import pandas as pd
from utilsforecast.plotting import plot_series
from mlforecast import MLForecast # 需要实例化MLForecast对象并使用交叉验证方法 交叉验证
在这个例子中,我们将实现时间序列交叉验证来评估模型的性能。
先决条件
本教程假设您对 MLForecast 有基本的了解。有关最简示例,请访问 快速入门
介绍
时间序列交叉验证是一种评估模型在过去表现的方法。它通过在历史数据上定义一个滑动窗口,并预测其后的时间段来实现。

MLForecast 提供了一种快速且易于使用的时间序列交叉验证实现。这种实现使交叉验证成为高效的操作,从而减少了时间消耗。在本笔记本中,我们将在 M4 Competition 每小时数据集的一个子集上使用它。
大纲:
- 安装库
- 加载和探索数据
- 训练模型
- 执行时间序列交叉验证
- 评估结果
Tip
您可以使用 Colab 以交互方式运行此笔记本 ![]()
安装库
我们假设您已经安装了 MLForecast。如果没有,请查看本指南以获取有关 如何安装 MLForecast 的说明。
使用pip install mlforecast安装必要的包。
加载和探索数据
如介绍中所述,我们将使用M4竞赛的每小时数据集。我们首先将使用pandas从URL导入数据。
Y_df = pd.read_csv('https://datasets-nixtla.s3.amazonaws.com/m4-hourly.csv') # 加载数据
Y_df.head() | unique_id | ds | y | |
|---|---|---|---|
| 0 | H1 | 1 | 605.0 |
| 1 | H1 | 2 | 586.0 |
| 2 | H1 | 3 | 586.0 |
| 3 | H1 | 4 | 559.0 |
| 4 | H1 | 5 | 511.0 |
MLForecast的输入是一个数据框,采用长格式,包含三列:unique_id、ds和y:
unique_id(字符串、整数或类别)表示系列的标识符。ds(日期戳或整数)列应该是一个整数,用于索引时间,或者是格式为YYYY-MM-DD或YYYY-MM-DD HH:MM:SS的日期戳。y(数值型)表示我们希望预测的测量值。
这个例子中的数据已经具备这种格式,因此不需要任何更改。
我们可以使用以下函数绘制我们将使用的时间序列。
fig = plot_series(Y_df, max_ids=4, plot_random=False, max_insample_length=24 * 14)fig.savefig('../../figs/cross_validation__series.png', bbox_inches='tight')
定义预测对象
在这个例子中,我们将使用 LightGBM。我们首先需要导入它,然后需要实例化一个新的 MLForecast 对象。
在这个例子中,我们仅使用 differences 和 lags 来生成特征。请参阅 完整文档 以查看所有可用特征。
所有设置都通过构造函数传入。然后你调用它的 fit 方法,并传入历史数据框 df。
import lightgbm as lgb
from mlforecast.target_transforms import Differencesmodels = [lgb.LGBMRegressor(verbosity=-1)]
mlf = MLForecast(
models=models,
freq=1,# our series have integer timestamps, so we'll just add 1 in every timeste,
target_transforms=[Differences([24])],
lags=range(1, 25)
)执行时间序列交叉验证
一旦 MLForecast 对象被实例化,我们可以使用 cross_validation 方法。
在这个特定的例子中,我们将使用3个24小时的窗口。
cv_df = mlf.cross_validation(
df=Y_df,
h=24,
n_windows=3,
)crossvaldation_df 对象是一个新的数据框,其中包含以下列:
unique_id: 标识每个时间序列。ds: 日期戳或时间索引。cutoff:n_windows的最后日期戳或时间索引。y: 真实值"model": 包含模型名称和拟合值的列。
cv_df.head()| unique_id | ds | cutoff | y | LGBMRegressor | |
|---|---|---|---|---|---|
| 0 | H1 | 677 | 676 | 691.0 | 673.703191 |
| 1 | H1 | 678 | 676 | 618.0 | 552.306270 |
| 2 | H1 | 679 | 676 | 563.0 | 541.778027 |
| 3 | H1 | 680 | 676 | 529.0 | 502.778027 |
| 4 | H1 | 681 | 676 | 504.0 | 480.778027 |
我们现在将绘制每个截断期的预测结果。
import matplotlib.pyplot as pltdef plot_cv(df, df_cv, uid, fname, last_n=24 * 14):
cutoffs = df_cv.query('unique_id == @uid')['cutoff'].unique()
fig, ax = plt.subplots(nrows=len(cutoffs), ncols=1, figsize=(14, 6), gridspec_kw=dict(hspace=0.8))
for cutoff, axi in zip(cutoffs, ax.flat):
df.query('unique_id == @uid').tail(last_n).set_index('ds').plot(ax=axi, title=uid, y='y')
df_cv.query('unique_id == @uid & cutoff == @cutoff').set_index('ds').plot(ax=axi, title=uid, y='LGBMRegressor')
fig.savefig(fname, bbox_inches='tight')
plt.close()plot_cv(Y_df, cv_df, 'H1', '../../figs/cross_validation__predictions.png')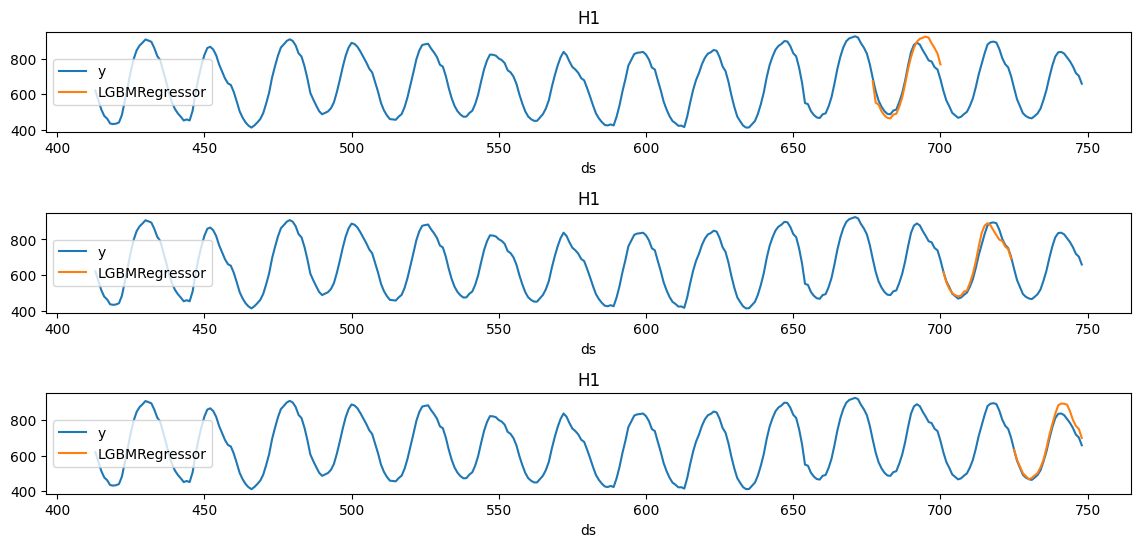
注意,在每个截止期内,我们仅使用该周期之前的数据y生成了接下来24小时的预测。
评估结果
现在我们可以使用适当的准确性指标来计算预测的准确性。在这里我们将使用均方根误差 (RMSE)。为此,我们可以使用 utilsforecast,这是一个由 Nixtla 开发的 Python 库,其中包含计算 RMSE 的函数。
from utilsforecast.evaluation import evaluate
from utilsforecast.losses import rmse cv_rmse = evaluate(
cv_df.drop(columns='cutoff'),
metrics=[rmse],
agg_fn='mean',
)
print(f"RMSE using cross-validation: {cv_rmse['LGBMRegressor'].item():.1f}")RMSE using cross-validation: 269.0该指标应更好地反映我们模型的预测能力,因为它使用了不同的时间段来测试其准确性。
参考文献
Rob J. Hyndman 和 George Athanasopoulos (2018). “预测原理与实践,时间序列交叉验证”。
Give us a ⭐ on Github