OpenAI GPT2
概述
OpenAI GPT-2 模型由 Alec Radford、Jeffrey Wu、Rewon Child、David Luan、Dario Amodei 和 Ilya Sutskever 在 Language Models are Unsupervised Multitask Learners 中提出。它是一个因果(单向)的 transformer 模型,通过在一个约 40 GB 的文本数据语料库上进行语言建模预训练。
论文的摘要如下:
GPT-2 是一个基于 Transformer 的大型语言模型,拥有 15 亿个参数,训练于一个包含 800 万个网页的数据集[1]。GPT-2 的训练目标很简单:给定文本中的所有前面的单词,预测下一个单词。数据集的多样性使得这个简单的目标自然包含了跨多个领域的许多任务的演示。GPT-2 是 GPT 的直接扩展,参数数量超过 10 倍,并且训练数据量也超过 10 倍。
Write With Transformer 是一个由 Hugging Face 创建并托管的网络应用程序,展示了多个模型的生成能力。GPT-2 是其中之一,并且有五种不同的规模:small、medium、large、xl 以及 small 检查点的蒸馏版本:distilgpt-2。
使用提示
- GPT-2 是一个具有绝对位置嵌入的模型,因此通常建议在输入的右侧而不是左侧进行填充。
- GPT-2 是通过因果语言建模(CLM)目标进行训练的,因此在预测序列中的下一个标记方面非常强大。利用这一特性,GPT-2 可以生成语法连贯的文本,正如在 run_generation.py 示例脚本中所观察到的那样。
- 模型可以接受past_key_values(对于PyTorch)或past(对于TF)作为输入,这是先前计算的键/值注意力对。使用这个(past_key_values或past)值可以防止模型在文本生成上下文中重新计算预计算的值。对于PyTorch,请参阅GPT2Model.forward()方法的past_key_values参数,或对于TF,请参阅TFGPT2Model.call()方法的past参数以获取更多关于其使用的信息。
- 启用scale_attn_by_inverse_layer_idx和reorder_and_upcast_attn标志将应用来自Mistral的训练稳定性改进(仅适用于PyTorch)。
使用示例
generate() 方法可用于使用 GPT2 模型生成文本。
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> model = AutoModelForCausalLM.from_pretrained("gpt2")
>>> tokenizer = AutoTokenizer.from_pretrained("gpt2")
>>> prompt = "GPT2 is a model developed by OpenAI."
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
>>> gen_tokens = model.generate(
... input_ids,
... do_sample=True,
... temperature=0.9,
... max_length=100,
... )
>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]使用 Flash Attention 2
Flash Attention 2 是一个更快、优化的注意力分数计算版本,它依赖于 cuda 内核。
安装
首先,检查您的硬件是否与Flash Attention 2兼容。最新的兼容硬件列表可以在官方文档中找到。如果您的硬件不兼容Flash Attention 2,您仍然可以通过上述介绍的Better Transformer支持从注意力内核优化中受益。
接下来,安装最新版本的Flash Attention 2:
pip install -U flash-attn --no-build-isolation
用法
要使用Flash Attention 2加载模型,我们可以将参数attn_implementation="flash_attention_2"传递给.from_pretrained。我们还将以半精度(例如torch.float16)加载模型,因为这样几乎不会降低音频质量,但可以显著减少内存使用并加快推理速度:
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = AutoModelForCausalLM.from_pretrained("gpt2", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = AutoTokenizer.from_pretrained("gpt2")
>>> prompt = "def hello_world():"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]预期的加速
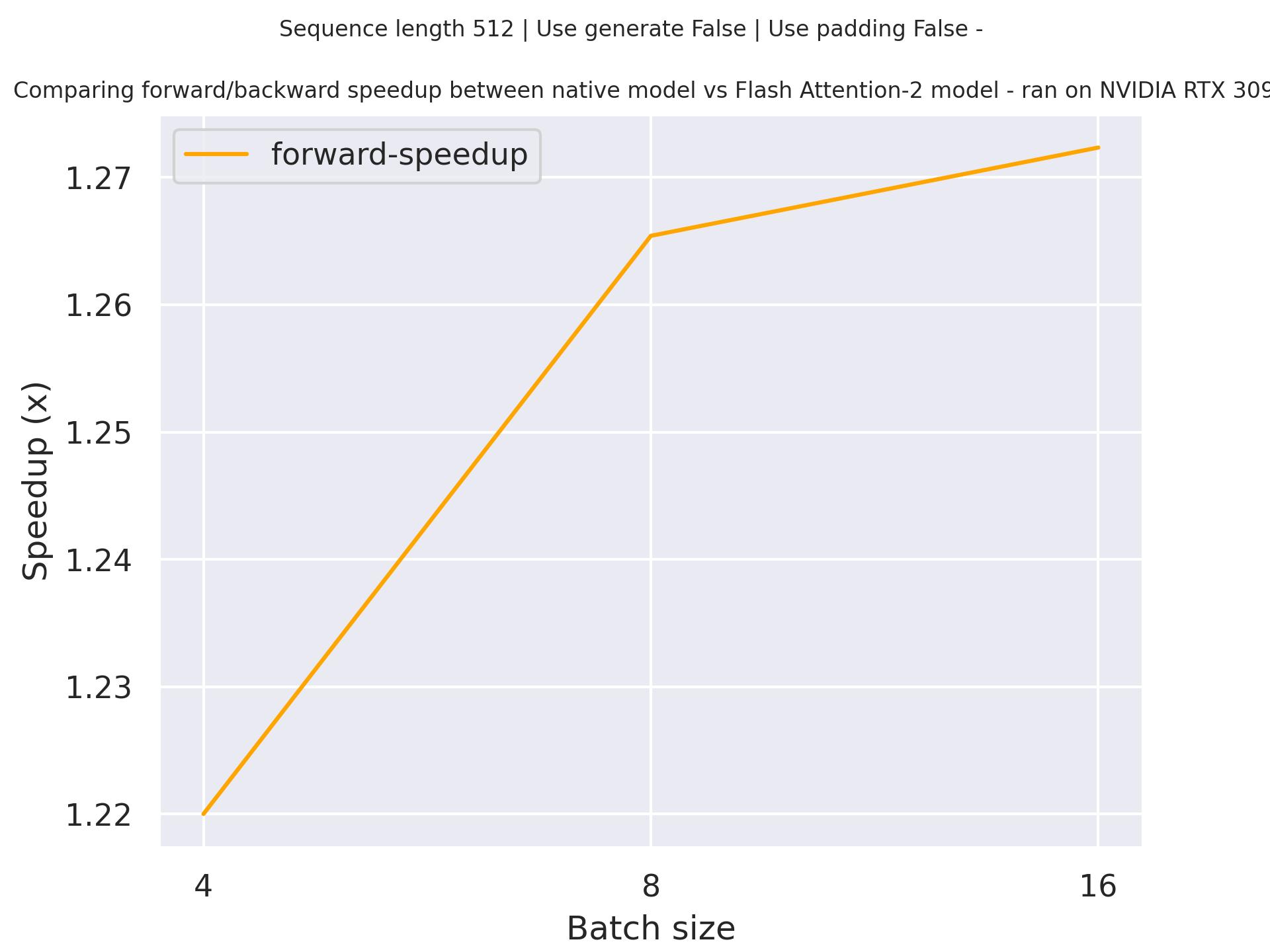
下面是一个预期的加速图,比较了使用gpt2检查点的transformers原生实现与使用序列长度为512的Flash Attention 2版本模型的纯推理时间。
使用缩放点积注意力 (SDPA)
PyTorch 包含一个原生的缩放点积注意力(SDPA)操作符,作为 torch.nn.functional 的一部分。这个函数
包含了几种实现,可以根据输入和使用的硬件进行应用。更多信息请参阅
官方文档
或 GPU 推理
页面。
默认情况下,当有可用实现时,SDPA 用于 torch>=2.1.1,但你也可以在 from_pretrained() 中设置 attn_implementation="sdpa" 来明确请求使用 SDPA。
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("gpt2", torch_dtype=torch.float16, attn_implementation="sdpa")
...为了获得最佳加速效果,我们建议以半精度加载模型(例如 torch.float16 或 torch.bfloat16)。
在本地基准测试(rtx3080ti-16GB,PyTorch 2.2.1,操作系统 Ubuntu 22.04)中,使用float16与
gpt2-large,我们在训练和推理过程中看到了以下加速效果。
训练
| 批量大小 | 序列长度 | 每批次时间(Eager - 秒) | 每批次时间(SDPA - 秒) | 加速百分比(%) | Eager 峰值内存(MB) | SDPA 峰值内存(MB) | 内存节省百分比(%) |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 0.039 | 0.032 | 23.042 | 3482.32 | 3494.62 | -0.352 |
| 1 | 256 | 0.073 | 0.059 | 25.15 | 3546.66 | 3552.6 | -0.167 |
| 1 | 512 | 0.155 | 0.118 | 30.96 | 4230.1 | 3665.59 | 15.4 |
| 1 | 1024 | 0.316 | 0.209 | 50.839 | 8682.26 | 4881.09 | 77.875 |
| 2 | 128 | 0.07 | 0.06 | 15.324 | 3557.8 | 3545.91 | 0.335 |
| 2 | 256 | 0.143 | 0.122 | 16.53 | 3901.5 | 3657.68 | 6.666 |
| 2 | 512 | 0.267 | 0.213 | 25.626 | 7062.21 | 4876.47 | 44.822 |
| 2 | 1024 | OOM | 0.404 | / | OOM | 8096.35 | SDPA 没有 OOM |
| 4 | 128 | 0.134 | 0.128 | 4.412 | 3675.79 | 3648.72 | 0.742 |
| 4 | 256 | 0.243 | 0.217 | 12.292 | 6129.76 | 4871.12 | 25.839 |
| 4 | 512 | 0.494 | 0.406 | 21.687 | 12466.6 | 8102.64 | 53.858 |
| 4 | 1024 | 内存溢出 | 0.795 | / | 内存溢出 | 14568.2 | SDPA 没有内存溢出 |
推理
| 批量大小 | 序列长度 | 每个令牌的延迟 Eager (毫秒) | 每个令牌的延迟 SDPA (毫秒) | 加速 (%) | 内存 Eager (MB) | 内存 SDPA (MB) | 内存节省 (%) |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 7.991 | 6.968 | 14.681 | 1685.2 | 1701.32 | -0.947 |
| 1 | 256 | 8.462 | 7.199 | 17.536 | 1745.49 | 1770.78 | -1.428 |
| 1 | 512 | 8.68 | 7.853 | 10.529 | 1907.69 | 1921.29 | -0.708 |
| 1 | 768 | 9.101 | 8.365 | 8.791 | 2032.93 | 2068.12 | -1.701 |
| 2 | 128 | 9.169 | 9.001 | 1.861 | 1803.84 | 1811.4 | -0.418 |
| 2 | 256 | 9.907 | 9.78 | 1.294 | 1907.72 | 1921.44 | -0.714 |
| 2 | 512 | 11.519 | 11.644 | -1.071 | 2176.86 | 2197.75 | -0.951 |
| 2 | 768 | 13.022 | 13.407 | -2.873 | 2464.3 | 2491.06 | -1.074 |
| 4 | 128 | 10.097 | 9.831 | 2.709 | 1942.25 | 1985.13 | -2.16 |
| 4 | 256 | 11.599 | 11.398 | 1.764 | 2177.28 | 2197.86 | -0.937 |
| 4 | 512 | 14.653 | 14.45 | 1.411 | 2753.16 | 2772.57 | -0.7 |
| 4 | 768 | 17.846 | 17.617 | 1.299 | 3327.04 | 3343.97 | -0.506 |
资源
以下是官方Hugging Face和社区(由🌎表示)提供的资源列表,帮助您开始使用GPT2。如果您有兴趣提交资源以包含在此处,请随时打开一个Pull Request,我们将进行审核!理想情况下,资源应展示一些新内容,而不是重复现有资源。
- 一篇关于如何使用Finetune a non-English GPT-2 Model with Hugging Face的博客。
- 一篇关于如何使用不同的解码方法通过Transformers生成文本的博客,使用GPT-2。
- 一篇关于从零开始训练CodeParrot 🦜的博客,这是一个大型的GPT-2模型。
- 一篇关于使用Faster Text Generation with TensorFlow and XLA和GPT-2的博客。
- 一篇关于如何使用Megatron-LM训练语言模型的博客,使用GPT-2模型。
- 一个关于如何微调GPT2以生成你最喜欢的艺术家风格的歌词的笔记本。🌎
- 一个关于如何微调GPT2以生成你最喜欢的Twitter用户风格的推文的笔记本。🌎
- Causal language modeling 🤗 Hugging Face 课程的章节。
- GPT2LMHeadModel 由这个 因果语言建模示例脚本、文本生成示例脚本 和 笔记本 支持。
- TFGPT2LMHeadModel 由这个 因果语言建模示例脚本 和 notebook 支持。
- FlaxGPT2LMHeadModel 由这个 因果语言建模示例脚本 和 notebook 支持。
- 文本分类任务指南
- Token分类任务指南
- 因果语言建模任务指南
GPT2Config
类 transformers.GPT2Config
< source >( vocab_size = 50257 n_positions = 1024 n_embd = 768 n_layer = 12 n_head = 12 n_inner = None activation_function = 'gelu_new' resid_pdrop = 0.1 embd_pdrop = 0.1 attn_pdrop = 0.1 layer_norm_epsilon = 1e-05 initializer_range = 0.02 summary_type = 'cls_index' summary_use_proj = True summary_activation = None summary_proj_to_labels = True summary_first_dropout = 0.1 scale_attn_weights = True use_cache = True bos_token_id = 50256 eos_token_id = 50256 scale_attn_by_inverse_layer_idx = False reorder_and_upcast_attn = False **kwargs )
参数
- vocab_size (
int, 可选, 默认为 50257) — GPT-2 模型的词汇量大小。定义了调用 GPT2Model 或 TFGPT2Model 时传递的inputs_ids可以表示的不同标记的数量。 - n_positions (
int, optional, 默认为 1024) — 该模型可能使用的最大序列长度。通常将其设置为较大的值以防万一(例如,512 或 1024 或 2048)。 - n_embd (
int, optional, 默认为 768) — 嵌入和隐藏状态的维度。 - n_layer (
int, optional, 默认为 12) — Transformer 编码器中的隐藏层数。 - n_head (
int, optional, 默认为 12) — Transformer 编码器中每个注意力层的注意力头数。 - n_inner (
int, optional) — 内部前馈层的维度。None会将其设置为 n_embd 的 4 倍 - activation_function (
str, 可选, 默认为"gelu_new") — 激活函数,从列表["relu", "silu", "gelu", "tanh", "gelu_new"]中选择。 - resid_pdrop (
float, optional, 默认为 0.1) — 嵌入层、编码器和池化器中所有全连接层的丢弃概率。 - embd_pdrop (
float, optional, defaults to 0.1) — 嵌入的dropout比率. - attn_pdrop (
float, optional, defaults to 0.1) — 注意力的dropout比例. - layer_norm_epsilon (
float, optional, defaults to 1e-05) — 用于层归一化层的epsilon值。 - initializer_range (
float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 - summary_type (
string, optional, defaults to"cls_index") — Argument used when doing sequence summary, used in the models GPT2DoubleHeadsModel and TFGPT2DoubleHeadsModel.必须是以下选项之一:
"last": Take the last token hidden state (like XLNet)."first": Take the first token hidden state (like BERT)."mean": Take the mean of all tokens hidden states."cls_index": Supply a Tensor of classification token position (like GPT/GPT-2)."attn": Not implemented now, use multi-head attention.
- summary_use_proj (
bool, optional, defaults toTrue) — Argument used when doing sequence summary, used in the models GPT2DoubleHeadsModel and TFGPT2DoubleHeadsModel.是否在向量提取后添加投影。
- summary_activation (
str, optional) — Argument used when doing sequence summary. Used in for the multiple choice head in GPT2DoubleHeadsModel.传递
"tanh"作为输出层的 tanh 激活函数,任何其他值将导致没有激活函数。 - summary_proj_to_labels (
bool, optional, defaults toTrue) — Argument used when doing sequence summary, used in the models GPT2DoubleHeadsModel and TFGPT2DoubleHeadsModel.投影输出是否应该具有
config.num_labels或config.hidden_size类别。 - summary_first_dropout (
float, optional, defaults to 0.1) — Argument used when doing sequence summary, used in the models GPT2DoubleHeadsModel and TFGPT2DoubleHeadsModel.在投影和激活后使用的丢弃比率。
- scale_attn_weights (
bool, optional, defaults toTrue) — 通过除以sqrt(hidden_size)来缩放注意力权重。 - use_cache (
bool, 可选, 默认为True) — 模型是否应返回最后的键/值注意力(并非所有模型都使用)。 - bos_token_id (
int, optional, 默认为 50256) — 词汇表中句子开始标记的ID. - eos_token_id (
int, 可选, 默认为 50256) — 词汇表中句子结束标记的ID。 - scale_attn_by_inverse_layer_idx (
bool, 可选, 默认为False) — 是否通过1 / layer_idx + 1额外缩放注意力权重. - reorder_and_upcast_attn (
bool, optional, defaults toFalse) — 是否在计算注意力(点积)之前缩放键(K),并在使用混合精度训练时将注意力点积/softmax上转换为float()类型。
这是用于存储GPT2Model或TFGPT2Model配置的配置类。它用于根据指定的参数实例化一个GPT-2模型,定义模型架构。使用默认值实例化配置将产生与GPT-2 openai-community/gpt2架构相似的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import GPT2Config, GPT2Model
>>> # Initializing a GPT2 configuration
>>> configuration = GPT2Config()
>>> # Initializing a model (with random weights) from the configuration
>>> model = GPT2Model(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configGPT2Tokenizer
类 transformers.GPT2Tokenizer
< source >( vocab_file merges_file errors = 'replace' unk_token = '<|endoftext|>' bos_token = '<|endoftext|>' eos_token = '<|endoftext|>' pad_token = None add_prefix_space = False add_bos_token = False **kwargs )
参数
- vocab_file (
str) — 词汇表文件的路径。 - merges_file (
str) — 合并文件的路径。 - errors (
str, 可选, 默认为"replace") — 解码字节为UTF-8时遵循的范式。更多信息请参见 bytes.decode. - unk_token (
str, optional, defaults to"<|endoftext|>") — 未知的标记。不在词汇表中的标记无法转换为ID,而是设置为这个标记。 - bos_token (
str, optional, defaults to"<|endoftext|>") — 序列的开始标记。 - eos_token (
str, optional, defaults to"<|endoftext|>") — 序列结束标记。 - pad_token (
str, optional) — 用于填充的标记,例如在对不同长度的序列进行批处理时使用。 - add_prefix_space (
bool, 可选, 默认为False) — 是否在输入前添加一个初始空格。这允许将前导词视为任何其他词。(GPT2 分词器通过前面的空格检测词的开头)。 - add_bos_token (
bool, optional, defaults toFalse) — 是否在输入中添加一个初始的句子开始标记。这允许将前导词视为任何其他词。
构建一个GPT-2分词器。基于字节级的字节对编码。
这个分词器已经被训练成将空格视为标记的一部分(有点像sentencepiece),因此一个单词将会
无论它是否在句子的开头(没有空格),编码方式都会有所不同:
>>> from transformers import GPT2Tokenizer
>>> tokenizer = GPT2Tokenizer.from_pretrained("openai-community/gpt2")
>>> tokenizer("Hello world")["input_ids"]
[15496, 995]
>>> tokenizer(" Hello world")["input_ids"]
[18435, 995]你可以通过在实例化此分词器或在某些文本上调用它时传递add_prefix_space=True来绕过这种行为,但由于模型不是以这种方式预训练的,这可能会导致性能下降。
当与is_split_into_words=True一起使用时,此分词器将在每个单词(即使是第一个单词)前添加一个空格。
此分词器继承自PreTrainedTokenizer,其中包含了大部分主要方法。用户应参考此超类以获取有关这些方法的更多信息。
GPT2TokenizerFast
类 transformers.GPT2TokenizerFast
< source >( vocab_file = None merges_file = None tokenizer_file = None unk_token = '<|endoftext|>' bos_token = '<|endoftext|>' eos_token = '<|endoftext|>' add_prefix_space = False **kwargs )
参数
- vocab_file (
str, optional) — 词汇表文件的路径。 - merges_file (
str, optional) — 合并文件的路径。 - tokenizer_file (
str, 可选) — 指向tokenizers文件的路径(通常具有.json扩展名),该文件包含加载分词器所需的所有内容。 - unk_token (
str, optional, defaults to"<|endoftext|>") — 未知的标记。不在词汇表中的标记无法转换为ID,而是设置为这个标记。 - bos_token (
str, optional, defaults to"<|endoftext|>") — 序列的开始标记。 - eos_token (
str, optional, defaults to"<|endoftext|>") — 序列结束标记。 - add_prefix_space (
bool, 可选, 默认为False) — 是否在输入前添加一个初始空格。这允许将前导词视为任何其他词。(GPT2 分词器通过前面的空格检测词的开头)。
构建一个“快速”的GPT-2分词器(由HuggingFace的tokenizers库支持)。基于字节级别的字节对编码。
这个分词器已经被训练成将空格视为标记的一部分(有点像sentencepiece),因此一个单词将会
无论它是否在句子的开头(没有空格),编码方式都会有所不同:
>>> from transformers import GPT2TokenizerFast
>>> tokenizer = GPT2TokenizerFast.from_pretrained("openai-community/gpt2")
>>> tokenizer("Hello world")["input_ids"]
[15496, 995]
>>> tokenizer(" Hello world")["input_ids"]
[18435, 995]你可以通过在实例化这个分词器时传递add_prefix_space=True来绕过这种行为,但由于模型不是以这种方式预训练的,这可能会导致性能下降。
当与is_split_into_words=True一起使用时,此分词器需要使用add_prefix_space=True进行实例化。
这个分词器继承自PreTrainedTokenizerFast,其中包含了大部分主要方法。用户应参考这个超类以获取有关这些方法的更多信息。
GPT2 特定输出
类 transformers.models.gpt2.modeling_gpt2.GPT2DoubleHeadsModelOutput
< source >( loss: typing.Optional[torch.FloatTensor] = None mc_loss: typing.Optional[torch.FloatTensor] = None logits: FloatTensor = None mc_logits: FloatTensor = None past_key_values: typing.Optional[typing.Tuple[typing.Tuple[torch.FloatTensor]]] = None hidden_states: typing.Optional[typing.Tuple[torch.FloatTensor]] = None attentions: typing.Optional[typing.Tuple[torch.FloatTensor]] = None )
参数
- loss (
torch.FloatTensorof shape(1,), optional, 当提供labels时返回) — 语言建模损失. - mc_loss (
torch.FloatTensorof shape(1,), optional, 当提供mc_labels时返回) — 多项选择分类损失. - logits (
torch.FloatTensorof shape(batch_size, num_choices, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax之前每个词汇标记的分数)。 - mc_logits (
torch.FloatTensorof shape(batch_size, num_choices)) — 多选分类头的预测分数(在SoftMax之前每个选择的分数)。 - past_key_values (
Tuple[Tuple[torch.Tensor]], optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple of lengthconfig.n_layers, containing tuples of tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)).包含预先计算的隐藏状态(注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).模型在每一层输出处的隐藏状态加上初始嵌入输出。
- attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).GPT2注意力权重在注意力softmax之后,用于计算自注意力头中的加权平均值。
用于预测两个句子是否连续的模型输出的基类。
类 transformers.models.gpt2.modeling_tf_gpt2.TFGPT2DoubleHeadsModelOutput
< source >( logits: tf.Tensor = None mc_logits: tf.Tensor = None past_key_values: List[tf.Tensor] | None = None hidden_states: Tuple[tf.Tensor] | None = None attentions: Tuple[tf.Tensor] | None = None )
参数
- logits (
tf.Tensorof shape(batch_size, num_choices, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax之前每个词汇标记的分数)。 - mc_logits (
tf.Tensorof shape(batch_size, num_choices)) — 多选分类头的预测分数(在SoftMax之前每个选择的分数)。 - past_key_values (
List[tf.Tensor], optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — List oftf.Tensorof lengthconfig.n_layers, with each tensor of shape(2, batch_size, num_heads, sequence_length, embed_size_per_head)).包含预先计算的隐藏状态(注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 - hidden_states (
tuple(tf.Tensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftf.Tensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).模型在每一层输出处的隐藏状态加上初始嵌入输出。
- attentions (
tuple(tf.Tensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftf.Tensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).注意力权重在注意力softmax之后,用于计算自注意力头中的加权平均值。
用于预测两个句子是否连续的模型输出的基类。
GPT2Model
类 transformers.GPT2Model
< source >( config )
参数
- config (GPT2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸GPT2模型变压器输出原始隐藏状态,没有任何特定的头部。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[typing.Tuple[typing.Tuple[torch.Tensor]]] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None position_ids: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None encoder_hidden_states: typing.Optional[torch.Tensor] = None encoder_attention_mask: typing.Optional[torch.FloatTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, input_ids_length)) —input_ids_length=sequence_lengthifpast_key_valuesisNoneelsepast_key_values[0][0].shape[-2](sequence_lengthof input past key value states). Indices of input sequence tokens in the vocabulary.如果使用了
past_key_values,则只应将未计算其过去的input_ids作为input_ids传递。可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- past_key_values (
Tuple[Tuple[torch.Tensor]]长度为config.n_layers) — 包含模型计算的预计算隐藏状态(注意力块中的键和值)(参见下面的past_key_values输出)。可用于加速顺序解码。已经将其过去状态提供给此模型的input_ids不应再作为input_ids传递,因为它们已经被计算过了。 - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
如果使用了
past_key_values,attention_mask需要包含用于past_key_values的掩码策略。换句话说,attention_mask的长度必须始终为:len(past_key_values) + len(input_ids) - token_type_ids (
torch.LongTensorof shape(batch_size, input_ids_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix.如果使用了
past_key_values,可以选择只输入最后的inputs_embeds(参见past_key_values)。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(GPT2Config)和输入。
-
last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。如果使用了
past_key_values,则只输出形状为(batch_size, 1, hidden_size)的序列的最后一个隐藏状态。 -
past_key_values (
tuple(tuple(torch.FloatTensor)), 可选, 当传递了use_cache=True或当config.use_cache=True时返回) — 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量,并且如果config.is_encoder_decoder=True,则还包含 2 个形状为(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)的额外张量。包含预先计算的隐藏状态(自注意力块中的键和值,并且如果
config.is_encoder_decoder=True,则还包含交叉注意力块中的键和值),这些隐藏状态可以用于(参见past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
-
cross_attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True和config.add_cross_attention=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器的交叉注意力层的注意力权重,在注意力 softmax 后,用于计算交叉注意力头中的加权平均值。
GPT2Model 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, GPT2Model
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
>>> model = GPT2Model.from_pretrained("openai-community/gpt2")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateGPT2LMHeadModel
class transformers.GPT2LMHeadModel
< source >( config )
参数
- config (GPT2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
GPT2模型变换器,顶部带有语言建模头(线性层,权重与输入嵌入绑定)。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[typing.Tuple[typing.Tuple[torch.Tensor]]] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None position_ids: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None encoder_hidden_states: typing.Optional[torch.Tensor] = None encoder_attention_mask: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.CausalLMOutputWithCrossAttentions 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, input_ids_length)) —input_ids_length=sequence_lengthifpast_key_valuesisNoneelsepast_key_values[0][0].shape[-2](sequence_lengthof input past key value states). Indices of input sequence tokens in the vocabulary.如果使用了
past_key_values,则只应将未计算其过去的input_ids作为input_ids传递。可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- past_key_values (
Tuple[Tuple[torch.Tensor]]长度为config.n_layers) — 包含模型计算的预计算隐藏状态(注意力块中的键和值)(参见下面的past_key_values输出)。可用于加速顺序解码。已经将其过去状态提供给此模型的input_ids不应再作为input_ids传递,因为它们已经被计算过了。 - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
如果使用了
past_key_values,attention_mask需要包含用于past_key_values的掩码策略。换句话说,attention_mask的长度必须始终为:len(past_key_values) + len(input_ids) - token_type_ids (
torch.LongTensorof shape(batch_size, input_ids_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix.如果使用了
past_key_values,可以选择只输入最后的inputs_embeds(参见past_key_values)。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — 用于语言建模的标签。请注意,标签在模型内部被移位,即你可以设置labels = input_ids索引在[-100, 0, ..., config.vocab_size]中选择。所有设置为-100的标签 将被忽略(掩码),损失仅针对[0, ..., config.vocab_size]中的标签计算
返回
transformers.modeling_outputs.CausalLMOutputWithCrossAttentions 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.CausalLMOutputWithCrossAttentions 或一个由 torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含根据配置(GPT2Config)和输入的各种元素。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 语言建模损失(用于下一个词的预测)。 -
logits (
torch.FloatTensor形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
-
cross_attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。交叉注意力 softmax 后的交叉注意力权重,用于计算交叉注意力头中的加权平均值。
-
past_key_values (
tuple(tuple(torch.FloatTensor)),可选,当传递use_cache=True或当config.use_cache=True时返回) — 由长度为config.n_layers的torch.FloatTensor元组组成的元组,每个元组包含自注意力和交叉注意力层的缓存键、值状态,如果模型用于编码器-解码器设置。仅在config.is_decoder = True时相关。包含预计算的隐藏状态(注意力块中的键和值),可用于(见
past_key_values输入)加速顺序解码。
GPT2LMHeadModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import torch
>>> from transformers import AutoTokenizer, GPT2LMHeadModel
>>> tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
>>> model = GPT2LMHeadModel.from_pretrained("openai-community/gpt2")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs, labels=inputs["input_ids"])
>>> loss = outputs.loss
>>> logits = outputs.logitsGPT2DoubleHeadsModel
类 transformers.GPT2DoubleHeadsModel
< source >( config )
参数
- config (GPT2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
GPT2模型变换器,顶部带有语言建模和多选分类头,例如用于RocStories/SWAG任务。这两个头是两个线性层。语言建模头的权重与输入嵌入绑定,分类头将输入序列中指定分类标记索引的输入作为输入。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[typing.Tuple[typing.Tuple[torch.Tensor]]] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None position_ids: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None mc_token_ids: typing.Optional[torch.LongTensor] = None labels: typing.Optional[torch.LongTensor] = None mc_labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None **kwargs ) → transformers.models.gpt2.modeling_gpt2.GPT2DoubleHeadsModelOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, input_ids_length)) —input_ids_length=sequence_lengthifpast_key_valuesisNoneelsepast_key_values[0][0].shape[-2](sequence_lengthof input past key value states). Indices of input sequence tokens in the vocabulary.如果使用了
past_key_values,则只应将未计算其过去的input_ids作为input_ids传递。可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- past_key_values (
Tuple[Tuple[torch.Tensor]]长度为config.n_layers) — 包含模型计算的预计算隐藏状态(注意力块中的键和值)(参见下面的past_key_values输出)。可用于加速顺序解码。已经将其过去状态提供给此模型的input_ids不应再作为input_ids传递,因为它们已经被计算过了。 - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
如果使用了
past_key_values,attention_mask需要包含用于past_key_values的掩码策略。换句话说,attention_mask的长度必须始终为:len(past_key_values) + len(input_ids) - token_type_ids (
torch.LongTensorof shape(batch_size, input_ids_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix.如果使用了
past_key_values,可以选择只输入最后的inputs_embeds(参见past_key_values)。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - mc_token_ids (
torch.LongTensorof shape(batch_size, num_choices), 可选, 默认为输入序列的最后一个token的索引) — 每个输入序列中分类token的索引。选择范围在[0, input_ids.size(-1) - 1]之间。 - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — 语言建模的标签。请注意,标签在模型内部被移位,即你可以设置labels = input_ids。索引在[-100, 0, ..., config.vocab_size - 1]中选择。所有设置为-100的标签将被忽略(掩码),损失仅计算[0, ..., config.vocab_size - 1]中的标签 - mc_labels (
torch.LongTensor形状为(batch_size), 可选) — 用于计算多项选择分类损失的标签。索引应在[0, ..., num_choices]范围内, 其中 num_choices 是输入张量第二维的大小。(参见上面的 input_ids)
返回
transformers.models.gpt2.modeling_gpt2.GPT2DoubleHeadsModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.models.gpt2.modeling_gpt2.GPT2DoubleHeadsModelOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(GPT2Config)和输入。
-
loss (
torch.FloatTensor形状为(1,), 可选, 当提供labels时返回) — 语言建模损失。 -
mc_loss (
torch.FloatTensor形状为(1,), 可选, 当提供mc_labels时返回) — 多项选择分类损失。 -
logits (
torch.FloatTensor形状为(batch_size, num_choices, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前的每个词汇标记的分数)。 -
mc_logits (
torch.FloatTensor形状为(batch_size, num_choices)) — 多项选择分类头的预测分数(SoftMax 之前的每个选择的分数)。 -
past_key_values (
Tuple[Tuple[torch.Tensor]], 可选, 当传递use_cache=True或当config.use_cache=True时返回) — 长度为config.n_layers的元组,包含形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量元组。包含预计算的隐藏状态(注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入的输出 + 一个用于每层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的 GPT2Attentions 权重,用于计算自注意力头中的加权平均值。
GPT2DoubleHeadsModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import torch
>>> from transformers import AutoTokenizer, GPT2DoubleHeadsModel
>>> tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
>>> model = GPT2DoubleHeadsModel.from_pretrained("openai-community/gpt2")
>>> # Add a [CLS] to the vocabulary (we should train it also!)
>>> num_added_tokens = tokenizer.add_special_tokens({"cls_token": "[CLS]"})
>>> # Update the model embeddings with the new vocabulary size
>>> embedding_layer = model.resize_token_embeddings(len(tokenizer))
>>> choices = ["Hello, my dog is cute [CLS]", "Hello, my cat is cute [CLS]"]
>>> encoded_choices = [tokenizer.encode(s) for s in choices]
>>> cls_token_location = [tokens.index(tokenizer.cls_token_id) for tokens in encoded_choices]
>>> input_ids = torch.tensor(encoded_choices).unsqueeze(0) # Batch size: 1, number of choices: 2
>>> mc_token_ids = torch.tensor([cls_token_location]) # Batch size: 1
>>> outputs = model(input_ids, mc_token_ids=mc_token_ids)
>>> lm_logits = outputs.logits
>>> mc_logits = outputs.mc_logitsGPT2ForQuestionAnswering
类 transformers.GPT2ForQuestionAnswering
< source >( config )
参数
- config (GPT2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
GPT-2模型变换器,顶部带有用于抽取式问答任务(如SQuAD)的跨度分类头(在隐藏状态输出之上的线性层,用于计算span start logits和span end logits)。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None position_ids: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None start_positions: typing.Optional[torch.LongTensor] = None end_positions: typing.Optional[torch.LongTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.QuestionAnsweringModelOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, input_ids_length)) —input_ids_length=sequence_lengthifpast_key_valuesisNoneelsepast_key_values[0][0].shape[-2](sequence_lengthof input past key value states). Indices of input sequence tokens in the vocabulary.如果使用了
past_key_values,则只应将未计算其过去的input_ids作为input_ids传递。可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- past_key_values (
Tuple[Tuple[torch.Tensor]]长度为config.n_layers) — 包含模型计算的预计算隐藏状态(注意力块中的键和值)(参见下面的past_key_values输出)。可用于加速顺序解码。已经将其过去状态提供给此模型的input_ids不应再作为input_ids传递,因为它们已经被计算过了。 - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
如果使用了
past_key_values,attention_mask需要包含用于past_key_values的掩码策略。换句话说,attention_mask的长度必须始终为:len(past_key_values) + len(input_ids) - token_type_ids (
torch.LongTensorof shape(batch_size, input_ids_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix.如果使用了
past_key_values,可以选择只输入最后的inputs_embeds(参见past_key_values)。 - use_cache (
bool, 可选) — 如果设置为True,将返回past_key_values键值状态,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - start_positions (
torch.LongTensorof shape(batch_size,), optional) — 用于计算标记分类损失的标记跨度起始位置(索引)的标签。 位置被限制在序列长度内(sequence_length)。序列之外的位置不会用于计算损失。 - end_positions (
torch.LongTensorof shape(batch_size,), optional) — 用于计算标记分类损失的标记跨度结束位置(索引)的标签。 位置被限制在序列长度内(sequence_length)。序列之外的位置不会用于计算损失。
返回
transformers.modeling_outputs.QuestionAnsweringModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.QuestionAnsweringModelOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(GPT2Config)和输入。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 总跨度提取损失是起始和结束位置的交叉熵之和。 -
start_logits (
torch.FloatTensor形状为(batch_size, sequence_length)) — 跨度起始分数(在 SoftMax 之前)。 -
end_logits (
torch.FloatTensor形状为(batch_size, sequence_length)) — 跨度结束分数(在 SoftMax 之前)。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力权重在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
GPT2ForQuestionAnswering 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
此示例使用随机模型,因为真实模型都非常大。要获得正确的结果,您应该使用
openai-community/gpt2 而不是 openai-community/gpt2。如果在加载该检查点时出现内存不足的情况,您可以尝试
在 from_pretrained 调用中添加 device_map="auto"。
示例:
>>> from transformers import AutoTokenizer, GPT2ForQuestionAnswering
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
>>> model = GPT2ForQuestionAnswering.from_pretrained("openai-community/gpt2")
>>> question, text = "Who was Jim Henson?", "Jim Henson was a nice puppet"
>>> inputs = tokenizer(question, text, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> answer_start_index = outputs.start_logits.argmax()
>>> answer_end_index = outputs.end_logits.argmax()
>>> predict_answer_tokens = inputs.input_ids[0, answer_start_index : answer_end_index + 1]
>>> # target is "nice puppet"
>>> target_start_index = torch.tensor([14])
>>> target_end_index = torch.tensor([15])
>>> outputs = model(**inputs, start_positions=target_start_index, end_positions=target_end_index)
>>> loss = outputs.lossGPT2ForSequenceClassification
类 transformers.GPT2ForSequenceClassification
< source >( config )
参数
- config (GPT2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
GPT2模型变换器,顶部带有序列分类头(线性层)。
GPT2ForSequenceClassification 使用最后一个标记进行分类,就像其他因果模型(例如 GPT-1)所做的那样。
由于它对最后一个标记进行分类,因此需要知道最后一个标记的位置。如果在配置中定义了pad_token_id,它会在每一行中找到不是填充标记的最后一个标记。如果没有定义pad_token_id,它只需取批次中每一行的最后一个值。由于在传递inputs_embeds而不是input_ids时无法猜测填充标记,它会执行相同的操作(取批次中每一行的最后一个值)。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[typing.Tuple[typing.Tuple[torch.Tensor]]] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None position_ids: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.SequenceClassifierOutputWithPast 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, input_ids_length)) —input_ids_length=sequence_lengthifpast_key_valuesisNoneelsepast_key_values[0][0].shape[-2](sequence_lengthof input past key value states). Indices of input sequence tokens in the vocabulary.如果使用了
past_key_values,则只应将未计算其过去的input_ids作为input_ids传递。可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- past_key_values (
Tuple[Tuple[torch.Tensor]]长度为config.n_layers) — 包含模型计算的预计算隐藏状态(注意力块中的键和值)(参见下面的past_key_values输出)。可用于加速顺序解码。已经将其过去状态提供给此模型的input_ids不应再作为input_ids传递,因为它们已经被计算过了。 - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
如果使用了
past_key_values,attention_mask需要包含用于past_key_values的掩码策略。换句话说,attention_mask的长度必须始终为:len(past_key_values) + len(input_ids) - token_type_ids (
torch.LongTensorof shape(batch_size, input_ids_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix.如果使用了
past_key_values,可以选择只输入最后的inputs_embeds(参见past_key_values)。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size,), optional) — 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.SequenceClassifierOutputWithPast 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.SequenceClassifierOutputWithPast 或一个由 torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种元素,具体取决于配置(GPT2Config)和输入。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 分类(或回归,如果 config.num_labels==1)损失。 -
logits (
torch.FloatTensor形状为(batch_size, config.num_labels)) — 分类(或回归,如果 config.num_labels==1)得分(在 SoftMax 之前)。 -
past_key_values (
tuple(tuple(torch.FloatTensor)),可选,当传递use_cache=True或当config.use_cache=True时返回) — 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量。包含预先计算的隐藏状态(自注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
GPT2ForSequenceClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
单标签分类示例:
>>> import torch
>>> from transformers import AutoTokenizer, GPT2ForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/DialogRPT-updown")
>>> model = GPT2ForSequenceClassification.from_pretrained("microsoft/DialogRPT-updown")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_id = logits.argmax().item()
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = GPT2ForSequenceClassification.from_pretrained("microsoft/DialogRPT-updown", num_labels=num_labels)
>>> labels = torch.tensor([1])
>>> loss = model(**inputs, labels=labels).loss多标签分类示例:
>>> import torch
>>> from transformers import AutoTokenizer, GPT2ForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/DialogRPT-updown")
>>> model = GPT2ForSequenceClassification.from_pretrained("microsoft/DialogRPT-updown", problem_type="multi_label_classification")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_ids = torch.arange(0, logits.shape[-1])[torch.sigmoid(logits).squeeze(dim=0) > 0.5]
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = GPT2ForSequenceClassification.from_pretrained(
... "microsoft/DialogRPT-updown", num_labels=num_labels, problem_type="multi_label_classification"
... )
>>> labels = torch.sum(
... torch.nn.functional.one_hot(predicted_class_ids[None, :].clone(), num_classes=num_labels), dim=1
... ).to(torch.float)
>>> loss = model(**inputs, labels=labels).lossGPT2ForTokenClassification
类 transformers.GPT2ForTokenClassification
< source >( config )
参数
- config (GPT2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
GPT2模型,顶部带有标记分类头(在隐藏状态输出之上的线性层),例如用于命名实体识别(NER)任务。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[typing.Tuple[typing.Tuple[torch.Tensor]]] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None position_ids: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.TokenClassifierOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, input_ids_length)) —input_ids_length=sequence_lengthifpast_key_valuesisNoneelsepast_key_values[0][0].shape[-2](sequence_lengthof input past key value states). Indices of input sequence tokens in the vocabulary.如果使用了
past_key_values,则只应将未计算其过去的input_ids作为input_ids传递。可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- past_key_values (
Tuple[Tuple[torch.Tensor]]长度为config.n_layers) — 包含模型计算的预计算隐藏状态(注意力块中的键和值)(参见下面的past_key_values输出)。可用于加速顺序解码。已经将其过去状态提供给此模型的input_ids不应再作为input_ids传递,因为它们已经被计算过了。 - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
如果使用了
past_key_values,attention_mask需要包含用于past_key_values的掩码策略。换句话说,attention_mask的长度必须始终为:len(past_key_values) + len(input_ids) - token_type_ids (
torch.LongTensorof shape(batch_size, input_ids_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix.如果使用了
past_key_values,可以选择只输入最后的inputs_embeds(参见past_key_values)。 - use_cache (
bool, 可选) — 如果设置为True,将返回past_key_values键值状态,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - labels (
torch.LongTensor形状为(batch_size, sequence_length), 可选) — 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.TokenClassifierOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.TokenClassifierOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(GPT2Config)和输入。
-
loss (
torch.FloatTensor形状为(1,), 可选, 当提供labels时返回) — 分类损失。 -
logits (
torch.FloatTensor形状为(batch_size, sequence_length, config.num_labels)) — 分类分数(在 SoftMax 之前)。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
GPT2ForTokenClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, GPT2ForTokenClassification
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("brad1141/gpt2-finetuned-comp2")
>>> model = GPT2ForTokenClassification.from_pretrained("brad1141/gpt2-finetuned-comp2")
>>> inputs = tokenizer(
... "HuggingFace is a company based in Paris and New York", add_special_tokens=False, return_tensors="pt"
... )
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_token_class_ids = logits.argmax(-1)
>>> # Note that tokens are classified rather then input words which means that
>>> # there might be more predicted token classes than words.
>>> # Multiple token classes might account for the same word
>>> predicted_tokens_classes = [model.config.id2label[t.item()] for t in predicted_token_class_ids[0]]
>>> predicted_tokens_classes
['Lead', 'Lead', 'Lead', 'Position', 'Lead', 'Lead', 'Lead', 'Lead', 'Lead', 'Lead', 'Lead', 'Lead']
>>> labels = predicted_token_class_ids
>>> loss = model(**inputs, labels=labels).loss
>>> round(loss.item(), 2)
0.25TFGPT2Model
类 transformers.TFGPT2Model
< source >( config *inputs **kwargs )
参数
- config (GPT2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸GPT2模型变压器输出原始隐藏状态,没有任何特定的头部。
该模型继承自 TFPreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个keras.Model子类。可以将其作为常规的TF 2.0 Keras模型使用,并参考TF 2.0文档以了解与一般使用和行为相关的所有事项。
TensorFlow 模型和层在 transformers 中接受两种格式作为输入:
- 将所有输入作为关键字参数(如PyTorch模型),或
- 将所有输入作为列表、元组或字典放在第一个位置参数中。
支持第二种格式的原因是,Keras 方法在将输入传递给模型和层时更喜欢这种格式。由于这种支持,当使用像 model.fit() 这样的方法时,事情应该“正常工作”——只需以 model.fit() 支持的任何格式传递你的输入和标签!然而,如果你想在 Keras 方法之外使用第二种格式,比如在使用 Keras Functional API 创建自己的层或模型时,有三种方法可以用来将所有输入张量收集到第一个位置参数中:
- 仅包含
input_ids的单个张量,没有其他内容:model(input_ids) - 一个长度不定的列表,包含一个或多个输入张量,按照文档字符串中给出的顺序:
model([input_ids, attention_mask])或model([input_ids, attention_mask, token_type_ids]) - 一个字典,包含一个或多个与文档字符串中给出的输入名称相关联的输入张量:
model({"input_ids": input_ids, "token_type_ids": token_type_ids})
请注意,当使用子类化创建模型和层时,您不需要担心这些,因为您可以像传递任何其他Python函数一样传递输入!
调用
< source >( input_ids: TFModelInputType | None = None past_key_values: Optional[Tuple[Tuple[Union[np.ndarray, tf.Tensor]]]] = None attention_mask: np.ndarray | tf.Tensor | None = None token_type_ids: np.ndarray | tf.Tensor | None = None position_ids: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None inputs_embeds: np.ndarray | tf.Tensor | None = None encoder_hidden_states: np.ndarray | tf.Tensor | None = None encoder_attention_mask: np.ndarray | tf.Tensor | None = None use_cache: Optional[bool] = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: Optional[bool] = False ) → transformers.modeling_tf_outputs.TFBaseModelOutputWithPastAndCrossAttentions 或 tuple(tf.Tensor)
参数
- input_ids (
Numpy arrayortf.Tensorof shape(batch_size, input_ids_length)) —input_ids_length=sequence_lengthifpast_key_valuesisNoneelsepast_key_values[0].shape[-2](sequence_lengthof input past key value states). Indices of input sequence tokens in the vocabulary.如果使用了
past_key_values,则只应将未计算其过去的输入ID作为input_ids传递。可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.call()和 PreTrainedTokenizer.encode()。
- past_key_values (
List[tf.Tensor]长度为config.n_layers) — 包含模型计算的预计算隐藏状态(注意力块中的键和值)(见下面的past_key_values输出)。可用于加速顺序解码。已经计算过的令牌ID不应作为输入ID传递,因为它们已经被计算过了。 - attention_mask (
tf.TensororNumpy arrayof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
如果使用了
past_key_values,attention_mask需要包含用于past_key_values的掩码策略。换句话说,attention_mask的长度必须始终为:len(past_key_values) + len(input_ids) - token_type_ids (
tf.TensororNumpy arrayof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
tf.TensororNumpy arrayof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
Numpy array或tf.Tensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部未被屏蔽,
- 0 表示头部被屏蔽.
- inputs_embeds (
tf.Tensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。此参数只能在eager模式下使用,在graph模式下将使用配置中的值。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。此参数只能在急切模式下使用,在图形模式下将使用配置中的值。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。此参数可以在eager模式下使用,在graph模式下该值将始终设置为True. - 训练 (
bool, 可选, 默认为False) — 是否在训练模式下使用模型(一些模块如dropout模块在训练和评估之间有不同的行为)。 - encoder_hidden_states (
tf.Tensorof shape(batch_size, sequence_length, hidden_size), optional) — 编码器最后一层输出的隐藏状态序列。如果模型配置为解码器,则在交叉注意力中使用。 - encoder_attention_mask (
tf.Tensorof shape(batch_size, sequence_length), optional) — 用于避免在编码器输入的填充标记索引上执行注意力操作的掩码。如果模型配置为解码器,则在交叉注意力中使用此掩码。掩码值在[0, 1]中选择:- 1 表示 未掩码 的标记,
- 0 表示 掩码 的标记。
- past_key_values (
Tuple[Tuple[tf.Tensor]]长度为config.n_layers) — 包含预计算的注意力块的关键和值隐藏状态。可用于加速解码。 如果使用了past,用户可以选择仅输入形状为(batch_size, 1)的最后一个decoder_input_ids(那些没有将其过去的关键值状态提供给此模型的),而不是所有形状为(batch_size, sequence_length)的decoder_input_ids。 - use_cache (
bool, 可选, 默认为True) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past)。在训练期间设置为False,在生成期间设置为True
返回
transformers.modeling_tf_outputs.TFBaseModelOutputWithPastAndCrossAttentions 或 tuple(tf.Tensor)
一个 transformers.modeling_tf_outputs.TFBaseModelOutputWithPastAndCrossAttentions 或一个 tf.Tensor 元组(如果
return_dict=False 被传递或当 config.return_dict=False 时)包含根据配置(GPT2Config)和输入的各种元素。
-
last_hidden_state (
tf.Tensor形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。如果使用了
past_key_values,则只输出形状为(batch_size, 1, hidden_size)的序列的最后一个隐藏状态。 -
past_key_values (
List[tf.Tensor], 可选, 当use_cache=True被传递或当config.use_cache=True时返回) — 长度为config.n_layers的tf.Tensor列表,每个张量的形状为(2, batch_size, num_heads, sequence_length, embed_size_per_head)。包含预计算的隐藏状态(注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(tf.FloatTensor), 可选, 当output_hidden_states=True被传递或当config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的tf.Tensor元组(一个用于嵌入的输出 + 一个用于每层的输出)。模型在每层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(tf.Tensor), 可选, 当output_attentions=True被传递或当config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的tf.Tensor元组(每层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
-
cross_attentions (
tuple(tf.Tensor), 可选, 当output_attentions=True被传递或当config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的tf.Tensor元组(每层一个)。解码器的交叉注意力层的注意力权重,在注意力 softmax 后,用于计算交叉注意力头中的加权平均值。
TFGPT2Model 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, TFGPT2Model
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
>>> model = TFGPT2Model.from_pretrained("openai-community/gpt2")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
>>> outputs = model(inputs)
>>> last_hidden_states = outputs.last_hidden_stateTFGPT2LMHeadModel
类 transformers.TFGPT2LMHeadModel
< source >( config *inputs **kwargs )
参数
- config (GPT2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
GPT2模型变换器,顶部带有语言建模头(线性层,权重与输入嵌入绑定)。
该模型继承自 TFPreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个keras.Model子类。可以将其作为常规的TF 2.0 Keras模型使用,并参考TF 2.0文档以了解与一般使用和行为相关的所有事项。
TensorFlow 模型和层在 transformers 中接受两种格式作为输入:
- 将所有输入作为关键字参数(如PyTorch模型),或
- 将所有输入作为列表、元组或字典放在第一个位置参数中。
支持第二种格式的原因是,Keras 方法在将输入传递给模型和层时更喜欢这种格式。由于这种支持,当使用像 model.fit() 这样的方法时,事情应该“正常工作”——只需以 model.fit() 支持的任何格式传递你的输入和标签!然而,如果你想在 Keras 方法之外使用第二种格式,比如在使用 Keras Functional API 创建自己的层或模型时,有三种方法可以用来将所有输入张量收集到第一个位置参数中:
- 仅包含
input_ids的单个张量,没有其他内容:model(input_ids) - 一个长度不定的列表,包含一个或多个输入张量,按照文档字符串中给出的顺序:
model([input_ids, attention_mask])或model([input_ids, attention_mask, token_type_ids]) - 一个字典,包含一个或多个与文档字符串中给出的输入名称相关联的输入张量:
model({"input_ids": input_ids, "token_type_ids": token_type_ids})
请注意,当使用子类化创建模型和层时,您不需要担心这些,因为您可以像传递任何其他Python函数一样传递输入!
调用
< source >( input_ids: TFModelInputType | None = None past_key_values: Optional[Tuple[Tuple[Union[np.ndarray, tf.Tensor]]]] = None attention_mask: np.ndarray | tf.Tensor | None = None token_type_ids: np.ndarray | tf.Tensor | None = None position_ids: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None inputs_embeds: np.ndarray | tf.Tensor | None = None encoder_hidden_states: np.ndarray | tf.Tensor | None = None encoder_attention_mask: np.ndarray | tf.Tensor | None = None use_cache: Optional[bool] = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None labels: np.ndarray | tf.Tensor | None = None training: Optional[bool] = False ) → transformers.modeling_tf_outputs.TFCausalLMOutputWithCrossAttentions 或 tuple(tf.Tensor)
参数
- input_ids (
Numpy arrayortf.Tensorof shape(batch_size, input_ids_length)) —input_ids_length=sequence_lengthifpast_key_valuesisNoneelsepast_key_values[0].shape[-2](sequence_lengthof input past key value states). Indices of input sequence tokens in the vocabulary.如果使用了
past_key_values,则只应将未计算其过去的输入ID作为input_ids传递。可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.call()和 PreTrainedTokenizer.encode()。
- past_key_values (
List[tf.Tensor]长度为config.n_layers) — 包含模型预先计算的隐藏状态(注意力块中的键和值)(见下面的past_key_values输出)。可用于加速顺序解码。已经计算过的令牌ID不应作为输入ID传递,因为它们已经被计算过了。 - attention_mask (
tf.TensororNumpy arrayof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
如果使用了
past_key_values,attention_mask需要包含用于past_key_values的掩码策略。换句话说,attention_mask的长度必须始终为:len(past_key_values) + len(input_ids) - token_type_ids (
tf.TensororNumpy arrayof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
tf.TensororNumpy arrayof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
Numpy array或tf.Tensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
tf.Tensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。此参数只能在eager模式下使用,在graph模式下将使用配置中的值。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。此参数只能在eager模式下使用,在graph模式下将使用配置中的值。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。此参数可以在eager模式下使用,在graph模式下该值将始终设置为True. - 训练 (
bool, 可选, 默认为False) — 是否在训练模式下使用模型(一些模块如dropout模块在训练和评估时具有不同的行为)。 - encoder_hidden_states (
tf.Tensor形状为(batch_size, sequence_length, hidden_size), 可选) — 编码器最后一层输出的隐藏状态序列。如果模型配置为解码器,则在交叉注意力中使用。 - encoder_attention_mask (
tf.Tensorof shape(batch_size, sequence_length), optional) — 用于避免在编码器输入的填充标记索引上执行注意力。如果模型配置为解码器,则在交叉注意力中使用此掩码。掩码值在[0, 1]中选择:- 1 表示 未掩码 的标记,
- 0 表示 掩码 的标记。
- past_key_values (
Tuple[Tuple[tf.Tensor]]长度为config.n_layers) — 包含预计算的关键和值隐藏状态的注意力块。可用于加速解码。 如果使用了past,用户可以选择仅输入形状为(batch_size, 1)的最后一个decoder_input_ids(那些没有将其过去的关键值状态提供给此模型的),而不是所有形状为(batch_size, sequence_length)的decoder_input_ids。 - use_cache (
bool, 可选, 默认为True) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past)。在训练期间设置为False,在生成期间设置为True - labels (
tf.Tensorof shape(batch_size, sequence_length), optional) — 用于计算交叉熵分类损失的标签。索引应在[0, ..., config.vocab_size - 1]范围内。
返回
transformers.modeling_tf_outputs.TFCausalLMOutputWithCrossAttentions 或 tuple(tf.Tensor)
一个 transformers.modeling_tf_outputs.TFCausalLMOutputWithCrossAttentions 或一个由 tf.Tensor 组成的元组(如果
return_dict=False 被传递或当 config.return_dict=False 时),包含根据配置 (GPT2Config) 和输入的各种元素。
-
loss (
tf.Tensor形状为(n,), 可选, 其中 n 是非掩码标签的数量,当提供labels时返回) — 语言建模损失(用于下一个标记预测)。 -
logits (
tf.Tensor形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
hidden_states (
tuple(tf.Tensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由tf.Tensor组成的元组(一个用于嵌入的输出 + 一个用于每层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(tf.Tensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由tf.Tensor组成的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
-
cross_attentions (
tuple(tf.Tensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由tf.Tensor组成的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器交叉注意力层的注意力权重,在注意力 softmax 后,用于计算交叉注意力头中的加权平均值。
-
past_key_values (
List[tf.Tensor], 可选, 当传递use_cache=True或当config.use_cache=True时返回) — 长度为config.n_layers的tf.Tensor列表,每个张量形状为(2, batch_size, num_heads, sequence_length, embed_size_per_head))。包含预计算的隐藏状态(注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。
TFGPT2LMHeadModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, TFGPT2LMHeadModel
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
>>> model = TFGPT2LMHeadModel.from_pretrained("openai-community/gpt2")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
>>> outputs = model(inputs)
>>> logits = outputs.logitsTFGPT2DoubleHeadsModel
类 transformers.TFGPT2DoubleHeadsModel
< source >( config *inputs **kwargs )
参数
- config (GPT2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
GPT2模型变换器,顶部带有语言建模和多选分类头,例如用于RocStories/SWAG任务。这两个头是两个线性层。语言建模头的权重与输入嵌入绑定,分类头将输入序列中指定分类标记索引的输入作为输入。
该模型继承自 TFPreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个keras.Model子类。可以将其作为常规的TF 2.0 Keras模型使用,并参考TF 2.0文档以了解与一般使用和行为相关的所有事项。
TensorFlow 模型和层在 transformers 中接受两种格式作为输入:
- 将所有输入作为关键字参数(如PyTorch模型),或
- 将所有输入作为列表、元组或字典放在第一个位置参数中。
支持第二种格式的原因是,Keras 方法在将输入传递给模型和层时更喜欢这种格式。由于这种支持,当使用像 model.fit() 这样的方法时,事情应该“正常工作”——只需以 model.fit() 支持的任何格式传递你的输入和标签!然而,如果你想在 Keras 方法之外使用第二种格式,比如在使用 Keras Functional API 创建自己的层或模型时,有三种方法可以用来将所有输入张量收集到第一个位置参数中:
- 仅包含
input_ids的单个张量,没有其他内容:model(input_ids) - 一个长度不定的列表,包含一个或多个输入张量,按照文档字符串中给出的顺序:
model([input_ids, attention_mask])或model([input_ids, attention_mask, token_type_ids]) - 一个字典,包含一个或多个与文档字符串中给出的输入名称相关联的输入张量:
model({"input_ids": input_ids, "token_type_ids": token_type_ids})
请注意,当使用子类化创建模型和层时,您不需要担心这些,因为您可以像传递任何其他Python函数一样传递输入!
调用
< source >( input_ids: TFModelInputType | None = None past_key_values: Optional[Tuple[Tuple[Union[np.ndarray, tf.Tensor]]]] = None attention_mask: np.ndarray | tf.Tensor | None = None token_type_ids: np.ndarray | tf.Tensor | None = None position_ids: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None inputs_embeds: np.ndarray | tf.Tensor | None = None mc_token_ids: np.ndarray | tf.Tensor | None = None use_cache: Optional[bool] = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: Optional[bool] = False ) → transformers.models.gpt2.modeling_tf_gpt2.TFGPT2DoubleHeadsModelOutput 或 tuple(tf.Tensor)
参数
- input_ids (
Numpy arrayortf.Tensorof shape(batch_size, input_ids_length)) —input_ids_length=sequence_lengthifpast_key_valuesisNoneelsepast_key_values[0].shape[-2](sequence_lengthof input past key value states). Indices of input sequence tokens in the vocabulary.如果使用了
past_key_values,则只应将未计算其过去的输入ID作为input_ids传递。可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.call()和 PreTrainedTokenizer.encode()。
- past_key_values (
List[tf.Tensor]长度为config.n_layers) — 包含模型计算的预计算隐藏状态(注意力块中的键和值)(参见下面的past_key_values输出)。可用于加速顺序解码。已经计算过的令牌ID不应作为输入ID传递,因为它们已经被计算过了。 - attention_mask (
tf.TensororNumpy arrayof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
如果使用了
past_key_values,attention_mask需要包含用于past_key_values的掩码策略。换句话说,attention_mask的长度必须始终为:len(past_key_values) + len(input_ids) - token_type_ids (
tf.TensororNumpy arrayof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
tf.TensororNumpy arrayof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
Numpy array或tf.Tensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
tf.Tensor形状为(batch_size, sequence_length, hidden_size), 可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。此参数只能在eager模式下使用,在graph模式下将使用配置中的值。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。此参数只能在eager模式下使用,在graph模式下将使用配置中的值。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。此参数可以在eager模式下使用,在graph模式下该值将始终设置为True. - 训练 (
bool, 可选, 默认为False) — 是否在训练模式下使用模型(一些模块如dropout模块在训练和评估之间有不同的行为)。 - mc_token_ids (
tf.Tensor或Numpy array,形状为(batch_size, num_choices),可选,默认为输入序列的最后一个标记的索引) — 每个输入序列中分类标记的索引。选择范围在[0, input_ids.size(-1) - 1]之间。
返回
transformers.models.gpt2.modeling_tf_gpt2.TFGPT2DoubleHeadsModelOutput 或 tuple(tf.Tensor)
一个 transformers.models.gpt2.modeling_tf_gpt2.TFGPT2DoubleHeadsModelOutput 或一个由 tf.Tensor 组成的元组(如果
return_dict=False 被传递或当 config.return_dict=False 时),包含根据配置(GPT2Config)和输入的各种元素。
-
logits (
tf.Tensor形状为(batch_size, num_choices, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前的每个词汇标记的分数)。 -
mc_logits (
tf.Tensor形状为(batch_size, num_choices)) — 多项选择分类头的预测分数(SoftMax 之前的每个选择的分数)。 -
past_key_values (
List[tf.Tensor], 可选, 当use_cache=True被传递或当config.use_cache=True时返回) — 长度为config.n_layers的tf.Tensor列表,每个张量的形状为(2, batch_size, num_heads, sequence_length, embed_size_per_head))。包含预计算的隐藏状态(注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(tf.Tensor), 可选, 当output_hidden_states=True被传递或当config.output_hidden_states=True时返回) — 由tf.Tensor组成的元组(一个用于嵌入的输出 + 一个用于每层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(tf.Tensor), 可选, 当output_attentions=True被传递或当config.output_attentions=True时返回) — 由tf.Tensor组成的元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
TFGPT2DoubleHeadsModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import tensorflow as tf
>>> from transformers import AutoTokenizer, TFGPT2DoubleHeadsModel
>>> tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
>>> model = TFGPT2DoubleHeadsModel.from_pretrained("openai-community/gpt2")
>>> # Add a [CLS] to the vocabulary (we should train it also!)
>>> num_added_tokens = tokenizer.add_special_tokens({"cls_token": "[CLS]"})
>>> embedding_layer = model.resize_token_embeddings(
... len(tokenizer)
... ) # Update the model embeddings with the new vocabulary size
>>> choices = ["Hello, my dog is cute [CLS]", "Hello, my cat is cute [CLS]"]
>>> encoded_choices = [tokenizer.encode(s) for s in choices]
>>> cls_token_location = [tokens.index(tokenizer.cls_token_id) for tokens in encoded_choices]
>>> input_ids = tf.constant(encoded_choices)[None, :] # Batch size: 1, number of choices: 2
>>> mc_token_ids = tf.constant([cls_token_location]) # Batch size: 1
>>> outputs = model(input_ids, mc_token_ids=mc_token_ids)
>>> lm_prediction_scores, mc_prediction_scores = outputs[:2]TFGPT2ForSequenceClassification
类 transformers.TFGPT2ForSequenceClassification
< source >( config *inputs **kwargs )
参数
- config (GPT2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
GPT2模型变换器,顶部带有序列分类头(线性层)。
TFGPT2ForSequenceClassification 使用最后一个标记进行分类,就像其他因果模型(例如 GPT-1)所做的那样。
由于它对最后一个标记进行分类,因此需要知道最后一个标记的位置。如果在配置中定义了pad_token_id,它会在每一行中找到不是填充标记的最后一个标记。如果没有定义pad_token_id,它只需取批次中每一行的最后一个值。由于在传递inputs_embeds而不是input_ids时无法猜测填充标记,它会执行相同的操作(取批次中每一行的最后一个值)。
该模型继承自 TFPreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个keras.Model子类。可以将其作为常规的TF 2.0 Keras模型使用,并参考TF 2.0文档以了解与一般使用和行为相关的所有事项。
TensorFlow 模型和层在 transformers 中接受两种格式作为输入:
- 将所有输入作为关键字参数(如PyTorch模型),或
- 将所有输入作为列表、元组或字典放在第一个位置参数中。
支持第二种格式的原因是,Keras 方法在将输入传递给模型和层时更喜欢这种格式。由于这种支持,当使用像 model.fit() 这样的方法时,事情应该“正常工作”——只需以 model.fit() 支持的任何格式传递你的输入和标签!然而,如果你想在 Keras 方法之外使用第二种格式,比如在使用 Keras Functional API 创建自己的层或模型时,有三种方法可以用来将所有输入张量收集到第一个位置参数中:
- 仅包含
input_ids的单个张量,没有其他内容:model(input_ids) - 一个长度不定的列表,包含一个或多个输入张量,按照文档字符串中给出的顺序:
model([input_ids, attention_mask])或model([input_ids, attention_mask, token_type_ids]) - 一个字典,包含一个或多个与文档字符串中给出的输入名称相关联的输入张量:
model({"input_ids": input_ids, "token_type_ids": token_type_ids})
请注意,当使用子类化创建模型和层时,您不需要担心这些,因为您可以像传递任何其他Python函数一样传递输入!
调用
< source >( input_ids: TFModelInputType | None = None past_key_values: Optional[Tuple[Tuple[Union[np.ndarray, tf.Tensor]]]] = None attention_mask: np.ndarray | tf.Tensor | None = None token_type_ids: np.ndarray | tf.Tensor | None = None position_ids: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None inputs_embeds: np.ndarray | tf.Tensor | None = None use_cache: Optional[bool] = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None labels: np.ndarray | tf.Tensor | None = None training: Optional[bool] = False ) → transformers.modeling_tf_outputs.TFSequenceClassifierOutputWithPast 或 tuple(tf.Tensor)
参数
- input_ids (
Numpy arrayortf.Tensorof shape(batch_size, input_ids_length)) —input_ids_length=sequence_lengthifpast_key_valuesisNoneelsepast_key_values[0].shape[-2](sequence_lengthof input past key value states). Indices of input sequence tokens in the vocabulary.如果使用了
past_key_values,则只应将未计算其过去的输入ID作为input_ids传递。可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.call()和 PreTrainedTokenizer.encode()。
- past_key_values (
List[tf.Tensor]长度为config.n_layers) — 包含模型计算的预计算隐藏状态(注意力块中的键和值)(见下面的past_key_values输出)。可用于加速顺序解码。已经计算过的令牌ID不应作为输入ID传递,因为它们已经被计算过了。 - attention_mask (
tf.TensororNumpy arrayof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
如果使用了
past_key_values,attention_mask需要包含用于past_key_values的掩码策略。换句话说,attention_mask的长度必须始终为:len(past_key_values) + len(input_ids) - token_type_ids (
tf.TensororNumpy arrayof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
tf.TensororNumpy arrayof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
Numpy array或tf.Tensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
tf.Tensor形状为(batch_size, sequence_length, hidden_size), 可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。此参数只能在eager模式下使用,在graph模式下将使用配置中的值。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。此参数只能在eager模式下使用,在graph模式下将使用配置中的值。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。此参数可以在eager模式下使用,在graph模式下该值将始终设置为True. - 训练 (
bool, 可选, 默认为False) — 是否在训练模式下使用模型(一些模块如dropout模块在训练和评估之间有不同的行为)。 - labels (
tf.Tensorof shape(batch_size, sequence_length), optional) — 用于计算交叉熵分类损失的标签。索引应在[0, ..., config.vocab_size - 1]范围内。
返回
transformers.modeling_tf_outputs.TFSequenceClassifierOutputWithPast 或 tuple(tf.Tensor)
一个 transformers.modeling_tf_outputs.TFSequenceClassifierOutputWithPast 或一个由 tf.Tensor 组成的元组(如果
return_dict=False 被传递或当 config.return_dict=False 时),包含根据配置(GPT2Config)和输入而定的各种元素。
-
loss (
tf.Tensor形状为(batch_size, ), 可选, 当提供labels时返回) — 分类(或回归,如果 config.num_labels==1)损失。 -
logits (
tf.Tensor形状为(batch_size, config.num_labels)) — 分类(或回归,如果 config.num_labels==1)得分(在 SoftMax 之前)。 -
past_key_values (
List[tf.Tensor], 可选, 当传递use_cache=True或当config.use_cache=True时返回) — 长度为config.n_layers的tf.Tensor列表,每个张量的形状为(2, batch_size, num_heads, sequence_length, embed_size_per_head))。包含预先计算的隐藏状态(注意力块中的键和值),可用于(见
past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(tf.Tensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由tf.Tensor组成的元组(一个用于嵌入的输出 + 一个用于每层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(tf.Tensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由tf.Tensor组成的元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
TFGPT2ForSequenceClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, TFGPT2ForSequenceClassification
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/DialogRPT-updown")
>>> model = TFGPT2ForSequenceClassification.from_pretrained("microsoft/DialogRPT-updown")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
>>> logits = model(**inputs).logits
>>> predicted_class_id = int(tf.math.argmax(logits, axis=-1)[0])>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = TFGPT2ForSequenceClassification.from_pretrained("microsoft/DialogRPT-updown", num_labels=num_labels)
>>> labels = tf.constant(1)
>>> loss = model(**inputs, labels=labels).lossTFSequenceClassifierOutputWithPast
类 transformers.modeling_tf_outputs.TFSequenceClassifierOutputWithPast
< source >( loss: tf.Tensor | None = None logits: tf.Tensor = None past_key_values: List[tf.Tensor] | None = None hidden_states: Tuple[tf.Tensor] | None = None attentions: Tuple[tf.Tensor] | None = None )
参数
- loss (
tf.Tensor形状为(batch_size, ), 可选, 当提供labels时返回) — 分类(或回归,如果 config.num_labels==1)损失. - logits (
tf.Tensorof shape(batch_size, config.num_labels)) — 分类(如果 config.num_labels==1 则为回归)分数(在 SoftMax 之前)。 - past_key_values (
List[tf.Tensor], optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — List oftf.Tensorof lengthconfig.n_layers, with each tensor of shape(2, batch_size, num_heads, sequence_length, embed_size_per_head)).包含预先计算的隐藏状态(注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 - hidden_states (
tuple(tf.Tensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftf.Tensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).模型在每一层输出处的隐藏状态加上初始嵌入输出。
- attentions (
tuple(tf.Tensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftf.Tensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).注意力权重在注意力softmax之后,用于计算自注意力头中的加权平均值。
句子分类模型输出的基类。
TFGPT2Tokenizer
类 transformers.TFGPT2Tokenizer
< source >( vocab: typing.Dict[str, int] merges: typing.List[str] max_length: int = None pad_token_id: int = None )
这是一个用于GPT2的图内分词器。它应该与其他分词器类似地初始化,使用from_pretrained()方法。它也可以通过from_tokenizer()方法初始化,该方法从现有的标准分词器对象导入设置。
与其他的 Hugging Face 分词器不同,图内分词器实际上是 Keras 层,设计为在模型调用时运行,而不是在预处理期间运行。因此,它们的选项比标准的分词器类稍微有限。当你想要创建一个从 tf.string 输入直接到输出的端到端模型时,它们最为有用。
从配置创建TFGPT2Tokenizer
from_pretrained
< source >( pretrained_model_name_or_path: typing.Union[str, os.PathLike] *init_inputs **kwargs )
从预训练的GPT2Tokenizer创建TFGPT2Tokenizer
from_tokenizer
< source >( tokenizer: GPT2Tokenizer *args **kwargs )
从GPT2Tokenizer创建TFGPT2Tokenizer
FlaxGPT2Model
类 transformers.FlaxGPT2Model
< source >( config: GPT2Config input_shape: 类型.元组 = (1, 1) seed: 整数 = 0 dtype: 数据类型 =
参数
- config (GPT2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
- dtype (
jax.numpy.dtype, optional, defaults tojax.numpy.float32) — The data type of the computation. Can be one ofjax.numpy.float32,jax.numpy.float16(on GPUs) andjax.numpy.bfloat16(on TPUs).这可以用于在GPU或TPU上启用混合精度训练或半精度推理。如果指定,所有计算将使用给定的
dtype执行。请注意,这仅指定了计算的数据类型,并不影响模型参数的数据类型。
裸GPT2模型变压器输出原始隐藏状态,没有任何特定的头部。
该模型继承自FlaxPreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头等)。
该模型也是一个Flax Linen flax.nn.Module 子类。将其作为常规的Flax模块使用,并参考Flax文档以获取与一般用法和行为相关的所有信息。
最后,该模型支持JAX的固有特性,例如:
__call__
< source >( input_ids attention_mask = None position_ids = None encoder_hidden_states: typing.Optional[jax.Array] = None encoder_attention_mask: typing.Optional[jax.Array] = None params: dict = None past_key_values: dict = None dropout_rng: tuple(torch.FloatTensor)
参数
- input_ids (
numpy.ndarrayof shape(batch_size, input_ids_length)) —input_ids_length=sequence_length. Indices of input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
numpy.ndarrayof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
numpy.ndarrayof shape(batch_size, sequence_length), optional) — 每个输入序列标记在位置嵌入中的位置索引。选择范围在[0, config.max_position_embeddings - 1]之间。 - past_key_values (
Dict[str, np.ndarray], 可选, 由init_cache返回或传递先前的past_key_values) — 预计算的隐藏状态字典(注意力块中的键和值),可用于快速自回归解码。预计算的键和值隐藏状态的形状为 [batch_size, max_length]. - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。
返回
transformers.modeling_flax_outputs.FlaxBaseModelOutputWithPastAndCrossAttentions 或 tuple(torch.FloatTensor)
一个 transformers.modeling_flax_outputs.FlaxBaseModelOutputWithPastAndCrossAttentions 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(GPT2Config)和输入。
-
last_hidden_state (
jnp.ndarray形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。如果使用了
past_key_values,则只输出形状为(batch_size, 1, hidden_size)的序列的最后一个隐藏状态。 -
past_key_values (
tuple(tuple(jnp.ndarray)), 可选, 当传递了use_cache=True或当config.use_cache=True时返回) — 长度为config.n_layers的tuple(jnp.ndarray)元组,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量,并且如果config.is_encoder_decoder=True,则还包含 2 个形状为(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)的额外张量。包含预先计算的隐藏状态(自注意力块中的键和值,并且如果
config.is_encoder_decoder=True,则还包含交叉注意力块中的键和值),这些隐藏状态可以用于(参见past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(jnp.ndarray), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由jnp.ndarray组成的元组(一个用于嵌入的输出,一个用于每一层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(jnp.ndarray), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由jnp.ndarray组成的元组(每一层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
-
cross_attentions (
tuple(jnp.ndarray), 可选, 当传递了output_attentions=True和config.add_cross_attention=True或当config.output_attentions=True时返回) — 由jnp.ndarray组成的元组(每一层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器的交叉注意力层的注意力权重,在注意力 softmax 后,用于计算交叉注意力头中的加权平均值。
FlaxGPT2PreTrainedModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, FlaxGPT2Model
>>> tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
>>> model = FlaxGPT2Model.from_pretrained("openai-community/gpt2")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="jax")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateFlaxGPT2LMHeadModel
类 transformers.FlaxGPT2LMHeadModel
< source >( config: GPT2Config input_shape: 类型.元组 = (1, 1) seed: 整数 = 0 dtype: 数据类型 =
参数
- config (GPT2Config) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
- dtype (
jax.numpy.dtype, optional, defaults tojax.numpy.float32) — The data type of the computation. Can be one ofjax.numpy.float32,jax.numpy.float16(on GPUs) andjax.numpy.bfloat16(on TPUs).这可以用于在GPU或TPU上启用混合精度训练或半精度推理。如果指定,所有计算将使用给定的
dtype执行。请注意,这仅指定了计算的数据类型,并不影响模型参数的数据类型。
GPT2模型变换器,顶部带有语言建模头(线性层,权重与输入嵌入绑定)。
该模型继承自FlaxPreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头等)。
该模型也是一个Flax Linen flax.nn.Module 子类。将其作为常规的Flax模块使用,并参考Flax文档以获取与一般用法和行为相关的所有信息。
最后,该模型支持JAX的固有特性,例如:
__call__
< source >( input_ids attention_mask = None position_ids = None encoder_hidden_states: typing.Optional[jax.Array] = None encoder_attention_mask: typing.Optional[jax.Array] = None params: dict = None past_key_values: dict = None dropout_rng: tuple(torch.FloatTensor)
参数
- input_ids (
numpy.ndarrayof shape(batch_size, input_ids_length)) —input_ids_length=sequence_length. Indices of input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
numpy.ndarrayof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
numpy.ndarrayof shape(batch_size, sequence_length), optional) — 每个输入序列标记在位置嵌入中的位置索引。选择范围在[0, config.max_position_embeddings - 1]之间。 - past_key_values (
Dict[str, np.ndarray], 可选, 由init_cache返回或传递先前的past_key_values) — 预计算的隐藏状态字典(注意力块中的键和值),可用于快速自回归解码。预计算的键和值隐藏状态的形状为 [batch_size, max_length]. - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。
返回
transformers.modeling_flax_outputs.FlaxCausalLMOutputWithCrossAttentions 或 tuple(torch.FloatTensor)
一个 transformers.modeling_flax_outputs.FlaxCausalLMOutputWithCrossAttentions 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,取决于配置(GPT2Config)和输入。
-
logits (
jnp.ndarray形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前的每个词汇标记的分数)。 -
hidden_states (
tuple(jnp.ndarray), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由jnp.ndarray组成的元组(一个用于嵌入的输出 + 一个用于每一层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(jnp.ndarray), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由jnp.ndarray组成的元组(每一层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
-
cross_attentions (
tuple(jnp.ndarray), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由jnp.ndarray组成的元组(每一层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的交叉注意力权重,用于计算交叉注意力头中的加权平均值。
-
past_key_values (
tuple(tuple(jnp.ndarray)), 可选, 当传递了use_cache=True或当config.use_cache=True时返回) — 由长度为config.n_layers的jnp.ndarray元组组成的元组,每个元组包含自注意力和交叉注意力层的缓存键、值 状态,如果模型用于编码器-解码器设置。 仅在config.is_decoder = True时相关。包含预计算的隐藏状态(注意力块中的键和值),可用于(参见
past_key_values输入)以加速顺序解码。
FlaxGPT2PreTrainedModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, FlaxGPT2LMHeadModel
>>> tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
>>> model = FlaxGPT2LMHeadModel.from_pretrained("openai-community/gpt2")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="np")
>>> outputs = model(**inputs)
>>> # retrieve logts for next token
>>> next_token_logits = outputs.logits[:, -1]