Hubert
概述
Hubert 是在 HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units 中由 Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed 提出的。
论文的摘要如下:
自监督的语音表示学习方法面临三个独特的问题:(1) 每个输入话语中有多个声音单元,(2) 在预训练阶段没有输入声音单元的词汇表,(3) 声音单元的长度可变且没有明确的分割。为了解决这三个问题,我们提出了用于自监督语音表示学习的隐藏单元BERT(HuBERT)方法,该方法利用离线聚类步骤为类似BERT的预测损失提供对齐的目标标签。我们方法的一个关键要素是仅在掩码区域上应用预测损失,这迫使模型在连续输入上学习结合声学和语言模型。HuBERT主要依赖于无监督聚类步骤的一致性,而不是分配的聚类标签的内在质量。从100个聚类的简单k-means教师开始,并使用两次聚类迭代,HuBERT模型在Librispeech(960小时)和Libri-light(60,000小时)基准测试中,使用10分钟、1小时、10小时、100小时和960小时的微调子集,匹配或改进了最先进的wav2vec 2.0性能。使用1B参数模型,HuBERT在更具挑战性的dev-other和test-other评估子集上显示出高达19%和13%的相对WER减少。
该模型由patrickvonplaten贡献。
使用提示
- Hubert 是一个语音模型,它接受与语音信号的原始波形相对应的浮点数组。
- Hubert模型使用连接主义时间分类(CTC)进行了微调,因此模型输出必须使用Wav2Vec2CTCTokenizer进行解码。
使用 Flash Attention 2
Flash Attention 2 是该模型的一个更快、优化的版本。
安装
首先,检查您的硬件是否与Flash Attention 2兼容。最新的兼容硬件列表可以在官方文档中找到。如果您的硬件不兼容Flash Attention 2,您仍然可以通过上述介绍的Better Transformer支持从注意力内核优化中受益。
接下来,安装最新版本的Flash Attention 2:
pip install -U flash-attn --no-build-isolation
用法
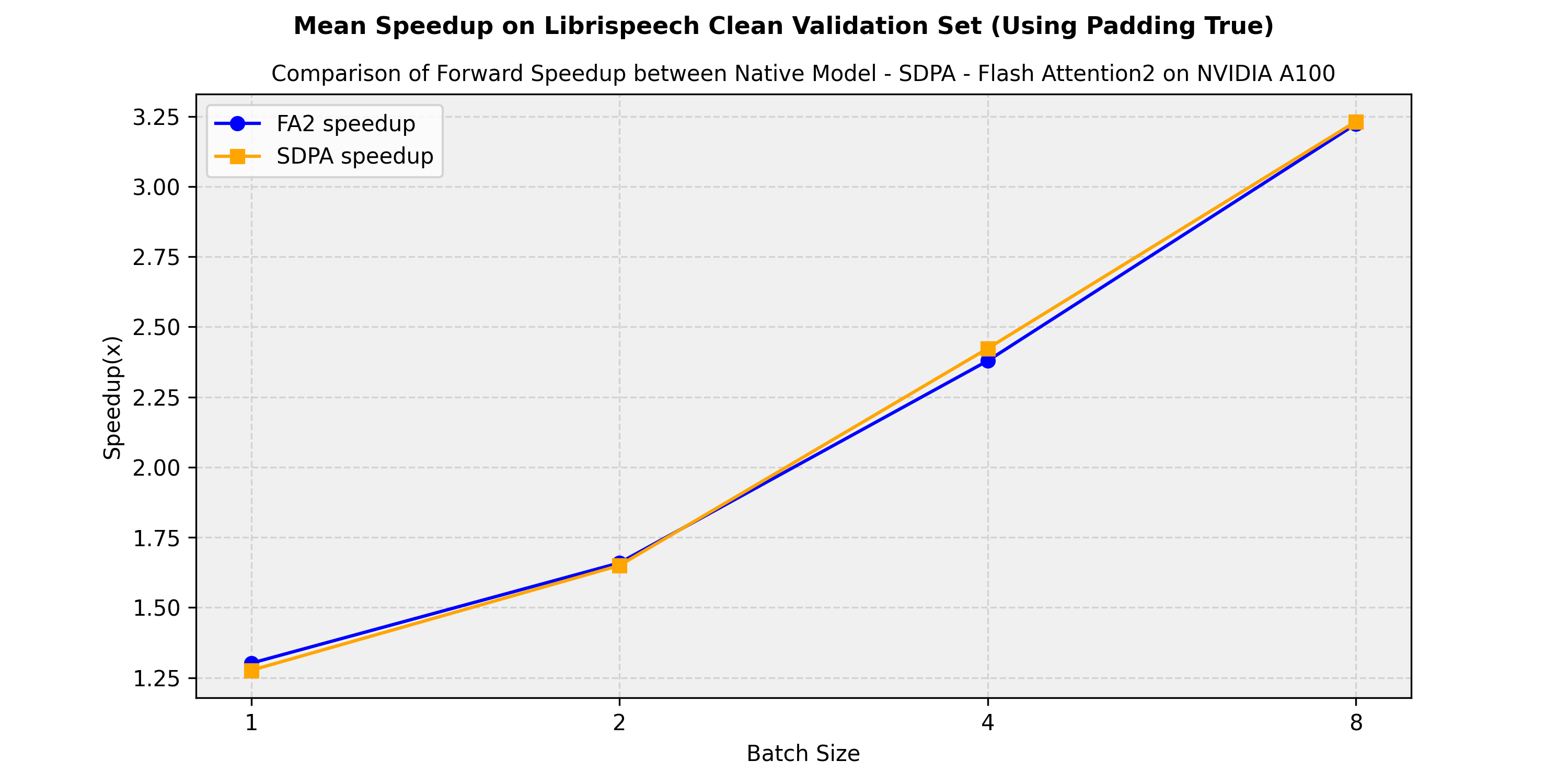
下面是一个预期的加速图,比较了facebook/hubert-large-ls960-ft在transformers中的原生实现、flash-attention-2和sdpa(scale-dot-product-attention)版本之间的纯推理时间。我们展示了在librispeech_asr的clean验证集上获得的平均加速:
>>> from transformers import Wav2Vec2Model
model = Wav2Vec2Model.from_pretrained("facebook/hubert-large-ls960-ft", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to(device)
...预期的加速
下面是一个预期的加速图,比较了facebook/hubert-large-ls960-ft模型在transformers中的原生实现与flash-attention-2和sdpa(scale-dot-product-attention)版本之间的纯推理时间。我们展示了在librispeech_asr clean验证集上获得的平均加速:
资源
HubertConfig
类 transformers.HubertConfig
< source >( vocab_size = 32 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout = 0.1 activation_dropout = 0.1 attention_dropout = 0.1 feat_proj_layer_norm = True feat_proj_dropout = 0.0 final_dropout = 0.1 layerdrop = 0.1 initializer_range = 0.02 layer_norm_eps = 1e-05 feat_extract_norm = 'group' feat_extract_activation = 'gelu' conv_dim = (512, 512, 512, 512, 512, 512, 512) conv_stride = (5, 2, 2, 2, 2, 2, 2) conv_kernel = (10, 3, 3, 3, 3, 2, 2) conv_bias = False num_conv_pos_embeddings = 128 num_conv_pos_embedding_groups = 16 do_stable_layer_norm = False apply_spec_augment = True mask_time_prob = 0.05 mask_time_length = 10 mask_time_min_masks = 2 mask_feature_prob = 0.0 mask_feature_length = 10 mask_feature_min_masks = 0 ctc_loss_reduction = 'sum' ctc_zero_infinity = False use_weighted_layer_sum = False classifier_proj_size = 256 pad_token_id = 0 bos_token_id = 1 eos_token_id = 2 **kwargs )
参数
- vocab_size (
int, optional, 默认为 32) — Hubert 模型的词汇表大小。定义了调用 HubertModel 时传递的inputs_ids可以表示的不同标记的数量。模型的词汇表大小。定义了传递给 HubertModel 的 inputs_ids 可以表示的不同标记的数量。 - hidden_size (
int, optional, 默认为 768) — 编码器层和池化层的维度。 - num_hidden_layers (
int, 可选, 默认为 12) — Transformer 编码器中的隐藏层数。 - num_attention_heads (
int, optional, defaults to 12) — Transformer编码器中每个注意力层的注意力头数。 - intermediate_size (
int, optional, 默认为 3072) — Transformer 编码器中“中间”(即前馈)层的维度。 - hidden_act (
str或function, 可选, 默认为"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"selu"和"gelu_new"。 - hidden_dropout(
float, 可选, 默认为 0.1) — 嵌入层、编码器和池化器中所有全连接层的 dropout 概率。 - activation_dropout (
float, optional, 默认为 0.1) — 全连接层内部激活的丢弃比例。 - attention_dropout(
float, 可选, 默认为 0.1) — 注意力概率的丢弃比例。 - final_dropout (
float, optional, 默认为 0.1) — Wav2Vec2ForCTC 的最终投影层的 dropout 概率。 - layerdrop (
float, 可选, 默认为 0.1) — LayerDrop 概率。更多详情请参阅 [LayerDrop 论文](see https://arxiv.org/abs/1909.11556)。 - initializer_range (
float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 - layer_norm_eps (
float, optional, defaults to 1e-12) — 层归一化层使用的epsilon值。 - feat_extract_norm (
str, 可选, 默认为"group") — 应用于特征编码器中1D卷积层的归一化方法。可以是"group"用于仅对第一个1D卷积层进行组归一化,或"layer"用于对所有1D卷积层进行层归一化。 - feat_proj_dropout (
float, optional, 默认为 0.0) — 特征编码器输出的丢弃概率。 - feat_proj_layer_norm (
bool, 可选, 默认为True) — 是否对特征编码器的输出应用LayerNorm。 - feat_extract_activation (
str,可选, 默认为“gelu”) -- 特征提取器中1D卷积层的非线性激活函数(函数或字符串)。如果是字符串,支持“gelu”,“relu”,“selu”和“gelu_new”`。 - conv_dim (
Tuple[int], 可选, 默认为(512, 512, 512, 512, 512, 512, 512)) — 一个整数元组,定义了特征编码器中每个1D卷积层的输入和输出通道数。conv_dim的长度定义了1D卷积层的数量。 - conv_stride (
Tuple[int], 可选, 默认为(5, 2, 2, 2, 2, 2, 2)) — 一个整数元组,定义了特征编码器中每个一维卷积层的步幅。conv_stride 的长度定义了卷积层的数量,并且必须与 conv_dim 的长度匹配。 - conv_kernel (
Tuple[int], 可选, 默认为(10, 3, 3, 3, 3, 3, 3)) — 一个整数元组,定义了特征编码器中每个1D卷积层的核大小。conv_kernel的长度定义了卷积层的数量,并且必须与conv_dim的长度匹配。 - conv_bias (
bool, 可选, 默认为False) — 1D卷积层是否具有偏置。 - num_conv_pos_embeddings (
int, 可选, 默认为 128) — 卷积位置嵌入的数量。定义了1D卷积位置嵌入层的核大小。 - num_conv_pos_embedding_groups (
int, optional, 默认为 16) — 1D 卷积位置嵌入层的组数。 - do_stable_layer_norm (
bool, optional, defaults toFalse) — 是否应用Transformer编码器的稳定层归一化架构。do_stable_layer_norm is True对应于在注意力层之前应用层归一化,而do_stable_layer_norm is False对应于在注意力层之后应用层归一化。 - apply_spec_augment (
bool, 可选, 默认为True) — 是否对特征编码器的输出应用SpecAugment数据增强。有关参考,请参见 SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. - mask_time_prob (
float, optional, 默认为 0.05) — 沿时间轴的所有特征向量将被掩码的百分比(介于 0 和 1 之间)。掩码过程会生成 ”mask_time_problen(time_axis)/mask_time_length” 个独立的掩码。如果从每个特征向量被选为要掩码的向量跨度的起始点的概率来推理,mask_time_prob 应该是 `prob_vector_startmask_time_length。请注意,重叠可能会减少实际被掩码的向量的百分比。这仅在apply_spec_augment 为 True` 时相关。 - mask_time_length (
int, optional, defaults to 10) — 沿时间轴的向量跨度长度。 - mask_time_min_masks (
int, 可选, 默认为 2), — 每次沿时间轴生成的mask_feature_length长度的最小掩码数量,每个时间步长, 不考虑mask_feature_prob。仅在“mask_time_prob*len(time_axis)/mask_time_length < mask_time_min_masks”时相关 - mask_feature_prob (
float, optional, 默认为 0.0) — 所有特征向量沿特征轴的百分比(介于 0 和 1 之间)将被掩码。掩码过程生成 ”mask_feature_problen(feature_axis)/mask_time_length” 个独立的掩码覆盖该轴。如果从每个特征向量被选为要掩码的向量跨度的起始点的概率推理,mask_feature_prob 应为 `prob_vector_startmask_feature_length。请注意,重叠可能会减少实际被掩码的向量的百分比。这仅在apply_spec_augment 为 True` 时相关。 - mask_feature_length (
int, optional, defaults to 10) — 沿特征轴的向量跨度长度。 - mask_feature_min_masks (
int, 可选, 默认为 0), — 每次时间步长生成的长度为mask_feature_length的最小掩码数量,与mask_feature_prob无关。仅在 ”mask_feature_prob*len(feature_axis)/mask_feature_length < mask_feature_min_masks” 时相关 - ctc_loss_reduction (
str, 可选, 默认为"sum") — 指定应用于torch.nn.CTCLoss输出的减少方式。仅在训练HubertForCTC实例时相关。 - ctc_zero_infinity (
bool, 可选, 默认为False) — 是否将无限损失和torch.nn.CTCLoss的相关梯度归零。无限损失主要发生在输入太短无法与目标对齐时。仅在训练HubertForCTC实例时相关。 - use_weighted_layer_sum (
bool, 可选, 默认为False) — 是否使用带有学习权重的层输出的加权平均。仅在使用的实例为 HubertForSequenceClassification 时相关。 - classifier_proj_size (
int, optional, 默认为 256) — 分类前用于标记平均池化的投影维度.
这是用于存储HubertModel配置的配置类。它用于根据指定的参数实例化一个Hubert模型,定义模型架构。使用默认值实例化配置将产生类似于Hubert facebook/hubert-base-ls960架构的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import HubertModel, HubertConfig
>>> # Initializing a Hubert facebook/hubert-base-ls960 style configuration
>>> configuration = HubertConfig()
>>> # Initializing a model from the facebook/hubert-base-ls960 style configuration
>>> model = HubertModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configHubertModel
类 transformers.HubertModel
< source >( config: HubertConfig )
参数
- config (HubertConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的Hubert模型转换器输出原始隐藏状态,没有任何特定的头部。 Hubert是由Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed在HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units中提出的。
该模型继承自 PreTrainedModel。请查看超类文档,了解库为其所有模型实现的通用方法(如下载或保存等)。
该模型是一个PyTorch torch.nn.Module 子类。将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_values: typing.Optional[torch.Tensor] attention_mask: typing.Optional[torch.Tensor] = None mask_time_indices: typing.Optional[torch.FloatTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.BaseModelOutput 或 tuple(torch.FloatTensor)
参数
- input_values (
torch.FloatTensorof shape(batch_size, sequence_length)) — 输入原始语音波形的浮点值。可以通过将.flac或.wav音频文件加载到List[float]类型的数组或numpy.ndarray中来获取值,例如通过soundfile库(pip install soundfile)。要将数组准备为input_values,应使用AutoProcessor进行填充并转换为torch.FloatTensor类型的张量。有关详细信息,请参阅Wav2Vec2Processor.call()。 - attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
attention_mask只有在相应的处理器具有config.return_attention_mask == True时才应传递。对于所有处理器具有config.return_attention_mask == False的模型,例如 hubert-base,attention_mask应不传递, 以避免在进行批量推理时性能下降。对于这些模型,input_values应简单地用 0 填充并传递,而不使用attention_mask。请注意,这些模型根据input_values是否填充也会产生略微不同的结果。 - output_attentions (
bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。
返回
transformers.modeling_outputs.BaseModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(HubertConfig)和输入。
-
last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
HubertModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoProcessor, HubertModel
>>> from datasets import load_dataset
>>> import soundfile as sf
>>> processor = AutoProcessor.from_pretrained("facebook/hubert-large-ls960-ft")
>>> model = HubertModel.from_pretrained("facebook/hubert-large-ls960-ft")
>>> def map_to_array(batch):
... speech, _ = sf.read(batch["file"])
... batch["speech"] = speech
... return batch
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> ds = ds.map(map_to_array)
>>> input_values = processor(ds["speech"][0], return_tensors="pt").input_values # Batch size 1
>>> hidden_states = model(input_values).last_hidden_stateHubertForCTC
类 transformers.HubertForCTC
< source >( config target_lang: typing.Optional[str] = None )
参数
- config (HubertConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
Hubert 模型,顶部带有语言建模头,用于连接时序分类(CTC)。
Hubert 是由 Wei-Ning Hsu、Benjamin Bolte、Yao-Hung Hubert Tsai、Kushal Lakhotia、Ruslan Salakhutdinov 和 Abdelrahman Mohamed 在 HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units 中提出的。
该模型继承自 PreTrainedModel。请查看超类文档,了解库为其所有模型实现的通用方法(如下载或保存等)。
该模型是一个PyTorch torch.nn.Module 子类。将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_values: typing.Optional[torch.Tensor] attention_mask: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None labels: typing.Optional[torch.Tensor] = None ) → transformers.modeling_outputs.CausalLMOutput 或 tuple(torch.FloatTensor)
参数
- input_values (
torch.FloatTensorof shape(batch_size, sequence_length)) — 输入原始语音波形的浮点值。可以通过将.flac或.wav音频文件加载到List[float]类型的数组或numpy.ndarray中来获取这些值,例如通过soundfile库(pip install soundfile)。要将数组准备为input_values,应使用AutoProcessor进行填充并转换为torch.FloatTensor类型的张量。有关详细信息,请参阅Wav2Vec2Processor.call()。 - attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
attention_mask只有在相应的处理器具有config.return_attention_mask == True时才应传递。对于所有处理器具有config.return_attention_mask == False的模型,例如 hubert-base,attention_mask应不传递, 以避免在进行批量推理时性能下降。对于这些模型,input_values应简单地用 0 填充并传递,而不使用attention_mask。请注意,这些模型根据input_values是否填充也会产生略微不同的结果。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size, target_length), optional) — 用于连接时序分类的标签。注意target_length必须小于或等于输出 logits 的序列长度。索引在[-100, 0, ..., config.vocab_size - 1]中选择。 所有设置为-100的标签将被忽略(掩码),损失仅针对[0, ..., config.vocab_size - 1]中的标签计算。
返回
transformers.modeling_outputs.CausalLMOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.CausalLMOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(HubertConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,), 可选, 当提供labels时返回) — 语言建模损失(用于下一个令牌预测)。 -
logits (
torch.FloatTensor形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇令牌的分数)。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
HubertForCTC 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoProcessor, HubertForCTC
>>> from datasets import load_dataset
>>> import torch
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation", trust_remote_code=True)
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> processor = AutoProcessor.from_pretrained("facebook/hubert-large-ls960-ft")
>>> model = HubertForCTC.from_pretrained("facebook/hubert-large-ls960-ft")
>>> # audio file is decoded on the fly
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_ids = torch.argmax(logits, dim=-1)
>>> # transcribe speech
>>> transcription = processor.batch_decode(predicted_ids)
>>> transcription[0]
'MISTER QUILTER IS THE APOSTLE OF THE MIDDLE CLASSES AND WE ARE GLAD TO WELCOME HIS GOSPEL'
>>> inputs["labels"] = processor(text=dataset[0]["text"], return_tensors="pt").input_ids
>>> # compute loss
>>> loss = model(**inputs).loss
>>> round(loss.item(), 2)
22.68HubertForSequenceClassification
类 transformers.HubertForSequenceClassification
< source >( config )
参数
- config (HubertConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
Hubert 模型,顶部带有序列分类头(在池化输出上的线性层),适用于诸如 SUPERB 关键词检测等任务。
Hubert 是在 HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units 中由 Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed 提出的。
该模型继承自 PreTrainedModel。请查看超类文档,了解库为其所有模型实现的通用方法(如下载或保存等)。
该模型是一个PyTorch torch.nn.Module 子类。将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_values: typing.Optional[torch.Tensor] attention_mask: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None labels: typing.Optional[torch.Tensor] = None ) → transformers.modeling_outputs.SequenceClassifierOutput 或 tuple(torch.FloatTensor)
参数
- input_values (
torch.FloatTensorof shape(batch_size, sequence_length)) — Float values of input raw speech waveform. Values can be obtained by loading a.flacor.wavaudio file into an array of typeList[float]or anumpy.ndarray, e.g. via the soundfile library (pip install soundfile). To prepare the array intoinput_values, the AutoProcessor should be used for padding and conversion into a tensor of typetorch.FloatTensor. See Wav2Vec2Processor.call() for details. - attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
attention_mask只有在相应的处理器具有config.return_attention_mask == True时才应传递。对于所有处理器具有config.return_attention_mask == False的模型,例如 hubert-base,attention_mask应不传递, 以避免在进行批量推理时性能下降。对于这些模型,input_values应简单地用 0 填充并传递,而不使用attention_mask。请注意,这些模型根据input_values是否填充也会产生略微不同的结果。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size,), optional) — 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.SequenceClassifierOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.SequenceClassifierOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(HubertConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 分类(或回归,如果 config.num_labels==1)损失。 -
logits (
torch.FloatTensor形状为(batch_size, config.num_labels)) — 分类(或回归,如果 config.num_labels==1)得分(在 SoftMax 之前)。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
HubertForSequenceClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoFeatureExtractor, HubertForSequenceClassification
>>> from datasets import load_dataset
>>> import torch
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation", trust_remote_code=True)
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("superb/hubert-base-superb-ks")
>>> model = HubertForSequenceClassification.from_pretrained("superb/hubert-base-superb-ks")
>>> # audio file is decoded on the fly
>>> inputs = feature_extractor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_ids = torch.argmax(logits, dim=-1).item()
>>> predicted_label = model.config.id2label[predicted_class_ids]
>>> predicted_label
'_unknown_'
>>> # compute loss - target_label is e.g. "down"
>>> target_label = model.config.id2label[0]
>>> inputs["labels"] = torch.tensor([model.config.label2id[target_label]])
>>> loss = model(**inputs).loss
>>> round(loss.item(), 2)
8.53TFHubertModel
类 transformers.TFHubertModel
< source >( config: HubertConfig *inputs **kwargs )
参数
- config (HubertConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的TFHubert模型转换器输出原始隐藏状态,没有任何特定的头部。
该模型继承自 TFPreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个keras.Model子类。可以将其作为常规的TF 2.0 Keras模型使用,并参考TF 2.0文档以了解与一般使用和行为相关的所有事项。
TensorFlow 模型和层在 transformers 中接受两种格式作为输入:
- 将所有输入作为关键字参数(如PyTorch模型),或
- 将所有输入作为列表、元组或字典放在第一个位置参数中。
支持第二种格式的原因是,Keras 方法在将输入传递给模型和层时更喜欢这种格式。由于这种支持,当使用像 model.fit() 这样的方法时,事情应该“正常工作”——只需以 model.fit() 支持的任何格式传递你的输入和标签!然而,如果你想在 Keras 方法之外使用第二种格式,比如在使用 Keras Functional API 创建自己的层或模型时,有三种方法可以用来将所有输入张量收集到第一个位置参数中:
- 仅包含
input_values的单个张量,没有其他内容:model(input_values) - 一个长度不定的列表,包含一个或多个输入张量,顺序按照文档字符串中给出的顺序:
model([input_values, attention_mask])或model([input_values, attention_mask, token_type_ids]) - 一个字典,包含一个或多个与文档字符串中给出的输入名称相关联的输入张量:
model({"input_values": input_values, "token_type_ids": token_type_ids})
请注意,当使用子类化创建模型和层时,您不需要担心这些,因为您可以像传递任何其他Python函数一样传递输入!
调用
< source >( input_values: tf.Tensor attention_mask: tf.Tensor | None = None token_type_ids: tf.Tensor | None = None position_ids: tf.Tensor | None = None head_mask: tf.Tensor | None = None inputs_embeds: tf.Tensor | None = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: bool = False ) → transformers.modeling_tf_outputs.TFBaseModelOutput 或 tuple(tf.Tensor)
参数
- input_values (
np.ndarray,tf.Tensor,List[tf.Tensor]Dict[str, tf.Tensor]orDict[str, np.ndarray]and each example must have the shape({0})) — Indices of input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.call()和 PreTrainedTokenizer.encode()。
- attention_mask (
np.ndarrayortf.Tensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
np.ndarrayortf.Tensorof shape({0}), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
np.ndarrayortf.Tensorof shape({0}), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
np.ndarray或tf.Tensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
np.ndarray或tf.Tensor形状为({0}, hidden_size), 可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_values。 如果您希望对如何将input_values索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。此参数只能在eager模式下使用,在graph模式下将使用配置中的值。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。此参数只能在急切模式下使用,在图形模式下将使用配置中的值。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。此参数可以在eager模式下使用,在graph模式下该值将始终设置为True. - 训练 (
bool, 可选, 默认为 `False“) — 是否在训练模式下使用模型(一些模块如dropout模块在训练和评估之间有不同的行为)。
返回
transformers.modeling_tf_outputs.TFBaseModelOutput 或 tuple(tf.Tensor)
一个 transformers.modeling_tf_outputs.TFBaseModelOutput 或一个 tf.Tensor 的元组(如果
return_dict=False 被传递或当 config.return_dict=False 时)包含各种元素,具体取决于
配置 (HubertConfig) 和输入。
-
last_hidden_state (
tf.Tensor形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。 -
hidden_states (
tuple(tf.FloatTensor), 可选, 当output_hidden_states=True被传递或当config.output_hidden_states=True时返回) —tf.Tensor的元组(一个用于嵌入的输出 + 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(tf.Tensor), 可选, 当output_attentions=True被传递或当config.output_attentions=True时返回) —tf.Tensor的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
TFHubertModel 的 forward 方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoProcessor, TFHubertModel
>>> from datasets import load_dataset
>>> import soundfile as sf
>>> processor = AutoProcessor.from_pretrained("facebook/hubert-large-ls960-ft")
>>> model = TFHubertModel.from_pretrained("facebook/hubert-large-ls960-ft")
>>> def map_to_array(batch):
... speech, _ = sf.read(batch["file"])
... batch["speech"] = speech
... return batch
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> ds = ds.map(map_to_array)
>>> input_values = processor(ds["speech"][0], return_tensors="tf").input_values # Batch size 1
>>> hidden_states = model(input_values).last_hidden_stateTFHubertForCTC
类 transformers.TFHubertForCTC
< source >( config: HubertConfig *inputs **kwargs )
参数
- config (HubertConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
TFHubert 模型,顶部带有语言建模头,用于连接主义时间分类(CTC)。
该模型继承自 TFPreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个keras.Model子类。可以将其作为常规的TF 2.0 Keras模型使用,并参考TF 2.0文档以了解与一般使用和行为相关的所有事项。
TensorFlow 模型和层在 transformers 中接受两种格式作为输入:
- 将所有输入作为关键字参数(如PyTorch模型),或
- 将所有输入作为列表、元组或字典放在第一个位置参数中。
支持第二种格式的原因是,Keras 方法在将输入传递给模型和层时更喜欢这种格式。由于这种支持,当使用像 model.fit() 这样的方法时,事情应该“正常工作”——只需以 model.fit() 支持的任何格式传递你的输入和标签!然而,如果你想在 Keras 方法之外使用第二种格式,比如在使用 Keras Functional API 创建自己的层或模型时,有三种方法可以用来将所有输入张量收集到第一个位置参数中:
- 仅包含
input_values的单个张量,没有其他内容:model(input_values) - 一个长度不定的列表,包含一个或多个输入张量,顺序按照文档字符串中给出的顺序:
model([input_values, attention_mask])或model([input_values, attention_mask, token_type_ids]) - 一个字典,包含一个或多个与文档字符串中给出的输入名称相关联的输入张量:
model({"input_values": input_values, "token_type_ids": token_type_ids})
请注意,当使用子类化创建模型和层时,您不需要担心这些,因为您可以像传递任何其他Python函数一样传递输入!
调用
< source >( input_values: tf.Tensor attention_mask: tf.Tensor | None = None token_type_ids: tf.Tensor | None = None position_ids: tf.Tensor | None = None head_mask: tf.Tensor | None = None inputs_embeds: tf.Tensor | None = None output_attentions: Optional[bool] = None labels: tf.Tensor | None = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: Optional[bool] = False ) → transformers.modeling_tf_outputs.TFCausalLMOutput 或 tuple(tf.Tensor)
参数
- input_values (
np.ndarray,tf.Tensor,List[tf.Tensor]Dict[str, tf.Tensor]orDict[str, np.ndarray]and each example must have the shape({0})) — Indices of input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.call()和 PreTrainedTokenizer.encode()。
- attention_mask (
np.ndarrayortf.Tensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
np.ndarrayortf.Tensorof shape({0}), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
np.ndarrayortf.Tensorof shape({0}), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
np.ndarray或tf.Tensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
np.ndarray或tf.Tensor形状为({0}, hidden_size), 可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_values。 如果您希望对如何将input_values索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。此参数只能在eager模式下使用,在graph模式下将使用配置中的值。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。此参数只能在eager模式下使用,在graph模式下将使用配置中的值。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。此参数可以在eager模式下使用,在graph模式下该值将始终设置为True. - 训练 (
bool, 可选, 默认为 `False“) — 是否在训练模式下使用模型(一些模块如dropout模块在训练和评估之间有不同的行为)。 - labels (
tf.Tensor或np.ndarray形状为(batch_size, sequence_length), 可选) — 用于计算掩码语言建模损失的标签。索引应在[-100, 0, ..., config.vocab_size]范围内(参见input_values文档字符串)。索引设置为-100的标记将被忽略(掩码), 损失仅针对标签在[0, ..., config.vocab_size]范围内的标记计算
返回
transformers.modeling_tf_outputs.TFCausalLMOutput 或 tuple(tf.Tensor)
一个 transformers.modeling_tf_outputs.TFCausalLMOutput 或一个 tf.Tensor 元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含根据配置 (HubertConfig) 和输入的各种元素。
-
loss (
tf.Tensor形状为(n,), 可选, 其中 n 是非掩码标签的数量,当提供labels时返回) — 语言建模损失(用于下一个标记预测)。 -
logits (
tf.Tensor形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
hidden_states (
tuple(tf.Tensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) —tf.Tensor元组(一个用于嵌入的输出 + 一个用于每层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(tf.Tensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) —tf.Tensor元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
TFHubertForCTC 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import tensorflow as tf
>>> from transformers import AutoProcessor, TFHubertForCTC
>>> from datasets import load_dataset
>>> import soundfile as sf
>>> processor = AutoProcessor.from_pretrained("facebook/hubert-large-ls960-ft")
>>> model = TFHubertForCTC.from_pretrained("facebook/hubert-large-ls960-ft")
>>> def map_to_array(batch):
... speech, _ = sf.read(batch["file"])
... batch["speech"] = speech
... return batch
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> ds = ds.map(map_to_array)
>>> input_values = processor(ds["speech"][0], return_tensors="tf").input_values # Batch size 1
>>> logits = model(input_values).logits
>>> predicted_ids = tf.argmax(logits, axis=-1)
>>> transcription = processor.decode(predicted_ids[0])
>>> # compute loss
>>> target_transcription = "A MAN SAID TO THE UNIVERSE SIR I EXIST"
>>> # Pass the transcription as text to encode labels
>>> labels = processor(text=transcription, return_tensors="tf").input_values
>>> loss = model(input_values, labels=labels).loss