ImageGPT
概述
ImageGPT模型由Mark Chen、Alec Radford、Rewon Child、Jeffrey Wu、Heewoo Jun、David Luan和Ilya Sutskever在Generative Pretraining from Pixels中提出。ImageGPT(iGPT)是一个类似于GPT-2的模型,训练用于预测下一个像素值,允许进行无条件或有条件的图像生成。
论文的摘要如下:
受到自然语言无监督表示学习进展的启发,我们研究了类似的模型是否能够学习到有用的图像表示。我们训练了一个序列Transformer来自回归预测像素,而不引入2D输入结构的知识。尽管在没有标签的低分辨率ImageNet上进行训练,我们发现一个GPT-2规模的模型通过线性探测、微调和低数据分类学习到了强大的图像表示。在CIFAR-10上,我们通过线性探测达到了96.3%的准确率,超过了有监督的Wide ResNet,并且在完全微调的情况下达到了99.0%的准确率,与顶级的有监督预训练模型相匹配。当用VQVAE编码替换像素时,我们在ImageNet上的自监督基准测试中也具有竞争力,通过线性探测我们的特征达到了69.0%的top-1准确率。
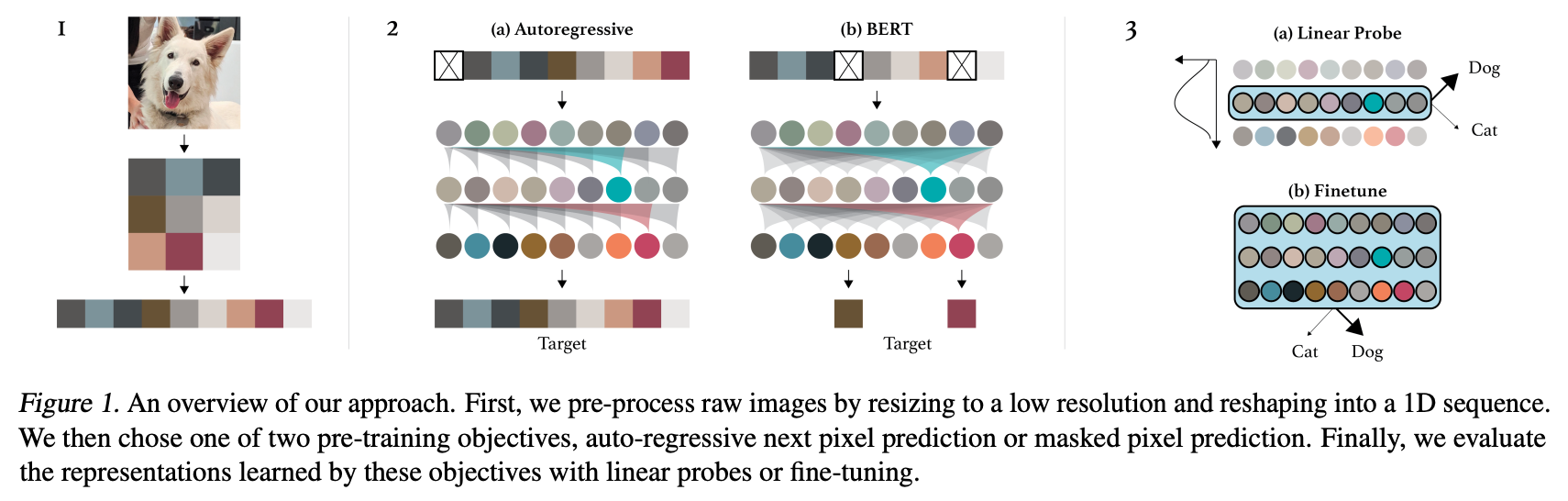 Summary of the approach. Taken from the [original paper](https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf).
Summary of the approach. Taken from the [original paper](https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf). 该模型由nielsr贡献,基于此问题。原始代码可以在这里找到。
使用提示
- ImageGPT 几乎与 GPT-2 完全相同,唯一的区别是使用了不同的激活函数(即“quick gelu”),并且层归一化层不会对输入进行均值中心化。ImageGPT 也没有绑定输入和输出的嵌入。
- 由于Transformer的注意力机制在序列长度上的时间和内存需求呈二次方增长,作者在较小的输入分辨率(如32x32和64x64)上预训练了ImageGPT。然而,将32x32x3=3072个0..255的标记序列输入Transformer仍然过大。因此,作者对(R,G,B)像素值应用了k=512的k-means聚类。这样,我们只有一个32*32=1024长的序列,但现在整数范围是0..511。因此,我们以更大的嵌入矩阵为代价缩短了序列长度。换句话说,ImageGPT的词汇大小为512,加上一个特殊的“句子开始”(SOS)标记,用于每个序列的开头。可以使用ImageGPTImageProcessor来为模型准备图像。
- 尽管是完全无监督预训练的(即不使用任何标签),ImageGPT 生成的图像特征在下游任务(如图像分类)中表现相当出色。作者表明,网络中间的特征表现最佳,可以直接用于训练线性模型(例如 sklearn 逻辑回归模型)。这也被称为“线性探测”。特征可以通过首先将图像通过模型前向传播,然后指定
output_hidden_states=True,然后在任意层对隐藏状态进行平均池化来轻松获得。 - 或者,可以像BERT一样在下游数据集上进一步微调整个模型。为此,您可以使用ImageGPTForImageClassification。
- ImageGPT 有不同的大小:有 ImageGPT-small、ImageGPT-medium 和 ImageGPT-large。作者还训练了一个 XL 变体,但他们没有发布。大小的差异总结在下表中:
| 模型变体 | 深度 | 隐藏层大小 | 解码器隐藏层大小 | 参数 (百万) | ImageNet-1k Top 1 |
|---|---|---|---|---|---|
| MiT-b0 | [2, 2, 2, 2] | [32, 64, 160, 256] | 256 | 3.7 | 70.5 |
| MiT-b1 | [2, 2, 2, 2] | [64, 128, 320, 512] | 256 | 14.0 | 78.7 |
| MiT-b2 | [3, 4, 6, 3] | [64, 128, 320, 512] | 768 | 25.4 | 81.6 |
| MiT-b3 | [3, 4, 18, 3] | [64, 128, 320, 512] | 768 | 45.2 | 83.1 |
| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
资源
一份官方的Hugging Face和社区(由🌎表示)资源列表,帮助您开始使用ImageGPT。
- ImageGPT 的演示笔记本可以在这里找到。
- ImageGPTForImageClassification 由这个 示例脚本 和 笔记本 支持。
- 另请参阅:图像分类任务指南
如果您有兴趣提交资源以包含在此处,请随时打开一个 Pull Request,我们将进行审核!理想情况下,资源应展示一些新内容,而不是重复现有资源。
ImageGPTConfig
类 transformers.ImageGPTConfig
< source >( 词汇大小 = 513 位置数量 = 1024 嵌入维度 = 512 层数 = 24 头数 = 8 内部维度 = 无 激活函数 = 'quick_gelu' 残差丢弃率 = 0.1 嵌入丢弃率 = 0.1 注意力丢弃率 = 0.1 层归一化epsilon = 1e-05 初始化范围 = 0.02 缩放注意力权重 = 真 使用缓存 = 真 绑定词嵌入 = 假 按逆层索引缩放注意力 = 假 重新排序和上转换注意力 = 假 **kwargs )
参数
- vocab_size (
int, 可选, 默认为 512) — GPT-2 模型的词汇量大小。定义了调用 ImageGPTModel 或TFImageGPTModel时传递的inputs_ids可以表示的不同标记的数量。 - n_positions (
int, 可选, 默认为 32*32) — 此模型可能使用的最大序列长度。通常将其设置为较大的值以防万一(例如,512 或 1024 或 2048)。 - n_embd (
int, optional, 默认为 512) — 嵌入和隐藏状态的维度。 - n_layer (
int, optional, 默认为 24) — Transformer 编码器中的隐藏层数。 - n_head (
int, optional, 默认为 8) — Transformer 编码器中每个注意力层的注意力头数。 - n_inner (
int, 可选, 默认为 None) — 内部前馈层的维度。None会将其设置为 n_embd 的 4 倍 - activation_function (
str, optional, defaults to"quick_gelu") — 激活函数(可以是src/transformers/activations.py中定义的激活函数之一)。 默认为“quick_gelu”。 - resid_pdrop (
float, optional, 默认为 0.1) — 嵌入层、编码器和池化器中所有全连接层的丢弃概率。 - embd_pdrop (
int, optional, 默认为 0.1) — 嵌入的丢弃比例。 - attn_pdrop (
float, optional, defaults to 0.1) — 注意力的dropout比例. - layer_norm_epsilon (
float, optional, defaults to 1e-5) — 用于层归一化层的epsilon值。 - initializer_range (
float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 - scale_attn_weights (
bool, optional, defaults toTrue) — 通过除以sqrt(hidden_size)来缩放注意力权重。 - use_cache (
bool, 可选, 默认为True) — 模型是否应返回最后的键/值注意力(并非所有模型都使用)。 - scale_attn_by_inverse_layer_idx (
bool, 可选, 默认为False) — 是否通过1 / layer_idx + 1额外缩放注意力权重. - reorder_and_upcast_attn (
bool, optional, defaults toFalse) — 是否在计算注意力(点积)之前缩放键(K),并在使用混合精度训练时将注意力点积/softmax上转换为float()。
这是用于存储ImageGPTModel或TFImageGPTModel配置的配置类。它用于根据指定的参数实例化GPT-2模型,定义模型架构。使用默认值实例化配置将产生类似于ImageGPT openai/imagegpt-small架构的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import ImageGPTConfig, ImageGPTModel
>>> # Initializing a ImageGPT configuration
>>> configuration = ImageGPTConfig()
>>> # Initializing a model (with random weights) from the configuration
>>> model = ImageGPTModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configImageGPTFeatureExtractor
预处理一张图像或一批图像。
ImageGPTImageProcessor
class transformers.ImageGPTImageProcessor
< source >( clusters: typing.Union[typing.List[typing.List[int]], numpy.ndarray, NoneType] = None do_resize: bool = True size: typing.Dict[str, int] = None resample: Resampling =
参数
- clusters (
np.ndarray或List[List[int]], 可选) — 用于颜色量化的颜色簇,形状为(n_clusters, 3)。可以在preprocess中被clusters覆盖。 - do_resize (
bool, 可选, 默认为True) — 是否将图像的尺寸调整为(size["height"], size["width"])。可以在preprocess中通过do_resize覆盖此设置。 - size (
Dict[str, int]optional, defaults to{"height" -- 256, "width": 256}): 调整大小后的图像尺寸。可以在preprocess中被size覆盖。 - resample (
PILImageResampling, 可选, 默认为Resampling.BILINEAR) — 如果调整图像大小,使用的重采样过滤器。可以在preprocess中通过resample覆盖。 - do_normalize (
bool, 可选, 默认为True) — 是否将图像像素值归一化到 [-1, 1] 之间。可以在preprocess中被do_normalize覆盖。 - do_color_quantize (
bool, 可选, 默认为True) — 是否对图像进行颜色量化。可以在preprocess中被do_color_quantize覆盖。
构建一个ImageGPT图像处理器。此图像处理器可用于将图像调整为较小的分辨率(例如32x32或64x64),对其进行归一化处理,最后进行颜色量化以获得“像素值”序列(颜色簇)。
预处理
< source >( images: typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), typing.List[ForwardRef('PIL.Image.Image')], typing.List[numpy.ndarray], typing.List[ForwardRef('torch.Tensor')]] do_resize: bool = None size: typing.Dict[str, int] = None resample: Resampling = None do_normalize: bool = None do_color_quantize: typing.Optional[bool] = None clusters: typing.Union[typing.List[typing.List[int]], numpy.ndarray, NoneType] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None data_format: typing.Union[str, transformers.image_utils.ChannelDimension, NoneType] =
参数
- 图像 (
ImageInput) — 要预处理的图像。期望输入单个或批量的图像,像素值范围在0到255之间。如果传入的图像像素值在0到1之间,请设置do_normalize=False. - do_resize (
bool, optional, defaults toself.do_resize) — 是否调整图像大小. - size (
Dict[str, int], optional, defaults toself.size) — 调整大小后的图像尺寸。 - resample (
int, 可选, 默认为self.resample) — 如果调整图像大小,则使用的重采样过滤器。这可以是枚举PILImageResampling之一,仅在do_resize设置为True时有效。 - do_normalize (
bool, 可选, 默认为self.do_normalize) — 是否对图像进行归一化 - do_color_quantize (
bool, optional, defaults toself.do_color_quantize) — 是否对图像进行颜色量化。 - clusters (
np.ndarray或List[List[int]], 可选, 默认为self.clusters) — 用于量化形状为(n_clusters, 3)的图像的聚类。仅在do_color_quantize设置为True时有效。 - return_tensors (
str或TensorType, 可选) — 返回的张量类型。可以是以下之一:- 未设置:返回一个
np.ndarray列表。 TensorType.TENSORFLOW或'tf':返回一个类型为tf.Tensor的批次。TensorType.PYTORCH或'pt':返回一个类型为torch.Tensor的批次。TensorType.NUMPY或'np':返回一个类型为np.ndarray的批次。TensorType.JAX或'jax':返回一个类型为jax.numpy.ndarray的批次。
- 未设置:返回一个
- data_format (
ChannelDimension或str, 可选, 默认为ChannelDimension.FIRST) — 输出图像的通道维度格式。可以是以下之一:ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。 仅在do_color_quantize设置为False时有效。
- input_data_format (
ChannelDimension或str, 可选) — 输入图像的通道维度格式。如果未设置,则从输入图像推断通道维度格式。可以是以下之一:"channels_first"或ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。"channels_last"或ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。"none"或ChannelDimension.NONE: 图像格式为 (height, width)。
预处理一张图像或一批图像。
ImageGPTModel
类 transformers.ImageGPTModel
< source >( config: ImageGPTConfig )
参数
- config (ImageGPTConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的ImageGPT模型变压器输出原始隐藏状态,顶部没有任何特定的头部。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.Tensor] = None past_key_values: typing.Optional[typing.Tuple[typing.Tuple[torch.Tensor]]] = None attention_mask: typing.Optional[torch.Tensor] = None token_type_ids: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None inputs_embeds: typing.Optional[torch.Tensor] = None encoder_hidden_states: typing.Optional[torch.Tensor] = None encoder_attention_mask: typing.Optional[torch.Tensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None **kwargs: typing.Any ) → transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) —input_ids_length=sequence_lengthifpast_key_valuesisNoneelsepast_key_values[0][0].shape[-2](sequence_lengthof input past key value states). Indices of input sequence tokens in the vocabulary.如果使用了
past_key_values,则只应将未计算其过去的input_ids作为input_ids传递。可以使用AutoImageProcessor获取索引。详情请参见ImageGPTImageProcessor.call()。
- past_key_values (
Tuple[Tuple[torch.Tensor]]长度为config.n_layers) — 包含模型计算的预计算隐藏状态(注意力块中的键和值)(参见下面的past_key_values输出)。可用于加速顺序解码。已经将其过去状态提供给此模型的input_ids不应再作为input_ids传递,因为它们已经被计算过了。 - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix.如果使用了
past_key_values,可以选择只输入最后的inputs_embeds(参见past_key_values)。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — 语言建模的标签。请注意,标签在模型内部被移位,即你可以设置labels = input_ids索引在[-100, 0, ..., config.vocab_size]中选择。所有设置为-100的标签 将被忽略(掩码),损失仅针对[0, ..., config.vocab_size]中的标签计算
返回
transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(ImageGPTConfig)和输入。
-
last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。如果使用了
past_key_values,则只输出形状为(batch_size, 1, hidden_size)的序列的最后一个隐藏状态。 -
past_key_values (
tuple(tuple(torch.FloatTensor)), 可选, 当传递了use_cache=True或当config.use_cache=True时返回) — 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量,并且如果config.is_encoder_decoder=True,则还包含 2 个额外的形状为(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)的张量。包含预先计算的隐藏状态(自注意力块中的键和值,并且如果
config.is_encoder_decoder=True,则在交叉注意力块中),可用于(参见past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
-
cross_attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True和config.add_cross_attention=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器的交叉注意力层的注意力权重,在注意力 softmax 后,用于计算交叉注意力头中的加权平均值。
ImageGPTModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, ImageGPTModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("openai/imagegpt-small")
>>> model = ImageGPTModel.from_pretrained("openai/imagegpt-small")
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateImageGPTForCausalImageModeling
类 transformers.ImageGPTForCausalImageModeling
< source >( config: ImageGPTConfig )
参数
- config (ImageGPTConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
ImageGPT模型变换器,顶部带有语言建模头(线性层,权重与输入嵌入绑定)。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.Tensor] = None past_key_values: typing.Optional[typing.Tuple[typing.Tuple[torch.Tensor]]] = None attention_mask: typing.Optional[torch.Tensor] = None token_type_ids: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None inputs_embeds: typing.Optional[torch.Tensor] = None encoder_hidden_states: typing.Optional[torch.Tensor] = None encoder_attention_mask: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.Tensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None **kwargs: typing.Any ) → transformers.modeling_outputs.CausalLMOutputWithCrossAttentions 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) —input_ids_length=sequence_lengthifpast_key_valuesisNoneelsepast_key_values[0][0].shape[-2](sequence_lengthof input past key value states). Indices of input sequence tokens in the vocabulary.如果使用了
past_key_values,则只应将未计算其过去的input_ids作为input_ids传递。可以使用AutoImageProcessor获取索引。详情请参见ImageGPTImageProcessor.call()。
- past_key_values (
Tuple[Tuple[torch.Tensor]]长度为config.n_layers) — 包含模型计算的预计算隐藏状态(注意力块中的键和值)(参见下面的past_key_values输出)。可用于加速顺序解码。已经将其过去状态提供给此模型的input_ids不应再作为input_ids传递,因为它们已经被计算过了。 - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix.如果使用了
past_key_values,可以选择只输入最后的inputs_embeds(参见past_key_values)。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — 语言建模的标签。请注意,标签在模型内部被移位,即你可以设置labels = input_ids索引在[-100, 0, ..., config.vocab_size]中选择。所有设置为-100的标签 将被忽略(掩码),损失仅针对[0, ..., config.vocab_size]中的标签计算
返回
transformers.modeling_outputs.CausalLMOutputWithCrossAttentions 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.CausalLMOutputWithCrossAttentions 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(ImageGPTConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 语言建模损失(用于下一个标记的预测)。 -
logits (
torch.FloatTensor形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
-
cross_attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的交叉注意力权重,用于计算交叉注意力头中的加权平均值。
-
past_key_values (
tuple(tuple(torch.FloatTensor)),可选,当传递use_cache=True或当config.use_cache=True时返回) — 由长度为config.n_layers的torch.FloatTensor元组组成的元组,每个元组包含自注意力和交叉注意力层的缓存键, 值状态,如果模型用于编码器-解码器设置。仅在config.is_decoder = True时相关。包含预计算的隐藏状态(注意力块中的键和值),可用于(参见
past_key_values输入)以加速顺序解码。
ImageGPTForCausalImageModeling 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, ImageGPTForCausalImageModeling
>>> import torch
>>> import matplotlib.pyplot as plt
>>> import numpy as np
>>> image_processor = AutoImageProcessor.from_pretrained("openai/imagegpt-small")
>>> model = ImageGPTForCausalImageModeling.from_pretrained("openai/imagegpt-small")
>>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
>>> model.to(device)
>>> # unconditional generation of 8 images
>>> batch_size = 4
>>> context = torch.full((batch_size, 1), model.config.vocab_size - 1) # initialize with SOS token
>>> context = context.to(device)
>>> output = model.generate(
... input_ids=context, max_length=model.config.n_positions + 1, temperature=1.0, do_sample=True, top_k=40
... )
>>> clusters = image_processor.clusters
>>> height = image_processor.size["height"]
>>> width = image_processor.size["width"]
>>> samples = output[:, 1:].cpu().detach().numpy()
>>> samples_img = [
... np.reshape(np.rint(127.5 * (clusters[s] + 1.0)), [height, width, 3]).astype(np.uint8) for s in samples
... ] # convert color cluster tokens back to pixels
>>> f, axes = plt.subplots(1, batch_size, dpi=300)
>>> for img, ax in zip(samples_img, axes):
... ax.axis("off")
... ax.imshow(img)ImageGPTForImageClassification
class transformers.ImageGPTForImageClassification
< source >( config: ImageGPTConfig )
参数
- config (ImageGPTConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
ImageGPT模型转换器,顶部带有图像分类头(线性层)。 ImageGPTForImageClassification 对隐藏状态进行平均池化以进行分类。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.Tensor] = None past_key_values: typing.Optional[typing.Tuple[typing.Tuple[torch.Tensor]]] = None attention_mask: typing.Optional[torch.Tensor] = None token_type_ids: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None inputs_embeds: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.Tensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None **kwargs: typing.Any ) → transformers.modeling_outputs.SequenceClassifierOutputWithPast 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) —input_ids_length=sequence_lengthifpast_key_valuesisNoneelsepast_key_values[0][0].shape[-2](sequence_lengthof input past key value states). Indices of input sequence tokens in the vocabulary.如果使用了
past_key_values,则只应将未计算其过去的input_ids作为input_ids传递。可以使用AutoImageProcessor获取索引。详情请参见ImageGPTImageProcessor.call()。
- past_key_values (
Tuple[Tuple[torch.Tensor]]长度为config.n_layers) — 包含模型计算的预计算隐藏状态(注意力块中的键和值)(参见下面的past_key_values输出)。可用于加速顺序解码。已经将其过去状态提供给此模型的input_ids不应再作为input_ids传递,因为它们已经被计算过了。 - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix.如果使用了
past_key_values,可以选择只输入最后的inputs_embeds(参见past_key_values)。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - labels (
torch.LongTensor形状为(batch_size,), 可选) — 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.SequenceClassifierOutputWithPast 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.SequenceClassifierOutputWithPast 或一个由 torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含根据配置(ImageGPTConfig)和输入的各种元素。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 分类(或回归,如果 config.num_labels==1)损失。 -
logits (
torch.FloatTensor形状为(batch_size, config.num_labels)) — 分类(或回归,如果 config.num_labels==1)得分(在 SoftMax 之前)。 -
past_key_values (
tuple(tuple(torch.FloatTensor)),可选,当传递use_cache=True或当config.use_cache=True时返回) — 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量。包含预先计算的隐藏状态(自注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层的输出)。模型在每层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。注意力权重在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
ImageGPTForImageClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, ImageGPTForImageClassification
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("openai/imagegpt-small")
>>> model = ImageGPTForImageClassification.from_pretrained("openai/imagegpt-small")
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits