MarkupLM
概述
MarkupLM模型由Junlong Li、Yiheng Xu、Lei Cui和Furu Wei在MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding中提出。MarkupLM是BERT模型,但应用于HTML页面而非原始文本文档。该模型结合了额外的嵌入层以提高性能,类似于LayoutLM。
该模型可用于网页上的问答任务或从网页中提取信息。它在两个重要的基准测试中取得了最先进的结果:
论文的摘要如下:
多模态预训练结合文本、布局和图像在视觉丰富的文档理解(VrDU)方面取得了显著进展,尤其是对于固定布局的文档,如扫描的文档图像。然而,仍有大量数字文档的布局信息不固定,需要交互式和动态渲染以实现可视化,这使得现有的基于布局的预训练方法不易应用。在本文中,我们提出了MarkupLM,用于以标记语言(如基于HTML/XML的文档)为骨干的文档理解任务,其中文本和标记信息被联合预训练。实验结果表明,预训练的MarkupLM在多个文档理解任务上显著优于现有的强基线模型。预训练模型和代码将公开提供。
使用提示
- 除了
input_ids,forward()还期望2个额外的输入,即xpath_tags_seq和xpath_subs_seq。 这些分别是输入序列中每个标记的XPATH标签和下标。 - 可以使用MarkupLMProcessor来为模型准备所有数据。更多信息请参考usage guide。
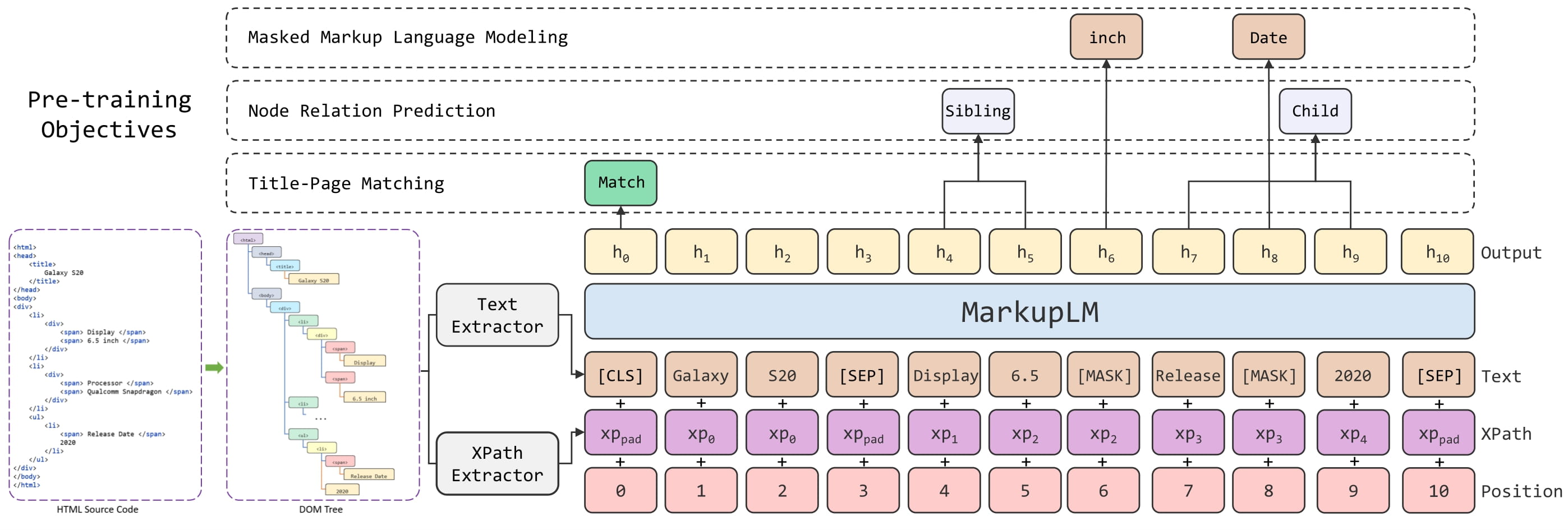 MarkupLM architecture. Taken from the original paper.
MarkupLM architecture. Taken from the original paper. 用法:MarkupLMProcessor
为模型准备数据的最简单方法是使用MarkupLMProcessor,它在内部结合了一个特征提取器
(MarkupLMFeatureExtractor)和一个分词器(MarkupLMTokenizer或MarkupLMTokenizerFast)。特征提取器用于
从HTML字符串中提取所有节点和xpath,然后将它们提供给分词器,分词器将它们转换为模型的token级输入(input_ids等)。请注意,如果您只想处理其中一项任务,仍然可以单独使用特征提取器和分词器。
from transformers import MarkupLMFeatureExtractor, MarkupLMTokenizerFast, MarkupLMProcessor
feature_extractor = MarkupLMFeatureExtractor()
tokenizer = MarkupLMTokenizerFast.from_pretrained("microsoft/markuplm-base")
processor = MarkupLMProcessor(feature_extractor, tokenizer)简而言之,可以向MarkupLMProcessor提供HTML字符串(可能还包括其他数据),它将创建模型所需的输入。在内部,处理器首先使用MarkupLMFeatureExtractor获取节点列表和相应的xpath。然后,这些节点和xpath被提供给MarkupLMTokenizer或MarkupLMTokenizerFast,它们将这些转换为标记级别的input_ids、attention_mask、token_type_ids、xpath_subs_seq、xpath_tags_seq。可选地,可以向处理器提供节点标签,这些标签将被转换为标记级别的labels。
MarkupLMFeatureExtractor 使用 Beautiful Soup,这是一个用于从HTML和XML文件中提取数据的Python库。请注意,您仍然可以选择使用自己的解析解决方案,并自行提供节点和xpath给 MarkupLMTokenizer 或 MarkupLMTokenizerFast。
总共有5个用例由处理器支持。下面,我们列出了所有这些用例。请注意,这些用例都适用于批处理和非批处理输入(我们以非批处理输入为例进行说明)。
用例1:网页分类(训练、推理)+ 标记分类(推理),parse_html = True
这是最简单的情况,处理器将使用特征提取器从HTML中获取所有节点和xpaths。
>>> from transformers import MarkupLMProcessor
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
>>> html_string = """
... <!DOCTYPE html>
... <html>
... <head>
... <title>Hello world</title>
... </head>
... <body>
... <h1>Welcome</h1>
... <p>Here is my website.</p>
... </body>
... </html>"""
>>> # note that you can also add provide all tokenizer parameters here such as padding, truncation
>>> encoding = processor(html_string, return_tensors="pt")
>>> print(encoding.keys())
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])用例2:网页分类(训练、推理)+ 标记分类(推理),parse_html=False
如果已经获取了所有节点和xpaths,就不需要特征提取器。在这种情况下,应该将节点和相应的xpaths提供给处理器,并确保将parse_html设置为False。
>>> from transformers import MarkupLMProcessor
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
>>> processor.parse_html = False
>>> nodes = ["hello", "world", "how", "are"]
>>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
>>> encoding = processor(nodes=nodes, xpaths=xpaths, return_tensors="pt")
>>> print(encoding.keys())
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])用例3:标记分类(训练),parse_html=False
对于标记分类任务(例如SWDE),还可以提供相应的节点标签以训练模型。处理器随后会将这些标签转换为标记级别的labels。默认情况下,它只会标记一个词的第一个子词,并将剩余的子词标记为-100,这是PyTorch的CrossEntropyLoss的ignore_index。如果您希望一个词的所有子词都被标记,可以将分词器初始化为only_label_first_subword设置为False。
>>> from transformers import MarkupLMProcessor
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
>>> processor.parse_html = False
>>> nodes = ["hello", "world", "how", "are"]
>>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
>>> node_labels = [1, 2, 2, 1]
>>> encoding = processor(nodes=nodes, xpaths=xpaths, node_labels=node_labels, return_tensors="pt")
>>> print(encoding.keys())
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq', 'labels'])用例4:网页问答(推理),parse_html=True
对于网页上的问答任务,您可以向处理器提供一个问题。默认情况下,处理器将使用特征提取器获取所有节点和xpath,并创建[CLS]问题标记[SEP]单词标记[SEP]。
>>> from transformers import MarkupLMProcessor
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
>>> html_string = """
... <!DOCTYPE html>
... <html>
... <head>
... <title>Hello world</title>
... </head>
... <body>
... <h1>Welcome</h1>
... <p>My name is Niels.</p>
... </body>
... </html>"""
>>> question = "What's his name?"
>>> encoding = processor(html_string, questions=question, return_tensors="pt")
>>> print(encoding.keys())
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])用例5:网页问答(推理),parse_html=False
对于问答任务(例如WebSRC),您可以向处理器提供一个问题。如果您已经自己提取了所有节点和xpaths,您可以直接将它们提供给处理器。请确保将parse_html设置为False。
>>> from transformers import MarkupLMProcessor
>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
>>> processor.parse_html = False
>>> nodes = ["hello", "world", "how", "are"]
>>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"]
>>> question = "What's his name?"
>>> encoding = processor(nodes=nodes, xpaths=xpaths, questions=question, return_tensors="pt")
>>> print(encoding.keys())
dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq'])资源
MarkupLMConfig
类 transformers.MarkupLMConfig
< source >( 词汇大小 = 30522 隐藏大小 = 768 隐藏层数 = 12 注意力头数 = 12 中间大小 = 3072 隐藏激活函数 = 'gelu' 隐藏层丢弃概率 = 0.1 注意力概率丢弃概率 = 0.1 最大位置嵌入 = 512 类型词汇大小 = 2 初始化范围 = 0.02 层归一化epsilon = 1e-12 填充标记ID = 0 开始标记ID = 0 结束标记ID = 2 最大XPath标签单元嵌入 = 256 最大XPath子单元嵌入 = 1024 标签填充ID = 216 子填充ID = 1001 XPath单元隐藏大小 = 32 最大深度 = 50 位置嵌入类型 = 'absolute' 使用缓存 = True 分类器丢弃 = None **kwargs )
参数
- vocab_size (
int, 可选, 默认为 30522) — MarkupLM 模型的词汇表大小。定义了可以通过传递给 MarkupLMModel 的 inputs_ids 表示的不同标记。 - hidden_size (
int, optional, 默认为 768) — 编码器层和池化层的维度。 - num_hidden_layers (
int, optional, 默认为 12) — Transformer 编码器中的隐藏层数量。 - num_attention_heads (
int, optional, 默认为 12) — Transformer 编码器中每个注意力层的注意力头数。 - intermediate_size (
int, optional, 默认为 3072) — Transformer 编码器中“中间”(即前馈)层的维度。 - hidden_act (
str或function, 可选, 默认为"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"silu"和"gelu_new"。 - hidden_dropout_prob (
float, 可选, 默认为 0.1) — 嵌入层、编码器和池化器中所有全连接层的 dropout 概率。 - attention_probs_dropout_prob (
float, optional, defaults to 0.1) — 注意力概率的丢弃比率。 - max_position_embeddings (
int, optional, 默认为 512) — 此模型可能使用的最大序列长度。通常将其设置为较大的值以防万一(例如,512、1024 或 2048)。 - type_vocab_size (
int, 可选, 默认为 2) — 传递给 MarkupLMModel 的token_type_ids的词汇表大小。 - initializer_range (
float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 - layer_norm_eps (
float, optional, defaults to 1e-12) — 层归一化层使用的epsilon值。 - max_tree_id_unit_embeddings (
int, 可选, 默认为 1024) — 树 id 单元嵌入可能使用的最大值。通常将其设置为较大的值以防万一(例如,1024)。 - max_xpath_tag_unit_embeddings (
int, 可选, 默认为 256) — xpath 标签单元嵌入可能使用的最大值。通常将其设置为较大的值以防万一(例如,256)。 - max_xpath_subs_unit_embeddings (
int, optional, defaults to 1024) — xpath下标单元嵌入可能使用的最大值。通常将其设置为较大的值以防万一(例如,1024)。 - tag_pad_id (
int, optional, 默认为 216) — xpath 标签中填充标记的 id. - subs_pad_id (
int, optional, 默认为 1001) — xpath 下标中填充标记的 id. - xpath_tag_unit_hidden_size (
int, optional, 默认为 32) — 每个树ID单元的隐藏大小。一个完整的树索引将具有 (50*xpath_tag_unit_hidden_size)-维. - max_depth (
int, optional, 默认为 50) — xpath 中的最大深度。
这是用于存储MarkupLMModel配置的配置类。它用于根据指定的参数实例化一个MarkupLM模型,定义模型架构。使用默认值实例化配置将产生与MarkupLM microsoft/markuplm-base架构类似的配置。
配置对象继承自 BertConfig,可用于控制模型输出。阅读 BertConfig 的文档以获取更多信息。
示例:
>>> from transformers import MarkupLMModel, MarkupLMConfig
>>> # Initializing a MarkupLM microsoft/markuplm-base style configuration
>>> configuration = MarkupLMConfig()
>>> # Initializing a model from the microsoft/markuplm-base style configuration
>>> model = MarkupLMModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configMarkupLMFeatureExtractor
构建一个MarkupLM特征提取器。这可以用于从HTML字符串中获取节点列表和相应的xpath。
此特征提取器继承自PreTrainedFeatureExtractor(),其中包含了大部分主要方法。用户应参考此超类以获取有关这些方法的更多信息。
__call__
< source >( html_strings ) → BatchFeature
准备模型的一个或多个HTML字符串的主要方法。
示例:
>>> from transformers import MarkupLMFeatureExtractor
>>> page_name_1 = "page1.html"
>>> page_name_2 = "page2.html"
>>> page_name_3 = "page3.html"
>>> with open(page_name_1) as f:
... single_html_string = f.read()
>>> feature_extractor = MarkupLMFeatureExtractor()
>>> # single example
>>> encoding = feature_extractor(single_html_string)
>>> print(encoding.keys())
>>> # dict_keys(['nodes', 'xpaths'])
>>> # batched example
>>> multi_html_strings = []
>>> with open(page_name_2) as f:
... multi_html_strings.append(f.read())
>>> with open(page_name_3) as f:
... multi_html_strings.append(f.read())
>>> encoding = feature_extractor(multi_html_strings)
>>> print(encoding.keys())
>>> # dict_keys(['nodes', 'xpaths'])MarkupLMTokenizer
类 transformers.MarkupLMTokenizer
< source >( vocab_file merges_file tags_dict errors = 'replace' bos_token = '' eos_token = '' sep_token = '' cls_token = '' unk_token = '
参数
- vocab_file (
str) — 词汇表文件的路径。 - merges_file (
str) — 合并文件的路径。 - errors (
str, 可选, 默认为"replace") — 解码字节为UTF-8时遵循的范式。更多信息请参见 bytes.decode. - bos_token (
str, optional, defaults to"<s>") — The beginning of sequence token that was used during pretraining. Can be used a sequence classifier token.在使用特殊标记构建序列时,这不是用于序列开头的标记。使用的标记是
cls_token。 - eos_token (
str, optional, defaults to"</s>") — The end of sequence token.在使用特殊标记构建序列时,这不是用于序列结束的标记。 使用的标记是
sep_token。 - sep_token (
str, 可选, 默认为"") — 分隔符标记,用于从多个序列构建序列时,例如用于序列分类的两个序列或用于问答的文本和问题。它也用作使用特殊标记构建的序列的最后一个标记。 - cls_token (
str, 可选, 默认为") — 用于序列分类的分类器标记(对整个序列进行分类而不是对每个标记进行分类)。当使用特殊标记构建时,它是序列的第一个标记。" - unk_token (
str, optional, defaults to") — 未知标记。不在词汇表中的标记无法转换为ID,而是设置为这个标记。" - pad_token (
str, optional, defaults to") — 用于填充的标记,例如在对不同长度的序列进行批处理时使用。" - mask_token (
str, 可选, 默认为") — 用于屏蔽值的标记。这是在训练此模型时用于屏蔽语言建模的标记。这是模型将尝试预测的标记。" - add_prefix_space (
bool, 可选, 默认为False) — 是否在输入前添加一个初始空格。这允许将前导词视为任何其他词。(RoBERTa 分词器通过前面的空格检测词的开头)。
构建一个MarkupLM分词器。基于字节级的字节对编码(BPE)。MarkupLMTokenizer 可以将HTML字符串转换为标记级别的 input_ids、attention_mask、token_type_ids、xpath_tags_seq 和 xpath_tags_seq。该分词器继承自 PreTrainedTokenizer,其中包含了大部分主要方法。用户应参考此超类以获取有关这些方法的更多信息。
build_inputs_with_special_tokens
< source >( token_ids_0: typing.List[int] token_ids_1: typing.Optional[typing.List[int]] = None ) → List[int]
通过连接和添加特殊标记,从序列或序列对构建序列分类任务的模型输入。一个RoBERTa序列具有以下格式:
- 单一序列:
X - 序列对:
AB
get_special_tokens_mask
< source >( token_ids_0: typing.List[int] token_ids_1: typing.Optional[typing.List[int]] = None already_has_special_tokens: bool = False ) → List[int]
create_token_type_ids_from_sequences
< source >( token_ids_0: typing.List[int] token_ids_1: typing.Optional[typing.List[int]] = None ) → List[int]
从传递给序列对分类任务的两个序列中创建一个掩码。RoBERTa不使用标记类型ID,因此返回一个零列表。
MarkupLMTokenizerFast
类 transformers.MarkupLMTokenizerFast
< source >( vocab_file merges_file tags_dict tokenizer_file = None errors = 'replace' bos_token = '' eos_token = '' sep_token = '' cls_token = '' unk_token = '
参数
- vocab_file (
str) — 词汇表文件的路径。 - merges_file (
str) — 合并文件的路径。 - errors (
str, 可选, 默认为"replace") — 解码字节为UTF-8时遵循的范式。更多信息请参见 bytes.decode. - bos_token (
str, optional, defaults to"<s>") — The beginning of sequence token that was used during pretraining. Can be used a sequence classifier token.在使用特殊标记构建序列时,这不是用于序列开头的标记。使用的标记是
cls_token。 - eos_token (
str, optional, defaults to"</s>") — The end of sequence token.在使用特殊标记构建序列时,这不是用于序列结束的标记。 使用的标记是
sep_token。 - sep_token (
str, 可选, 默认为"") — 分隔符标记,用于从多个序列构建序列时,例如用于序列分类的两个序列或用于问答的文本和问题。它也用作使用特殊标记构建的序列的最后一个标记。 - cls_token (
str, 可选, 默认为") — 用于序列分类的分类器标记(对整个序列进行分类而不是对每个标记进行分类)。当使用特殊标记构建时,它是序列的第一个标记。" - unk_token (
str, optional, defaults to") — 未知标记。不在词汇表中的标记无法转换为ID,而是设置为这个标记。" - pad_token (
str, optional, defaults to") — 用于填充的标记,例如在对不同长度的序列进行批处理时使用。" - mask_token (
str, 可选, 默认为") — 用于屏蔽值的标记。这是在训练此模型时使用的标记,用于屏蔽语言建模。这是模型将尝试预测的标记。" - add_prefix_space (
bool, 可选, 默认为False) — 是否在输入前添加一个初始空格。这允许将前导词视为任何其他词。(RoBERTa 分词器通过前面的空格检测词的开头)。
构建一个MarkupLM分词器。基于字节级的字节对编码(BPE)。
MarkupLMTokenizerFast 可用于将HTML字符串转换为标记级别的 input_ids, attention_mask,
token_type_ids, xpath_tags_seq 和 xpath_tags_seq。该分词器继承自 PreTrainedTokenizer,其中
包含了大多数主要方法。
用户应参考此超类以获取有关这些方法的更多信息。
batch_encode_plus
< source >( batch_text_or_text_pairs: typing.Union[typing.List[str], typing.List[typing.Tuple[str, str]], typing.List[typing.List[str]]] is_pair: bool = None xpaths: typing.Optional[typing.List[typing.List[typing.List[int]]]] = None node_labels: typing.Union[typing.List[int], typing.List[typing.List[int]], NoneType] = None add_special_tokens: bool = True padding: typing.Union[bool, str, transformers.utils.generic.PaddingStrategy] = False truncation: typing.Union[bool, str, transformers.tokenization_utils_base.TruncationStrategy] = None max_length: typing.Optional[int] = None stride: int = 0 pad_to_multiple_of: typing.Optional[int] = None padding_side: typing.Optional[bool] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None return_token_type_ids: typing.Optional[bool] = None return_attention_mask: typing.Optional[bool] = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True **kwargs )
add_special_tokens (bool, 可选, 默认为 True):
是否在编码序列时添加特殊标记。这将使用底层的
PretrainedTokenizerBase.build_inputs_with_special_tokens 函数,该函数定义了哪些标记会自动添加到输入ID中。如果您想自动添加 bos 或 eos 标记,这将非常有用。
padding (bool, str 或 PaddingStrategy, 可选, 默认为 False):
激活并控制填充。接受以下值:
True或'longest':填充到批次中最长的序列(如果只提供了一个序列,则不进行填充)。'max_length': 填充到由参数max_length指定的最大长度,如果未提供该参数,则填充到模型可接受的最大输入长度。False或'do_not_pad'(默认):不进行填充(即可以输出一个包含不同长度序列的批次)。 截断 (bool,str或 TruncationStrategy, 可选, 默认为False): 激活并控制截断。接受以下值:True或'longest_first':截断到由参数max_length指定的最大长度,或者如果未提供该参数,则截断到模型可接受的最大输入长度。这将逐个标记进行截断,如果提供了一对序列(或一批对),则从这对序列中最长的序列中移除一个标记。'only_first': 截断到由参数max_length指定的最大长度,或者如果未提供该参数,则截断到模型可接受的最大输入长度。如果提供了一对序列(或一批对),这将仅截断这对序列中的第一个序列。'only_second': 截断到由参数max_length指定的最大长度,或者如果未提供该参数,则截断到模型可接受的最大输入长度。如果提供了一对序列(或一批对),这将仅截断这对序列中的第二个序列。False或'do_not_truncate'(默认):不进行截断(即可以输出序列长度大于模型最大允许输入大小的批次)。 max_length (int, 可选): 控制通过截断/填充参数之一使用的最大长度。
如果未设置或设置为None,则在需要最大长度时,将使用预定义的模型最大长度。如果模型没有特定的最大输入长度(如XLNet),则截断/填充到最大长度将被停用。
stride (int, 可选, 默认为0):
如果与max_length一起设置为一个数字,则当return_overflowing_tokens=True时返回的溢出标记将包含来自截断序列末尾的一些标记,以提供截断和溢出序列之间的一些重叠。此参数的值定义了重叠标记的数量。
is_split_into_words (bool, 可选, 默认为False):
输入是否已经预分词(例如,分成单词)。如果设置为True,分词器假定输入已经分成单词(例如,通过空格分割),它将对其进行分词。这对于NER或标记分类非常有用。
pad_to_multiple_of (int, 可选):
如果设置,将序列填充到提供的值的倍数。需要激活padding。这对于在计算能力>= 7.5(Volta)的NVIDIA硬件上启用Tensor Cores特别有用。
padding_side (str, 可选):
模型应在哪一侧应用填充。应在['right', 'left']之间选择。默认值从同名的类属性中选取。
return_tensors (str 或 TensorType, 可选):
如果设置,将返回张量而不是Python整数列表。可接受的值有:
'tf': 返回 TensorFlowtf.constant对象。'pt': 返回 PyTorchtorch.Tensor对象。'np': 返回 Numpynp.ndarray对象。
add_special_tokens (bool, 可选, 默认为 True):
是否使用与模型相关的特殊标记对序列进行编码。
padding (bool, str 或 PaddingStrategy, 可选, 默认为 False):
激活并控制填充。接受以下值:
True或'longest':填充到批次中最长的序列(如果只提供了一个序列,则不进行填充)。'max_length': 填充到由参数max_length指定的最大长度,如果未提供该参数,则填充到模型可接受的最大输入长度。False或'do_not_pad'(默认):不进行填充(即可以输出一个包含不同长度序列的批次)。 截断 (bool,str或 TruncationStrategy, 可选, 默认为False): 激活并控制截断。接受以下值:True或'longest_first':截断到由参数max_length指定的最大长度,或者如果未提供该参数,则截断到模型可接受的最大输入长度。这将逐个标记进行截断,如果提供了一对序列(或一批对),则从这对序列中最长的序列中移除一个标记。'only_first': 截断到由参数max_length指定的最大长度,或者如果未提供该参数,则截断到模型可接受的最大输入长度。如果提供了一对序列(或一批对),这将仅截断这对序列中的第一个序列。'only_second': 截断到由参数max_length指定的最大长度,或者如果未提供该参数,则截断到模型可接受的最大输入长度。如果提供了一对序列(或一批对),这将仅截断这对序列中的第二个序列。False或'do_not_truncate'(默认):不进行截断(即可以输出序列长度大于模型最大允许输入大小的批次)。 max_length(int,可选): 控制通过截断/填充参数之一使用的最大长度。如果未设置或设置为None,则在需要最大长度时,将使用预定义的模型最大长度。如果模型没有特定的最大输入长度(如XLNet),则截断/填充到最大长度将被停用。 stride(int,可选,默认为0): 如果与max_length一起设置为一个数字,则当return_overflowing_tokens=True时返回的溢出标记将包含来自截断序列末尾的一些标记,以提供截断序列和溢出序列之间的一些重叠。此参数的值定义了重叠标记的数量。 pad_to_multiple_of(int,可选): 如果设置,将序列填充到提供的值的倍数。这对于在计算能力>= 7.5(Volta)的NVIDIA硬件上启用Tensor Cores特别有用。 return_tensors(str或 TensorType,可选): 如果设置,将返回张量而不是Python整数列表。可接受的值有:'tf': 返回 TensorFlowtf.constant对象。'pt': 返回 PyTorchtorch.Tensor对象。'np': 返回 Numpynp.ndarray对象。
build_inputs_with_special_tokens
< source >( token_ids_0: typing.List[int] token_ids_1: typing.Optional[typing.List[int]] = None ) → List[int]
通过连接和添加特殊标记,从序列或序列对构建序列分类任务的模型输入。一个RoBERTa序列具有以下格式:
- 单一序列:
X - 序列对:
AB
create_token_type_ids_from_sequences
< source >( token_ids_0: typing.List[int] token_ids_1: typing.Optional[typing.List[int]] = None ) → List[int]
从传递给序列对分类任务的两个序列中创建一个掩码。RoBERTa不使用标记类型ID,因此返回一个零列表。
encode_plus
< source >( text: typing.Union[str, typing.List[str]] text_pair: typing.Optional[typing.List[str]] = None xpaths: typing.Optional[typing.List[typing.List[int]]] = None node_labels: typing.Optional[typing.List[int]] = None add_special_tokens: bool = True padding: typing.Union[bool, str, transformers.utils.generic.PaddingStrategy] = False truncation: typing.Union[bool, str, transformers.tokenization_utils_base.TruncationStrategy] = None max_length: typing.Optional[int] = None stride: int = 0 pad_to_multiple_of: typing.Optional[int] = None padding_side: typing.Optional[bool] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None return_token_type_ids: typing.Optional[bool] = None return_attention_mask: typing.Optional[bool] = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True **kwargs )
参数
- text (
str,List[str],List[List[str]]) — 要编码的第一个序列。这可以是一个字符串、一个字符串列表或一个字符串列表的列表。 - text_pair (
List[str]或List[int], 可选) — 可选的第二个序列进行编码。这可以是一个字符串列表(单个示例的单词)或一个字符串列表的列表(一批示例的单词)。 - add_special_tokens (
bool, 可选, 默认为True) — 是否在编码序列时添加特殊标记。这将使用底层的PretrainedTokenizerBase.build_inputs_with_special_tokens函数,该函数定义了哪些标记会自动添加到输入ID中。如果您想自动添加bos或eos标记,这将非常有用。 - padding (
bool,stror PaddingStrategy, optional, defaults toFalse) — Activates and controls padding. Accepts the following values:Trueor'longest': Pad to the longest sequence in the batch (or no padding if only a single sequence if provided).'max_length': Pad to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided.Falseor'do_not_pad'(default): No padding (i.e., can output a batch with sequences of different lengths).
- truncation (
bool,stror TruncationStrategy, optional, defaults toFalse) — Activates and controls truncation. Accepts the following values:Trueor'longest_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will truncate token by token, removing a token from the longest sequence in the pair if a pair of sequences (or a batch of pairs) is provided.'only_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the first sequence of a pair if a pair of sequences (or a batch of pairs) is provided.'only_second': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the second sequence of a pair if a pair of sequences (or a batch of pairs) is provided.Falseor'do_not_truncate'(default): No truncation (i.e., can output batch with sequence lengths greater than the model maximum admissible input size).
- max_length (
int, optional) — Controls the maximum length to use by one of the truncation/padding parameters.如果未设置或设置为
None,则在需要截断/填充参数时,将使用预定义的模型最大长度。如果模型没有特定的最大输入长度(如XLNet),则截断/填充到最大长度的功能将被停用。 - stride (
int, 可选, 默认为 0) — 如果设置为一个数字并与max_length一起使用,当return_overflowing_tokens=True时返回的溢出标记将包含一些来自截断序列末尾的标记, 以提供截断序列和溢出序列之间的一些重叠。此参数的值定义了重叠标记的数量。 - is_split_into_words (
bool, 可选, 默认为False) — 输入是否已经预分词(例如,分割成单词)。如果设置为True,分词器会假设输入已经分割成单词(例如,通过空格分割),然后进行分词。这对于NER或分词分类非常有用。 - pad_to_multiple_of (
int, 可选) — 如果设置,将序列填充到提供的值的倍数。需要激活padding。 这对于在计算能力>= 7.5(Volta)的NVIDIA硬件上启用Tensor Cores特别有用。 - padding_side (
str, optional) — 模型应在哪一侧应用填充。应在['right', 'left']之间选择。 默认值从同名的类属性中选取。 - return_tensors (
str或 TensorType, 可选) — 如果设置,将返回张量而不是Python整数列表。可接受的值有:'tf': 返回 TensorFlowtf.constant对象。'pt': 返回 PyTorchtorch.Tensor对象。'np': 返回 Numpynp.ndarray对象。
- add_special_tokens (
bool, optional, defaults toTrue) — 是否使用与模型相关的特殊标记对序列进行编码。 - padding (
bool,stror PaddingStrategy, optional, defaults toFalse) — Activates and controls padding. Accepts the following values:Trueor'longest': Pad to the longest sequence in the batch (or no padding if only a single sequence if provided).'max_length': Pad to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided.Falseor'do_not_pad'(default): No padding (i.e., can output a batch with sequences of different lengths).
- truncation (
bool,stror TruncationStrategy, optional, defaults toFalse) — Activates and controls truncation. Accepts the following values:Trueor'longest_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will truncate token by token, removing a token from the longest sequence in the pair if a pair of sequences (or a batch of pairs) is provided.'only_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the first sequence of a pair if a pair of sequences (or a batch of pairs) is provided.'only_second': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the second sequence of a pair if a pair of sequences (or a batch of pairs) is provided.Falseor'do_not_truncate'(default): No truncation (i.e., can output batch with sequence lengths greater than the model maximum admissible input size).
- max_length (
int, 可选) — 控制由截断/填充参数之一使用的最大长度。如果未设置或设置为None,则在需要最大长度的情况下,将使用预定义的模型最大长度。如果模型没有特定的最大输入长度(如XLNet), 则截断/填充到最大长度的功能将被停用。 - stride (
int, 可选, 默认为 0) — 如果设置为一个数字并与max_length一起使用,当return_overflowing_tokens=True时返回的溢出标记将包含一些来自截断序列末尾的标记, 以提供截断序列和溢出序列之间的一些重叠。此参数的值定义了重叠标记的数量。 - pad_to_multiple_of (
int, 可选) — 如果设置,将序列填充到提供的值的倍数。这对于在计算能力>= 7.5(Volta)的NVIDIA硬件上启用Tensor Cores特别有用。 - return_tensors (
str或 TensorType, 可选) — 如果设置,将返回张量而不是Python整数列表。可接受的值有:'tf': 返回 TensorFlowtf.constant对象。'pt': 返回 PyTorchtorch.Tensor对象。'np': 返回 Numpynp.ndarray对象。
对序列或序列对进行分词并准备模型。.. 警告:: 此方法已弃用,应改用__call__。
给定一个特定节点的xpath表达式(如“/html/body/div/li[1]/div/span[2]”),返回一个标签ID和相应下标的列表,考虑最大深度。
MarkupLMProcessor
类 transformers.MarkupLMProcessor
< source >( *args **kwargs )
参数
- feature_extractor (
MarkupLMFeatureExtractor) — 一个 MarkupLMFeatureExtractor 的实例。特征提取器是一个必需的输入。 - tokenizer (
MarkupLMTokenizer或MarkupLMTokenizerFast) — MarkupLMTokenizer 或 MarkupLMTokenizerFast 的实例。tokenizer 是一个必需的输入。 - parse_html (
bool, 可选, 默认为True) — 是否使用MarkupLMFeatureExtractor将 HTML 字符串解析为节点和相应的 xpaths.
构建一个MarkupLM处理器,它将MarkupLM特征提取器和MarkupLM分词器组合成一个单一的处理器。
MarkupLMProcessor 提供了准备模型数据所需的所有功能。
首先使用MarkupLMFeatureExtractor从一个或多个HTML字符串中提取节点和相应的xpath。
接着,这些信息被提供给MarkupLMTokenizer或MarkupLMTokenizerFast,它们将这些信息转换为标记级别的
input_ids, attention_mask, token_type_ids, xpath_tags_seq 和 xpath_subs_seq。
__call__
< source >( html_strings = None nodes = None xpaths = None node_labels = None questions = None add_special_tokens: bool = True padding: typing.Union[bool, str, transformers.utils.generic.PaddingStrategy] = False truncation: typing.Union[bool, str, transformers.tokenization_utils_base.TruncationStrategy] = None max_length: typing.Optional[int] = None stride: int = 0 pad_to_multiple_of: typing.Optional[int] = None return_token_type_ids: typing.Optional[bool] = None return_attention_mask: typing.Optional[bool] = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None **kwargs )
此方法首先将html_strings参数转发给call()。接着,它将nodes和xpaths连同其他参数一起传递给__call__()并返回输出。
可选地,还可以提供一个text参数,该参数作为第一个序列传递。
请参考上述两个方法的文档字符串以获取更多信息。
MarkupLMModel
类 transformers.MarkupLMModel
< source >( config add_pooling_layer = True )
参数
- config (MarkupLMConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的MarkupLM模型转换器输出原始隐藏状态,没有任何特定的头部。 这个模型是一个PyTorch torch.nn.Module 子类。使用 它作为常规的PyTorch模块,并参考PyTorch文档以获取与一般使用和行为相关的所有事项。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None xpath_tags_seq: typing.Optional[torch.LongTensor] = None xpath_subs_seq: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None position_ids: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- xpath_tags_seq (
torch.LongTensorof shape(batch_size, sequence_length, config.max_depth), optional) — 输入序列中每个标记的标签ID,填充至config.max_depth。 - xpath_subs_seq (
torch.LongTensorof shape(batch_size, sequence_length, config.max_depth), optional) — 输入序列中每个标记的下标ID,填充至config.max_depth。 - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:1for tokens that are NOT MASKED,0for MASKED tokens. - token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:0corresponds to a sentence A token,1corresponds to a sentence B token - position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:1表示头部未被屏蔽,0表示头部被屏蔽。 - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 如果设置为True,则返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 如果设置为True,则返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 - return_dict (
bool, 可选) — 如果设置为True,模型将返回一个 ModelOutput 而不是一个普通的元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(MarkupLMConfig)和输入。
-
last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。 -
pooler_output (
torch.FloatTensor形状为(batch_size, hidden_size)) — 序列的第一个标记(分类标记)在经过用于辅助预训练任务的层进一步处理后的最后一层隐藏状态。例如,对于BERT系列模型,这返回经过线性层和tanh激活函数处理后的分类标记。线性层的权重是在预训练期间通过下一句预测(分类)目标训练的。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力权重在注意力softmax之后,用于计算自注意力头中的加权平均值。
-
cross_attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True和config.add_cross_attention=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器的交叉注意力层的注意力权重,在注意力softmax之后,用于计算交叉注意力头中的加权平均值。
-
past_key_values (
tuple(tuple(torch.FloatTensor)), 可选, 当传递了use_cache=True或当config.use_cache=True时返回) — 由tuple(torch.FloatTensor)组成的元组,长度为config.n_layers,每个元组包含2个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量,并且如果config.is_encoder_decoder=True则还包含2个形状为(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)的额外张量。包含预计算的隐藏状态(自注意力块中的键和值,并且如果
config.is_encoder_decoder=True则还包含交叉注意力块中的键和值),可以用于(参见past_key_values输入)加速顺序解码。
MarkupLMModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoProcessor, MarkupLMModel
>>> processor = AutoProcessor.from_pretrained("microsoft/markuplm-base")
>>> model = MarkupLMModel.from_pretrained("microsoft/markuplm-base")
>>> html_string = "<html> <head> <title>Page Title</title> </head> </html>"
>>> encoding = processor(html_string, return_tensors="pt")
>>> outputs = model(**encoding)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 4, 768]MarkupLMForSequenceClassification
类 transformers.MarkupLMForSequenceClassification
< source >( config )
参数
- config (MarkupLMConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
MarkupLM模型转换器,顶部带有序列分类/回归头(在池化输出之上的线性层),例如用于GLUE任务。
该模型是一个PyTorch torch.nn.Module 子类。将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.Tensor] = None xpath_tags_seq: typing.Optional[torch.Tensor] = None xpath_subs_seq: typing.Optional[torch.Tensor] = None attention_mask: typing.Optional[torch.Tensor] = None token_type_ids: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None inputs_embeds: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.SequenceClassifierOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- xpath_tags_seq (
torch.LongTensorof shape(batch_size, sequence_length, config.max_depth), optional) — 输入序列中每个标记的标签ID,填充至config.max_depth。 - xpath_subs_seq (
torch.LongTensorof shape(batch_size, sequence_length, config.max_depth), optional) — 输入序列中每个标记的下标ID,填充至config.max_depth。 - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:1for tokens that are NOT MASKED,0for MASKED tokens. - token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:0corresponds to a sentence A token,1corresponds to a sentence B token - position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:1表示头部未被屏蔽,0表示头部被屏蔽。 - inputs_embeds (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size), 可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将 input_ids 索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 如果设置为True,则返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 如果设置为True,则返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 - return_dict (
bool, 可选) — 如果设置为True,模型将返回一个 ModelOutput 而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size,), optional) — 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.SequenceClassifierOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.SequenceClassifierOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(MarkupLMConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 分类(或回归,如果 config.num_labels==1)损失。 -
logits (
torch.FloatTensor形状为(batch_size, config.num_labels)) — 分类(或回归,如果 config.num_labels==1)得分(在 SoftMax 之前)。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
MarkupLMForSequenceClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoProcessor, AutoModelForSequenceClassification
>>> import torch
>>> processor = AutoProcessor.from_pretrained("microsoft/markuplm-base")
>>> model = AutoModelForSequenceClassification.from_pretrained("microsoft/markuplm-base", num_labels=7)
>>> html_string = "<html> <head> <title>Page Title</title> </head> </html>"
>>> encoding = processor(html_string, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**encoding)
>>> loss = outputs.loss
>>> logits = outputs.logitsMarkupLMForTokenClassification
类 transformers.MarkupLMForTokenClassification
< source >( config )
参数
- config (MarkupLMConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
MarkupLM 模型顶部带有 token_classification 头。
该模型是 PyTorch torch.nn.Module 的子类。将其作为常规的 PyTorch 模块使用,并参考 PyTorch 文档以了解与一般使用和行为相关的所有事项。
前进
< source >( input_ids: typing.Optional[torch.Tensor] = None xpath_tags_seq: typing.Optional[torch.Tensor] = None xpath_subs_seq: typing.Optional[torch.Tensor] = None attention_mask: typing.Optional[torch.Tensor] = None token_type_ids: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None inputs_embeds: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.MaskedLMOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- xpath_tags_seq (
torch.LongTensorof shape(batch_size, sequence_length, config.max_depth), optional) — 输入序列中每个标记的标签ID,填充至config.max_depth。 - xpath_subs_seq (
torch.LongTensorof shape(batch_size, sequence_length, config.max_depth), optional) — 输入序列中每个标记的下标ID,填充至config.max_depth。 - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:1for tokens that are NOT MASKED,0for MASKED tokens. - token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:0corresponds to a sentence A token,1corresponds to a sentence B token - position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:1表示头部未被屏蔽,0表示头部被屏蔽。 - inputs_embeds (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size), 可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将 input_ids 索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 如果设置为True,则返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 如果设置为True,则返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 - return_dict (
bool, 可选) — 如果设置为True,模型将返回一个 ModelOutput 而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — 用于计算标记分类损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。
返回
transformers.modeling_outputs.MaskedLMOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.MaskedLMOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(MarkupLMConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,), 可选, 当提供labels时返回) — 掩码语言建模(MLM)损失。 -
logits (
torch.FloatTensor形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
MarkupLMForTokenClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoProcessor, AutoModelForTokenClassification
>>> import torch
>>> processor = AutoProcessor.from_pretrained("microsoft/markuplm-base")
>>> processor.parse_html = False
>>> model = AutoModelForTokenClassification.from_pretrained("microsoft/markuplm-base", num_labels=7)
>>> nodes = ["hello", "world"]
>>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span"]
>>> node_labels = [1, 2]
>>> encoding = processor(nodes=nodes, xpaths=xpaths, node_labels=node_labels, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**encoding)
>>> loss = outputs.loss
>>> logits = outputs.logitsMarkupLMForQuestionAnswering
类 transformers.MarkupLMForQuestionAnswering
< source >( config )
参数
- config (MarkupLMConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
MarkupLM 模型,顶部带有用于抽取式问答任务(如 SQuAD)的跨度分类头(在隐藏状态输出之上的线性层,用于计算 span start logits 和 span end logits)。
该模型是一个PyTorch torch.nn.Module 子类。将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.Tensor] = None xpath_tags_seq: typing.Optional[torch.Tensor] = None xpath_subs_seq: typing.Optional[torch.Tensor] = None attention_mask: typing.Optional[torch.Tensor] = None token_type_ids: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None inputs_embeds: typing.Optional[torch.Tensor] = None start_positions: typing.Optional[torch.Tensor] = None end_positions: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.QuestionAnsweringModelOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- xpath_tags_seq (
torch.LongTensorof shape(batch_size, sequence_length, config.max_depth), optional) — 输入序列中每个标记的标签ID,填充至config.max_depth。 - xpath_subs_seq (
torch.LongTensorof shape(batch_size, sequence_length, config.max_depth), optional) — 输入序列中每个标记的下标ID,填充至config.max_depth。 - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:1for tokens that are NOT MASKED,0for MASKED tokens. - token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:0corresponds to a sentence A token,1corresponds to a sentence B token - position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:1表示头部未被屏蔽,0表示头部被屏蔽。 - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制权,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 如果设置为True,则返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 如果设置为True,则返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 - return_dict (
bool, 可选) — 如果设置为True,模型将返回一个 ModelOutput 而不是一个普通的元组。 - start_positions (
torch.LongTensorof shape(batch_size,), optional) — 用于计算标记分类损失的标记跨度起始位置(索引)的标签。 位置被限制在序列长度内(sequence_length)。序列之外的位置不会被考虑用于计算损失。 - end_positions (
torch.LongTensorof shape(batch_size,), optional) — 用于计算标记分类损失的标记跨度结束位置(索引)的标签。 位置被限制在序列长度内(sequence_length)。序列之外的位置不会用于计算损失。
返回
transformers.modeling_outputs.QuestionAnsweringModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.QuestionAnsweringModelOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(MarkupLMConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,), 可选, 当提供labels时返回) — 总跨度提取损失是起始和结束位置的交叉熵之和。 -
start_logits (
torch.FloatTensor形状为(batch_size, sequence_length)) — 跨度起始分数(在 SoftMax 之前)。 -
end_logits (
torch.FloatTensor形状为(batch_size, sequence_length)) — 跨度结束分数(在 SoftMax 之前)。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
MarkupLMForQuestionAnswering 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoProcessor, MarkupLMForQuestionAnswering
>>> import torch
>>> processor = AutoProcessor.from_pretrained("microsoft/markuplm-base-finetuned-websrc")
>>> model = MarkupLMForQuestionAnswering.from_pretrained("microsoft/markuplm-base-finetuned-websrc")
>>> html_string = "<html> <head> <title>My name is Niels</title> </head> </html>"
>>> question = "What's his name?"
>>> encoding = processor(html_string, questions=question, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**encoding)
>>> answer_start_index = outputs.start_logits.argmax()
>>> answer_end_index = outputs.end_logits.argmax()
>>> predict_answer_tokens = encoding.input_ids[0, answer_start_index : answer_end_index + 1]
>>> processor.decode(predict_answer_tokens).strip()
'Niels'