GPU推理
GPU是机器学习的标准硬件选择,与CPU不同,因为它们针对内存带宽和并行性进行了优化。为了跟上现代模型的更大规模或在现有和较旧的硬件上运行这些大型模型,您可以使用几种优化来加速GPU推理。在本指南中,您将学习如何使用FlashAttention-2(一种更高效的内存注意力机制)、BetterTransformer(PyTorch原生快速路径执行)以及bitsandbytes将模型量化为较低精度。最后,学习如何使用🤗 Optimum在Nvidia和AMD GPU上通过ONNX Runtime加速推理。
这里描述的大多数优化也适用于多GPU设置!
FlashAttention-2
FlashAttention-2 是实验性的,在未来的版本中可能会有很大的变化。
FlashAttention-2 是标准注意力机制的一种更快、更高效的实现,可以通过以下方式显著加速推理:
- 另外,在序列长度上并行化注意力计算
- 在GPU线程之间分配工作,以减少它们之间的通信和共享内存的读取/写入
FlashAttention-2 目前支持以下架构:
- Bark
- Bart
- Chameleon
- CLIP
- Cohere
- GLM
- Dbrx
- DistilBert
- Gemma
- Gemma2
- GPT2
- GPTBigCode
- GPTNeo
- GPTNeoX
- GPT-J
- Granite
- GraniteMoe
- Idefics2
- Idefics3
- Falcon
- JetMoe
- Jamba
- Llama
- Llava
- Llava-NeXT
- Llava-NeXT-Video
- LLaVA-Onevision
- Mimi
- VipLlava
- VideoLlava
- M2M100
- MBart
- Mistral
- Mixtral
- Moshi
- Musicgen
- MusicGen Melody
- Nemotron
- NLLB
- OLMo
- OLMo2
- OLMoE
- OPT
- PaliGemma
- Phi
- Phi3
- PhiMoE
- StableLm
- Starcoder2
- Qwen2
- Qwen2Audio
- Qwen2MoE
- Qwen2VL
- RAG
- SpeechEncoderDecoder
- VisionEncoderDecoder
- VisionTextDualEncoder
- Whisper
- Wav2Vec2
- Hubert
- data2vec_audio
- Sew
- SigLIP
- UniSpeech
- unispeech_sat
你可以通过打开一个GitHub Issue或Pull Request来请求为另一个模型添加FlashAttention-2支持。
在开始之前,请确保你已经安装了FlashAttention-2。
pip install flash-attn --no-build-isolation
我们强烈建议参考详细的安装说明,以了解更多关于支持的硬件和数据类型的信息!
要启用 FlashAttention-2,请将参数 attn_implementation="flash_attention_2" 传递给 from_pretrained():
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)FlashAttention-2 只能在模型的 dtype 为 fp16 或 bf16 时使用。在使用 FlashAttention-2 之前,请确保将模型转换为适当的 dtype 并将其加载到支持的设备上。
你也可以设置use_flash_attention_2=True来启用FlashAttention-2,但它已被弃用,推荐使用attn_implementation="flash_attention_2"。
FlashAttention-2 可以与其他优化技术(如量化)结合使用,以进一步加速推理。例如,您可以将 FlashAttention-2 与 8 位或 4 位量化结合使用:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
# load in 8bit
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_8bit=True,
attn_implementation="flash_attention_2",
)
# load in 4bit
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
attn_implementation="flash_attention_2",
)预期的加速
你可以从推理中获得显著的加速,特别是对于长序列的输入。然而,由于FlashAttention-2不支持使用填充标记计算注意力分数,当序列包含填充标记时,你必须手动填充/取消填充注意力分数以进行批量推理。这会导致带有填充标记的批量生成显著减慢。
为了解决这个问题,你应该在训练期间使用没有填充标记的FlashAttention-2(通过打包数据集或连接序列直到达到最大序列长度)。
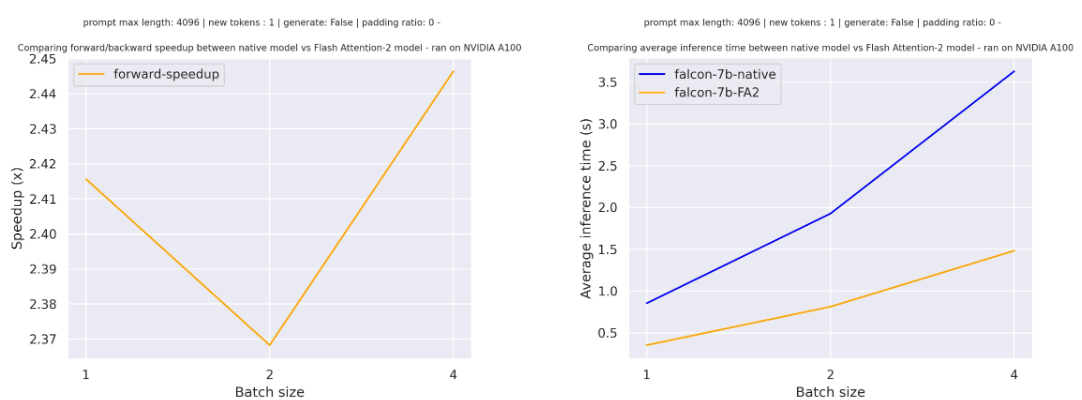
对于在tiiuae/falcon-7b上进行的一次前向传递,序列长度为4096且没有填充标记的各种批量大小,预期的加速是:
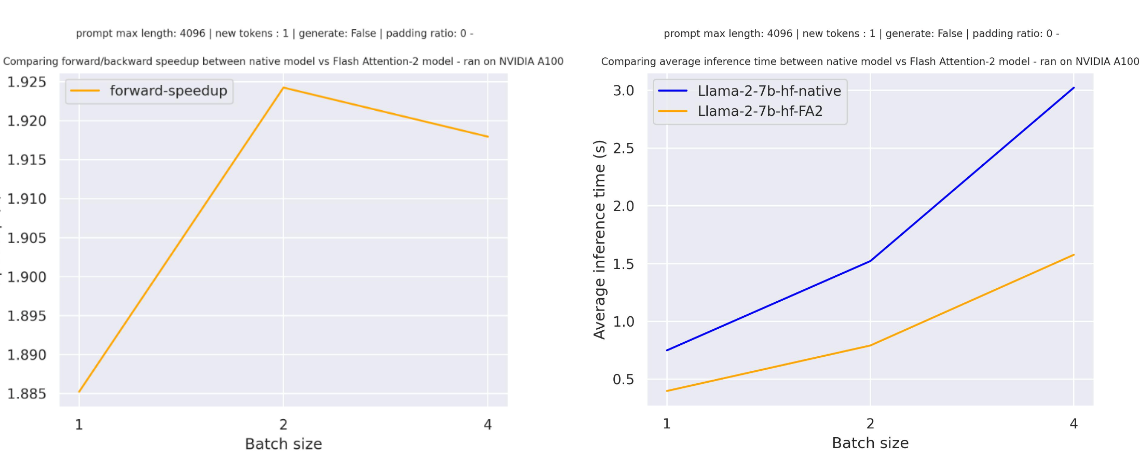
对于在meta-llama/Llama-7b-hf上进行一次前向传递,序列长度为4096且没有填充标记的各种批量大小,预期的加速是:
对于带有填充标记的序列(使用填充标记生成),您需要对输入序列进行去填充/填充以正确计算注意力分数。在序列长度相对较小的情况下,单次前向传递会产生开销,导致速度提升较小(在下面的示例中,30%的输入被填充标记填充):
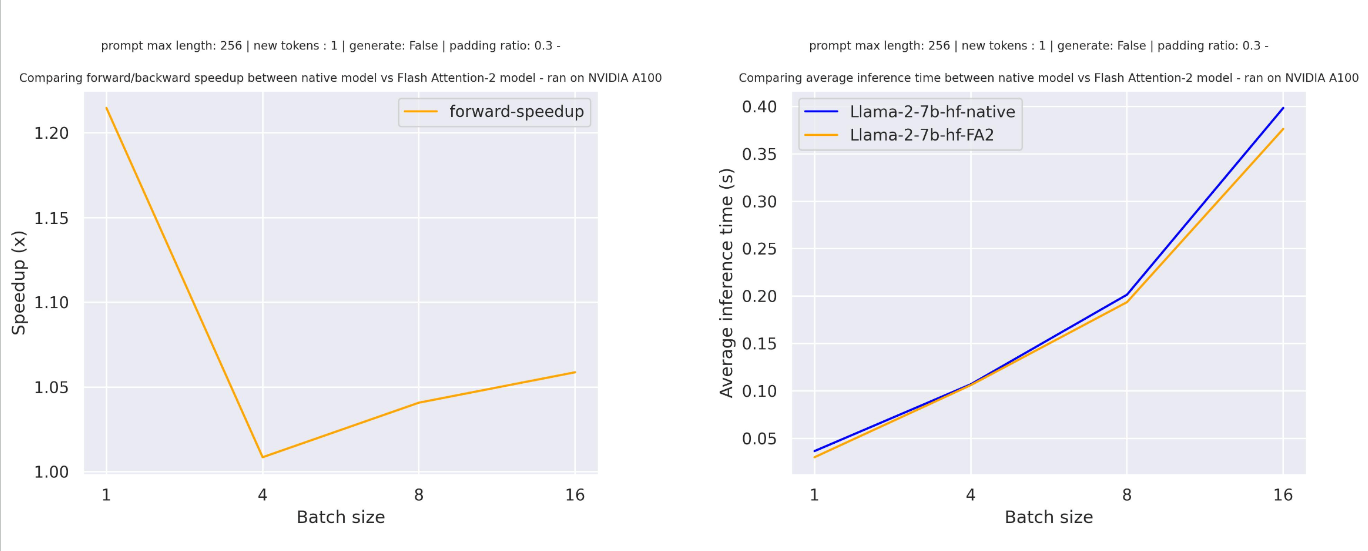
但对于更长的序列长度,你可以期待更多的加速优势:
FlashAttention 更加节省内存,这意味着你可以在更大的序列长度上进行训练,而不会遇到内存不足的问题。对于较大的序列长度,你有可能将内存使用量减少多达20倍。查看 flash-attention 仓库以获取更多详细信息。

PyTorch 缩放点积注意力
PyTorch 的 torch.nn.functional.scaled_dot_product_attention (SDPA) 也可以在底层调用 FlashAttention 和内存高效的注意力内核。目前,Transformers 正在原生添加 SDPA 支持,并且在 torch>=2.1.1 时默认使用,当有可用实现时。你也可以在 from_pretrained() 中设置 attn_implementation="sdpa" 来明确请求使用 SDPA。
目前,Transformers 支持以下架构的 SDPA 推理和训练:
- Albert
- Audio Spectrogram Transformer
- Bart
- Bert
- BioGpt
- CamemBERT
- Chameleon
- CLIP
- GLM
- Cohere
- data2vec_audio
- Dbrx
- DeiT
- Dinov2
- DistilBert
- Dpr
- EncoderDecoder
- Falcon
- Gemma
- Gemma2
- Granite
- GPT2
- GPTBigCode
- GPTNeoX
- Hubert
- Idefics
- Idefics2
- Idefics3
- I-JEPA
- GraniteMoe
- JetMoe
- Jamba
- Llama
- Llava
- Llava-NeXT
- Llava-NeXT-Video
- LLaVA-Onevision
- M2M100
- Mimi
- Mistral
- Mllama
- Mixtral
- Moshi
- Musicgen
- MusicGen Melody
- NLLB
- OLMo
- OLMo2
- OLMoE
- OPT
- PaliGemma
- Phi
- Phi3
- PhiMoE
- Idefics
- Whisper
- mBart
- Mistral
- Mixtral
- StableLm
- Starcoder2
- Qwen2
- Qwen2Audio
- Qwen2MoE
- RoBERTa
- Sew
- SigLIP
- StableLm
- Starcoder2
- UniSpeech
- unispeech_sat
- RoBERTa
- Qwen2VL
- Musicgen
- MusicGen Melody
- Nemotron
- SpeechEncoderDecoder
- VideoLlava
- VipLlava
- VisionEncoderDecoder
- ViT
- ViTHybrid
- ViTMAE
- ViTMSN
- VisionTextDualEncoder
- VideoMAE
- ViViT
- wav2vec2
- Whisper
- XLM-RoBERTa
- XLM-RoBERTa-XL
- YOLOS
FlashAttention 只能用于具有 fp16 或 bf16 torch 类型的模型,因此请确保先将模型转换为适当的类型。内存高效的注意力后端能够处理 fp32 模型。
SDPA 不支持某些注意力参数集,例如 head_mask 和 output_attentions=True。
在这种情况下,您应该会看到一条警告消息,并且我们将回退到(较慢的)eager 实现。
默认情况下,SDPA会选择性能最佳的内核,但你可以使用torch.backends.cuda.sdp_kernel作为上下文管理器来检查在特定设置(硬件、问题大小)下是否有可用的后端:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16).to("cuda")
input_text = "Hello my dog is cute and"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
+ with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))如果您看到以下回溯中的错误,请尝试使用PyTorch的夜间版本,该版本可能对FlashAttention有更广泛的支持:
RuntimeError: No available kernel. Aborting execution.
# install PyTorch nightly
pip3 install -U --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu118BetterTransformer
一些BetterTransformer功能正在被上游化到Transformers中,默认支持原生的torch.nn.scaled_dot_product_attention。BetterTransformer仍然比Transformers的SDPA集成有更广泛的覆盖范围,但你可以期待越来越多的架构在Transformers中原生支持SDPA。
查看我们在PyTorch 2.0 中 🤗 解码器模型的开箱即用加速和内存节省中使用 BetterTransformer 和缩放点积注意力的基准测试,并在BetterTransformer博客文章中了解更多关于快速路径执行的信息。
BetterTransformer通过其快速路径(PyTorch原生专门实现的Transformer函数)加速推理。快速路径执行中的两个优化是:
- 融合,将多个顺序操作组合成一个单一的“内核”,以减少计算步骤的数量
- 跳过填充标记的固有稀疏性,以避免使用嵌套张量进行不必要的计算
BetterTransformer 还将所有注意力操作转换为使用更节省内存的 scaled dot product attention (SDPA),并且在底层调用了像 FlashAttention 这样的优化内核。
在开始之前,请确保你已经安装了🤗 Optimum。
然后你可以使用 PreTrainedModel.to_bettertransformer() 方法来启用 BetterTransformer:
model = model.to_bettertransformer()
你可以使用reverse_bettertransformer()方法返回原始的Transformers模型。在保存模型以使用规范的Transformers建模之前,你应该使用这个方法:
model = model.reverse_bettertransformer()
model.save_pretrained("saved_model")bitsandbytes
bitsandbytes 是一个量化库,支持4位和8位量化。量化可以减少模型的大小,相比于其原生全精度版本,使得在内存有限的GPU上更容易部署大型模型。
确保你已经安装了bitsandbytes和🤗 Accelerate:
# these versions support 8-bit and 4-bit
pip install bitsandbytes>=0.39.0 accelerate>=0.20.0
# install Transformers
pip install transformers4位
要加载一个4位模型进行推理,请使用load_in_4bit参数。device_map参数是可选的,但我们建议将其设置为"auto",以便🤗 Accelerate能够根据环境中的可用资源自动且高效地分配模型。
from transformers import AutoModelForCausalLM
model_name = "bigscience/bloom-2b5"
model_4bit = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto", load_in_4bit=True)要在多GPU上进行4位推理加载模型,您可以控制每个GPU分配多少显存。例如,将600MB内存分配给第一个GPU,1GB内存分配给第二个GPU:
max_memory_mapping = {0: "600MB", 1: "1GB"}
model_name = "bigscience/bloom-3b"
model_4bit = AutoModelForCausalLM.from_pretrained(
model_name, torch_dtype="auto", device_map="auto", load_in_4bit=True, max_memory=max_memory_mapping
)8位
如果你对8位量化的概念感到好奇并想了解更多,请阅读使用Hugging Face Transformers、Accelerate和bitsandbytes进行大规模8位矩阵乘法的温和介绍博客文章。
要加载一个8位模型进行推理,请使用load_in_8bit参数。device_map参数是可选的,但我们建议将其设置为"auto",以便🤗 Accelerate能够根据环境中的可用资源自动且高效地分配模型:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
model_name = "bigscience/bloom-2b5"
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", quantization_config=BitsAndBytesConfig(load_in_8bit=True))如果你正在加载一个8位模型用于文本生成,你应该使用generate()方法,而不是Pipeline函数,因为后者没有针对8位模型进行优化,速度会更慢。一些采样策略,如核采样,也不被Pipeline支持用于8位模型。你还应该将所有输入放在与模型相同的设备上:
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_name = "bigscience/bloom-2b5"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", quantization_config=BitsAndBytesConfig(load_in_8bit=True))
prompt = "Hello, my llama is cute"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
generated_ids = model.generate(**inputs)
outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)要在多GPU上进行4位推理加载模型,您可以控制每个GPU分配多少显存。例如,将1GB内存分配给第一个GPU,将2GB内存分配给第二个GPU:
max_memory_mapping = {0: "1GB", 1: "2GB"}
model_name = "bigscience/bloom-3b"
model_8bit = AutoModelForCausalLM.from_pretrained(
model_name, torch_dtype="auto", device_map="auto", load_in_8bit=True, max_memory=max_memory_mapping
)🤗 最佳
了解更多关于在🤗 Optimum中使用ORT的详细信息,请参阅在NVIDIA GPU上的加速推理和在AMD GPU上的加速推理指南。本节仅提供一个简要的示例。
ONNX Runtime (ORT) 是一个模型加速器,支持在Nvidia GPU和使用ROCm堆栈的AMD GPU上进行加速推理。ORT使用优化技术,如将常见操作融合到单个节点和常量折叠,以减少执行的计算次数并加速推理。ORT还将计算最密集的操作放在GPU上,其余操作放在CPU上,以智能地在两个设备之间分配工作负载。
ORT 由 🤗 Optimum 支持,可以在 🤗 Transformers 中使用。你需要为你要解决的任务使用一个 ORTModel,并指定 provider 参数,该参数可以设置为 CUDAExecutionProvider、ROCMExecutionProvider 或 TensorrtExecutionProvider。如果你想加载一个尚未导出为 ONNX 的模型,你可以设置 export=True 来将你的模型即时转换为 ONNX 格式:
from optimum.onnxruntime import ORTModelForSequenceClassification
ort_model = ORTModelForSequenceClassification.from_pretrained(
"distilbert/distilbert-base-uncased-finetuned-sst-2-english",
export=True,
provider="CUDAExecutionProvider",
)现在你可以自由地使用模型进行推理:
from optimum.pipelines import pipeline
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased-finetuned-sst-2-english")
pipeline = pipeline(task="text-classification", model=ort_model, tokenizer=tokenizer, device="cuda:0")
result = pipeline("Both the music and visual were astounding, not to mention the actors performance.")组合优化
通常可以将上述几种优化技术结合起来,以获得模型的最佳推理性能。例如,您可以以4位加载模型,然后启用带有FlashAttention的BetterTransformer:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
# load model in 4-bit
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype="auto", quantization_config=quantization_config)
# enable BetterTransformer
model = model.to_bettertransformer()
input_text = "Hello my dog is cute and"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
# enable FlashAttention
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))