# %%capture
# !pip 安装 prophet
# !pip 安装 -U mlforecast
# !pip 安装 -U utilsforecast电力负荷预测
在这个例子中,我们将展示如何使用 MLForecast 和多种模型进行电力负荷预测。我们还将它们与 prophet 库进行比较。
介绍
一些时间序列是从非常低频的数据生成的。这些数据通常表现出多重季节性。例如,按小时的数据可能每小时(每24个观测值)或每天(每24 * 7,每天的小时数,观测值)表现出重复的模式。电力负荷就是这种情况。电力负荷可能每小时变化,例如,在晚上,电力消耗可能会有所增加。但电力负荷也会按周变化。也许在周末,电力活动会增加。
在这个例子中,我们将展示如何建模时间序列的两种季节性,以在短时间内生成准确的预测。我们将使用PJ电力负荷的小时数据。原始数据可以在 此处 找到。
库
在这个示例中,我们将使用以下库:
mlforecast。使用经典机器学习模型进行准确且⚡️快速的预测。prophet。由Facebook开发的基准模型。utilsforecast。提供不同函数用于预测评估的库。
如果您已经安装了库,可以跳过下一个单元;如果没有,请确保运行它。
使用多重季节性进行预测
电力负荷数据
根据数据集页面,
PJM Interconnection LLC (PJM) 是美国的一家区域传输组织(RTO)。它是东部互联电网的一部分,运营着一个电力传输系统,为特拉华州、伊利诺伊州、印度纳州、肯塔基州、马里兰州、密歇根州、新泽西州、北卡罗来纳州、俄亥俄州、宾夕法尼亚州、田纳西州、弗吉尼亚州、西弗吉尼亚州和哥伦比亚特区的全部或部分地区提供服务。每小时的电力消费数据来自PJM的网站,单位为兆瓦(MW)。
让我们来看一下数据。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from utilsforecast.plotting import plot_seriespd.plotting.register_matplotlib_converters()
plt.rc("figure", figsize=(10, 8))
plt.rc("font", size=10)data_url = 'https://raw.githubusercontent.com/panambY/Hourly_Energy_Consumption/master/data/PJM_Load_hourly.csv'
df = pd.read_csv(data_url, parse_dates=['Datetime'])
df.columns = ['ds', 'y']
df.insert(0, 'unique_id', 'PJM_Load_hourly')
df['ds'] = pd.to_datetime(df['ds'])
df = df.sort_values(['unique_id', 'ds']).reset_index(drop=True)
print(f'Shape of the data {df.shape}')
df.tail()Shape of the data (32896, 3)| unique_id | ds | y | |
|---|---|---|---|
| 32891 | PJM_Load_hourly | 2001-12-31 20:00:00 | 36392.0 |
| 32892 | PJM_Load_hourly | 2001-12-31 21:00:00 | 35082.0 |
| 32893 | PJM_Load_hourly | 2001-12-31 22:00:00 | 33890.0 |
| 32894 | PJM_Load_hourly | 2001-12-31 23:00:00 | 32590.0 |
| 32895 | PJM_Load_hourly | 2002-01-01 00:00:00 | 31569.0 |
fig = plot_series(df)fig.savefig('../../figs/load_forecasting__raw.png', bbox_inches='tight')
我们清楚地观察到时间序列呈现出季节性模式。此外,该时间序列包含 32,896 个观测值,因此有必要使用非常高效的计算方法将在生产中显示它们。
我们将对序列进行拆分,以创建训练集和测试集。模型将使用时间序列的最后24小时进行测试。
threshold_time = df['ds'].max() - pd.Timedelta(hours=24)
# 拆分数据框
df_train = df[df['ds'] <= threshold_time]
df_last_24_hours = df[df['ds'] > threshold_time]分析季节性
首先,我们必须可视化模型的季节性。如前所述,电力负荷每24小时(每小时)和每24 * 7(每日)小时呈现季节性。因此,我们将使用 [24, 24 * 7] 作为模型的季节性。为了分析它们如何影响我们的序列,我们将使用 Difference 方法。
from mlforecast import MLForecast
from mlforecast.target_transforms import Differences我们可以使用 MLForecast.preprocess 方法来探索不同的转换。看起来这些序列在每天的时辰上有强烈的季节性,因此我们可以从前一天同一时刻的值中减去它,以消除这种影响。这可以通过 mlforecast.target_transforms.Differences 转换器来实现,我们将其传递给 target_transforms。
为了单独和联合分析趋势,我们将分别和合并绘制它们。因此,我们可以将它们与原始序列进行比较。我们可以使用下一个函数来实现这一点。
def plot_differences(df, differences,fname):
prep = [df]
# 描绘个体差异
for d in differences:
fcst = MLForecast(
models=[], # we're not interested in modeling yet
freq='H', # 我们的系列数据每小时更新一次。
target_transforms=[Differences([d])],
)
df_ = fcst.preprocess(df)
df_['unique_id'] = df_['unique_id'] + f'_{d}'
prep.append(df_)
# Plot combined Differences
fcst = MLForecast(
models=[], # we're not interested in modeling yet
freq='H', # 我们的系列数据每小时更新一次。
target_transforms=[Differences([24, 24*7])],
)
df_ = fcst.preprocess(df)
df_['unique_id'] = df_['unique_id'] + f'_all_diff'
prep.append(df_)
prep = pd.concat(prep, ignore_index=True)
#返回准备
n_series = len(prep['unique_id'].unique())
fig, ax = plt.subplots(nrows=n_series, figsize=(7 * n_series, 10*n_series), squeeze=False)
for title, axi in zip(prep['unique_id'].unique(), ax.flat):
df_ = prep[prep['unique_id'] == title]
df_.set_index('ds')['y'].plot(title=title, ax=axi)
fig.savefig(f'../../figs/{fname}', bbox_inches='tight')
plt.close()由于季节性存在于 24 小时(每日)和 24*7(每周),我们将使用 Differences([24, 24*7]) 从序列中减去它们并绘制。
plot_differences(df=df_train, differences=[24, 24*7], fname='load_forecasting__differences.png')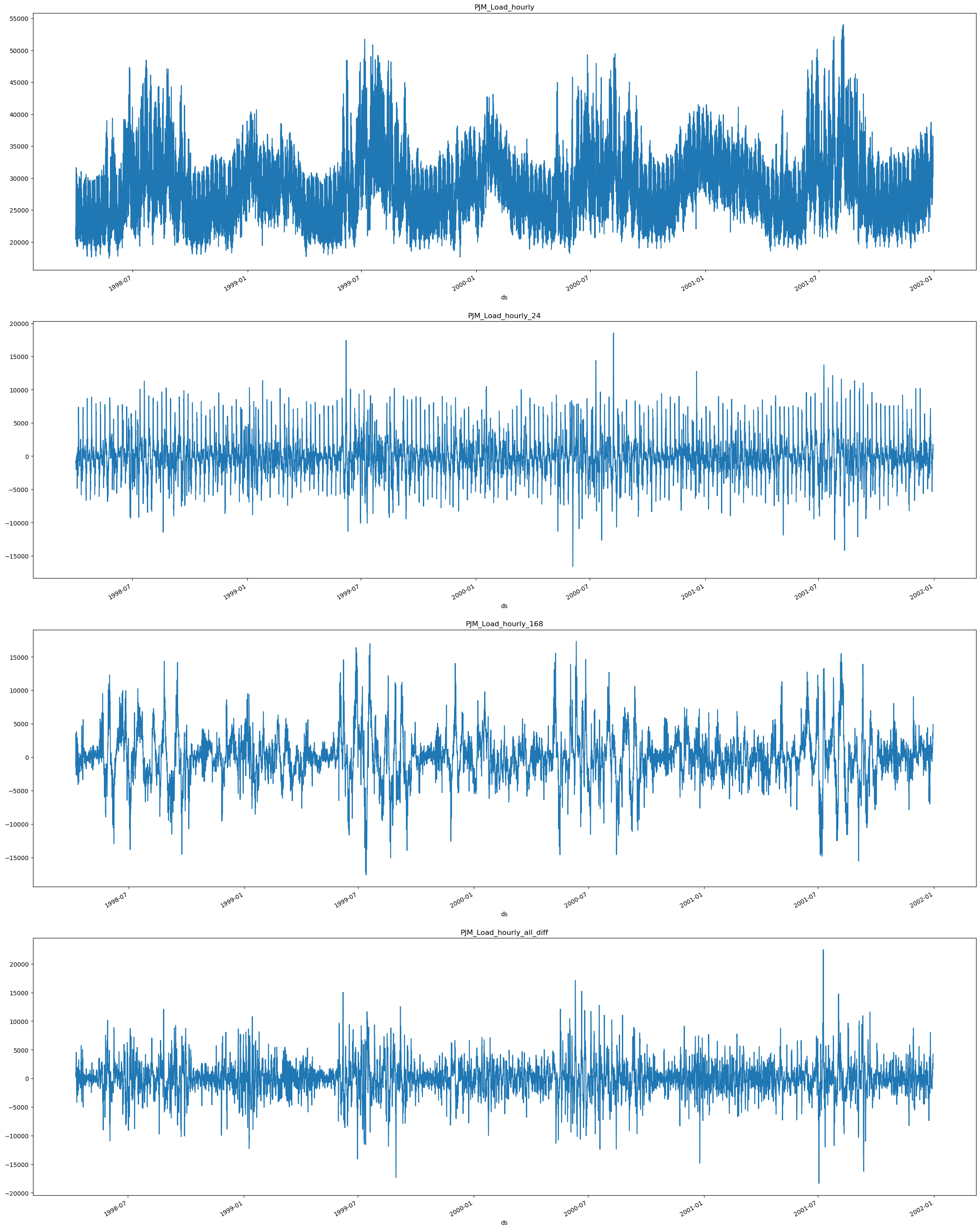
我们可以看到,当我们提取 PJM_Load_hourly_24 的24小时差异(每日差异)时,该系列似乎稳定下来,因为与原始系列 PJM_Load_hourly 相比,峰值看起来更加均匀。
当我们提取24*7(每周) PJM_Load_hourly_168 的差异时,我们可以看到,与原始系列相比,峰值的周期性更强。
最后,我们可以看到通过减去所有差异而得到的组合结果 PJM_Load_hourly_all_diff。
对于建模,我们将使用差分进行预测,因此我们将 MLForecast 对象中的参数 target_transforms 设置为 [Differences([24, 24*7])]。如果我们想要包含年度差分,我们需要添加项 24*365。
fcst = MLForecast(
models=[], # we're not interested in modeling yet
freq='H', # our series have hourly frequency
target_transforms=[Differences([24, 24*7])],
)
prep = fcst.preprocess(df_train)
prep| unique_id | ds | y | |
|---|---|---|---|
| 192 | PJM_Load_hourly | 1998-04-09 02:00:00 | 831.0 |
| 193 | PJM_Load_hourly | 1998-04-09 03:00:00 | 918.0 |
| 194 | PJM_Load_hourly | 1998-04-09 04:00:00 | 760.0 |
| 195 | PJM_Load_hourly | 1998-04-09 05:00:00 | 849.0 |
| 196 | PJM_Load_hourly | 1998-04-09 06:00:00 | 710.0 |
| ... | ... | ... | ... |
| 32867 | PJM_Load_hourly | 2001-12-30 20:00:00 | 3417.0 |
| 32868 | PJM_Load_hourly | 2001-12-30 21:00:00 | 3596.0 |
| 32869 | PJM_Load_hourly | 2001-12-30 22:00:00 | 3501.0 |
| 32870 | PJM_Load_hourly | 2001-12-30 23:00:00 | 3939.0 |
| 32871 | PJM_Load_hourly | 2001-12-31 00:00:00 | 4235.0 |
32680 rows × 3 columns
fig = plot_series(prep)fig.savefig('../../figs/load_forecasting__transformed.png', bbox_inches='tight')![]()
使用交叉验证进行模型选择
我们可以使用 MLForecast 的 cross_validation 同时测试多个模型。我们可以导入 lightgbm 和 scikit-learn 模型,并尝试它们的不同组合,以及之前创建的不同目标变换和历史变量。
您可以在这里查看关于如何使用 MLForecast 交叉验证方法的深入教程。
import lightgbm as lgb
from sklearn.base import BaseEstimator
from sklearn.linear_model import Lasso, LinearRegression, Ridge
from sklearn.neighbors import KNeighborsRegressor
from sklearn.neural_network import MLPRegressor
from sklearn.ensemble import RandomForestRegressor
from mlforecast.lag_transforms import ExpandingMean, RollingMean
from mlforecast.target_transforms import Differences我们可以创建一个基准 Naive 模型,该模型使用最后一个小时的电力负荷作为预测 lag1,如下面的单元格所示。您可以创建自己的模型,并使用相同的结构在 MLForecast 中进行尝试。
class Naive(BaseEstimator):
def fit(self, X, y):
return self
def predict(self, X):
return X['lag1']现在让我们尝试来自 scikit-learn 库的不同模型:Lasso、LinearRegression、Ridge、KNN、MLP 和 Random Forest,以及 LightGBM。您可以通过将它们添加到字典 (models) 中来训练和比较它们,如下所示。
# 模型词典
models ={
'naive': Naive(),
'lgbm': lgb.LGBMRegressor(verbosity=-1),
'lasso': Lasso(),
'lin_reg': LinearRegression(),
'ridge': Ridge(),
'knn': KNeighborsRegressor(),
'mlp': MLPRegressor(),
'rf': RandomForestRegressor()
}
然后我们可以实例化 MLForecast 类,传入我们想要尝试的模型,以及 target_transforms、lags、lag_transforms 和 date_features。所有这些特征都将应用于我们选择的模型。
在这种情况下,我们使用第1个、第12个和第24个滞后,这些值以列表的形式传递。您可以选择传递一个 range。
lags=[1,12,24]滞后变换被定义为一个字典,其中键是滞后期,值是我们希望对该滞后期应用的变换列表。您可以参考滞后变换指南以获取更多详细信息。
为了使用日期特征,您需要确保您的时间列由时间戳组成。然后,提取诸如周、星期几、季度等特征可能是有意义的。您可以通过传递一个包含 pandas 时间/日期组件 的字符串列表来实现。您也可以传递将时间列作为输入的函数,正如我们将在这里展示的那样。
在这里,我们添加了月份、小时和星期几特征:
date_features=['month', 'hour', 'dayofweek']
mlf = MLForecast(
models = models,
freq='H', # 我们的系列数据每小时更新一次
target_transforms=[Differences([24, 24*7])],
lags=[1,12,24], # 用作特征的滞后项
lag_transforms={
1: [ExpandingMean()],
24: [RollingMean(window_size=48)],
},
date_features=['month', 'hour', 'dayofweek']
)
现在我们使用 cross_validation 方法来训练和评估模型。 + df:接收训练数据 + h:预测的时间范围 + n_windows:我们想要预测的折数
您可以指定时间序列 ID、时间和目标列的名称。 + id_col:标识每个序列的列(默认 unique_id) + time_col:标识每个时间步的列,其值可以是时间戳或整数(默认 ds) + target_col:包含目标的列(默认 y)
crossvalidation_df = mlf.cross_validation(
df=df_train,
h=24,
n_windows=4,
refit=False,
)
crossvalidation_df.head()| unique_id | ds | cutoff | y | naive | lgbm | lasso | lin_reg | ridge | knn | mlp | rf | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | PJM_Load_hourly | 2001-12-27 01:00:00 | 2001-12-27 | 28332.0 | 28837.0 | 28526.505572 | 28703.185712 | 28702.625949 | 28702.625956 | 28479.0 | 28660.021947 | 27995.17 |
| 1 | PJM_Load_hourly | 2001-12-27 02:00:00 | 2001-12-27 | 27329.0 | 27969.0 | 27467.860847 | 27693.502318 | 27692.395954 | 27692.395969 | 27521.6 | 27584.635434 | 27112.50 |
| 2 | PJM_Load_hourly | 2001-12-27 03:00:00 | 2001-12-27 | 26986.0 | 27435.0 | 26605.710615 | 26991.795124 | 26990.157567 | 26990.157589 | 26451.6 | 26809.412477 | 26529.72 |
| 3 | PJM_Load_hourly | 2001-12-27 04:00:00 | 2001-12-27 | 27009.0 | 27401.0 | 26284.065138 | 26789.418399 | 26787.262262 | 26787.262291 | 26388.4 | 26523.416348 | 26490.83 |
| 4 | PJM_Load_hourly | 2001-12-27 05:00:00 | 2001-12-27 | 27555.0 | 28169.0 | 26823.617078 | 27369.643789 | 27366.983075 | 27366.983111 | 26779.6 | 26986.355992 | 27180.69 |
现在我们可以绘制每个模型和窗口(折叠),以查看其表现如何。
def plot_cv(df, df_cv, uid, fname, last_n=24 * 14, models={}):
cutoffs = df_cv.query('unique_id == @uid')['cutoff'].unique()
fig, ax = plt.subplots(nrows=len(cutoffs), ncols=1, figsize=(14, 14), gridspec_kw=dict(hspace=0.8))
for cutoff, axi in zip(cutoffs, ax.flat):
max_date = df_cv.query('unique_id == @uid & cutoff == @cutoff')['ds'].max()
df[df['ds'] < max_date].query('unique_id == @uid').tail(last_n).set_index('ds').plot(ax=axi, title=uid, y='y')
for m in models.keys():
df_cv.query('unique_id == @uid & cutoff == @cutoff').set_index('ds').plot(ax=axi, title=uid, y=m)
fig.savefig(f'../../figs/{fname}', bbox_inches='tight')
plt.close()plot_cv(df_train, crossvalidation_df, 'PJM_Load_hourly', 'load_forecasting__predictions.png', models=models)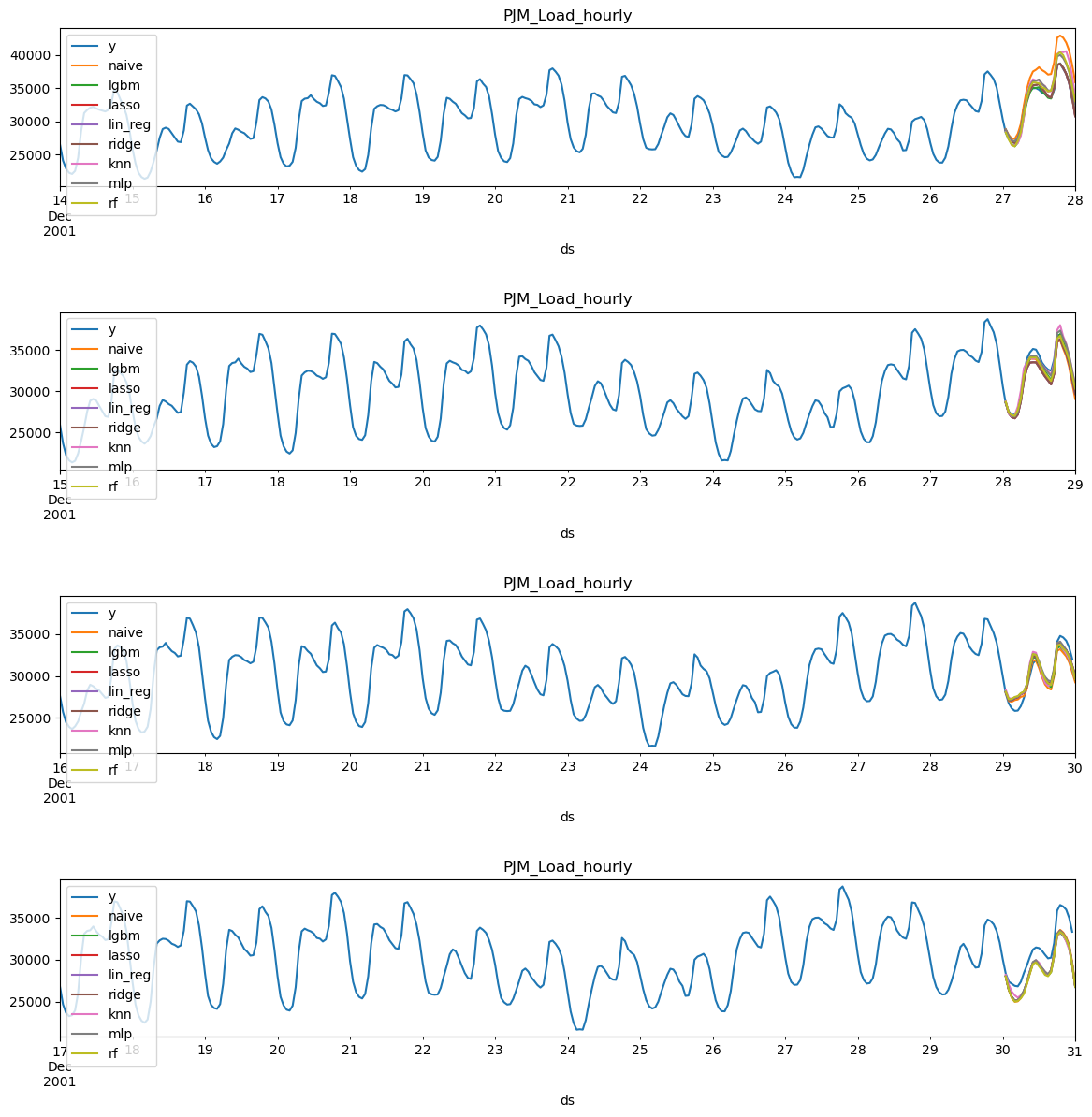
直观地检查预测结果可以让我们对模型的表现有一些了解,但为了评估性能,我们需要通过指标来进行评估。为此,我们使用utilsforecast库,该库包含许多有用的指标和一个评估函数。
from utilsforecast.losses import mae, mape, rmse, smape
from utilsforecast.evaluation import evaluate# 用于评估的指标
metrics = [
mae,
rmse,
mape,
smape
]# 用于评估交叉验证的函数
def evaluate_crossvalidation(crossvalidation_df, metrics, models):
evaluations = []
for c in crossvalidation_df['cutoff'].unique():
df_cv = crossvalidation_df.query('cutoff == @c')
evaluation = evaluate(
df = df_cv,
metrics=metrics,
models=list(models.keys())
)
evaluations.append(evaluation)
evaluations = pd.concat(evaluations, ignore_index=True).drop(columns='unique_id')
evaluations = evaluations.groupby('metric').mean()
return evaluations.style.background_gradient(cmap='RdYlGn_r', axis=1)
evaluate_crossvalidation(crossvalidation_df, metrics, models) | naive | lgbm | lasso | lin_reg | ridge | knn | mlp | rf | |
|---|---|---|---|---|---|---|---|---|
| metric | ||||||||
| mae | 1631.395833 | 971.536200 | 1003.796433 | 1007.998597 | 1007.998547 | 1248.145833 | 1870.547722 | 1017.957813 |
| mape | 0.049759 | 0.030966 | 0.031760 | 0.031888 | 0.031888 | 0.038721 | 0.057504 | 0.032341 |
| rmse | 1871.398919 | 1129.713256 | 1148.616156 | 1153.262719 | 1153.262664 | 1451.964390 | 2102.098238 | 1154.647164 |
| smape | 0.024786 | 0.015886 | 0.016269 | 0.016338 | 0.016338 | 0.019549 | 0.029917 | 0.016563 |
我们可以看到模型 lgbm 在大多数指标上表现最佳,其次是 lasso regression。这两种模型的表现远远优于 naive。
测试评估
现在我们将评估它们在测试集中的表现。我们可以将它们用于预测测试集,并提供一些预测区间。为此,我们可以使用 mlforecast.utils 中的 PredictionIntervals 函数。
您可以在 这里查看 probabilistic forecasting 的深入教程。
from mlforecast.utils import PredictionIntervalsmodels_evaluation ={
'lgbm': lgb.LGBMRegressor(verbosity=-1),
'lasso': Lasso(),
}
mlf_evaluation = MLForecast(
models = models_evaluation,
freq='H', # 我们的系列数据每小时更新一次。
target_transforms=[Differences([24, 24*7])],
lags=[1,12,24],
lag_transforms={
1: [ExpandingMean()],
24: [RollingMean(window_size=48)],
},
date_features=['month', 'hour', 'dayofweek']
)
现在我们准备生成点预测和预测区间。为此,我们将使用 fit 方法,该方法需要以下参数:
df: 长格式的系列数据。id_col: 标识每个系列的列。在我们的例子中,是 unique_id。time_col: 标识每个时间步的列,其值可以是时间戳或整数。在我们的例子中,是 ds。target_col: 包含目标的列。在我们的例子中,是 y。
PredictionIntervals 函数用于计算使用 保序预测 的模型的预测区间。该函数接受以下参数: + n_windows:表示用于校准区间的交叉验证窗口数量 + h:预测时间范围
mlf_evaluation.fit(
df = df_train,
prediction_intervals=PredictionIntervals(n_windows=4, h=24)
)MLForecast(models=[lgbm, lasso], freq=H, lag_features=['lag1', 'lag12', 'lag24', 'expanding_mean_lag1', 'rolling_mean_lag24_window_size48'], date_features=['month', 'hour', 'dayofweek'], num_threads=1)现在模型已经训练完成,我们将使用 predict 方法预测接下来的24小时,以便与我们的 test 数据进行比较。此外,我们还将创建 levels 为 [90,95] 的预测区间。
levels = [90, 95] # 预测区间的水平
forecasts = mlf_evaluation.predict(24, level=levels)
forecasts.head()| unique_id | ds | lgbm | lasso | lgbm-lo-95 | lgbm-lo-90 | lgbm-hi-90 | lgbm-hi-95 | lasso-lo-95 | lasso-lo-90 | lasso-hi-90 | lasso-hi-95 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | PJM_Load_hourly | 2001-12-31 01:00:00 | 28847.573176 | 29124.085976 | 28544.593464 | 28567.603130 | 29127.543222 | 29150.552888 | 28762.752269 | 28772.604275 | 29475.567677 | 29485.419682 |
| 1 | PJM_Load_hourly | 2001-12-31 02:00:00 | 27862.589195 | 28365.330749 | 27042.311414 | 27128.839888 | 28596.338503 | 28682.866977 | 27528.548959 | 27619.065224 | 29111.596275 | 29202.112539 |
| 2 | PJM_Load_hourly | 2001-12-31 03:00:00 | 27044.418960 | 27712.161676 | 25596.659896 | 25688.230426 | 28400.607493 | 28492.178023 | 26236.955369 | 26338.087102 | 29086.236251 | 29187.367984 |
| 3 | PJM_Load_hourly | 2001-12-31 04:00:00 | 26976.104125 | 27661.572733 | 25249.961527 | 25286.024722 | 28666.183529 | 28702.246724 | 25911.133521 | 25959.815715 | 29363.329750 | 29412.011944 |
| 4 | PJM_Load_hourly | 2001-12-31 05:00:00 | 26694.246238 | 27393.922370 | 25044.220845 | 25051.548832 | 28336.943644 | 28344.271631 | 25751.547897 | 25762.524815 | 29025.319924 | 29036.296843 |
predict 方法返回一个 DataFrame,其中包含每个模型(lasso 和 lgbm)的预测结果以及预测阈值。高阈值用关键词 hi 表示,低阈值用关键词 lo 表示,列名称中的数字表示级别。
test = df_last_24_hours.merge(forecasts, how='left', on=['unique_id', 'ds'])
test.head()| unique_id | ds | y | lgbm | lasso | lgbm-lo-95 | lgbm-lo-90 | lgbm-hi-90 | lgbm-hi-95 | lasso-lo-95 | lasso-lo-90 | lasso-hi-90 | lasso-hi-95 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | PJM_Load_hourly | 2001-12-31 01:00:00 | 29001.0 | 28847.573176 | 29124.085976 | 28544.593464 | 28567.603130 | 29127.543222 | 29150.552888 | 28762.752269 | 28772.604275 | 29475.567677 | 29485.419682 |
| 1 | PJM_Load_hourly | 2001-12-31 02:00:00 | 28138.0 | 27862.589195 | 28365.330749 | 27042.311414 | 27128.839888 | 28596.338503 | 28682.866977 | 27528.548959 | 27619.065224 | 29111.596275 | 29202.112539 |
| 2 | PJM_Load_hourly | 2001-12-31 03:00:00 | 27830.0 | 27044.418960 | 27712.161676 | 25596.659896 | 25688.230426 | 28400.607493 | 28492.178023 | 26236.955369 | 26338.087102 | 29086.236251 | 29187.367984 |
| 3 | PJM_Load_hourly | 2001-12-31 04:00:00 | 27874.0 | 26976.104125 | 27661.572733 | 25249.961527 | 25286.024722 | 28666.183529 | 28702.246724 | 25911.133521 | 25959.815715 | 29363.329750 | 29412.011944 |
| 4 | PJM_Load_hourly | 2001-12-31 05:00:00 | 28427.0 | 26694.246238 | 27393.922370 | 25044.220845 | 25051.548832 | 28336.943644 | 28344.271631 | 25751.547897 | 25762.524815 | 29025.319924 | 29036.296843 |
现在我们可以评估test集中的指标和性能。
evaluate(
df = test,
metrics=metrics,
models=list(models_evaluation.keys())
)| unique_id | metric | lgbm | lasso | |
|---|---|---|---|---|
| 0 | PJM_Load_hourly | mae | 1092.050817 | 899.979743 |
| 1 | PJM_Load_hourly | rmse | 1340.422762 | 1163.695525 |
| 2 | PJM_Load_hourly | mape | 0.033600 | 0.027688 |
| 3 | PJM_Load_hourly | smape | 0.017137 | 0.013812 |
我们可以看到,lasso 回归在测试集上的表现略优于 LightGBM。此外,我们还可以将预测结果及其预测区间进行绘图。为此,我们可以使用 utilsforecast.plotting 中提供的 plot_series 方法。
我们可以同时绘制一个或多个模型及其置信区间。
fig = plot_series(
df_train,
test,
models=['lasso', 'lgbm'],
plot_random=False,
level=levels,
max_insample_length=24
)fig.savefig(f'../../figs/load_forecasting__prediction_intervals.png', bbox_inches='tight')
与Prophet的比较
最广泛使用的时间序列预测模型之一是Prophet。该模型以能够建模不同季节性(每周、每日和每年)而闻名。我们将使用该模型作为基准,以查看lgbm与MLForecast是否为这个时间序列带来了额外的价值。
# 禁用 cmdstanpy 日志记录
import logging
logger = logging.getLogger('cmdstanpy')
logger.addHandler(logging.NullHandler())
logger.propagate = False
logger.setLevel(logging.CRITICAL)from prophet import Prophet
from time import timeImporting plotly failed. Interactive plots will not work.# 创建先知模型
prophet = Prophet(interval_width=0.9)
init = time()
prophet.fit(df_train)
# 生成预测
future = prophet.make_future_dataframe(periods=len(df_last_24_hours), freq='H', include_history=False)
forecast_prophet = prophet.predict(future)
end = time()
# 数据整理
forecast_prophet = forecast_prophet[['ds', 'yhat', 'yhat_lower', 'yhat_upper']]
forecast_prophet.columns = ['ds', 'Prophet', 'Prophet-lo-90', 'Prophet-hi-90']
forecast_prophet.insert(0, 'unique_id', 'PJM_Load_hourly')
forecast_prophet.head()| unique_id | ds | Prophet | Prophet-lo-90 | Prophet-hi-90 | |
|---|---|---|---|---|---|
| 0 | PJM_Load_hourly | 2001-12-31 01:00:00 | 25333.448442 | 20589.873559 | 30370.174820 |
| 1 | PJM_Load_hourly | 2001-12-31 02:00:00 | 24039.925936 | 18927.503487 | 29234.930903 |
| 2 | PJM_Load_hourly | 2001-12-31 03:00:00 | 23363.998793 | 18428.462513 | 28292.424622 |
| 3 | PJM_Load_hourly | 2001-12-31 04:00:00 | 23371.799609 | 18206.273446 | 28181.023448 |
| 4 | PJM_Load_hourly | 2001-12-31 05:00:00 | 24146.468610 | 19356.171497 | 29006.546759 |
time_prophet = (end - init)
print(f'Prophet Time: {time_prophet:.2f} seconds')Prophet Time: 18.00 secondsmodels_comparison ={
'lgbm': lgb.LGBMRegressor(verbosity=-1)
}
mlf_comparison = MLForecast(
models = models_comparison,
freq='H', # 我们的系列数据每小时更新一次。
target_transforms=[Differences([24, 24*7])],
lags=[1,12,24],
lag_transforms={
1: [ExpandingMean()],
24: [RollingMean(window_size=48)],
},
date_features=['month', 'hour', 'dayofweek']
)
init = time()
mlf_comparison.fit(
df = df_train,
prediction_intervals=PredictionIntervals(n_windows=4, h=24)
)
levels = [90]
forecasts_comparison = mlf_comparison.predict(24, level=levels)
end = time()
forecasts_comparison.head()| unique_id | ds | lgbm | lgbm-lo-90 | lgbm-hi-90 | |
|---|---|---|---|---|---|
| 0 | PJM_Load_hourly | 2001-12-31 01:00:00 | 28847.573176 | 28567.603130 | 29127.543222 |
| 1 | PJM_Load_hourly | 2001-12-31 02:00:00 | 27862.589195 | 27128.839888 | 28596.338503 |
| 2 | PJM_Load_hourly | 2001-12-31 03:00:00 | 27044.418960 | 25688.230426 | 28400.607493 |
| 3 | PJM_Load_hourly | 2001-12-31 04:00:00 | 26976.104125 | 25286.024722 | 28666.183529 |
| 4 | PJM_Load_hourly | 2001-12-31 05:00:00 | 26694.246238 | 25051.548832 | 28336.943644 |
time_lgbm = (end - init)
print(f'LGBM Time: {time_lgbm:.2f} seconds')LGBM Time: 0.86 secondsmetrics_comparison = df_last_24_hours.merge(forecasts_comparison, how='left', on=['unique_id', 'ds']).merge(
forecast_prophet, how='left', on=['unique_id', 'ds'])
metrics_comparison = evaluate(
df = metrics_comparison,
metrics=metrics,
models=['Prophet', 'lgbm']
)
metrics_comparison.reset_index(drop=True).style.background_gradient(cmap='RdYlGn_r', axis=1)| unique_id | metric | Prophet | lgbm | |
|---|---|---|---|---|
| 0 | PJM_Load_hourly | mae | 2266.561642 | 1092.050817 |
| 1 | PJM_Load_hourly | rmse | 2701.302779 | 1340.422762 |
| 2 | PJM_Load_hourly | mape | 0.073226 | 0.033600 |
| 3 | PJM_Load_hourly | smape | 0.038320 | 0.017137 |
正如我们所看到的,lgbm的指标始终优于prophet。
metrics_comparison['improvement'] = metrics_comparison['Prophet'] / metrics_comparison['lgbm']
metrics_comparison['improvement'] = metrics_comparison['improvement'].apply(lambda x: f'{x:.2f}')
metrics_comparison.set_index('metric')[['improvement']]| improvement | |
|---|---|
| metric | |
| mae | 2.08 |
| rmse | 2.02 |
| mape | 2.18 |
| smape | 2.24 |
print(f'lgbm with MLForecast has a speedup of {time_prophet/time_lgbm:.2f} compared with prophet')lgbm with MLForecast has a speedup of 20.95 compared with prophet我们可以看到,使用 MLForecast 的 lgbm 提供的指标至少是 Prophet 的两倍,如上面的 improvement 列所示,而且速度更快。
Give us a ⭐ on Github