Bark
概述
Bark 是由 Suno AI 在 suno-ai/bark 中提出的基于 transformer 的文本转语音模型。
Bark由4个主要模型组成:
- BarkSemanticModel(也称为‘文本’模型):一种因果自回归变压器模型,它接收标记化的文本作为输入,并预测捕捉文本含义的语义文本标记。
- BarkCoarseModel(也称为‘粗粒度声学’模型):一个因果自回归变压器,它接收BarkSemanticModel模型的结果作为输入。其目标是预测EnCodec所需的前两个音频编码本。
- BarkFineModel(‘精细声学’模型),这次是一个非因果自编码器变压器,它基于先前码本嵌入的总和迭代预测最后的码本。
- 在从EncodecModel预测所有码本通道后,Bark 使用它来解码输出音频数组。
需要注意的是,前三个模块中的每一个都可以支持条件说话人嵌入,以根据特定的预定义语音条件输出声音。
该模型由Yoach Lacombe (ylacombe)和Sanchit Gandhi (sanchit-gandhi)贡献。 原始代码可以在这里找到。
优化Bark
Bark 可以通过添加几行额外的代码进行优化,这显著减少了其内存占用并加速了推理。
使用半精度
您可以通过以半精度加载模型来加速推理并减少50%的内存占用。
from transformers import BarkModel
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)使用CPU卸载
如上所述,Bark由4个子模型组成,这些子模型在音频生成过程中依次调用。换句话说,当一个子模型在使用时,其他子模型处于空闲状态。
如果您使用的是CUDA设备,一个简单的解决方案是在子模型空闲时将它们从GPU卸载到CPU,这样可以减少80%的内存占用。此操作称为CPU卸载。您可以使用以下一行代码来实现:
model.enable_cpu_offload()
请注意,在使用此功能之前必须安装🤗 Accelerate。Here’s how to install it.
使用更好的变压器
Better Transformer 是 🤗 Optimum 的一个功能,它在底层执行内核融合。你可以在不降低性能的情况下获得 20% 到 30% 的速度提升。只需一行代码即可将模型导出到 🤗 Better Transformer:
model = model.to_bettertransformer()
请注意,在使用此功能之前必须安装🤗 Optimum。这里是安装方法。
使用 Flash Attention 2
Flash Attention 2 是之前优化版本的更快、更优化的版本。
安装
首先,检查您的硬件是否与Flash Attention 2兼容。最新的兼容硬件列表可以在官方文档中找到。如果您的硬件不兼容Flash Attention 2,您仍然可以通过上述介绍的Better Transformer支持从注意力内核优化中受益。
接下来,安装最新版本的Flash Attention 2:
pip install -U flash-attn --no-build-isolation
用法
要使用Flash Attention 2加载模型,我们可以将attn_implementation="flash_attention_2"标志传递给.from_pretrained。我们还将以半精度(例如torch.float16)加载模型,因为这样几乎不会降低音频质量,但会显著减少内存使用并加快推理速度:
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to(device)性能比较
下图展示了原生注意力实现(无优化)与Better Transformer和Flash Attention 2的延迟对比。在所有情况下,我们使用PyTorch 2.1在40GB A100 GPU上生成400个语义标记。Flash Attention 2始终比Better Transformer更快,并且随着批量大小的增加,其性能进一步提升:
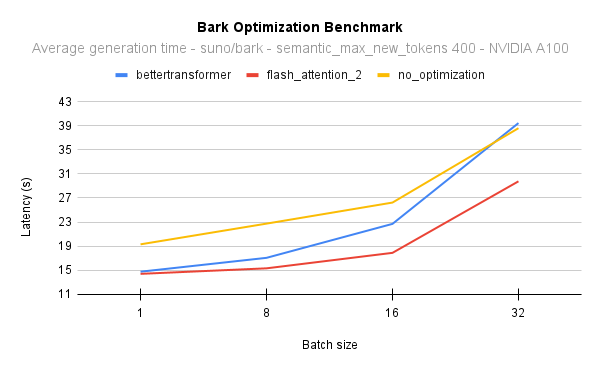
为了更直观地理解这一点,在NVIDIA A100上,当批量大小为16生成400个语义标记时,你可以获得17倍的吞吐量,并且仍然比使用原生模型实现逐句生成快2秒。换句话说,所有样本的生成速度将提高17倍。
在NVIDIA A100上,当批量大小为8时,Flash Attention 2比Better Transformer快10%,当批量大小为16时,快25%。
结合优化技术
你可以结合优化技术,同时使用CPU卸载、半精度和Flash Attention 2(或🤗 Better Transformer)。
from transformers import BarkModel
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
# load in fp16 and use Flash Attention 2
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to(device)
# enable CPU offload
model.enable_cpu_offload()了解更多关于推理优化技术的信息 这里。
使用提示
Suno 提供了多种语言的语音预设库 这里。 这些预设也上传到了中心 这里 或 这里。
>>> from transformers import AutoProcessor, BarkModel
>>> processor = AutoProcessor.from_pretrained("suno/bark")
>>> model = BarkModel.from_pretrained("suno/bark")
>>> voice_preset = "v2/en_speaker_6"
>>> inputs = processor("Hello, my dog is cute", voice_preset=voice_preset)
>>> audio_array = model.generate(**inputs)
>>> audio_array = audio_array.cpu().numpy().squeeze()Bark 可以生成高度逼真的多语言语音以及其他音频 - 包括音乐、背景噪音和简单的音效。
>>> # Multilingual speech - simplified Chinese
>>> inputs = processor("惊人的!我会说中文")
>>> # Multilingual speech - French - let's use a voice_preset as well
>>> inputs = processor("Incroyable! Je peux générer du son.", voice_preset="fr_speaker_5")
>>> # Bark can also generate music. You can help it out by adding music notes around your lyrics.
>>> inputs = processor("♪ Hello, my dog is cute ♪")
>>> audio_array = model.generate(**inputs)
>>> audio_array = audio_array.cpu().numpy().squeeze()该模型还可以产生非语言交流,如笑、叹息和哭泣。
>>> # Adding non-speech cues to the input text
>>> inputs = processor("Hello uh ... [clears throat], my dog is cute [laughter]")
>>> audio_array = model.generate(**inputs)
>>> audio_array = audio_array.cpu().numpy().squeeze()要保存音频,只需从模型配置中获取采样率并使用一些scipy工具:
>>> from scipy.io.wavfile import write as write_wav
>>> # save audio to disk, but first take the sample rate from the model config
>>> sample_rate = model.generation_config.sample_rate
>>> write_wav("bark_generation.wav", sample_rate, audio_array)BarkConfig
类 transformers.BarkConfig
< source >( semantic_config: typing.Dict = None coarse_acoustics_config: typing.Dict = None fine_acoustics_config: typing.Dict = None codec_config: typing.Dict = None initializer_range = 0.02 **kwargs )
参数
- semantic_config (BarkSemanticConfig, 可选) — 底层语义子模型的配置。
- coarse_acoustics_config (BarkCoarseConfig, 可选) — 底层粗声学子模型的配置。
- fine_acoustics_config (BarkFineConfig, 可选) — 底层精细声学子模型的配置。
- codec_config (AutoConfig, 可选) — 底层编解码子模型的配置。
- 示例 —
- ```python —
从transformers导入 (
- … BarkSemanticConfig, —
- … BarkCoarseConfig, —
- … BarkFineConfig, —
- … BarkModel, —
- … BarkConfig, —
- … AutoConfig, —
- … ) —
这是用于存储BarkModel配置的配置类。它用于根据指定的子模型配置实例化Bark模型,定义模型架构。
使用默认值实例化配置将产生类似于Bark suno/bark 架构的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
from_sub_model_configs
< source >( semantic_config: BarkSemanticConfig coarse_acoustics_config: BarkCoarseConfig fine_acoustics_config: BarkFineConfig codec_config: PretrainedConfig **kwargs ) → BarkConfig
从 bark 子模型配置实例化一个 BarkConfig(或派生类)。
BarkProcessor
类 transformers.BarkProcessor
< source >( tokenizer speaker_embeddings = 无 )
参数
- tokenizer (PreTrainedTokenizer) — 一个 PreTrainedTokenizer 的实例.
- speaker_embeddings (
Dict[Dict[str]], 可选) — 可选的嵌套说话者嵌入字典。第一层包含语音预设名称(例如"en_speaker_4")。第二层包含"semantic_prompt"、"coarse_prompt"和"fine_prompt"嵌入。值对应于相应np.ndarray的路径。请参阅 这里 获取voice_preset_names的列表。
构建一个Bark处理器,它将文本分词器和可选的Bark语音预设封装到一个单一的处理器中。
__call__
< source >( text = None voice_preset = None return_tensors = 'pt' max_length = 256 add_special_tokens = False return_attention_mask = True return_token_type_ids = False **kwargs ) → 元组(BatchEncoding, BatchFeature)
参数
- text (
str,List[str],List[List[str]]) — 要编码的序列或序列批次。每个序列可以是一个字符串或一个字符串列表(预分词的字符串)。如果序列以字符串列表(预分词)的形式提供,你必须设置is_split_into_words=True(以消除与序列批次的歧义)。 - voice_preset (
str,Dict[np.ndarray]) — 语音预设,即说话者嵌入。它可以是有效的voice_preset名称,例如"en_speaker_1",或者直接是Bark每个子模型的np.ndarray嵌入的字典。或者 它可以是本地.npz单个语音预设的有效文件名。 - return_tensors (
str或 TensorType, 可选) — 如果设置,将返回特定框架的张量。可接受的值为:'pt': 返回 PyTorchtorch.Tensor对象。'np': 返回 NumPynp.ndarray对象。
返回
一个由BatchEncoding组成的元组,即tokenizer的输出,以及一个BatchFeature,即具有正确张量类型的语音预设。
准备模型一个或多个序列的主要方法。该方法将text和kwargs参数转发给AutoTokenizer的__call__()以编码文本。该方法还提出了一个语音预设,它是一个数组字典,用于条件化Bark的输出。如果voice_preset是一个有效的文件名,kwargs参数将被转发给分词器和cached_file方法。
from_pretrained
< source >( pretrained_processor_name_or_path speaker_embeddings_dict_path = 'speaker_embeddings_path.json' **kwargs )
参数
- pretrained_model_name_or_path (
str或os.PathLike) — 这可以是以下之一:- 一个字符串,表示托管在 huggingface.co 上的模型仓库中的预训练 BarkProcessor 的 模型 id。
- 一个路径,指向使用 save_pretrained() 方法保存的处理器所在的 目录,例如
./my_model_directory/。
- speaker_embeddings_dict_path (
str, 可选, 默认为"speaker_embeddings_path.json") — 包含位于pretrained_model_name_or_path中的 speaker_embeddings 字典的.json文件的名称。如果为None,则不加载 speaker_embeddings。 - **kwargs —
传递给
~tokenization_utils_base.PreTrainedTokenizer.from_pretrained的额外关键字参数.
实例化一个与预训练模型关联的Bark处理器。
save_pretrained
< source >( save_directory speaker_embeddings_dict_path = 'speaker_embeddings_path.json' speaker_embeddings_directory = 'speaker_embeddings' push_to_hub: bool = False **kwargs )
参数
- save_directory (
stroros.PathLike) — 保存分词器文件和说话者嵌入的目录(如果目录不存在,将会创建)。 - speaker_embeddings_dict_path (
str, 可选, 默认为"speaker_embeddings_path.json") — 如果存在,将包含 speaker_embeddings 嵌套路径字典的.json文件的名称,该文件将位于pretrained_model_name_or_path/speaker_embeddings_directory中。 - speaker_embeddings_directory (
str, optional, defaults to"speaker_embeddings/") — 保存speaker_embeddings数组的文件夹名称。 - push_to_hub (
bool, optional, defaults toFalse) — 是否在保存后将模型推送到 Hugging Face 模型中心。您可以使用repo_id指定要推送到的仓库(默认为您命名空间中的save_directory名称)。 - kwargs — 传递给 push_to_hub() 方法的额外关键字参数。
将此处理器(分词器…)的属性保存在指定目录中,以便可以使用 from_pretrained() 方法重新加载。
BarkModel
类 transformers.BarkModel
< source >( config )
参数
- config (BarkConfig) — 模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型相关的权重,仅加载配置。查看 from_pretrained() 方法以加载模型权重。
完整的Bark模型,一个由4个子模型组成的文本到语音模型:
- BarkSemanticModel(也称为‘文本’模型):一种因果自回归变压器模型,它接收作为输入的标记化文本,并预测捕捉文本含义的语义文本标记。
- BarkCoarseModel(也称为“粗声学”模型),也是一个因果自回归变换器,
它考虑了上一个模型的输入结果。它的目标是回归前两个音频编码本,这些编码本对于
encodec是必要的。 - BarkFineModel(‘精细声学’模型),这次是一个非因果自编码器变压器,它基于先前码本嵌入的总和迭代预测最后的码本。
- 在从EncodecModel预测所有码本通道后,Bark 使用它来解码输出音频数组。
需要注意的是,前三个模块中的每一个都可以支持条件说话人嵌入,以根据特定的预定义语音来调节输出声音。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
生成
< source >( input_ids: typing.Optional[torch.Tensor] = None history_prompt: typing.Optional[typing.Dict[str, torch.Tensor]] = None return_output_lengths: typing.Optional[bool] = None **kwargs ) → 默认情况下
参数
- input_ids (
Optional[torch.Tensor]of shape (batch_size, seq_len), optional) — 输入ID。将被截断至最多256个标记。请注意,输出音频将与批次中最长的生成音频一样长。 - history_prompt (
Optional[Dict[str,torch.Tensor]], optional) — 可选的Bark说话者提示。请注意,目前该模型每批次仅接受一个说话者提示。 - kwargs (optional) — Remaining dictionary of keyword arguments. Keyword arguments are of two types:
- Without a prefix, they will be entered as
**kwargsfor thegeneratemethod of each sub-model. - With a semantic_, coarse_, fine_ prefix, they will be input for the
generatemethod of the semantic, coarse and fine respectively. It has the priority over the keywords without a prefix.
这意味着你可以,例如,为所有子模型指定一个生成策略,除了一个。
- Without a prefix, they will be entered as
- return_output_lengths (
bool, optional) — 是否返回波形长度。在批处理时很有用。
返回
默认情况下
- audio_waveform (
torch.Tensorof shape (batch_size, seq_len)): 生成的音频波形。 当return_output_lengths=True时: 返回一个由以下内容组成的元组: - audio_waveform (
torch.Tensorof shape (batch_size, seq_len)): 生成的音频波形。 - output_lengths (
torch.Tensorof shape (batch_size)): 批次中每个波形的长度
从输入提示和可选的Bark说话者提示生成音频。
示例:
>>> from transformers import AutoProcessor, BarkModel
>>> processor = AutoProcessor.from_pretrained("suno/bark-small")
>>> model = BarkModel.from_pretrained("suno/bark-small")
>>> # To add a voice preset, you can pass `voice_preset` to `BarkProcessor.__call__(...)`
>>> voice_preset = "v2/en_speaker_6"
>>> inputs = processor("Hello, my dog is cute, I need him in my life", voice_preset=voice_preset)
>>> audio_array = model.generate(**inputs, semantic_max_new_tokens=100)
>>> audio_array = audio_array.cpu().numpy().squeeze()enable_cpu_offload
< source >( gpu_id: typing.Optional[int] = 0 )
使用accelerate将所有子模型卸载到CPU,以减少内存使用,同时对性能影响较小。此方法在使用时将整个子模型一次移动到GPU,并且该子模型在GPU中保持直到下一个子模型运行。
BarkSemanticModel
class transformers.BarkSemanticModel
< source >( config )
参数
- config (BarkSemanticConfig) — 模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
Bark语义(或文本)模型。它与粗粒度模型共享相同的架构。 它是一个类似于GPT-2的自回归模型,顶部有一个语言建模头。 该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入大小、修剪头等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.Tensor] = None past_key_values: typing.Optional[typing.Tuple[torch.FloatTensor]] = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.LongTensor] = None input_embeds: typing.Optional[torch.Tensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None )
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — 词汇表中输入序列标记的索引。默认情况下,如果您提供了填充,它将被忽略。可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。什么是输入ID? - past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cacheis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head).包含预先计算的隐藏状态(自注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。如果使用了
past_key_values,用户可以选择只输入最后一个decoder_input_ids(那些没有将其过去键值状态提供给此模型的)形状为(batch_size, 1),而不是所有形状为(batch_size, sequence_length)的input_ids。 - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.Tensorof shape(encoder_layers, encoder_attention_heads), optional) — 用于在编码器中屏蔽注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- input_embeds (
torch.FloatTensor形状为(batch_size, input_sequence_length, hidden_size), 可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。 在这里,由于Bark的特殊性,如果使用了past_key_values,input_embeds将被忽略,您必须使用input_ids。如果未使用past_key_values并且use_cache设置为True,则优先使用input_embeds而不是input_ids。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。
BarkCausalModel 的 forward 方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
BarkCoarseModel
类 transformers.BarkCoarseModel
< source >( config )
参数
- config (BarkCoarseConfig) — 模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
Bark 粗糙声学模型。 它与语义(或文本)模型共享相同的架构。它是一个类似于 GPT-2 的自回归模型,顶部有一个语言建模头。 该模型继承自 PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入大小、修剪头等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.Tensor] = None past_key_values: typing.Optional[typing.Tuple[torch.FloatTensor]] = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.LongTensor] = None input_embeds: typing.Optional[torch.Tensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None )
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — 词汇表中输入序列标记的索引。默认情况下,如果您提供了填充,它将被忽略。可以使用AutoTokenizer获取索引。有关详细信息,请参阅PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。什么是输入ID? - past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cacheis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head).包含预先计算的隐藏状态(自注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。如果使用了
past_key_values,用户可以选择只输入最后一个decoder_input_ids(那些没有将其过去键值状态提供给此模型的)形状为(batch_size, 1),而不是所有形状为(batch_size, sequence_length)的input_ids。 - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.Tensorof shape(encoder_layers, encoder_attention_heads), optional) — 用于在编码器中屏蔽注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- input_embeds (
torch.FloatTensor形状为(batch_size, input_sequence_length, hidden_size), 可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。 在这里,由于Bark的特殊性,如果使用了past_key_values,input_embeds将被忽略,您必须使用input_ids。如果未使用past_key_values并且use_cache设置为True,则优先使用input_embeds而不是input_ids。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。
BarkCausalModel 的 forward 方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
BarkFineModel
类 transformers.BarkFineModel
< source >( config )
参数
- config (BarkFineConfig) — 模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
Bark 精细声学模型。这是一个非因果的类似 GPT 的模型,具有 config.n_codes_total 嵌入层和语言建模头,每个码本一个。
该模型继承自 PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入大小、修剪头等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( codebook_idx: int input_ids: typing.Optional[torch.Tensor] = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.LongTensor] = None input_embeds: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None )
参数
- codebook_idx (
int) — 将被预测的codebook的索引。 - input_ids (
torch.LongTensorof shape(batch_size, sequence_length, number_of_codebooks)) — 词汇表中输入序列标记的索引。默认情况下,如果您提供了填充,它将被忽略。最初,前两个码本的索引是从coarse子模型中获得的。其余部分通过关注先前预测的通道递归预测。模型在长度为1024的窗口上进行预测。 - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.Tensorof shape(encoder_layers, encoder_attention_heads), optional) — 用于在编码器中屏蔽注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — 尚未实现. - input_embeds (
torch.FloatTensorof shape(batch_size, input_sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果使用了past_key_values,则可以选择仅输入最后一个input_embeds(参见past_key_values)。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。
BarkFineModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
BarkCausalModel
前进
< source >( input_ids: typing.Optional[torch.Tensor] = None past_key_values: typing.Optional[typing.Tuple[torch.FloatTensor]] = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.LongTensor] = None input_embeds: typing.Optional[torch.Tensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None )
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — 词汇表中输入序列标记的索引。默认情况下,如果您提供了填充,它将被忽略。可以使用AutoTokenizer获取索引。有关详细信息,请参阅PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。什么是输入ID? - past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cacheis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head).包含预先计算的隐藏状态(自注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。如果使用了
past_key_values,用户可以选择只输入最后一个decoder_input_ids(那些没有将其过去键值状态提供给此模型的)形状为(batch_size, 1),而不是所有形状为(batch_size, sequence_length)的input_ids。 - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.Tensorof shape(encoder_layers, encoder_attention_heads), optional) — 用于在编码器中屏蔽注意力模块中选定的头。在[0, 1]中选择的掩码值:- 1 表示头 未被屏蔽,
- 0 表示头 被屏蔽.
- input_embeds (
torch.FloatTensor形状为(batch_size, input_sequence_length, hidden_size), 可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。 在这里,由于Bark的特殊性,如果使用了past_key_values,input_embeds将被忽略,您必须使用input_ids。如果未使用past_key_values并且use_cache设置为True,则优先使用input_embeds而不是input_ids。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。
BarkCausalModel 的 forward 方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
BarkCoarseConfig
类 transformers.BarkCoarseConfig
< source >( block_size = 1024 input_vocab_size = 10048 output_vocab_size = 10048 num_layers = 12 num_heads = 12 hidden_size = 768 dropout = 0.0 bias = True initializer_range = 0.02 use_cache = True **kwargs )
参数
- block_size (
int, optional, defaults to 1024) — 此模型可能使用的最大序列长度。通常将其设置为较大的值以防万一(例如,512、1024或2048)。 - input_vocab_size (
int, 可选, 默认为 10_048) — Bark 子模型的词汇表大小。定义了调用 BarkCoarseModel 时传递的inputs_ids可以表示的不同令牌的数量。默认为 10_048,但应根据所选的子模型仔细考虑。 - output_vocab_size (
int, 可选, 默认为 10_048) — Bark子模型的输出词汇大小。定义了在传递BarkCoarseModel时,output_ids可以表示的不同令牌的数量。默认为10_048,但应根据所选的子模型仔细考虑。 - num_layers (
int, optional, defaults to 12) — 给定子模型中的隐藏层数量。 - num_heads (
int, optional, defaults to 12) — Transformer架构中每个注意力层的注意力头数量。 - hidden_size (
int, optional, 默认为 768) — 架构中“中间”(通常称为前馈)层的维度。 - dropout (
float, optional, defaults to 0.0) — 嵌入层、编码器和池化器中所有全连接层的dropout概率。 - bias (
bool, 可选, 默认为True) — 是否在线性层和层归一化层中使用偏置。 - initializer_range (
float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 - use_cache (
bool, 可选, 默认为True) — 模型是否应返回最后的键/值注意力(并非所有模型都使用)。
这是用于存储BarkCoarseModel配置的配置类。它用于根据指定的参数实例化模型,定义模型架构。使用默认值实例化配置将产生类似于Bark suno/bark架构的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import BarkCoarseConfig, BarkCoarseModel
>>> # Initializing a Bark sub-module style configuration
>>> configuration = BarkCoarseConfig()
>>> # Initializing a model (with random weights) from the suno/bark style configuration
>>> model = BarkCoarseModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configBarkFineConfig
类 transformers.BarkFineConfig
< source >( tie_word_embeddings = True n_codes_total = 8 n_codes_given = 1 **kwargs )
参数
- block_size (
int, optional, defaults to 1024) — 该模型可能使用的最大序列长度。通常将其设置为较大的值以防万一(例如,512 或 1024 或 2048)。 - input_vocab_size (
int, 可选, 默认为 10_048) — Bark 子模型的词汇量大小。定义了调用 BarkFineModel 时传递的inputs_ids可以表示的不同令牌的数量。默认为 10_048,但应根据所选的子模型仔细考虑。 - output_vocab_size (
int, 可选, 默认为 10_048) — Bark 子模型的输出词汇大小。定义了在传递 BarkFineModel 时,output_ids可以表示的不同令牌的数量。默认为 10_048,但应根据所选的子模型仔细考虑。 - num_layers (
int, optional, defaults to 12) — 给定子模型中的隐藏层数量。 - num_heads (
int, optional, defaults to 12) — Transformer架构中每个注意力层的注意力头数。 - hidden_size (
int, optional, 默认为 768) — 架构中“中间”(通常称为前馈)层的维度。 - dropout (
float, optional, defaults to 0.0) — 嵌入层、编码器和池化器中所有全连接层的dropout概率。 - bias (
bool, optional, defaults toTrue) — 是否在线性层和层归一化层中使用偏置。 - initializer_range (
float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 - use_cache (
bool, 可选, 默认为True) — 模型是否应返回最后的键/值注意力(并非所有模型都使用)。 - n_codes_total (
int, optional, 默认为 8) — 预测的音频码本总数。用于精细声学子模型。 - n_codes_given (
int, optional, 默认为 1) — 在粗糙声学子模型中预测的音频码本数量。用于声学子模型。
这是用于存储BarkFineModel配置的配置类。它用于根据指定的参数实例化模型,定义模型架构。使用默认值实例化配置将产生与Bark suno/bark架构类似的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import BarkFineConfig, BarkFineModel
>>> # Initializing a Bark sub-module style configuration
>>> configuration = BarkFineConfig()
>>> # Initializing a model (with random weights) from the suno/bark style configuration
>>> model = BarkFineModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configBarkSemanticConfig
类 transformers.BarkSemanticConfig
< source >( block_size = 1024 input_vocab_size = 10048 output_vocab_size = 10048 num_layers = 12 num_heads = 12 hidden_size = 768 dropout = 0.0 bias = True initializer_range = 0.02 use_cache = True **kwargs )
参数
- block_size (
int, optional, defaults to 1024) — 此模型可能使用的最大序列长度。通常将其设置为较大的值以防万一(例如,512 或 1024 或 2048)。 - input_vocab_size (
int, 可选, 默认为 10_048) — Bark 子模型的词汇表大小。定义了调用 BarkSemanticModel 时传递的inputs_ids可以表示的不同令牌的数量。默认为 10_048,但应根据所选的子模型仔细考虑。 - output_vocab_size (
int, 可选, 默认为 10_048) — Bark 子模型的输出词汇大小。定义了在传递 BarkSemanticModel 时,output_ids可以表示的不同令牌的数量。默认为 10_048,但应根据所选的子模型仔细考虑。 - num_layers (
int, optional, defaults to 12) — 给定子模型中的隐藏层数量。 - num_heads (
int, optional, defaults to 12) — Transformer架构中每个注意力层的注意力头数。 - hidden_size (
int, optional, 默认为 768) — 架构中“中间”(通常称为前馈)层的维度。 - dropout (
float, optional, defaults to 0.0) — 嵌入层、编码器和池化器中所有全连接层的dropout概率。 - bias (
bool, optional, defaults toTrue) — 是否在线性层和层归一化层中使用偏置。 - initializer_range (
float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 - use_cache (
bool, 可选, 默认为True) — 模型是否应返回最后的键/值注意力(并非所有模型都使用)。
这是用于存储BarkSemanticModel配置的配置类。它用于根据指定的参数实例化模型,定义模型架构。使用默认值实例化配置将产生类似于Bark suno/bark架构的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import BarkSemanticConfig, BarkSemanticModel
>>> # Initializing a Bark sub-module style configuration
>>> configuration = BarkSemanticConfig()
>>> # Initializing a model (with random weights) from the suno/bark style configuration
>>> model = BarkSemanticModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config