Wav2Vec2
概述
Wav2Vec2模型由Alexei Baevski、Henry Zhou、Abdelrahman Mohamed和Michael Auli在wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations中提出。
论文的摘要如下:
我们首次展示了仅从语音音频中学习强大的表示,然后对转录语音进行微调,可以在概念上更简单的同时超越最好的半监督方法。wav2vec 2.0 在潜在空间中屏蔽语音输入,并解决了一个基于潜在表示量化的对比任务,这些表示是联合学习的。使用 Librispeech 的所有标记数据进行的实验在干净/其他测试集上达到了 1.8/3.3 WER。当将标记数据量减少到一小时时,wav2vec 2.0 在使用 100 倍少的标记数据的情况下,在 100 小时子集上超越了之前的最新技术。仅使用十分钟的标记数据并在 53k 小时的未标记数据上进行预训练,仍然达到了 4.8/8.2 WER。这证明了在有限标记数据量下进行语音识别的可行性。
该模型由patrickvonplaten贡献。
注意:Meta (FAIR) 发布了新版本的 Wav2Vec2-BERT 2.0 - 它预训练了450万小时的音频数据。我们特别推荐将其用于微调任务,例如按照 此指南 进行操作。
使用提示
- Wav2Vec2 是一个语音模型,它接受与语音信号的原始波形相对应的浮点数组。
- Wav2Vec2 模型是使用连接时序分类(CTC)进行训练的,因此模型输出必须使用 Wav2Vec2CTCTokenizer 进行解码。
使用 Flash Attention 2
Flash Attention 2 是该模型的一个更快、优化的版本。
安装
首先,检查您的硬件是否与Flash Attention 2兼容。最新的兼容硬件列表可以在官方文档中找到。如果您的硬件不兼容Flash Attention 2,您仍然可以通过上述介绍的Better Transformer支持从注意力内核优化中受益。
接下来,安装最新版本的Flash Attention 2:
pip install -U flash-attn --no-build-isolation
用法
要使用Flash Attention 2加载模型,我们可以将参数attn_implementation="flash_attention_2"传递给.from_pretrained。我们还将以半精度(例如torch.float16)加载模型,因为这样几乎不会降低音频质量,但可以显著减少内存使用并加快推理速度:
>>> from transformers import Wav2Vec2Model
model = Wav2Vec2Model.from_pretrained("facebook/wav2vec2-large-960h-lv60-self", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to(device)
...预期的加速
下面是一个预期的加速图,比较了facebook/wav2vec2-large-960h-lv60-self模型在transformers中的原生实现与flash-attention-2和sdpa(scale-dot-product-attention)版本之间的纯推理时间。我们展示了在librispeech_asr clean验证集上获得的平均加速:
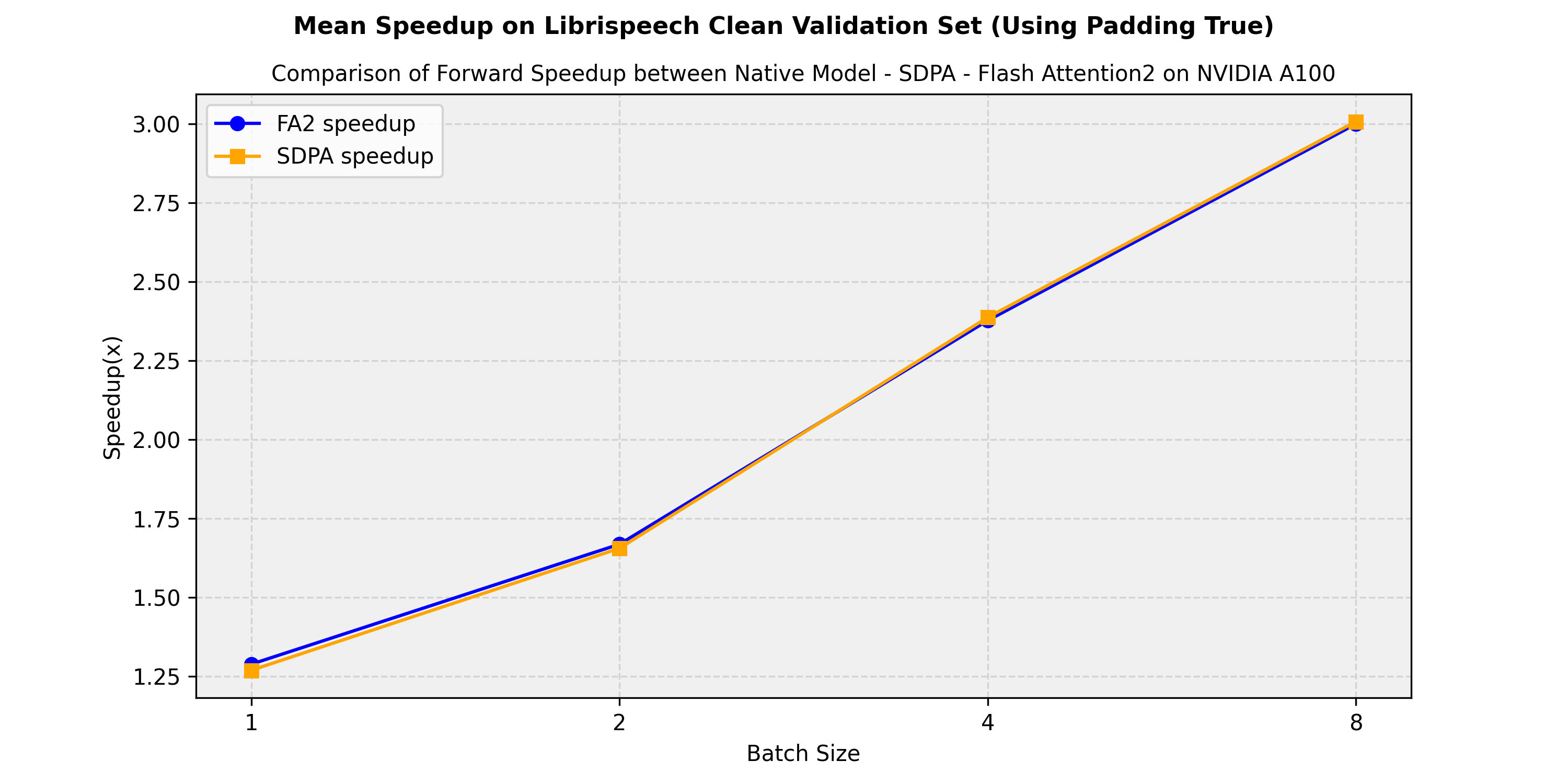
资源
一份官方的Hugging Face和社区(由🌎表示)资源列表,帮助您开始使用Wav2Vec2。如果您有兴趣提交资源以包含在此处,请随时打开一个Pull Request,我们将进行审核!理想情况下,资源应展示一些新内容,而不是重复现有资源。
- 一个关于如何利用预训练的Wav2Vec2模型进行情感分类的笔记本。🌎
- Wav2Vec2ForCTC 由这个 示例脚本 和 笔记本 支持。
- 音频分类任务指南
- 一篇关于在🤗 Transformers中使用n-grams增强Wav2Vec2的博客文章boosting Wav2Vec2 with n-grams in 🤗 Transformers。
- 一篇关于如何使用🤗 Transformers微调Wav2Vec2进行英语ASR的博客文章。
- 一篇关于使用🤗 Transformers微调XLS-R进行多语言ASR的博客文章。
- 一个关于如何通过使用Wav2Vec2转录音频从任何视频创建YouTube字幕的笔记本。🌎
- Wav2Vec2ForCTC 支持一个关于如何微调英语语音识别模型的笔记本,以及如何微调任何语言的语音识别模型。
- 自动语音识别任务指南
🚀 部署
- 一篇关于如何使用Hugging Face的Transformers和Amazon SageMaker部署Wav2Vec2进行自动语音识别的博客文章。
Wav2Vec2Config
类 transformers.Wav2Vec2Config
< source >( vocab_size = 32 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout = 0.1 activation_dropout = 0.1 attention_dropout = 0.1 feat_proj_dropout = 0.0 feat_quantizer_dropout = 0.0 final_dropout = 0.1 layerdrop = 0.1 initializer_range = 0.02 layer_norm_eps = 1e-05 feat_extract_norm = 'group' feat_extract_activation = 'gelu' conv_dim = (512, 512, 512, 512, 512, 512, 512) conv_stride = (5, 2, 2, 2, 2, 2, 2) conv_kernel = (10, 3, 3, 3, 3, 2, 2) conv_bias = False num_conv_pos_embeddings = 128 num_conv_pos_embedding_groups = 16 do_stable_layer_norm = False apply_spec_augment = True mask_time_prob = 0.05 mask_time_length = 10 mask_time_min_masks = 2 mask_feature_prob = 0.0 mask_feature_length = 10 mask_feature_min_masks = 0 num_codevectors_per_group = 320 num_codevector_groups = 2 contrastive_logits_temperature = 0.1 num_negatives = 100 codevector_dim = 256 proj_codevector_dim = 256 diversity_loss_weight = 0.1 ctc_loss_reduction = 'sum' ctc_zero_infinity = False use_weighted_layer_sum = False classifier_proj_size = 256 tdnn_dim = (512, 512, 512, 512, 1500) tdnn_kernel = (5, 3, 3, 1, 1) tdnn_dilation = (1, 2, 3, 1, 1) xvector_output_dim = 512 pad_token_id = 0 bos_token_id = 1 eos_token_id = 2 add_adapter = False adapter_kernel_size = 3 adapter_stride = 2 num_adapter_layers = 3 output_hidden_size = None adapter_attn_dim = None **kwargs )
参数
- vocab_size (
int, optional, 默认为 32) — Wav2Vec2 模型的词汇表大小。定义了调用 Wav2Vec2Model 或 TFWav2Vec2Model 时传递的inputs_ids可以表示的不同标记的数量。模型的词汇表大小。定义了传递给 Wav2Vec2Model 的 inputs_ids 可以表示的不同标记。 - hidden_size (
int, optional, defaults to 768) — 编码器层和池化层的维度。 - num_hidden_layers (
int, optional, 默认为 12) — Transformer 编码器中的隐藏层数量。 - num_attention_heads (
int, optional, 默认为 12) — Transformer 编码器中每个注意力层的注意力头数。 - intermediate_size (
int, optional, 默认为 3072) — Transformer 编码器中“中间”(即前馈)层的维度。 - hidden_act (
str或function, 可选, 默认为"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"selu"和"gelu_new"。 - hidden_dropout (
float, optional, 默认为 0.1) — 嵌入层、编码器和池化器中所有全连接层的 dropout 概率。 - activation_dropout (
float, optional, defaults to 0.1) — 全连接层内部激活的dropout比率。 - attention_dropout (
float, optional, 默认为 0.1) — 注意力概率的丢弃比率。 - final_dropout (
float, optional, defaults to 0.1) — Wav2Vec2ForCTC的最终投影层的dropout概率。 - layerdrop (
float, 可选, 默认为 0.1) — LayerDrop 概率。更多详情请参阅 [LayerDrop 论文](see https://arxiv.org/abs/1909.11556)。 - initializer_range (
float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的 truncated_normal_initializer 的标准差。 - layer_norm_eps (
float, optional, defaults to 1e-12) — 层归一化层使用的epsilon值。 - feat_extract_norm (
str, 可选, 默认为"group") — 应用于特征编码器中1D卷积层的归一化方法。可以是"group"用于仅对第一个1D卷积层进行组归一化,或"layer"用于对所有1D卷积层进行层归一化。 - feat_proj_dropout (
float, optional, defaults to 0.0) — 特征编码器输出的丢弃概率。 - feat_extract_activation (
str,可选, 默认为“gelu”) -- 特征提取器的1D卷积层中的非线性激活函数(函数或字符串)。如果是字符串,支持“gelu”,“relu”,“selu”和“gelu_new”`。 - feat_quantizer_dropout (
float, optional, defaults to 0.0) — 量化特征编码器状态的丢弃概率。 - conv_dim (
Tuple[int]或List[int], 可选, 默认为(512, 512, 512, 512, 512, 512, 512)) — 一个整数元组,定义了特征编码器中每个1D卷积层的输入和输出通道数。conv_dim 的长度定义了1D卷积层的数量。 - conv_stride (
Tuple[int]或List[int], 可选, 默认为(5, 2, 2, 2, 2, 2, 2)) — 一个整数元组,定义了特征编码器中每个一维卷积层的步幅。conv_stride 的长度定义了卷积层的数量,并且必须与 conv_dim 的长度匹配。 - conv_kernel (
Tuple[int]或List[int], 可选, 默认为(10, 3, 3, 3, 3, 3, 3)) — 一个整数元组,定义了特征编码器中每个一维卷积层的卷积核大小。conv_kernel 的长度定义了卷积层的数量,并且必须与 conv_dim 的长度匹配。 - conv_bias (
bool, optional, defaults toFalse) — 1D卷积层是否具有偏置。 - num_conv_pos_embeddings (
int, 可选, 默认为 128) — 卷积位置嵌入的数量。定义了1D卷积位置嵌入层的核大小。 - num_conv_pos_embedding_groups (
int, optional, defaults to 16) — 1D卷积位置嵌入层的组数。 - do_stable_layer_norm (
bool, optional, defaults toFalse) — 是否应用Transformer编码器的稳定层归一化架构。do_stable_layer_norm is True对应于在注意力层之前应用层归一化,而do_stable_layer_norm is False对应于在注意力层之后应用层归一化。 - apply_spec_augment (
bool, 可选, 默认为True) — 是否对特征编码器的输出应用SpecAugment数据增强。有关参考,请参见 SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. - mask_time_prob (
float, optional, 默认为 0.05) — 沿时间轴的所有特征向量将被掩码的百分比(介于 0 和 1 之间)。掩码过程会生成 ”mask_time_problen(time_axis)/mask_time_length” 个独立的掩码覆盖该轴。如果从每个特征向量被选为要掩码的向量跨度的起始点的概率来推理,mask_time_prob 应为 `prob_vector_startmask_time_length。请注意,重叠可能会减少实际被掩码的向量的百分比。这仅在apply_spec_augment 为 True` 时相关。 - mask_time_length (
int, optional, 默认为 10) — 沿时间轴的向量跨度长度。 - mask_time_min_masks (
int, 可选, 默认为 2), — 每次时间步长生成的最小掩码数量,长度为mask_feature_length,与mask_feature_prob无关。仅在“mask_time_prob*len(time_axis)/mask_time_length < mask_time_min_masks”时相关 - mask_feature_prob (
float, optional, 默认为 0.0) — 所有特征向量沿特征轴将被掩码的百分比(介于 0 和 1 之间)。掩码过程生成“mask_feature_problen(feature_axis)/mask_time_length”个独立的掩码覆盖该轴。如果从每个特征向量被选为要掩码的向量跨度的起始点的概率来推理,mask_feature_prob 应为 `prob_vector_startmask_feature_length。请注意,重叠可能会减少实际被掩码的向量的百分比。这仅在apply_spec_augment 为 True` 时相关。 - mask_feature_length (
int, optional, defaults to 10) — 沿特征轴的向量跨度长度。 - mask_feature_min_masks (
int, 可选, 默认为 0), — 每次时间步长生成的长度为mask_feature_length的最小掩码数量,与mask_feature_prob无关。仅在 ”mask_feature_prob*len(feature_axis)/mask_feature_length < mask_feature_min_masks” 时相关 - num_codevectors_per_group (
int, optional, defaults to 320) — 每个量化码本(组)中的条目数。 - num_codevector_groups (
int, 可选, 默认为 2) — 用于产品码向量量化的码向量组数量。 - contrastive_logits_temperature (
float, optional, 默认为 0.1) — 对比损失中的温度 kappa. - feat_quantizer_dropout (
float, 可选, 默认为 0.0) — 用于量化器的特征编码器输出的丢弃概率。 - num_negatives (
int, optional, defaults to 100) — 对比损失的负样本数量。 - codevector_dim (
int, optional, defaults to 256) — 量化特征向量的维度。 - proj_codevector_dim (
int, optional, 默认为 256) — 量化特征和变压器特征的最终投影的维度。 - diversity_loss_weight (
int, optional, defaults to 0.1) — 代码书多样性损失组件的权重。 - ctc_loss_reduction (
str, 可选, 默认为"sum") — 指定应用于torch.nn.CTCLoss输出的减少方式。仅在训练Wav2Vec2ForCTC实例时相关。 - ctc_zero_infinity (
bool, 可选, 默认为False) — 是否将无限损失和torch.nn.CTCLoss的相关梯度归零。无限损失主要发生在输入太短无法与目标对齐时。仅在训练Wav2Vec2ForCTC实例时相关。 - use_weighted_layer_sum (
bool, 可选, 默认为False) — 是否使用带有学习权重的层输出的加权平均。仅在使用 Wav2Vec2ForSequenceClassification 实例时相关。 - classifier_proj_size (
int, optional, 默认为 256) — 分类前用于标记平均池化的投影维度. - tdnn_dim (
Tuple[int]或List[int], 可选, 默认为(512, 512, 512, 512, 1500)) — 一个整数元组,定义了XVector模型中TDNN模块的每个1D卷积层的输出通道数。tdnn_dim的长度定义了TDNN层的数量。 - tdnn_kernel (
Tuple[int]或List[int], 可选, 默认为(5, 3, 3, 1, 1)) — 一个整数元组,定义了XVector模型中TDNN模块的每个1D卷积层的核大小。tdnn_kernel的长度必须与tdnn_dim的长度匹配。 - tdnn_dilation (
Tuple[int]或List[int], 可选, 默认为(1, 2, 3, 1, 1)) — 一个整数元组,定义了XVector模型中TDNN模块的每个一维卷积层的扩张因子。tdnn_dilation的长度必须与tdnn_dim的长度匹配。 - xvector_output_dim (
int, optional, 默认为 512) — XVector 嵌入向量的维度。 - add_adapter (
bool, 可选, 默认为False) — 是否应该在Wav2Vec2编码器之上堆叠一个卷积网络。这对于为SpeechEncoderDecoder模型预热Wav2Vec2非常有用。 - adapter_kernel_size (
int, optional, 默认为 3) — 适配器网络中卷积层的核大小。仅在add_adapter is True时相关。 - adapter_stride (
int, 可选, 默认为 2) — 适配器网络中卷积层的步幅。仅在add_adapter 为 True时相关。 - num_adapter_layers (
int, 可选, 默认为 3) — 适配器网络中应使用的卷积层数。仅在add_adapter is True时相关。 - adapter_attn_dim (
int, 可选) — 在每个注意力块中使用的注意力适配器权重的维度。使用注意力适配器的模型示例是 facebook/mms-1b-all. - output_hidden_size (
int, optional) — 编码器输出层的维度。如果未定义,则默认为hidden-size。仅在add_adapter is True时相关。
这是用于存储Wav2Vec2Model配置的配置类。它用于根据指定的参数实例化一个Wav2Vec2模型,定义模型架构。使用默认值实例化配置将产生类似于facebook/wav2vec2-base-960h架构的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import Wav2Vec2Config, Wav2Vec2Model
>>> # Initializing a Wav2Vec2 facebook/wav2vec2-base-960h style configuration
>>> configuration = Wav2Vec2Config()
>>> # Initializing a model (with random weights) from the facebook/wav2vec2-base-960h style configuration
>>> model = Wav2Vec2Model(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configWav2Vec2CTCTokenizer
类 transformers.Wav2Vec2CTCTokenizer
< source >( vocab_file bos_token = '' eos_token = '' unk_token = '
参数
- vocab_file (
str) — 包含词汇表的文件。 - bos_token (
str, optional, defaults to") — 句子的开始标记。" - eos_token (
str, optional, defaults to"") — 句子的结束标记。 - unk_token (
str, optional, defaults to") — 未知标记。不在词汇表中的标记无法转换为ID,而是设置为这个标记。" - pad_token (
str, optional, defaults to") — 用于填充的标记,例如在对不同长度的序列进行批处理时使用。" - word_delimiter_token (
str, 可选, 默认为"|") — 用于定义单词结束的标记。 - do_lower_case (
bool, 可选, 默认为False) — 是否接受小写输入并在解码时将输出转换为小写。 - target_lang (
str, optional) — 分词器应默认设置的目标语言。target_lang必须为多语言、嵌套词汇表(如 facebook/mms-1b-all)定义。 - **kwargs — 传递给PreTrainedTokenizer的额外关键字参数
构建一个Wav2Vec2CTC分词器。
这个分词器继承自PreTrainedTokenizer,其中包含了一些主要方法。用户应参考超类以获取有关这些方法的更多信息。
__call__
< source >( text: typing.Union[str, typing.List[str], typing.List[typing.List[str]]] = None text_pair: typing.Union[str, typing.List[str], typing.List[typing.List[str]], NoneType] = None text_target: typing.Union[str, typing.List[str], typing.List[typing.List[str]]] = None text_pair_target: typing.Union[str, typing.List[str], typing.List[typing.List[str]], NoneType] = None add_special_tokens: bool = True padding: typing.Union[bool, str, transformers.utils.generic.PaddingStrategy] = False truncation: typing.Union[bool, str, transformers.tokenization_utils_base.TruncationStrategy] = None max_length: typing.Optional[int] = None stride: int = 0 is_split_into_words: bool = False pad_to_multiple_of: typing.Optional[int] = None padding_side: typing.Optional[bool] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None return_token_type_ids: typing.Optional[bool] = None return_attention_mask: typing.Optional[bool] = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True **kwargs ) → BatchEncoding
参数
- text (
str,List[str],List[List[str]], optional) — 要编码的序列或序列批次。每个序列可以是一个字符串或一个字符串列表(预分词的字符串)。如果序列以字符串列表(预分词)的形式提供,你必须设置is_split_into_words=True(以消除与序列批次的歧义)。 - text_pair (
str,List[str],List[List[str]], optional) — 要编码的序列或序列批次。每个序列可以是一个字符串或一个字符串列表(预分词的字符串)。如果序列以字符串列表(预分词)的形式提供,你必须设置is_split_into_words=True(以消除与序列批次的歧义)。 - text_target (
str,List[str],List[List[str]], 可选) — 要编码为目标文本的序列或序列批次。每个序列可以是一个字符串或一个字符串列表(预分词的字符串)。如果序列以字符串列表(预分词)的形式提供,你必须设置is_split_into_words=True(以消除与序列批次的歧义)。 - text_pair_target (
str,List[str],List[List[str]], optional) — 要编码为目标文本的序列或序列批次。每个序列可以是一个字符串或一个字符串列表(预分词的字符串)。如果序列以字符串列表(预分词)的形式提供,你必须设置is_split_into_words=True(以消除与序列批次的歧义)。 - add_special_tokens (
bool, optional, defaults toTrue) — 是否在编码序列时添加特殊标记。这将使用底层的PretrainedTokenizerBase.build_inputs_with_special_tokens函数,该函数定义了哪些标记会自动添加到输入ID中。如果您想自动添加bos或eos标记,这将非常有用。 - padding (
bool,stror PaddingStrategy, optional, defaults toFalse) — Activates and controls padding. Accepts the following values:Trueor'longest': Pad to the longest sequence in the batch (or no padding if only a single sequence if provided).'max_length': Pad to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided.Falseor'do_not_pad'(default): No padding (i.e., can output a batch with sequences of different lengths).
- truncation (
bool,stror TruncationStrategy, optional, defaults toFalse) — Activates and controls truncation. Accepts the following values:Trueor'longest_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will truncate token by token, removing a token from the longest sequence in the pair if a pair of sequences (or a batch of pairs) is provided.'only_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the first sequence of a pair if a pair of sequences (or a batch of pairs) is provided.'only_second': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the second sequence of a pair if a pair of sequences (or a batch of pairs) is provided.Falseor'do_not_truncate'(default): No truncation (i.e., can output batch with sequence lengths greater than the model maximum admissible input size).
- max_length (
int, optional) — Controls the maximum length to use by one of the truncation/padding parameters.如果未设置或设置为
None,则在需要截断/填充参数时,将使用预定义的模型最大长度。如果模型没有特定的最大输入长度(如XLNet),则截断/填充到最大长度的功能将被停用。 - stride (
int, 可选, 默认为 0) — 如果与max_length一起设置为一个数字,当return_overflowing_tokens=True时返回的溢出标记将包含来自截断序列末尾的一些标记,以提供截断序列和溢出序列之间的一些重叠。此参数的值定义了重叠标记的数量。 - is_split_into_words (
bool, 可选, 默认为False) — 输入是否已经预分词(例如,分割成单词)。如果设置为True,分词器会假设输入已经分割成单词(例如,通过空格分割),然后进行分词。这对于NER或分词分类非常有用。 - pad_to_multiple_of (
int, 可选) — 如果设置,将序列填充到提供的值的倍数。需要激活padding。 这对于在计算能力>= 7.5(Volta)的NVIDIA硬件上启用Tensor Cores特别有用。 - padding_side (
str, optional) — 模型应在哪一侧应用填充。应在['right', 'left']之间选择。 默认值从同名的类属性中选取。 - return_tensors (
str或 TensorType, 可选) — 如果设置,将返回张量而不是Python整数列表。可接受的值有:'tf': 返回 TensorFlowtf.constant对象。'pt': 返回 PyTorchtorch.Tensor对象。'np': 返回 Numpynp.ndarray对象。
- return_token_type_ids (
bool, optional) — Whether to return token type IDs. If left to the default, will return the token type IDs according to the specific tokenizer’s default, defined by thereturn_outputsattribute. - return_attention_mask (
bool, optional) — Whether to return the attention mask. If left to the default, will return the attention mask according to the specific tokenizer’s default, defined by thereturn_outputsattribute. - return_overflowing_tokens (
bool, optional, defaults toFalse) — 是否返回溢出的标记序列。如果提供了一对输入ID序列(或一批对)并且使用了truncation_strategy = longest_first或True,则会引发错误而不是返回溢出的标记。 - return_special_tokens_mask (
bool, optional, defaults toFalse) — 是否返回特殊令牌掩码信息。 - return_offsets_mapping (
bool, optional, defaults toFalse) — Whether or not to return(char_start, char_end)for each token.这仅在继承自PreTrainedTokenizerFast的快速分词器上可用,如果使用Python的分词器,此方法将引发
NotImplementedError。 - return_length (
bool, 可选, 默认为False) — 是否返回编码输入的长度。 - verbose (
bool, optional, defaults toTrue) — 是否打印更多信息和警告。 - **kwargs — 传递给
self.tokenize()方法
一个BatchEncoding包含以下字段:
-
input_ids — 要输入模型的令牌ID列表。
-
token_type_ids — 要输入模型的令牌类型ID列表(当
return_token_type_ids=True或 如果“token_type_ids”在self.model_input_names中)。 -
attention_mask — 指定模型应关注哪些令牌的索引列表(当
return_attention_mask=True或如果“attention_mask”在self.model_input_names中)。 -
overflowing_tokens — 溢出令牌序列列表(当指定了
max_length并且return_overflowing_tokens=True)。 -
num_truncated_tokens — 截断的令牌数量(当指定了
max_length并且return_overflowing_tokens=True)。 -
special_tokens_mask — 0和1的列表,1表示添加的特殊令牌,0表示 常规序列令牌(当
add_special_tokens=True和return_special_tokens_mask=True)。 -
length — 输入的长度(当
return_length=True)
主要方法,用于将一个或多个序列或一个或多个序列对进行标记化并准备供模型使用。
解码
< source >( token_ids: typing.Union[int, typing.List[int], ForwardRef('np.ndarray'), ForwardRef('torch.Tensor'), ForwardRef('tf.Tensor')] skip_special_tokens: bool = False clean_up_tokenization_spaces: bool = None output_char_offsets: bool = False output_word_offsets: bool = False **kwargs ) → str 或 Wav2Vec2CTCTokenizerOutput
参数
- token_ids (
Union[int, List[int], np.ndarray, torch.Tensor, tf.Tensor]) — 标记化的输入ID列表。可以使用__call__方法获取。 - skip_special_tokens (
bool, optional, defaults toFalse) — 是否在解码过程中移除特殊标记。 - clean_up_tokenization_spaces (
bool, optional) — 是否清理分词后的空格。 - output_char_offsets (
bool, optional, defaults toFalse) — Whether or not to output character offsets. Character offsets can be used in combination with the sampling rate and model downsampling rate to compute the time-stamps of transcribed characters.请查看下面的示例,以更好地理解如何使用
output_char_offsets。 - output_word_offsets (
bool, optional, defaults toFalse) — Whether or not to output word offsets. Word offsets can be used in combination with the sampling rate and model downsampling rate to compute the time-stamps of transcribed words.请查看下面的示例,以更好地理解如何使用
output_word_offsets。 - kwargs (额外的关键字参数, 可选) — 将被传递给底层模型的特定解码方法.
返回
str 或 Wav2Vec2CTCTokenizerOutput
解码后的句子列表。当output_char_offsets == True或output_word_offsets == True时,将是一个Wav2Vec2CTCTokenizerOutput。
使用分词器和词汇表将字符串中的ID序列转换为文本,可选择移除特殊标记并清理分词空格。
类似于执行 self.convert_tokens_to_string(self.convert_ids_to_tokens(token_ids))。
示例:
>>> # Let's see how to retrieve time steps for a model
>>> from transformers import AutoTokenizer, AutoFeatureExtractor, AutoModelForCTC
>>> from datasets import load_dataset
>>> import datasets
>>> import torch
>>> # import model, feature extractor, tokenizer
>>> model = AutoModelForCTC.from_pretrained("facebook/wav2vec2-base-960h")
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/wav2vec2-base-960h")
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base-960h")
>>> # load first sample of English common_voice
>>> dataset = load_dataset("mozilla-foundation/common_voice_11_0", "en", split="train", streaming=True, trust_remote_code=True)
>>> dataset = dataset.cast_column("audio", datasets.Audio(sampling_rate=16_000))
>>> dataset_iter = iter(dataset)
>>> sample = next(dataset_iter)
>>> # forward sample through model to get greedily predicted transcription ids
>>> input_values = feature_extractor(sample["audio"]["array"], return_tensors="pt").input_values
>>> logits = model(input_values).logits[0]
>>> pred_ids = torch.argmax(logits, axis=-1)
>>> # retrieve word stamps (analogous commands for `output_char_offsets`)
>>> outputs = tokenizer.decode(pred_ids, output_word_offsets=True)
>>> # compute `time_offset` in seconds as product of downsampling ratio and sampling_rate
>>> time_offset = model.config.inputs_to_logits_ratio / feature_extractor.sampling_rate
>>> word_offsets = [
... {
... "word": d["word"],
... "start_time": round(d["start_offset"] * time_offset, 2),
... "end_time": round(d["end_offset"] * time_offset, 2),
... }
... for d in outputs.word_offsets
... ]
>>> # compare word offsets with audio `en_train_0/common_voice_en_19121553.mp3` online on the dataset viewer:
>>> # https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0/viewer/en
>>> word_offsets[:3]
[{'word': 'THE', 'start_time': 0.7, 'end_time': 0.78}, {'word': 'TRICK', 'start_time': 0.88, 'end_time': 1.08}, {'word': 'APPEARS', 'start_time': 1.2, 'end_time': 1.64}]batch_decode
< source >( sequences: typing.Union[typing.List[int], typing.List[typing.List[int]], ForwardRef('np.ndarray'), ForwardRef('torch.Tensor'), ForwardRef('tf.Tensor')] skip_special_tokens: bool = False clean_up_tokenization_spaces: bool = None output_char_offsets: bool = False output_word_offsets: bool = False **kwargs ) → List[str] 或 Wav2Vec2CTCTokenizerOutput
参数
- sequences (
Union[List[int], List[List[int]], np.ndarray, torch.Tensor, tf.Tensor]) — 标记化输入ID的列表。可以使用__call__方法获取。 - skip_special_tokens (
bool, optional, defaults toFalse) — 是否在解码过程中移除特殊标记。 - clean_up_tokenization_spaces (
bool, optional) — 是否清理分词空格。 - output_char_offsets (
bool, optional, defaults toFalse) — Whether or not to output character offsets. Character offsets can be used in combination with the sampling rate and model downsampling rate to compute the time-stamps of transcribed characters.请查看decode()的示例,以更好地理解如何使用
output_char_offsets。batch_decode()在处理批处理输出时的工作方式相同。 - output_word_offsets (
bool, optional, defaults toFalse) — Whether or not to output word offsets. Word offsets can be used in combination with the sampling rate and model downsampling rate to compute the time-stamps of transcribed words.请查看decode()的示例,以更好地理解如何使用
output_word_offsets。batch_decode()在处理批处理输出时的工作方式相同。 - kwargs (额外的关键字参数,可选) — 将被传递给底层模型的特定解码方法。
返回
List[str] 或 Wav2Vec2CTCTokenizerOutput
解码后的句子列表。当output_char_offsets == True或output_word_offsets == True时,将是一个Wav2Vec2CTCTokenizerOutput。
通过调用decode将token id的列表列表转换为字符串列表。
设置嵌套多语言字典的目标语言
Wav2Vec2FeatureExtractor
类 transformers.Wav2Vec2FeatureExtractor
< source >( feature_size = 1 sampling_rate = 16000 padding_value = 0.0 return_attention_mask = False do_normalize = True **kwargs )
参数
- feature_size (
int, optional, defaults to 1) — 提取特征的特征维度。 - sampling_rate (
int, optional, defaults to 16000) — 音频文件应被数字化的采样率,以赫兹(Hz)表示。 - padding_value (
float, 可选, 默认为 0.0) — 用于填充填充值的值。 - do_normalize (
bool, 可选, 默认为True) — 是否对输入进行零均值单位方差归一化。归一化可以显著提高某些模型的性能,例如, wav2vec2-lv60. - return_attention_mask (
bool, optional, defaults toFalse) — Whether or not call() should returnattention_mask.设置了
config.feat_extract_norm == "group"的Wav2Vec2模型,例如 wav2vec2-base,没有使用attention_mask进行训练。对于这些模型,input_values应该简单地用0填充,并且不应该传递attention_mask。对于设置了
config.feat_extract_norm == "layer"的Wav2Vec2模型,例如 wav2vec2-lv60,attention_mask应该 在批量推理时传递。
构建一个Wav2Vec2特征提取器。
此特征提取器继承自SequenceFeatureExtractor,其中包含 大部分主要方法。用户应参考此超类以获取有关这些方法的更多信息。
__call__
< source >( raw_speech: typing.Union[numpy.ndarray, typing.List[float], typing.List[numpy.ndarray], typing.List[typing.List[float]]] padding: typing.Union[bool, str, transformers.utils.generic.PaddingStrategy] = False max_length: typing.Optional[int] = None truncation: bool = False pad_to_multiple_of: typing.Optional[int] = None return_attention_mask: typing.Optional[bool] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None sampling_rate: typing.Optional[int] = None **kwargs )
参数
- raw_speech (
np.ndarray,List[float],List[np.ndarray],List[List[float]]) — 要填充的序列或序列批次。每个序列可以是一个numpy数组、一个浮点值列表、一个numpy数组列表或一个浮点值列表的列表。必须是单声道音频,而不是立体声,即每个时间步长只有一个浮点数。 - padding (
bool,stror PaddingStrategy, optional, defaults toFalse) — Select a strategy to pad the returned sequences (according to the model’s padding side and padding index) among:Trueor'longest': Pad to the longest sequence in the batch (or no padding if only a single sequence if provided).'max_length': Pad to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided.Falseor'do_not_pad'(default): No padding (i.e., can output a batch with sequences of different lengths).
- max_length (
int, optional) — 返回列表的最大长度以及可选的填充长度(见上文)。 - 截断 (
bool) — 激活截断功能,将超过max_length的输入序列截断至max_length. - pad_to_multiple_of (
int, optional) — If set will pad the sequence to a multiple of the provided value.这对于在计算能力
>= 7.5(Volta)的NVIDIA硬件上启用Tensor Cores特别有用,或者对于TPUs来说,序列长度为128的倍数是有益的。 - return_attention_mask (
bool, optional) — Whether to return the attention mask. If left to the default, will return the attention mask according to the specific feature_extractor’s default.设置了
config.feat_extract_norm == "group"的Wav2Vec2模型,例如 wav2vec2-base,没有使用attention_mask进行训练。对于这些模型,input_values应该简单地用0填充,并且不应该传递attention_mask。对于设置了
config.feat_extract_norm == "layer"的Wav2Vec2模型,例如 wav2vec2-lv60,attention_mask应该 在批量推理时传递。 - return_tensors (
str或 TensorType, 可选) — 如果设置,将返回张量而不是Python整数列表。可接受的值有:'tf': 返回 TensorFlowtf.constant对象。'pt': 返回 PyTorchtorch.Tensor对象。'np': 返回 Numpynp.ndarray对象。
- sampling_rate (
int, optional) —raw_speech输入被采样的采样率。强烈建议在前向调用时传递sampling_rate以防止静默错误。 - padding_value (
float, 可选, 默认值为 0.0) —
用于特征化并为一个或多个序列准备模型的主要方法。
Wav2Vec2Processor
类 transformers.Wav2Vec2Processor
< source >( feature_extractor tokenizer )
参数
- feature_extractor (
Wav2Vec2FeatureExtractor) — 一个 Wav2Vec2FeatureExtractor 的实例。特征提取器是一个必需的输入。 - tokenizer (PreTrainedTokenizer) — 一个 PreTrainedTokenizer 的实例。tokenizer 是一个必需的输入。
构建一个Wav2Vec2处理器,它将Wav2Vec2特征提取器和Wav2Vec2 CTC分词器封装到一个单一的处理器中。
Wav2Vec2Processor 提供了 Wav2Vec2FeatureExtractor 和 PreTrainedTokenizer 的所有功能。 有关更多信息,请参阅 call() 和 decode() 的文档字符串。
__call__
< source >( audio: typing.Union[ForwardRef('np.ndarray'), ForwardRef('torch.Tensor'), typing.List[ForwardRef('np.ndarray')], typing.List[ForwardRef('torch.Tensor')]] = None text: typing.Union[str, typing.List[str], NoneType] = None images = None videos = None **kwargs: typing_extensions.Unpack[transformers.models.wav2vec2.processing_wav2vec2.Wav2Vec2ProcessorKwargs] )
在正常模式下使用时,此方法会将其所有参数转发给Wav2Vec2FeatureExtractor的
call()并返回其输出。如果在
as_target_processor()上下文中使用,此方法会将其所有参数转发给PreTrainedTokenizer的
call()。请参考上述两种方法的文档字符串以获取更多信息。
在正常模式下使用时,此方法会将其所有参数转发给Wav2Vec2FeatureExtractor的
pad() 并返回其输出。如果在
as_target_processor() 上下文中使用,此方法会将其所有参数转发给PreTrainedTokenizer的
pad()。请参考上述两种方法的文档字符串以获取更多信息。
save_pretrained
< source >( save_directory push_to_hub: bool = False **kwargs )
参数
- save_directory (
stroros.PathLike) — 保存特征提取器 JSON 文件和分词器文件的目录(如果目录不存在,将会创建)。 - push_to_hub (
bool, 可选, 默认为False) — 是否在保存后将你的模型推送到 Hugging Face 模型中心。你可以通过repo_id指定你想要推送到的仓库(默认情况下会使用你命名空间中的save_directory名称)。 - kwargs (
Dict[str, Any], 可选) — 传递给 push_to_hub() 方法的额外关键字参数。
保存此处理器(特征提取器、分词器等)的属性到指定目录,以便可以使用from_pretrained()方法重新加载。
这个类方法只是调用了 save_pretrained() 和 save_pretrained()。请参考上述方法的文档字符串以获取更多信息。
此方法将其所有参数转发给PreTrainedTokenizer的batch_decode()。请参考该方法的文档字符串以获取更多信息。
此方法将其所有参数转发给PreTrainedTokenizer的decode()。请参考该方法的文档字符串以获取更多信息。
Wav2Vec2ProcessorWithLM
类 transformers.Wav2Vec2ProcessorWithLM
< source >( feature_extractor: FeatureExtractionMixin tokenizer: PreTrainedTokenizerBase decoder: BeamSearchDecoderCTC )
参数
- feature_extractor (Wav2Vec2FeatureExtractor 或 SeamlessM4TFeatureExtractor) — Wav2Vec2FeatureExtractor 或 SeamlessM4TFeatureExtractor 的实例。特征提取器是一个必需的输入。
- tokenizer (Wav2Vec2CTCTokenizer) — 一个 Wav2Vec2CTCTokenizer 的实例。tokenizer 是一个必需的输入。
- 解码器 (
pyctcdecode.BeamSearchDecoderCTC) —pyctcdecode.BeamSearchDecoderCTC的一个实例。解码器是一个必需的输入。
构建一个Wav2Vec2处理器,该处理器将Wav2Vec2特征提取器、Wav2Vec2 CTC分词器和带有语言模型支持的解码器封装到一个处理器中,用于语言模型增强的语音识别解码。
在正常模式下使用时,此方法会将其所有参数转发给特征提取器的__call__()并返回其输出。如果在as_target_processor()上下文中使用,此方法会将其所有参数转发给Wav2Vec2CTCTokenizer的call()。请参考上述两个方法的文档字符串以获取更多信息。
在正常模式下使用时,此方法会将其所有参数转发给特征提取器的~FeatureExtractionMixin.pad并返回其输出。如果在as_target_processor()上下文中使用,此方法会将其所有参数转发给Wav2Vec2CTCTokenizer的pad()。请参考上述两种方法的文档字符串以获取更多信息。
from_pretrained
< source >( pretrained_model_name_or_path **kwargs )
参数
- pretrained_model_name_or_path (
str或os.PathLike) — 这可以是以下之一:- 一个字符串,表示托管在 huggingface.co 上的模型仓库中的预训练特征提取器的 模型 id。
- 一个路径,指向使用 save_pretrained() 方法保存的特征提取器文件的 目录,例如
./my_model_directory/。 - 一个路径或 URL,指向保存的特征提取器 JSON 文件,例如
./my_model_directory/preprocessor_config.json。
- **kwargs — 传递给SequenceFeatureExtractor和 PreTrainedTokenizer的额外关键字参数
从预训练的Wav2Vec2处理器实例化一个Wav2Vec2ProcessorWithLM。
这个类方法只是调用了特征提取器的
from_pretrained(),Wav2Vec2CTCTokenizer的
from_pretrained(),以及
pyctcdecode.BeamSearchDecoderCTC.load_from_hf_hub。
请参考上述方法的文档字符串以获取更多信息。
batch_decode
< source >( logits: ndarray pool: typing.Optional[
参数
- logits (
np.ndarray) — 模型输出的logits向量,表示每个token的对数概率。 - pool (
multiprocessing.Pool, optional) — An optional user-managed pool. If not set, one will be automatically created and closed. The pool should be instantiated afterWav2Vec2ProcessorWithLM. Otherwise, the LM won’t be available to the pool’s sub-processes.目前,只能使用通过“fork”上下文创建的池。如果传递了“spawn”池,它将被忽略,并改用顺序解码。
- num_processes (
int, optional) — 如果未设置pool,则函数应并行化的进程数。默认为可用CPU的数量。 - beam_width (
int, 可选) — 解码过程中每一步的最大光束数。默认为 pyctcdecode 的 DEFAULT_BEAM_WIDTH. - beam_prune_logp (
int, optional) — 比最佳beam差很多的beam将被修剪 默认为pyctcdecode的DEFAULT_PRUNE_LOGP. - token_min_logp (
int, 可选) — 低于此logp的标记将被跳过,除非它们是帧的argmax。默认为pyctcdecode的 DEFAULT_MIN_TOKEN_LOGP. - hotwords (
List[str], optional) — 具有额外重要性的单词列表,对于LM可以是OOV - hotword_weight (
int, optional) — 热词重要性的权重因子,默认为 pyctcdecode 的 DEFAULT_HOTWORD_WEIGHT. - alpha (
float, optional) — 浅融合期间语言模型的权重 - beta (
float, 可选) — 在评分过程中用于调整长度得分的权重 - unk_score_offset (
float, optional) — 未知标记的日志分数偏移量 - lm_score_boundary (
bool, optional) — 是否让kenlm在评分时尊重边界 - output_word_offsets (
bool, optional, 默认为False) — 是否输出单词偏移量。单词偏移量可以与采样率和模型下采样率结合使用,以计算转录单词的时间戳。 - n_best (
int, optional, defaults to1) — Number of best hypotheses to return. Ifn_bestis greater than 1, the returnedtextwill be a list of lists of strings,logit_scorewill be a list of lists of floats, andlm_scorewill be a list of lists of floats, where the length of the outer list will correspond to the batch size and the length of the inner list will correspond to the number of returned hypotheses . The value should be >= 1.请查看decode()的示例,以更好地理解如何使用
output_word_offsets。batch_decode()以相同的方式处理批量输出。
批量解码输出logits为音频转录,支持语言模型。
此函数利用了Python的多进程处理功能。目前,多进程处理仅在Unix系统上可用(参见此问题)。
如果你正在解码多个批次,考虑创建一个Pool并将其传递给batch_decode。否则,batch_decode将会非常慢,因为它会为每次调用创建一个新的Pool。请参见下面的使用示例。
示例: 参见 解码多个音频。
解码
< source >( logits: ndarray beam_width: typing.Optional[int] = None beam_prune_logp: typing.Optional[float] = None token_min_logp: typing.Optional[float] = None hotwords: typing.Optional[typing.Iterable[str]] = None hotword_weight: typing.Optional[float] = None alpha: typing.Optional[float] = None beta: typing.Optional[float] = None unk_score_offset: typing.Optional[float] = None lm_score_boundary: typing.Optional[bool] = None output_word_offsets: bool = False n_best: int = 1 )
参数
- logits (
np.ndarray) — 模型输出的logits向量,表示每个token的对数概率。 - beam_width (
int, 可选) — 解码过程中每一步的最大光束数。默认为 pyctcdecode 的 DEFAULT_BEAM_WIDTH. - beam_prune_logp (
int, 可选) — 一个阈值,用于剪枝那些对数概率小于 best_beam_logp + beam_prune_logp 的 beams。该值应 <= 0。默认为 pyctcdecode 的 DEFAULT_PRUNE_LOGP. - token_min_logp (
int, 可选) — 如果令牌的对数概率低于 token_min_logp,则跳过这些令牌,除非它们是某个话语的最大对数概率。默认值为 pyctcdecode 的 DEFAULT_MIN_TOKEN_LOGP. - hotwords (
List[str], optional) — 具有额外重要性的单词列表,这些单词可能不在LM的词汇表中,例如 [“huggingface”] - hotword_weight (
int, optional) — 权重乘数,用于提升热词分数。默认为 pyctcdecode 的 DEFAULT_HOTWORD_WEIGHT. - alpha (
float, optional) — 浅融合期间语言模型的权重 - beta (
float, optional) — 在评分期间用于长度分数调整的权重 - unk_score_offset (
float, optional) — 未知标记的日志分数偏移量 - lm_score_boundary (
bool, optional) — 是否让kenlm在评分时尊重边界 - output_word_offsets (
bool, optional, defaults toFalse) — 是否输出单词偏移量。单词偏移量可以与采样率和模型下采样率结合使用,以计算转录单词的时间戳。 - n_best (
int, optional, defaults to1) — Number of best hypotheses to return. Ifn_bestis greater than 1, the returnedtextwill be a list of strings,logit_scorewill be a list of floats, andlm_scorewill be a list of floats, where the length of these lists will correspond to the number of returned hypotheses. The value should be >= 1.请查看下面的示例,以更好地理解如何使用
output_word_offsets。
使用语言模型支持将输出logits解码为音频转录。
示例:
>>> # Let's see how to retrieve time steps for a model
>>> from transformers import AutoTokenizer, AutoProcessor, AutoModelForCTC
>>> from datasets import load_dataset
>>> import datasets
>>> import torch
>>> # import model, feature extractor, tokenizer
>>> model = AutoModelForCTC.from_pretrained("patrickvonplaten/wav2vec2-base-100h-with-lm")
>>> processor = AutoProcessor.from_pretrained("patrickvonplaten/wav2vec2-base-100h-with-lm")
>>> # load first sample of English common_voice
>>> dataset = load_dataset("mozilla-foundation/common_voice_11_0", "en", split="train", streaming=True, trust_remote_code=True)
>>> dataset = dataset.cast_column("audio", datasets.Audio(sampling_rate=16_000))
>>> dataset_iter = iter(dataset)
>>> sample = next(dataset_iter)
>>> # forward sample through model to get greedily predicted transcription ids
>>> input_values = processor(sample["audio"]["array"], return_tensors="pt").input_values
>>> with torch.no_grad():
... logits = model(input_values).logits[0].cpu().numpy()
>>> # retrieve word stamps (analogous commands for `output_char_offsets`)
>>> outputs = processor.decode(logits, output_word_offsets=True)
>>> # compute `time_offset` in seconds as product of downsampling ratio and sampling_rate
>>> time_offset = model.config.inputs_to_logits_ratio / processor.feature_extractor.sampling_rate
>>> word_offsets = [
... {
... "word": d["word"],
... "start_time": round(d["start_offset"] * time_offset, 2),
... "end_time": round(d["end_offset"] * time_offset, 2),
... }
... for d in outputs.word_offsets
... ]
>>> # compare word offsets with audio `en_train_0/common_voice_en_19121553.mp3` online on the dataset viewer:
>>> # https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0/viewer/en
>>> word_offsets[:4]
[{'word': 'THE', 'start_time': 0.68, 'end_time': 0.78}, {'word': 'TRACK', 'start_time': 0.88, 'end_time': 1.1}, {'word': 'APPEARS', 'start_time': 1.18, 'end_time': 1.66}, {'word': 'ON', 'start_time': 1.86, 'end_time': 1.92}]解码多个音频
如果你计划解码多批音频,你应该考虑使用batch_decode()并传递一个实例化的multiprocessing.Pool。
否则,batch_decode()的性能将比单独调用decode()慢,因为它在每次调用时都会在内部实例化一个新的Pool。请参见以下示例:
>>> # Let's see how to use a user-managed pool for batch decoding multiple audios
>>> from multiprocessing import get_context
>>> from transformers import AutoTokenizer, AutoProcessor, AutoModelForCTC
>>> from datasets import load_dataset
>>> import datasets
>>> import torch
>>> # import model, feature extractor, tokenizer
>>> model = AutoModelForCTC.from_pretrained("patrickvonplaten/wav2vec2-base-100h-with-lm").to("cuda")
>>> processor = AutoProcessor.from_pretrained("patrickvonplaten/wav2vec2-base-100h-with-lm")
>>> # load example dataset
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> dataset = dataset.cast_column("audio", datasets.Audio(sampling_rate=16_000))
>>> def map_to_array(batch):
... batch["speech"] = batch["audio"]["array"]
... return batch
>>> # prepare speech data for batch inference
>>> dataset = dataset.map(map_to_array, remove_columns=["audio"])
>>> def map_to_pred(batch, pool):
... inputs = processor(batch["speech"], sampling_rate=16_000, padding=True, return_tensors="pt")
... inputs = {k: v.to("cuda") for k, v in inputs.items()}
... with torch.no_grad():
... logits = model(**inputs).logits
... transcription = processor.batch_decode(logits.cpu().numpy(), pool).text
... batch["transcription"] = transcription
... return batch
>>> # note: pool should be instantiated *after* `Wav2Vec2ProcessorWithLM`.
>>> # otherwise, the LM won't be available to the pool's sub-processes
>>> # select number of processes and batch_size based on number of CPU cores available and on dataset size
>>> with get_context("fork").Pool(processes=2) as pool:
... result = dataset.map(
... map_to_pred, batched=True, batch_size=2, fn_kwargs={"pool": pool}, remove_columns=["speech"]
... )
>>> result["transcription"][:2]
['MISTER QUILTER IS THE APOSTLE OF THE MIDDLE CLASSES AND WE ARE GLAD TO WELCOME HIS GOSPEL', "NOR IS MISTER COULTER'S MANNER LESS INTERESTING THAN HIS MATTER"]Wav2Vec2 特定输出
class transformers.models.wav2vec2_with_lm.processing_wav2vec2_with_lm.Wav2Vec2DecoderWithLMOutput
< source >( text: typing.Union[typing.List[typing.List[str]], typing.List[str], str] logit_score: typing.Union[typing.List[typing.List[float]], typing.List[float], float] = None lm_score: typing.Union[typing.List[typing.List[float]], typing.List[float], float] = None word_offsets: typing.Union[typing.List[typing.List[typing.List[typing.Dict[str, typing.Union[int, str]]]]], typing.List[typing.List[typing.Dict[str, typing.Union[int, str]]]], typing.List[typing.Dict[str, typing.Union[int, str]]]] = None )
Wav2Vec2DecoderWithLM的输出类型,带有转录。
类 transformers.modeling_outputs.Wav2Vec2BaseModelOutput
< source >( last_hidden_state: FloatTensor = None extract_features: FloatTensor = None hidden_states: typing.Optional[typing.Tuple[torch.FloatTensor, ...]] = None attentions: typing.Optional[typing.Tuple[torch.FloatTensor, ...]] = None )
参数
- last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。 - extract_features (
torch.FloatTensor形状为(batch_size, sequence_length, conv_dim[-1])) — 模型最后一个卷积层提取的特征向量序列。 - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).模型在每一层输出处的隐藏状态加上初始嵌入输出。
- attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).注意力权重在注意力softmax之后,用于计算自注意力头中的加权平均值。
使用Wav2Vec2损失目标训练的模型的基础类。
class transformers.models.wav2vec2.modeling_wav2vec2.Wav2Vec2ForPreTrainingOutput
< source >( loss: typing.Optional[torch.FloatTensor] = None projected_states: FloatTensor = None projected_quantized_states: FloatTensor = None codevector_perplexity: FloatTensor = None hidden_states: typing.Optional[typing.Tuple[torch.FloatTensor]] = None attentions: typing.Optional[typing.Tuple[torch.FloatTensor]] = None contrastive_loss: typing.Optional[torch.FloatTensor] = None diversity_loss: typing.Optional[torch.FloatTensor] = None )
参数
- loss (可选, 当传递
sample_negative_indices时返回,torch.FloatTensor形状为(1,)) — 总损失为对比损失 (L_m) 和多样性损失 (L_d) 的总和,如 官方论文 中所述。(分类) 损失. - projected_states (
torch.FloatTensorof shape(batch_size, sequence_length, config.proj_codevector_dim)) — 模型的隐藏状态投影到config.proj_codevector_dim,可用于预测被遮蔽的投影量化状态。 - projected_quantized_states (
torch.FloatTensorof shape(batch_size, sequence_length, config.proj_codevector_dim)) — 量化提取的特征向量投影到config.proj_codevector_dim,表示对比损失的正目标向量。 - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).模型在每一层输出处的隐藏状态加上初始嵌入输出。
- attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).注意力权重在注意力softmax之后,用于计算自注意力头中的加权平均值。
- contrastive_loss (可选, 当传递
sample_negative_indices时返回,torch.FloatTensor形状为(1,)) — 对比损失 (L_m) 如 官方论文 中所述. - diversity_loss (可选, 当传递
sample_negative_indices时返回,torch.FloatTensor形状为(1,)) — 在官方论文中所述的多样性损失 (L_d)。
Wav2Vec2ForPreTraining的输出类型,可能包含隐藏状态和注意力。
类 transformers.models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2BaseModelOutput
< source >( last_hidden_state: 数组 = 无 extract_features: 数组 = 无 hidden_states: typing.Optional[typing.Tuple[jax.Array]] = 无 attentions: typing.Optional[typing.Tuple[jax.Array]] = 无 )
参数
- last_hidden_state (
jnp.ndarrayof shape(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。 - extract_features (
jnp.ndarrayof shape(batch_size, sequence_length, last_conv_dim)) — 模型最后一个卷积层提取的特征向量序列,其中last_conv_dim是最后一个卷积层的维度。 - hidden_states (
tuple(jnp.ndarray), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple ofjnp.ndarray(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).模型在每一层输出处的隐藏状态加上初始嵌入输出。
- attentions (
tuple(jnp.ndarray), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple ofjnp.ndarray(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).注意力权重在注意力softmax之后,用于计算自注意力头中的加权平均值。
输出类型为 FlaxWav2Vec2BaseModelOutput,可能包含隐藏状态和注意力。
“返回一个新对象,用新值替换指定的字段。
类 transformers.models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2ForPreTrainingOutput
< source >( projected_states: 数组 = 无 projected_quantized_states: 数组 = 无 codevector_perplexity: 数组 = 无 hidden_states: typing.Optional[typing.Tuple[jax.Array]] = 无 attentions: typing.Optional[typing.Tuple[jax.Array]] = 无 )
参数
- loss (可选,当模型处于训练模式时返回,
jnp.ndarray形状为(1,)) — 总损失,即对比损失(L_m)和多样性损失(L_d)的总和,如官方论文所述。(分类)损失。 - projected_states (
jnp.ndarrayof shape(batch_size, sequence_length, config.proj_codevector_dim)) — 模型的隐藏状态投影到 config.proj_codevector_dim,可用于预测被遮蔽的投影量化状态。 - projected_quantized_states (
jnp.ndarrayof shape(batch_size, sequence_length, config.proj_codevector_dim)) — 量化提取的特征向量投影到config.proj_codevector_dim,表示对比损失的正目标向量。 - hidden_states (
tuple(jnp.ndarray), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple ofjnp.ndarray(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).模型在每一层输出处的隐藏状态加上初始嵌入输出。
- attentions (
tuple(jnp.ndarray), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple ofjnp.ndarray(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).注意力权重在注意力softmax之后,用于计算自注意力头中的加权平均值。
输出类型为 FlaxWav2Vec2ForPreTrainingOutput,可能包含隐藏状态和注意力。
“返回一个新对象,用新值替换指定的字段。
Wav2Vec2Model
类 transformers.Wav2Vec2Model
< source >( config: Wav2Vec2Config )
参数
- config (Wav2Vec2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸Wav2Vec2模型变压器输出原始隐藏状态,没有任何特定的头部。 Wav2Vec2由Alexei Baevski、Henry Zhou、Abdelrahman Mohamed和Michael Auli在wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations中提出。
该模型继承自 PreTrainedModel。请查看超类文档,了解库为其所有模型实现的通用方法(如下载或保存等)。
该模型是一个PyTorch torch.nn.Module 子类。将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_values: typing.Optional[torch.Tensor] attention_mask: typing.Optional[torch.Tensor] = None mask_time_indices: typing.Optional[torch.FloatTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.Wav2Vec2BaseModelOutput 或 tuple(torch.FloatTensor)
参数
- input_values (
torch.FloatTensorof shape(batch_size, sequence_length)) — 输入原始语音波形的浮点值。可以通过将.flac或.wav音频文件加载到List[float]类型的数组或numpy.ndarray中获取值,例如通过soundfile库(pip install soundfile)。要将数组准备为input_values,应使用AutoProcessor进行填充并转换为torch.FloatTensor类型的张量。有关详细信息,请参阅Wav2Vec2Processor.call()。 - attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
attention_mask只有在相应的处理器具有config.return_attention_mask == True时才应传递。对于所有处理器具有config.return_attention_mask == False的模型,例如 wav2vec2-base,attention_mask应 不 传递,以避免在进行批量推理时性能下降。对于这些模型,input_values应 简单地用 0 填充并传递,而不使用attention_mask。请注意,这些模型也会根据input_values是否填充而产生略微不同的结果。 - output_attentions (
bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。
返回
transformers.modeling_outputs.Wav2Vec2BaseModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.Wav2Vec2BaseModelOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(Wav2Vec2Config)和输入。
-
last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层的隐藏状态序列。 -
extract_features (
torch.FloatTensor形状为(batch_size, sequence_length, conv_dim[-1])) — 模型最后一个卷积层提取的特征向量序列。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,一个用于每一层的输出), 形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力权重在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
Wav2Vec2Model 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoProcessor, Wav2Vec2Model
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation", trust_remote_code=True)
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
>>> model = Wav2Vec2Model.from_pretrained("facebook/wav2vec2-base-960h")
>>> # audio file is decoded on the fly
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 292, 768]Wav2Vec2ForCTC
类 transformers.Wav2Vec2ForCTC
< source >( config target_lang: typing.Optional[str] = None )
参数
- config (Wav2Vec2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
- target_lang (
str, 可选) — 适配器权重的语言ID。适配器权重以adapter..safetensors或adapter. .bin的格式存储。仅在使用带有适配器的Wav2Vec2ForCTC实例时相关。默认使用‘eng’。
Wav2Vec2 模型,顶部带有语言建模头,用于连接时序分类(CTC)。
Wav2Vec2 是由 Alexei Baevski、Henry Zhou、Abdelrahman Mohamed 和 Michael Auli 在 wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations 中提出的。
该模型继承自 PreTrainedModel。请查看超类文档,了解库为其所有模型实现的通用方法(如下载或保存等)。
该模型是一个PyTorch torch.nn.Module 子类。将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_values: typing.Optional[torch.Tensor] attention_mask: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None labels: typing.Optional[torch.Tensor] = None ) → transformers.modeling_outputs.CausalLMOutput 或 tuple(torch.FloatTensor)
参数
- input_values (
torch.FloatTensorof shape(batch_size, sequence_length)) — 输入原始语音波形的浮点值。可以通过将.flac或.wav音频文件加载到List[float]类型的数组或numpy.ndarray中来获取值,例如通过soundfile库(pip install soundfile)。要将数组准备为input_values,应使用AutoProcessor进行填充并转换为torch.FloatTensor类型的张量。有关详细信息,请参阅Wav2Vec2Processor.call()。 - attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
attention_mask只有在相应的处理器具有config.return_attention_mask == True时才应传递。对于所有处理器具有config.return_attention_mask == False的模型,例如 wav2vec2-base,attention_mask应 不 传递,以避免在进行批量推理时性能下降。对于这些模型,input_values应 简单地用 0 填充并传递,而不使用attention_mask。请注意,这些模型也会根据input_values是否填充而产生略微不同的结果。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size, target_length), optional) — 用于连接时序分类的标签。注意target_length必须小于或等于输出 logits 的序列长度。索引在[-100, 0, ..., config.vocab_size - 1]中选择。 所有设置为-100的标签将被忽略(屏蔽),损失仅计算[0, ..., config.vocab_size - 1]中的标签。
返回
transformers.modeling_outputs.CausalLMOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.CausalLMOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(Wav2Vec2Config)和输入。
-
loss (
torch.FloatTensor形状为(1,), 可选, 当提供labels时返回) — 语言建模损失(用于下一个标记预测)。 -
logits (
torch.FloatTensor形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
Wav2Vec2ForCTC 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoProcessor, Wav2Vec2ForCTC
>>> from datasets import load_dataset
>>> import torch
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation", trust_remote_code=True)
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
>>> model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h")
>>> # audio file is decoded on the fly
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_ids = torch.argmax(logits, dim=-1)
>>> # transcribe speech
>>> transcription = processor.batch_decode(predicted_ids)
>>> transcription[0]
'MISTER QUILTER IS THE APOSTLE OF THE MIDDLE CLASSES AND WE ARE GLAD TO WELCOME HIS GOSPEL'
>>> inputs["labels"] = processor(text=dataset[0]["text"], return_tensors="pt").input_ids
>>> # compute loss
>>> loss = model(**inputs).loss
>>> round(loss.item(), 2)
53.48load_adapter
< source >( target_lang: str force_load = True **kwargs )
参数
- target_lang (
str) — 必须是现有适配器权重的语言ID。适配器权重以adapter..safetensors或adapter. .bin的格式存储 - force_load (
bool, 默认为True) — 是否应加载权重,即使target_lang与self.target_lang匹配。 - cache_dir (
Union[str, os.PathLike], 可选) — 如果不应使用标准缓存,则应缓存下载的预训练模型配置的目录路径。 - force_download (
bool, 可选, 默认为False) — 是否强制(重新)下载模型权重和配置文件,覆盖已存在的缓存版本。 - resume_download — 已弃用并被忽略。现在默认情况下,所有下载在可能的情况下都会自动恢复。 将在Transformers的v5版本中移除。
- proxies (
Dict[str, str], 可选) — 一个按协议或端点使用的代理服务器字典,例如{'http': 'foo.bar:3128', 'http://hostname': 'foo.bar:4012'}。这些代理在每个请求中使用。 - local_files_only(
bool, 可选, 默认为False) — 是否仅查看本地文件(即不尝试下载模型)。 - token (
str或bool, 可选) — 用于远程文件的HTTP承载授权的令牌。如果为True或未指定,将使用运行huggingface-cli login时生成的令牌(存储在~/.huggingface中)。 - revision (
str, optional, defaults to"main") — The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a git-based system for storing models and other artifacts on huggingface.co, sorevisioncan be any identifier allowed by git.要测试你在Hub上提交的拉取请求,你可以传递
revision="refs/pr/。" - 镜像 (
str, 可选) — 镜像源以加速在中国的下载。如果您来自中国并且遇到访问问题,可以设置此选项来解决。请注意,我们不保证及时性或安全性。 请参考镜像站点以获取更多信息。
从预训练的适配器模型加载语言适配器模型。
激活特殊的“离线模式”以在防火墙环境中使用此方法。
示例:
>>> from transformers import Wav2Vec2ForCTC, AutoProcessor
>>> ckpt = "facebook/mms-1b-all"
>>> processor = AutoProcessor.from_pretrained(ckpt)
>>> model = Wav2Vec2ForCTC.from_pretrained(ckpt, target_lang="eng")
>>> # set specific language
>>> processor.tokenizer.set_target_lang("spa")
>>> model.load_adapter("spa")Wav2Vec2ForSequenceClassification
类 transformers.Wav2Vec2ForSequenceClassification
< source >( config )
参数
- config (Wav2Vec2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
Wav2Vec2 模型,顶部带有序列分类头(在池化输出上的线性层),用于诸如 SUPERB 关键词检测等任务。
Wav2Vec2 是由 Alexei Baevski、Henry Zhou、Abdelrahman Mohamed 和 Michael Auli 在 wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations 中提出的。
该模型继承自 PreTrainedModel。请查看超类文档,了解库为其所有模型实现的通用方法(如下载或保存等)。
该模型是一个PyTorch torch.nn.Module 子类。将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_values: typing.Optional[torch.Tensor] attention_mask: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None labels: typing.Optional[torch.Tensor] = None ) → transformers.modeling_outputs.SequenceClassifierOutput 或 tuple(torch.FloatTensor)
参数
- input_values (
torch.FloatTensorof shape(batch_size, sequence_length)) — 输入原始语音波形的浮点值。可以通过将.flac或.wav音频文件加载到List[float]类型的数组或numpy.ndarray中来获取值,例如通过soundfile库(pip install soundfile)。要将数组准备为input_values,应使用AutoProcessor进行填充并转换为torch.FloatTensor类型的张量。有关详细信息,请参阅Wav2Vec2Processor.call()。 - attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
attention_mask只有在相应的处理器具有config.return_attention_mask == True时才应传递。对于所有处理器具有config.return_attention_mask == False的模型,例如 wav2vec2-base,attention_mask应 不 传递,以避免在进行批量推理时性能下降。对于这些模型,input_values应 简单地用 0 填充并传递,而不使用attention_mask。请注意,这些模型也会根据input_values是否填充而产生略微不同的结果。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size,), optional) — 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.SequenceClassifierOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.SequenceClassifierOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(Wav2Vec2Config)和输入。
-
loss (
torch.FloatTensor形状为(1,), 可选, 当提供labels时返回) — 分类(或回归,如果 config.num_labels==1)损失。 -
logits (
torch.FloatTensor形状为(batch_size, config.num_labels)) — 分类(或回归,如果 config.num_labels==1)得分(在 SoftMax 之前)。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
Wav2Vec2ForSequenceClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoFeatureExtractor, Wav2Vec2ForSequenceClassification
>>> from datasets import load_dataset
>>> import torch
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation", trust_remote_code=True)
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("superb/wav2vec2-base-superb-ks")
>>> model = Wav2Vec2ForSequenceClassification.from_pretrained("superb/wav2vec2-base-superb-ks")
>>> # audio file is decoded on the fly
>>> inputs = feature_extractor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_ids = torch.argmax(logits, dim=-1).item()
>>> predicted_label = model.config.id2label[predicted_class_ids]
>>> predicted_label
'_unknown_'
>>> # compute loss - target_label is e.g. "down"
>>> target_label = model.config.id2label[0]
>>> inputs["labels"] = torch.tensor([model.config.label2id[target_label]])
>>> loss = model(**inputs).loss
>>> round(loss.item(), 2)
6.54Wav2Vec2ForAudioFrameClassification
类 transformers.Wav2Vec2ForAudioFrameClassification
< source >( config )
参数
- config (Wav2Vec2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
Wav2Vec2 模型,顶部带有帧分类头,适用于说话人日志等任务。
Wav2Vec2 是由 Alexei Baevski、Henry Zhou、Abdelrahman Mohamed 和 Michael Auli 在 wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations 中提出的。
该模型继承自 PreTrainedModel。请查看超类文档,了解库为其所有模型实现的通用方法(如下载或保存等)。
该模型是一个PyTorch torch.nn.Module 子类。将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_values: typing.Optional[torch.Tensor] attention_mask: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.TokenClassifierOutput 或 tuple(torch.FloatTensor)
参数
- input_values (
torch.FloatTensorof shape(batch_size, sequence_length)) — Float values of input raw speech waveform. Values can be obtained by loading a.flacor.wavaudio file into an array of typeList[float]or anumpy.ndarray, e.g. via the soundfile library (pip install soundfile). To prepare the array intoinput_values, the AutoProcessor should be used for padding and conversion into a tensor of typetorch.FloatTensor. See Wav2Vec2Processor.call() for details. - attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
attention_mask只有在相应的处理器具有config.return_attention_mask == True时才应传递。对于所有处理器具有config.return_attention_mask == False的模型,例如 wav2vec2-base,attention_mask应 不 传递,以避免在进行批量推理时性能下降。对于这些模型,input_values应 简单地用 0 填充并传递,而不使用attention_mask。请注意,这些模型也会根据input_values是否填充而产生略微不同的结果。 - output_attentions (
bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - labels (
torch.LongTensor形状为(batch_size,), 可选) — 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.TokenClassifierOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.TokenClassifierOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(Wav2Vec2Config)和输入。
-
loss (
torch.FloatTensor形状为(1,), 可选, 当提供labels时返回) — 分类损失。 -
logits (
torch.FloatTensor形状为(batch_size, sequence_length, config.num_labels)) — 分类分数(在 SoftMax 之前)。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
Wav2Vec2ForAudioFrameClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoFeatureExtractor, Wav2Vec2ForAudioFrameClassification
>>> from datasets import load_dataset
>>> import torch
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation", trust_remote_code=True)
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("anton-l/wav2vec2-base-superb-sd")
>>> model = Wav2Vec2ForAudioFrameClassification.from_pretrained("anton-l/wav2vec2-base-superb-sd")
>>> # audio file is decoded on the fly
>>> inputs = feature_extractor(dataset[0]["audio"]["array"], return_tensors="pt", sampling_rate=sampling_rate)
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> probabilities = torch.sigmoid(logits[0])
>>> # labels is a one-hot array of shape (num_frames, num_speakers)
>>> labels = (probabilities > 0.5).long()
>>> labels[0].tolist()
[0, 0]Wav2Vec2ForXVector
类 transformers.Wav2Vec2ForXVector
< source >( config )
参数
- config (Wav2Vec2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
Wav2Vec2 模型,顶部带有 XVector 特征提取头,适用于说话人验证等任务。
Wav2Vec2 是由 Alexei Baevski、Henry Zhou、Abdelrahman Mohamed 和 Michael Auli 在 wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations 中提出的。
该模型继承自 PreTrainedModel。请查看超类文档,了解库为其所有模型实现的通用方法(如下载或保存等)。
该模型是一个PyTorch torch.nn.Module 子类。将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_values: typing.Optional[torch.Tensor] attention_mask: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None labels: typing.Optional[torch.Tensor] = None ) → transformers.modeling_outputs.XVectorOutput 或 tuple(torch.FloatTensor)
参数
- input_values (
torch.FloatTensorof shape(batch_size, sequence_length)) — 输入原始语音波形的浮点值。可以通过将.flac或.wav音频文件加载到List[float]类型的数组或numpy.ndarray中获取值,例如通过soundfile库(pip install soundfile)。要将数组准备为input_values,应使用AutoProcessor进行填充并转换为torch.FloatTensor类型的张量。详情请参见Wav2Vec2Processor.call()。 - attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
attention_mask只有在相应的处理器具有config.return_attention_mask == True时才应传递。对于所有处理器具有config.return_attention_mask == False的模型,例如 wav2vec2-base,attention_mask应 不 传递,以避免在进行批量推理时性能下降。对于这些模型,input_values应 简单地用 0 填充并传递,而不使用attention_mask。请注意,这些模型也会根据input_values是否填充而产生略微不同的结果。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size,), optional) — 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.XVectorOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.XVectorOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(Wav2Vec2Config)和输入。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 分类损失。 -
logits (
torch.FloatTensor形状为(batch_size, config.xvector_output_dim)) — AMSoftmax 之前的分类隐藏状态。 -
embeddings (
torch.FloatTensor形状为(batch_size, config.xvector_output_dim)) — 用于基于向量相似性检索的话语嵌入。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入的输出 + 一个用于每层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
Wav2Vec2ForXVector 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoFeatureExtractor, Wav2Vec2ForXVector
>>> from datasets import load_dataset
>>> import torch
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation", trust_remote_code=True)
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("anton-l/wav2vec2-base-superb-sv")
>>> model = Wav2Vec2ForXVector.from_pretrained("anton-l/wav2vec2-base-superb-sv")
>>> # audio file is decoded on the fly
>>> inputs = feature_extractor(
... [d["array"] for d in dataset[:2]["audio"]], sampling_rate=sampling_rate, return_tensors="pt", padding=True
... )
>>> with torch.no_grad():
... embeddings = model(**inputs).embeddings
>>> embeddings = torch.nn.functional.normalize(embeddings, dim=-1).cpu()
>>> # the resulting embeddings can be used for cosine similarity-based retrieval
>>> cosine_sim = torch.nn.CosineSimilarity(dim=-1)
>>> similarity = cosine_sim(embeddings[0], embeddings[1])
>>> threshold = 0.7 # the optimal threshold is dataset-dependent
>>> if similarity < threshold:
... print("Speakers are not the same!")
>>> round(similarity.item(), 2)
0.98Wav2Vec2ForPreTraining
类 transformers.Wav2Vec2ForPreTraining
< source >( config: Wav2Vec2Config )
参数
- config (Wav2Vec2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
带有量化器和VQ头的Wav2Vec2模型。
Wav2Vec2是由Alexei Baevski、Henry Zhou、Abdelrahman Mohamed和Michael Auli在wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations中提出的。
该模型继承自 PreTrainedModel。请查看超类文档,了解库为其所有模型实现的通用方法(如下载或保存等)。
该模型是一个PyTorch torch.nn.Module 子类。将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_values: typing.Optional[torch.Tensor] attention_mask: typing.Optional[torch.Tensor] = None mask_time_indices: typing.Optional[torch.BoolTensor] = None sampled_negative_indices: typing.Optional[torch.BoolTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.models.wav2vec2.modeling_wav2vec2.Wav2Vec2ForPreTrainingOutput 或 tuple(torch.FloatTensor)
参数
- input_values (
torch.FloatTensor形状为(batch_size, sequence_length)) — 输入原始语音波形的浮点值。可以通过将.flac或.wav音频文件加载到类型为List[float]或numpy.ndarray的数组中来获取值,例如 通过 soundfile 库 (pip install soundfile)。要将数组准备为input_values,应使用 AutoProcessor 进行填充并转换为类型为torch.FloatTensor的张量。详情请参见 Wav2Vec2Processor.call(). - attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
attention_mask只有在相应的处理器具有config.return_attention_mask == True时才应传递。对于所有处理器具有config.return_attention_mask == False的模型,例如 wav2vec2-base,attention_mask应 不 传递,以避免在进行批量推理时性能下降。对于这些模型,input_values应 简单地用 0 填充并传递,而不使用attention_mask。请注意,这些模型也会根据input_values是否填充而产生略微不同的结果。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - mask_time_indices (
torch.BoolTensorof shape(batch_size, sequence_length), optional) — 用于对比损失的特征提取掩码索引。在训练模式下,模型学习在config.proj_codevector_dim空间中预测被掩码的特征提取结果。 - sampled_negative_indices (
torch.BoolTensorof shape(batch_size, sequence_length, num_negatives), optional) — 指示哪些量化目标向量在对比损失中被用作负采样向量的索引。 预训练所需的输入。
返回
transformers.models.wav2vec2.modeling_wav2vec2.Wav2Vec2ForPreTrainingOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.wav2vec2.modeling_wav2vec2.Wav2Vec2ForPreTrainingOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(Wav2Vec2Config)和输入。
-
loss (可选,当传递
sample_negative_indices时返回,torch.FloatTensor形状为(1,)) — 总损失,为对比损失(L_m)和多样性损失(L_d)之和,如 官方论文 所述。(分类)损失。 -
projected_states (
torch.FloatTensor形状为(batch_size, sequence_length, config.proj_codevector_dim)) — 模型投影到 config.proj_codevector_dim 的隐藏状态,可用于预测被掩码的投影量化状态。 -
projected_quantized_states (
torch.FloatTensor形状为(batch_size, sequence_length, config.proj_codevector_dim)) — 量化提取的特征向量投影到 config.proj_codevector_dim,表示对比损失的正目标向量。 -
hidden_states (
tuple(torch.FloatTensor), 可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入的输出,一个用于每层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力权重在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
-
contrastive_loss (可选,当传递
sample_negative_indices时返回,torch.FloatTensor形状为(1,)) — 对比损失(L_m),如 官方论文 所述。 -
diversity_loss (可选,当传递
sample_negative_indices时返回,torch.FloatTensor形状为(1,)) — 多样性损失(L_d),如 官方论文 所述。
Wav2Vec2ForPreTraining 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import torch
>>> from transformers import AutoFeatureExtractor, Wav2Vec2ForPreTraining
>>> from transformers.models.wav2vec2.modeling_wav2vec2 import _compute_mask_indices, _sample_negative_indices
>>> from datasets import load_dataset
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
>>> model = Wav2Vec2ForPreTraining.from_pretrained("facebook/wav2vec2-base")
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> input_values = feature_extractor(ds[0]["audio"]["array"], return_tensors="pt").input_values # Batch size 1
>>> # compute masked indices
>>> batch_size, raw_sequence_length = input_values.shape
>>> sequence_length = model._get_feat_extract_output_lengths(raw_sequence_length).item()
>>> mask_time_indices = _compute_mask_indices(
... shape=(batch_size, sequence_length), mask_prob=0.2, mask_length=2
... )
>>> sampled_negative_indices = _sample_negative_indices(
... features_shape=(batch_size, sequence_length),
... num_negatives=model.config.num_negatives,
... mask_time_indices=mask_time_indices,
... )
>>> mask_time_indices = torch.tensor(data=mask_time_indices, device=input_values.device, dtype=torch.long)
>>> sampled_negative_indices = torch.tensor(
... data=sampled_negative_indices, device=input_values.device, dtype=torch.long
... )
>>> with torch.no_grad():
... outputs = model(input_values, mask_time_indices=mask_time_indices)
>>> # compute cosine similarity between predicted (=projected_states) and target (=projected_quantized_states)
>>> cosine_sim = torch.cosine_similarity(outputs.projected_states, outputs.projected_quantized_states, dim=-1)
>>> # show that cosine similarity is much higher than random
>>> cosine_sim[mask_time_indices.to(torch.bool)].mean() > 0.5
tensor(True)
>>> # for contrastive loss training model should be put into train mode
>>> model = model.train()
>>> loss = model(
... input_values, mask_time_indices=mask_time_indices, sampled_negative_indices=sampled_negative_indices
... ).lossTFWav2Vec2Model
类 transformers.TFWav2Vec2Model
< source >( config: Wav2Vec2Config *inputs **kwargs )
参数
- config (Wav2Vec2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的TFWav2Vec2模型转换器输出原始隐藏状态,没有任何特定的头部。
该模型继承自 TFPreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个keras.Model子类。可以将其作为常规的TF 2.0 Keras模型使用,并参考TF 2.0文档以了解与一般使用和行为相关的所有事项。
TensorFlow 模型和层在 transformers 中接受两种格式作为输入:
- 将所有输入作为关键字参数(如PyTorch模型),或
- 将所有输入作为列表、元组或字典放在第一个位置参数中。
支持第二种格式的原因是,Keras 方法在将输入传递给模型和层时更喜欢这种格式。由于这种支持,当使用像 model.fit() 这样的方法时,事情应该“正常工作”——只需以 model.fit() 支持的任何格式传递你的输入和标签!然而,如果你想在 Keras 方法之外使用第二种格式,比如在使用 Keras Functional API 创建自己的层或模型时,有三种方法可以用来将所有输入张量收集到第一个位置参数中:
- 仅包含
input_values的单个张量,没有其他内容:model(input_values) - 一个长度不定的列表,包含一个或多个输入张量,顺序按照文档字符串中给出的顺序:
model([input_values, attention_mask])或model([input_values, attention_mask, token_type_ids]) - 一个字典,包含一个或多个与文档字符串中给出的输入名称相关联的输入张量:
model({"input_values": input_values, "token_type_ids": token_type_ids})
请注意,当使用子类化创建模型和层时,您不需要担心这些,因为您可以像传递任何其他Python函数一样传递输入!
调用
< source >( input_values: tf.Tensor attention_mask: tf.Tensor | None = None token_type_ids: tf.Tensor | None = None position_ids: tf.Tensor | None = None head_mask: tf.Tensor | None = None inputs_embeds: tf.Tensor | None = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: bool = False ) → transformers.modeling_tf_outputs.TFBaseModelOutput 或 tuple(tf.Tensor)
参数
- input_values (
np.ndarray,tf.Tensor,List[tf.Tensor]Dict[str, tf.Tensor]orDict[str, np.ndarray]and each example must have the shape({0})) — Indices of input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.call()和 PreTrainedTokenizer.encode()。
- attention_mask (
np.ndarrayortf.Tensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
np.ndarrayortf.Tensorof shape({0}), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
np.ndarrayortf.Tensorof shape({0}), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
np.ndarray或tf.Tensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
np.ndarray或tf.Tensor形状为({0}, hidden_size), 可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_values。 如果您希望对如何将input_values索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。此参数只能在eager模式下使用,在graph模式下将使用配置中的值代替。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。此参数只能在eager模式下使用,在graph模式下将使用配置中的值。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。此参数可以在eager模式下使用,在graph模式下该值将始终设置为True. - 训练 (
bool, 可选, 默认为 `False“) — 是否在训练模式下使用模型(一些模块如dropout模块在训练和评估之间有不同的行为)。
返回
transformers.modeling_tf_outputs.TFBaseModelOutput 或 tuple(tf.Tensor)
一个 transformers.modeling_tf_outputs.TFBaseModelOutput 或一个 tf.Tensor 的元组(如果
return_dict=False 被传递或当 config.return_dict=False 时)包含各种元素,取决于
配置 (Wav2Vec2Config) 和输入。
-
last_hidden_state (
tf.Tensor形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。 -
hidden_states (
tuple(tf.FloatTensor), 可选, 当output_hidden_states=True被传递或当config.output_hidden_states=True时返回) —tf.Tensor的元组(一个用于嵌入的输出 + 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(tf.Tensor), 可选, 当output_attentions=True被传递或当config.output_attentions=True时返回) —tf.Tensor的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
TFWav2Vec2Model 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoProcessor, TFWav2Vec2Model
>>> from datasets import load_dataset
>>> import soundfile as sf
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
>>> model = TFWav2Vec2Model.from_pretrained("facebook/wav2vec2-base-960h")
>>> def map_to_array(batch):
... speech, _ = sf.read(batch["file"])
... batch["speech"] = speech
... return batch
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> ds = ds.map(map_to_array)
>>> input_values = processor(ds["speech"][0], return_tensors="tf").input_values # Batch size 1
>>> hidden_states = model(input_values).last_hidden_stateTFWav2Vec2ForSequenceClassification
调用
< source >( input_values: tf.Tensor attention_mask: tf.Tensor | None = None output_attentions: bool | None = None output_hidden_states: bool | None = None return_dict: bool | None = None labels: tf.Tensor | None = None training: bool = False )
TFWav2Vec2ForCTC
类 transformers.TFWav2Vec2ForCTC
< source >( config: Wav2Vec2Config *inputs **kwargs )
参数
- config (Wav2Vec2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
TFWav2Vec2 模型,顶部带有语言建模头,用于连接时序分类(CTC)。
该模型继承自 TFPreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个keras.Model子类。可以将其作为常规的TF 2.0 Keras模型使用,并参考TF 2.0文档以了解与一般使用和行为相关的所有事项。
TensorFlow 模型和层在 transformers 中接受两种格式作为输入:
- 将所有输入作为关键字参数(如PyTorch模型),或
- 将所有输入作为列表、元组或字典放在第一个位置参数中。
支持第二种格式的原因是,Keras 方法在将输入传递给模型和层时更喜欢这种格式。由于这种支持,当使用像 model.fit() 这样的方法时,事情应该“正常工作”——只需以 model.fit() 支持的任何格式传递你的输入和标签!然而,如果你想在 Keras 方法之外使用第二种格式,比如在使用 Keras Functional API 创建自己的层或模型时,有三种方法可以用来将所有输入张量收集到第一个位置参数中:
- 仅包含
input_values的单个张量,没有其他内容:model(input_values) - 一个长度不定的列表,包含一个或多个输入张量,顺序按照文档字符串中给出的顺序:
model([input_values, attention_mask])或model([input_values, attention_mask, token_type_ids]) - 一个字典,包含一个或多个与文档字符串中给出的输入名称相关联的输入张量:
model({"input_values": input_values, "token_type_ids": token_type_ids})
请注意,当使用子类化创建模型和层时,您不需要担心这些,因为您可以像传递任何其他Python函数一样传递输入!
调用
< source >( input_values: tf.Tensor attention_mask: tf.Tensor | None = None token_type_ids: tf.Tensor | None = None position_ids: tf.Tensor | None = None head_mask: tf.Tensor | None = None inputs_embeds: tf.Tensor | None = None output_attentions: Optional[bool] = None labels: tf.Tensor | None = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: Optional[bool] = False ) → transformers.modeling_tf_outputs.TFCausalLMOutput 或 tuple(tf.Tensor)
参数
- input_values (
np.ndarray,tf.Tensor,List[tf.Tensor]Dict[str, tf.Tensor]orDict[str, np.ndarray]and each example must have the shape({0})) — Indices of input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.call()和 PreTrainedTokenizer.encode()。
- attention_mask (
np.ndarrayortf.Tensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
np.ndarrayortf.Tensorof shape({0}), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
np.ndarrayortf.Tensorof shape({0}), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
np.ndarray或tf.Tensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
np.ndarray或tf.Tensor形状为({0}, hidden_size), 可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_values。 如果您希望对如何将input_values索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。此参数只能在eager模式下使用,在graph模式下将使用配置中的值。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。此参数只能在急切模式下使用,在图形模式下将使用配置中的值。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。此参数可以在eager模式下使用,在graph模式下该值将始终设置为True. - 训练 (
bool, 可选, 默认为 `False“) — 是否在训练模式下使用模型(一些模块如dropout模块在训练和评估之间有不同的行为)。 - labels (
tf.Tensor或np.ndarray形状为(batch_size, sequence_length), 可选) — 用于计算掩码语言建模损失的标签。索引应在[-100, 0, ..., config.vocab_size]范围内(参见input_values文档字符串)。索引设置为-100的标记将被忽略(掩码), 损失仅针对标签在[0, ..., config.vocab_size]范围内的标记计算
返回
transformers.modeling_tf_outputs.TFCausalLMOutput 或 tuple(tf.Tensor)
一个 transformers.modeling_tf_outputs.TFCausalLMOutput 或一个由 tf.Tensor 组成的元组(如果
return_dict=False 被传递或当 config.return_dict=False 时),包含根据配置 (Wav2Vec2Config) 和输入的各种元素。
-
loss (
tf.Tensor形状为(n,), 可选, 其中 n 是非掩码标签的数量,当提供labels时返回) — 语言建模损失(用于下一个标记预测)。 -
logits (
tf.Tensor形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
hidden_states (
tuple(tf.Tensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由tf.Tensor组成的元组(一个用于嵌入的输出 + 一个用于每层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(tf.Tensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由tf.Tensor组成的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
TFWav2Vec2ForCTC 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import tensorflow as tf
>>> from transformers import AutoProcessor, TFWav2Vec2ForCTC
>>> from datasets import load_dataset
>>> import soundfile as sf
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
>>> model = TFWav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h")
>>> def map_to_array(batch):
... speech, _ = sf.read(batch["file"])
... batch["speech"] = speech
... return batch
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> ds = ds.map(map_to_array)
>>> input_values = processor(ds["speech"][0], return_tensors="tf").input_values # Batch size 1
>>> logits = model(input_values).logits
>>> predicted_ids = tf.argmax(logits, axis=-1)
>>> transcription = processor.decode(predicted_ids[0])
>>> # compute loss
>>> target_transcription = "A MAN SAID TO THE UNIVERSE SIR I EXIST"
>>> # Pass transcription as `text` to encode labels
>>> labels = processor(text=transcription, return_tensors="tf").input_ids
>>> loss = model(input_values, labels=labels).lossFlaxWav2Vec2Model
类 transformers.FlaxWav2Vec2Model
< source >( config: Wav2Vec2Config input_shape: typing.Tuple = (1, 1024) seed: int = 0 dtype: dtype =
参数
- config (Wav2Vec2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
- dtype (
jax.numpy.dtype, optional, defaults tojax.numpy.float32) — The data type of the computation. Can be one ofjax.numpy.float32,jax.numpy.float16(on GPUs) andjax.numpy.bfloat16(on TPUs).这可以用于在GPU或TPU上启用混合精度训练或半精度推理。如果指定,所有计算将使用给定的
dtype执行。请注意,这仅指定了计算的数据类型,并不影响模型参数的数据类型。
裸Wav2Vec2模型变压器输出原始隐藏状态,没有任何特定的头部。 Wav2Vec2由Alexei Baevski、Henry Zhou、Abdelrahman Mohamed和Michael Auli在wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations中提出。
该模型继承自FlaxPreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头等)。
该模型也是一个Flax Linen flax.nn.Module 子类。将其作为常规的Flax模块使用,并参考Flax文档以获取与一般用法和行为相关的所有信息。
最后,该模型支持JAX的固有特性,例如:
__call__
< source >( input_values attention_mask = None mask_time_indices = None params: dict = None dropout_rng: tuple(torch.FloatTensor)
参数
- input_values (
jnp.ndarrayof shape(batch_size, sequence_length)) — 输入原始语音波形的浮点值。可以通过将.flac或.wav音频文件加载到List[float]类型的数组或numpy.ndarray中获取值,例如通过soundfile库(pip install soundfile)。要将数组准备为input_values,应使用AutoProcessor进行填充并转换为jnp.ndarray类型的张量。详情请参见Wav2Vec2Processor.call()。 - attention_mask (
jnp.ndarrayof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
什么是注意力掩码? .. 警告::
attention_mask应该仅在相应的处理器具有config.return_attention_mask == True时传递。对于所有处理器具有config.return_attention_mask == False的模型,例如 wav2vec2-base,attention_mask应该 不 传递,以避免在进行批量推理时性能下降。对于这些模型,input_values应该简单地用 0 填充并传递,而不使用attention_mask。请注意,这些模型根据input_values是否填充也会产生略微不同的结果。 - mask_time_indices (
jnp.ndarrayof shape(batch_size, sequence_length), optional) — 用于对比损失的掩码提取特征的索引。在训练模式下,模型学习在config.proj_codevector_dim空间中预测被掩码的提取特征。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。
返回
transformers.models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2BaseModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2BaseModelOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(
-
last_hidden_state (
jnp.ndarray形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。 -
extract_features (
jnp.ndarray形状为(batch_size, sequence_length, last_conv_dim)) — 模型最后一个卷积层提取的特征向量序列,last_conv_dim是最后一个卷积层的维度。 -
hidden_states (
tuple(jnp.ndarray), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由jnp.ndarray组成的元组(一个用于嵌入层的输出,一个用于每一层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(jnp.ndarray), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由jnp.ndarray组成的元组(每一层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力权重在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
FlaxWav2Vec2PreTrainedModel 的 forward 方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoProcessor, FlaxWav2Vec2Model
>>> from datasets import load_dataset
>>> import soundfile as sf
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-large-lv60")
>>> model = FlaxWav2Vec2Model.from_pretrained("facebook/wav2vec2-large-lv60")
>>> def map_to_array(batch):
... speech, _ = sf.read(batch["file"])
... batch["speech"] = speech
... return batch
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> ds = ds.map(map_to_array)
>>> input_values = processor(
... ds["speech"][0], sampling_rate=16_000, return_tensors="np"
... ).input_values # Batch size 1
>>> hidden_states = model(input_values).last_hidden_stateFlaxWav2Vec2ForCTC
类 transformers.FlaxWav2Vec2ForCTC
< source >( config: Wav2Vec2Config input_shape: typing.Tuple = (1, 1024) seed: int = 0 dtype: dtype =
参数
- config (Wav2Vec2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
- dtype (
jax.numpy.dtype, optional, defaults tojax.numpy.float32) — The data type of the computation. Can be one ofjax.numpy.float32,jax.numpy.float16(on GPUs) andjax.numpy.bfloat16(on TPUs).这可以用于在GPU或TPU上启用混合精度训练或半精度推理。如果指定,所有计算将使用给定的
dtype执行。请注意,这仅指定了计算的数据类型,并不影响模型参数的数据类型。
Wav2Vec2 模型,顶部带有语言建模头,用于连接时序分类(CTC)。
Wav2Vec2 是由 Alexei Baevski、Henry Zhou、Abdelrahman Mohamed 和 Michael Auli 在 wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations 中提出的。
该模型继承自FlaxPreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头等)。
该模型也是一个Flax Linen flax.nn.Module 子类。将其作为常规的Flax模块使用,并参考Flax文档以获取与一般用法和行为相关的所有信息。
最后,该模型支持JAX的固有特性,例如:
__call__
< source >( input_values attention_mask = None mask_time_indices = None params: dict = None dropout_rng: tuple(torch.FloatTensor)
参数
- input_values (
jnp.ndarrayof shape(batch_size, sequence_length)) — 输入原始语音波形的浮点值。可以通过将.flac或.wav音频文件加载到List[float]类型的数组或numpy.ndarray中来获取值,例如通过soundfile库(pip install soundfile)。要将数组准备为input_values,应使用AutoProcessor进行填充并转换为jnp.ndarray类型的张量。详情请参见Wav2Vec2Processor.call()。 - attention_mask (
jnp.ndarrayof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
什么是注意力掩码? .. 警告::
attention_mask应该仅在相应的处理器具有config.return_attention_mask == True时传递。对于所有处理器具有config.return_attention_mask == False的模型,例如 wav2vec2-base,attention_mask应该 不 传递,以避免在进行批量推理时性能下降。对于这些模型,input_values应该简单地用 0 填充并传递,而不使用attention_mask。请注意,这些模型根据input_values是否填充也会产生略微不同的结果。 - mask_time_indices (
jnp.ndarrayof shape(batch_size, sequence_length), optional) — 用于对比损失的掩码提取特征的索引。在训练模式下,模型学习在config.proj_codevector_dim空间中预测被掩码的提取特征。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。
返回
transformers.modeling_flax_outputs.FlaxMaskedLMOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_flax_outputs.FlaxMaskedLMOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(
-
logits (
jnp.ndarray形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前的每个词汇标记的分数)。 -
hidden_states (
tuple(jnp.ndarray), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由jnp.ndarray组成的元组(一个用于嵌入的输出 + 一个用于每层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(jnp.ndarray), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由jnp.ndarray组成的元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
FlaxWav2Vec2PreTrainedModel 的 forward 方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import jax.numpy as jnp
>>> from transformers import AutoProcessor, FlaxWav2Vec2ForCTC
>>> from datasets import load_dataset
>>> import soundfile as sf
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-large-960h-lv60")
>>> model = FlaxWav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-large-960h-lv60")
>>> def map_to_array(batch):
... speech, _ = sf.read(batch["file"])
... batch["speech"] = speech
... return batch
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> ds = ds.map(map_to_array)
>>> input_values = processor(
... ds["speech"][0], sampling_rate=16_000, return_tensors="np"
... ).input_values # Batch size 1
>>> logits = model(input_values).logits
>>> predicted_ids = jnp.argmax(logits, axis=-1)
>>> transcription = processor.decode(predicted_ids[0])
>>> # should give: "A MAN SAID TO THE UNIVERSE SIR I EXIST"FlaxWav2Vec2ForPreTraining
类 transformers.FlaxWav2Vec2ForPreTraining
< source >( config: Wav2Vec2Config input_shape: typing.Tuple = (1, 1024) seed: int = 0 dtype: dtype =
参数
- config (Wav2Vec2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
- dtype (
jax.numpy.dtype, optional, defaults tojax.numpy.float32) — The data type of the computation. Can be one ofjax.numpy.float32,jax.numpy.float16(on GPUs) andjax.numpy.bfloat16(on TPUs).这可以用于在GPU或TPU上启用混合精度训练或半精度推理。如果指定,所有计算将使用给定的
dtype执行。请注意,这仅指定了计算的数据类型,并不影响模型参数的数据类型。
带有量化器和VQ头的Wav2Vec2模型。
Wav2Vec2是由Alexei Baevski、Henry Zhou、Abdelrahman Mohamed和Michael Auli在wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations中提出的。
该模型继承自FlaxPreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头等)。
该模型也是一个Flax Linen flax.nn.Module 子类。将其作为常规的Flax模块使用,并参考Flax文档以获取与一般用法和行为相关的所有信息。
最后,该模型支持JAX的固有特性,例如:
__call__
< source >( input_values attention_mask = None mask_time_indices = None gumbel_temperature: int = 1 params: dict = None dropout_rng: tuple(torch.FloatTensor)
参数
- input_values (
jnp.ndarrayof shape(batch_size, sequence_length)) — 输入原始语音波形的浮点值。可以通过将.flac或.wav音频文件加载到类型为List[float]或numpy.ndarray的数组中来获取值,例如通过soundfile库(pip install soundfile)。要将数组准备为input_values,应使用AutoProcessor进行填充并转换为类型为jnp.ndarray的张量。有关详细信息,请参阅Wav2Vec2Processor.call()。 - attention_mask (
jnp.ndarrayof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
什么是注意力掩码? .. 警告::
attention_mask应该仅在相应的处理器具有config.return_attention_mask == True时传递。对于所有处理器具有config.return_attention_mask == False的模型,例如 wav2vec2-base,attention_mask应该 不 传递,以避免在进行批量推理时性能下降。对于这些模型,input_values应该简单地用 0 填充并传递,而不使用attention_mask。请注意,这些模型根据input_values是否填充也会产生略微不同的结果。 - mask_time_indices (
jnp.ndarrayof shape(batch_size, sequence_length), optional) — 用于对比损失的掩码提取特征的索引。在训练模式下,模型学习在config.proj_codevector_dim空间中预测被掩码的提取特征。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。
返回
transformers.models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2ForPreTrainingOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2ForPreTrainingOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(
-
loss (可选,当模型处于训练模式时返回,
jnp.ndarray形状为(1,)) — 总损失,作为对比损失(L_m)和多样性损失(L_d)的总和,如 官方论文 中所述。(分类)损失。 -
projected_states (
jnp.ndarray形状为(batch_size, sequence_length, config.proj_codevector_dim)) — 模型投影到 config.proj_codevector_dim 的隐藏状态,可用于预测被遮蔽的投影量化状态。 -
projected_quantized_states (
jnp.ndarray形状为(batch_size, sequence_length, config.proj_codevector_dim)) — 量化提取的特征向量投影到 config.proj_codevector_dim,表示对比损失的正目标向量。 -
hidden_states (
tuple(jnp.ndarray), 可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由jnp.ndarray组成的元组(一个用于嵌入的输出 + 一个用于每层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(jnp.ndarray), 可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由jnp.ndarray组成的元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力权重在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
FlaxWav2Vec2ForPreTraining 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import optax
>>> import numpy as np
>>> import jax.numpy as jnp
>>> from transformers import AutoFeatureExtractor, FlaxWav2Vec2ForPreTraining
>>> from transformers.models.wav2vec2.modeling_flax_wav2vec2 import _compute_mask_indices
>>> from datasets import load_dataset
>>> import soundfile as sf
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-large-lv60")
>>> model = FlaxWav2Vec2ForPreTraining.from_pretrained("facebook/wav2vec2-large-lv60")
>>> def map_to_array(batch):
... speech, _ = sf.read(batch["file"])
... batch["speech"] = speech
... return batch
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> ds = ds.map(map_to_array)
>>> input_values = feature_extractor(ds["speech"][0], return_tensors="np").input_values # Batch size 1
>>> # compute masked indices
>>> batch_size, raw_sequence_length = input_values.shape
>>> sequence_length = model._get_feat_extract_output_lengths(raw_sequence_length)
>>> mask_time_indices = _compute_mask_indices((batch_size, sequence_length), mask_prob=0.2, mask_length=2)
>>> outputs = model(input_values, mask_time_indices=mask_time_indices)
>>> # compute cosine similarity between predicted (=projected_states) and target (=projected_quantized_states)
>>> cosine_sim = optax.cosine_similarity(outputs.projected_states, outputs.projected_quantized_states)
>>> # show that cosine similarity is much higher than random
>>> assert np.asarray(cosine_sim)[mask_time_indices].mean() > 0.5