M2M100
概述
M2M100模型由Angela Fan、Shruti Bhosale、Holger Schwenk、Zhiyi Ma、Ahmed El-Kishky、Siddharth Goyal、Mandeep Baines、Onur Celebi、Guillaume Wenzek、Vishrav Chaudhary、Naman Goyal、Tom Birch、Vitaliy Liptchinsky、Sergey Edunov、Edouard Grave、Michael Auli、Armand Joulin在Beyond English-Centric Multilingual Machine Translation中提出。
论文的摘要如下:
现有的翻译工作展示了通过训练一个能够在任何语言对之间进行翻译的单一模型来实现大规模多语言机器翻译的潜力。然而,这些工作大多以英语为中心,仅使用从英语翻译或翻译成英语的数据进行训练。虽然这得到了大量训练数据的支持,但它并不能反映全球的翻译需求。在这项工作中,我们创建了一个真正的多对多多语言翻译模型,能够直接在100种语言中的任何一对之间进行翻译。我们构建并开源了一个训练数据集,该数据集通过大规模挖掘创建,涵盖了数千种语言方向的监督数据。然后,我们探索如何通过密集缩放和特定语言的稀疏参数组合来有效增加模型容量,以创建高质量的模型。我们对非英语中心模型的关注使得在非英语方向之间直接翻译时,BLEU得分提高了10分以上,同时在与WMT的最佳单一系统竞争时表现出色。我们开源了我们的脚本,以便其他人可以复制数据、评估和最终的M2M-100模型。
该模型由valhalla贡献。
使用技巧和示例
M2M100 是一个多语言编码器-解码器(序列到序列)模型,主要用于翻译任务。由于该模型是多语言的,它期望序列以特定格式输入:在源文本和目标文本中都使用一个特殊的语言标识符作为前缀。源文本的格式是 [lang_code] X [eos],其中 lang_code 是源文本的源语言标识符和目标文本的目标语言标识符,X 是源文本或目标文本。
M2M100Tokenizer 依赖于 sentencepiece,因此在运行示例之前请确保安装它。要安装 sentencepiece,请运行 pip install sentencepiece。
监督训练
from transformers import M2M100Config, M2M100ForConditionalGeneration, M2M100Tokenizer
model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="en", tgt_lang="fr")
src_text = "Life is like a box of chocolates."
tgt_text = "La vie est comme une boîte de chocolat."
model_inputs = tokenizer(src_text, text_target=tgt_text, return_tensors="pt")
loss = model(**model_inputs).loss # forward pass生成
M2M100 使用 eos_token_id 作为 decoder_start_token_id 进行生成,目标语言 ID 被强制作为第一个生成的 token。要将目标语言 ID 强制作为第一个生成的 token,请将 forced_bos_token_id 参数传递给 generate 方法。以下示例展示了如何使用 facebook/m2m100_418M 检查点在印地语到法语和中文到英语之间进行翻译。
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> hi_text = "जीवन एक चॉकलेट बॉक्स की तरह है।"
>>> chinese_text = "生活就像一盒巧克力。"
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M")
>>> # translate Hindi to French
>>> tokenizer.src_lang = "hi"
>>> encoded_hi = tokenizer(hi_text, return_tensors="pt")
>>> generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.get_lang_id("fr"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"La vie est comme une boîte de chocolat."
>>> # translate Chinese to English
>>> tokenizer.src_lang = "zh"
>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"Life is like a box of chocolate."资源
M2M100Config
类 transformers.M2M100Config
< source >( vocab_size = 128112 max_position_embeddings = 1024 encoder_layers = 12 encoder_ffn_dim = 4096 encoder_attention_heads = 16 decoder_layers = 12 decoder_ffn_dim = 4096 decoder_attention_heads = 16 encoder_layerdrop = 0.05 decoder_layerdrop = 0.05 use_cache = True is_encoder_decoder = True activation_function = 'relu' d_model = 1024 dropout = 0.1 attention_dropout = 0.1 activation_dropout = 0.0 init_std = 0.02 decoder_start_token_id = 2 scale_embedding = True pad_token_id = 1 bos_token_id = 0 eos_token_id = 2 **kwargs )
参数
- vocab_size (
int, 可选, 默认为 50265) — M2M100 模型的词汇表大小。定义了可以通过调用 M2M100Model 时传递的inputs_ids表示的不同标记的数量 - d_model (
int, 可选, 默认为 1024) — 层和池化层的维度。 - encoder_layers (
int, optional, defaults to 12) — 编码器层数. - decoder_layers (
int, optional, defaults to 12) — 解码器层数. - encoder_attention_heads (
int, optional, defaults to 16) — Transformer编码器中每个注意力层的注意力头数。 - decoder_attention_heads (
int, optional, defaults to 16) — Transformer解码器中每个注意力层的注意力头数量。 - decoder_ffn_dim (
int, optional, defaults to 4096) — 解码器中“中间”(通常称为前馈)层的维度。 - encoder_ffn_dim (
int, optional, defaults to 4096) — 解码器中“中间”(通常称为前馈)层的维度。 - activation_function (
str或function, 可选, 默认为"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"silu"和"gelu_new"。 - dropout (
float, optional, defaults to 0.1) — 嵌入层、编码器和池化器中所有全连接层的dropout概率。 - attention_dropout (
float, optional, 默认为 0.0) — 注意力概率的丢弃比率。 - activation_dropout (
float, optional, defaults to 0.0) — 全连接层内激活函数的丢弃比率。 - classifier_dropout (
float, optional, 默认为 0.0) — 分类器的丢弃比率。 - max_position_embeddings (
int, optional, 默认为 1024) — 此模型可能使用的最大序列长度。通常将其设置为较大的值以防万一(例如,512 或 1024 或 2048)。 - init_std (
float, optional, 默认为 0.02) — 用于初始化所有权重矩阵的 truncated_normal_initializer 的标准差。 - encoder_layerdrop (
float, optional, 默认为 0.0) — 编码器的LayerDrop概率。有关更多详细信息,请参阅[LayerDrop论文](见 https://arxiv.org/abs/1909.11556)。 - decoder_layerdrop (
float, 可选, 默认为 0.0) — 解码器的LayerDrop概率。有关更多详细信息,请参阅[LayerDrop论文](见 https://arxiv.org/abs/1909.11556)。 - use_cache (
bool, 可选, 默认为True) — 模型是否应返回最后的键/值注意力(并非所有模型都使用)。
这是用于存储M2M100Model配置的配置类。它用于根据指定的参数实例化一个M2M100模型,定义模型架构。使用默认值实例化配置将产生与M2M100 facebook/m2m100_418M架构类似的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import M2M100Config, M2M100Model
>>> # Initializing a M2M100 facebook/m2m100_418M style configuration
>>> configuration = M2M100Config()
>>> # Initializing a model (with random weights) from the facebook/m2m100_418M style configuration
>>> model = M2M100Model(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configM2M100Tokenizer
类 transformers.M2M100Tokenizer
< source >( vocab_file spm_file src_lang = 无 tgt_lang = 无 bos_token = '' eos_token = '' sep_token = '' pad_token = '
参数
- vocab_file (
str) — 词汇表文件的路径。 - spm_file (
str) — 指向SentencePiece文件的路径(通常具有.spm扩展名),该文件包含词汇表。 - src_lang (
str, optional) — 表示源语言的字符串。 - tgt_lang (
str, optional) — 表示目标语言的字符串。 - eos_token (
str, optional, defaults to"") — 序列结束标记。 - sep_token (
str, 可选, 默认为"") — 分隔符标记,用于从多个序列构建序列时,例如用于序列分类的两个序列或用于问答的文本和问题。它也用作使用特殊标记构建的序列的最后一个标记。 - unk_token (
str, optional, defaults to") — 未知标记。不在词汇表中的标记无法转换为ID,而是设置为这个标记。" - pad_token (
str, optional, defaults to") — 用于填充的标记,例如在对不同长度的序列进行批处理时使用。" - language_codes (
str, 可选, 默认为"m2m100") — 使用哪种语言代码。应为"m2m100"或"wmt21"之一。 - sp_model_kwargs (
dict, optional) — Will be passed to theSentencePieceProcessor.__init__()method. The Python wrapper for SentencePiece can be used, among other things, to set:-
enable_sampling: 启用子词正则化。 -
nbest_size: 用于unigram的采样参数。对于BPE-Dropout无效。nbest_size = {0,1}: No sampling is performed.nbest_size > 1: samples from the nbest_size results.nbest_size < 0: assuming that nbest_size is infinite and samples from the all hypothesis (lattice) using forward-filtering-and-backward-sampling algorithm.
-
alpha: 用于单字采样的平滑参数,以及BPE-dropout的合并操作丢弃概率。
-
构建一个M2M100分词器。基于SentencePiece。
此分词器继承自PreTrainedTokenizer,其中包含了大部分主要方法。用户应参考此超类以获取有关这些方法的更多信息。
示例:
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="en", tgt_lang="ro")
>>> src_text = " UN Chief Says There Is No Military Solution in Syria"
>>> tgt_text = "Şeful ONU declară că nu există o soluţie militară în Siria"
>>> model_inputs = tokenizer(src_text, text_target=tgt_text, return_tensors="pt")
>>> outputs = model(**model_inputs) # should workbuild_inputs_with_special_tokens
< source >( token_ids_0: typing.List[int] token_ids_1: typing.Optional[typing.List[int]] = None ) → List[int]
通过连接和添加特殊标记,从序列或序列对构建序列分类任务的模型输入。一个MBART序列具有以下格式,其中X代表序列:
input_ids(用于编码器)X [eos, src_lang_code]decoder_input_ids: (用于解码器)X [eos, tgt_lang_code]
BOS 从未被使用。序列对不是预期的使用场景,但它们将在没有分隔符的情况下处理。
get_special_tokens_mask
< source >( token_ids_0: typing.List[int] token_ids_1: typing.Optional[typing.List[int]] = None already_has_special_tokens: bool = False ) → List[int]
从没有添加特殊标记的标记列表中检索序列ID。当使用标记器的prepare_for_model方法添加特殊标记时,会调用此方法。
create_token_type_ids_from_sequences
< source >( token_ids_0: typing.List[int] token_ids_1: typing.Optional[typing.List[int]] = None ) → List[int]
创建与传递的序列相对应的令牌类型ID。什么是令牌类型ID?
如果模型有特殊的构建方式,应该在子类中重写。
M2M100Model
类 transformers.M2M100Model
< source >( config: M2M100Config )
参数
- config (M2M100Config) — 模型配置类,包含模型的所有参数。使用配置文件初始化时不会加载与模型相关的权重,仅加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的M2M100模型输出原始隐藏状态,没有任何特定的头部。 该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.Tensor] = None decoder_input_ids: typing.Optional[torch.LongTensor] = None decoder_attention_mask: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.Tensor] = None decoder_head_mask: typing.Optional[torch.Tensor] = None cross_attn_head_mask: typing.Optional[torch.Tensor] = None encoder_outputs: typing.Optional[typing.Tuple[typing.Tuple[torch.FloatTensor]]] = None past_key_values: typing.Optional[typing.Tuple[typing.Tuple[torch.FloatTensor]]] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None decoder_inputs_embeds: typing.Optional[torch.FloatTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.Seq2SeqModelOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- decoder_input_ids (
torch.LongTensorof shape(batch_size, target_sequence_length), optional) — Indices of decoder input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
M2M100 使用
eos_token_id作为decoder_input_ids生成的起始标记。如果使用了past_key_values,则可以选择只输入最后一个decoder_input_ids(参见past_key_values)。 - decoder_attention_mask (
torch.LongTensorof shape(batch_size, target_sequence_length), optional) — 默认行为:生成一个忽略decoder_input_ids中填充标记的张量。默认情况下也会使用因果掩码。 - head_mask (
torch.Tensorof shape(encoder_layers, encoder_attention_heads), optional) — 用于在编码器中屏蔽注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- decoder_head_mask (
torch.Tensorof shape(decoder_layers, decoder_attention_heads), optional) — 用于在解码器中取消选择注意力模块的头部。掩码值在[0, 1]中选择:- 1 表示头部 未被掩码,
- 0 表示头部 被掩码.
- cross_attn_head_mask (
torch.Tensorof shape(decoder_layers, decoder_attention_heads), optional) — 用于在解码器中取消选择交叉注意力模块中特定头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部未被掩码,
- 0 表示头部被掩码.
- encoder_outputs (
tuple(tuple(torch.FloatTensor), 可选) — 元组由 (last_hidden_state, 可选:hidden_states, 可选:attentions) 组成last_hidden_state的形状为(batch_size, sequence_length, hidden_size), 可选) 是编码器最后一层的输出隐藏状态序列。用于解码器的交叉注意力中。 - past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and 2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head).包含预先计算的隐藏状态(自注意力块和交叉注意力块中的键和值),这些状态可用于(参见
past_key_values输入)以加速顺序解码。如果使用了
past_key_values,用户可以选择只输入形状为(batch_size, 1)的最后一个decoder_input_ids(那些没有将其过去键值状态提供给此模型的),而不是形状为(batch_size, sequence_length)的所有decoder_input_ids。 - inputs_embeds (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size), 可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。 如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - decoder_inputs_embeds (
torch.FloatTensorof shape(batch_size, target_sequence_length, hidden_size), optional) — Optionally, instead of passingdecoder_input_idsyou can choose to directly pass an embedded representation. Ifpast_key_valuesis used, optionally only the lastdecoder_inputs_embedshave to be input (seepast_key_values). This is useful if you want more control over how to convertdecoder_input_idsindices into associated vectors than the model’s internal embedding lookup matrix.如果
decoder_input_ids和decoder_inputs_embeds都未设置,decoder_inputs_embeds将取inputs_embeds的值。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。
返回
transformers.modeling_outputs.Seq2SeqModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.Seq2SeqModelOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(M2M100Config)和输入。
-
last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size)) — 模型解码器最后一层输出的隐藏状态序列。如果使用了
past_key_values,则只输出形状为(batch_size, 1, hidden_size)的序列的最后一个隐藏状态。 -
past_key_values (
tuple(tuple(torch.FloatTensor)), 可选, 当传递了use_cache=True或当config.use_cache=True时返回) — 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量和 2 个形状为(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)的额外张量。包含预计算的隐藏状态(自注意力块和交叉注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 -
decoder_hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层的输出)形状为(batch_size, sequence_length, hidden_size)。解码器每层输出的隐藏状态加上可选的初始嵌入输出。
-
decoder_attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器的注意力权重,经过注意力 softmax 后,用于计算自注意力头中的加权平均值。
-
cross_attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器交叉注意力层的注意力权重,经过注意力 softmax 后,用于计算交叉注意力头中的加权平均值。
-
encoder_last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size), 可选) — 模型编码器最后一层输出的隐藏状态序列。 -
encoder_hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层的输出)形状为(batch_size, sequence_length, hidden_size)。编码器每层输出的隐藏状态加上可选的初始嵌入输出。
-
encoder_attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。编码器的注意力权重,经过注意力 softmax 后,用于计算自注意力头中的加权平均值。
M2M100Model 的 forward 方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, M2M100Model
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/m2m100_418M")
>>> model = M2M100Model.from_pretrained("facebook/m2m100_418M")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateM2M100ForConditionalGeneration
类 transformers.M2M100ForConditionalGeneration
< source >( config: M2M100Config )
参数
- config (M2M100Config) — 模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
带有语言建模头的M2M100模型。可用于摘要生成。 该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入大小、修剪头等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.Tensor] = None decoder_input_ids: typing.Optional[torch.LongTensor] = None decoder_attention_mask: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.Tensor] = None decoder_head_mask: typing.Optional[torch.Tensor] = None cross_attn_head_mask: typing.Optional[torch.Tensor] = None encoder_outputs: typing.Optional[typing.Tuple[typing.Tuple[torch.FloatTensor]]] = None past_key_values: typing.Optional[typing.Tuple[typing.Tuple[torch.FloatTensor]]] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None decoder_inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.Seq2SeqLMOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- decoder_input_ids (
torch.LongTensorof shape(batch_size, target_sequence_length), optional) — Indices of decoder input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
M2M100 使用
eos_token_id作为decoder_input_ids生成的起始标记。如果使用了past_key_values,则可以选择只输入最后一个decoder_input_ids(参见past_key_values)。 - decoder_attention_mask (
torch.LongTensorof shape(batch_size, target_sequence_length), optional) — 默认行为:生成一个忽略decoder_input_ids中填充标记的张量。默认情况下也会使用因果掩码。 - head_mask (
torch.Tensorof shape(encoder_layers, encoder_attention_heads), optional) — 用于在编码器中屏蔽注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- decoder_head_mask (
torch.Tensorof shape(decoder_layers, decoder_attention_heads), optional) — 用于在解码器中取消选择注意力模块的特定头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被掩码,
- 0 表示头部 被掩码.
- cross_attn_head_mask (
torch.Tensorof shape(decoder_layers, decoder_attention_heads), optional) — 用于在解码器中取消选择交叉注意力模块中特定头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被掩码,
- 0 表示头部 被掩码.
- encoder_outputs (
tuple(tuple(torch.FloatTensor), 可选) — 元组由 (last_hidden_state, 可选:hidden_states, 可选:attentions)last_hidden_state的形状为(batch_size, sequence_length, hidden_size), 可选) 是编码器最后一层输出的隐藏状态序列。用于解码器的交叉注意力中。 - past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and 2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head).包含预先计算的隐藏状态(自注意力块和交叉注意力块中的键和值),这些状态可用于(参见
past_key_values输入)以加速顺序解码。如果使用了
past_key_values,用户可以选择只输入形状为(batch_size, 1)的最后一个decoder_input_ids(那些没有将其过去键值状态提供给此模型的),而不是形状为(batch_size, sequence_length)的所有decoder_input_ids。 - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。 如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - decoder_inputs_embeds (
torch.FloatTensorof shape(batch_size, target_sequence_length, hidden_size), optional) — Optionally, instead of passingdecoder_input_idsyou can choose to directly pass an embedded representation. Ifpast_key_valuesis used, optionally only the lastdecoder_inputs_embedshave to be input (seepast_key_values). This is useful if you want more control over how to convertdecoder_input_idsindices into associated vectors than the model’s internal embedding lookup matrix.如果
decoder_input_ids和decoder_inputs_embeds都未设置,decoder_inputs_embeds将取inputs_embeds的值。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — 用于计算掩码语言建模损失的标签。索引应在[0, ..., config.vocab_size]或 -100 之间(参见input_ids文档字符串)。索引设置为-100的标记将被忽略 (掩码),损失仅针对标签在[0, ..., config.vocab_size]之间的标记计算。
返回
transformers.modeling_outputs.Seq2SeqLMOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.Seq2SeqLMOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(M2M100Config)和输入。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 语言建模损失。 -
logits (
torch.FloatTensor形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前的每个词汇标记的分数)。 -
past_key_values (
tuple(tuple(torch.FloatTensor)),可选,当传递use_cache=True或当config.use_cache=True时返回) — 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量和 2 个形状为(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)的额外张量。包含预先计算的隐藏状态(自注意力块和交叉注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 -
decoder_hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) —torch.FloatTensor的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层的输出)形状为(batch_size, sequence_length, hidden_size)。解码器在每层输出处的隐藏状态加上初始嵌入输出。
-
decoder_attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) —torch.FloatTensor的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器的注意力权重,在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
-
cross_attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) —torch.FloatTensor的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器的交叉注意力层的注意力权重,在注意力 softmax 之后,用于计算交叉注意力头中的加权平均值。
-
encoder_last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size),可选) — 模型编码器最后一层输出的隐藏状态序列。 -
encoder_hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) —torch.FloatTensor的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层的输出)形状为(batch_size, sequence_length, hidden_size)。编码器在每层输出处的隐藏状态加上初始嵌入输出。
-
encoder_attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) —torch.FloatTensor的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。编码器的注意力权重,在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
M2M100ForConditionalGeneration 的 forward 方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
翻译示例:
>>> from transformers import AutoTokenizer, M2M100ForConditionalGeneration
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/m2m100_418M")
>>> text_to_translate = "Life is like a box of chocolates"
>>> model_inputs = tokenizer(text_to_translate, return_tensors="pt")
>>> # translate to French
>>> gen_tokens = model.generate(**model_inputs, forced_bos_token_id=tokenizer.get_lang_id("fr"))
>>> print(tokenizer.batch_decode(gen_tokens, skip_special_tokens=True))使用 Flash Attention 2
Flash Attention 2 是一个更快、优化的注意力分数计算版本,它依赖于 cuda 内核。
安装
首先,检查您的硬件是否与Flash Attention 2兼容。最新的兼容硬件列表可以在官方文档中找到。
接下来,安装最新版本的Flash Attention 2:
pip install -U flash-attn --no-build-isolation
用法
要使用Flash Attention 2加载模型,我们可以将参数attn_implementation="flash_attention_2"传递给.from_pretrained。你可以使用torch.float16或torch.bfloat16精度。
>>> import torch
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to("cuda").eval()
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M")
>>> # translate Hindi to French
>>> hi_text = "जीवन एक चॉकलेट बॉक्स की तरह है।"
>>> tokenizer.src_lang = "hi"
>>> encoded_hi = tokenizer(hi_text, return_tensors="pt").to("cuda")
>>> generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.get_lang_id("fr"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"La vie est comme une boîte de chocolat."预期的加速
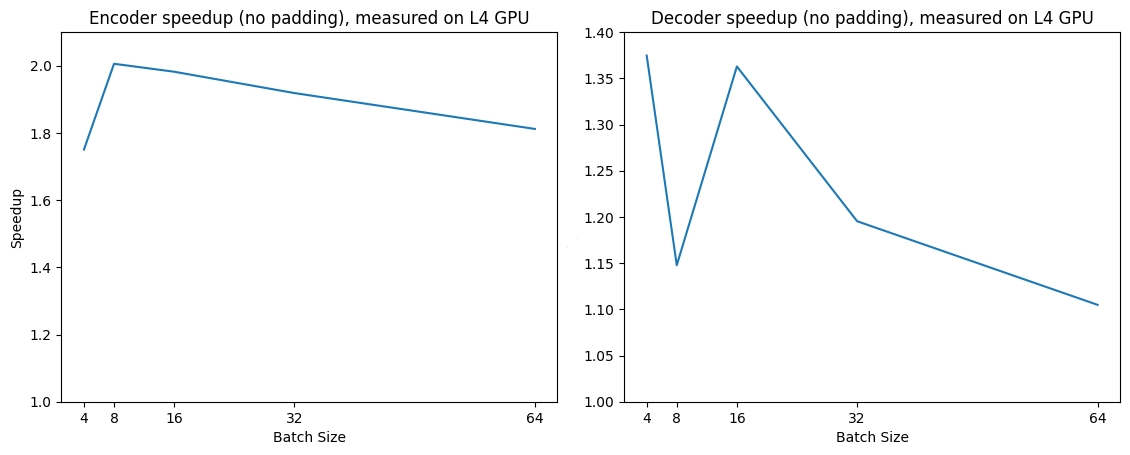
下面是一个预期的加速图,比较了原生实现和Flash Attention 2之间的纯推理时间。
使用缩放点积注意力 (SDPA)
PyTorch 包含一个原生的缩放点积注意力(SDPA)操作符,作为 torch.nn.functional 的一部分。这个函数
包含了几种实现,可以根据输入和使用的硬件进行应用。更多信息请参阅
官方文档
或 GPU 推理
页面。
默认情况下,当有可用实现时,SDPA 用于 torch>=2.1.1,但你也可以在 from_pretrained() 中设置 attn_implementation="sdpa" 来明确请求使用 SDPA。
from transformers import M2M100ForConditionalGeneration
model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M", torch_dtype=torch.float16, attn_implementation="sdpa")
...为了获得最佳加速效果,我们建议以半精度加载模型(例如 torch.float16 或 torch.bfloat16)。