DiT
概述
DiT 是由李俊龙、徐一恒、吕腾超、崔磊、张超、魏福如提出的,发表在 DiT: Self-supervised Pre-training for Document Image Transformer 中。 DiT 将 BEiT(图像变换器的BERT预训练)的自监督目标应用于4200万张文档图像,从而在包括以下任务中取得了最先进的结果:
- 文档图像分类:RVL-CDIP 数据集(包含40万张图像,属于16个类别之一)。
- 文档布局分析:PubLayNet 数据集(一个包含超过360,000张文档图像的集合,通过自动解析PubMed XML文件构建)。
- 表格检测:ICDAR 2019 cTDaR 数据集(包含600张训练图像和240张测试图像)。
论文的摘要如下:
图像变换器最近在自然图像理解方面取得了显著进展,无论是使用监督(ViT、DeiT等)还是自监督(BEiT、MAE等)预训练技术。在本文中,我们提出了DiT,一种自监督预训练的文档图像变换器模型,使用大规模未标记的文本图像进行文档AI任务,这是至关重要的,因为由于缺乏人类标记的文档图像,目前不存在监督的对应物。我们将DiT作为各种基于视觉的文档AI任务的骨干网络,包括文档图像分类、文档布局分析以及表格检测。实验结果表明,自监督预训练的DiT模型在这些下游任务上取得了新的最先进结果,例如文档图像分类(91.11 → 92.69)、文档布局分析(91.0 → 94.9)和表格检测(94.23 → 96.55)。
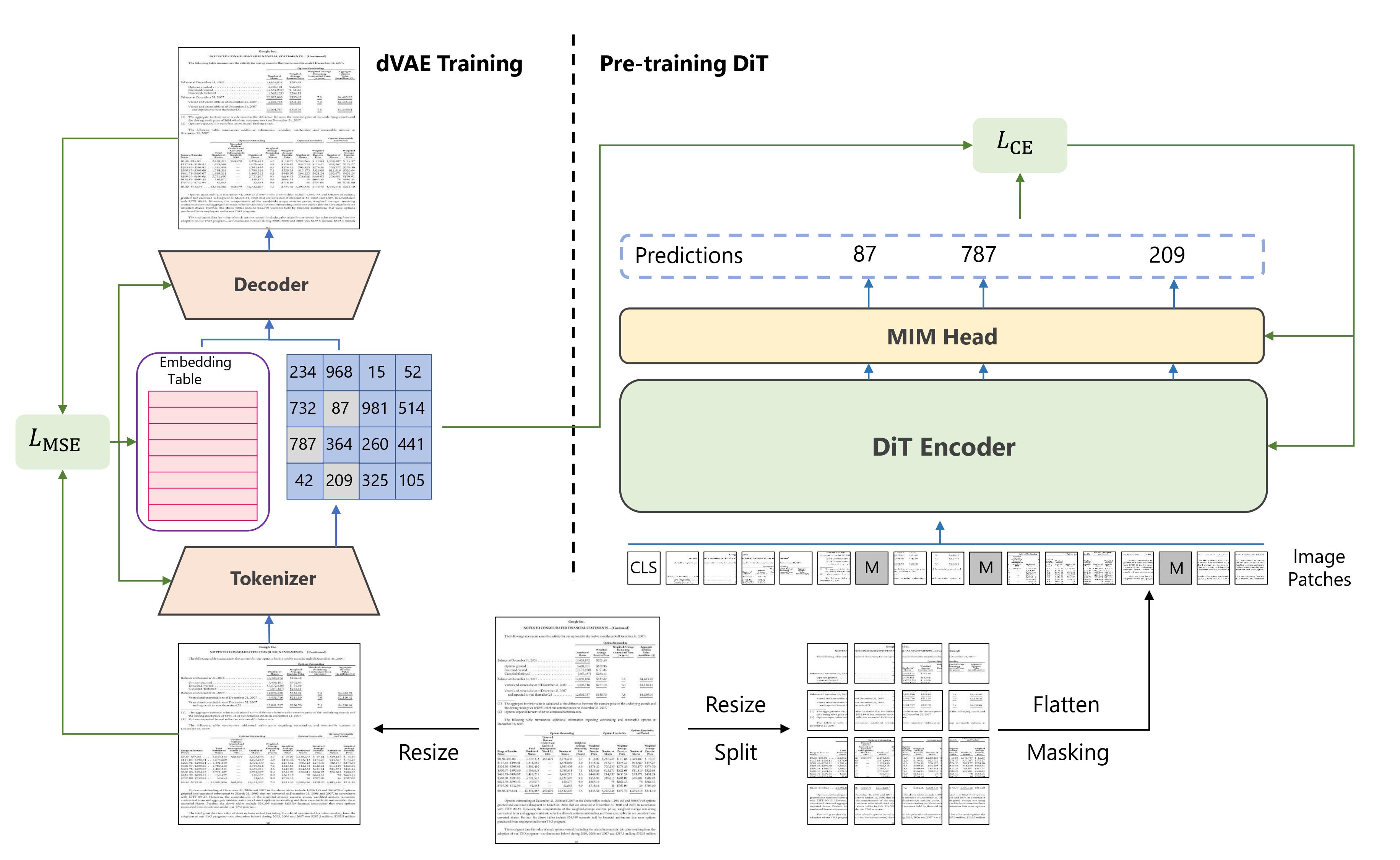 Summary of the approach. Taken from the [original paper](https://arxiv.org/abs/2203.02378).
Summary of the approach. Taken from the [original paper](https://arxiv.org/abs/2203.02378). 使用提示
可以直接使用AutoModel API中的DiT权重:
from transformers import AutoModel
model = AutoModel.from_pretrained("microsoft/dit-base")这将加载预训练的掩码图像建模模型。请注意,这不包括顶部的语言建模头,用于预测视觉标记。
要包含头部,你可以将权重加载到BeitForMaskedImageModeling模型中,如下所示:
from transformers import BeitForMaskedImageModeling
model = BeitForMaskedImageModeling.from_pretrained("microsoft/dit-base")你也可以从hub加载一个微调模型,如下所示:
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained("microsoft/dit-base-finetuned-rvlcdip")这个特定的检查点是在RVL-CDIP上进行微调的,这是一个重要的文档图像分类基准。 一个展示文档图像分类推理的笔记本可以在这里找到。
资源
以下是官方 Hugging Face 和社区(由🌎表示)提供的资源列表,帮助您开始使用 DiT。
- BeitForImageClassification 由这个 示例脚本 和 笔记本 支持。
如果您有兴趣提交资源以包含在此处,请随时打开一个 Pull Request,我们将进行审核!理想情况下,资源应展示一些新内容,而不是重复现有资源。
由于DiT的架构与BEiT相同,可以参考BEiT的文档页面获取所有提示、代码示例和笔记本。