Jamba
概述
Jamba 是一种先进的混合 SSM-Transformer 大型语言模型。它是第一个生产规模的 Mamba 实现,为研究和应用开辟了有趣的机会。虽然初步实验显示出令人鼓舞的成果,但我们预计这些成果将通过未来的优化和探索进一步增强。
有关此模型的完整详细信息,请阅读发布博客文章。
模型详情
Jamba 是一个预训练的专家混合(MoE)生成文本模型,具有120亿个活跃参数和所有专家总共520亿个参数。它支持256K的上下文长度,并且可以在单个80GB的GPU上容纳多达140K的令牌。
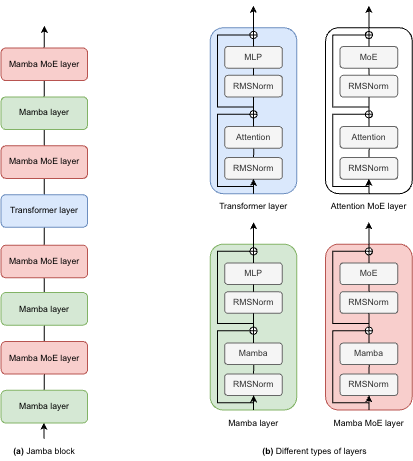
如下图所示,Jamba的架构采用了块和层的方法,使得Jamba能够成功地将Transformer和Mamba架构整合在一起。每个Jamba块包含一个注意力层或一个Mamba层,随后是一个多层感知器(MLP),总体比例为每八层中有一层是Transformer层。
用法
先决条件
Jamba 要求您使用 transformers 版本 4.39.0 或更高版本:
pip install transformers>=4.39.0
为了运行优化的Mamba实现,首先需要安装 mamba-ssm 和 causal-conv1d:
pip install mamba-ssm causal-conv1d>=1.2.0
您还需要将模型放在CUDA设备上。
你可以不使用优化的Mamba内核来运行模型,但不建议这样做,因为它会导致显著更高的延迟。为了做到这一点,你需要在加载模型时指定use_mamba_kernels=False。
运行模型
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("ai21labs/Jamba-v0.1")
tokenizer = AutoTokenizer.from_pretrained("ai21labs/Jamba-v0.1")
input_ids = tokenizer("In the recent Super Bowl LVIII,", return_tensors='pt').to(model.device)["input_ids"]
outputs = model.generate(input_ids, max_new_tokens=216)
print(tokenizer.batch_decode(outputs))
# ["<|startoftext|>In the recent Super Bowl LVIII, the Kansas City Chiefs emerged victorious, defeating the San Francisco 49ers in a thrilling overtime showdown. The game was a nail-biter, with both teams showcasing their skills and determination.\n\nThe Chiefs, led by their star quarterback Patrick Mahomes, displayed their offensive prowess, while the 49ers, led by their strong defense, put up a tough fight. The game went into overtime, with the Chiefs ultimately securing the win with a touchdown.\n\nThe victory marked the Chiefs' second Super Bowl win in four years, solidifying their status as one of the top teams in the NFL. The game was a testament to the skill and talent of both teams, and a thrilling end to the NFL season.\n\nThe Super Bowl is not just about the game itself, but also about the halftime show and the commercials. This year's halftime show featured a star-studded lineup, including Usher, Alicia Keys, and Lil Jon. The show was a spectacle of music and dance, with the performers delivering an energetic and entertaining performance.\n"]Loading the model in half precision
发布的检查点以BF16格式保存。为了将其以BF16/FP16格式加载到RAM中,您需要指定torch_dtype:
from transformers import AutoModelForCausalLM
import torch
model = AutoModelForCausalLM.from_pretrained("ai21labs/Jamba-v0.1", torch_dtype=torch.bfloat16)
# you can also use torch_dtype=torch.float16在使用半精度时,您可以启用FlashAttention2实现的注意力块。为了使用它,您还需要将模型放在CUDA设备上。由于在这种精度下,模型太大无法适应单个80GB GPU,您还需要使用accelerate进行并行化:
from transformers import AutoModelForCausalLM
import torch
model = AutoModelForCausalLM.from_pretrained("ai21labs/Jamba-v0.1",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="auto")Load the model in 8-bit
使用8位精度,可以在单个80GB GPU上容纳高达140K的序列长度。 你可以使用bitsandbytes轻松将模型量化为8位。为了不降低模型质量,我们建议将Mamba块从量化中排除:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True, llm_int8_skip_modules=["mamba"])
model = AutoModelForCausalLM.from_pretrained(
"ai21labs/Jamba-v0.1", torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2", quantization_config=quantization_config
)JambaConfig
类 transformers.JambaConfig
< source >( vocab_size = 65536 tie_word_embeddings = False hidden_size = 4096 intermediate_size = 14336 num_hidden_layers = 32 num_attention_heads = 32 num_key_value_heads = 8 hidden_act = 'silu' initializer_range = 0.02 rms_norm_eps = 1e-06 use_cache = True num_logits_to_keep = 1 output_router_logits = False router_aux_loss_coef = 0.001 pad_token_id = 0 bos_token_id = 1 eos_token_id = 2 sliding_window = None max_position_embeddings = 262144 attention_dropout = 0.0 num_experts_per_tok = 2 num_experts = 16 expert_layer_period = 2 expert_layer_offset = 1 attn_layer_period = 8 attn_layer_offset = 4 use_mamba_kernels = True mamba_d_state = 16 mamba_d_conv = 4 mamba_expand = 2 mamba_dt_rank = 'auto' mamba_conv_bias = True mamba_proj_bias = False **kwargs )
参数
- vocab_size (
int, optional, 默认为 65536) — Jamba 模型的词汇表大小。定义了可以通过调用 JambaModel 时传递的inputs_ids表示的不同标记的数量 - tie_word_embeddings (
bool, optional, defaults toFalse) — 模型是否应该绑定输入和输出的词嵌入。请注意,这仅在模型具有输出词嵌入层时相关。 - hidden_size (
int, optional, 默认为 4096) — 隐藏表示的维度。 - intermediate_size (
int, optional, 默认为14336) — MLP表示的维度。 - num_hidden_layers (
int, optional, 默认为 32) — Transformer 编码器中的隐藏层数量。 - num_attention_heads (
int, optional, 默认为 32) — Transformer 编码器中每个注意力层的注意力头数。 - num_key_value_heads (
int, 可选, 默认为 8) — 这是用于实现分组查询注意力(Grouped Query Attention)的键值头数量。如果num_key_value_heads=num_attention_heads,模型将使用多头注意力(MHA),如果num_key_value_heads=1,模型将使用多查询注意力(MQA),否则将使用GQA。当 将多头检查点转换为GQA检查点时,每个组的键和值头应通过对该组内所有原始头进行平均池化来构建。更多详细信息请查看这篇 论文。如果未指定,将默认为8. - hidden_act (
str或function, 可选, 默认为"silu") — 解码器中的非线性激活函数(函数或字符串)。 - initializer_range (
float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 - rms_norm_eps (
float, optional, defaults to 1e-06) — rms归一化层使用的epsilon值。 - use_cache (
bool, 可选, 默认为True) — 模型是否应返回最后的键/值注意力(并非所有模型都使用)。仅在config.is_decoder=True时相关。 - num_logits_to_keep (
int或None, 可选, 默认为 1) — 在生成过程中要计算的提示 logits 的数量。如果为None,将计算所有 logits。如果为整数值,则仅计算最后num_logits_to_keep个 logits。默认值为 1,因为生成只需要最后一个提示 token 的 logits。对于长序列,整个序列的 logits 可能会占用大量内存,因此设置num_logits_to_keep=1将显著减少内存占用。 - output_router_logits (
bool, 可选, 默认为False) — 是否应由模型返回路由器logits。启用此选项还将允许模型输出辅助损失。有关更多详细信息,请参见 这里 - router_aux_loss_coef (
float, optional, defaults to 0.001) — 总损失的辅助损失因子。 - pad_token_id (
int, optional, defaults to 0) — 填充令牌的ID。 - bos_token_id (
int, optional, defaults to 1) — “序列开始”标记的ID。 - eos_token_id (
int, optional, defaults to 2) — “序列结束”标记的id. - sliding_window (
int, optional) — 滑动窗口注意力窗口大小。如果未指定,将默认为None. - max_position_embeddings (
int, 可选, 默认为 262144) — 这个值没有任何实际效果。这是模型预期使用的最大序列长度。它可以用于更长的序列,但性能可能会下降。 - attention_dropout (
float, optional, defaults to 0.0) — 注意力概率的丢弃比率。 - num_experts_per_tok (
int, 可选, 默认为 2) — 每个令牌的专家数量,也可以解释为top-p路由参数 - num_experts (
int, optional, defaults to 16) — 每个稀疏MLP层的专家数量。 - expert_layer_period (
int, optional, defaults to 2) — 在这多层中,我们将有一个专家层 - expert_layer_offset (
int, optional, defaults to 1) — 包含专家mlp层的第一层索引 - attn_layer_period (
int, optional, defaults to 8) — 在这多层中,我们将有一个普通的注意力层 - attn_layer_offset (
int, optional, 默认为 4) — 第一个包含普通注意力mlp层的层索引 - use_mamba_kernels (
bool, 可选, 默认为True) — 标志指示是否使用快速的mamba内核。这些仅在安装了mamba-ssm和causal-conv1d,并且mamba模块在CUDA设备上运行时可用。如果True且内核不可用,则引发ValueError - mamba_d_state (
int, optional, defaults to 16) — mamba状态空间潜变量的维度 - mamba_d_conv (
int, optional, defaults to 4) — mamba卷积核的大小 - mamba_expand (
int, 可选, 默认为 2) — 扩展因子(相对于 hidden_size)用于确定 mamba 中间大小 - mamba_dt_rank (
Union[int,str], 可选, 默认为"auto") — mamba离散化投影矩阵的秩。"auto"表示它将默认为math.ceil(self.hidden_size / 16) - mamba_conv_bias (
bool, optional, defaults toTrue) — 标志指示是否在mamba混合器块的卷积层中使用偏置。 - mamba_proj_bias (
bool, 可选, 默认为False) — 标志,指示是否在mamba混合器块的输入和输出投影([“in_proj”, “out_proj”])中使用偏置
这是用于存储JambaModel配置的配置类。它用于根据指定的参数实例化一个Jamba模型,定义模型架构。使用默认值实例化配置将产生与Jamba-v0.1模型类似的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
JambaModel
类 transformers.JambaModel
< source >( config: JambaConfig )
参数
- config (JambaConfig) — 模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型相关的权重,仅加载配置。查看 from_pretrained() 方法以加载模型权重。
- config — JambaConfig
裸的Jamba模型输出原始的隐藏状态,没有任何特定的头部。 该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
Transformer解码器由config.num_hidden_layers层组成。每一层都是一个JambaDecoderLayer
前进
< source >( input_ids: LongTensor = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[transformers.models.jamba.modeling_jamba.HybridMambaAttentionDynamicCache] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None output_router_logits: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None cache_position: typing.Optional[torch.LongTensor] = None )
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
如果使用了
past_key_values,可以选择只输入最后的input_ids(参见past_key_values)。如果你想改变填充行为,你应该阅读
modeling_opt._prepare_decoder_attention_mask并根据你的需求进行修改。有关默认策略的更多信息,请参见论文中的图1。- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
HybridMambaAttentionDynamicCache, optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — A HybridMambaAttentionDynamicCache object containing pre-computed hidden-states (keys and values in the self-attention blocks and convolution and ssm states in the mamba blocks) that can be used (seepast_key_valuesinput) to speed up sequential decoding. Key and value cache tensors have shape(batch_size, num_heads, seq_len, head_dim). Convolution and ssm states tensors have shape(batch_size, d_inner, d_conv)and(batch_size, d_inner, d_state)respectively. See theHybridMambaAttentionDynamicCacheclass for more details.如果使用了
past_key_values,用户可以选择只输入形状为(batch_size, 1)的最后input_ids(那些没有将其过去键值状态提供给此模型的),而不是形状为(batch_size, sequence_length)的所有input_ids。 - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - output_router_logits (
bool, optional) — 是否返回所有路由器的logits。它们对于计算路由器损失非常有用,并且在推理期间不应返回。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - cache_position (
torch.LongTensorof shape(sequence_length), optional) — 表示输入序列标记在序列中的位置的索引。与position_ids不同, 这个张量不受填充的影响。它用于在正确的位置更新缓存并推断 完整的序列长度。
JambaModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
JambaForCausalLM
前进
< source >( input_ids: LongTensor = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[transformers.models.jamba.modeling_jamba.HybridMambaAttentionDynamicCache] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None output_router_logits: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None cache_position: typing.Optional[torch.LongTensor] = None num_logits_to_keep: typing.Optional[int] = None **loss_kwargs ) → transformers.modeling_outputs.MoeCausalLMOutputWithPast 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
如果使用了
past_key_values,可以选择只输入最后的input_ids(参见past_key_values)。如果你想改变填充行为,你应该阅读
modeling_opt._prepare_decoder_attention_mask并根据你的需求进行修改。有关默认策略的更多信息,请参见论文中的图1。- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
HybridMambaAttentionDynamicCache, optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — A HybridMambaAttentionDynamicCache object containing pre-computed hidden-states (keys and values in the self-attention blocks and convolution and ssm states in the mamba blocks) that can be used (seepast_key_valuesinput) to speed up sequential decoding. Key and value cache tensors have shape(batch_size, num_heads, seq_len, head_dim). Convolution and ssm states tensors have shape(batch_size, d_inner, d_conv)and(batch_size, d_inner, d_state)respectively. See theHybridMambaAttentionDynamicCacheclass for more details.如果使用了
past_key_values,用户可以选择只输入形状为(batch_size, 1)的最后input_ids(那些没有将其过去键值状态提供给此模型的),而不是形状为(batch_size, sequence_length)的所有input_ids。 - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - output_router_logits (
bool, optional) — 是否返回所有路由器的logits。它们对于计算路由器损失非常有用,并且 在推理期间不应返回。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - cache_position (
torch.LongTensorof shape(sequence_length), optional) — 表示输入序列标记在序列中的位置的索引。与position_ids相反, 这个张量不受填充的影响。它用于在正确的位置更新缓存并推断 完整的序列长度。 - Args —
labels (
torch.LongTensorof shape(batch_size, sequence_length), optional): Labels for computing the masked language modeling loss. Indices should either be in[0, ..., config.vocab_size]or -100 (seeinput_idsdocstring). Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size].num_logits_to_keep (
int或None, 可选): 计算最后num_logits_to_keep个 token 的 logits。如果为None,则计算所有input_ids的 logits。生成时只需要最后一个 token 的 logits,仅计算该 token 的 logits 可以节省内存,这对于长序列来说非常重要。
返回
transformers.modeling_outputs.MoeCausalLMOutputWithPast 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.MoeCausalLMOutputWithPast 或一个由 torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含根据配置(JambaConfig)和输入而定的各种元素。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 语言建模损失(用于下一个词的预测)。 -
logits (
torch.FloatTensor形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
aux_loss (
torch.FloatTensor,可选,当提供labels时返回) — 稀疏模块的辅助损失。 -
router_logits (
tuple(torch.FloatTensor),可选,当传递output_router_probs=True和config.add_router_probs=True或当config.output_router_probs=True时返回) — 由torch.FloatTensor组成的元组(每层一个),形状为(batch_size, sequence_length, num_experts)。由 MoE 路由器计算的原始路由器 logits(softmax 后),这些项用于计算专家混合模型的辅助损失。
-
past_key_values (
tuple(tuple(torch.FloatTensor)),可选,当传递use_cache=True或当config.use_cache=True时返回) — 由tuple(torch.FloatTensor)组成的元组,长度为config.n_layers,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量。包含预计算的隐藏状态(自注意力块中的键和值),可用于加速顺序解码(参见
past_key_values输入)。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
JambaForCausalLM 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, JambaForCausalLM
>>> model = JambaForCausalLM.from_pretrained("ai21labs/Jamba-v0.1")
>>> tokenizer = AutoTokenizer.from_pretrained("ai21labs/Jamba-v0.1")
>>> prompt = "Hey, are you conscious? Can you talk to me?"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> # Generate
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
"Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."JambaForSequenceClassification
类 transformers.JambaForSequenceClassification
< source >( config )
参数
- config (JambaConfig) — 模型配置类,包含模型的所有参数。使用配置文件初始化时不会加载与模型相关的权重,仅加载配置。查看 from_pretrained() 方法以加载模型权重。
Jamba模型顶部带有序列分类头(线性层)。
JambaForSequenceClassification 使用最后一个标记进行分类,就像其他因果模型(例如 GPT-2)所做的那样。
由于它对最后一个标记进行分类,因此需要知道最后一个标记的位置。如果在配置中定义了pad_token_id,它会在每一行中找到不是填充标记的最后一个标记。如果没有定义pad_token_id,它只需取批次中每一行的最后一个值。由于在传递inputs_embeds而不是input_ids时无法猜测填充标记,它会执行相同的操作(取批次中每一行的最后一个值)。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Union[transformers.cache_utils.Cache, typing.List[torch.FloatTensor], NoneType] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None )
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
如果使用了
past_key_values,可以选择只输入最后的input_ids(参见past_key_values)。如果你想改变填充行为,你应该阅读
modeling_opt._prepare_decoder_attention_mask并根据你的需求进行修改。有关默认策略的更多信息,请参见论文中的图1。- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
HybridMambaAttentionDynamicCache, optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — A HybridMambaAttentionDynamicCache object containing pre-computed hidden-states (keys and values in the self-attention blocks and convolution and ssm states in the mamba blocks) that can be used (seepast_key_valuesinput) to speed up sequential decoding. Key and value cache tensors have shape(batch_size, num_heads, seq_len, head_dim). Convolution and ssm states tensors have shape(batch_size, d_inner, d_conv)and(batch_size, d_inner, d_state)respectively. See theHybridMambaAttentionDynamicCacheclass for more details.如果使用了
past_key_values,用户可以选择只输入形状为(batch_size, 1)的最后input_ids(那些没有将其过去键值状态提供给此模型的),而不是形状为(batch_size, sequence_length)的所有input_ids。 - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - output_router_logits (
bool, optional) — 是否返回所有路由器的logits。它们对于计算路由器损失非常有用,并且 在推理期间不应返回。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - cache_position (
torch.LongTensorof shape(sequence_length), optional) — 表示输入序列标记在序列中的位置的索引。与position_ids不同, 这个张量不受填充的影响。它用于在正确的位置更新缓存并推断 完整的序列长度。 - labels (
torch.LongTensorof shape(batch_size,), optional) — 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
JambaForSequenceClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。