深度任何
概述
Depth Anything 模型由 Lihe Yang、Bingyi Kang、Zilong Huang、Xiaogang Xu、Jiashi Feng 和 Hengshuang Zhao 在 Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data 中提出。Depth Anything 基于 DPT 架构,训练了约 6200 万张图像,在相对和绝对深度估计方面取得了最先进的结果。
Depth Anything V2 于2024年6月发布。它使用了与Depth Anything相同的架构,因此与所有代码示例和现有工作流程兼容。然而,它利用合成数据和更大容量的教师模型来实现更精细和稳健的深度预测。
论文的摘要如下:
这项工作介绍了Depth Anything,一个用于鲁棒单目深度估计的高度实用解决方案。我们不追求新颖的技术模块,而是旨在构建一个简单但强大的基础模型,以处理任何情况下的任何图像。为此,我们通过设计一个数据引擎来扩展数据集,以收集和自动注释大规模未标记数据(约62M),这显著扩大了数据覆盖范围,从而能够减少泛化误差。我们研究了两种简单但有效的策略,使数据扩展成为可能。首先,通过利用数据增强工具创建一个更具挑战性的优化目标。它迫使模型主动寻求额外的视觉知识并获得鲁棒的表示。其次,开发了一种辅助监督,以强制模型从预训练的编码器中继承丰富的语义先验。我们广泛评估了其零样本能力,包括六个公共数据集和随机拍摄的照片。它展示了令人印象深刻的泛化能力。此外,通过使用来自NYUv2和KITTI的度量深度信息进行微调,设置了新的SOTA。我们更好的深度模型还导致了更好的深度条件ControlNet。
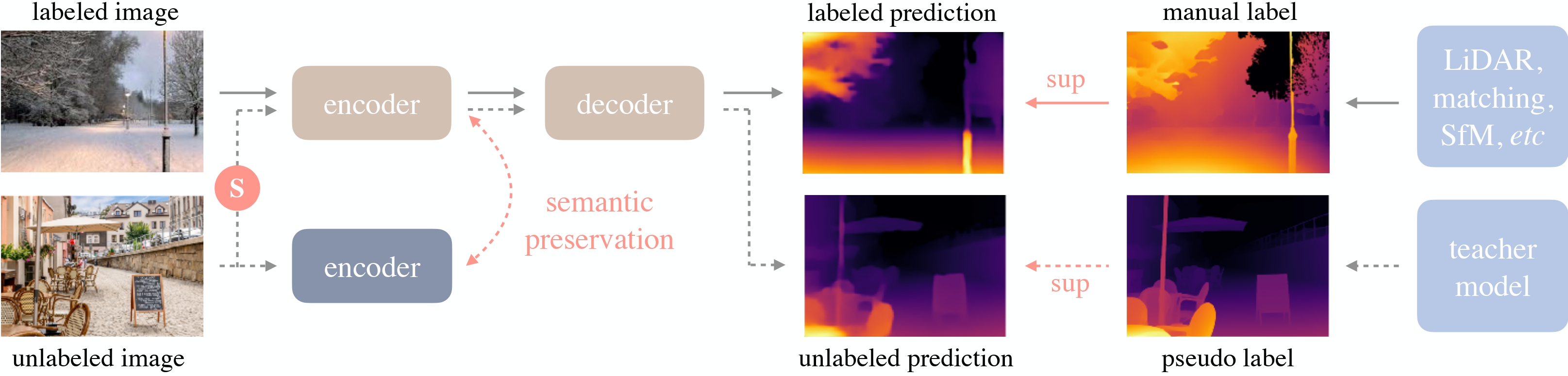 Depth Anything overview. Taken from the original paper.
Depth Anything overview. Taken from the original paper. 使用示例
使用Depth Anything主要有两种方式:一种是使用管道API,它会为你抽象掉所有的复杂性;另一种是自己使用DepthAnythingForDepthEstimation类。
管道 API
管道允许在几行代码中使用模型:
>>> from transformers import pipeline
>>> from PIL import Image
>>> import requests
>>> # load pipe
>>> pipe = pipeline(task="depth-estimation", model="LiheYoung/depth-anything-small-hf")
>>> # load image
>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> # inference
>>> depth = pipe(image)["depth"]自己使用模型
如果你想自己进行预处理和后处理,以下是操作方法:
>>> from transformers import AutoImageProcessor, AutoModelForDepthEstimation
>>> import torch
>>> import numpy as np
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("LiheYoung/depth-anything-small-hf")
>>> model = AutoModelForDepthEstimation.from_pretrained("LiheYoung/depth-anything-small-hf")
>>> # prepare image for the model
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> # interpolate to original size and visualize the prediction
>>> post_processed_output = image_processor.post_process_depth_estimation(
... outputs,
... target_sizes=[(image.height, image.width)],
... )
>>> predicted_depth = post_processed_output[0]["predicted_depth"]
>>> depth = (predicted_depth - predicted_depth.min()) / (predicted_depth.max() - predicted_depth.min())
>>> depth = depth.detach().cpu().numpy() * 255
>>> depth = Image.fromarray(depth.astype("uint8"))资源
一份官方的 Hugging Face 和社区(由🌎表示)资源列表,帮助您开始使用 Depth Anything。
- 单目深度估计任务指南
- 一个展示使用DepthAnythingForDepthEstimation进行推理的笔记本可以在这里找到。🌎
如果您有兴趣提交资源以包含在此处,请随时打开一个 Pull Request,我们将进行审核!理想情况下,资源应展示一些新内容,而不是重复现有资源。
DepthAnythingConfig
类 transformers.DepthAnythingConfig
< source >( backbone_config = 无 backbone = 无 use_pretrained_backbone = 假 use_timm_backbone = 假 backbone_kwargs = 无 patch_size = 14 initializer_range = 0.02 reassemble_hidden_size = 384 reassemble_factors = [4, 2, 1, 0.5] neck_hidden_sizes = [48, 96, 192, 384] fusion_hidden_size = 64 head_in_index = -1 head_hidden_size = 32 depth_estimation_type = 'relative' max_depth = 无 **kwargs )
参数
- backbone_config (
Union[Dict[str, Any], PretrainedConfig], 可选) — 骨干模型的配置。仅在is_hybrid为True或您希望利用 AutoBackbone API 时使用。 - backbone (
str, 可选) — 当backbone_config为None时使用的骨干网络名称。如果use_pretrained_backbone为True,这将从timm或transformers库加载相应的预训练权重。如果use_pretrained_backbone为False,这将加载骨干网络的配置并使用该配置初始化具有随机权重的骨干网络。 - use_pretrained_backbone (
bool, 可选, 默认为False) — 是否使用预训练的权重作为骨干网络。 - use_timm_backbone (
bool, 可选, 默认为False) — 是否使用timm库作为骨干网络。如果设置为False,将使用 AutoBackbone API. - backbone_kwargs (
dict, 可选) — 从检查点加载时传递给AutoBackbone的关键字参数 例如{'out_indices': (0, 1, 2, 3)}。如果设置了backbone_config,则不能指定此参数。 - patch_size (
int, 可选, 默认为 14) — 从骨干特征中提取的补丁的大小。 - initializer_range (
float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 - reassemble_hidden_size (
int, 可选, 默认为 384) — 重组层的输入通道数。 - reassemble_factors (
List[int], 可选, 默认为[4, 2, 1, 0.5]) — 重新组装层的上/下采样因子。 - neck_hidden_sizes (
List[str], optional, 默认为[48, 96, 192, 384]) — 用于投影到骨干网络特征图的隐藏大小。 - fusion_hidden_size (
int, optional, defaults to 64) — 融合前的通道数。 - head_in_index (
int, optional, 默认为 -1) — 用于深度估计头的特征索引。 - head_hidden_size (
int, 可选, 默认为 32) — 深度估计头中第二个卷积的输出通道数。 - depth_estimation_type (
str, 可选, 默认为"relative") — 使用的深度估计类型。可以是["relative", "metric"]中的一个。 - max_depth (
float, optional) — 用于“metric”深度估计头的最大深度。室内模型应使用20,室外模型应使用80。对于“relative”深度估计,此值将被忽略。
这是用于存储DepthAnythingModel配置的配置类。它用于根据指定的参数实例化DepthAnything模型,定义模型架构。使用默认值实例化配置将产生与DepthAnything LiheYoung/depth-anything-small-hf 架构类似的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import DepthAnythingConfig, DepthAnythingForDepthEstimation
>>> # Initializing a DepthAnything small style configuration
>>> configuration = DepthAnythingConfig()
>>> # Initializing a model from the DepthAnything small style configuration
>>> model = DepthAnythingForDepthEstimation(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config将此实例序列化为Python字典。覆盖默认的to_dict()。返回:
Dict[str, any]: 构成此配置实例的所有属性的字典,
深度估计的DepthAnything
类 transformers.DepthAnythingForDepthEstimation
< source >( config )
参数
- config (DepthAnythingConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
Depth Anything 模型,顶部带有深度估计头(由3个卷积层组成),例如用于KITTI、NYUv2。
该模型是一个PyTorch torch.nn.Module 子类。将其用作常规的PyTorch模块,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( pixel_values: FloatTensor labels: typing.Optional[torch.LongTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.DepthEstimatorOutput 或 tuple(torch.FloatTensor)
参数
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用AutoImageProcessor获取。详情请参见DPTImageProcessor.call()。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size, height, width), optional) — 用于计算损失的真实深度估计图。
返回
transformers.modeling_outputs.DepthEstimatorOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.DepthEstimatorOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(DepthAnythingConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,), 可选, 当提供labels时返回) — 分类(或回归,如果 config.num_labels==1)损失。 -
predicted_depth (
torch.FloatTensor形状为(batch_size, height, width)) — 每个像素的预测深度。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, num_channels, height, width)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, patch_size, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
DepthAnythingForDepthEstimation 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, AutoModelForDepthEstimation
>>> import torch
>>> import numpy as np
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("LiheYoung/depth-anything-small-hf")
>>> model = AutoModelForDepthEstimation.from_pretrained("LiheYoung/depth-anything-small-hf")
>>> # prepare image for the model
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> # interpolate to original size
>>> post_processed_output = image_processor.post_process_depth_estimation(
... outputs,
... target_sizes=[(image.height, image.width)],
... )
>>> # visualize the prediction
>>> predicted_depth = post_processed_output[0]["predicted_depth"]
>>> depth = predicted_depth * 255 / predicted_depth.max()
>>> depth = depth.detach().cpu().numpy()
>>> depth = Image.fromarray(depth.astype("uint8"))