GPTBigCode
概述
GPTBigCode模型由BigCode在SantaCoder: don’t reach for the stars!中提出。列出的作者包括:Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra。
论文的摘要如下:
BigCode项目是一个开放科学合作项目,致力于负责任地开发用于代码的大型语言模型。本技术报告描述了截至2022年12月的合作进展,概述了个人可识别信息(PII)编辑管道的当前状态、为降低模型架构风险而进行的实验,以及研究更好训练数据预处理方法的实验。我们在The Stack的Java、JavaScript和Python子集上训练了1.1B参数模型,并在MultiPL-E文本到代码基准上进行了评估。我们发现,更积极地过滤近重复项可以进一步提高性能,而令人惊讶的是,从拥有5+ GitHub星标的仓库中选择文件会显著降低性能。尽管我们的最佳模型规模明显较小,但在MultiPL-E的Java、JavaScript和Python部分上,无论是从左到右生成还是填充,都优于之前的开源多语言代码生成模型(InCoder-6.7B和CodeGen-Multi-2.7B)。所有模型均在OpenRAIL许可证下发布,可在此https URL找到。
该模型是一个优化的GPT2模型,支持多查询注意力机制。
实现细节
与GPT2相比的主要区别。
- 增加了对多查询注意力机制的支持。
- 使用
gelu_pytorch_tanh而不是经典的gelu。 - 避免不必要的同步(这已经在#20061中被添加到GPT2中,但在参考代码库中没有)。
- 使用线性层代替Conv1D(速度提升明显,但会使检查点不兼容)。
- 合并
_attn和_upcast_and_reordered_attn。始终将矩阵乘法与缩放合并。将reorder_and_upcast_attn重命名为attention_softmax_in_fp32 - 缓存注意力掩码值,以避免每次重新创建它。
- 使用jit来融合注意力机制的fp32类型转换、掩码、softmax和缩放。
- 将注意力掩码和因果掩码合并为一个,预先为整个模型计算,而不是为每一层计算。
- 将键和值缓存合并为一个(这会改变layer_past/present的格式,是否存在创建问题的风险?)
- 使用内存布局 (self.num_heads, 3, self.head_dim) 而不是
(3, self.num_heads, self.head_dim)来处理带有MHA的QKV张量。(防止合并键和值时的开销,但会使检查点与原始的openai-community/gpt2模型不兼容)。
你可以在原始拉取请求中阅读更多关于优化的信息
结合Starcoder和Flash Attention 2
首先,确保安装最新版本的 Flash Attention 2 以包含滑动窗口注意力功能。
pip install -U flash-attn --no-build-isolation
请确保您拥有与Flash-Attention 2兼容的硬件。更多信息请参阅flash-attn仓库的官方文档。同时,请确保以半精度加载您的模型(例如 `torch.float16`)。
要使用Flash Attention 2加载并运行模型,请参考以下代码片段:
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = AutoModelForCausalLM.from_pretrained("bigcode/gpt_bigcode-santacoder", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = AutoTokenizer.from_pretrained("bigcode/gpt_bigcode-santacoder")
>>> prompt = "def hello_world():"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=30, do_sample=False)
>>> tokenizer.batch_decode(generated_ids)[0]
'def hello_world():\n print("hello world")\n\nif __name__ == "__main__":\n print("hello world")\n<|endoftext|>'预期的加速
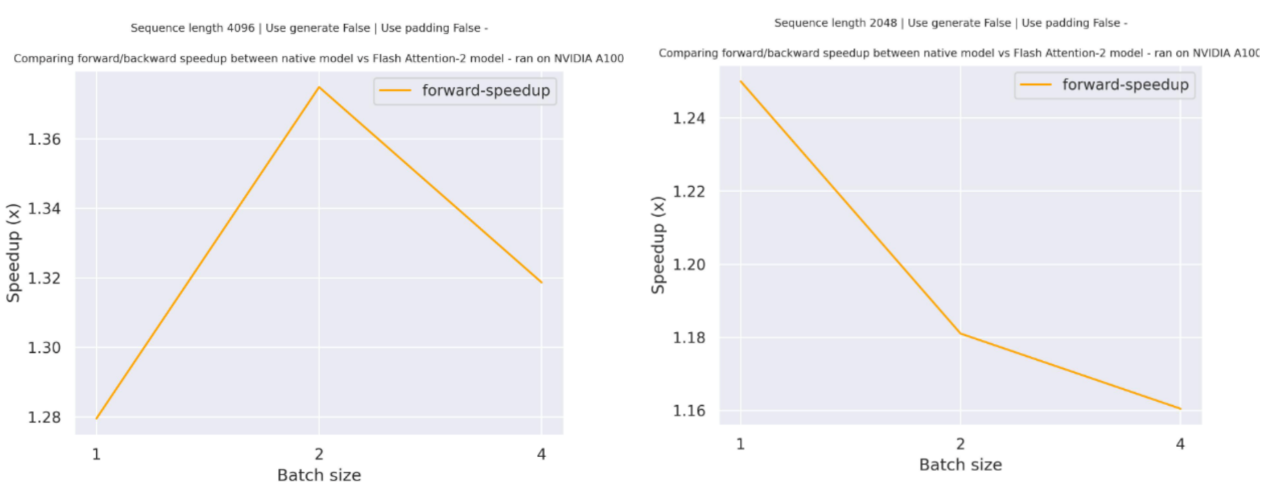
下面是一个预期的加速图,比较了使用bigcode/starcoder检查点的transformers原生实现与使用两种不同序列长度的Flash Attention 2版本模型的纯推理时间。
GPTBigCodeConfig
类 transformers.GPTBigCodeConfig
< source >( vocab_size = 50257 n_positions = 1024 n_embd = 768 n_layer = 12 n_head = 12 n_inner = None activation_function = 'gelu_pytorch_tanh' resid_pdrop = 0.1 embd_pdrop = 0.1 attn_pdrop = 0.1 layer_norm_epsilon = 1e-05 initializer_range = 0.02 scale_attn_weights = True use_cache = True bos_token_id = 50256 eos_token_id = 50256 attention_softmax_in_fp32 = True scale_attention_softmax_in_fp32 = True multi_query = True **kwargs )
参数
- vocab_size (
int, 可选, 默认为 50257) — GPT-2 模型的词汇量大小。定义了调用 GPTBigCodeModel 时传递的inputs_ids可以表示的不同标记的数量。 - n_positions (
int, optional, 默认为 1024) — 该模型可能使用的最大序列长度。通常将其设置为较大的值以防万一(例如,512 或 1024 或 2048)。 - n_embd (
int, optional, 默认为 768) — 嵌入和隐藏状态的维度。 - n_layer (
int, optional, defaults to 12) — Transformer编码器中的隐藏层数量。 - n_head (
int, optional, 默认为 12) — Transformer 编码器中每个注意力层的注意力头数量。 - n_inner (
int, 可选, 默认为 None) — 内部前馈层的维度。None会将其设置为 n_embd 的 4 倍 - activation_function (
str, 可选, 默认为"gelu_pytorch_tanh") — 激活函数,从列表["relu", "silu", "gelu", "tanh", "gelu_new", "gelu_pytorch_tanh"]中选择。 - resid_pdrop (
float, optional, 默认为 0.1) — 嵌入层、编码器和池化器中所有全连接层的 dropout 概率。 - embd_pdrop (
float, optional, defaults to 0.1) — 嵌入的dropout比率. - attn_pdrop (
float, optional, 默认为 0.1) — 注意力机制的丢弃比例。 - layer_norm_epsilon (
float, optional, defaults to 1e-5) — 用于层归一化层的epsilon值。 - initializer_range (
float, 可选, 默认值为 0.02) — 用于初始化所有权重矩阵的 truncated_normal_initializer 的标准差。 - scale_attn_weights (
bool, optional, defaults toTrue) — 通过除以sqrt(hidden_size)来缩放注意力权重。 - use_cache (
bool, 可选, 默认为True) — 模型是否应返回最后的键/值注意力(并非所有模型都使用)。 - attention_softmax_in_fp32 (
bool, 可选, 默认为True) — 是否在float32中调用融合的softmax. - scale_attention_softmax_in_fp32 (
bool, optional, defaults toTrue) — 是否在float32中缩放注意力softmax. - attention_type (
bool, 可选, 默认为True) — 是否使用多查询注意力 (True) 或多头注意力 (False)。
这是用于存储GPTBigCodeModel配置的配置类。它用于根据指定的参数实例化一个GPTBigCode模型,定义模型架构。使用默认值实例化配置将产生与gpt_bigcode架构相似的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import GPTBigCodeConfig, GPTBigCodeModel
>>> # Initializing a GPTBigCode configuration
>>> configuration = GPTBigCodeConfig()
>>> # Initializing a model (with random weights) from the configuration
>>> model = GPTBigCodeModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configGPTBigCodeModel
类 transformers.GPTBigCodeModel
< source >( config )
参数
- config (GPTBigCodeConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的GPT_BIGCODE模型变压器输出原始隐藏状态,顶部没有任何特定的头部。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.Tensor] = None past_key_values: typing.Optional[typing.List[torch.Tensor]] = None attention_mask: typing.Optional[torch.Tensor] = None token_type_ids: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None inputs_embeds: typing.Optional[torch.Tensor] = None encoder_hidden_states: typing.Optional[torch.Tensor] = None encoder_attention_mask: typing.Optional[torch.Tensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.Tensorof shape(batch_size, input_ids_length)) —input_ids_length=sequence_lengthifpast_key_valuesisNoneelsepast_key_values[0][0].shape[-2](sequence_lengthof input past key value states). Indices of input sequence tokens in the vocabulary.如果使用了
past_key_values,则只应将未计算其过去的input_ids作为input_ids传递。可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- past_key_values (
Tuple[torch.Tensor]长度为config.n_layers) — 包含由模型预先计算的隐藏状态(注意力块中的键和值)(参见下面的past_key_values输出)。可用于加速顺序解码。已经将其过去状态提供给此模型的input_ids不应再作为input_ids传递,因为它们已经被计算过了。 - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
如果使用了
past_key_values,attention_mask需要包含用于past_key_values的掩码策略。换句话说,attention_mask的长度必须始终为:len(past_key_values) + len(input_ids) - token_type_ids (
torch.Tensorof shape(batch_size, input_ids_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.Tensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.Tensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.Tensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix.如果使用了
past_key_values,可以选择只输入最后的inputs_embeds(参见past_key_values)。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(GPTBigCodeConfig)和输入。
-
last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。如果使用了
past_key_values,则只输出形状为(batch_size, 1, hidden_size)的序列的最后一个隐藏状态。 -
past_key_values (
tuple(tuple(torch.FloatTensor)), 可选, 当传递了use_cache=True或当config.use_cache=True时返回) — 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量,并且如果config.is_encoder_decoder=True,则还包含 2 个形状为(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)的额外张量。包含预先计算的隐藏状态(自注意力块中的键和值,并且如果
config.is_encoder_decoder=True,则还包含交叉注意力块中的键和值),可以用于(参见past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
-
cross_attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True和config.add_cross_attention=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器的交叉注意力层的注意力权重,在注意力 softmax 后,用于计算交叉注意力头中的加权平均值。
GPTBigCodeModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, GPTBigCodeModel
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("bigcode/gpt_bigcode-santacoder")
>>> model = GPTBigCodeModel.from_pretrained("bigcode/gpt_bigcode-santacoder")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateGPTBigCodeForCausalLM
类 transformers.GPTBigCodeForCausalLM
< source >( config )
参数
- config (GPTBigCodeConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
GPT_BIGCODE 模型变压器,顶部带有语言建模头(线性层,其权重与输入嵌入绑定)。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.Tensor] = None past_key_values: typing.Optional[typing.Tuple[typing.Tuple[torch.Tensor]]] = None attention_mask: typing.Optional[torch.Tensor] = None token_type_ids: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None inputs_embeds: typing.Optional[torch.Tensor] = None encoder_hidden_states: typing.Optional[torch.Tensor] = None encoder_attention_mask: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.Tensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.CausalLMOutputWithCrossAttentions 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.Tensorof shape(batch_size, input_ids_length)) —input_ids_length=sequence_lengthifpast_key_valuesisNoneelsepast_key_values[0][0].shape[-2](sequence_lengthof input past key value states). Indices of input sequence tokens in the vocabulary.如果使用了
past_key_values,则只应将未计算其过去的input_ids作为input_ids传递。可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- past_key_values (
Tuple[torch.Tensor]长度为config.n_layers) — 包含由模型预先计算的隐藏状态(注意力块中的键和值)(参见下面的past_key_values输出)。可用于加速顺序解码。已经将其过去状态提供给此模型的input_ids不应再作为input_ids传递,因为它们已经被计算过了。 - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
如果使用了
past_key_values,attention_mask需要包含用于past_key_values的掩码策略。换句话说,attention_mask的长度必须始终为:len(past_key_values) + len(input_ids) - token_type_ids (
torch.Tensorof shape(batch_size, input_ids_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.Tensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.Tensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.Tensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix.如果使用了
past_key_values,可以选择只输入最后的inputs_embeds(参见past_key_values)。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - labels (
torch.Tensorof shape(batch_size, sequence_length), optional) — 用于语言建模的标签。请注意,标签在模型内部被移位,即你可以设置labels = input_ids索引在[-100, 0, ..., config.vocab_size]中选择。所有设置为-100的标签 将被忽略(掩码),损失仅针对[0, ..., config.vocab_size]中的标签计算
返回
transformers.modeling_outputs.CausalLMOutputWithCrossAttentions 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.CausalLMOutputWithCrossAttentions 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(GPTBigCodeConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 语言建模损失(用于下一个标记预测)。 -
logits (
torch.FloatTensor形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
-
cross_attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的交叉注意力权重,用于计算交叉注意力头中的加权平均值。
-
past_key_values (
tuple(tuple(torch.FloatTensor)),可选,当传递use_cache=True或当config.use_cache=True时返回) — 由长度为config.n_layers的torch.FloatTensor元组组成的元组,每个元组包含自注意力和交叉注意力层的缓存键, 值状态,如果模型用于编码器-解码器设置。仅在config.is_decoder = True时相关。包含预计算的隐藏状态(注意力块中的键和值),可用于(参见
past_key_values输入)以加速顺序解码。
GPTBigCodeForCausalLM 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import torch
>>> from transformers import AutoTokenizer, GPTBigCodeForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("bigcode/gpt_bigcode-santacoder")
>>> model = GPTBigCodeForCausalLM.from_pretrained("bigcode/gpt_bigcode-santacoder")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs, labels=inputs["input_ids"])
>>> loss = outputs.loss
>>> logits = outputs.logitsGPTBigCodeForSequenceClassification
类 transformers.GPTBigCodeForSequenceClassification
< source >( config )
参数
- config (GPTBigCodeConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
GPTBigCode 模型变压器,顶部带有序列分类头(线性层)。
GPTBigCodeForSequenceClassification 使用最后一个标记来进行分类,就像其他因果模型(例如 GPT-1)一样。
由于它对最后一个标记进行分类,因此需要知道最后一个标记的位置。如果在配置中定义了pad_token_id,它会在每一行中找到不是填充标记的最后一个标记。如果没有定义pad_token_id,它只需取批次中每一行的最后一个值。由于在传递inputs_embeds而不是input_ids时无法猜测填充标记,它会执行相同的操作(取批次中每一行的最后一个值)。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.Tensor] = None past_key_values: typing.Optional[typing.Tuple[typing.Tuple[torch.Tensor]]] = None attention_mask: typing.Optional[torch.Tensor] = None token_type_ids: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None inputs_embeds: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.Tensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None )
参数
- input_ids (
torch.Tensorof shape(batch_size, input_ids_length)) —input_ids_length=sequence_lengthifpast_key_valuesisNoneelsepast_key_values[0][0].shape[-2](sequence_lengthof input past key value states). Indices of input sequence tokens in the vocabulary.如果使用了
past_key_values,则只应将未计算其过去的input_ids作为input_ids传递。可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- past_key_values (
Tuple[torch.Tensor]长度为config.n_layers) — 包含模型计算的预计算隐藏状态(注意力块中的键和值)(见下面的past_key_values输出)。可用于加速顺序解码。已经将其过去状态提供给此模型的input_ids不应再作为input_ids传递,因为它们已经被计算过了。 - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
如果使用了
past_key_values,attention_mask需要包含用于past_key_values的掩码策略。换句话说,attention_mask的长度必须始终为:len(past_key_values) + len(input_ids) - token_type_ids (
torch.Tensorof shape(batch_size, input_ids_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.Tensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.Tensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.Tensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix.如果使用了
past_key_values,可以选择只输入最后的inputs_embeds(参见past_key_values)。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - labels (
torch.Tensor形状为(batch_size,), 可选) — 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
GPTBigCodeForSequenceClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
GPTBigCodeForTokenClassification
类 transformers.GPTBigCodeForTokenClassification
< source >( config )
参数
- config (GPTBigCodeConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
GPT_BIGCODE 模型,顶部带有标记分类头(在隐藏状态输出之上的线性层),例如用于命名实体识别(NER)任务。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.Tensor] = None past_key_values: typing.Optional[typing.Tuple[typing.Tuple[torch.Tensor]]] = None attention_mask: typing.Optional[torch.Tensor] = None token_type_ids: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None inputs_embeds: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.Tensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None )
参数
- input_ids (
torch.Tensorof shape(batch_size, input_ids_length)) —input_ids_length=sequence_lengthifpast_key_valuesisNoneelsepast_key_values[0][0].shape[-2](sequence_lengthof input past key value states). Indices of input sequence tokens in the vocabulary.如果使用了
past_key_values,则只应将未计算其过去的input_ids作为input_ids传递。可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- past_key_values (
Tuple[torch.Tensor]长度为config.n_layers) — 包含由模型预先计算的隐藏状态(注意力块中的键和值)(见下面的past_key_values输出)。可用于加速顺序解码。已经将其过去状态提供给此模型的input_ids不应再作为input_ids传递,因为它们已经被计算过了。 - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
如果使用了
past_key_values,attention_mask需要包含用于past_key_values的掩码策略。换句话说,attention_mask的长度必须始终为:len(past_key_values) + len(input_ids) - token_type_ids (
torch.Tensorof shape(batch_size, input_ids_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.Tensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.Tensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.Tensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix.如果使用了
past_key_values,可以选择只输入最后的inputs_embeds(参见past_key_values)。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - labels (
torch.Tensorof shape(batch_size, sequence_length), optional) — 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
GPTBigCodeForTokenClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。