Phi
概述
Phi-1模型由Suriya Gunasekar、Yi Zhang、Jyoti Aneja、Caio César Teodoro Mendes、Allie Del Giorno、Sivakanth Gopi、Mojan Javaheripi、Piero Kauffmann、Gustavo de Rosa、Olli Saarikivi、Adil Salim、Shital Shah、Harkirat Singh Behl、Xin Wang、Sébastien Bubeck、Ronen Eldan、Adam Tauman Kalai、Yin Tat Lee和Yuanzhi Li在Textbooks Are All You Need中提出。
Phi-1.5 模型由 Yuanzhi Li、Sébastien Bubeck、Ronen Eldan、Allie Del Giorno、Suriya Gunasekar 和 Yin Tat Lee 在 Textbooks Are All You Need II: phi-1.5 技术报告 中提出。
摘要
在Phi-1和Phi-1.5的论文中,作者展示了数据质量在训练中相对于模型大小的重要性。 他们选择了高质量的“教科书”数据以及合成生成的数据来训练他们的小型Transformer模型Phi-1,该模型具有13亿个参数。尽管规模较小,phi-1在HumanEval上的pass@1准确率达到50.6%,在MBPP上达到55.5%。 他们为Phi-1.5采用了相同的策略,并创建了另一个13亿参数的模型,在自然语言任务上的表现与5倍大的模型相当,并超越了大多数非前沿的LLM。Phi-1.5展示了许多更大LLM的特征,例如“逐步思考”的能力或执行一些基本的上下文学习。 通过这两个实验,作者成功地展示了训练数据质量在训练机器学习模型时的巨大影响。
Phi-1 论文的摘要如下:
我们介绍了phi-1,一个新的用于代码的大型语言模型,其规模显著小于竞争模型:phi-1是一个基于Transformer的模型,拥有13亿个参数,在8个A100上训练了4天,使用了从网络上精选的“教科书质量”数据(60亿个标记)以及使用GPT-3.5生成的合成教科书和练习(10亿个标记)。尽管规模较小,phi-1在HumanEval上的pass@1准确率达到50.6%,在MBPP上达到55.5%。与我们在编码练习数据集上进行微调阶段之前的模型phi-1-base相比,以及与我们使用相同流程训练的较小模型phi-1-small(拥有3.5亿个参数,在HumanEval上仍达到45%的准确率)相比,phi-1还显示出令人惊讶的涌现特性。
Phi-1.5 论文的摘要如下:
我们继续研究基于Transformer的小型语言模型的能力,这一研究始于TinyStories——一个拥有1000万参数的模型,能够生成连贯的英语——以及后续关于phi-1的工作,phi-1是一个拥有13亿参数的模型,其Python编码性能接近最先进水平。后者的工作提出使用现有的大型语言模型(LLMs)生成“教科书质量”的数据,作为一种与传统网络数据相比增强学习过程的方式。我们遵循“你只需要教科书”的方法,这次专注于自然语言中的常识推理,并创建了一个名为phi-1.5的新13亿参数模型,其在自然语言任务上的表现可与大5倍的模型相媲美,并在更复杂的推理任务(如小学数学和基本编码)上超越了大多数非前沿的LLMs。更广泛地说,phi-1.5展示了许多更大LLMs的特征,既有好的——例如“逐步思考”的能力或执行一些基本的上下文学习——也有坏的,包括幻觉和生成有毒和偏见内容的可能性——令人鼓舞的是,由于没有网络数据,我们在这方面看到了改进。我们开源了phi-1.5,以促进对这些紧迫主题的进一步研究。
该模型由Susnato Dhar贡献。
Phi-1、Phi-1.5 和 Phi-2 的原始代码可以分别在 这里、这里 和 这里 找到。
使用提示
- 这个模型与
Llama非常相似,主要区别在于PhiDecoderLayer,其中他们使用了并行配置的PhiAttention和PhiMLP层。 - 该模型使用的分词器与CodeGenTokenizer相同。
如何使用 Phi-2
Phi-2 已集成到 transformers 的开发版本 (4.37.0.dev) 中。在通过 pip 发布正式版本之前,请确保您执行以下操作之一:
加载模型时,确保将
trust_remote_code=True作为from_pretrained()函数的参数传递。将本地的
transformers更新到开发版本:pip uninstall -y transformers && pip install git+https://github.com/huggingface/transformers。前面的命令是克隆和从源代码安装的替代方法。
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> model = AutoModelForCausalLM.from_pretrained("microsoft/phi-2")
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-2")
>>> inputs = tokenizer('Can you help me write a formal email to a potential business partner proposing a joint venture?', return_tensors="pt", return_attention_mask=False)
>>> outputs = model.generate(**inputs, max_length=30)
>>> text = tokenizer.batch_decode(outputs)[0]
>>> print(text)
Can you help me write a formal email to a potential business partner proposing a joint venture?
Input: Company A: ABC Inc.
Company B示例:
>>> from transformers import PhiForCausalLM, AutoTokenizer
>>> # define the model and tokenizer.
>>> model = PhiForCausalLM.from_pretrained("microsoft/phi-1_5")
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-1_5")
>>> # feel free to change the prompt to your liking.
>>> prompt = "If I were an AI that had just achieved"
>>> # apply the tokenizer.
>>> tokens = tokenizer(prompt, return_tensors="pt")
>>> # use the model to generate new tokens.
>>> generated_output = model.generate(**tokens, use_cache=True, max_new_tokens=10)
>>> tokenizer.batch_decode(generated_output)[0]
'If I were an AI that had just achieved a breakthrough in machine learning, I would be thrilled'结合Phi和Flash Attention 2
首先,确保安装最新版本的 Flash Attention 2 以包含滑动窗口注意力功能。
pip install -U flash-attn --no-build-isolation
请确保您拥有与Flash-Attention 2兼容的硬件。更多信息请参阅flash-attn仓库的官方文档。同时,请确保以半精度加载您的模型(例如 `torch.float16`)。
要使用Flash Attention 2加载并运行模型,请参考以下代码片段:
>>> import torch
>>> from transformers import PhiForCausalLM, AutoTokenizer
>>> # define the model and tokenizer and push the model and tokens to the GPU.
>>> model = PhiForCausalLM.from_pretrained("microsoft/phi-1_5", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to("cuda")
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-1_5")
>>> # feel free to change the prompt to your liking.
>>> prompt = "If I were an AI that had just achieved"
>>> # apply the tokenizer.
>>> tokens = tokenizer(prompt, return_tensors="pt").to("cuda")
>>> # use the model to generate new tokens.
>>> generated_output = model.generate(**tokens, use_cache=True, max_new_tokens=10)
>>> tokenizer.batch_decode(generated_output)[0]
'If I were an AI that had just achieved a breakthrough in machine learning, I would be thrilled'预期的加速
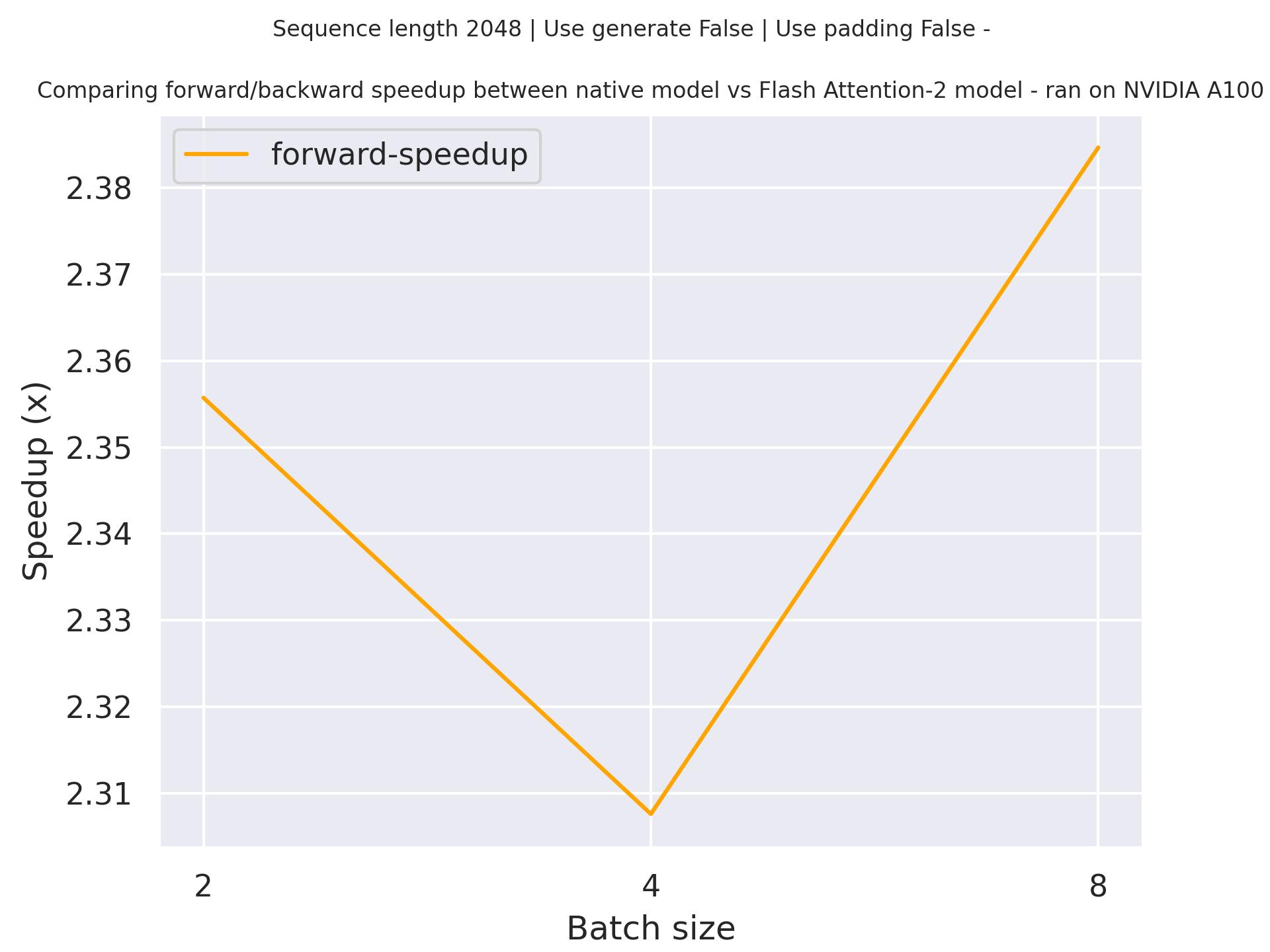
下面是一个预期的加速图,比较了使用microsoft/phi-1检查点的transformers原生实现与使用序列长度为2048的Flash Attention 2版本模型的纯推理时间。
PhiConfig
类 transformers.PhiConfig
< source >( 词汇大小 = 51200 隐藏大小 = 2048 中间大小 = 8192 隐藏层数 = 24 注意力头数 = 32 键值头数 = 无 残差丢弃率 = 0.0 嵌入丢弃率 = 0.0 注意力丢弃率 = 0.0 隐藏激活函数 = 'gelu_new' 最大位置嵌入 = 2048 初始化范围 = 0.02 层归一化epsilon = 1e-05 使用缓存 = 真 绑定词嵌入 = 假 rope_theta = 10000.0 rope_scaling = 无 部分旋转因子 = 0.5 qk_layernorm = 假 bos_token_id = 1 eos_token_id = 2 **kwargs )
参数
- vocab_size (
int, 可选, 默认为 51200) — Phi 模型的词汇表大小。定义了可以通过调用 PhiModel 时传递的inputs_ids表示的不同标记的数量。 - hidden_size (
int, optional, defaults to 2048) — 隐藏表示的维度。 - intermediate_size (
int, optional, 默认为 8192) — MLP 表示的维度。 - num_hidden_layers (
int, 可选, 默认为 24) — Transformer 解码器中的隐藏层数。 - num_attention_heads (
int, 可选, 默认为 32) — Transformer解码器中每个注意力层的注意力头数量。 - num_key_value_heads (
int, optional) — 这是用于实现分组查询注意力的键值头的数量。如果num_key_value_heads=num_attention_heads,模型将使用多头注意力(MHA),如果num_key_value_heads=1,模型将使用多查询注意力(MQA),否则将使用GQA。当 将多头检查点转换为GQA检查点时,每个组的键和值头应通过平均池化该组中的所有原始头来构建。更多详情请查看这篇 论文。如果未指定,将默认为num_attention_heads. - resid_pdrop (
float, optional, 默认为 0.0) — MLP 输出的 dropout 概率. - embd_pdrop (
int, optional, 默认为 0.0) — 嵌入的 dropout 比例。 - attention_dropout (
float, optional, defaults to 0.0) — 在计算注意力分数后的丢弃比率。 - hidden_act (
str或function, 可选, 默认为"gelu_new") — 解码器中的非线性激活函数(函数或字符串)。 - max_position_embeddings (
int, optional, 默认为 2048) — 该模型可能使用的最大序列长度。Phi-1 和 Phi-1.5 支持最多 2048 个标记。 - initializer_range (
float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 - layer_norm_eps (
float, optional, defaults to 1e-05) — 用于rms归一化层的epsilon值。 - use_cache (
bool, 可选, 默认为True) — 模型是否应返回最后的键/值注意力(并非所有模型都使用)。仅在config.is_decoder=True时相关。是否绑定权重嵌入。 - tie_word_embeddings (
bool, optional, defaults toFalse) — 是否绑定权重嵌入 - rope_theta (
float, optional, 默认为 10000.0) — RoPE 嵌入的基础周期。 - rope_scaling (
Dict, optional) — Dictionary containing the scaling configuration for the RoPE embeddings. NOTE: if you apply new rope type and you expect the model to work on longermax_position_embeddings, we recommend you to update this value accordingly. Expected contents:rope_type(str): The sub-variant of RoPE to use. Can be one of [‘default’, ‘linear’, ‘dynamic’, ‘yarn’, ‘longrope’, ‘llama3’], with ‘default’ being the original RoPE implementation.factor(float, optional): Used with all rope types except ‘default’. The scaling factor to apply to the RoPE embeddings. In most scaling types, afactorof x will enable the model to handle sequences of length x original maximum pre-trained length.original_max_position_embeddings(int, optional): Used with ‘dynamic’, ‘longrope’ and ‘llama3’. The original max position embeddings used during pretraining.attention_factor(float, optional): Used with ‘yarn’ and ‘longrope’. The scaling factor to be applied on the attention computation. If unspecified, it defaults to value recommended by the implementation, using thefactorfield to infer the suggested value.beta_fast(float, optional): Only used with ‘yarn’. Parameter to set the boundary for extrapolation (only) in the linear ramp function. If unspecified, it defaults to 32.beta_slow(float, optional): Only used with ‘yarn’. Parameter to set the boundary for interpolation (only) in the linear ramp function. If unspecified, it defaults to 1.short_factor(List[float], optional): Only used with ‘longrope’. The scaling factor to be applied to short contexts (<original_max_position_embeddings). Must be a list of numbers with the same length as the hidden size divided by the number of attention heads divided by 2long_factor(List[float], optional): Only used with ‘longrope’. The scaling factor to be applied to long contexts (<original_max_position_embeddings). Must be a list of numbers with the same length as the hidden size divided by the number of attention heads divided by 2low_freq_factor(float, optional): Only used with ‘llama3’. Scaling factor applied to low frequency components of the RoPEhigh_freq_factor(float, optional*): Only used with ‘llama3’. Scaling factor applied to high frequency components of the RoPE - partial_rotary_factor (
float, optional, defaults to 0.5) — 查询和键中将具有旋转嵌入的百分比。 - qk_layernorm (
bool, optional, defaults toFalse) — 是否在投影隐藏状态后对查询和键进行归一化。 - bos_token_id (
int, optional, 默认为 1) — 表示序列开始的标记 id. - eos_token_id (
int, 可选, 默认为 2) — 表示序列结束的标记 id.
这是用于存储PhiModel配置的配置类。它用于根据指定的参数实例化Phi模型,定义模型架构。使用默认值实例化配置将产生类似于microsoft/phi-1的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import PhiModel, PhiConfig
>>> # Initializing a Phi-1 style configuration
>>> configuration = PhiConfig.from_pretrained("microsoft/phi-1")
>>> # Initializing a model from the configuration
>>> model = PhiModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configPhiModel
类 transformers.PhiModel
< source >( config: PhiConfig )
参数
- config (PhiConfig) — 模型配置类,包含模型的所有参数。使用配置文件初始化时不会加载与模型相关的权重,仅加载配置。查看 from_pretrained() 方法以加载模型权重。
- config — PhiConfig
裸的Phi模型输出原始隐藏状态,没有任何特定的头部。 此模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
Transformer解码器由config.num_hidden_layers层组成。每一层都是一个PhiDecoderLayer
前进
< source >( input_ids: LongTensor = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[typing.List[torch.FloatTensor]] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None cache_position: typing.Optional[torch.LongTensor] = None )
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
如果使用了
past_key_values,可以选择只输入最后的input_ids(参见past_key_values)。如果你想改变填充行为,你应该阅读
modeling_opt._prepare_decoder_attention_mask并根据你的需求进行修改。有关默认策略的更多信息,请参见论文中的图1。- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
Cacheortuple(tuple(torch.FloatTensor)), optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.允许两种格式:
- a Cache instance, see our kv cache guide;
- Tuple of
tuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)). This is also known as the legacy cache format.
模型将输出与输入相同的缓存格式。如果没有传递
past_key_values,将返回旧的缓存格式。如果使用了
past_key_values,用户可以选择只输入形状为(batch_size, 1)的最后input_ids(那些没有将其过去键值状态提供给此模型的input_ids),而不是形状为(batch_size, sequence_length)的所有input_ids。 - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - cache_position (
torch.LongTensorof shape(sequence_length), optional) — 表示输入序列标记在序列中的位置的索引。与position_ids不同, 这个张量不受填充的影响。它用于在正确的位置更新缓存并推断 完整的序列长度。
PhiModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
PhiForCausalLM
前进
< source >( input_ids: LongTensor = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[typing.List[torch.FloatTensor]] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None cache_position: typing.Optional[torch.LongTensor] = None num_logits_to_keep: int = 0 **loss_kwargs ) → transformers.modeling_outputs.CausalLMOutputWithPast 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
如果使用了
past_key_values,可以选择只输入最后的input_ids(参见past_key_values)。如果你想改变填充行为,你应该阅读
modeling_opt._prepare_decoder_attention_mask并根据你的需求进行修改。有关默认策略的更多信息,请参见论文中的图1。- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
Cacheortuple(tuple(torch.FloatTensor)), optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.允许两种格式:
- a Cache instance, see our kv cache guide;
- Tuple of
tuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)). This is also known as the legacy cache format.
模型将输出与输入相同的缓存格式。如果没有传递
past_key_values,将返回旧的缓存格式。如果使用了
past_key_values,用户可以选择只输入形状为(batch_size, 1)的最后input_ids(那些没有将其过去键值状态提供给此模型的input_ids),而不是形状为(batch_size, sequence_length)的所有input_ids。 - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制权,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - use_cache (
bool, 可选) — 如果设置为True,将返回past_key_values键值状态,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - cache_position (
torch.LongTensorof shape(sequence_length), optional) — 表示输入序列标记在序列中的位置的索引。与position_ids相反, 这个张量不受填充的影响。它用于在正确的位置更新缓存并推断 完整的序列长度。 - Args —
labels (
torch.LongTensorof shape(batch_size, sequence_length), optional): Labels for computing the masked language modeling loss. Indices should either be in[0, ..., config.vocab_size]or -100 (seeinput_idsdocstring). Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size].num_logits_to_keep (
int, 可选): 计算最后num_logits_to_keep个token的logits。如果为0,则计算所有input_ids的logits(特殊情况)。生成时只需要最后一个token的logits,仅计算该token的logits可以节省内存,这对于长序列或大词汇量来说非常重要。
返回
transformers.modeling_outputs.CausalLMOutputWithPast 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.CausalLMOutputWithPast 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(PhiConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,), 可选, 当提供labels时返回) — 语言建模损失(用于下一个标记预测)。 -
logits (
torch.FloatTensor形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
past_key_values (
tuple(tuple(torch.FloatTensor)), 可选, 当传递use_cache=True或当config.use_cache=True时返回) — 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量)包含预先计算的隐藏状态(自注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) —torch.FloatTensor元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) —torch.FloatTensor元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
PhiForCausalLM 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, PhiForCausalLM
>>> model = PhiForCausalLM.from_pretrained("microsoft/phi-1")
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-1")
>>> prompt = "This is an example script ."
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> # Generate
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
'This is an example script .\n\n\n\nfrom typing import List\n\ndef find_most_common_letter(words: List[str'生成
< source >( inputs: typing.Optional[torch.Tensor] = None generation_config: typing.Optional[transformers.generation.configuration_utils.GenerationConfig] = None logits_processor: typing.Optional[transformers.generation.logits_process.LogitsProcessorList] = None stopping_criteria: typing.Optional[transformers.generation.stopping_criteria.StoppingCriteriaList] = None prefix_allowed_tokens_fn: typing.Optional[typing.Callable[[int, torch.Tensor], typing.List[int]]] = None synced_gpus: typing.Optional[bool] = None assistant_model: typing.Optional[ForwardRef('PreTrainedModel')] = None streamer: typing.Optional[ForwardRef('BaseStreamer')] = None negative_prompt_ids: typing.Optional[torch.Tensor] = None negative_prompt_attention_mask: typing.Optional[torch.Tensor] = None **kwargs ) → ModelOutput 或 torch.LongTensor
参数
- inputs (
torch.Tensor形状根据模态不同而变化,可选) — 用作生成提示或编码器模型输入的序列。如果为None,则该方法使用bos_token_id和批量大小为 1 进行初始化。对于仅解码器模型,inputs应为input_ids格式。对于编码器-解码器模型,inputs 可以表示input_ids、input_values、input_features或pixel_values中的任意一种。 - generation_config (GenerationConfig, optional) —
The generation configuration to be used as base parametrization for the generation call.
**kwargspassed to generate matching the attributes ofgeneration_configwill override them. Ifgeneration_configis not provided, the default will be used, which has the following loading priority: 1) from thegeneration_config.jsonmodel file, if it exists; 2) from the model configuration. Please note that unspecified parameters will inherit GenerationConfig’s default values, whose documentation should be checked to parameterize generation. - logits_processor (
LogitsProcessorList, 可选) — 自定义的logits处理器,用于补充从参数和生成配置中构建的默认logits处理器。如果传递了一个已经通过参数或生成配置创建的logit处理器,则会抛出错误。此功能面向高级用户。 - stopping_criteria (
StoppingCriteriaList, 可选) — 自定义停止标准,补充了由参数和生成配置构建的默认停止标准。如果传递了一个已经由参数或生成配置创建的停止标准,则会抛出错误。如果你的停止标准依赖于scores输入,请确保你传递return_dict_in_generate=True, output_scores=True给generate。此功能面向高级用户。 - prefix_allowed_tokens_fn (
Callable[[int, torch.Tensor], List[int]], 可选) — 如果提供,此函数将约束束搜索,使其在每一步仅允许特定的令牌。如果未提供,则不应用任何约束。此函数接受2个参数:批次IDbatch_id和input_ids。它必须返回一个列表,其中包含根据批次IDbatch_id和先前生成的令牌inputs_ids条件允许的下一生成步骤的令牌。此参数对于基于前缀的条件生成非常有用,如自回归实体检索中所述。 - synced_gpus (
bool, 可选) — 是否继续运行循环直到达到最大长度。除非被覆盖,否则在使用FullyShardedDataParallel或DeepSpeed ZeRO Stage 3与多个GPU时,此标志将设置为True,以避免一个GPU在其他GPU完成生成之前完成生成而导致死锁。否则,默认为False. - assistant_model (
PreTrainedModel, optional) — 一个可用于加速生成的辅助模型。辅助模型必须具有完全相同的分词器。当使用辅助模型预测候选标记比从您调用的生成模型运行生成快得多时,可以实现加速。因此,辅助模型应该小得多。 - streamer (
BaseStreamer, 可选) — 用于流式传输生成序列的流式处理对象。生成的令牌通过streamer.put(token_ids)传递,流式处理器负责任何进一步的处理。 - negative_prompt_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — 某些处理器(如CFG)所需的负提示。批量大小必须与输入批量大小匹配。这是一个实验性功能,未来版本可能会发生破坏性的API更改。 - negative_prompt_attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) —negative_prompt_ids的注意力掩码. - kwargs (
Dict[str, Any], 可选) —generation_config的临时参数化和/或额外的模型特定 kwargs,这些参数将被转发到模型的forward函数。如果模型是编码器-解码器模型,编码器特定的 kwargs 不应加前缀,而解码器特定的 kwargs 应加上 decoder_ 前缀。
返回
ModelOutput 或 torch.LongTensor
一个 ModelOutput(如果 return_dict_in_generate=True
或当 config.return_dict_in_generate=True)或一个 torch.LongTensor。
如果模型不是编码器-解码器模型(model.config.is_encoder_decoder=False),可能的
ModelOutput 类型有:
如果模型是编码器-解码器模型(model.config.is_encoder_decoder=True),可能的
ModelOutput 类型有:
为具有语言建模头的模型生成标记ID序列。
大多数生成控制参数都在generation_config中设置,如果没有传递,将设置为模型的默认生成配置。您可以通过将相应的参数传递给generate()来覆盖任何generation_config,例如.generate(inputs, num_beams=4, do_sample=True)。
有关生成策略和代码示例的概述,请查看以下指南。
PhiForSequenceClassification
类 transformers.PhiForSequenceClassification
< source >( config )
参数
- config (PhiConfig) — 模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
带有序列分类头(线性层)的PhiModel。
PhiForSequenceClassification 使用最后一个标记进行分类,与其他因果模型(例如 GPT-2)相同。
由于它对最后一个标记进行分类,因此需要知道最后一个标记的位置。如果在配置中定义了pad_token_id,它会在每一行中找到不是填充标记的最后一个标记。如果没有定义pad_token_id,它只需取批次中每一行的最后一个值。由于在传递inputs_embeds而不是input_ids时无法猜测填充标记,它会执行相同的操作(取批次中每一行的最后一个值)。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Union[transformers.cache_utils.Cache, typing.List[torch.FloatTensor], NoneType] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None )
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
如果使用了
past_key_values,可以选择只输入最后的input_ids(参见past_key_values)。如果你想改变填充行为,你应该阅读
modeling_opt._prepare_decoder_attention_mask并根据你的需求进行修改。有关默认策略的更多信息,请参见论文中的图1。- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
Cacheortuple(tuple(torch.FloatTensor)), optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.允许两种格式:
- a Cache instance, see our kv cache guide;
- Tuple of
tuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)). This is also known as the legacy cache format.
模型将输出与输入相同的缓存格式。如果没有传递
past_key_values,将返回旧的缓存格式。如果使用了
past_key_values,用户可以选择只输入形状为(batch_size, 1)的最后input_ids(那些没有将其过去键值状态提供给此模型的input_ids),而不是形状为(batch_size, sequence_length)的所有input_ids。 - inputs_embeds (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size), 可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - cache_position (
torch.LongTensorof shape(sequence_length), optional) — 表示输入序列标记在序列中的位置的索引。与position_ids相反, 这个张量不受填充的影响。它用于在正确的位置更新缓存并推断 完整的序列长度。 - labels (
torch.LongTensorof shape(batch_size,), optional) — 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
PhiForSequenceClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
PhiForTokenClassification
类 transformers.PhiForTokenClassification
< source >( config: PhiConfig )
参数
- config (PhiConfig) — 模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
PhiModel 带有一个位于顶部的标记分类头(在隐藏状态输出之上的线性层),例如用于命名实体识别(NER)任务。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[typing.Tuple[typing.Tuple[torch.Tensor, torch.Tensor], ...]] = None attention_mask: typing.Optional[torch.Tensor] = None inputs_embeds: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.Tensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None **deprecated_arguments ) → transformers.modeling_outputs.TokenClassifierOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
如果使用了
past_key_values,可以选择只输入最后的input_ids(参见past_key_values)。如果你想改变填充行为,你应该阅读
modeling_opt._prepare_decoder_attention_mask并根据你的需求进行修改。有关默认策略的更多信息,请参见论文中的图1。- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
Cacheortuple(tuple(torch.FloatTensor)), optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.允许两种格式:
- a Cache instance, see our kv cache guide;
- Tuple of
tuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)). This is also known as the legacy cache format.
模型将输出与输入相同的缓存格式。如果没有传递
past_key_values,将返回旧的缓存格式。如果使用了
past_key_values,用户可以选择只输入形状为(batch_size, 1)的最后input_ids(那些没有将其过去键值状态提供给此模型的input_ids),而不是形状为(batch_size, sequence_length)的所有input_ids。 - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - use_cache (
bool, 可选) — 如果设置为True,将返回past_key_values键值状态,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - cache_position (
torch.LongTensorof shape(sequence_length), optional) — 表示输入序列标记在序列中的位置的索引。与position_ids不同, 这个张量不受填充的影响。它用于在正确的位置更新缓存并推断 完整的序列长度。 - labels (
torch.LongTensorof shape(batch_size,), optional) — 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.TokenClassifierOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.TokenClassifierOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(PhiConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,), 可选, 当提供labels时返回) — 分类损失。 -
logits (
torch.FloatTensor形状为(batch_size, sequence_length, config.num_labels)) — 分类分数(在 SoftMax 之前)。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
PhiForTokenClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, PhiForTokenClassification
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-1")
>>> model = PhiForTokenClassification.from_pretrained("microsoft/phi-1")
>>> inputs = tokenizer(
... "HuggingFace is a company based in Paris and New York", add_special_tokens=False, return_tensors="pt"
... )
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_token_class_ids = logits.argmax(-1)
>>> # Note that tokens are classified rather then input words which means that
>>> # there might be more predicted token classes than words.
>>> # Multiple token classes might account for the same word
>>> predicted_tokens_classes = [model.config.id2label[t.item()] for t in predicted_token_class_ids[0]]
>>> labels = predicted_token_class_ids
>>> loss = model(**inputs, labels=labels).loss