ZoeDepth
概述
ZoeDepth模型由Shariq Farooq Bhat、Reiner Birkl、Diana Wofk、Peter Wonka和Matthias Müller在ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth中提出。ZoeDepth扩展了DPT框架,用于度量(也称为绝对)深度估计。ZoeDepth在12个数据集上使用相对深度进行预训练,并在两个领域(NYU和KITTI)上使用度量深度进行微调。每个领域使用一个轻量级头部,并采用一种称为度量箱模块的新型箱调整设计。在推理过程中,每个输入图像通过潜在分类器自动路由到适当的头部。
论文的摘要如下:
本文解决了从单张图像进行深度估计的问题。现有工作要么关注于忽略度量尺度的泛化性能,即相对深度估计,要么关注于特定数据集上的最先进结果,即度量深度估计。我们提出了第一种结合两者的方法,从而在保持度量尺度的同时,获得具有优异泛化性能的模型。我们的旗舰模型ZoeD-M12-NK在12个数据集上使用相对深度进行预训练,并在两个数据集上使用度量深度进行微调。我们为每个领域使用了一个轻量级的头部,并采用了一种新颖的称为度量箱模块的箱调整设计。在推理过程中,每个输入图像通过潜在分类器自动路由到适当的头部。我们的框架允许根据用于相对深度预训练和度量微调的数据集进行多种配置。即使没有预训练,我们也能显著提高NYU Depth v2室内数据集上的最先进水平(SOTA)。在12个数据集上进行预训练并在NYU Depth v2室内数据集上进行微调后,我们进一步将SOTA的相对绝对误差(REL)提高了21%。最后,ZoeD-M12-NK是第一个可以在多个数据集(NYU Depth v2和KITTI)上联合训练而不会显著降低性能的模型,并且在八个未见过的室内和室外数据集上实现了前所未有的零样本泛化性能。
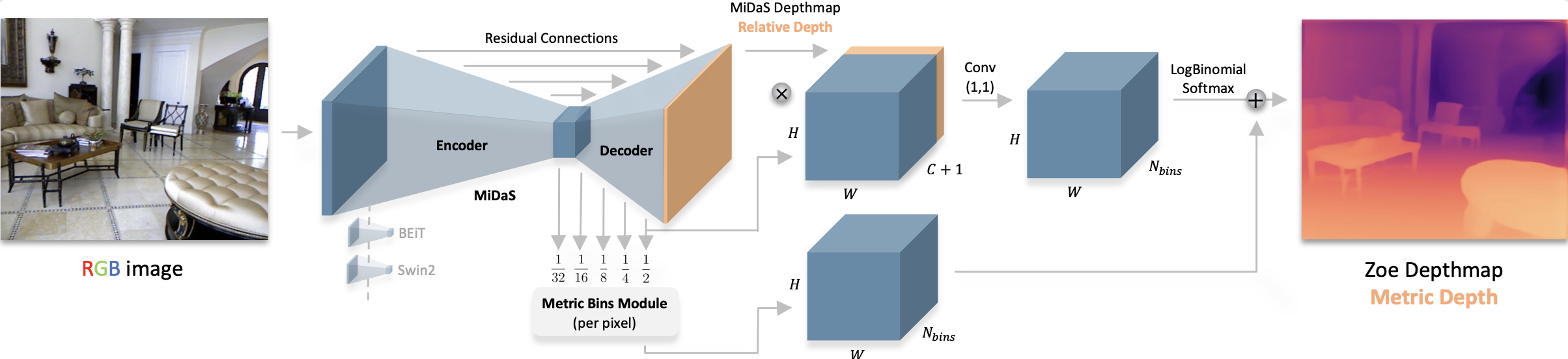 ZoeDepth architecture. Taken from the original paper.
ZoeDepth architecture. Taken from the original paper. 使用提示
- ZoeDepth 是一个绝对(也称为度量)深度估计模型,与 DPT 不同,DPT 是一个相对深度估计模型。这意味着 ZoeDepth 能够以米等度量单位估计深度。
使用ZoeDepth进行推理的最简单方法是利用pipeline API:
>>> from transformers import pipeline
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> pipe = pipeline(task="depth-estimation", model="Intel/zoedepth-nyu-kitti")
>>> result = pipe(image)
>>> depth = result["depth"]或者,也可以使用类进行推理:
>>> from transformers import AutoImageProcessor, ZoeDepthForDepthEstimation
>>> import torch
>>> import numpy as np
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("Intel/zoedepth-nyu-kitti")
>>> model = ZoeDepthForDepthEstimation.from_pretrained("Intel/zoedepth-nyu-kitti")
>>> # prepare image for the model
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(pixel_values)
>>> # interpolate to original size and visualize the prediction
>>> ## ZoeDepth dynamically pads the input image. Thus we pass the original image size as argument
>>> ## to `post_process_depth_estimation` to remove the padding and resize to original dimensions.
>>> post_processed_output = image_processor.post_process_depth_estimation(
... outputs,
... source_sizes=[(image.height, image.width)],
... )
>>> predicted_depth = post_processed_output[0]["predicted_depth"]
>>> depth = (predicted_depth - predicted_depth.min()) / (predicted_depth.max() - predicted_depth.min())
>>> depth = depth.detach().cpu().numpy() * 255
>>> depth = Image.fromarray(depth.astype("uint8"))在原始实现中,ZoeDepth模型对原始图像和翻转图像进行推理并平均结果。post_process_depth_estimation函数可以通过将翻转输出传递给可选的outputs_flipped参数来处理这一点:
>>> with torch.no_grad():
... outputs = model(pixel_values)
... outputs_flipped = model(pixel_values=torch.flip(inputs.pixel_values, dims=[3]))
>>> post_processed_output = image_processor.post_process_depth_estimation(
... outputs,
... source_sizes=[(image.height, image.width)],
... outputs_flipped=outputs_flipped,
... )
资源
一份官方的Hugging Face和社区(由🌎表示)资源列表,帮助您开始使用ZoeDepth。
- 关于使用ZoeDepth模型进行推理的演示笔记本可以在这里找到。🌎
ZoeDepthConfig
类 transformers.ZoeDepthConfig
< source >( backbone_config = None backbone = None use_pretrained_backbone = False backbone_kwargs = None hidden_act = 'gelu' initializer_range = 0.02 batch_norm_eps = 1e-05 readout_type = 'project' reassemble_factors = [4, 2, 1, 0.5] neck_hidden_sizes = [96, 192, 384, 768] fusion_hidden_size = 256 head_in_index = -1 use_batch_norm_in_fusion_residual = False use_bias_in_fusion_residual = None num_relative_features = 32 add_projection = False bottleneck_features = 256 num_attractors = [16, 8, 4, 1] bin_embedding_dim = 128 attractor_alpha = 1000 attractor_gamma = 2 attractor_kind = 'mean' min_temp = 0.0212 max_temp = 50.0 bin_centers_type = 'softplus' bin_configurations = [{'n_bins': 64, 'min_depth': 0.001, 'max_depth': 10.0}] num_patch_transformer_layers = None patch_transformer_hidden_size = None patch_transformer_intermediate_size = None patch_transformer_num_attention_heads = None **kwargs )
参数
- backbone_config (
Union[Dict[str, Any], PretrainedConfig], 可选, 默认为BeitConfig()) — 骨干模型的配置。 - backbone (
str, 可选) — 当backbone_config为None时使用的骨干网络名称。如果use_pretrained_backbone为True,这将从 timm 或 transformers 库加载相应的预训练权重。如果use_pretrained_backbone为False,这将加载骨干网络的配置并使用该配置初始化具有随机权重的骨干网络。 - use_pretrained_backbone (
bool, 可选, 默认为False) — 是否使用预训练的权重作为骨干网络。 - backbone_kwargs (
dict, optional) — 从检查点加载时传递给AutoBackbone的关键字参数 例如{'out_indices': (0, 1, 2, 3)}。如果设置了backbone_config,则不能指定此参数。 - hidden_act (
str或function, 可选, 默认为"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"selu"和"gelu_new"。 - initializer_range (
float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 - batch_norm_eps (
float, optional, defaults to 1e-05) — 批归一化层使用的epsilon值。 - readout_type (
str, 可选, 默认为"project") — 在处理ViT骨干网络中间隐藏状态的读出标记(CLS标记)时使用的读出类型。可以是以下之一:["ignore","add","project"]。- “ignore” 简单地忽略CLS标记。
- “add” 通过添加表示将CLS标记的信息传递给所有其他标记。
- “project” 通过将读出连接到所有其他标记,然后使用线性层和GELU非线性将表示投影到原始特征维度D,将信息传递给其他标记。
- reassemble_factors (
List[int], 可选, 默认为[4, 2, 1, 0.5]) — 重新组装层的上/下采样因子。 - neck_hidden_sizes (
List[str], optional, 默认为[96, 192, 384, 768]) — 用于投影到骨干网络特征图的隐藏大小。 - fusion_hidden_size (
int, optional, 默认为 256) — 融合前的通道数。 - head_in_index (
int, optional, 默认为 -1) — 用于头部的特征索引。 - use_batch_norm_in_fusion_residual (
bool, 可选, 默认为False) — 是否在融合块的预激活残差单元中使用批量归一化。 - use_bias_in_fusion_residual (
bool, 可选, 默认为True) — 是否在融合块的预激活残差单元中使用偏置。 - num_relative_features (
int, optional, defaults to 32) — 用于相对深度估计头部的特征数量。 - add_projection (
bool, 可选, 默认为False) — 是否在深度估计头之前添加一个投影层。 - bottleneck_features (
int, optional, defaults to 256) — 瓶颈层中的特征数量。 - num_attractors (
List[int], *optional*, defaults to[16, 8, 4, 1]`) — 每个阶段使用的吸引子数量。 - bin_embedding_dim (
int, optional, defaults to 128) — bin嵌入的维度。 - attractor_alpha (
int, 可选, 默认为 1000) — 在吸引子中使用的 alpha 值。 - attractor_gamma (
int, optional, defaults to 2) — 在吸引子中使用的gamma值。 - attractor_kind (
str, 可选, 默认为"mean") — 使用的吸引子类型。可以是 ["mean","sum"] 之一。 - min_temp (
float, optional, 默认值为 0.0212) — 要考虑的最小温度值。 - max_temp (
float, optional, 默认值为 50.0) — 要考虑的最大温度值。 - bin_centers_type (
str, 可选, 默认为"softplus") — 用于分箱中心的激活类型。可以是“normed”或“softplus”。对于“normed”分箱中心,应用线性归一化技巧。 这会导致分箱中心有界。对于“softplus”,使用softplus激活,因此是无界的。 - bin_configurations (
List[dict], optional, defaults to[{'n_bins' -- 64, 'min_depth': 0.001, 'max_depth': 10.0}]): Configuration for each of the bin heads. Each configuration should consist of the following keys:- name (
str): The name of the bin head - only required in case of multiple bin configurations. n_bins(int): The number of bins to use.min_depth(float): The minimum depth value to consider.max_depth(float): The maximum depth value to consider. In case only a single configuration is passed, the model will use a single head with the specified configuration. In case multiple configurations are passed, the model will use multiple heads with the specified configurations.
- name (
- num_patch_transformer_layers (
int, optional) — 在补丁变压器中使用的变压器层数。仅在多个箱配置的情况下使用。 - patch_transformer_hidden_size (
int, optional) — 在补丁变换器中使用的隐藏大小。仅在多个bin配置的情况下使用。 - patch_transformer_intermediate_size (
int, optional) — 在补丁变换器中使用的中间大小。仅在多个bin配置的情况下使用。 - patch_transformer_num_attention_heads (
int, optional) — 在补丁变换器中使用的注意力头数。仅在多个bin配置的情况下使用。
这是用于存储ZoeDepthForDepthEstimation配置的配置类。它用于根据指定的参数实例化ZoeDepth模型,定义模型架构。使用默认值实例化配置将产生与ZoeDepth Intel/zoedepth-nyu架构相似的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import ZoeDepthConfig, ZoeDepthForDepthEstimation
>>> # Initializing a ZoeDepth zoedepth-large style configuration
>>> configuration = ZoeDepthConfig()
>>> # Initializing a model from the zoedepth-large style configuration
>>> model = ZoeDepthForDepthEstimation(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configZoeDepthImageProcessor
类 transformers.ZoeDepthImageProcessor
< source >( do_pad: bool = True do_rescale: bool = True rescale_factor: typing.Union[int, float] = 0.00392156862745098 do_normalize: bool = True image_mean: typing.Union[float, typing.List[float], NoneType] = None image_std: typing.Union[float, typing.List[float], NoneType] = None do_resize: bool = True size: typing.Dict[str, int] = None resample: Resampling =
参数
- do_pad (
bool, optional, defaults toTrue) — 是否对输入进行填充. - do_rescale (
bool, 可选, 默认为True) — 是否通过指定的比例rescale_factor重新缩放图像。可以在preprocess中被do_rescale覆盖。 - rescale_factor (
int或float, 可选, 默认为1/255) — 如果重新缩放图像,则使用的缩放因子。可以在preprocess中被rescale_factor覆盖。 - do_normalize (
bool, 可选, 默认为True) — 是否对图像进行归一化。可以在preprocess方法中通过do_normalize参数进行覆盖。 - image_mean (
float或List[float], 可选, 默认为IMAGENET_STANDARD_MEAN) — 如果对图像进行归一化,则使用的均值。这是一个浮点数或与图像通道数长度相同的浮点数列表。可以通过preprocess方法中的image_mean参数进行覆盖。 - image_std (
float或List[float], 可选, 默认为IMAGENET_STANDARD_STD) — 如果对图像进行归一化,则使用的标准差。这是一个浮点数或与图像通道数长度相同的浮点数列表。可以通过preprocess方法中的image_std参数进行覆盖。 - do_resize (
bool, 可选, 默认为True) — 是否调整图像的(高度,宽度)尺寸。可以在preprocess中被do_resize覆盖。 - size (
Dict[str, int]可选, 默认为{"height" -- 384, "width": 512}): 调整大小后的图像尺寸。如果keep_aspect_ratio为True, 图像将通过选择高度和宽度缩放因子中较小的一个,并将其用于两个维度来调整大小。 如果还设置了ensure_multiple_of,图像将进一步调整为此值的倍数大小。 可以在preprocess中通过size覆盖此设置。 - resample (
PILImageResampling, 可选, 默认为Resampling.BILINEAR) — 定义在调整图像大小时使用的重采样过滤器。可以在preprocess中通过resample覆盖此设置。 - keep_aspect_ratio (
bool, 可选, 默认为True) — 如果为True,图像将通过选择高度和宽度缩放因子中较小的一个来调整大小,并将其用于两个维度。这确保了图像在尽可能少地缩小的情况下仍然适合所需的输出尺寸。如果还设置了ensure_multiple_of,图像将进一步调整大小,使其高度和宽度向下取整到该值的最近倍数。可以通过preprocess中的keep_aspect_ratio进行覆盖。 - ensure_multiple_of (
int, optional, defaults to 32) — Ifdo_resizeisTrue, the image is resized to a size that is a multiple of this value. Works by flooring the height and width to the nearest multiple of this value.无论是否将
keep_aspect_ratio设置为True,都可以工作。可以在preprocess中被ensure_multiple_of覆盖。
构建一个ZoeDepth图像处理器。
预处理
< source >( images: typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), typing.List[ForwardRef('PIL.Image.Image')], typing.List[numpy.ndarray], typing.List[ForwardRef('torch.Tensor')]] do_pad: bool = None do_rescale: bool = None rescale_factor: float = None do_normalize: bool = None image_mean: typing.Union[float, typing.List[float], NoneType] = None image_std: typing.Union[float, typing.List[float], NoneType] = None do_resize: bool = None size: int = None keep_aspect_ratio: bool = None ensure_multiple_of: int = None resample: Resampling = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None data_format: ChannelDimension =
参数
- 图像 (
ImageInput) — 要预处理的图像。期望输入单个或批量的图像,像素值范围在0到255之间。如果传入的图像像素值在0到1之间,请设置do_rescale=False. - do_pad (
bool, 可选, 默认为self.do_pad) — 是否对输入图像进行填充. - do_rescale (
bool, optional, defaults toself.do_rescale) — 是否将图像值缩放到 [0 - 1] 之间。 - rescale_factor (
float, optional, defaults toself.rescale_factor) — 如果do_rescale设置为True,则用于重新缩放图像的重新缩放因子。 - do_normalize (
bool, optional, defaults toself.do_normalize) — 是否对图像进行归一化处理. - image_mean (
float或List[float], 可选, 默认为self.image_mean) — 图像均值. - image_std (
floatorList[float], optional, defaults toself.image_std) — 图像标准差. - do_resize (
bool, optional, defaults toself.do_resize) — 是否调整图像大小. - size (
Dict[str, int], 可选, 默认为self.size) — 调整大小后的图像尺寸。如果keep_aspect_ratio为True,则通过选择高度和宽度缩放因子中的较小者并将其用于两个维度来调整图像大小。如果还设置了ensure_multiple_of,则图像会进一步调整为此值的倍数大小。 - keep_aspect_ratio (
bool, 可选, 默认为self.keep_aspect_ratio) — 如果为True且do_resize=True,图像将通过选择高度和宽度缩放因子中的较小者来调整大小,并将其用于两个维度。这确保图像在尽可能少地缩小的情况下仍能适应所需的输出尺寸。如果还设置了ensure_multiple_of,图像将进一步调整大小,使其高度和宽度向下取整到该值的最近倍数。 - ensure_multiple_of (
int, optional, defaults toself.ensure_multiple_of) — Ifdo_resizeisTrue, the image is resized to a size that is a multiple of this value. Works by flooring the height and width to the nearest multiple of this value.无论是否将
keep_aspect_ratio设置为True,都可以正常工作。可以在preprocess中通过ensure_multiple_of进行覆盖。 - resample (
int, 可选, 默认为self.resample) — 如果调整图像大小,则使用的重采样过滤器。这可以是枚举PILImageResampling之一,只有在do_resize设置为True时才会生效。 - return_tensors (
str或TensorType, 可选) — 返回的张量类型。可以是以下之一:- 未设置:返回一个
np.ndarray列表。 TensorType.TENSORFLOW或'tf':返回一个类型为tf.Tensor的批次。TensorType.PYTORCH或'pt':返回一个类型为torch.Tensor的批次。TensorType.NUMPY或'np':返回一个类型为np.ndarray的批次。TensorType.JAX或'jax':返回一个类型为jax.numpy.ndarray的批次。
- 未设置:返回一个
- data_format (
ChannelDimension或str, 可选, 默认为ChannelDimension.FIRST) — 输出图像的通道维度格式。可以是以下之一:ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。
- input_data_format (
ChannelDimension或str, 可选) — 输入图像的通道维度格式。如果未设置,则从输入图像推断通道维度格式。可以是以下之一:"channels_first"或ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。"channels_last"或ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。"none"或ChannelDimension.NONE: 图像格式为 (height, width)。
预处理一张图像或一批图像。
ZoeDepthForDepthEstimation
类 transformers.ZoeDepthForDepthEstimation
< source >( config )
参数
- config (ViTConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
ZoeDepth 模型,顶部带有一个或多个度量深度估计头。
该模型是一个PyTorch torch.nn.Module 子类。将其用作常规的PyTorch模块,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( pixel_values: FloatTensor labels: typing.Optional[torch.LongTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.DepthEstimatorOutput 或 tuple(torch.FloatTensor)
参数
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用AutoImageProcessor获取。详情请参见DPTImageProcessor.call()。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size, height, width), optional) — 用于计算损失的真实深度估计图。
返回
transformers.modeling_outputs.DepthEstimatorOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.DepthEstimatorOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(ZoeDepthConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,), 可选, 当提供labels时返回) — 分类(或回归,如果 config.num_labels==1)损失。 -
predicted_depth (
torch.FloatTensor形状为(batch_size, height, width)) — 每个像素的预测深度。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层的输出)形状为(batch_size, num_channels, height, width)。模型在每层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个)形状为(batch_size, num_heads, patch_size, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
ZoeDepthForDepthEstimation 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, ZoeDepthForDepthEstimation
>>> import torch
>>> import numpy as np
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("Intel/zoedepth-nyu-kitti")
>>> model = ZoeDepthForDepthEstimation.from_pretrained("Intel/zoedepth-nyu-kitti")
>>> # prepare image for the model
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> # interpolate to original size
>>> post_processed_output = image_processor.post_process_depth_estimation(
... outputs,
... source_sizes=[(image.height, image.width)],
... )
>>> # visualize the prediction
>>> predicted_depth = post_processed_output[0]["predicted_depth"]
>>> depth = predicted_depth * 255 / predicted_depth.max()
>>> depth = depth.detach().cpu().numpy()
>>> depth = Image.fromarray(depth.astype("uint8"))