NLLB
更新后的分词器行为
免责声明:分词器的默认行为在2023年4月进行了修复并因此发生了变化。
之前的版本在目标分词和源分词的标记序列末尾添加了[self.eos_token_id, self.cur_lang_code]。这是错误的,正如NLLB论文中提到的(第48页,6.1.1. 模型架构):
请注意,我们在源序列前加上源语言,而不是像之前几项工作中那样加上目标语言(Arivazhagan et al., 2019; Johnson et al., 2017)。这主要是因为我们将优先优化模型在任何200种语言对上的零样本性能,而稍微牺牲监督性能。
之前的行为:
>>> from transformers import NllbTokenizer
>>> tokenizer = NllbTokenizer.from_pretrained("facebook/nllb-200-distilled-600M")
>>> tokenizer("How was your day?").input_ids
[13374, 1398, 4260, 4039, 248130, 2, 256047]
>>> # 2: '</s>'
>>> # 256047 : 'eng_Latn'新行为
>>> from transformers import NllbTokenizer
>>> tokenizer = NllbTokenizer.from_pretrained("facebook/nllb-200-distilled-600M")
>>> tokenizer("How was your day?").input_ids
[256047, 13374, 1398, 4260, 4039, 248130, 2]启用旧行为可以按如下方式进行:
>>> from transformers import NllbTokenizer
>>> tokenizer = NllbTokenizer.from_pretrained("facebook/nllb-200-distilled-600M", legacy_behaviour=True)概述
NLLB模型在《No Language Left Behind: Scaling Human-Centered Machine Translation》一文中由Marta R. Costa-jussà、James Cross、Onur Çelebi、Maha Elbayad、Kenneth Heafield、Kevin Heffernan、Elahe Kalbassi、Janice Lam、Daniel Licht、Jean Maillard、Anna Sun、Skyler Wang、Guillaume Wenzek、Al Youngblood、Bapi Akula、Loic Barrault、Gabriel Mejia Gonzalez、Prangthip Hansanti、John Hoffman、Semarley Jarrett、Kaushik Ram Sadagopan、Dirk Rowe、Shannon Spruit、Chau Tran、Pierre Andrews、Necip Fazil Ayan、Shruti Bhosale、Sergey Edunov、Angela Fan、Cynthia Gao、Vedanuj Goswami、Francisco Guzmán、Philipp Koehn、Alexandre Mourachko、Christophe Ropers、Safiyyah Saleem、Holger Schwenk和Jeff Wang共同提出。
论文的摘要如下:
以消除全球语言障碍为目标,机器翻译已成为当今人工智能研究的一个关键焦点。然而,这些努力主要集中在少数语言上,而忽略了大多数资源匮乏的语言。在确保安全、高质量结果的同时,如何突破200种语言的障碍,并牢记伦理考虑?在“不让任何语言掉队”项目中,我们通过与原语者的探索性访谈,首先将低资源语言翻译支持的需求置于背景中。然后,我们创建了旨在缩小低资源语言和高资源语言之间性能差距的数据集和模型。更具体地说,我们开发了一个基于稀疏门控专家混合的条件计算模型,该模型使用针对低资源语言量身定制的新颖有效的数据挖掘技术获得的数据进行训练。我们提出了多种架构和训练改进措施,以在数千个任务训练中对抗过拟合。关键的是,我们使用人工翻译的基准Flores-200评估了超过40,000种不同翻译方向的性能,并将人工评估与覆盖Flores-200所有语言的新型毒性基准相结合,以评估翻译的安全性。我们的模型相对于之前的最新技术实现了44%的BLEU提升,为实现通用翻译系统奠定了重要基础。
此实现包含发布时可用的密集模型。
稀疏模型NLLB-MoE(专家混合)现已可用!更多详情请点击这里
使用NLLB生成
在生成目标文本时,将forced_bos_token_id设置为目标语言的ID。以下示例展示了如何使用facebook/nllb-200-distilled-600M模型将英语翻译成法语。
请注意,我们使用的是法语的BCP-47代码 fra_Latn。有关Flores 200数据集中所有BCP-47代码的列表,请参见这里。
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-200-distilled-600M")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M")
>>> article = "UN Chief says there is no military solution in Syria"
>>> inputs = tokenizer(article, return_tensors="pt")
>>> translated_tokens = model.generate(
... **inputs, forced_bos_token_id=tokenizer.convert_tokens_to_ids("fra_Latn"), max_length=30
... )
>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
Le chef de l'ONU dit qu'il n'y a pas de solution militaire en Syrie从非英语的其他语言生成
英语 (eng_Latn) 被设置为默认的翻译源语言。为了指定您希望从其他语言进行翻译,您应在分词器初始化的 src_lang 关键字参数中指定 BCP-47 代码。
请参见以下从罗马尼亚语翻译成德语的示例:
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained(
... "facebook/nllb-200-distilled-600M", token=True, src_lang="ron_Latn"
... )
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M", token=True)
>>> article = "Şeful ONU spune că nu există o soluţie militară în Siria"
>>> inputs = tokenizer(article, return_tensors="pt")
>>> translated_tokens = model.generate(
... **inputs, forced_bos_token_id=tokenizer.convert_tokens_to_ids("deu_Latn"), max_length=30
... )
>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
UN-Chef sagt, es gibt keine militärische Lösung in Syrien资源
NllbTokenizer
类 transformers.NllbTokenizer
< source >( vocab_file bos_token = '' eos_token = '' sep_token = '' cls_token = '' unk_token = '
参数
- vocab_file (
str) — 词汇表文件的路径。 - bos_token (
str, optional, defaults to"<s>") — The beginning of sequence token that was used during pretraining. Can be used a sequence classifier token.在使用特殊标记构建序列时,这不是用于序列开头的标记。使用的标记是
cls_token。 - eos_token (
str, optional, defaults to"</s>") — The end of sequence token.在使用特殊标记构建序列时,这不是用于序列结束的标记。 使用的标记是
sep_token。 - sep_token (
str, 可选, 默认为"") — 分隔符标记,用于从多个序列构建序列时,例如用于序列分类的两个序列或用于问答的文本和问题。它也用作使用特殊标记构建的序列的最后一个标记。 - cls_token (
str, 可选, 默认为") — 用于序列分类的分类器标记(对整个序列进行分类而不是对每个标记进行分类)。当使用特殊标记构建时,它是序列的第一个标记。" - unk_token (
str, optional, defaults to") — 未知标记。不在词汇表中的标记无法转换为ID,而是设置为这个标记。" - pad_token (
str, optional, defaults to") — 用于填充的标记,例如在对不同长度的序列进行批处理时使用。" - mask_token (
str, 可选, 默认为") — 用于屏蔽值的标记。这是在训练此模型时用于屏蔽语言建模的标记。这是模型将尝试预测的标记。" - tokenizer_file (
str, optional) — 用于替代词汇表文件的标记器文件的路径。 - src_lang (
str, optional) — 用于翻译的源语言。 - tgt_lang (
str, optional) — 用于翻译的目标语言。 - sp_model_kwargs (
Dict[str, str]) — 传递给模型初始化的额外关键字参数。
构建一个NLLB分词器。
改编自 RobertaTokenizer 和 XLNetTokenizer。基于 SentencePiece。
分词方法是
示例:
>>> from transformers import NllbTokenizer
>>> tokenizer = NllbTokenizer.from_pretrained(
... "facebook/nllb-200-distilled-600M", src_lang="eng_Latn", tgt_lang="fra_Latn"
... )
>>> example_english_phrase = " UN Chief Says There Is No Military Solution in Syria"
>>> expected_translation_french = "Le chef de l'ONU affirme qu'il n'y a pas de solution militaire en Syrie."
>>> inputs = tokenizer(example_english_phrase, text_target=expected_translation_french, return_tensors="pt")build_inputs_with_special_tokens
< source >( token_ids_0: typing.List[int] token_ids_1: typing.Optional[typing.List[int]] = None ) → List[int]
通过连接和添加特殊标记,从序列或序列对构建序列分类任务的模型输入。一个NLLB序列具有以下格式,其中X代表序列:
input_ids(用于编码器)X [eos, src_lang_code]decoder_input_ids: (用于解码器)X [eos, tgt_lang_code]
BOS 从未被使用。序列对不是预期的使用场景,但它们将在没有分隔符的情况下处理。
NllbTokenizerFast
类 transformers.NllbTokenizerFast
< source >( vocab_file = None tokenizer_file = None bos_token = '' eos_token = '' sep_token = '' cls_token = '' unk_token = '
参数
- vocab_file (
str) — 词汇表文件的路径。 - bos_token (
str, optional, defaults to"<s>") — The beginning of sequence token that was used during pretraining. Can be used a sequence classifier token.在使用特殊标记构建序列时,这不是用于序列开头的标记。使用的标记是
cls_token。 - eos_token (
str, optional, defaults to"</s>") — The end of sequence token.在使用特殊标记构建序列时,这不是用于序列结束的标记。 使用的标记是
sep_token。 - sep_token (
str, optional, defaults to"") — 分隔符标记,用于从多个序列构建序列时,例如用于序列分类的两个序列或用于问答的文本和问题。它也用作使用特殊标记构建的序列的最后一个标记。 - cls_token (
str, 可选, 默认为") — 用于序列分类的分类器标记(对整个序列进行分类而不是对每个标记进行分类)。当使用特殊标记构建时,它是序列的第一个标记。" - unk_token (
str, optional, defaults to") — 未知标记。不在词汇表中的标记无法转换为ID,而是设置为这个标记。" - pad_token (
str, optional, defaults to") — 用于填充的标记,例如在对不同长度的序列进行批处理时使用。" - mask_token (
str, 可选, 默认为") — 用于屏蔽值的标记。这是在训练此模型时用于屏蔽语言建模的标记。这是模型将尝试预测的标记。" - tokenizer_file (
str, optional) — 用于替代词汇表文件的标记器文件的路径。 - src_lang (
str, optional) — 用于翻译的源语言。 - tgt_lang (
str, optional) — 用作翻译目标语言的语言。
构建一个“快速”的NLLB分词器(由HuggingFace的tokenizers库支持)。基于 BPE。
这个分词器继承自PreTrainedTokenizerFast,其中包含了大部分主要方法。用户应参考这个超类以获取有关这些方法的更多信息。
分词方法是
示例:
>>> from transformers import NllbTokenizerFast
>>> tokenizer = NllbTokenizerFast.from_pretrained(
... "facebook/nllb-200-distilled-600M", src_lang="eng_Latn", tgt_lang="fra_Latn"
... )
>>> example_english_phrase = " UN Chief Says There Is No Military Solution in Syria"
>>> expected_translation_french = "Le chef de l'ONU affirme qu'il n'y a pas de solution militaire en Syrie."
>>> inputs = tokenizer(example_english_phrase, text_target=expected_translation_french, return_tensors="pt")build_inputs_with_special_tokens
< source >( token_ids_0: typing.List[int] token_ids_1: typing.Optional[typing.List[int]] = None ) → List[int]
通过连接和添加特殊标记,从序列或序列对构建序列分类任务的模型输入。特殊标记取决于调用set_lang。
一个NLLB序列具有以下格式,其中X代表序列:
input_ids(用于编码器)X [eos, src_lang_code]decoder_input_ids: (用于解码器)X [eos, tgt_lang_code]
BOS 从未被使用。序列对不是预期的使用场景,但它们将在没有分隔符的情况下处理。
create_token_type_ids_from_sequences
< source >( token_ids_0: typing.List[int] token_ids_1: typing.Optional[typing.List[int]] = None ) → List[int]
从传递给序列对分类任务的两个序列中创建一个掩码。nllb 不使用标记类型 ID,因此返回一个零列表。
将特殊令牌重置为源语言设置。
- 在传统模式下:没有前缀和后缀=[eos, src_lang_code]。
- 在默认模式下:前缀=[src_lang_code],后缀=[eos]
将特殊令牌重置为目标语言设置。
- 在传统模式下:没有前缀和后缀=[eos, tgt_lang_code]。
- 在默认模式下:前缀=[tgt_lang_code],后缀=[eos]
使用 Flash Attention 2
Flash Attention 2 是一个更快、优化的注意力分数计算版本,它依赖于 cuda 内核。
安装
首先,检查您的硬件是否与Flash Attention 2兼容。最新的兼容硬件列表可以在官方文档中找到。
接下来,安装最新版本的Flash Attention 2:
pip install -U flash-attn --no-build-isolation
用法
要使用Flash Attention 2加载模型,我们可以将参数attn_implementation="flash_attention_2"传递给.from_pretrained。你可以使用torch.float16或torch.bfloat16精度。
>>> import torch
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to("cuda").eval()
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-200-distilled-600M")
>>> article = "Şeful ONU spune că nu există o soluţie militară în Siria"
>>> inputs = tokenizer(article, return_tensors="pt").to("cuda")
>>> translated_tokens = model.generate(
... **inputs, forced_bos_token_id=tokenizer.convert_tokens_to_ids("deu_Latn"), max_length=30
... )
>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
"UN-Chef sagt, es gibt keine militärische Lösung in Syrien"预期的加速
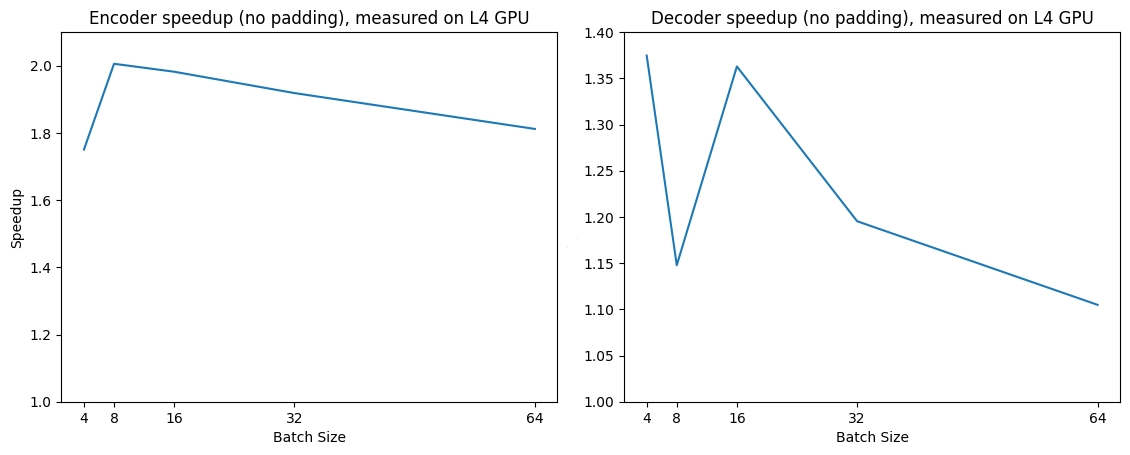
下面是一个预期的加速图,比较了原生实现和Flash Attention 2之间的纯推理时间。
使用缩放点积注意力(SDPA)
PyTorch 包含一个原生的缩放点积注意力(SDPA)操作符,作为 torch.nn.functional 的一部分。这个函数
包含了几种实现,可以根据输入和使用的硬件进行应用。更多信息请参阅
官方文档
或 GPU 推理
页面。
默认情况下,当有可用实现时,SDPA 用于 torch>=2.1.1,但你也可以在 from_pretrained() 中设置 attn_implementation="sdpa" 来明确请求使用 SDPA。
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M", torch_dtype=torch.float16, attn_implementation="sdpa")
...为了获得最佳加速效果,我们建议以半精度加载模型(例如 torch.float16 或 torch.bfloat16)。