音频频谱图转换器
概述
音频频谱图变换器模型由Yuan Gong、Yu-An Chung和James Glass在AST: Audio Spectrogram Transformer中提出。 音频频谱图变换器通过将音频转换为图像(频谱图),将视觉变换器应用于音频。该模型在音频分类方面取得了最先进的结果。
论文的摘要如下:
在过去的十年中,卷积神经网络(CNNs)被广泛采用作为端到端音频分类模型的主要构建模块,这些模型旨在学习从音频频谱图到相应标签的直接映射。为了更好地捕捉长距离的全局上下文,最近的一个趋势是在CNN之上添加自注意力机制,形成CNN-注意力混合模型。然而,尚不清楚对CNN的依赖是否是必要的,以及纯粹基于注意力的神经网络是否足以在音频分类中获得良好的性能。在本文中,我们通过引入音频频谱图变换器(AST)来回答这个问题,这是第一个无卷积、纯粹基于注意力的音频分类模型。我们在各种音频分类基准上评估了AST,在AudioSet上达到了0.485 mAP的最新成果,在ESC-50上达到了95.6%的准确率,在Speech Commands V2上达到了98.1%的准确率。
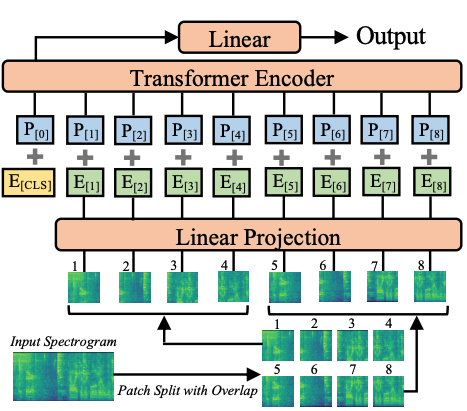 Audio Spectrogram Transformer architecture. Taken from the original paper.
Audio Spectrogram Transformer architecture. Taken from the original paper. 使用提示
- 在您自己的数据集上微调音频频谱图变换器(AST)时,建议注意输入归一化(确保输入均值为0,标准差为0.5)。ASTFeatureExtractor会处理这一点。请注意,它默认使用AudioSet的均值和标准差。您可以查看
ast/src/get_norm_stats.py以了解作者如何计算下游数据集的统计信息。 - 请注意,AST需要一个较低的学习率(作者使用的学习率比他们在PSLA论文中提出的CNN模型小10倍),并且收敛速度很快,因此请为您的任务搜索合适的学习率和学习率调度器。
使用缩放点积注意力 (SDPA)
PyTorch 包含一个原生的缩放点积注意力(SDPA)操作符,作为 torch.nn.functional 的一部分。这个函数
包含了几种实现,可以根据输入和使用的硬件进行应用。更多信息请参阅
官方文档
或 GPU 推理
页面。
默认情况下,当有可用实现时,SDPA 用于 torch>=2.1.1,但你也可以在 from_pretrained() 中设置 attn_implementation="sdpa" 来明确请求使用 SDPA。
from transformers import ASTForAudioClassification
model = ASTForAudioClassification.from_pretrained("MIT/ast-finetuned-audioset-10-10-0.4593", attn_implementation="sdpa", torch_dtype=torch.float16)
...为了获得最佳加速效果,我们建议以半精度加载模型(例如 torch.float16 或 torch.bfloat16)。
在本地基准测试(A100-40GB,PyTorch 2.3.0,操作系统 Ubuntu 22.04)中,使用float32和MIT/ast-finetuned-audioset-10-10-0.4593模型,我们在推理过程中看到了以下加速效果。
| 批量大小 | 平均推理时间(毫秒),eager模式 | 平均推理时间(毫秒),sdpa模型 | 加速比,Sdpa / Eager(倍) |
|---|---|---|---|
| 1 | 27 | 6 | 4.5 |
| 2 | 12 | 6 | 2 |
| 4 | 21 | 8 | 2.62 |
| 8 | 40 | 14 | 2.86 |
资源
以下是官方Hugging Face和社区(由🌎表示)提供的资源列表,帮助您开始使用音频频谱变换器。
- 一个展示使用AST进行音频分类推理的笔记本可以在这里找到。
- ASTForAudioClassification 由这个 示例脚本 和 笔记本 支持。
- 另请参阅:音频分类。
如果您有兴趣提交资源以包含在此处,请随时打开一个 Pull Request,我们将进行审核!理想情况下,资源应展示一些新内容,而不是重复现有资源。
ASTConfig
类 transformers.ASTConfig
< source >( hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.0 attention_probs_dropout_prob = 0.0 initializer_range = 0.02 layer_norm_eps = 1e-12 patch_size = 16 qkv_bias = True frequency_stride = 10 time_stride = 10 max_length = 1024 num_mel_bins = 128 **kwargs )
参数
- hidden_size (
int, optional, 默认为 768) — 编码器层和池化层的维度。 - num_hidden_layers (
int, optional, defaults to 12) — Transformer编码器中的隐藏层数量。 - num_attention_heads (
int, optional, defaults to 12) — Transformer编码器中每个注意力层的注意力头数。 - intermediate_size (
int, optional, 默认为 3072) — Transformer 编码器中“中间”(即前馈)层的维度。 - hidden_act (
str或function, 可选, 默认为"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"selu"和"gelu_new"。 - hidden_dropout_prob (
float, optional, 默认为 0.0) — 嵌入层、编码器和池化器中所有全连接层的 dropout 概率。 - attention_probs_dropout_prob (
float, optional, 默认为 0.0) — 注意力概率的丢弃比率。 - initializer_range (
float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 - layer_norm_eps (
float, optional, defaults to 1e-12) — 层归一化层使用的epsilon值。 - patch_size (
int, optional, defaults to 16) — 每个补丁的大小(分辨率)。 - qkv_bias (
bool, optional, defaults toTrue) — 是否在查询、键和值中添加偏置。 - frequency_stride (
int, optional, defaults to 10) — 在将频谱图分割成小块时使用的频率步长。 - time_stride (
int, optional, defaults to 10) — 在将频谱图分割成小块时使用的时间步长。 - max_length (
int, optional, 默认为 1024) — 频谱图的时间维度。 - num_mel_bins (
int, optional, defaults to 128) — 频谱图的频率维度(Mel频率分箱的数量)。
这是用于存储ASTModel配置的配置类。它用于根据指定的参数实例化一个AST模型,定义模型架构。使用默认值实例化配置将产生类似于MIT/ast-finetuned-audioset-10-10-0.4593架构的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import ASTConfig, ASTModel
>>> # Initializing a AST MIT/ast-finetuned-audioset-10-10-0.4593 style configuration
>>> configuration = ASTConfig()
>>> # Initializing a model (with random weights) from the MIT/ast-finetuned-audioset-10-10-0.4593 style configuration
>>> model = ASTModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configASTFeatureExtractor
类 transformers.ASTFeatureExtractor
< source >( feature_size = 1 sampling_rate = 16000 num_mel_bins = 128 max_length = 1024 padding_value = 0.0 do_normalize = True mean = -4.2677393 std = 4.5689974 return_attention_mask = False **kwargs )
参数
- feature_size (
int, optional, defaults to 1) — 提取的特征的特征维度。 - sampling_rate (
int, optional, defaults to 16000) — 音频文件应被数字化的采样率,以赫兹(Hz)表示。 - num_mel_bins (
int, optional, defaults to 128) — 梅尔频率区间的数量。 - max_length (
int, optional, defaults to 1024) — 提取特征的最大长度,用于填充或截断。 - do_normalize (
bool, 可选, 默认为True) — 是否使用mean和std对 log-Mel 特征进行归一化. - mean (
float, optional, 默认为 -4.2677393) — 用于归一化对数梅尔特征的均值。默认使用AudioSet的均值。 - std (
float, 可选, 默认值为 4.5689974) — 用于归一化对数梅尔特征的标准差值。默认使用 AudioSet 的标准差。 - return_attention_mask (
bool, 可选, 默认为False) — 是否 call() 应该返回attention_mask.
构建一个音频频谱图转换器(AST)特征提取器。
此特征提取器继承自SequenceFeatureExtractor,其中包含 大部分主要方法。用户应参考此超类以获取有关这些方法的更多信息。
该类从原始语音中提取梅尔滤波器组特征,如果安装了TorchAudio则使用TorchAudio,否则使用numpy,将它们填充/截断到固定长度,并使用均值和标准差进行归一化。
__call__
< source >( raw_speech: typing.Union[numpy.ndarray, typing.List[float], typing.List[numpy.ndarray], typing.List[typing.List[float]]] sampling_rate: typing.Optional[int] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None **kwargs )
参数
- raw_speech (
np.ndarray,List[float],List[np.ndarray],List[List[float]]) — 要填充的序列或序列批次。每个序列可以是一个numpy数组、一个浮点值列表、一个numpy数组列表或一个浮点值列表的列表。必须是单声道音频,而不是立体声,即每个时间步长只有一个浮点数。 - sampling_rate (
int, optional) —raw_speech输入被采样的采样率。强烈建议在前向调用时传递sampling_rate以防止静默错误。 - return_tensors (
str或 TensorType, 可选) — 如果设置,将返回张量而不是Python整数列表。可接受的值有:'tf': 返回 TensorFlowtf.constant对象。'pt': 返回 PyTorchtorch.Tensor对象。'np': 返回 Numpynp.ndarray对象。
用于特征化并为一个或多个序列准备模型的主要方法。
ASTModel
类 transformers.ASTModel
< source >( config: ASTConfig )
参数
- config (ASTConfig) — 模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型相关的权重,仅加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的AST模型转换器输出原始的隐藏状态,没有任何特定的头部。 这个模型是一个PyTorch torch.nn.Module 子类。将其用作常规的PyTorch模块,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_values: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.BaseModelOutputWithPooling 或 tuple(torch.FloatTensor)
参数
- input_values (
torch.FloatTensorof shape(batch_size, max_length, num_mel_bins)) — Float values mel features extracted from the raw audio waveform. Raw audio waveform can be obtained by loading a.flacor.wavaudio file into an array of typeList[float]or anumpy.ndarray, e.g. via the soundfile library (pip install soundfile). To prepare the array intoinput_features, the AutoFeatureExtractor should be used for extracting the mel features, padding and conversion into a tensor of typetorch.FloatTensor. See call() - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPooling 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithPooling 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(ASTConfig)和输入。
-
last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。 -
pooler_output (
torch.FloatTensor形状为(batch_size, hidden_size)) — 序列的第一个标记(分类标记)在经过用于辅助预训练任务的层进一步处理后的最后一层隐藏状态。例如,对于BERT系列模型,这返回经过线性层和tanh激活函数处理后的分类标记。线性层的权重是在预训练期间通过下一个句子预测(分类)目标训练的。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力softmax后的注意力权重,用于计算自注意力头中的加权平均值。
ASTModel 的 forward 方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoProcessor, ASTModel
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation", trust_remote_code=True)
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> processor = AutoProcessor.from_pretrained("MIT/ast-finetuned-audioset-10-10-0.4593")
>>> model = ASTModel.from_pretrained("MIT/ast-finetuned-audioset-10-10-0.4593")
>>> # audio file is decoded on the fly
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 1214, 768]ASTForAudioClassification
类 transformers.ASTForAudioClassification
< source >( config: ASTConfig )
参数
- config (ASTConfig) — 模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型相关的权重,仅加载配置。查看 from_pretrained() 方法以加载模型权重。
音频频谱图变换器模型,顶部带有音频分类头(在池化输出之上的线性层),例如用于AudioSet、Speech Commands v2等数据集。
该模型是一个PyTorch torch.nn.Module 子类。将其用作常规的PyTorch模块,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_values: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.SequenceClassifierOutput 或 tuple(torch.FloatTensor)
参数
- input_values (
torch.FloatTensorof shape(batch_size, max_length, num_mel_bins)) — Float values mel features extracted from the raw audio waveform. Raw audio waveform can be obtained by loading a.flacor.wavaudio file into an array of typeList[float]or anumpy.ndarray, e.g. via the soundfile library (pip install soundfile). To prepare the array intoinput_features, the AutoFeatureExtractor should be used for extracting the mel features, padding and conversion into a tensor of typetorch.FloatTensor. See call() - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size,), optional) — 用于计算音频分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.SequenceClassifierOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.SequenceClassifierOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(ASTConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 分类(或回归,如果 config.num_labels==1)损失。 -
logits (
torch.FloatTensor形状为(batch_size, config.num_labels)) — 分类(或回归,如果 config.num_labels==1)分数(在 SoftMax 之前)。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
ASTForAudioClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoFeatureExtractor, ASTForAudioClassification
>>> from datasets import load_dataset
>>> import torch
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation", trust_remote_code=True)
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("MIT/ast-finetuned-audioset-10-10-0.4593")
>>> model = ASTForAudioClassification.from_pretrained("MIT/ast-finetuned-audioset-10-10-0.4593")
>>> # audio file is decoded on the fly
>>> inputs = feature_extractor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_ids = torch.argmax(logits, dim=-1).item()
>>> predicted_label = model.config.id2label[predicted_class_ids]
>>> predicted_label
'Speech'
>>> # compute loss - target_label is e.g. "down"
>>> target_label = model.config.id2label[0]
>>> inputs["labels"] = torch.tensor([model.config.label2id[target_label]])
>>> loss = model(**inputs).loss
>>> round(loss.item(), 2)
0.17