OPT
概述
OPT模型是由Meta AI在Open Pre-trained Transformer Language Models中提出的。 OPT是一系列开源的大型因果语言模型,其性能与GPT3相似。
论文的摘要如下:
大型语言模型通常需要数十万计算日的训练,它们在零样本和少样本学习方面展示了显著的能力。鉴于其计算成本,这些模型在没有大量资金的情况下难以复制。对于通过API提供的少数模型,无法访问完整的模型权重,这使得它们难以研究。我们推出了Open Pre-trained Transformers (OPT),这是一套仅包含解码器的预训练变换器,参数范围从125M到175B,我们旨在全面且负责任地与感兴趣的研究人员分享。我们展示了OPT-175B与GPT-3相当,而开发所需的碳足迹仅为1/7。我们还发布了我们的日志,详细记录了我们面临的基础设施挑战,以及用于实验所有发布模型的代码。
该模型由Arthur Zucker、Younes Belkada和Patrick Von Platen贡献。 原始代码可以在这里找到。
提示:
- OPT 具有与
BartDecoder相同的架构。 - 与GPT2相反,OPT在每个提示的开头添加了EOS标记
。
资源
以下是官方Hugging Face和社区(由🌎表示)提供的资源列表,帮助您开始使用OPT。如果您有兴趣提交资源以包含在此处,请随时打开一个Pull Request,我们将进行审核。理想情况下,资源应展示一些新内容,而不是重复现有资源。
- 一个关于使用PEFT、bitsandbytes和Transformers微调OPT的笔记本。🌎
- 一篇关于使用OPT的解码策略的博客文章。
- Causal language modeling 🤗 Hugging Face 课程的章节。
- OPTForCausalLM 由这个 因果语言建模示例脚本 和 notebook 支持。
- TFOPTForCausalLM 由这个 因果语言建模示例脚本 和 notebook 支持。
- FlaxOPTForCausalLM 由这个 因果语言建模示例脚本 支持。
- 文本分类任务指南
- OPTForSequenceClassification 由这个 示例脚本 和 笔记本 支持。
- OPTForQuestionAnswering 由这个 question answering example script 和 notebook 支持。
- Question answering 章节 来自 🤗 Hugging Face 课程。
⚡️ 推理
结合OPT和Flash Attention 2
首先,确保安装最新版本的 Flash Attention 2 以包含滑动窗口注意力功能。
pip install -U flash-attn --no-build-isolation
请确保您拥有与Flash-Attention 2兼容的硬件。更多信息请参阅flash-attn仓库的官方文档。同时,请确保以半精度加载您的模型(例如 `torch.float16`)。
要使用Flash Attention 2加载并运行模型,请参考以下代码片段:
>>> import torch
>>> from transformers import OPTForCausalLM, GPT2Tokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = OPTForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = GPT2Tokenizer.from_pretrained("facebook/opt-350m")
>>> prompt = ("A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the "
"Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived "
"there?")
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=30, do_sample=False)
>>> tokenizer.batch_decode(generated_ids)[0]
'</s>A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived there?\nStatue: I have lived here for about a year.\nHuman: What is your favorite place to eat?\nStatue: I love'预期的加速
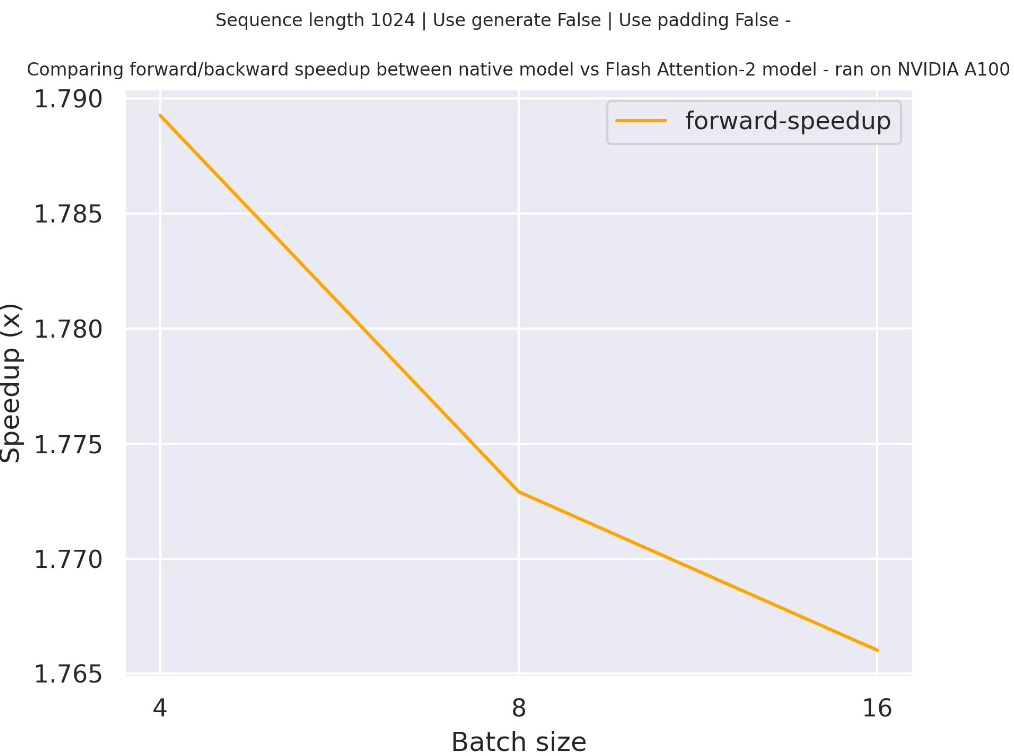
下面是一个预期的加速图,比较了使用facebook/opt-2.7b检查点的transformers原生实现与使用两种不同序列长度的Flash Attention 2版本模型的纯推理时间。
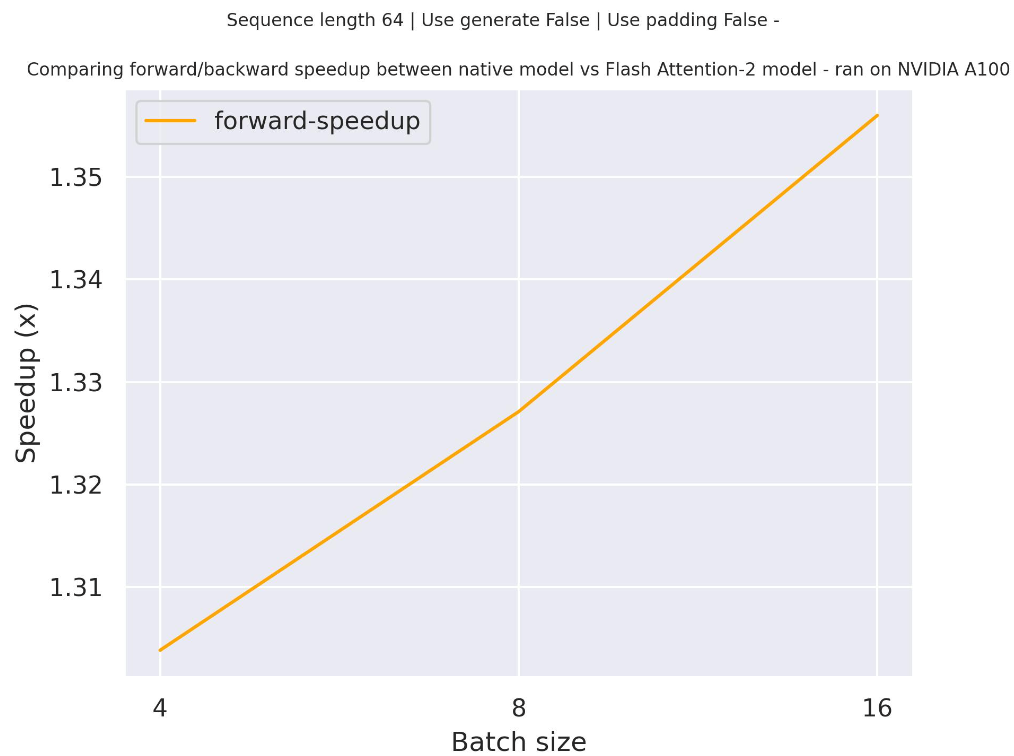
下面是一个预期的加速图,比较了使用facebook/opt-350m检查点的transformers原生实现与使用两种不同序列长度的Flash Attention 2版本模型的纯推理时间。
使用缩放点积注意力 (SDPA)
PyTorch 包含一个原生的缩放点积注意力(SDPA)操作符,作为 torch.nn.functional 的一部分。这个函数
包含了几种实现,可以根据输入和使用的硬件进行应用。更多信息请参阅
官方文档
或 GPU 推理
页面。
默认情况下,当有可用实现时,SDPA 用于 torch>=2.1.1,但你也可以在 from_pretrained() 中设置 attn_implementation="sdpa" 来明确请求使用 SDPA。
from transformers import OPTForCausalLM
model = OPTForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16, attn_implementation="sdpa")
...为了获得最佳加速效果,我们建议以半精度加载模型(例如 torch.float16 或 torch.bfloat16)。
在本地基准测试(L40S-45GB,PyTorch 2.4.0,操作系统 Debian GNU/Linux 11)中使用 float16 和
facebook/opt-350m,我们在训练和推理过程中看到了以下加速效果。
训练
| batch_size | seq_len | 每批次时间(eager - 秒) | 每批次时间(sdpa - 秒) | 加速百分比 (%) | Eager 峰值内存 (MB) | sdpa 峰值内存 (MB) | 内存节省百分比 (%) |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 0.047 | 0.037 | 26.360 | 1474.611 | 1474.32 | 0.019 |
| 1 | 256 | 0.046 | 0.037 | 24.335 | 1498.541 | 1499.49 | -0.063 |
| 1 | 512 | 0.046 | 0.037 | 24.959 | 1973.544 | 1551.35 | 27.215 |
| 1 | 1024 | 0.062 | 0.038 | 65.135 | 4867.113 | 1698.35 | 186.578 |
| 1 | 2048 | 0.230 | 0.039 | 483.933 | 15662.224 | 2715.75 | 476.718 |
| 2 | 128 | 0.045 | 0.037 | 20.455 | 1498.164 | 1499.49 | -0.089 |
| 2 | 256 | 0.046 | 0.037 | 24.027 | 1569.367 | 1551.35 | 1.161 |
| 2 | 512 | 0.045 | 0.037 | 20.965 | 3257.074 | 1698.35 | 91.778 |
| 2 | 1024 | 0.122 | 0.038 | 225.958 | 9054.405 | 2715.75 | 233.403 |
| 2 | 2048 | 0.464 | 0.067 | 593.646 | 30572.058 | 4750.55 | 543.548 |
| 4 | 128 | 0.045 | 0.037 | 21.918 | 1549.448 | 1551.35 | -0.123 |
| 4 | 256 | 0.044 | 0.038 | 18.084 | 2451.768 | 1698.35 | 44.361 |
| 4 | 512 | 0.069 | 0.037 | 84.421 | 5833.180 | 2715.75 | 114.791 |
| 4 | 1024 | 0.262 | 0.062 | 319.475 | 17427.842 | 4750.55 | 266.860 |
| 4 | 2048 | OOM | 0.062 | Eager OOM | OOM | 4750.55 | Eager OOM |
| 8 | 128 | 0.044 | 0.037 | 18.436 | 2049.115 | 1697.78 | 20.694 |
| 8 | 256 | 0.048 | 0.036 | 32.887 | 4222.567 | 2715.75 | 55.484 |
| 8 | 512 | 0.153 | 0.06 | 154.862 | 10985.391 | 4750.55 | 131.245 |
| 8 | 1024 | 0.526 | 0.122 | 330.697 | 34175.763 | 8821.18 | 287.428 |
| 8 | 2048 | OOM | 0.122 | 急切 OOM | OOM | 8821.18 | 急切 OOM |
推理
| batch_size | seq_len | 每个令牌的延迟 eager (毫秒) | 每个令牌的延迟 SDPA (毫秒) | 加速 (%) | 内存 eager (MB) | 内存 BT (MB) | 内存节省 (%) |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 11.634 | 8.647 | 34.546 | 717.676 | 717.674 | 0 |
| 1 | 256 | 11.593 | 8.86 | 30.851 | 742.852 | 742.845 | 0.001 |
| 1 | 512 | 11.515 | 8.816 | 30.614 | 798.232 | 799.593 | -0.17 |
| 1 | 1024 | 11.556 | 8.915 | 29.628 | 917.265 | 895.538 | 2.426 |
| 2 | 128 | 12.724 | 11.002 | 15.659 | 762.434 | 762.431 | 0 |
| 2 | 256 | 12.704 | 11.063 | 14.83 | 816.809 | 816.733 | 0.009 |
| 2 | 512 | 12.757 | 10.947 | 16.535 | 917.383 | 918.339 | -0.104 |
| 2 | 1024 | 13.018 | 11.018 | 18.147 | 1162.65 | 1114.81 | 4.291 |
| 4 | 128 | 12.739 | 10.959 | 16.243 | 856.335 | 856.483 | -0.017 |
| 4 | 256 | 12.718 | 10.837 | 17.355 | 957.298 | 957.674 | -0.039 |
| 4 | 512 | 12.813 | 10.822 | 18.393 | 1158.44 | 1158.45 | -0.001 |
| 4 | 1024 | 13.416 | 11.06 | 21.301 | 1653.42 | 1557.19 | 6.18 |
| 8 | 128 | 12.763 | 10.891 | 17.193 | 1036.13 | 1036.51 | -0.036 |
| 8 | 256 | 12.89 | 11.104 | 16.085 | 1236.98 | 1236.87 | 0.01 |
| 8 | 512 | 13.327 | 10.939 | 21.836 | 1642.29 | 1641.78 | 0.031 |
| 8 | 1024 | 15.181 | 11.175 | 35.848 | 2634.98 | 2443.35 | 7.843 |
OPTConfig
类 transformers.OPTConfig
< source >( 词汇大小 = 50272 隐藏大小 = 768 隐藏层数 = 12 前馈网络维度 = 3072 最大位置嵌入 = 2048 是否在层前进行归一化 = True 移除最终层归一化 = False 词嵌入投影维度 = None 丢弃率 = 0.1 注意力丢弃率 = 0.0 注意力头数 = 12 激活函数 = 'relu' 层丢弃率 = 0.0 初始化标准差 = 0.02 使用缓存 = True 填充标记ID = 1 开始标记ID = 2 结束标记ID = 2 启用偏置 = True 层归一化元素仿射 = True **kwargs )
参数
- vocab_size (
int, 可选, 默认为 50272) — OPT 模型的词汇量大小。定义了调用 OPTModel 时传递的inputs_ids可以表示的不同标记的数量 - hidden_size (
int, optional, 默认为 768) — 层和池化层的维度。 - num_hidden_layers (
int, optional, 默认为 12) — 解码器层数. - ffn_dim (
int, optional, 默认为 3072) — 解码器中“中间”(通常称为前馈)层的维度。 - num_attention_heads (
int, optional, defaults to 12) — Transformer解码器中每个注意力层的注意力头数。 - activation_function (
str或function, 可选, 默认为"relu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu","relu","silu"和"gelu_new". - max_position_embeddings (
int, optional, 默认为 2048) — 此模型可能使用的最大序列长度。通常将其设置为较大的值以防万一(例如,512 或 1024 或 2048)。 - do_layer_norm_before (
bool, 可选, 默认为True) — 是否在注意力块之前执行层归一化。 - word_embed_proj_dim (
int, 可选) —word_embed_proj_dim可以设置为下投影词嵌入,例如opt-350m。默认为hidden_size. - dropout (
float, optional, defaults to 0.1) — 嵌入层、编码器和池化器中所有全连接层的dropout概率。 - attention_dropout (
float, optional, 默认为 0.0) — 注意力概率的丢弃比例。 - layerdrop (
float, optional, 默认为 0.0) — LayerDrop 概率。更多详情请参阅 [LayerDrop 论文](see https://arxiv.org/abs/1909.11556)。 - init_std (
float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 - use_cache (
bool, optional, defaults toTrue) — 模型是否应返回最后的键/值注意力(并非所有模型都使用)。 - enable_bias (
bool, optional, 默认为True) — 是否在注意力块中的线性层使用偏置项。 - layer_norm_elementwise_affine (
bool, optional, defaults toTrue) — 层归一化是否应具有可学习的参数。
这是用于存储OPTModel配置的配置类。它用于根据指定的参数实例化一个OPT模型,定义模型架构。使用默认值实例化配置将产生类似于facebook/opt-350m架构的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import OPTConfig, OPTModel
>>> # Initializing a OPT facebook/opt-large style configuration
>>> configuration = OPTConfig()
>>> # Initializing a model (with random weights) from the facebook/opt-large style configuration
>>> model = OPTModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configOPTModel
类 transformers.OPTModel
< source >( config: OPTConfig )
参数
- config (OPTConfig) — 模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的OPT模型输出原始的隐藏状态,没有任何特定的头部。 此模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: LongTensor = None attention_mask: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None past_key_values: typing.Optional[typing.List[torch.FloatTensor]] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None position_ids: typing.Optional[torch.LongTensor] = None ) → transformers.modeling_outputs.BaseModelOutputWithPast 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
如果使用了
past_key_values,则可以选择性地仅输入最后一个decoder_input_ids(参见past_key_values)。如果你想改变填充行为,你应该阅读
modeling_opt._prepare_decoder_attention_mask并根据你的需求进行修改。有关默认策略的更多信息,请参见论文中的图1。 - head_mask (
torch.Tensorof shape(encoder_layers, encoder_attention_heads), optional) — 用于在编码器中屏蔽注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and 2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head).包含预先计算的隐藏状态(自注意力块和交叉注意力块中的键和值),这些状态可用于(参见
past_key_values输入)以加速顺序解码。如果使用了
past_key_values,用户可以选择只输入形状为(batch_size, 1)的最后一个decoder_input_ids(那些没有将其过去键值状态提供给此模型的),而不是形状为(batch_size, sequence_length)的所有decoder_input_ids。 - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制权,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. for padding use -1.
返回
transformers.modeling_outputs.BaseModelOutputWithPast 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithPast 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(OPTConfig)和输入。
-
last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。如果使用了
past_key_values,则只输出形状为(batch_size, 1, hidden_size)的序列的最后一个隐藏状态。 -
past_key_values (
tuple(tuple(torch.FloatTensor)), 可选, 当传递了use_cache=True或当config.use_cache=True时返回) — 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量,并且如果config.is_encoder_decoder=True,则还包含 2 个形状为(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)的额外张量。包含预先计算的隐藏状态(自注意力块中的键和值,并且如果
config.is_encoder_decoder=True,则还包含交叉注意力块中的键和值),这些隐藏状态可以用于(参见past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每个层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
OPTModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, OPTModel
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = OPTModel.from_pretrained("facebook/opt-350m")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateOPTForCausalLM
前进
< source >( input_ids: LongTensor = None attention_mask: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None past_key_values: typing.Optional[typing.List[torch.FloatTensor]] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None position_ids: typing.Optional[torch.LongTensor] = None ) → transformers.modeling_outputs.CausalLMOutputWithPast 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- head_mask (
torch.Tensor形状为(num_hidden_layers, num_attention_heads), 可选) — 用于屏蔽注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and 2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head). The two additional tensors are only required when the model is used as a decoder in a Sequence to Sequence model.包含预先计算的隐藏状态(自注意力块和交叉注意力块中的键和值),这些状态可用于(参见
past_key_values输入)以加速顺序解码。如果使用了
past_key_values,用户可以选择只输入最后一个decoder_input_ids(那些没有将其过去键值状态提供给此模型的)形状为(batch_size, 1),而不是所有形状为(batch_size, sequence_length)的decoder_input_ids。 - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。 如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — 用于计算掩码语言建模损失的标签。索引应在[0, ..., config.vocab_size]或 -100 之间(参见input_ids文档字符串)。索引设置为-100的标记将被忽略 (掩码),损失仅针对标签在[0, ..., config.vocab_size]之间的标记计算。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码 (参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. for padding use -1.
返回
transformers.modeling_outputs.CausalLMOutputWithPast 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.CausalLMOutputWithPast 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(OPTConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,), 可选, 当提供labels时返回) — 语言建模损失(用于下一个标记预测)。 -
logits (
torch.FloatTensor形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
past_key_values (
tuple(tuple(torch.FloatTensor)), 可选, 当传递use_cache=True或当config.use_cache=True时返回) — 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量)包含预计算的隐藏状态(自注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) —torch.FloatTensor的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) —torch.FloatTensor的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
示例:
>>> from transformers import AutoTokenizer, OPTForCausalLM
>>> model = OPTForCausalLM.from_pretrained("facebook/opt-350m")
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> prompt = "Hey, are you conscious? Can you talk to me?"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> # Generate
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
"Hey, are you conscious? Can you talk to me?\nI'm not conscious. I'm just a little bit of a weirdo."OPTForSequenceClassification
类 transformers.OPTForSequenceClassification
< source >( config: OPTConfig )
参数
- config (OPTConfig) — 模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
带有序列分类头(线性层)的OPT模型转换器。
OPTForSequenceClassification 使用最后一个标记进行分类,就像其他因果模型(例如 GPT-2)所做的那样。
由于它对最后一个标记进行分类,因此需要知道最后一个标记的位置。如果在配置中定义了pad_token_id,它会在每一行中找到不是填充标记的最后一个标记。如果没有定义pad_token_id,它只需取批次中每一行的最后一个值。由于在传递inputs_embeds而不是input_ids时无法猜测填充标记,它会执行相同的操作(取批次中每一行的最后一个值)。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None past_key_values: typing.Optional[typing.Tuple[typing.Tuple[torch.Tensor]]] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None position_ids: typing.Optional[torch.LongTensor] = None ) → transformers.modeling_outputs.SequenceClassifierOutputWithPast 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
如果使用了
past_key_values,则可以选择性地仅输入最后一个decoder_input_ids(参见past_key_values)。如果你想改变填充行为,你应该阅读
modeling_opt._prepare_decoder_attention_mask并根据你的需求进行修改。有关默认策略的更多信息,请参见论文中的图1。 - head_mask (
torch.Tensor形状为(encoder_layers, encoder_attention_heads), 可选) — 用于在编码器中屏蔽注意力模块中选定的头。屏蔽值在[0, 1]中选择:- 1 表示头 未被屏蔽,
- 0 表示头 被屏蔽.
- past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and 2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head).包含预先计算的隐藏状态(自注意力块和交叉注意力块中的键和值),这些状态可用于(参见
past_key_values输入)以加速顺序解码。如果使用了
past_key_values,用户可以选择只输入形状为(batch_size, 1)的最后一个decoder_input_ids(那些没有将其过去键值状态提供给此模型的),而不是形状为(batch_size, sequence_length)的所有decoder_input_ids。 - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制权,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. for padding use -1. - labels (
torch.LongTensor形状为(batch_size,), 可选) — 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.SequenceClassifierOutputWithPast 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.SequenceClassifierOutputWithPast 或一个由 torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含根据配置(OPTConfig)和输入的各种元素。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 分类(或回归,如果 config.num_labels==1)损失。 -
logits (
torch.FloatTensor形状为(batch_size, config.num_labels)) — 分类(或回归,如果 config.num_labels==1)得分(在 SoftMax 之前)。 -
past_key_values (
tuple(tuple(torch.FloatTensor)),可选,当传递use_cache=True或当config.use_cache=True时返回) — 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量。包含预先计算的隐藏状态(自注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) —torch.FloatTensor元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) —torch.FloatTensor元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
OPTForSequenceClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
单标签分类示例:
>>> import torch
>>> from transformers import AutoTokenizer, OPTForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("ArthurZ/opt-350m-dummy-sc")
>>> model = OPTForSequenceClassification.from_pretrained("ArthurZ/opt-350m-dummy-sc")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_id = logits.argmax().item()
>>> model.config.id2label[predicted_class_id]
'LABEL_0'
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = OPTForSequenceClassification.from_pretrained("ArthurZ/opt-350m-dummy-sc", num_labels=num_labels)
>>> labels = torch.tensor([1])
>>> loss = model(**inputs, labels=labels).loss
>>> round(loss.item(), 2)
1.71多标签分类示例:
>>> import torch
>>> from transformers import AutoTokenizer, OPTForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("ArthurZ/opt-350m-dummy-sc")
>>> model = OPTForSequenceClassification.from_pretrained("ArthurZ/opt-350m-dummy-sc", problem_type="multi_label_classification")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_ids = torch.arange(0, logits.shape[-1])[torch.sigmoid(logits).squeeze(dim=0) > 0.5]
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = OPTForSequenceClassification.from_pretrained(
... "ArthurZ/opt-350m-dummy-sc", num_labels=num_labels, problem_type="multi_label_classification"
... )
>>> labels = torch.sum(
... torch.nn.functional.one_hot(predicted_class_ids[None, :].clone(), num_classes=num_labels), dim=1
... ).to(torch.float)
>>> loss = model(**inputs, labels=labels).lossOPTForQuestionAnswering
类 transformers.OPTForQuestionAnswering
< source >( config: OPTConfig )
参数
- config (OPTConfig) — 模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型相关的权重,仅加载配置。查看 from_pretrained() 方法以加载模型权重。
OPT模型转换器,顶部带有用于抽取式问答任务(如SQuAD)的跨度分类头
(在隐藏状态输出之上的线性层,用于计算span start logits和span end logits)。
该模型继承自PreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个PyTorch torch.nn.Module 子类。 将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None past_key_values: typing.Optional[typing.Tuple[typing.Tuple[torch.Tensor]]] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None start_positions: typing.Optional[torch.LongTensor] = None end_positions: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None position_ids: typing.Optional[torch.LongTensor] = None ) → transformers.modeling_outputs.QuestionAnsweringModelOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
如果使用了
past_key_values,则可以选择性地仅输入最后一个decoder_input_ids(参见past_key_values)。如果你想改变填充行为,你应该阅读
modeling_opt._prepare_decoder_attention_mask并根据你的需求进行修改。有关默认策略的更多信息,请参见论文中的图1。 - head_mask (
torch.Tensorof shape(encoder_layers, encoder_attention_heads), optional) — 用于在编码器中屏蔽注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and 2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head).包含预先计算的隐藏状态(自注意力块和交叉注意力块中的键和值),这些状态可用于(参见
past_key_values输入)以加速顺序解码。如果使用了
past_key_values,用户可以选择只输入形状为(batch_size, 1)的最后一个decoder_input_ids(那些没有将其过去键值状态提供给此模型的),而不是形状为(batch_size, sequence_length)的所有decoder_input_ids。 - inputs_embeds (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size), 可选) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - use_cache (
bool, 可选) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. for padding use -1. - start_positions (
torch.LongTensorof shape(batch_size,), optional) — 用于计算标记分类损失的标记跨度起始位置(索引)的标签。 位置被限制在序列长度内(sequence_length)。序列之外的位置不会用于计算损失。 - end_positions (
torch.LongTensorof shape(batch_size,), optional) — 用于计算标记分类损失的标记跨度结束位置(索引)的标签。 位置被限制在序列长度内(sequence_length)。序列之外的位置不会用于计算损失。
返回
transformers.modeling_outputs.QuestionAnsweringModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.QuestionAnsweringModelOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,取决于配置(OPTConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 总跨度提取损失是起始和结束位置的交叉熵之和。 -
start_logits (
torch.FloatTensor形状为(batch_size, sequence_length)) — 跨度起始分数(在 SoftMax 之前)。 -
end_logits (
torch.FloatTensor形状为(batch_size, sequence_length)) — 跨度结束分数(在 SoftMax 之前)。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
OPTForQuestionAnswering 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, OPTForQuestionAnswering
>>> import torch
>>> torch.manual_seed(4)
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> # note: we are loading a OPTForQuestionAnswering from the hub here,
>>> # so the head will be randomly initialized, hence the predictions will be random
>>> model = OPTForQuestionAnswering.from_pretrained("facebook/opt-350m")
>>> question, text = "Who was Jim Henson?", "Jim Henson was a nice puppet"
>>> inputs = tokenizer(question, text, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> answer_start_index = outputs.start_logits.argmax()
>>> answer_end_index = outputs.end_logits.argmax()
>>> answer_offset = len(tokenizer(question)[0])
>>> predict_answer_tokens = inputs.input_ids[
... 0, answer_offset + answer_start_index : answer_offset + answer_end_index + 1
... ]
>>> predicted = tokenizer.decode(predict_answer_tokens)
>>> predicted
' a nice puppet'TFOPTModel
类 transformers.TFOPTModel
< source >( config: OPTConfig **kwargs )
参数
- config (OPTConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的TF OPT模型输出原始隐藏状态,没有任何特定的头部。 此模型继承自TFPreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入大小、修剪头部等)。
该模型也是一个keras.Model子类。可以将其作为常规的TF 2.0 Keras模型使用,并参考TF 2.0文档以了解与一般使用和行为相关的所有事项。
TensorFlow 模型和层在 transformers 中接受两种格式作为输入:
- 将所有输入作为关键字参数(如PyTorch模型),或
- 将所有输入作为列表、元组或字典放在第一个位置参数中。
支持第二种格式的原因是,Keras 方法在将输入传递给模型和层时更喜欢这种格式。由于这种支持,当使用像 model.fit() 这样的方法时,事情应该“正常工作”——只需以 model.fit() 支持的任何格式传递你的输入和标签!然而,如果你想在 Keras 方法之外使用第二种格式,比如在使用 Keras Functional API 创建自己的层或模型时,有三种方法可以用来将所有输入张量收集到第一个位置参数中:
- 仅包含
input_ids的单个张量,没有其他内容:model(input_ids) - 一个长度不定的列表,包含一个或多个输入张量,按照文档字符串中给出的顺序:
model([input_ids, attention_mask])或model([input_ids, attention_mask, token_type_ids]) - 一个字典,包含一个或多个与文档字符串中给出的输入名称相关联的输入张量:
model({"input_ids": input_ids, "token_type_ids": token_type_ids})
请注意,当使用子类化创建模型和层时,您不需要担心这些,因为您可以像传递任何其他Python函数一样传递输入!
调用
< source >( input_ids: TFModelInputType | None = None attention_mask: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None past_key_values: Optional[Tuple[Tuple[Union[np.ndarray, tf.Tensor]]]] = None inputs_embeds: np.ndarray | tf.Tensor | None = None use_cache: Optional[bool] = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: Optional[bool] = False **kwargs ) → transformers.modeling_tf_outputs.TFBaseModelOutputWithPast 或 tuple(tf.Tensor)
参数
- input_ids (
tf.Tensorof shape({0})) — Indices of input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
tf.Tensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- head_mask (
tf.Tensor形状为(encoder_layers, encoder_attention_heads), 可选) — 用于在编码器中屏蔽注意力模块中选定的头。在[0, 1]中选择的掩码值:- 1 表示头 未被屏蔽,
- 0 表示头 被屏蔽.
- past_key_values (
Tuple[Tuple[tf.Tensor]]长度为config.n_layers) — 包含预计算的注意力块的关键和值隐藏状态。可用于加速解码。 如果使用了past_key_values,用户可以选择仅输入形状为(batch_size, 1)的最后一个decoder_input_ids(那些没有将其过去的关键值状态提供给此模型的),而不是所有形状为(batch_size, sequence_length)的decoder_input_ids。 - use_cache (
bool, 可选, 默认为True) — 如果设置为True,past_key_values键值状态将被返回,并可用于加速解码(参见past_key_values)。在训练期间设置为False,在生成期间设置为True - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。此参数只能在eager模式下使用,在graph模式下将使用配置中的值。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。此参数只能在急切模式下使用,在图形模式下将使用配置中的值。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。此参数可以在eager模式下使用,在graph模式下该值将始终设置为True. - 训练 (
bool, 可选, 默认为False) — 是否在训练模式下使用模型(一些模块如dropout模块在训练和评估时具有不同的行为)。
返回
transformers.modeling_tf_outputs.TFBaseModelOutputWithPast 或 tuple(tf.Tensor)
一个 transformers.modeling_tf_outputs.TFBaseModelOutputWithPast 或一个 tf.Tensor 元组(如果
return_dict=False 被传递或当 config.return_dict=False 时)包含各种元素,具体取决于
配置 (OPTConfig) 和输入。
-
last_hidden_state (
tf.Tensor形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。如果使用了
past_key_values,则只输出形状为(batch_size, 1, hidden_size)的序列的最后一个隐藏状态。 -
past_key_values (
List[tf.Tensor], 可选, 当use_cache=True被传递或当config.use_cache=True时返回) — 长度为config.n_layers的tf.Tensor列表,每个张量的形状为(2, batch_size, num_heads, sequence_length, embed_size_per_head))。包含预先计算的隐藏状态(注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(tf.Tensor), 可选, 当output_hidden_states=True被传递或当config.output_hidden_states=True时返回) —tf.Tensor元组(一个用于嵌入的输出 + 一个用于每层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(tf.Tensor), 可选, 当output_attentions=True被传递或当config.output_attentions=True时返回) —tf.Tensor元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
TFOPTModel 的 forward 方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, TFOPTModel
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = TFOPTModel.from_pretrained("facebook/opt-350m")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
>>> outputs = model(inputs)
>>> last_hidden_states = outputs.last_hidden_stateTFOPTForCausalLM
类 transformers.TFOPTForCausalLM
< source >( config: OPTConfig **kwargs )
参数
- config (OPTConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,仅加载配置。查看 from_pretrained() 方法以加载模型权重。
带有语言建模头部的OPT模型转换器。
该模型继承自 TFPreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头部等)。
该模型也是一个keras.Model子类。可以将其作为常规的TF 2.0 Keras模型使用,并参考TF 2.0文档以了解与一般使用和行为相关的所有事项。
TensorFlow 模型和层在 transformers 中接受两种格式作为输入:
- 将所有输入作为关键字参数(如PyTorch模型),或
- 将所有输入作为列表、元组或字典放在第一个位置参数中。
支持第二种格式的原因是,Keras 方法在将输入传递给模型和层时更喜欢这种格式。由于这种支持,当使用像 model.fit() 这样的方法时,事情应该“正常工作”——只需以 model.fit() 支持的任何格式传递你的输入和标签!然而,如果你想在 Keras 方法之外使用第二种格式,比如在使用 Keras Functional API 创建自己的层或模型时,有三种方法可以用来将所有输入张量收集到第一个位置参数中:
- 仅包含
input_ids的单个张量,没有其他内容:model(input_ids) - 一个长度不定的列表,包含一个或多个输入张量,按照文档字符串中给出的顺序:
model([input_ids, attention_mask])或model([input_ids, attention_mask, token_type_ids]) - 一个字典,包含一个或多个与文档字符串中给出的输入名称相关联的输入张量:
model({"input_ids": input_ids, "token_type_ids": token_type_ids})
请注意,当使用子类化创建模型和层时,您不需要担心这些,因为您可以像传递任何其他Python函数一样传递输入!
调用
< source >( input_ids: TFModelInputType | None = None past_key_values: Optional[Tuple[Tuple[Union[np.ndarray, tf.Tensor]]]] = None attention_mask: np.ndarray | tf.Tensor | None = None position_ids: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None inputs_embeds: np.ndarray | tf.Tensor | None = None labels: np.ndarray | tf.Tensor | None = None use_cache: Optional[bool] = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: Optional[bool] = False **kwargs ) → transformers.modeling_tf_outputs.TFCausalLMOutputWithPast or tuple(tf.Tensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- head_mask (
torch.Tensorof shape(num_hidden_layers, num_attention_heads), optional) — 用于屏蔽注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and 2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head). The two additional tensors are only required when the model is used as a decoder in a Sequence to Sequence model.包含预先计算的隐藏状态(自注意力块和交叉注意力块中的键和值),这些状态可用于(参见
past_key_values输入)以加速顺序解码。如果使用了
past_key_values,用户可以选择只输入形状为(batch_size, 1)的最后一个input_ids(那些没有将其过去键值状态提供给此模型的),而不是形状为(batch_size, sequence_length)的所有decoder_input_ids。 - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。 如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — 用于计算掩码语言建模损失的标签。索引应在[0, ..., config.vocab_size]或 -100 之间(参见input_ids文档字符串)。索引设置为-100的标记将被忽略 (掩码),损失仅针对标签在[0, ..., config.vocab_size]之间的标记计算。 - use_cache (
bool, 可选) — 如果设置为True,将返回past_key_values键值状态,并可用于加速解码 (参见past_key_values)。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。
返回
transformers.modeling_tf_outputs.TFCausalLMOutputWithPast 或 tuple(tf.Tensor)
一个 transformers.modeling_tf_outputs.TFCausalLMOutputWithPast 或一个 tf.Tensor 元组(如果
return_dict=False 被传递或当 config.return_dict=False 时)包含各种元素,具体取决于
配置 (OPTConfig) 和输入。
-
loss (
tf.Tensor形状为(n,), 可选, 其中 n 是非掩码标签的数量,当提供labels时返回) — 语言建模损失(用于下一个标记的预测)。 -
logits (
tf.Tensor形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前的每个词汇标记的分数)。 -
past_key_values (
List[tf.Tensor], 可选, 当传递use_cache=True或当config.use_cache=True时返回) — 长度为config.n_layers的tf.Tensor列表,每个张量的形状为(2, batch_size, num_heads, sequence_length, embed_size_per_head))。包含预计算的隐藏状态(注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(tf.Tensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) —tf.Tensor元组(一个用于嵌入的输出 + 一个用于每层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(tf.Tensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) —tf.Tensor元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
transformers.modeling_tf_outputs.TFCausalLMOutputWithPast 或 tuple(tf.Tensor): 一个 transformers.modeling_tf_outputs.TFCausalLMOutputWithPast 或一个 tf.Tensor 元组(如果
return_dict=False 被传递或当 config.return_dict=False 时)包含各种元素,具体取决于
配置 (OPTConfig) 和输入。
-
loss (
tf.Tensor形状为(n,), 可选, 其中 n 是非掩码标签的数量,当提供labels时返回) — 语言建模损失(用于下一个标记的预测)。 -
logits (
tf.Tensor形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前的每个词汇标记的分数)。 -
past_key_values (
List[tf.Tensor], 可选, 当传递use_cache=True或当config.use_cache=True时返回) — 长度为config.n_layers的tf.Tensor列表,每个张量的形状为(2, batch_size, num_heads, sequence_length, embed_size_per_head))。包含预计算的隐藏状态(注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(tf.Tensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) —tf.Tensor元组(一个用于嵌入的输出 + 一个用于每层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(tf.Tensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) —tf.Tensor元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
示例:
>>> from transformers import AutoTokenizer, TFOPTForCausalLM
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = TFOPTForCausalLM.from_pretrained("facebook/opt-350m")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
>>> outputs = model(inputs)
>>> logits = outputs.logitsFlaxOPTModel
类 transformers.FlaxOPTModel
< source >( config: OPTConfig input_shape: 类型.元组[int] = (1, 1) seed: 整数 = 0 dtype: 数据类型 =
__call__
< source >( input_ids: 数组 attention_mask: 可选的[jax.Array] = None position_ids: 可选的[jax.Array] = None params: 字典 = None past_key_values: 字典 = None output_attentions: 可选的[布尔] = None output_hidden_states: 可选的[布尔] = None return_dict: 可选的[布尔] = None dropout_rng: tuple(torch.FloatTensor)
返回
transformers.modeling_flax_outputs.FlaxBaseModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_flax_outputs.FlaxBaseModelOutput 或一个元组
torch.FloatTensor(如果传递了 return_dict=False 或当 config.return_dict=False 时)包含各种
元素,具体取决于配置(OPTConfig)和输入。
-
last_hidden_state (
jnp.ndarray形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。 -
hidden_states (
tuple(jnp.ndarray), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 元组jnp.ndarray(一个用于嵌入的输出 + 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(jnp.ndarray), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 元组jnp.ndarray(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
示例:
>>> from transformers import AutoTokenizer, FlaxOPTModel
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = FlaxOPTModel.from_pretrained("facebook/opt-350m")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="jax")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateFlaxOPTForCausalLM
类 transformers.FlaxOPTForCausalLM
< source >( config: OPTConfig input_shape: 类型.元组[int] = (1, 1) seed: 整数 = 0 dtype: 数据类型 =
参数
- config (OPTConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
- dtype (
jax.numpy.dtype, optional, defaults tojax.numpy.float32) — The data type of the computation. Can be one ofjax.numpy.float32,jax.numpy.float16(on GPUs) andjax.numpy.bfloat16(on TPUs).这可以用于在GPU或TPU上启用混合精度训练或半精度推理。如果指定,所有计算将使用给定的
dtype执行。请注意,这仅指定了计算的数据类型,并不影响模型参数的数据类型。
带有语言建模头部的OPT模型(权重与输入嵌入绑定的线性层),例如用于自回归任务。
该模型继承自FlaxPreTrainedModel。请查看超类文档以了解库为其所有模型实现的通用方法(如下载或保存、调整输入嵌入的大小、修剪头等)。
该模型也是一个Flax Linen flax.nn.Module 子类。将其作为常规的Flax模块使用,并参考Flax文档以获取与一般用法和行为相关的所有信息。
最后,该模型支持JAX的固有特性,例如:
__call__
< source >( input_ids: 数组 attention_mask: 可选的[jax.Array] = None position_ids: 可选的[jax.Array] = None params: 字典 = None past_key_values: 字典 = None output_attentions: 可选的[布尔] = None output_hidden_states: 可选的[布尔] = None return_dict: 可选的[布尔] = None dropout_rng: <函数 PRNGKey 在 0x7f50727b7640> = None deterministic: 布尔 = True ) → transformers.modeling_flax_outputs.FlaxBaseModelOutput 或 tuple(torch.FloatTensor)
返回
transformers.modeling_flax_outputs.FlaxBaseModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_flax_outputs.FlaxBaseModelOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(OPTConfig)和输入。
-
last_hidden_state (
jnp.ndarray形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。 -
hidden_states (
tuple(jnp.ndarray), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由jnp.ndarray组成的元组(一个用于嵌入层的输出,一个用于每一层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(jnp.ndarray), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由jnp.ndarray组成的元组(每一层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力权重在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
示例:
>>> from transformers import AutoTokenizer, FlaxOPTForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = FlaxOPTForCausalLM.from_pretrained("facebook/opt-350m")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="np")
>>> outputs = model(**inputs)
>>> # retrieve logts for next token
>>> next_token_logits = outputs.logits[:, -1]