表格转换器
概述
Table Transformer模型由Brandon Smock、Rohith Pesala和Robin Abraham在PubTables-1M: Towards comprehensive table extraction from unstructured documents中提出。作者引入了一个新的数据集PubTables-1M,用于基准测试从非结构化文档中提取表格的进展,以及表格结构识别和功能分析。作者训练了2个DETR模型,一个用于表格检测,另一个用于表格结构识别,称为Table Transformers。
论文的摘要如下:
最近,在将机器学习应用于从非结构化文档中进行表格结构推断和提取的问题上取得了显著进展。然而,最大的挑战之一仍然是如何大规模创建具有完整、明确真实标签的数据集。为了解决这个问题,我们开发了一个新的、更全面的表格提取数据集,称为PubTables-1M。PubTables-1M包含来自科学文章的近百万个表格,支持多种输入模式,并包含表格结构的详细标题和位置信息,使其适用于各种建模方法。它还通过一种新颖的规范化程序解决了在先前数据集中观察到的真实标签不一致的一个重要来源,即过度分割。我们证明这些改进显著提高了训练性能,并在评估表格结构识别时提供了更可靠的模型性能估计。此外,我们展示了在PubTables-1M上训练的基于transformer的目标检测模型在检测、结构识别和功能分析这三个任务上均取得了优异的结果,而无需对这些任务进行任何特殊定制。
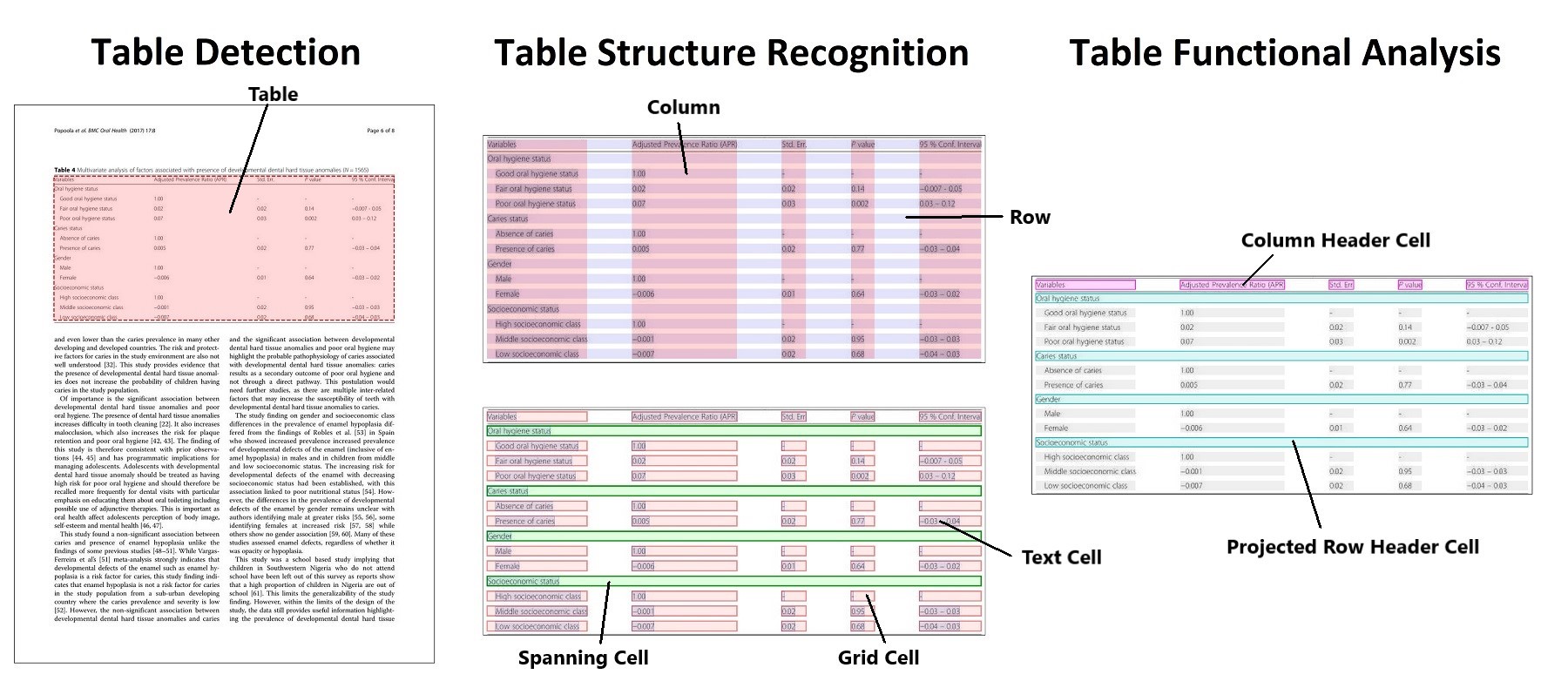 Table detection and table structure recognition clarified. Taken from the original paper.
Table detection and table structure recognition clarified. Taken from the original paper. 作者发布了2个模型,一个用于文档中的表格检测,另一个用于表格结构识别(识别表格中的各个行、列等的任务)。
资源
TableTransformerConfig
类 transformers.TableTransformerConfig
< source >( use_timm_backbone = True backbone_config = None num_channels = 3 num_queries = 100 encoder_layers = 6 encoder_ffn_dim = 2048 encoder_attention_heads = 8 decoder_layers = 6 decoder_ffn_dim = 2048 decoder_attention_heads = 8 encoder_layerdrop = 0.0 decoder_layerdrop = 0.0 is_encoder_decoder = True activation_function = 'relu' d_model = 256 dropout = 0.1 attention_dropout = 0.0 activation_dropout = 0.0 init_std = 0.02 init_xavier_std = 1.0 auxiliary_loss = False position_embedding_type = 'sine' backbone = 'resnet50' use_pretrained_backbone = True backbone_kwargs = None dilation = False class_cost = 1 bbox_cost = 5 giou_cost = 2 mask_loss_coefficient = 1 dice_loss_coefficient = 1 bbox_loss_coefficient = 5 giou_loss_coefficient = 2 eos_coefficient = 0.1 **kwargs )
参数
- use_timm_backbone (
bool, 可选, 默认为True) — 是否使用timm库作为骨干网络。如果设置为False,将使用 AutoBackbone API. - backbone_config (
PretrainedConfig或dict, 可选) — 骨干模型的配置。仅在use_timm_backbone设置为False时使用,此时默认值为ResNetConfig(). - num_channels (
int, optional, defaults to 3) — 输入通道的数量。 - num_queries (
int, 可选, 默认为 100) — 对象查询的数量,即检测槽。这是 TableTransformerModel 在单张图像中可以检测到的最大对象数量。对于 COCO,我们建议使用 100 个查询。 - d_model (
int, optional, defaults to 256) — 层的维度. - encoder_layers (
int, optional, defaults to 6) — 编码器层数. - decoder_layers (
int, optional, defaults to 6) — 解码器层数. - encoder_attention_heads (
int, optional, 默认为 8) — Transformer 编码器中每个注意力层的注意力头数量。 - decoder_attention_heads (
int, optional, defaults to 8) — Transformer解码器中每个注意力层的注意力头数。 - decoder_ffn_dim (
int, optional, defaults to 2048) — 解码器中“中间”(通常称为前馈)层的维度。 - encoder_ffn_dim (
int, optional, defaults to 2048) — 解码器中“中间”(通常称为前馈)层的维度。 - activation_function (
str或function, 可选, 默认为"relu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu","relu","silu"和"gelu_new". - dropout (
float, optional, defaults to 0.1) — 嵌入层、编码器和池化器中所有全连接层的dropout概率。 - attention_dropout (
float, optional, 默认为 0.0) — 注意力概率的丢弃比例。 - activation_dropout (
float, optional, defaults to 0.0) — 全连接层内激活函数的丢弃比例。 - init_std (
float, optional, 默认为 0.02) — 用于初始化所有权重矩阵的 truncated_normal_initializer 的标准差。 - init_xavier_std (
float, optional, defaults to 1) — 用于HM注意力图模块中Xavier初始化增益的缩放因子。 - encoder_layerdrop (
float, optional, defaults to 0.0) — 编码器的LayerDrop概率。有关更多详细信息,请参阅[LayerDrop论文](see https://arxiv.org/abs/1909.11556)。 - decoder_layerdrop (
float, 可选, 默认为 0.0) — 解码器的LayerDrop概率。有关更多详细信息,请参阅[LayerDrop论文](见 https://arxiv.org/abs/1909.11556)。 - auxiliary_loss (
bool, optional, defaults toFalse) — 是否使用辅助解码损失(每个解码器层的损失)。 - position_embedding_type (
str, 可选, 默认为"sine") — 在图像特征之上使用的位置嵌入类型。可选值为"sine"或"learned". - backbone (
str, 可选) — 当backbone_config为None时使用的骨干网络名称。如果use_pretrained_backbone为True,这将从timm或transformers库加载相应的预训练权重。如果use_pretrained_backbone为False,这将加载骨干网络的配置并使用该配置初始化具有随机权重的骨干网络。 - use_pretrained_backbone (
bool, optional,True) — 是否使用预训练的权重作为骨干网络。 - backbone_kwargs (
dict, 可选) — 从检查点加载时传递给AutoBackbone的关键字参数 例如{'out_indices': (0, 1, 2, 3)}。如果设置了backbone_config,则不能指定此参数。 - dilation (
bool, 可选, 默认为False) — 是否在最后一个卷积块(DC5)中用扩张替换步幅。仅在use_timm_backbone=True时支持。 - class_cost (
float, optional, defaults to 1) — 匈牙利匹配成本中分类错误的相对权重。 - bbox_cost (
float, optional, defaults to 5) — 匈牙利匹配成本中边界框坐标的L1误差的相对权重。 - giou_cost (
float, optional, defaults to 2) — 在匈牙利匹配成本中,边界框的广义IoU损失的相对权重。 - mask_loss_coefficient (
float, optional, 默认为 1) — 全景分割损失中 Focal 损失的相对权重。 - dice_loss_coefficient (
float, optional, defaults to 1) — 在全景分割损失中,DICE/F-1损失的相对权重。 - bbox_loss_coefficient (
float, optional, defaults to 5) — 在目标检测损失中,L1边界框损失的相对权重。 - giou_loss_coefficient (
float, optional, defaults to 2) — 在目标检测损失中,广义IoU损失的相对权重。 - eos_coefficient (
float, optional, 默认为 0.1) — 在目标检测损失中,‘无对象’类的相对分类权重。
这是用于存储TableTransformerModel配置的配置类。它用于根据指定的参数实例化一个Table Transformer模型,定义模型架构。使用默认值实例化配置将产生与Table Transformer microsoft/table-transformer-detection架构类似的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import TableTransformerModel, TableTransformerConfig
>>> # Initializing a Table Transformer microsoft/table-transformer-detection style configuration
>>> configuration = TableTransformerConfig()
>>> # Initializing a model from the microsoft/table-transformer-detection style configuration
>>> model = TableTransformerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configTableTransformerModel
类 transformers.TableTransformerModel
< source >( config: TableTransformerConfig )
参数
- config (TableTransformerConfig) — 模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型相关的权重,仅加载配置。查看 from_pretrained() 方法以加载模型权重。
裸表转换器模型(由骨干和编码器-解码器转换器组成)输出原始隐藏状态,顶部没有任何特定的头部。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( pixel_values: FloatTensor pixel_mask: typing.Optional[torch.FloatTensor] = None decoder_attention_mask: typing.Optional[torch.FloatTensor] = None encoder_outputs: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None decoder_inputs_embeds: typing.Optional[torch.FloatTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.models.table_transformer.modeling_table_transformer.TableTransformerModelOutput 或 tuple(torch.FloatTensor)
参数
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Padding will be ignored by default should you provide it.可以使用DetrImageProcessor获取像素值。详情请参见DetrImageProcessor.call()。
- pixel_mask (
torch.FloatTensorof shape(batch_size, height, width), optional) — Mask to avoid performing attention on padding pixel values. Mask values selected in[0, 1]:- 1 for pixels that are real (i.e. not masked),
- 0 for pixels that are padding (i.e. masked).
- decoder_attention_mask (
torch.FloatTensorof shape(batch_size, num_queries), optional) — 默认不使用。可用于屏蔽对象查询。 - encoder_outputs (
tuple(tuple(torch.FloatTensor), 可选) — 元组由 (last_hidden_state, 可选:hidden_states, 可选:attentions)last_hidden_state的形状为(batch_size, sequence_length, hidden_size), 可选) 是编码器最后一层的输出隐藏状态序列。用于解码器的交叉注意力中。 - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递图像的扁平化表示,而不是传递扁平化的特征图(骨干网络 + 投影层的输出)。 - decoder_inputs_embeds (
torch.FloatTensorof shape(batch_size, num_queries, hidden_size), optional) — 可选地,您可以选择直接传递一个嵌入表示,而不是用零张量初始化查询。 - output_attentions (
bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。
返回
transformers.models.table_transformer.modeling_table_transformer.TableTransformerModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.table_transformer.modeling_table_transformer.TableTransformerModelOutput 或一个由 torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含根据配置(TableTransformerConfig)和输入而定的各种元素。
- last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size)) — 模型解码器最后一层输出的隐藏状态序列。 - decoder_hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,一个用于每一层的输出),形状为(batch_size, sequence_length, hidden_size)。解码器在每一层输出后的隐藏状态加上初始嵌入输出。 - decoder_attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器的注意力权重,经过注意力 softmax 后,用于计算自注意力头中的加权平均值。 - cross_attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器的交叉注意力层的注意力权重,经过注意力 softmax 后,用于计算交叉注意力头中的加权平均值。 - encoder_last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size), 可选) — 模型编码器最后一层输出的隐藏状态序列。 - encoder_hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,一个用于每一层的输出),形状为(batch_size, sequence_length, hidden_size)。编码器在每一层输出后的隐藏状态加上初始嵌入输出。 - encoder_attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。编码器的注意力权重,经过注意力 softmax 后,用于计算自注意力头中的加权平均值。 - intermediate_hidden_states (
torch.FloatTensor形状为(config.decoder_layers, batch_size, sequence_length, hidden_size), 可选, 当config.auxiliary_loss=True时返回) — 中间解码器激活,即每一层解码器的输出,每一层都经过了一个层归一化。
TableTransformerModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, TableTransformerModel
>>> from huggingface_hub import hf_hub_download
>>> from PIL import Image
>>> file_path = hf_hub_download(repo_id="nielsr/example-pdf", repo_type="dataset", filename="example_pdf.png")
>>> image = Image.open(file_path).convert("RGB")
>>> image_processor = AutoImageProcessor.from_pretrained("microsoft/table-transformer-detection")
>>> model = TableTransformerModel.from_pretrained("microsoft/table-transformer-detection")
>>> # prepare image for the model
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**inputs)
>>> # the last hidden states are the final query embeddings of the Transformer decoder
>>> # these are of shape (batch_size, num_queries, hidden_size)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 15, 256]TableTransformerForObjectDetection
类 transformers.TableTransformerForObjectDetection
< source >( config: TableTransformerConfig )
参数
- config (TableTransformerConfig) — 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,仅加载配置。查看 from_pretrained() 方法以加载模型权重。
表格转换器模型(由骨干网络和编码器-解码器转换器组成),顶部带有目标检测头,适用于COCO检测等任务。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( pixel_values: FloatTensor pixel_mask: typing.Optional[torch.FloatTensor] = None decoder_attention_mask: typing.Optional[torch.FloatTensor] = None encoder_outputs: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None decoder_inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[typing.List[typing.Dict]] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.models.table_transformer.modeling_table_transformer.TableTransformerObjectDetectionOutput 或 tuple(torch.FloatTensor)
参数
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Padding will be ignored by default should you provide it.可以使用DetrImageProcessor获取像素值。详情请参见DetrImageProcessor.call()。
- pixel_mask (
torch.FloatTensorof shape(batch_size, height, width), optional) — Mask to avoid performing attention on padding pixel values. Mask values selected in[0, 1]:- 1 for pixels that are real (i.e. not masked),
- 0 for pixels that are padding (i.e. masked).
- decoder_attention_mask (
torch.FloatTensorof shape(batch_size, num_queries), optional) — 默认不使用。可用于屏蔽对象查询。 - encoder_outputs (
tuple(tuple(torch.FloatTensor), 可选的) — 元组由 (last_hidden_state, 可选的:hidden_states, 可选的:attentions)last_hidden_state的形状为(batch_size, sequence_length, hidden_size), 可选的) 是 编码器最后一层输出的隐藏状态序列。用于解码器的交叉注意力中。 - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递图像的扁平化表示,而不是传递扁平化的特征图(骨干网络 + 投影层的输出)。 - decoder_inputs_embeds (
torch.FloatTensorof shape(batch_size, num_queries, hidden_size), optional) — 可选地,您可以选择直接传递一个嵌入表示,而不是用零张量初始化查询。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - labels (
List[Dict]长度为(batch_size,), 可选) — 用于计算二分匹配损失的标签。字典列表,每个字典至少包含以下两个键:'class_labels' 和 'boxes'(分别是批次中图像的类别标签和边界框)。类别标签本身应为长度为(图像中边界框的数量,)的torch.LongTensor,而边界框应为形状为(图像中边界框的数量, 4)的torch.FloatTensor。
返回
transformers.models.table_transformer.modeling_table_transformer.TableTransformerObjectDetectionOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.table_transformer.modeling_table_transformer.TableTransformerObjectDetectionOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(TableTransformerConfig)和输入。
- loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 总损失,作为类别预测的负对数似然(交叉熵)和 边界框损失的线性组合。后者定义为 L1 损失和广义 尺度不变 IoU 损失的线性组合。 - loss_dict (
Dict,可选) — 包含各个损失的字典。用于记录日志。 - logits (
torch.FloatTensor形状为(batch_size, num_queries, num_classes + 1)) — 所有查询的分类 logits(包括无对象)。 - pred_boxes (
torch.FloatTensor形状为(batch_size, num_queries, 4)) — 所有查询的归一化框坐标,表示为 (center_x, center_y, width, height)。这些 值在 [0, 1] 范围内归一化,相对于批次中每个单独图像的大小(忽略 可能的填充)。您可以使用~TableTransformerImageProcessor.post_process_object_detection来检索 未归一化的边界框。 - auxiliary_outputs (
list[Dict],可选) — 可选,仅在激活辅助损失时返回(即config.auxiliary_loss设置为True) 并且提供了标签。它是一个字典列表,包含每个解码器层的上述两个键(logits和pred_boxes)。 - last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size),可选) — 模型解码器最后一层输出的隐藏状态序列。 - decoder_hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入输出 + 一个用于每层输出)形状为(batch_size, sequence_length, hidden_size)。解码器在每层输出处的隐藏状态加上初始嵌入输出。 - decoder_attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器的注意力权重,在注意力 softmax 之后,用于计算 自注意力头中的加权平均值。 - cross_attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器交叉注意力层的注意力权重,在注意力 softmax 之后, 用于计算交叉注意力头中的加权平均值。 - encoder_last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size),可选) — 模型编码器最后一层输出的隐藏状态序列。 - encoder_hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入输出 + 一个用于每层输出)形状为(batch_size, sequence_length, hidden_size)。编码器在每层输出处的隐藏状态加上初始嵌入输出。 - encoder_attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。编码器的注意力权重,在注意力 softmax 之后,用于计算 自注意力头中的加权平均值。
TableTransformerForObjectDetection 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from huggingface_hub import hf_hub_download
>>> from transformers import AutoImageProcessor, TableTransformerForObjectDetection
>>> import torch
>>> from PIL import Image
>>> file_path = hf_hub_download(repo_id="nielsr/example-pdf", repo_type="dataset", filename="example_pdf.png")
>>> image = Image.open(file_path).convert("RGB")
>>> image_processor = AutoImageProcessor.from_pretrained("microsoft/table-transformer-detection")
>>> model = TableTransformerForObjectDetection.from_pretrained("microsoft/table-transformer-detection")
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # convert outputs (bounding boxes and class logits) to Pascal VOC format (xmin, ymin, xmax, ymax)
>>> target_sizes = torch.tensor([image.size[::-1]])
>>> results = image_processor.post_process_object_detection(outputs, threshold=0.9, target_sizes=target_sizes)[
... 0
... ]
>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
... box = [round(i, 2) for i in box.tolist()]
... print(
... f"Detected {model.config.id2label[label.item()]} with confidence "
... f"{round(score.item(), 3)} at location {box}"
... )
Detected table with confidence 1.0 at location [202.1, 210.59, 1119.22, 385.09]