BEiT
概述
BEiT模型由Hangbo Bao、Li Dong和Furu Wei在BEiT: BERT Pre-Training of Image Transformers中提出。受BERT启发,BEiT是第一篇使视觉变换器(ViTs)的自监督预训练优于监督预训练的论文。与预训练模型以预测图像的类别(如原始ViT论文中所做的那样)不同,BEiT模型被预训练以从OpenAI的DALL-E模型的代码本中预测视觉标记,给定被遮蔽的补丁。
论文的摘要如下:
我们介绍了一种自监督的视觉表示模型BEiT,它代表来自图像变换器的双向编码器表示。继自然语言处理领域开发的BERT之后,我们提出了一种掩码图像建模任务来预训练视觉变换器。具体来说,在我们的预训练中,每个图像有两个视图,即图像块(如16x16像素)和视觉标记(即离散标记)。我们首先将原始图像“标记化”为视觉标记。然后我们随机掩码一些图像块并将它们输入到骨干变换器中。预训练的目标是基于损坏的图像块恢复原始视觉标记。在预训练BEiT之后,我们通过在预训练编码器上附加任务层直接在下游任务上微调模型参数。图像分类和语义分割的实验结果表明,我们的模型与之前的预训练方法相比取得了竞争性的结果。例如,基础大小的BEiT在ImageNet-1K上达到了83.2%的top-1准确率,显著优于相同设置下的从头开始的DeiT训练(81.8%)。此外,仅使用ImageNet-1K的大尺寸BEiT获得了86.3%的准确率,甚至优于在ImageNet-22K上进行监督预训练的ViT-L(85.2%)。
该模型由nielsr贡献。该模型的JAX/FLAX版本由kamalkraj贡献。原始代码可以在这里找到。
使用提示
- BEiT模型是常规的视觉变换器,但以自监督的方式进行预训练,而不是监督学习。在ImageNet-1K和CIFAR-100上进行微调时,它们优于原始模型(ViT)以及数据高效的图像变换器(DeiT)。您可以查看有关推理以及在自定义数据上进行微调的演示笔记本这里(您只需将ViTFeatureExtractor替换为BeitImageProcessor,并将ViTForImageClassification替换为BeitForImageClassification)。
- 还有一个演示笔记本可用,展示了如何将DALL-E的图像分词器与BEiT结合使用以执行掩码图像建模。你可以在这里找到它here。
- 由于BEiT模型期望每张图像具有相同的大小(分辨率),可以使用 BeitImageProcessor来调整(或重新缩放)和归一化图像以适应模型。
- 预训练或微调期间使用的补丁分辨率和图像分辨率都反映在每个检查点的名称中。例如,
microsoft/beit-base-patch16-224指的是一个基础大小的架构,补丁分辨率为16x16,微调分辨率为224x224。所有检查点都可以在hub上找到。 - 可用的检查点要么是(1)仅在ImageNet-22k(包含1400万张图像和22k个类别的集合)上预训练,(2)也在ImageNet-22k上微调,或者(3)也在ImageNet-1k(也称为ILSVRC 2012,包含130万张图像和1000个类别的集合)上微调。
- BEiT 使用了相对位置嵌入,灵感来自 T5 模型。在预训练期间,作者在多个自注意力层之间共享了相对位置偏差。在微调期间,每一层的相对位置偏差都用预训练后获得的共享相对位置偏差进行初始化。请注意,如果要从头开始预训练模型,需要将
use_relative_position_bias或 BeitConfig 的use_relative_position_bias属性设置为True,以便添加位置嵌入。
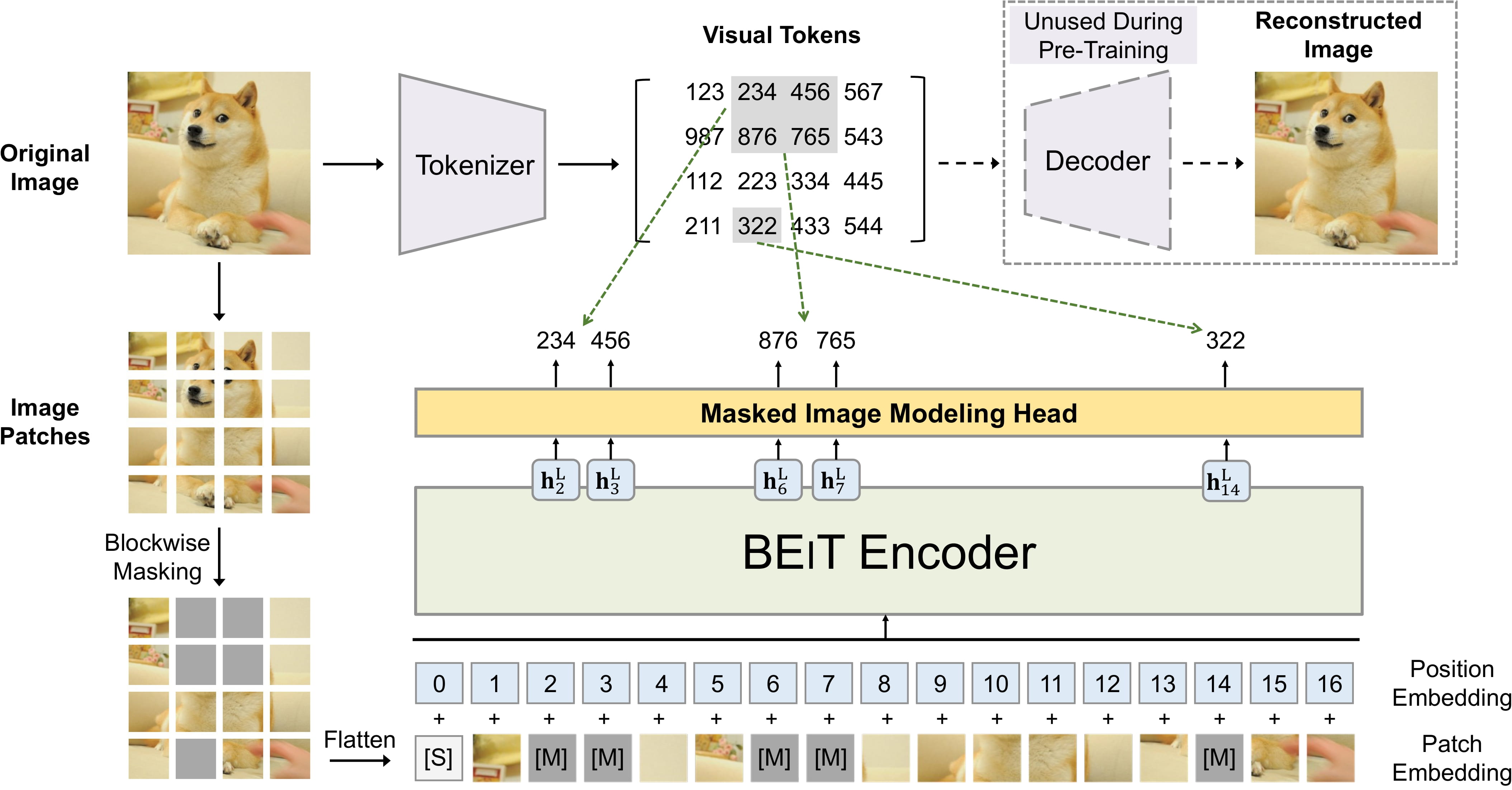 BEiT pre-training. Taken from the original paper.
BEiT pre-training. Taken from the original paper. 资源
一份官方的Hugging Face和社区(由🌎表示)资源列表,帮助您开始使用BEiT。
- BeitForImageClassification 由这个 示例脚本 和 笔记本 支持。
- 另请参阅:图像分类任务指南
语义分割
如果您有兴趣提交资源以包含在此处,请随时打开一个 Pull Request,我们将进行审核!理想情况下,资源应展示一些新内容,而不是重复现有资源。
BEiT 特定输出
类 transformers.models.beit.modeling_beit.BeitModelOutputWithPooling
< source >( last_hidden_state: FloatTensor = None pooler_output: FloatTensor = None hidden_states: typing.Optional[typing.Tuple[torch.FloatTensor, ...]] = None attentions: typing.Optional[typing.Tuple[torch.FloatTensor, ...]] = None )
参数
- last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。 - pooler_output (
torch.FloatTensorof shape(batch_size, hidden_size)) — 如果config.use_mean_pooling设置为True,则返回补丁标记的最后一层隐藏状态的平均值(不包括[CLS]标记)。如果设置为False,则返回[CLS]标记的最终隐藏状态。 - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).模型在每一层输出处的隐藏状态加上初始嵌入输出。
- attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).注意力权重在注意力softmax之后,用于计算自注意力头中的加权平均值。
用于BeitModel输出的类。
类 transformers.models.beit.modeling_flax_beit.FlaxBeitModelOutputWithPooling
< source >( last_hidden_state: 数组 = 无 pooler_output: 数组 = 无 hidden_states: typing.Optional[typing.Tuple[jax.Array]] = 无 attentions: typing.Optional[typing.Tuple[jax.Array]] = 无 )
参数
- last_hidden_state (
jnp.ndarrayof shape(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。 - pooler_output (
jnp.ndarrayof shape(batch_size, hidden_size)) — 如果config.use_mean_pooling设置为True,则返回补丁标记的最后一层隐藏状态的平均值(不包括[CLS]标记)。如果设置为False,则返回[CLS]标记的最终隐藏状态。 - hidden_states (
tuple(jnp.ndarray), 可选, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) —jnp.ndarray的元组(一个用于嵌入的输出 + 一个用于每一层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上 初始嵌入输出。 - 注意力 (
tuple(jnp.ndarray), 可选, 当传递output_attentions=True或config.output_attentions=True时返回) —jnp.ndarray的元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力权重在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
用于FlaxBeitModel输出的类。
BeitConfig
类 transformers.BeitConfig
< source >( vocab_size = 8192 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.0 attention_probs_dropout_prob = 0.0 initializer_range = 0.02 layer_norm_eps = 1e-12 image_size = 224 patch_size = 16 num_channels = 3 use_mask_token = False use_absolute_position_embeddings = False use_relative_position_bias = False use_shared_relative_position_bias = False layer_scale_init_value = 0.1 drop_path_rate = 0.1 use_mean_pooling = True pool_scales = [1, 2, 3, 6] use_auxiliary_head = True auxiliary_loss_weight = 0.4 auxiliary_channels = 256 auxiliary_num_convs = 1 auxiliary_concat_input = False semantic_loss_ignore_index = 255 out_features = None out_indices = None add_fpn = False reshape_hidden_states = True **kwargs )
参数
- vocab_size (
int, optional, 默认为 8192) — BEiT 模型的词汇表大小。定义了在预训练期间可以使用的不同图像标记的数量。 - hidden_size (
int, optional, 默认为 768) — 编码器层和池化层的维度。 - num_hidden_layers (
int, optional, 默认为 12) — Transformer 编码器中的隐藏层数量。 - num_attention_heads (
int, optional, defaults to 12) — Transformer编码器中每个注意力层的注意力头数。 - intermediate_size (
int, optional, 默认为 3072) — Transformer 编码器中“中间”(即前馈)层的维度。 - hidden_act (
str或function, 可选, 默认为"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"selu"和"gelu_new"。 - hidden_dropout_prob (
float, 可选, 默认为 0.0) — 嵌入层、编码器和池化器中所有全连接层的 dropout 概率。 - attention_probs_dropout_prob (
float, optional, 默认为 0.0) — 注意力概率的丢弃比例。 - initializer_range (
float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 - layer_norm_eps (
float, optional, defaults to 1e-12) — 层归一化层使用的epsilon值。 - image_size (
int, optional, 默认为 224) — 每张图片的大小(分辨率)。 - patch_size (
int, optional, defaults to 16) — 每个补丁的大小(分辨率)。 - num_channels (
int, optional, defaults to 3) — 输入通道的数量。 - use_mask_token (
bool, 可选, 默认为False) — 是否使用掩码标记进行掩码图像建模. - use_absolute_position_embeddings (
bool, 可选, 默认为False) — 是否使用BERT风格的绝对位置嵌入. - use_relative_position_bias (
bool, optional, defaults toFalse) — 是否在自注意力层中使用T5风格的相对位置嵌入。 - use_shared_relative_position_bias (
bool, optional, defaults toFalse) — 是否在Transformer的所有自注意力层中使用相同的相对位置嵌入。 - layer_scale_init_value (
float, optional, 默认为 0.1) — 用于自注意力层的缩放。基础模型为 0.1,大型模型为 1e-5。设置为 0 以禁用层缩放。 - drop_path_rate (
float, optional, 默认为 0.1) — 每个样本的随机深度率(当应用于残差层的主路径时)。 - use_mean_pooling (
bool, 可选, 默认为True) — 是否在应用分类头之前,对补丁的最终隐藏状态进行平均池化,而不是使用CLS标记的最终隐藏状态。 - pool_scales (
Tuple[int], 可选, 默认为[1, 2, 3, 6]) — 在应用于最后一个特征图的池化金字塔模块中使用的池化比例。 - use_auxiliary_head (
bool, optional, defaults toTrue) — 是否在训练期间使用辅助头。 - auxiliary_loss_weight (
float, optional, defaults to 0.4) — 辅助头的交叉熵损失的权重。 - auxiliary_channels (
int, optional, defaults to 256) — 辅助头中使用的通道数。 - auxiliary_num_convs (
int, optional, defaults to 1) — 在辅助头中使用的卷积层数量。 - auxiliary_concat_input (
bool, optional, defaults toFalse) — 是否在分类层之前将辅助头的输出与输入连接起来。 - semantic_loss_ignore_index (
int, optional, 默认为 255) — 语义分割模型的损失函数忽略的索引。 - out_features (
List[str], 可选) — 如果用作骨干网络,输出特征的列表。可以是"stem","stage1","stage2"等。 (取决于模型有多少个阶段)。如果未设置且out_indices已设置,将默认为相应的阶段。如果未设置且out_indices也未设置,将默认为最后一个阶段。必须与stage_names属性中定义的顺序相同。 - out_indices (
List[int], optional) — 如果用作骨干网络,输出特征的索引列表。可以是0、1、2等(取决于模型有多少个阶段)。如果未设置且out_features已设置,将默认为相应的阶段。如果未设置且out_features也未设置,将默认为最后一个阶段。必须与stage_names属性中定义的顺序相同。 - add_fpn (
bool, 可选, 默认为False) — 是否在骨干网络中添加FPN。仅对BeitBackbone相关。 - reshape_hidden_states (
bool, optional, defaults toTrue) — 是否将特征图重塑为形状为(batch_size, hidden_size, height, width)的4D张量,如果模型被用作骨干网络。如果为False,特征图将是形状为(batch_size, seq_len, hidden_size)的3D张量。仅对BeitBackbone相关。
这是用于存储BeitModel配置的配置类。它用于根据指定的参数实例化一个BEiT模型,定义模型架构。使用默认值实例化配置将产生与BEiT microsoft/beit-base-patch16-224-pt22k架构类似的配置。
示例:
>>> from transformers import BeitConfig, BeitModel
>>> # Initializing a BEiT beit-base-patch16-224-pt22k style configuration
>>> configuration = BeitConfig()
>>> # Initializing a model (with random weights) from the beit-base-patch16-224-pt22k style configuration
>>> model = BeitModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configBeitFeatureExtractor
post_process_semantic_segmentation
< source >( outputs target_sizes: typing.List[typing.Tuple] = None ) → 语义分割
参数
- 输出 (BeitForSemanticSegmentation) — 模型的原始输出。
- target_sizes (
List[Tuple]长度为batch_size, 可选) — 对应于每个预测请求的最终大小(高度,宽度)的元组列表。如果未设置,预测将不会调整大小。
返回
语义分割
List[torch.Tensor] 长度为 batch_size,其中每个项目是一个形状为 (高度, 宽度) 的语义分割图,对应于 target_sizes 条目(如果指定了 target_sizes)。每个 torch.Tensor 的每个条目对应于一个语义类别 ID。
将BeitForSemanticSegmentation的输出转换为语义分割图。仅支持PyTorch。
BeitImageProcessor
类 transformers.BeitImageProcessor
< source >( do_resize: bool = True size: typing.Dict[str, int] = None resample: Resampling =
参数
- do_resize (
bool, 可选, 默认为True) — 是否将图像的(高度,宽度)尺寸调整为指定的size。可以在preprocess方法中通过do_resize参数覆盖此设置。 - size (
Dict[str, int]可选, 默认为{"height" -- 256, "width": 256}): 调整大小后输出图像的尺寸。可以在preprocess方法中通过size参数覆盖此设置。 - resample (
PILImageResampling, 可选, 默认为Resampling.BICUBIC) — 如果调整图像大小,则使用的重采样过滤器。可以在preprocess方法中通过resample参数覆盖。 - do_center_crop (
bool, 可选, 默认为True) — 是否对图像进行中心裁剪。如果输入尺寸在任何一边小于crop_size,图像将用0填充,然后进行中心裁剪。可以在preprocess方法中通过do_center_crop参数覆盖此设置。 - crop_size (
Dict[str, int], optional, defaults to{"height" -- 224, "width": 224}): 应用中心裁剪时的期望输出大小。仅在do_center_crop设置为True时有效。 可以通过preprocess方法中的crop_size参数进行覆盖。 - rescale_factor (
int或float, 可选, 默认为1/255) — 如果重新缩放图像,则使用的缩放因子。可以在preprocess方法中通过rescale_factor参数覆盖此值。 - do_rescale (
bool, 可选, 默认为True) — 是否通过指定的比例rescale_factor重新缩放图像。可以在preprocess方法中通过do_rescale参数覆盖此设置。 - do_normalize (
bool, 可选, 默认为True) — 是否对图像进行归一化。可以在preprocess方法中通过do_normalize参数进行覆盖。 - image_mean (
float或List[float], 可选, 默认为IMAGENET_STANDARD_MEAN) — 如果对图像进行归一化,则使用的均值。这是一个浮点数或与图像通道数长度相同的浮点数列表。可以通过preprocess方法中的image_mean参数进行覆盖。 - image_std (
float或List[float], 可选, 默认为IMAGENET_STANDARD_STD) — 如果对图像进行归一化,则使用的标准差。这是一个浮点数或图像通道数长度的浮点数列表。可以通过preprocess方法中的image_std参数进行覆盖。 - do_reduce_labels (
bool, 可选, 默认为False) — 是否将分割图的所有标签值减1。通常用于数据集中0用于背景,而背景本身不包含在数据集的所有类别中(例如ADE20k)。背景标签将被替换为255。可以在preprocess方法中通过do_reduce_labels参数覆盖此设置。
构建一个BEiT图像处理器。
预处理
< source >( images: typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), typing.List[ForwardRef('PIL.Image.Image')], typing.List[numpy.ndarray], typing.List[ForwardRef('torch.Tensor')]] segmentation_maps: typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), typing.List[ForwardRef('PIL.Image.Image')], typing.List[numpy.ndarray], typing.List[ForwardRef('torch.Tensor')], NoneType] = None do_resize: bool = None size: typing.Dict[str, int] = None resample: Resampling = None do_center_crop: bool = None crop_size: typing.Dict[str, int] = None do_rescale: bool = None rescale_factor: float = None do_normalize: bool = None image_mean: typing.Union[float, typing.List[float], NoneType] = None image_std: typing.Union[float, typing.List[float], NoneType] = None do_reduce_labels: typing.Optional[bool] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None data_format: ChannelDimension =
参数
- 图像 (
ImageInput) — 要预处理的图像。期望输入单个或批量的图像,像素值范围在0到255之间。如果传入的图像像素值在0到1之间,请设置do_rescale=False. - segmentation_maps (
ImageInput, 可选) — 用于预处理的语义分割图。期望输入单个或批量的图像,像素值范围为0到255。如果输入的图像像素值在0到1之间,请设置do_rescale=False. - do_resize (
bool, optional, defaults toself.do_resize) — 是否调整图像大小. - size (
Dict[str, int], optional, defaults toself.size) — 调整大小后图像的尺寸。 - resample (
int, 可选, 默认为self.resample) — 如果调整图像大小,则使用的重采样过滤器。这可以是枚举PILImageResampling之一,仅在do_resize设置为True时有效。 - do_center_crop (
bool, optional, defaults toself.do_center_crop) — 是否对图像进行中心裁剪。 - crop_size (
Dict[str, int], 可选, 默认为self.crop_size) — 图像中心裁剪后的大小。如果图像的某一边小于crop_size,它将被填充零然后裁剪 - do_rescale (
bool, optional, defaults toself.do_rescale) — 是否将图像值缩放到 [0 - 1] 之间。 - rescale_factor (
float, 可选, 默认为self.rescale_factor) — 如果do_rescale设置为True,则用于重新缩放图像的重新缩放因子。 - do_normalize (
bool, optional, defaults toself.do_normalize) — 是否对图像进行归一化处理。 - image_mean (
float或List[float], 可选, 默认为self.image_mean) — 图像均值. - image_std (
float或List[float], 可选, 默认为self.image_std) — 图像标准差. - do_reduce_labels (
bool, optional, defaults toself.do_reduce_labels) — 是否将所有分割图的标签值减少1。通常用于背景使用0的数据集,且背景本身不包含在数据集的所有类别中(例如ADE20k)。背景标签将被替换为255。 - return_tensors (
str或TensorType, 可选) — 返回的张量类型。可以是以下之一:- 未设置:返回一个
np.ndarray列表。 TensorType.TENSORFLOW或'tf':返回一个类型为tf.Tensor的批次。TensorType.PYTORCH或'pt':返回一个类型为torch.Tensor的批次。TensorType.NUMPY或'np':返回一个类型为np.ndarray的批次。TensorType.JAX或'jax':返回一个类型为jax.numpy.ndarray的批次。
- 未设置:返回一个
- data_format (
ChannelDimension或str, 可选, 默认为ChannelDimension.FIRST) — 输出图像的通道维度格式。可以是以下之一:"channels_first"或ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。"channels_last"或ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。- 未设置:使用输入图像的通道维度格式。
- input_data_format (
ChannelDimension或str, 可选) — 输入图像的通道维度格式。如果未设置,则从输入图像推断通道维度格式。可以是以下之一:"channels_first"或ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。"channels_last"或ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。"none"或ChannelDimension.NONE: 图像格式为 (height, width)。
预处理一张图像或一批图像。
post_process_semantic_segmentation
< source >( outputs target_sizes: typing.List[typing.Tuple] = None ) → 语义分割
参数
- 输出 (BeitForSemanticSegmentation) — 模型的原始输出。
- target_sizes (
List[Tuple]长度为batch_size, 可选) — 对应于每个预测请求的最终大小(高度,宽度)的元组列表。如果未设置,预测将不会调整大小。
返回
语义分割
List[torch.Tensor] 长度为 batch_size,其中每个项目是一个形状为 (高度, 宽度) 的语义分割图,对应于 target_sizes 条目(如果指定了 target_sizes)。每个 torch.Tensor 的每个条目对应于一个语义类别 ID。
将BeitForSemanticSegmentation的输出转换为语义分割图。仅支持PyTorch。
BeitModel
类 transformers.BeitModel
< source >( config: BeitConfig add_pooling_layer: bool = True )
参数
- config (BeitConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,仅加载配置。查看 from_pretrained() 方法以加载模型权重。
基本的Beit模型转换器输出原始的隐藏状态,没有任何特定的头部。 这个模型是一个PyTorch torch.nn.Module 子类。将其用作常规的PyTorch模块,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( pixel_values: Tensor bool_masked_pos: typing.Optional[torch.BoolTensor] = None head_mask: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None interpolate_pos_encoding: bool = False return_dict: typing.Optional[bool] = None ) → transformers.models.beit.modeling_beit.BeitModelOutputWithPooling or tuple(torch.FloatTensor)
参数
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用AutoImageProcessor获取。详情请参见 BeitImageProcessor.call(). - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - interpolate_pos_encoding (
bool, optional, defaults toFalse) — 是否插值预训练的位置编码. - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - bool_masked_pos (
torch.BoolTensorof shape(batch_size, num_patches), optional) — 布尔掩码位置。指示哪些补丁被掩码(1)和哪些没有被掩码(0)。
返回
transformers.models.beit.modeling_beit.BeitModelOutputWithPooling 或 tuple(torch.FloatTensor)
一个 transformers.models.beit.modeling_beit.BeitModelOutputWithPooling 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(BeitConfig)和输入。
-
last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。 -
pooler_output (
torch.FloatTensor形状为(batch_size, hidden_size)) — 如果 config.use_mean_pooling 设置为 True,则返回补丁标记(不包括 [CLS] 标记)的最后一层隐藏状态的平均值。如果设置为 False,则返回 [CLS] 标记的最终隐藏状态。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入的输出 + 一个用于每层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
BeitModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, BeitModel
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image", trust_remote_code=True)
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("microsoft/beit-base-patch16-224-pt22k")
>>> model = BeitModel.from_pretrained("microsoft/beit-base-patch16-224-pt22k")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 197, 768]BeitForMaskedImageModeling
类 transformers.BeitForMaskedImageModeling
< source >( config: BeitConfig )
参数
- config (BeitConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
Beit 模型转换器,顶部带有“语言”建模头。BEiT 通过预测向量量化变分自编码器(VQ-VAE)的视觉标记来进行掩码图像建模,而其他视觉模型如 ViT 和 DeiT 则预测 RGB 像素值。因此,此类与 AutoModelForMaskedImageModeling 不兼容,因此如果您希望使用 BEiT 进行掩码图像建模,您将需要直接使用 BeitForMaskedImageModeling。 此模型是 PyTorch torch.nn.Module 的子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取与一般使用和行为相关的所有信息。
前进
< source >( pixel_values: typing.Optional[torch.Tensor] = None bool_masked_pos: typing.Optional[torch.BoolTensor] = None head_mask: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None interpolate_pos_encoding: bool = False return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.MaskedLMOutput 或 tuple(torch.FloatTensor)
参数
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用AutoImageProcessor获取。详情请参见 BeitImageProcessor.call(). - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - interpolate_pos_encoding (
bool, optional, defaults toFalse) — 是否插值预训练的位置编码。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - bool_masked_pos (
torch.BoolTensorof shape(batch_size, num_patches)) — 布尔掩码位置。指示哪些补丁被掩码(1)和哪些没有被掩码(0)。 - labels (
torch.LongTensor形状为(batch_size,), 可选) — 用于计算图像分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.MaskedLMOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.MaskedLMOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(BeitConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 掩码语言建模(MLM)损失。 -
logits (
torch.FloatTensor形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
BeitForMaskedImageModeling 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, BeitForMaskedImageModeling
>>> import torch
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("microsoft/beit-base-patch16-224-pt22k")
>>> model = BeitForMaskedImageModeling.from_pretrained("microsoft/beit-base-patch16-224-pt22k")
>>> num_patches = (model.config.image_size // model.config.patch_size) ** 2
>>> pixel_values = image_processor(images=image, return_tensors="pt").pixel_values
>>> # create random boolean mask of shape (batch_size, num_patches)
>>> bool_masked_pos = torch.randint(low=0, high=2, size=(1, num_patches)).bool()
>>> outputs = model(pixel_values, bool_masked_pos=bool_masked_pos)
>>> loss, logits = outputs.loss, outputs.logits
>>> list(logits.shape)
[1, 196, 8192]BeitForImageClassification
类 transformers.BeitForImageClassification
< source >( config: BeitConfig )
参数
- config (BeitConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
Beit模型转换器,顶部带有图像分类头(在补丁标记的最终隐藏状态的平均值之上的线性层),例如用于ImageNet。
该模型是一个PyTorch torch.nn.Module 子类。将其用作常规的PyTorch模块,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( pixel_values: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None interpolate_pos_encoding: bool = False return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.ImageClassifierOutput 或 tuple(torch.FloatTensor)
参数
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用AutoImageProcessor获取。详情请参见 BeitImageProcessor.call(). - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - interpolate_pos_encoding (
bool, optional, defaults toFalse) — 是否插值预训练的位置编码. - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size,), optional) — 用于计算图像分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.ImageClassifierOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.ImageClassifierOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(BeitConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 分类(或回归,如果 config.num_labels==1)损失。 -
logits (
torch.FloatTensor形状为(batch_size, config.num_labels)) — 分类(或回归,如果 config.num_labels==1)得分(在 SoftMax 之前)。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每个阶段的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每个阶段输出的隐藏状态 (也称为特征图)。 -
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每个层一个)形状为(batch_size, num_heads, patch_size, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
BeitForImageClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, BeitForImageClassification
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image", trust_remote_code=True)
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("microsoft/beit-base-patch16-224")
>>> model = BeitForImageClassification.from_pretrained("microsoft/beit-base-patch16-224")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
tabby, tabby catBeitForSemanticSegmentation
类 transformers.BeitForSemanticSegmentation
< source >( config: BeitConfig )
参数
- config (BeitConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
Beit模型转换器,顶部带有语义分割头,例如用于ADE20k、CityScapes。
该模型是一个PyTorch torch.nn.Module 子类。将其用作常规的PyTorch模块,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( pixel_values: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None interpolate_pos_encoding: bool = False return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.SemanticSegmenterOutput 或 tuple(torch.FloatTensor)
参数
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用AutoImageProcessor获取。详情请参见 BeitImageProcessor.call(). - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - interpolate_pos_encoding (
bool, optional, defaults toFalse) — 是否插值预训练的位置编码. - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size, height, width), optional) — 用于计算损失的真实语义分割图。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.SemanticSegmenterOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.SemanticSegmenterOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,取决于配置(BeitConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,), 可选, 当提供labels时返回) — 分类(或回归,如果 config.num_labels==1)损失。 -
logits (
torch.FloatTensor形状为(batch_size, config.num_labels, logits_height, logits_width)) — 每个像素的分类分数。返回的 logits 不一定与作为输入传递的
pixel_values大小相同。这是 为了避免在用户需要将 logits 调整回原始图像大小时进行两次插值并损失一些质量。您应始终检查 logits 的形状并根据需要调整大小。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层的输出)形状为(batch_size, patch_size, hidden_size)。模型在每层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个)形状为(batch_size, num_heads, patch_size, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
BeitForSemanticSegmentation 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, BeitForSemanticSegmentation
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("microsoft/beit-base-finetuned-ade-640-640")
>>> model = BeitForSemanticSegmentation.from_pretrained("microsoft/beit-base-finetuned-ade-640-640")
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # logits are of shape (batch_size, num_labels, height, width)
>>> logits = outputs.logitsFlaxBeitModel
类 transformers.FlaxBeitModel
< source >( config: BeitConfig input_shape = None seed: int = 0 dtype: dtype =
参数
- config (BeitConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
- dtype (
jax.numpy.dtype, optional, defaults tojax.numpy.float32) — The data type of the computation. Can be one ofjax.numpy.float32,jax.numpy.float16(on GPUs) andjax.numpy.bfloat16(on TPUs).这可以用于在GPU或TPU上启用混合精度训练或半精度推理。如果指定,所有计算将使用给定的
dtype执行。请注意,这仅指定了计算的数据类型,并不影响模型参数的数据类型。
Beit模型的基本转换器输出原始隐藏状态,顶部没有任何特定的头部。
该模型继承自FlaxPreTrainedModel。请查看超类文档,了解库为其所有模型实现的通用方法(如下载、保存和从PyTorch模型转换权重)。
该模型也是一个 flax.linen.Module 子类。将其作为 常规的 Flax linen 模块使用,并参考 Flax 文档以获取与一般使用和行为相关的所有信息。
最后,该模型支持JAX的固有特性,例如:
__call__
< source >( pixel_values bool_masked_pos = 无 params: 字典 = 无 dropout_rng: tuple(torch.FloatTensor)
返回
transformers.models.beit.modeling_flax_beit.FlaxBeitModelOutputWithPooling 或 tuple(torch.FloatTensor)
一个 transformers.models.beit.modeling_flax_beit.FlaxBeitModelOutputWithPooling 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(
- last_hidden_state (
jnp.ndarray形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层的隐藏状态序列。 - pooler_output (
jnp.ndarray形状为(batch_size, hidden_size)) — 如果 config.use_mean_pooling 设置为 True,则返回补丁标记(不包括 [CLS] 标记)的最后一层隐藏状态的平均值。如果设置为 False,则返回 [CLS] 标记的最终隐藏状态。 - hidden_states (
tuple(jnp.ndarray), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由jnp.ndarray组成的元组(一个用于嵌入层的输出,一个用于每一层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上初始嵌入输出。 - attentions (
tuple(jnp.ndarray), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由jnp.ndarray组成的元组(每一层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力权重在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
FlaxBeitPreTrainedModel 的 forward 方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, FlaxBeitModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("microsoft/beit-base-patch16-224-pt22k-ft22k")
>>> model = FlaxBeitModel.from_pretrained("microsoft/beit-base-patch16-224-pt22k-ft22k")
>>> inputs = image_processor(images=image, return_tensors="np")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateFlaxBeitForMaskedImageModeling
类 transformers.FlaxBeitForMaskedImageModeling
< source >( config: BeitConfig input_shape = None seed: int = 0 dtype: dtype =
参数
- config (BeitConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
- dtype (
jax.numpy.dtype, optional, defaults tojax.numpy.float32) — The data type of the computation. Can be one ofjax.numpy.float32,jax.numpy.float16(on GPUs) andjax.numpy.bfloat16(on TPUs).这可以用于在GPU或TPU上启用混合精度训练或半精度推理。如果指定,所有计算将使用给定的
dtype执行。请注意,这仅指定了计算的数据类型,并不影响模型参数的数据类型。
Beit 模型转换器,顶部带有“语言”建模头(用于预测视觉标记)。
该模型继承自FlaxPreTrainedModel。请查看超类文档,了解库为其所有模型实现的通用方法(如下载、保存和从PyTorch模型转换权重)。
该模型也是一个 flax.linen.Module 子类。将其作为 常规的 Flax linen 模块使用,并参考 Flax 文档以获取与一般使用和行为相关的所有信息。
最后,该模型支持JAX的固有特性,例如:
__call__
< source >( pixel_values bool_masked_pos = 无 params: 字典 = 无 dropout_rng: tuple(torch.FloatTensor)
返回
transformers.modeling_flax_outputs.FlaxMaskedLMOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_flax_outputs.FlaxMaskedLMOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(
-
logits (
jnp.ndarray形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
hidden_states (
tuple(jnp.ndarray), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由jnp.ndarray组成的元组(一个用于嵌入的输出 + 一个用于每一层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(jnp.ndarray), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由jnp.ndarray组成的元组(每一层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
FlaxBeitPreTrainedModel 的 forward 方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
bool_masked_pos (numpy.ndarray 形状为 (batch_size, num_patches)):
布尔掩码位置。指示哪些补丁被掩码(1),哪些没有被掩码(0)。
示例:
>>> from transformers import AutoImageProcessor, BeitForMaskedImageModeling
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("microsoft/beit-base-patch16-224-pt22k")
>>> model = BeitForMaskedImageModeling.from_pretrained("microsoft/beit-base-patch16-224-pt22k")
>>> inputs = image_processor(images=image, return_tensors="np")
>>> outputs = model(**inputs)
>>> logits = outputs.logitsFlaxBeitForImageClassification
类 transformers.FlaxBeitForImageClassification
< source >( config: BeitConfig input_shape = None seed: int = 0 dtype: dtype =
参数
- config (BeitConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
- dtype (
jax.numpy.dtype, optional, defaults tojax.numpy.float32) — The data type of the computation. Can be one ofjax.numpy.float32,jax.numpy.float16(on GPUs) andjax.numpy.bfloat16(on TPUs).这可以用于在GPU或TPU上启用混合精度训练或半精度推理。如果指定,所有计算将使用给定的
dtype执行。请注意,这仅指定了计算的数据类型,并不影响模型参数的数据类型。
Beit模型转换器,顶部带有图像分类头(在补丁标记的最终隐藏状态的平均值之上的线性层),例如用于ImageNet。
该模型继承自FlaxPreTrainedModel。请查看超类文档,了解库为其所有模型实现的通用方法(如下载、保存和从PyTorch模型转换权重)。
该模型也是一个 flax.linen.Module 子类。将其作为 常规的 Flax linen 模块使用,并参考 Flax 文档以获取与一般使用和行为相关的所有信息。
最后,该模型支持JAX的固有特性,例如:
__call__
< source >( pixel_values bool_masked_pos = None params: dict = None dropout_rng: tuple(torch.FloatTensor)
返回
transformers.modeling_flax_outputs.FlaxSequenceClassifierOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_flax_outputs.FlaxSequenceClassifierOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(
-
logits (
jnp.ndarray形状为(batch_size, config.num_labels)) — 分类(或回归,如果 config.num_labels==1)得分(在 SoftMax 之前)。 -
hidden_states (
tuple(jnp.ndarray), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由jnp.ndarray组成的元组(一个用于嵌入的输出 + 一个用于每一层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(jnp.ndarray), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由jnp.ndarray组成的元组(每一层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
FlaxBeitPreTrainedModel 的 forward 方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoImageProcessor, FlaxBeitForImageClassification
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("microsoft/beit-base-patch16-224")
>>> model = FlaxBeitForImageClassification.from_pretrained("microsoft/beit-base-patch16-224")
>>> inputs = image_processor(images=image, return_tensors="np")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_class_idx = logits.argmax(-1).item()
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])