YOSO
概述
YOSO模型在You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling
由Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh提出。YOSO通过基于局部敏感哈希(LSH)的伯努利采样方案来近似标准的softmax自注意力机制。原则上,所有的伯努利随机变量都可以通过一次哈希进行采样。
论文的摘要如下:
基于Transformer的模型在自然语言处理(NLP)中得到了广泛应用。Transformer模型的核心是自注意力机制,它捕捉输入序列中标记对的相互作用,并且与序列长度的平方成正比。在较长的序列上训练这些模型成本高昂。在本文中,我们展示了一种基于局部敏感哈希(LSH)的伯努利采样注意力机制,将此类模型的二次复杂度降低到线性。我们通过将自注意力视为与伯努利随机变量相关的单个标记的总和来绕过二次成本,这些标记原则上可以通过一次哈希采样(尽管在实践中,这个数字可能是一个小的常数)。这导致了一种有效的采样方案来估计自注意力,该方案依赖于LSH的特定修改(以便在GPU架构上部署)。我们在GLUE基准测试中评估了我们的算法,使用标准的512序列长度,我们看到了相对于标准预训练Transformer的有利性能。在长序列评估性能的长距离竞技场(LRA)基准测试中,我们的方法实现了与softmax自注意力一致的结果,但具有显著的速度提升和内存节省,并且通常优于其他高效的自注意力方法。我们的代码可在此https URL获取
使用提示
- YOSO注意力算法通过自定义的CUDA内核实现,这些内核是用CUDA C++编写的函数,可以在GPU上多次并行执行。
- 内核提供了一个
fast_hash函数,该函数使用快速哈达玛变换近似查询和键的随机投影。使用这些哈希码,lsh_cumulation函数通过基于LSH的伯努利采样近似自注意力。 - 要使用自定义内核,用户应设置
config.use_expectation = False。为了确保内核成功编译,用户必须安装正确版本的PyTorch和cudatoolkit。默认情况下,config.use_expectation = True,这会使用YOSO-E,并且不需要编译CUDA内核。
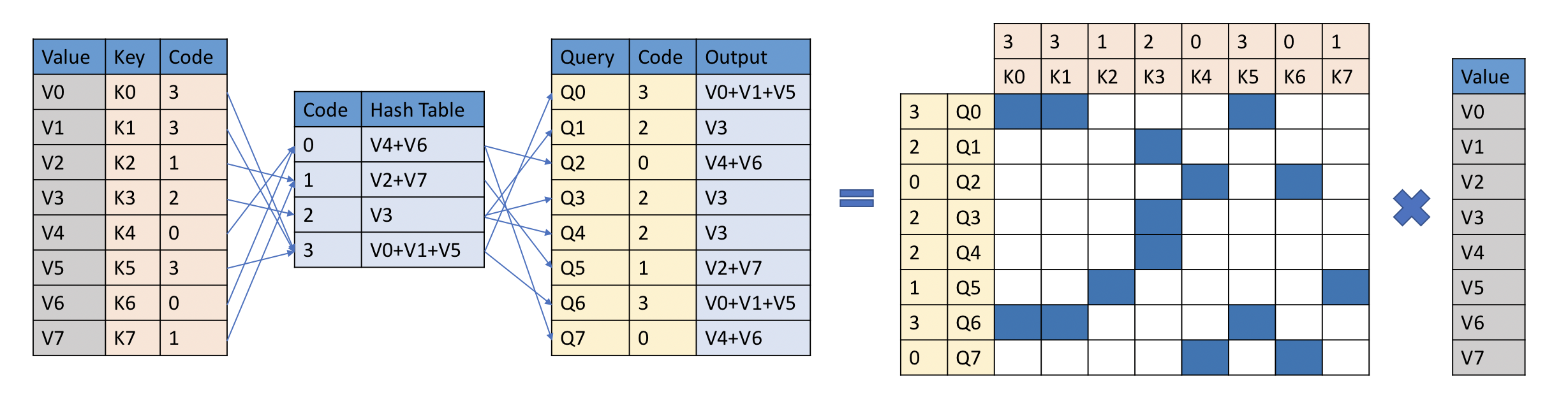 YOSO Attention Algorithm. Taken from the original paper.
YOSO Attention Algorithm. Taken from the original paper. 资源
YosoConfig
类 transformers.YosoConfig
< source >( vocab_size = 50265 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.1 attention_probs_dropout_prob = 0.1 max_position_embeddings = 4096 type_vocab_size = 1 initializer_range = 0.02 layer_norm_eps = 1e-12 position_embedding_type = 'absolute' use_expectation = True hash_code_len = 9 num_hash = 64 conv_window = None use_fast_hash = True lsh_backward = True pad_token_id = 1 bos_token_id = 0 eos_token_id = 2 **kwargs )
参数
- vocab_size (
int, 可选, 默认为 50265) — YOSO 模型的词汇量大小。定义了可以通过调用 YosoModel 时传递的inputs_ids表示的不同标记的数量。 - hidden_size (
int, optional, 默认为 768) — 编码器层和池化层的维度。 - num_hidden_layers (
int, optional, 默认为 12) — Transformer 编码器中的隐藏层数量。 - num_attention_heads (
int, optional, 默认为 12) — Transformer 编码器中每个注意力层的注意力头数。 - intermediate_size (
int, optional, 默认为 3072) — Transformer 编码器中“中间”(即前馈)层的维度。 - hidden_act (
str或function, 可选, 默认为"gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持"gelu"、"relu"、"selu"和"gelu_new"。 - hidden_dropout_prob (
float, optional, 默认为 0.1) — 嵌入层、编码器和池化器中所有全连接层的 dropout 概率。 - attention_probs_dropout_prob (
float, optional, defaults to 0.1) — 注意力概率的丢弃比例。 - max_position_embeddings (
int, optional, 默认为 512) — 此模型可能使用的最大序列长度。通常将其设置为较大的值以防万一(例如,512、1024 或 2048)。 - type_vocab_size (
int, 可选, 默认为 2) — 调用 YosoModel 时传递的token_type_ids的词汇大小. - initializer_range (
float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 - layer_norm_eps (
float, optional, defaults to 1e-12) — 层归一化层使用的epsilon值。 - position_embedding_type (
str, 可选, 默认为"absolute") — 位置嵌入的类型。选择"absolute","relative_key","relative_key_query"中的一个。 - use_expectation (
bool, 可选, 默认为True) — 是否使用YOSO期望。覆盖num_hash的任何效果。 - hash_code_len (
int, 可选, 默认为 9) — 哈希函数生成的哈希值的长度。 - num_hash (
int, 可选, 默认为 64) — 在YosoSelfAttention中使用的哈希函数数量。 - conv_window (
int, optional) — 深度卷积的核大小。 - use_fast_hash (
bool, 可选, 默认为False) — 是否使用自定义的cuda内核,通过哈达玛变换执行快速随机投影。 - lsh_backward (
bool, 可选, 默认为True) — 是否使用局部敏感哈希进行反向传播。
这是用于存储YosoModel配置的配置类。它用于根据指定的参数实例化YOSO模型,定义模型架构。使用默认值实例化配置将产生类似于YOSO uw-madison/yoso-4096架构的配置。
配置对象继承自PretrainedConfig,可用于控制模型输出。阅读PretrainedConfig的文档以获取更多信息。
示例:
>>> from transformers import YosoConfig, YosoModel
>>> # Initializing a YOSO uw-madison/yoso-4096 style configuration
>>> configuration = YosoConfig()
>>> # Initializing a model (with random weights) from the uw-madison/yoso-4096 style configuration
>>> model = YosoModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configYosoModel
类 transformers.YosoModel
< source >( config )
参数
- config (YosoConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的YOSO模型转换器输出原始隐藏状态,没有任何特定的头部。 这个模型是PyTorch torch.nn.Module 的子类。将其用作常规的PyTorch模块,并参考PyTorch文档以获取与一般使用和行为相关的所有事项。
前进
< source >( input_ids: typing.Optional[torch.Tensor] = None attention_mask: typing.Optional[torch.Tensor] = None token_type_ids: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None inputs_embeds: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.BaseModelOutputWithCrossAttentions 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。
返回
transformers.modeling_outputs.BaseModelOutputWithCrossAttentions 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithCrossAttentions 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(YosoConfig)和输入。
-
last_hidden_state (
torch.FloatTensor形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层的隐藏状态序列。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递了output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力softmax后的注意力权重,用于计算自注意力头中的加权平均值。
-
cross_attentions (
tuple(torch.FloatTensor), 可选, 当传递了output_attentions=True和config.add_cross_attention=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。解码器的交叉注意力层的注意力权重,在注意力softmax后,用于计算交叉注意力头中的加权平均值。
YosoModel 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, YosoModel
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("uw-madison/yoso-4096")
>>> model = YosoModel.from_pretrained("uw-madison/yoso-4096")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateYosoForMaskedLM
类 transformers.YosoForMaskedLM
< source >( config )
参数
- config (YosoConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
YOSO 模型顶部带有语言建模头。
该模型是 PyTorch torch.nn.Module 的子类。将其作为常规的 PyTorch 模块使用,并参考 PyTorch 文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.Tensor] = None attention_mask: typing.Optional[torch.Tensor] = None token_type_ids: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None inputs_embeds: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.MaskedLMOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — 用于计算掩码语言建模损失的标签。索引应在[-100, 0, ..., config.vocab_size]范围内(参见input_ids文档字符串)。索引设置为-100的标记将被忽略(掩码), 损失仅针对标签在[0, ..., config.vocab_size]范围内的标记进行计算。
返回
transformers.modeling_outputs.MaskedLMOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.MaskedLMOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(YosoConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 掩码语言建模(MLM)损失。 -
logits (
torch.FloatTensor形状为(batch_size, sequence_length, config.vocab_size)) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
YosoForMaskedLM 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, YosoForMaskedLM
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("uw-madison/yoso-4096")
>>> model = YosoForMaskedLM.from_pretrained("uw-madison/yoso-4096")
>>> inputs = tokenizer("The capital of France is [MASK].", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # retrieve index of [MASK]
>>> mask_token_index = (inputs.input_ids == tokenizer.mask_token_id)[0].nonzero(as_tuple=True)[0]
>>> predicted_token_id = logits[0, mask_token_index].argmax(axis=-1)
>>> labels = tokenizer("The capital of France is Paris.", return_tensors="pt")["input_ids"]
>>> # mask labels of non-[MASK] tokens
>>> labels = torch.where(inputs.input_ids == tokenizer.mask_token_id, labels, -100)
>>> outputs = model(**inputs, labels=labels)YosoForSequenceClassification
类 transformers.YosoForSequenceClassification
< source >( config )
参数
- config (YosoConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
YOSO 模型转换器,顶部带有序列分类/回归头(在池化输出之上的线性层),例如用于 GLUE 任务。 该模型是 PyTorch torch.nn.Module 的子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以了解与一般使用和行为相关的所有事项。
前进
< source >( input_ids: typing.Optional[torch.Tensor] = None attention_mask: typing.Optional[torch.Tensor] = None token_type_ids: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None inputs_embeds: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.SequenceClassifierOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size,), optional) — 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失),如果config.num_labels > 1,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.SequenceClassifierOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.SequenceClassifierOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(YosoConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 分类(或回归,如果 config.num_labels==1)损失。 -
logits (
torch.FloatTensor形状为(batch_size, config.num_labels)) — 分类(或回归,如果 config.num_labels==1)得分(在 SoftMax 之前)。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
YosoForSequenceClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
单标签分类示例:
>>> import torch
>>> from transformers import AutoTokenizer, YosoForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("uw-madison/yoso-4096")
>>> model = YosoForSequenceClassification.from_pretrained("uw-madison/yoso-4096")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_id = logits.argmax().item()
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = YosoForSequenceClassification.from_pretrained("uw-madison/yoso-4096", num_labels=num_labels)
>>> labels = torch.tensor([1])
>>> loss = model(**inputs, labels=labels).loss多标签分类示例:
>>> import torch
>>> from transformers import AutoTokenizer, YosoForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("uw-madison/yoso-4096")
>>> model = YosoForSequenceClassification.from_pretrained("uw-madison/yoso-4096", problem_type="multi_label_classification")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_ids = torch.arange(0, logits.shape[-1])[torch.sigmoid(logits).squeeze(dim=0) > 0.5]
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = YosoForSequenceClassification.from_pretrained(
... "uw-madison/yoso-4096", num_labels=num_labels, problem_type="multi_label_classification"
... )
>>> labels = torch.sum(
... torch.nn.functional.one_hot(predicted_class_ids[None, :].clone(), num_classes=num_labels), dim=1
... ).to(torch.float)
>>> loss = model(**inputs, labels=labels).lossYosoForMultipleChoice
类 transformers.YosoForMultipleChoice
< source >( config )
参数
- config (YosoConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
YOSO 模型,顶部带有多项选择分类头(在池化输出之上的线性层和 softmax),例如用于 RocStories/SWAG 任务。 该模型是 PyTorch torch.nn.Module 的子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以了解与一般使用和行为相关的所有事项。
前进
< source >( input_ids: typing.Optional[torch.Tensor] = None attention_mask: typing.Optional[torch.Tensor] = None token_type_ids: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None inputs_embeds: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.MultipleChoiceModelOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, num_choices, sequence_length)) — Indices of input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
torch.FloatTensorof shape(batch_size, num_choices, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, num_choices, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, num_choices, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, num_choices, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个ModelOutput而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size,), optional) — 用于计算多项选择分类损失的标签。索引应在[0, ..., num_choices-1]范围内,其中num_choices是输入张量第二维的大小。(参见上面的input_ids)
返回
transformers.modeling_outputs.MultipleChoiceModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.MultipleChoiceModelOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(YosoConfig)和输入。
-
loss (
torch.FloatTensor形状为 (1,),可选,当提供labels时返回) — 分类损失。 -
logits (
torch.FloatTensor形状为(batch_size, num_choices)) — num_choices 是输入张量的第二维度。(见上面的 input_ids)。分类分数(在 SoftMax 之前)。
-
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
YosoForMultipleChoice 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, YosoForMultipleChoice
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("uw-madison/yoso-4096")
>>> model = YosoForMultipleChoice.from_pretrained("uw-madison/yoso-4096")
>>> prompt = "In Italy, pizza served in formal settings, such as at a restaurant, is presented unsliced."
>>> choice0 = "It is eaten with a fork and a knife."
>>> choice1 = "It is eaten while held in the hand."
>>> labels = torch.tensor(0).unsqueeze(0) # choice0 is correct (according to Wikipedia ;)), batch size 1
>>> encoding = tokenizer([prompt, prompt], [choice0, choice1], return_tensors="pt", padding=True)
>>> outputs = model(**{k: v.unsqueeze(0) for k, v in encoding.items()}, labels=labels) # batch size is 1
>>> # the linear classifier still needs to be trained
>>> loss = outputs.loss
>>> logits = outputs.logitsYosoForTokenClassification
class transformers.YosoForTokenClassification
< source >( config )
参数
- config (YosoConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
YOSO模型在顶部带有标记分类头(在隐藏状态输出之上的线性层),例如用于命名实体识别(NER)任务。 该模型是PyTorch torch.nn.Module的子类。将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.Tensor] = None attention_mask: typing.Optional[torch.Tensor] = None token_type_ids: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None inputs_embeds: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.TokenClassifierOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将 input_ids 索引转换为相关向量有更多控制权,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — 用于计算令牌分类损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。
返回
transformers.modeling_outputs.TokenClassifierOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.TokenClassifierOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(YosoConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,), 可选, 当提供labels时返回) — 分类损失。 -
logits (
torch.FloatTensor形状为(batch_size, sequence_length, config.num_labels)) — 分类分数(在 SoftMax 之前)。 -
hidden_states (
tuple(torch.FloatTensor), 可选, 当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
YosoForTokenClassification 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, YosoForTokenClassification
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("uw-madison/yoso-4096")
>>> model = YosoForTokenClassification.from_pretrained("uw-madison/yoso-4096")
>>> inputs = tokenizer(
... "HuggingFace is a company based in Paris and New York", add_special_tokens=False, return_tensors="pt"
... )
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_token_class_ids = logits.argmax(-1)
>>> # Note that tokens are classified rather then input words which means that
>>> # there might be more predicted token classes than words.
>>> # Multiple token classes might account for the same word
>>> predicted_tokens_classes = [model.config.id2label[t.item()] for t in predicted_token_class_ids[0]]
>>> labels = predicted_token_class_ids
>>> loss = model(**inputs, labels=labels).lossYosoForQuestionAnswering
类 transformers.YosoForQuestionAnswering
< source >( config )
参数
- config (YosoConfig) — 包含模型所有参数的模型配置类。 使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法以加载模型权重。
YOSO模型,顶部带有跨度分类头,用于抽取式问答任务,如SQuAD(在隐藏状态输出顶部使用线性层来计算span start logits和span end logits)。
该模型是PyTorch torch.nn.Module的子类。将其作为常规的PyTorch模块使用,并参考PyTorch文档以获取与一般使用和行为相关的所有信息。
前进
< source >( input_ids: typing.Optional[torch.Tensor] = None attention_mask: typing.Optional[torch.Tensor] = None token_type_ids: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None inputs_embeds: typing.Optional[torch.Tensor] = None start_positions: typing.Optional[torch.Tensor] = None end_positions: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.QuestionAnsweringModelOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.可以使用AutoTokenizer获取索引。详情请参见PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。
- attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensor形状为(num_heads,)或(num_layers, num_heads), 可选) — 用于屏蔽自注意力模块中选定的头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部 未被屏蔽,
- 0 表示头部 被屏蔽.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — 可选地,您可以选择直接传递嵌入表示,而不是传递input_ids。如果您希望对如何将input_ids索引转换为相关向量有更多控制,而不是使用模型的内部嵌入查找矩阵,这将非常有用。 - output_attentions (
bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量中的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - start_positions (
torch.LongTensorof shape(batch_size,), optional) — 用于计算标记分类损失的标记跨度起始位置(索引)的标签。 位置被限制在序列长度内(sequence_length)。序列之外的位置不会用于计算损失。 - end_positions (
torch.LongTensorof shape(batch_size,), optional) — 用于计算标记分类损失的标记跨度结束位置(索引)的标签。 位置被限制在序列长度内(sequence_length)。序列之外的位置不会用于计算损失。
返回
transformers.modeling_outputs.QuestionAnsweringModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.QuestionAnsweringModelOutput 或一个由
torch.FloatTensor 组成的元组(如果传递了 return_dict=False 或当 config.return_dict=False 时),包含各种
元素,具体取决于配置(YosoConfig)和输入。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 总跨度提取损失是起始和结束位置的交叉熵之和。 -
start_logits (
torch.FloatTensor形状为(batch_size, sequence_length)) — 跨度起始分数(在 SoftMax 之前)。 -
end_logits (
torch.FloatTensor形状为(batch_size, sequence_length)) — 跨度结束分数(在 SoftMax 之前)。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 由torch.FloatTensor组成的元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每一层的输出)形状为(batch_size, sequence_length, hidden_size)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 由torch.FloatTensor组成的元组(每一层一个)形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
YosoForQuestionAnswering 的前向方法,重写了 __call__ 特殊方法。
尽管前向传递的配方需要在此函数内定义,但之后应该调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoTokenizer, YosoForQuestionAnswering
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("uw-madison/yoso-4096")
>>> model = YosoForQuestionAnswering.from_pretrained("uw-madison/yoso-4096")
>>> question, text = "Who was Jim Henson?", "Jim Henson was a nice puppet"
>>> inputs = tokenizer(question, text, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> answer_start_index = outputs.start_logits.argmax()
>>> answer_end_index = outputs.end_logits.argmax()
>>> predict_answer_tokens = inputs.input_ids[0, answer_start_index : answer_end_index + 1]
>>> # target is "nice puppet"
>>> target_start_index = torch.tensor([14])
>>> target_end_index = torch.tensor([15])
>>> outputs = model(**inputs, start_positions=target_start_index, end_positions=target_end_index)
>>> loss = outputs.loss