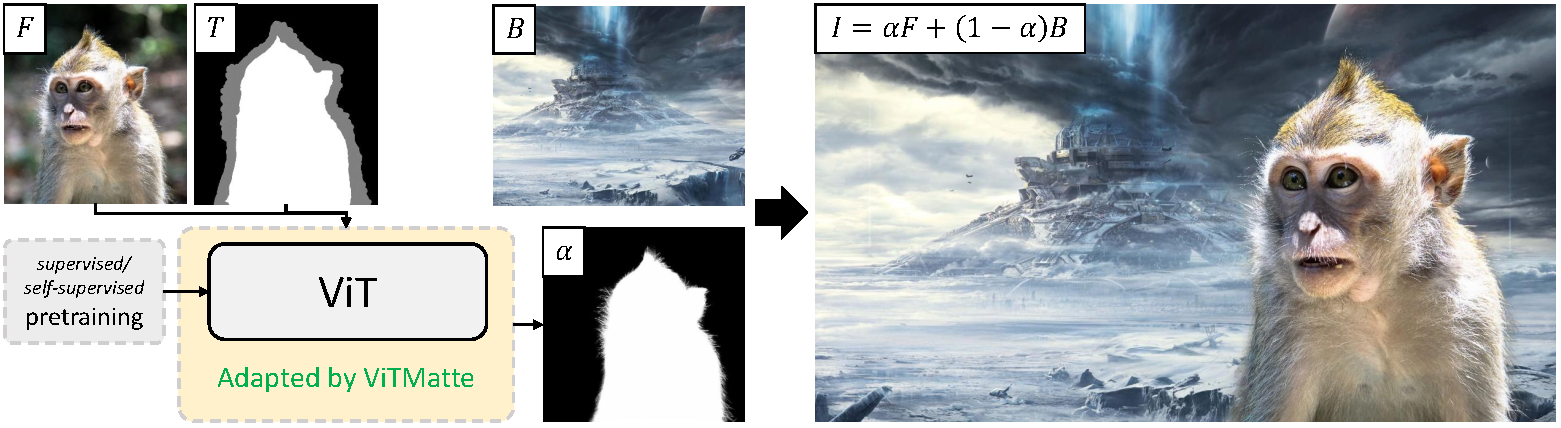 ViTMatte high-level overview. Taken from the original paper.
ViTMatte high-level overview. Taken from the original paper. 资源
以下是官方Hugging Face和社区(由🌎表示)提供的资源列表,帮助您开始使用ViTMatte。
- 关于使用VitMatteForImageMatting进行推理的演示笔记本,包括背景替换,可以在这里找到。
模型期望图像和trimap(连接在一起)作为输入。为此,请使用ViTMatteImageProcessor。
VitMatteConfig
类 transformers.VitMatteConfig
< source >( backbone_config: PretrainedConfig = None backbone = None use_pretrained_backbone = False use_timm_backbone = False backbone_kwargs = None hidden_size: int = 384 batch_norm_eps: float = 1e-05 initializer_range: float = 0.02 convstream_hidden_sizes: typing.List[int] = [48, 96, 192] fusion_hidden_sizes: typing.List[int] = [256, 128, 64, 32] **kwargs )
参数
- backbone_config (
PretrainedConfig或dict, 可选, 默认为VitDetConfig()) — 骨干模型的配置。 - backbone (
str, 可选) — 当backbone_config为None时使用的骨干网络名称。如果use_pretrained_backbone为True,这将从timm或transformers库加载相应的预训练权重。如果use_pretrained_backbone为False,这将加载骨干网络的配置并使用该配置初始化具有随机权重的骨干网络。 - use_pretrained_backbone (
bool, 可选, 默认为False) — 是否使用预训练的权重作为骨干网络。 - use_timm_backbone (
bool, 可选, 默认为False) — 是否从 timm 库加载backbone。如果为False,则从 transformers 库加载 backbone。 - backbone_kwargs (
dict, 可选) — 从检查点加载时传递给AutoBackbone的关键字参数 例如{'out_indices': (0, 1, 2, 3)}。如果设置了backbone_config,则不能指定此参数。 - hidden_size (
int, 可选, 默认为 384) — 解码器的输入通道数。 - batch_norm_eps (
float, optional, defaults to 1e-05) — 批归一化层使用的epsilon值。 - initializer_range (
float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的 truncated_normal_initializer 的标准差。 - convstream_hidden_sizes (
List[int], optional, 默认为[48, 96, 192]) — ConvStream模块的输出通道。 - fusion_hidden_sizes (
List[int], 可选, 默认为[256, 128, 64, 32]) — Fusion块的输出通道。
这是用于存储VitMatteForImageMatting配置的配置类。它用于根据指定的参数实例化ViTMatte模型,定义模型架构。使用默认值实例化配置将产生类似于ViTMatte hustvl/vitmatte-small-composition-1k架构的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import VitMatteConfig, VitMatteForImageMatting
>>> # Initializing a ViTMatte hustvl/vitmatte-small-composition-1k style configuration
>>> configuration = VitMatteConfig()
>>> # Initializing a model (with random weights) from the hustvl/vitmatte-small-composition-1k style configuration
>>> model = VitMatteForImageMatting(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config将此实例序列化为Python字典。覆盖默认的to_dict()。返回:
Dict[str, any]: 构成此配置实例的所有属性的字典,
VitMatteImageProcessor
类 transformers.VitMatteImageProcessor
< source >( do_rescale: bool = True rescale_factor: typing.Union[int, float] = 0.00392156862745098 do_normalize: bool = True image_mean: typing.Union[float, typing.List[float], NoneType] = None image_std: typing.Union[float, typing.List[float], NoneType] = None do_pad: bool = True size_divisibility: int = 32 **kwargs )
参数
- do_rescale (
bool, 可选, 默认为True) — 是否通过指定的比例rescale_factor重新缩放图像。可以在preprocess方法中通过do_rescale参数覆盖此设置。 - rescale_factor (
int或float, 可选, 默认为1/255) — 如果重新缩放图像,则使用的缩放因子。可以在preprocess方法中通过rescale_factor参数覆盖此值。 - do_normalize (
bool, 可选, 默认为True) — 是否对图像进行归一化。可以在preprocess方法中通过do_normalize参数进行覆盖。 - image_mean (
float或List[float], 可选, 默认为IMAGENET_STANDARD_MEAN) — 如果对图像进行归一化,则使用的均值。这是一个浮点数或与图像通道数长度相同的浮点数列表。可以通过preprocess方法中的image_mean参数进行覆盖。 - image_std (
float或List[float], 可选, 默认为IMAGENET_STANDARD_STD) — 如果对图像进行归一化,则使用的标准差。这是一个浮点数或与图像通道数长度相同的浮点数列表。可以通过preprocess方法中的image_std参数进行覆盖。 - do_pad (
bool, 可选, 默认为True) — 是否对图像进行填充以使宽度和高度可被size_divisibility整除。可以在preprocess方法中通过do_pad参数进行覆盖。 - size_divisibility (
int, optional, defaults to 32) — 图像的宽度和高度将被填充以使其可被此数字整除。
构建一个ViTMatte图像处理器。
预处理
< source >( images: typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), typing.List[ForwardRef('PIL.Image.Image')], typing.List[numpy.ndarray], typing.List[ForwardRef('torch.Tensor')]] trimaps: typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), typing.List[ForwardRef('PIL.Image.Image')], typing.List[numpy.ndarray], typing.List[ForwardRef('torch.Tensor')]] do_rescale: typing.Optional[bool] = None rescale_factor: typing.Optional[float] = None do_normalize: typing.Optional[bool] = None image_mean: typing.Union[float, typing.List[float], NoneType] = None image_std: typing.Union[float, typing.List[float], NoneType] = None do_pad: typing.Optional[bool] = None size_divisibility: typing.Optional[int] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None data_format: typing.Union[str, transformers.image_utils.ChannelDimension] =
参数
- 图像 (
ImageInput) — 要预处理的图像。期望输入单个或批量的图像,像素值范围从0到255。如果传入的图像像素值在0到1之间,请设置do_rescale=False. - trimaps (
ImageInput) — 用于预处理的Trimap. - do_rescale (
bool, optional, defaults toself.do_rescale) — 是否将图像值缩放到 [0 - 1] 之间。 - rescale_factor (
float, optional, defaults toself.rescale_factor) — 如果do_rescale设置为True,则用于重新缩放图像的重新缩放因子。 - do_normalize (
bool, optional, defaults toself.do_normalize) — 是否对图像进行归一化处理。 - image_mean (
float或List[float], 可选, 默认为self.image_mean) — 如果do_normalize设置为True,则使用的图像均值。 - image_std (
float或List[float], 可选, 默认为self.image_std) — 如果do_normalize设置为True,则使用的图像标准差。 - do_pad (
bool, 可选, 默认为self.do_pad) — 是否对图像进行填充. - size_divisibility (
int, 可选, 默认为self.size_divisibility) — 如果do_pad设置为True,则将图像填充到的大小可整除性。 - return_tensors (
str或TensorType, 可选) — 返回的张量类型。可以是以下之一:- 未设置:返回一个
np.ndarray列表。 TensorType.TENSORFLOW或'tf':返回一个类型为tf.Tensor的批次。TensorType.PYTORCH或'pt':返回一个类型为torch.Tensor的批次。TensorType.NUMPY或'np':返回一个类型为np.ndarray的批次。TensorType.JAX或'jax':返回一个类型为jax.numpy.ndarray的批次。
- 未设置:返回一个
- data_format (
ChannelDimension或str, 可选, 默认为ChannelDimension.FIRST) — 输出图像的通道维度格式。可以是以下之一:"channels_first"或ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。"channels_last"或ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。- 未设置:使用输入图像的通道维度格式。
- input_data_format (
ChannelDimension或str, 可选) — 输入图像的通道维度格式。如果未设置,则从输入图像推断通道维度格式。可以是以下之一:"channels_first"或ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。"channels_last"或ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。"none"或ChannelDimension.NONE: 图像格式为 (height, width)。
预处理一张图像或一批图像。
VitMatteForImageMatting
class transformers.VitMatteForImageMatting
< source >( config )
参数
- 这个 模型是一个 PyTorch [torch.nn.Module](https —//pytorch.org/docs/stable/nn.html#torch.nn.Module) 子类。使用
- it 作为一个常规的 PyTorch 模块,并参考 PyTorch 文档以获取与一般使用相关的所有事项和 —
- 行为。 — config (UperNetConfig): 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
ViTMatte框架利用任何视觉骨干网络,例如用于ADE20k、CityScapes。
前进
< source >( pixel_values: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None labels: typing.Optional[torch.Tensor] = None return_dict: typing.Optional[bool] = None ) → transformers.models.vitmatte.modeling_vitmatte.ImageMattingOutput 或 tuple(torch.FloatTensor)
参数
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。默认情况下,如果您提供了填充,它将被忽略。可以使用 AutoImageProcessor获取像素值。有关详细信息,请参见VitMatteImageProcessor.call(). - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量,如果主干网络有这些张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量中的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size, height, width), optional) — 用于计算损失的真实图像遮罩。
返回
transformers.models.vitmatte.modeling_vitmatte.ImageMattingOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.vitmatte.modeling_vitmatte.ImageMattingOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(VitMatteConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,), 可选, 当提供labels时返回) — 损失。 -
alphas (
torch.FloatTensor形状为(batch_size, num_channels, height, width)) — 估计的 alpha 值。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每个阶段的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每个阶段输出的隐藏状态 (也称为特征图)。 -
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每个层一个)形状为(batch_size, num_heads, patch_size, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
VitMatteForImageMatting 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import VitMatteImageProcessor, VitMatteForImageMatting
>>> import torch
>>> from PIL import Image
>>> from huggingface_hub import hf_hub_download
>>> processor = VitMatteImageProcessor.from_pretrained("hustvl/vitmatte-small-composition-1k")
>>> model = VitMatteForImageMatting.from_pretrained("hustvl/vitmatte-small-composition-1k")
>>> filepath = hf_hub_download(
... repo_id="hf-internal-testing/image-matting-fixtures", filename="image.png", repo_type="dataset"
... )
>>> image = Image.open(filepath).convert("RGB")
>>> filepath = hf_hub_download(
... repo_id="hf-internal-testing/image-matting-fixtures", filename="trimap.png", repo_type="dataset"
... )
>>> trimap = Image.open(filepath).convert("L")
>>> # prepare image + trimap for the model
>>> inputs = processor(images=image, trimaps=trimap, return_tensors="pt")
>>> with torch.no_grad():
... alphas = model(**inputs).alphas
>>> print(alphas.shape)
torch.Size([1, 1, 640, 960])