%load_ext autoreload
%autoreload 2MLForecast
完整的管道封装
import copy
import re
import warnings
from pathlib import Path
from typing import TYPE_CHECKING, Callable, Dict, Iterable, List, Optional, Tuple, Union
import cloudpickle
import fsspec
import numpy as np
import utilsforecast.processing as ufp
from sklearn.base import BaseEstimator, clone
from utilsforecast.compat import DFType, DataFrame
from mlforecast.core import (
DateFeature,
Freq,
LagTransforms,
Lags,
Models,
TargetTransform,
TimeSeries,
_name_models,
_get_model_name,
)
from mlforecast.grouped_array import GroupedArray
if TYPE_CHECKING:
from mlforecast.lgb_cv import LightGBMCV
from mlforecast.target_transforms import _BaseGroupedArrayTargetTransform
from mlforecast.utils import PredictionIntervalsimport pandas as pd
from fastcore.test import test_warns, test_eq, test_ne, test_fail, test_close
from nbdev import show_doc
from sklearn import set_configset_config(display='text')
warnings.simplefilter('ignore', UserWarning)def _add_conformal_distribution_intervals(
fcst_df: DFType,
cs_df: DFType,
model_names: List[str],
level: List[Union[int, float]],
cs_n_windows: int,
cs_h: int,
n_series: int,
horizon: int,
) -> DFType:
"""
Adds conformal intervals to a `fcst_df` based on conformal scores `cs_df`.
`level` should be already sorted. This strategy creates forecasts paths
based on errors and calculate quantiles using those paths.
"""
fcst_df = ufp.copy_if_pandas(fcst_df, deep=False)
alphas = [100 - lv for lv in level]
cuts = [alpha / 200 for alpha in reversed(alphas)]
cuts.extend(1 - alpha / 200 for alpha in alphas)
for model in model_names:
scores = cs_df[model].to_numpy().reshape(cs_n_windows, n_series, cs_h)
# 将分数限制在水平范围内
scores = scores[:,:,:horizon]
mean = fcst_df[model].to_numpy().reshape(1, n_series, -1)
scores = np.vstack([mean - scores, mean + scores])
quantiles = np.quantile(
scores,
cuts,
axis=0,
)
quantiles = quantiles.reshape(len(cuts), -1).T
lo_cols = [f"{model}-lo-{lv}" for lv in reversed(level)]
hi_cols = [f"{model}-hi-{lv}" for lv in level]
out_cols = lo_cols + hi_cols
fcst_df = ufp.assign_columns(fcst_df, out_cols, quantiles)
return fcst_dfdef _add_conformal_error_intervals(
fcst_df: DFType,
cs_df: DFType,
model_names: List[str],
level: List[Union[int, float]],
cs_n_windows: int,
cs_h: int,
n_series: int,
horizon: int,
) -> DFType:
"""
根据`cs_df`中的置信分数,为`fcst_df`添加符合条件的区间。`level`应已排序。此策略基于绝对误差创建预测区间。
"""
fcst_df = ufp.copy_if_pandas(fcst_df, deep=False)
cuts = [lv / 100 for lv in level]
for model in model_names:
mean = fcst_df[model].to_numpy().ravel()
scores = cs_df[model].to_numpy().reshape(cs_n_windows, n_series, cs_h)
# 将分数限制在水平范围内
scores = scores[:,:,:horizon]
quantiles = np.quantile(
scores,
cuts,
axis=0,
)
quantiles = quantiles.reshape(len(cuts), -1)
lo_cols = [f"{model}-lo-{lv}" for lv in reversed(level)]
hi_cols = [f"{model}-hi-{lv}" for lv in level]
quantiles = np.vstack([mean - quantiles[::-1], mean + quantiles]).T
columns = lo_cols + hi_cols
fcst_df = ufp.assign_columns(fcst_df, columns, quantiles)
return fcst_dfdef _get_conformal_method(method: str):
available_methods = {
'conformal_distribution': _add_conformal_distribution_intervals,
'conformal_error': _add_conformal_error_intervals,
}
if method not in available_methods.keys():
raise ValueError(
f'prediction intervals method {method} not supported '
f'please choose one of {", ".join(available_methods.keys())}'
)
return available_methods[method]test_fail(lambda: _get_conformal_method('my_method'))class MLForecast:
def __init__(
self,
models: Models,
freq: Freq,
lags: Optional[Lags] = None,
lag_transforms: Optional[LagTransforms] = None,
date_features: Optional[Iterable[DateFeature]] = None,
num_threads: int = 1,
target_transforms: Optional[List[TargetTransform]] = None,
lag_transforms_namer: Optional[Callable] = None,
):
"""Forecasting pipeline
Parameters
----------
models : regressor or list of regressors
Models that will be trained and used to compute the forecasts.
freq : str or int or pd.offsets.BaseOffset
Pandas offset, pandas offset alias, e.g. 'D', 'W-THU' or integer denoting the frequency of the series.
lags : list of int, optional (default=None)
Lags of the target to use as features.
lag_transforms : dict of int to list of functions, optional (default=None)
Mapping of target lags to their transformations.
date_features : list of str or callable, optional (default=None)
Features computed from the dates. Can be pandas date attributes or functions that will take the dates as input.
num_threads : int (default=1)
Number of threads to use when computing the features.
target_transforms : list of transformers, optional(default=None)
Transformations that will be applied to the target before computing the features and restored after the forecasting step.
lag_transforms_namer : callable, optional(default=None)
Function that takes a transformation (either function or class), a lag and extra arguments and produces a name.
"""
if not isinstance(models, dict) and not isinstance(models, list):
models = [models]
if isinstance(models, list):
model_names = _name_models([_get_model_name(m) for m in models])
models_with_names = dict(zip(model_names, models))
else:
models_with_names = models
self.models = models_with_names
self.ts = TimeSeries(
freq=freq,
lags=lags,
lag_transforms=lag_transforms,
date_features=date_features,
num_threads=num_threads,
target_transforms=target_transforms,
lag_transforms_namer=lag_transforms_namer,
)
def __repr__(self):
return (
f'{self.__class__.__name__}(models=[{", ".join(self.models.keys())}], '
f'freq={self.freq}, '
f'lag_features={list(self.ts.transforms.keys())}, '
f'date_features={self.ts.date_features}, '
f'num_threads={self.ts.num_threads})'
)
@property
def freq(self):
return self.ts.freq
@classmethod
def from_cv(cls, cv: 'LightGBMCV') -> 'MLForecast':
if not hasattr(cv, 'best_iteration_'):
raise ValueError('LightGBMCV object must be fitted first.')
import lightgbm as lgb
fcst = cls(
models=lgb.LGBMRegressor(**{**cv.params, 'n_estimators': cv.best_iteration_}),
freq=cv.ts.freq,
)
fcst.ts = copy.deepcopy(cv.ts)
return fcst
def preprocess(
self,
df: DFType,
id_col: str = 'unique_id',
time_col: str = 'ds',
target_col: str = 'y',
static_features: Optional[List[str]] = None,
dropna: bool = True,
keep_last_n: Optional[int] = None,
max_horizon: Optional[int] = None,
return_X_y: bool = False,
as_numpy: bool = False,
) -> Union[DFType, Tuple[DFType, np.ndarray]]:
"""Add the features to `data`.
Parameters
----------
df : pandas DataFrame
Series data in long format.
id_col : str (default='unique_id')
Column that identifies each serie.
time_col : str (default='ds')
Column that identifies each timestep, its values can be timestamps or integers.
target_col : str (default='y')
Column that contains the target.
static_features : list of str, optional (default=None)
Names of the features that are static and will be repeated when forecasting.
dropna : bool (default=True)
Drop rows with missing values produced by the transformations.
keep_last_n : int, optional (default=None)
Keep only these many records from each serie for the forecasting step. Can save time and memory if your features allow it.
max_horizon : int, optional (default=None)
Train this many models, where each model will predict a specific horizon.
return_X_y : bool (default=False)
Return a tuple with the features and the target. If False will return a single dataframe.
as_numpy : bool (default = False)
Cast features to numpy array. Only works for `return_X_y=True`.
Returns
-------
result : DataFrame or tuple of pandas Dataframe and a numpy array.
`df` plus added features and target(s).
"""
return self.ts.fit_transform(
df,
id_col=id_col,
time_col=time_col,
target_col=target_col,
static_features=static_features,
dropna=dropna,
keep_last_n=keep_last_n,
max_horizon=max_horizon,
return_X_y=return_X_y,
as_numpy=as_numpy,
)
def fit_models(
self,
X: Union[DataFrame, np.ndarray],
y: np.ndarray,
) -> 'MLForecast':
"""Manually train models. Use this if you called `MLForecast.preprocess` beforehand.
Parameters
----------
X : pandas or polars DataFrame or numpy array
Features.
y : numpy array.
Target.
Returns
-------
self : MLForecast
Forecast object with trained models.
"""
self.models_: Dict[str, Union[BaseEstimator, List[BaseEstimator]]] = {}
for name, model in self.models.items():
if y.ndim == 2 and y.shape[1] > 1:
self.models_[name] = []
for col in range(y.shape[1]):
keep = ~np.isnan(y[:, col])
if isinstance(X, np.ndarray):
# 待办事项:迁移至工具库
Xh = X[keep]
else:
Xh = ufp.filter_with_mask(X, keep)
yh = y[keep, col]
self.models_[name].append(clone(model).fit(Xh, yh))
else:
self.models_[name] = clone(model).fit(X, y)
return self
def _conformity_scores(
self,
df: DFType,
id_col: str,
time_col: str,
target_col: str,
static_features: Optional[List[str]] = None,
dropna: bool = True,
keep_last_n: Optional[int] = None,
max_horizon: Optional[int] = None,
n_windows: int = 2,
h: int = 1,
as_numpy: bool = False,
) -> DFType:
"""Compute conformity scores.
We need at least two cross validation errors to compute
quantiles for prediction intervals (`n_windows=2`).
The exception is raised by the PredictionIntervals data class.
In this simplest case, we assume the width of the interval
is the same for all the forecasting horizon (`h=1`).
"""
min_size = ufp.counts_by_id(df, id_col)['counts'].min()
min_samples = h * n_windows + 1
if min_size < min_samples:
raise ValueError(
"Minimum required samples in each serie for the prediction intervals "
f"settings are: {min_samples}, shortest serie has: {min_size}. "
"Please reduce the number of windows, horizon or remove those series."
)
cv_results = self.cross_validation(
df=df,
n_windows=n_windows,
h=h,
refit=False,
id_col=id_col,
time_col=time_col,
target_col=target_col,
static_features=static_features,
dropna=dropna,
keep_last_n=keep_last_n,
max_horizon=max_horizon,
prediction_intervals=None,
as_numpy=as_numpy,
)
# 每个模型的符合度评分
for model in self.models.keys():
# 计算每个模型的绝对误差
abs_err = abs(cv_results[model] - cv_results[target_col])
cv_results = ufp.assign_columns(cv_results, model, abs_err)
return ufp.drop_columns(cv_results, target_col)
def _invert_transforms_fitted(self, df: DFType) -> DFType:
if self.ts.target_transforms is None:
return df
if any(isinstance(tfm, _BaseGroupedArrayTargetTransform) for tfm in self.ts.target_transforms):
model_cols = [c for c in df.columns if c not in (self.ts.id_col, self.ts.time_col)]
id_counts = ufp.counts_by_id(df, self.ts.id_col)
sizes = id_counts['counts'].to_numpy()
indptr = np.append(0, sizes.cumsum())
for tfm in self.ts.target_transforms[::-1]:
if isinstance(tfm, _BaseGroupedArrayTargetTransform):
if self.ts._dropped_series is not None:
idxs = np.delete(np.arange(self.ts.ga.n_groups), self.ts._dropped_series)
tfm = tfm.take(idxs)
for col in model_cols:
ga = GroupedArray(df[col].to_numpy(), indptr)
ga = tfm.inverse_transform_fitted(ga)
df = ufp.assign_columns(df, col, ga.data)
else:
df = tfm.inverse_transform(df)
return df
def _extract_X_y(
self,
prep: DFType,
target_col: str,
) -> Tuple[Union[DFType, np.ndarray], np.ndarray]:
X = prep[self.ts.features_order_]
targets = [c for c in prep.columns if re.match(rf'^{target_col}\d*$', c)]
if len(targets) == 1:
targets = targets[0]
y = prep[targets].to_numpy()
return X, y
def _compute_fitted_values(
self,
base: DFType,
X: Union[DFType, np.ndarray],
y: np.ndarray,
id_col: str,
time_col: str,
target_col: str,
max_horizon: Optional[int],
) -> DFType:
base = ufp.copy_if_pandas(base, deep=False)
sort_idxs = ufp.maybe_compute_sort_indices(base, id_col, time_col)
if sort_idxs is not None:
base = ufp.take_rows(base, sort_idxs)
X = ufp.take_rows(X, sort_idxs)
y = y[sort_idxs]
if max_horizon is None:
fitted_values = ufp.assign_columns(base, target_col, y)
for name, model in self.models_.items():
assert not isinstance(model, list) # mypy
preds = model.predict(X)
fitted_values = ufp.assign_columns(fitted_values, name, preds)
fitted_values = self._invert_transforms_fitted(fitted_values)
else:
horizon_fitted_values = []
for horizon in range(max_horizon):
horizon_base = ufp.copy_if_pandas(base, deep=True)
horizon_base = ufp.assign_columns(horizon_base, target_col, y[:, horizon])
horizon_fitted_values.append(horizon_base)
for name, horizon_models in self.models_.items():
for horizon, model in enumerate(horizon_models):
preds = model.predict(X)
horizon_fitted_values[horizon] = ufp.assign_columns(
horizon_fitted_values[horizon], name, preds
)
for horizon, horizon_df in enumerate(horizon_fitted_values):
keep_mask = ~ufp.is_nan(horizon_df[target_col])
horizon_df = ufp.filter_with_mask(horizon_df, keep_mask)
horizon_df = ufp.copy_if_pandas(horizon_df, deep=True)
horizon_df = self._invert_transforms_fitted(horizon_df)
horizon_df = ufp.assign_columns(horizon_df, 'h', horizon + 1)
horizon_fitted_values[horizon] = horizon_df
fitted_values = ufp.vertical_concat(horizon_fitted_values, match_categories=False)
if self.ts.target_transforms is not None:
for tfm in self.ts.target_transforms[::-1]:
if hasattr(tfm, 'store_fitted'):
tfm.store_fitted = False
if hasattr(tfm, 'fitted_'):
tfm.fitted_ = []
return fitted_values
def fit(
self,
df: DataFrame,
id_col: str = 'unique_id',
time_col: str = 'ds',
target_col: str = 'y',
static_features: Optional[List[str]] = None,
dropna: bool = True,
keep_last_n: Optional[int] = None,
max_horizon: Optional[int] = None,
prediction_intervals: Optional[PredictionIntervals] = None,
fitted: bool = False,
as_numpy: bool = False,
) -> 'MLForecast':
"""Apply the feature engineering and train the models.
Parameters
----------
df : pandas or polars DataFrame
Series data in long format.
id_col : str (default='unique_id')
Column that identifies each serie.
time_col : str (default='ds')
Column that identifies each timestep, its values can be timestamps or integers.
target_col : str (default='y')
Column that contains the target.
static_features : list of str, optional (default=None)
Names of the features that are static and will be repeated when forecasting.
If `None`, will consider all columns (except id_col and time_col) as static.
dropna : bool (default=True)
Drop rows with missing values produced by the transformations.
keep_last_n : int, optional (default=None)
Keep only these many records from each serie for the forecasting step. Can save time and memory if your features allow it.
max_horizon : int, optional (default=None)
Train this many models, where each model will predict a specific horizon.
prediction_intervals : PredictionIntervals, optional (default=None)
Configuration to calibrate prediction intervals (Conformal Prediction).
fitted : bool (default=False)
Save in-sample predictions.
as_numpy : bool (default = False)
Cast features to numpy array.
Returns
-------
self : MLForecast
Forecast object with series values and trained models.
"""
if fitted and self.ts.target_transforms is not None:
for tfm in self.ts.target_transforms:
if hasattr(tfm, 'store_fitted'):
tfm.store_fitted = True
self._cs_df: Optional[DataFrame] = None
if prediction_intervals is not None:
self.prediction_intervals = prediction_intervals
self._cs_df = self._conformity_scores(
df=df,
id_col=id_col,
time_col=time_col,
target_col=target_col,
static_features=static_features,
dropna=dropna,
keep_last_n=keep_last_n,
n_windows=prediction_intervals.n_windows,
h=prediction_intervals.h,
as_numpy=as_numpy,
)
prep = self.preprocess(
df=df,
id_col=id_col,
time_col=time_col,
target_col=target_col,
static_features=static_features,
dropna=dropna,
keep_last_n=keep_last_n,
max_horizon=max_horizon,
return_X_y=not fitted,
as_numpy=as_numpy,
)
if isinstance(prep, tuple):
X, y = prep
else:
base = prep[[id_col, time_col]]
X, y = self._extract_X_y(prep, target_col)
if as_numpy:
X = ufp.to_numpy(X)
del prep
self.fit_models(X, y)
if fitted:
fitted_values = self._compute_fitted_values(
base=base,
X=X,
y=y,
id_col=id_col,
time_col=time_col,
target_col=target_col,
max_horizon=max_horizon,
)
fitted_values = ufp.drop_index_if_pandas(fitted_values)
self.fcst_fitted_values_ = fitted_values
return self
def forecast_fitted_values(self, level: Optional[List[Union[int, float]]] = None) -> DataFrame:
"""Access in-sample predictions.
Parameters
----------
level : list of ints or floats, optional (default=None)
Confidence levels between 0 and 100 for prediction intervals.
Returns
-------
pandas or polars DataFrame
Dataframe with predictions for the training set
"""
if not hasattr(self, 'fcst_fitted_values_'):
raise Exception('Please run the `fit` method using `fitted=True`')
res = self.fcst_fitted_values_
if level is not None:
res = ufp.add_insample_levels(
res,
models=list(self.models_.keys()),
level=level,
id_col=self.ts.id_col,
target_col=self.ts.target_col,
)
return res
def make_future_dataframe(self, h: int) -> DataFrame:
"""Create a dataframe with all ids and future times in the forecasting horizon.
Parameters
----------
h : int
Number of periods to predict.
Returns
-------
pandas or polars DataFrame
DataFrame with expected ids and future times
"""
if not hasattr(self.ts, 'id_col'):
raise ValueError('You must call fit first')
return ufp.make_future_dataframe(
uids=self.ts.uids,
last_times=self.ts.last_dates,
freq=self.freq,
h=h,
id_col=self.ts.id_col,
time_col=self.ts.time_col,
)
def get_missing_future(self, h: int, X_df: DFType) -> DFType:
"""Get the missing id and time combinations in `X_df`.
Parameters
----------
h : int
Number of periods to predict.
X_df : pandas or polars DataFrame, optional (default=None)
Dataframe with the future exogenous features. Should have the id column and the time column.
Returns
-------
pandas or polars DataFrame
DataFrame with expected ids and future times missing in `X_df`
"""
expected = self.make_future_dataframe(h=h)
ids = [self.ts.id_col, self.ts.time_col]
return ufp.anti_join(expected, X_df[ids], on=ids)
def predict(
self,
h: int,
before_predict_callback: Optional[Callable] = None,
after_predict_callback: Optional[Callable] = None,
new_df: Optional[DFType] = None,
level: Optional[List[Union[int, float]]] = None,
X_df: Optional[DFType] = None,
ids: Optional[List[str]] = None,
) -> DFType:
"""Compute the predictions for the next `h` steps.
Parameters
----------
h : int
Number of periods to predict.
before_predict_callback : callable, optional (default=None)
Function to call on the features before computing the predictions.
This function will take the input dataframe that will be passed to the model for predicting and should return a dataframe with the same structure.
The series identifier is on the index.
after_predict_callback : callable, optional (default=None)
Function to call on the predictions before updating the targets.
This function will take a pandas Series with the predictions and should return another one with the same structure.
The series identifier is on the index.
new_df : pandas or polars DataFrame, optional (default=None)
Series data of new observations for which forecasts are to be generated.
This dataframe should have the same structure as the one used to fit the model, including any features and time series data.
If `new_df` is not None, the method will generate forecasts for the new observations.
level : list of ints or floats, optional (default=None)
Confidence levels between 0 and 100 for prediction intervals.
X_df : pandas or polars DataFrame, optional (default=None)
Dataframe with the future exogenous features. Should have the id column and the time column.
ids : list of str, optional (default=None)
List with subset of ids seen during training for which the forecasts should be computed.
Returns
-------
result : pandas or polars DataFrame
Predictions for each serie and timestep, with one column per model.
"""
if not hasattr(self, 'models_'):
raise ValueError(
"No fitted models found. You have to call fit or preprocess + fit_models. "
"If you used cross_validation before please fit again."
)
first_model_is_list = isinstance(next(iter(self.models_.values())), list)
max_horizon = self.ts.max_horizon
if first_model_is_list and max_horizon is None:
raise ValueError(
'Found one model per horizon but `max_horizon` is None. '
'If you ran preprocess after fit please run fit again.'
)
elif not first_model_is_list and max_horizon is not None:
raise ValueError(
'Found a single model for all horizons '
f'but `max_horizon` is {max_horizon}. '
'If you ran preprocess after fit please run fit again.'
)
if new_df is not None:
if level is not None:
raise ValueError(
"Prediction intervals are not supported in transfer learning."
)
new_ts = TimeSeries(
freq=self.ts.freq,
lags=self.ts.lags,
lag_transforms=self.ts.lag_transforms,
date_features=self.ts.date_features,
num_threads=self.ts.num_threads,
target_transforms=self.ts.target_transforms,
lag_transforms_namer=self.ts.lag_transforms_namer,
)
new_ts._fit(
new_df,
id_col=self.ts.id_col,
time_col=self.ts.time_col,
target_col=self.ts.target_col,
static_features=self.ts.static_features,
keep_last_n=self.ts.keep_last_n,
)
core_tfms = new_ts._get_core_lag_tfms()
if core_tfms:
# 填充更新所需的统计数据
new_ts._compute_transforms(core_tfms, updates_only=False)
new_ts.max_horizon = self.ts.max_horizon
new_ts.as_numpy = self.ts.as_numpy
ts = new_ts
else:
ts = self.ts
forecasts = ts.predict(
models=self.models_,
horizon=h,
before_predict_callback=before_predict_callback,
after_predict_callback=after_predict_callback,
X_df=X_df,
ids=ids,
)
if level is not None:
if self._cs_df is None:
warn_msg = (
'Please rerun the `fit` method passing a proper value '
'to prediction intervals to compute them.'
)
warnings.warn(warn_msg, UserWarning)
else:
if (self.prediction_intervals.h != 1) and (self.prediction_intervals.h < h):
raise ValueError(
'The `h` argument of PredictionIntervals '
'should be equal to one or greater or equal to `h`. '
'Please rerun the `fit` method passing a proper value '
'to prediction intervals.'
)
if self.prediction_intervals.h == 1 and h > 1:
warn_msg = (
'Prediction intervals are calculated using 1-step ahead cross-validation, '
'with a constant width for all horizons. To vary the error by horizon, '
'pass PredictionIntervals(h=h) to the `prediction_intervals` '
'argument when refitting the model.'
)
warnings.warn(warn_msg, UserWarning)
level_ = sorted(level)
model_names = self.models.keys()
conformal_method = _get_conformal_method(self.prediction_intervals.method)
if ids is not None:
ids_mask = ufp.is_in(self._cs_df[self.ts.id_col], ids)
cs_df = ufp.filter_with_mask(self._cs_df, ids_mask)
n_series = len(ids)
else:
cs_df = self._cs_df
n_series = self.ts.ga.n_groups
forecasts = conformal_method(
forecasts,
cs_df,
model_names=list(model_names),
level=level_,
cs_h=self.prediction_intervals.h,
cs_n_windows=self.prediction_intervals.n_windows,
n_series=n_series,
horizon=h,
)
return forecasts
def cross_validation(
self,
df: DFType,
n_windows: int,
h: int,
id_col: str = 'unique_id',
time_col: str = 'ds',
target_col: str = 'y',
step_size: Optional[int] = None,
static_features: Optional[List[str]] = None,
dropna: bool = True,
keep_last_n: Optional[int] = None,
refit: Union[bool, int] = True,
max_horizon: Optional[int] = None,
before_predict_callback: Optional[Callable] = None,
after_predict_callback: Optional[Callable] = None,
prediction_intervals: Optional[PredictionIntervals] = None,
level: Optional[List[Union[int, float]]] = None,
input_size: Optional[int] = None,
fitted: bool = False,
as_numpy: bool = False,
) -> DFType:
"""Perform time series cross validation.
Creates `n_windows` splits where each window has `h` test periods,
trains the models, computes the predictions and merges the actuals.
Parameters
----------
df : pandas or polars DataFrame
Series data in long format.
n_windows : int
Number of windows to evaluate.
h : int
Forecast horizon.
id_col : str (default='unique_id')
Column that identifies each serie.
time_col : str (default='ds')
Column that identifies each timestep, its values can be timestamps or integers.
target_col : str (default='y')
Column that contains the target.
step_size : int, optional (default=None)
Step size between each cross validation window. If None it will be equal to `h`.
static_features : list of str, optional (default=None)
Names of the features that are static and will be repeated when forecasting.
dropna : bool (default=True)
Drop rows with missing values produced by the transformations.
keep_last_n : int, optional (default=None)
Keep only these many records from each serie for the forecasting step. Can save time and memory if your features allow it.
max_horizon: int, optional (default=None)
Train this many models, where each model will predict a specific horizon.
refit : bool or int (default=True)
Retrain model for each cross validation window.
If False, the models are trained at the beginning and then used to predict each window.
If positive int, the models are retrained every `refit` windows.
before_predict_callback : callable, optional (default=None)
Function to call on the features before computing the predictions.
This function will take the input dataframe that will be passed to the model for predicting and should return a dataframe with the same structure.
The series identifier is on the index.
after_predict_callback : callable, optional (default=None)
Function to call on the predictions before updating the targets.
This function will take a pandas Series with the predictions and should return another one with the same structure.
The series identifier is on the index.
prediction_intervals : PredictionIntervals, optional (default=None)
Configuration to calibrate prediction intervals (Conformal Prediction).
level : list of ints or floats, optional (default=None)
Confidence levels between 0 and 100 for prediction intervals.
input_size : int, optional (default=None)
Maximum training samples per serie in each window. If None, will use an expanding window.
fitted : bool (default=False)
Store the in-sample predictions.
as_numpy : bool (default = False)
Cast features to numpy array.
Returns
-------
result : pandas or polars DataFrame
Predictions for each window with the series id, timestamp, last train date, target value and predictions from each model.
"""
results = []
cv_models = []
cv_fitted_values = []
splits = ufp.backtest_splits(
df,
n_windows=n_windows,
h=h,
id_col=id_col,
time_col=time_col,
freq=self.freq,
step_size=step_size,
input_size=input_size,
)
for i_window, (cutoffs, train, valid) in enumerate(splits):
should_fit = i_window == 0 or (refit > 0 and i_window % refit == 0)
if should_fit:
self.fit(
train,
id_col=id_col,
time_col=time_col,
target_col=target_col,
static_features=static_features,
dropna=dropna,
keep_last_n=keep_last_n,
max_horizon=max_horizon,
prediction_intervals=prediction_intervals,
fitted=fitted,
as_numpy=as_numpy,
)
cv_models.append(self.models_)
if fitted:
cv_fitted_values.append(ufp.assign_columns(self.fcst_fitted_values_, 'fold', i_window))
if fitted and not should_fit:
if self.ts.target_transforms is not None:
for tfm in self.ts.target_transforms:
if hasattr(tfm, 'store_fitted'):
tfm.store_fitted = True
prep = self.preprocess(
train,
id_col=id_col,
time_col=time_col,
target_col=target_col,
static_features=static_features,
dropna=dropna,
keep_last_n=keep_last_n,
max_horizon=max_horizon,
return_X_y=False,
)
assert not isinstance(prep, tuple)
base = prep[[id_col, time_col]]
train_X, train_y = self._extract_X_y(prep, target_col)
if as_numpy:
train_X = ufp.to_numpy(train_X)
del prep
fitted_values = self._compute_fitted_values(
base=base,
X=train_X,
y=train_y,
id_col=id_col,
time_col=time_col,
target_col=target_col,
max_horizon=max_horizon,
)
fitted_values = ufp.assign_columns(fitted_values, 'fold', i_window)
cv_fitted_values.append(fitted_values)
static = [c for c in self.ts.static_features_.columns if c != id_col]
dynamic = [
c for c in valid.columns if c not in static + [id_col, time_col, target_col]
]
if dynamic:
X_df: Optional[DataFrame] = ufp.drop_columns(valid, static + [target_col])
else:
X_df = None
y_pred = self.predict(
h=h,
before_predict_callback=before_predict_callback,
after_predict_callback=after_predict_callback,
new_df=train if not should_fit else None,
level=level,
X_df=X_df,
)
y_pred = ufp.join(y_pred, cutoffs, on=id_col, how='left')
result = ufp.join(
valid[[id_col, time_col, target_col]],
y_pred,
on=[id_col, time_col],
)
sort_idxs = ufp.maybe_compute_sort_indices(result, id_col, time_col)
if sort_idxs is not None:
result = ufp.take_rows(result, sort_idxs)
if result.shape[0] < valid.shape[0]:
raise ValueError(
"Cross validation result produced less results than expected. "
"Please verify that the frequency set on the MLForecast constructor matches your series' "
"and that there aren't any missing periods."
)
results.append(result)
del self.models_
self.cv_models_ = cv_models
self.cv_fitted_values_ = cv_fitted_values
out = ufp.vertical_concat(results, match_categories=False)
out = ufp.drop_index_if_pandas(out)
first_out_cols = [id_col, time_col, 'cutoff', target_col]
remaining_cols = [c for c in out.columns if c not in first_out_cols]
return out[first_out_cols + remaining_cols]
def cross_validation_fitted_values(self):
if not getattr(self, 'cv_fitted_values_', []):
raise ValueError('Please run cross_validation with fitted=True first.')
out = ufp.vertical_concat(self.cv_fitted_values_, match_categories=False)
first_out_cols = [self.ts.id_col, self.ts.time_col, 'fold', self.ts.target_col]
remaining_cols = [c for c in out.columns if c not in first_out_cols]
out = ufp.drop_index_if_pandas(out)
return out[first_out_cols + remaining_cols]
def save(self, path: Union[str, Path]) -> None:
"""保存预测对象
参数
----------
路径 : str 或 pathlib.Path
存储工件的目录。"""
self.ts.save(f'{path}/ts.pkl')
with fsspec.open(f'{path}/models.pkl', 'wb') as f:
cloudpickle.dump(self.models_, f)
if self._cs_df is not None:
with fsspec.open(f'{path}/intervals.pkl', 'wb') as f:
cloudpickle.dump(
{'scores': self._cs_df, 'settings': self.prediction_intervals},
f
)
@staticmethod
def load(path: Union[str, Path]) -> 'MLForecast':
"""负荷预测对象
参数
----------
路径 : str 或 pathlib.Path
保存了工件的目录。"""
ts = TimeSeries.load(f'{path}/ts.pkl')
with fsspec.open(f'{path}/models.pkl', 'rb') as f:
models = cloudpickle.load(f)
try:
with fsspec.open(f'{path}/intervals.pkl', 'rb') as f:
intervals = cloudpickle.load(f)
except FileNotFoundError:
intervals = None
fcst = MLForecast(models=models, freq=ts.freq)
fcst.ts = ts
fcst.models_ = models
if intervals is not None:
fcst.prediction_intervals = intervals['settings']
fcst._cs_df = intervals['scores']
return fcst
def update(self, df: DataFrame) -> None:
"""更新存储序列的值。
参数
----------
df : pandas 或 polars 的 DataFrame
包含新观测值的数据框。"""
self.ts.update(df)数据
这展示了仅包含 M4 数据集中的 4 个系列的示例。如果您想自己在所有系列上运行它,可以参考 这个笔记本。
import random
import tempfile
import lightgbm as lgb
import matplotlib.pyplot as plt
import numpy as np
import xgboost as xgb
from datasetsforecast.m4 import M4, M4Info
from sklearn.linear_model import LinearRegression
from utilsforecast.plotting import plot_series
from mlforecast.lag_transforms import ExpandingMean, ExponentiallyWeightedMean, RollingMean
from mlforecast.lgb_cv import LightGBMCV
from mlforecast.target_transforms import Differences, LocalStandardScaler
from mlforecast.utils import generate_daily_seriesgroup = 'Hourly'
await M4.async_download('data', group=group)
df, *_ = M4.load(directory='data', group=group)
df['ds'] = df['ds'].astype('int')
ids = df['unique_id'].unique()
random.seed(0)
sample_ids = random.choices(ids, k=4)
sample_df = df[df['unique_id'].isin(sample_ids)]
sample_df| unique_id | ds | y | |
|---|---|---|---|
| 86796 | H196 | 1 | 11.8 |
| 86797 | H196 | 2 | 11.4 |
| 86798 | H196 | 3 | 11.1 |
| 86799 | H196 | 4 | 10.8 |
| 86800 | H196 | 5 | 10.6 |
| ... | ... | ... | ... |
| 325235 | H413 | 1004 | 99.0 |
| 325236 | H413 | 1005 | 88.0 |
| 325237 | H413 | 1006 | 47.0 |
| 325238 | H413 | 1007 | 41.0 |
| 325239 | H413 | 1008 | 34.0 |
4032 rows × 3 columns
我们现在将这些数据分割为训练集和验证集。
info = M4Info[group]
horizon = info.horizon
valid = sample_df.groupby('unique_id').tail(horizon)
train = sample_df.drop(valid.index)
train.shape, valid.shape((3840, 3), (192, 3))show_doc(MLForecast)MLForecast
MLForecast (models:Union[sklearn.base.BaseEstimator,List[sklearn.base.Bas eEstimator],Dict[str,sklearn.base.BaseEstimator]], freq:Union[int,str], lags:Optional[Iterable[int]]=None, lag_t ransforms:Optional[Dict[int,List[Union[Callable,Tuple[Callabl e,Any]]]]]=None, date_features:Optional[Iterable[Union[str,Callable]]]=None, num_threads:int=1, target_transforms:Optional[List[Union[mlfo recast.target_transforms.BaseTargetTransform,mlforecast.targe t_transforms._BaseGroupedArrayTargetTransform]]]=None, lag_transforms_namer:Optional[Callable]=None)
Forecasting pipeline
| Type | Default | Details | |
|---|---|---|---|
| models | Union | Models that will be trained and used to compute the forecasts. | |
| freq | Union | Pandas offset, pandas offset alias, e.g. ‘D’, ‘W-THU’ or integer denoting the frequency of the series. | |
| lags | Optional | None | Lags of the target to use as features. |
| lag_transforms | Optional | None | Mapping of target lags to their transformations. |
| date_features | Optional | None | Features computed from the dates. Can be pandas date attributes or functions that will take the dates as input. |
| num_threads | int | 1 | Number of threads to use when computing the features. |
| target_transforms | Optional | None | Transformations that will be applied to the target before computing the features and restored after the forecasting step. |
| lag_transforms_namer | Optional | None | Function that takes a transformation (either function or class), a lag and extra arguments and produces a name. |
MLForecast对象封装了特征工程 + 模型训练 + 预测。
fcst = MLForecast(
models=lgb.LGBMRegressor(random_state=0, verbosity=-1),
freq=1,
lags=[24 * (i+1) for i in range(7)],
lag_transforms={
48: [ExponentiallyWeightedMean(alpha=0.3)],
},
num_threads=1,
target_transforms=[Differences([24])],
)
fcstMLForecast(models=[LGBMRegressor], freq=1, lag_features=['lag24', 'lag48', 'lag72', 'lag96', 'lag120', 'lag144', 'lag168', 'exponentially_weighted_mean_lag48_alpha0.3'], date_features=[], num_threads=1)一旦我们完成了这个设置,我们就可以计算特征并拟合模型。
show_doc(MLForecast.fit)MLForecast.fit
MLForecast.fit (df:Union[pandas.core.frame.DataFrame,polars.dataframe.fr ame.DataFrame], id_col:str='unique_id', time_col:str='ds', target_col:str='y', static_features:Optional[List[str]]=None, dropna:bool=True, keep_last_n:Optional[int]=None, max_horizon:Optional[int]=None, prediction_intervals:Opti onal[mlforecast.utils.PredictionIntervals]=None, fitted:bool=False, as_numpy:bool=False)
Apply the feature engineering and train the models.
| Type | Default | Details | |
|---|---|---|---|
| df | Union | Series data in long format. | |
| id_col | str | unique_id | Column that identifies each serie. |
| time_col | str | ds | Column that identifies each timestep, its values can be timestamps or integers. |
| target_col | str | y | Column that contains the target. |
| static_features | Optional | None | Names of the features that are static and will be repeated when forecasting. If None, will consider all columns (except id_col and time_col) as static. |
| dropna | bool | True | Drop rows with missing values produced by the transformations. |
| keep_last_n | Optional | None | Keep only these many records from each serie for the forecasting step. Can save time and memory if your features allow it. |
| max_horizon | Optional | None | Train this many models, where each model will predict a specific horizon. |
| prediction_intervals | Optional | None | Configuration to calibrate prediction intervals (Conformal Prediction). |
| fitted | bool | False | Save in-sample predictions. |
| as_numpy | bool | False | Cast features to numpy array. |
| Returns | MLForecast | Forecast object with series values and trained models. |
fcst = MLForecast(
models=lgb.LGBMRegressor(random_state=0, verbosity=-1),
freq=1,
lags=[24 * (i+1) for i in range(7)],
lag_transforms={
48: [ExponentiallyWeightedMean(alpha=0.3)],
},
num_threads=1,
target_transforms=[Differences([24])],
)fcst.fit(train, fitted=True);show_doc(MLForecast.save)MLForecast.save
MLForecast.save (path:Union[str,pathlib.Path])
Save forecast object
| Type | Details | |
|---|---|---|
| path | Union | Directory where artifacts will be stored. |
| Returns | None |
show_doc(MLForecast.load)MLForecast.load
MLForecast.load (path:Union[str,pathlib.Path])
Load forecast object
| Type | Details | |
|---|---|---|
| path | Union | Directory with saved artifacts. |
| Returns | MLForecast |
show_doc(MLForecast.update)MLForecast.update
MLForecast.update (df:Union[pandas.core.frame.DataFrame,polars.dataframe .frame.DataFrame])
Update the values of the stored series.
| Type | Details | |
|---|---|---|
| df | Union | Dataframe with new observations. |
| Returns | None |
show_doc(MLForecast.make_future_dataframe)MLForecast.make_future_dataframe
MLForecast.make_future_dataframe (h:int)
Create a dataframe with all ids and future times in the forecasting horizon.
| Type | Details | |
|---|---|---|
| h | int | Number of periods to predict. |
| Returns | Union | DataFrame with expected ids and future times |
expected_future = fcst.make_future_dataframe(h=1)
expected_future| unique_id | ds | |
|---|---|---|
| 0 | H196 | 961 |
| 1 | H256 | 961 |
| 2 | H381 | 961 |
| 3 | H413 | 961 |
show_doc(MLForecast.get_missing_future)MLForecast.get_missing_future
MLForecast.get_missing_future (h:int, X_df:Union[pandas.core.frame.DataFrame,pol ars.dataframe.frame.DataFrame])
Get the missing id and time combinations in X_df.
| Type | Details | |
|---|---|---|
| h | int | Number of periods to predict. |
| X_df | Union | Dataframe with the future exogenous features. Should have the id column and the time column. |
| Returns | Union | DataFrame with expected ids and future times missing in X_df |
missing_future = fcst.get_missing_future(h=1, X_df=expected_future.head(2))
pd.testing.assert_frame_equal(
missing_future,
expected_future.tail(2).reset_index(drop=True)
)show_doc(MLForecast.forecast_fitted_values)MLForecast.forecast_fitted_values
MLForecast.forecast_fitted_values (level:Optional[List[Union[int,float]] ]=None)
Access in-sample predictions.
| Type | Default | Details | |
|---|---|---|---|
| level | Optional | None | Confidence levels between 0 and 100 for prediction intervals. |
| Returns | Union | Dataframe with predictions for the training set |
fcst.forecast_fitted_values()| unique_id | ds | y | LGBMRegressor | |
|---|---|---|---|---|
| 0 | H196 | 193 | 12.7 | 12.671271 |
| 1 | H196 | 194 | 12.3 | 12.271271 |
| 2 | H196 | 195 | 11.9 | 11.871271 |
| 3 | H196 | 196 | 11.7 | 11.671271 |
| 4 | H196 | 197 | 11.4 | 11.471271 |
| ... | ... | ... | ... | ... |
| 3067 | H413 | 956 | 59.0 | 68.280574 |
| 3068 | H413 | 957 | 58.0 | 70.427570 |
| 3069 | H413 | 958 | 53.0 | 44.767965 |
| 3070 | H413 | 959 | 38.0 | 48.691257 |
| 3071 | H413 | 960 | 46.0 | 46.652238 |
3072 rows × 4 columns
fcst.forecast_fitted_values(level=[90])| unique_id | ds | y | LGBMRegressor | LGBMRegressor-lo-90 | LGBMRegressor-hi-90 | |
|---|---|---|---|---|---|---|
| 0 | H196 | 193 | 12.7 | 12.671271 | 12.540634 | 12.801909 |
| 1 | H196 | 194 | 12.3 | 12.271271 | 12.140634 | 12.401909 |
| 2 | H196 | 195 | 11.9 | 11.871271 | 11.740634 | 12.001909 |
| 3 | H196 | 196 | 11.7 | 11.671271 | 11.540634 | 11.801909 |
| 4 | H196 | 197 | 11.4 | 11.471271 | 11.340634 | 11.601909 |
| ... | ... | ... | ... | ... | ... | ... |
| 3067 | H413 | 956 | 59.0 | 68.280574 | 58.846640 | 77.714509 |
| 3068 | H413 | 957 | 58.0 | 70.427570 | 60.993636 | 79.861504 |
| 3069 | H413 | 958 | 53.0 | 44.767965 | 35.334031 | 54.201899 |
| 3070 | H413 | 959 | 38.0 | 48.691257 | 39.257323 | 58.125191 |
| 3071 | H413 | 960 | 46.0 | 46.652238 | 37.218304 | 56.086172 |
3072 rows × 6 columns
# 检查经过变换后,从fitted_values中得到的拟合目标是否与原始目标一致。
fcst2 = MLForecast(
models=lgb.LGBMRegressor(random_state=0, verbosity=-1),
freq=1,
lags=[24 * (i+1) for i in range(7)],
lag_transforms={
48: [ExponentiallyWeightedMean(alpha=0.3)],
},
num_threads=1,
target_transforms=[Differences([24]), LocalStandardScaler()],
)
fcst2.fit(train, fitted=True)
fitted_vals = fcst2.forecast_fitted_values()
train_restored = train.merge(
fitted_vals.drop(columns='LGBMRegressor'),
on=['unique_id', 'ds'],
suffixes=('_expected', '_actual')
)
np.testing.assert_allclose(
train_restored['y_expected'].values,
train_restored['y_actual'].values,
)
# 检查已安装的 + 最大视野
max_horizon = 7
fcst2.fit(train, fitted=True, max_horizon=max_horizon)
max_horizon_fitted_values = fcst2.forecast_fitted_values()
# h 从 1 到 max_horizon
np.testing.assert_equal(
np.sort(max_horizon_fitted_values['h'].unique()),
np.arange(1, max_horizon + 1),
)
# 第一期预测等于递归
pd.testing.assert_frame_equal(
fitted_vals.reset_index(drop=True),
max_horizon_fitted_values[max_horizon_fitted_values['h'] == 1].drop(columns='h'),
)
# 恢复的值匹配
xx = max_horizon_fitted_values[lambda x: x['unique_id'].eq('H413')].pivot_table(
index=['unique_id', 'ds'], columns='h', values='y'
).loc['H413']
first_ds = xx.index.min()
last_ds = xx.index.max()
for h in range(1, max_horizon):
np.testing.assert_allclose(
xx.loc[first_ds + h :, 1].values,
xx.loc[: last_ds - h, h + 1].values,
)一旦我们运行完这个,我们就准备好计算我们的预测了。
show_doc(MLForecast.predict)MLForecast.predict
MLForecast.predict (h:int, before_predict_callback:Optional[Callable]=None, after_predict_callback:Optional[Callable]=None, new_d f:Union[pandas.core.frame.DataFrame,polars.dataframe. frame.DataFrame,NoneType]=None, level:Optional[List[Union[int,float]]]=None, X_df:Uni on[pandas.core.frame.DataFrame,polars.dataframe.frame .DataFrame,NoneType]=None, ids:Optional[List[str]]=None)
Compute the predictions for the next h steps.
| Type | Default | Details | |
|---|---|---|---|
| h | int | Number of periods to predict. | |
| before_predict_callback | Optional | None | Function to call on the features before computing the predictions. This function will take the input dataframe that will be passed to the model for predicting and should return a dataframe with the same structure. The series identifier is on the index. |
| after_predict_callback | Optional | None | Function to call on the predictions before updating the targets. This function will take a pandas Series with the predictions and should return another one with the same structure. The series identifier is on the index. |
| new_df | Union | None | Series data of new observations for which forecasts are to be generated. This dataframe should have the same structure as the one used to fit the model, including any features and time series data. If new_df is not None, the method will generate forecasts for the new observations. |
| level | Optional | None | Confidence levels between 0 and 100 for prediction intervals. |
| X_df | Union | None | Dataframe with the future exogenous features. Should have the id column and the time column. |
| ids | Optional | None | List with subset of ids seen during training for which the forecasts should be computed. |
| Returns | Union | Predictions for each serie and timestep, with one column per model. |
predictions = fcst.predict(horizon)我们可以看到几个结果。
results = valid.merge(predictions, on=['unique_id', 'ds'])
fig = plot_series(forecasts_df=results)fig.savefig('figs/forecast__predict.png', bbox_inches='tight')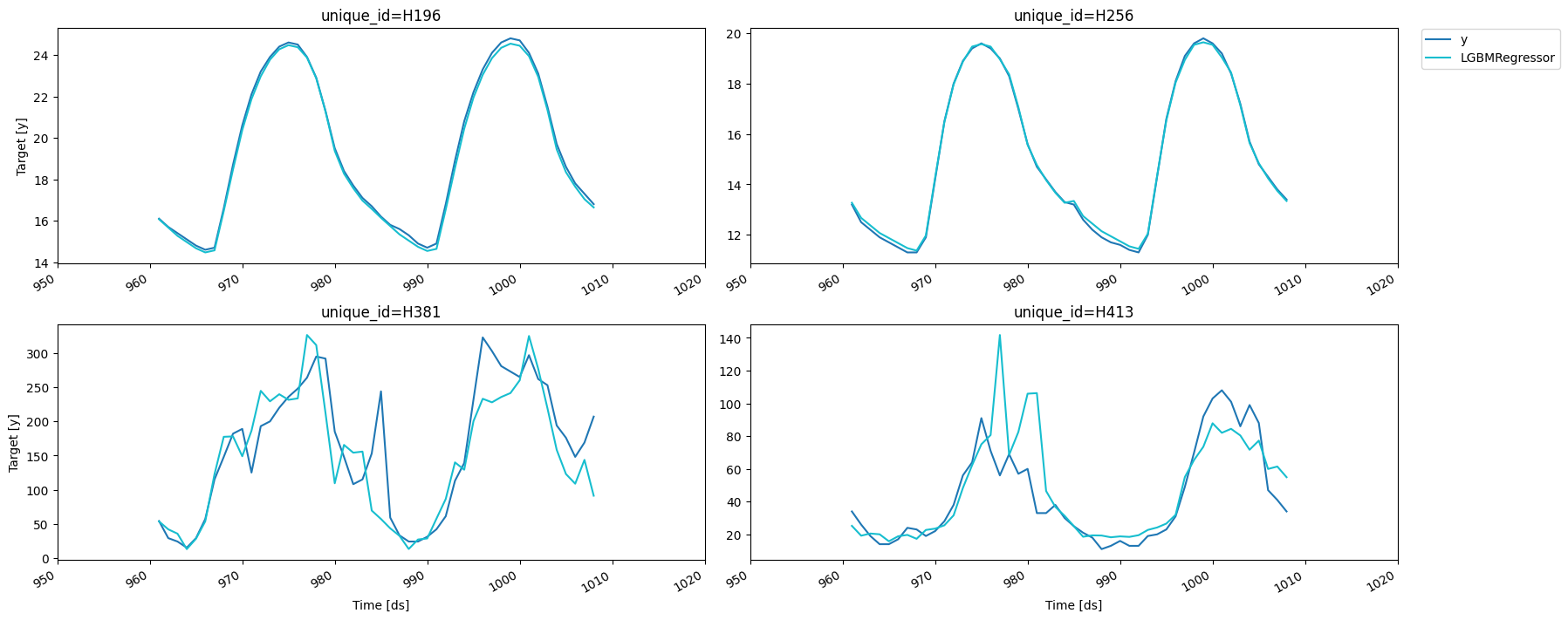
# 测试 new_df 参数
pd.testing.assert_frame_equal(
fcst.predict(horizon, new_df=train),
predictions
)预测区间
使用 MLForecast,您可以通过符合预测生成预测区间。要配置符合预测,您需要将 PredictionIntervals 类的实例传递给 fit 方法的 prediction_intervals 参数。该类接受三个参数:n_windows、h 和 method。
n_windows表示用于校准区间的交叉验证窗口数量h是预测时间范围method可以是conformal_distribution或conformal_error;默认的conformal_distribution基于交叉验证错误创建预测路径,并使用这些路径计算分位数,而conformal_error则计算误差分位数以生成预测区间。该策略将根据每个时间范围的步骤调整区间,导致每个步骤的宽度不同。请注意,必须使用至少 2 个交叉验证窗口。
fcst.fit(
train,
prediction_intervals=PredictionIntervals(n_windows=3, h=48)
);之后,您只需通过使用 level 参数将所需的置信水平包含到 predict 方法中。水平必须介于 0 和 100 之间。
predictions_w_intervals = fcst.predict(48, level=[50, 80, 95])
predictions_w_intervals.head()| unique_id | ds | LGBMRegressor | LGBMRegressor-lo-95 | LGBMRegressor-lo-80 | LGBMRegressor-lo-50 | LGBMRegressor-hi-50 | LGBMRegressor-hi-80 | LGBMRegressor-hi-95 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | H196 | 961 | 16.071271 | 15.958042 | 15.971271 | 16.005091 | 16.137452 | 16.171271 | 16.184501 |
| 1 | H196 | 962 | 15.671271 | 15.553632 | 15.553632 | 15.578632 | 15.763911 | 15.788911 | 15.788911 |
| 2 | H196 | 963 | 15.271271 | 15.153632 | 15.153632 | 15.162452 | 15.380091 | 15.388911 | 15.388911 |
| 3 | H196 | 964 | 14.971271 | 14.858042 | 14.871271 | 14.905091 | 15.037452 | 15.071271 | 15.084501 |
| 4 | H196 | 965 | 14.671271 | 14.553632 | 14.553632 | 14.562452 | 14.780091 | 14.788911 | 14.788911 |
# 测试我们可以预测低于h的地平线
# 带有预测区间
for method in ['conformal_distribution', 'conformal_errors']:
fcst.fit(
train,
prediction_intervals=PredictionIntervals(n_windows=3, h=48)
)
preds_h_lower_h = fcst.predict(1, level=[50, 80, 95])
preds_h_lower_h = fcst.predict(30, level=[50, 80, 95])
# 测试区间的单调性
test_eq(
preds_h_lower_h.filter(regex='lo|hi').apply(
lambda x: x.is_monotonic_increasing,
axis=1
).sum(),
len(preds_h_lower_h)
)test_fail(lambda: fcst.predict(49, level=[68]))# 测试我们可以恢复点预测
test_eq(
predictions,
predictions_w_intervals[predictions.columns]
)# 测试我们可以恢复级别0的平均预测
np.testing.assert_allclose(
predictions['LGBMRegressor'].values,
fcst.predict(48, level=[0])['LGBMRegressor-lo-0'].values,
)# 测试区间的单调性
test_eq(
predictions_w_intervals.filter(regex='lo|hi').apply(
lambda x: x.is_monotonic_increasing,
axis=1
).sum(),
len(predictions_w_intervals)
)让我们来探索生成的区间。
results = valid.merge(predictions_w_intervals, on=['unique_id', 'ds'])
fig = plot_series(forecasts_df=results, level=[50, 80, 95])fig.savefig('figs/forecast__predict_intervals.png', bbox_inches='tight')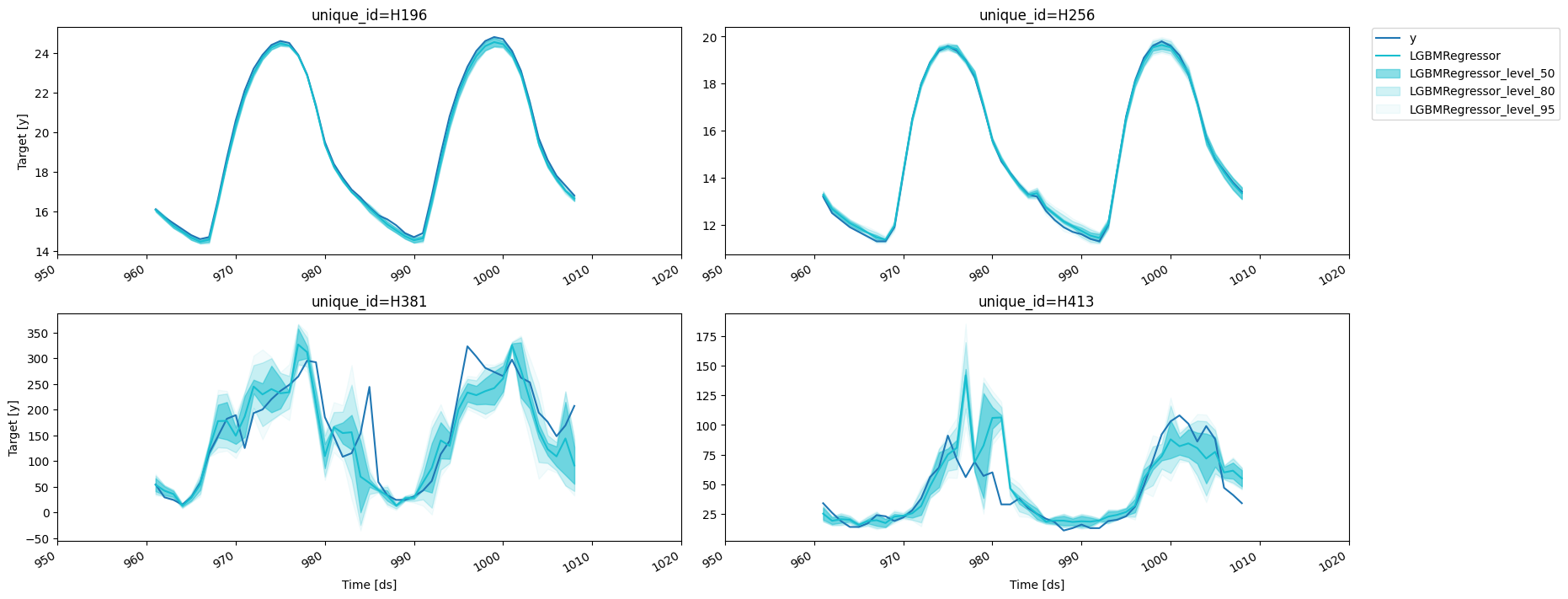
如果您想减少计算时间并为整个预测范围生成相同宽度的区间,只需将 h=1 传递给 PredictionIntervals 类即可。这个策略的一个缺点是在某些情况下,绝对残差的方差可能很小(甚至为零),因此区间可能会过于狭窄。
fcst.fit(
train,
prediction_intervals=PredictionIntervals(n_windows=3, h=1)
);predictions_w_intervals_ws_1 = fcst.predict(48, level=[80, 90, 95])让我们来探索生成的区间。
results = valid.merge(predictions_w_intervals_ws_1, on=['unique_id', 'ds'])
fig = plot_series(forecasts_df=results, level=[90])fig.savefig('figs/forecast__predict_intervals_window_size_1.png', bbox_inches='tight')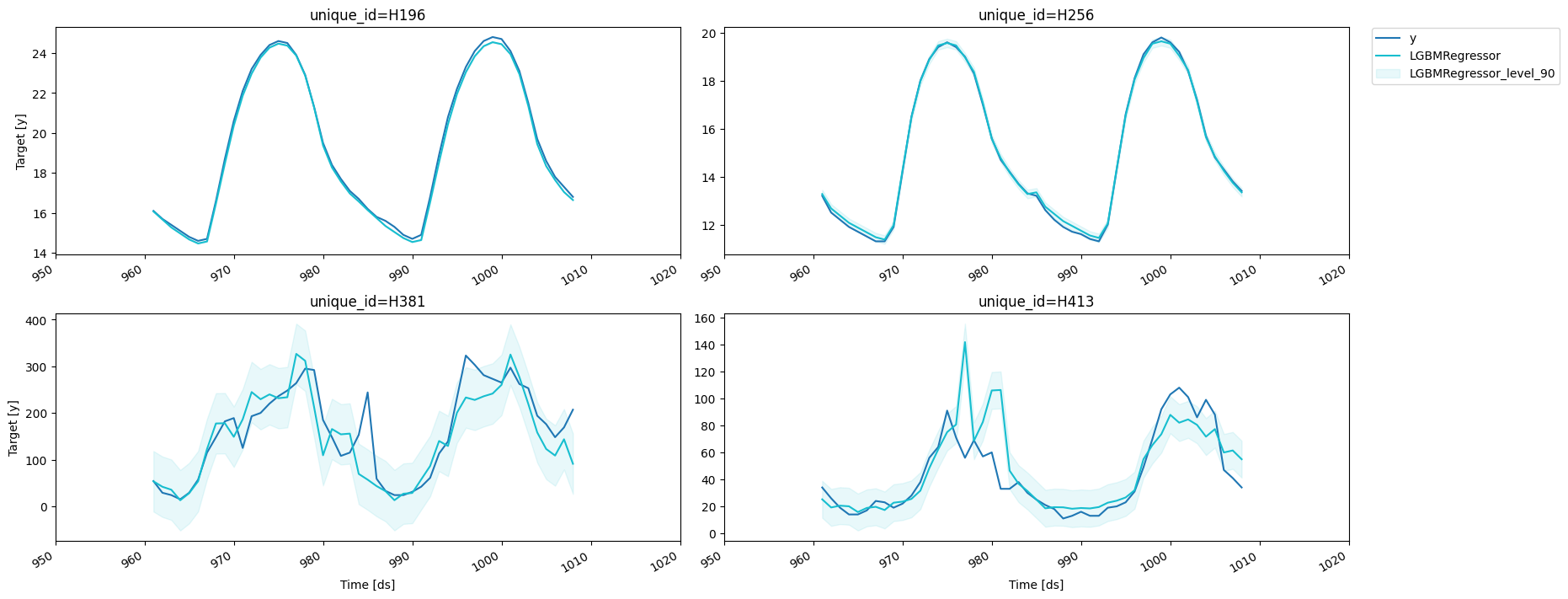
# 测试索引数据,日期时间 ds
fcst_test = MLForecast(
models=lgb.LGBMRegressor(random_state=0, verbosity=-1),
freq='D',
lags=[1],
num_threads=1,
)
df_test = generate_daily_series(1)
fcst_test.fit(
df_test,
# 预测区间=预测区间()
)
pred_test = fcst_test.predict(12)
pred_int_test = fcst_test.predict(12, level=[80, 90])
# 测试相同结构
test_eq(
pred_test,
pred_int_test[pred_test.columns]
)
# 测试区间的单调性
test_eq(
pred_int_test.filter(regex='lo|hi').apply(
lambda x: x.is_monotonic_increasing,
axis=1
).sum(),
len(pred_int_test)
)使用预训练模型进行预测
MLForecast允许您使用预训练模型为新数据集生成预测。只需在调用predict方法时提供一个包含新观察值的pandas dataframe,作为new_df参数的值。该dataframe应与用于拟合模型的结构相同,包括任何特征和时间序列数据。然后,函数将使用预训练模型为新观察值生成预测。这使您能够轻松地将预训练模型应用于新数据集,并生成预测,而无需重新训练模型。
ercot_df = pd.read_csv('https://datasets-nixtla.s3.amazonaws.com/ERCOT-clean.csv')
# 我们需要将 ds 列转换为整数。
# 由于MLForecast是基于该结构进行训练的
ercot_df['ds'] = np.arange(1, len(ercot_df) + 1)
# 使用 `new_df` 参数传递 ercot 数据集
ercot_fcsts = fcst.predict(horizon, new_df=ercot_df)
fig = plot_series(ercot_df, ercot_fcsts, max_insample_length=48 * 2)fig.get_axes()[0].set_title('ERCOT forecasts trained on M4-Hourly dataset')
fig.savefig('figs/forecast__ercot.png', bbox_inches='tight')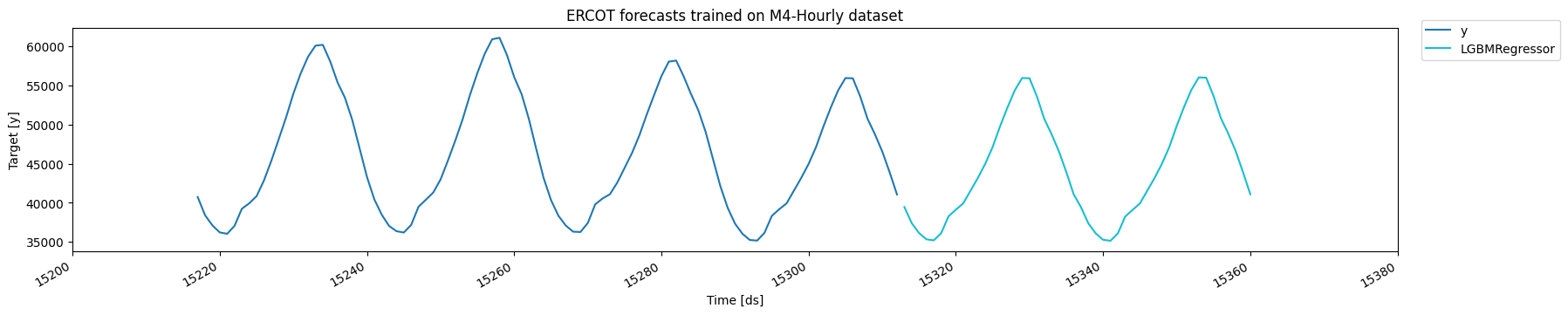
如果您想查看将用于训练模型的数据,可以调用 Forecast.preprocess。
show_doc(MLForecast.preprocess)MLForecast.preprocess
MLForecast.preprocess (df:Union[pandas.core.frame.DataFrame,polars.dataf rame.frame.DataFrame], id_col:str='unique_id', time_col:str='ds', target_col:str='y', static_features:Optional[List[str]]=None, dropna:bool=True, keep_last_n:Optional[int]=None, max_horizon:Optional[int]=None, return_X_y:bool=False, as_numpy:bool=False)
Add the features to data.
| Type | Default | Details | |
|---|---|---|---|
| df | Union | Series data in long format. | |
| id_col | str | unique_id | Column that identifies each serie. |
| time_col | str | ds | Column that identifies each timestep, its values can be timestamps or integers. |
| target_col | str | y | Column that contains the target. |
| static_features | Optional | None | Names of the features that are static and will be repeated when forecasting. |
| dropna | bool | True | Drop rows with missing values produced by the transformations. |
| keep_last_n | Optional | None | Keep only these many records from each serie for the forecasting step. Can save time and memory if your features allow it. |
| max_horizon | Optional | None | Train this many models, where each model will predict a specific horizon. |
| return_X_y | bool | False | Return a tuple with the features and the target. If False will return a single dataframe. |
| as_numpy | bool | False | Cast features to numpy array. Only works for return_X_y=True. |
| Returns | Union | df plus added features and target(s). |
prep_df = fcst.preprocess(train)
prep_df| unique_id | ds | y | lag24 | lag48 | lag72 | lag96 | lag120 | lag144 | lag168 | exponentially_weighted_mean_lag48_alpha0.3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 86988 | H196 | 193 | 0.1 | 0.0 | 0.0 | 0.0 | 0.3 | 0.1 | 0.1 | 0.3 | 0.002810 |
| 86989 | H196 | 194 | 0.1 | -0.1 | 0.1 | 0.0 | 0.3 | 0.1 | 0.1 | 0.3 | 0.031967 |
| 86990 | H196 | 195 | 0.1 | -0.1 | 0.1 | 0.0 | 0.3 | 0.1 | 0.2 | 0.1 | 0.052377 |
| 86991 | H196 | 196 | 0.1 | 0.0 | 0.0 | 0.0 | 0.3 | 0.2 | 0.1 | 0.2 | 0.036664 |
| 86992 | H196 | 197 | 0.0 | 0.0 | 0.0 | 0.1 | 0.2 | 0.2 | 0.1 | 0.2 | 0.025665 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 325187 | H413 | 956 | 0.0 | 10.0 | 1.0 | 6.0 | -53.0 | 44.0 | -21.0 | 21.0 | 7.963225 |
| 325188 | H413 | 957 | 9.0 | 10.0 | 10.0 | -7.0 | -46.0 | 27.0 | -19.0 | 24.0 | 8.574257 |
| 325189 | H413 | 958 | 16.0 | 8.0 | 5.0 | -9.0 | -36.0 | 32.0 | -13.0 | 8.0 | 7.501980 |
| 325190 | H413 | 959 | -3.0 | 17.0 | -7.0 | 2.0 | -31.0 | 22.0 | 5.0 | -2.0 | 3.151386 |
| 325191 | H413 | 960 | 15.0 | 11.0 | -6.0 | -5.0 | -17.0 | 22.0 | -18.0 | 10.0 | 0.405970 |
3072 rows × 11 columns
如果我们这样做,那么我们必须调用 Forecast.fit_models,因为这仅仅存储了序列信息。
# 转换命名器
def namer(tfm, lag, *args):
return f'hello_from_{tfm.__class__.__name__.lower()}'
fcst2 = MLForecast(
models=LinearRegression(),
freq=1,
lag_transforms={1: [ExpandingMean()]},
lag_transforms_namer=namer,
)
prep = fcst2.preprocess(train)
assert 'hello_from_expandingmean' in prepshow_doc(MLForecast.fit_models)MLForecast.fit_models
MLForecast.fit_models (X:Union[pandas.core.frame.DataFrame,polars.datafra me.frame.DataFrame,numpy.ndarray], y:numpy.ndarray)
Manually train models. Use this if you called MLForecast.preprocess beforehand.
| Type | Details | |
|---|---|---|
| X | Union | Features. |
| y | ndarray | Target. |
| Returns | MLForecast | Forecast object with trained models. |
X, y = prep_df.drop(columns=['unique_id', 'ds', 'y']), prep_df['y']
fcst.fit_models(X, y)MLForecast(models=[LGBMRegressor], freq=1, lag_features=['lag24', 'lag48', 'lag72', 'lag96', 'lag120', 'lag144', 'lag168', 'exponentially_weighted_mean_lag48_alpha0.3'], date_features=[], num_threads=1)predictions2 = fcst.predict(horizon)
pd.testing.assert_frame_equal(predictions, predictions2)# 测试间隔多输出
max_horizon = 24
individual_fcst_intervals = fcst.fit(
train,
max_horizon=max_horizon,
prediction_intervals=PredictionIntervals(h=max_horizon)
)
individual_preds = fcst.predict(max_horizon)
individual_preds_intervals = fcst.predict(max_horizon, level=[90, 80])
# 测试区间的单调性
test_eq(
individual_preds_intervals.filter(regex='lo|hi').apply(
lambda x: x.is_monotonic_increasing,
axis=1
).sum(),
len(individual_preds_intervals)
)
# 测试我们可以恢复带区间的点预测
test_eq(
individual_preds,
individual_preds_intervals[individual_preds.columns]
)# 在预测之前检查最大预测范围和模型状态是否存在问题
fcst = MLForecast(
models=[LinearRegression()],
freq=1,
lags=[12],
)
fcst.fit(df, max_horizon=2)
fcst.preprocess(df, max_horizon=None)
test_fail(lambda: fcst.predict(1), contains='Found one model per horizon')
fcst.fit(df, max_horizon=None)
fcst.preprocess(df, max_horizon=2)
test_fail(lambda: fcst.predict(1), contains='Found a single model for all horizons')show_doc(MLForecast.cross_validation)MLForecast.cross_validation
MLForecast.cross_validation (df:Union[pandas.core.frame.DataFrame,polars .dataframe.frame.DataFrame], n_windows:int, h:int, id_col:str='unique_id', time_col:str='ds', target_col:str='y', step_size:Optional[int]=None, static_features:Optional[List[str]]=None, dropna:bool=True, keep_last_n:Optional[int]=None, refit:Union[bool,int]=True, max_horizon:Optional[int]=None, before_predi ct_callback:Optional[Callable]=None, after_p redict_callback:Optional[Callable]=None, pre diction_intervals:Optional[mlforecast.utils. PredictionIntervals]=None, level:Optional[List[Union[int,float]]]=None, input_size:Optional[int]=None, fitted:bool=False, as_numpy:bool=False)
Perform time series cross validation. Creates n_windows splits where each window has h test periods, trains the models, computes the predictions and merges the actuals.
| Type | Default | Details | |
|---|---|---|---|
| df | Union | Series data in long format. | |
| n_windows | int | Number of windows to evaluate. | |
| h | int | Forecast horizon. | |
| id_col | str | unique_id | Column that identifies each serie. |
| time_col | str | ds | Column that identifies each timestep, its values can be timestamps or integers. |
| target_col | str | y | Column that contains the target. |
| step_size | Optional | None | Step size between each cross validation window. If None it will be equal to h. |
| static_features | Optional | None | Names of the features that are static and will be repeated when forecasting. |
| dropna | bool | True | Drop rows with missing values produced by the transformations. |
| keep_last_n | Optional | None | Keep only these many records from each serie for the forecasting step. Can save time and memory if your features allow it. |
| refit | Union | True | Retrain model for each cross validation window. If False, the models are trained at the beginning and then used to predict each window. If positive int, the models are retrained every refit windows. |
| max_horizon | Optional | None | |
| before_predict_callback | Optional | None | Function to call on the features before computing the predictions. This function will take the input dataframe that will be passed to the model for predicting and should return a dataframe with the same structure. The series identifier is on the index. |
| after_predict_callback | Optional | None | Function to call on the predictions before updating the targets. This function will take a pandas Series with the predictions and should return another one with the same structure. The series identifier is on the index. |
| prediction_intervals | Optional | None | Configuration to calibrate prediction intervals (Conformal Prediction). |
| level | Optional | None | Confidence levels between 0 and 100 for prediction intervals. |
| input_size | Optional | None | Maximum training samples per serie in each window. If None, will use an expanding window. |
| fitted | bool | False | Store the in-sample predictions. |
| as_numpy | bool | False | Cast features to numpy array. |
| Returns | Union | Predictions for each window with the series id, timestamp, last train date, target value and predictions from each model. |
如果我们想知道对于特定模型和特征集,我们的预测效果会有多好,那么我们可以进行交叉验证。交叉验证的过程是将我们的数据分成两部分,第一部分用于训练,而第二部分用于验证。由于数据是时间相关的,我们通常会将数据的最后 x 个观察值作为验证集。
这个过程在 MLForecast.cross_validation 中实现,它会使用我们的数据并按照上述过程进行 n_windows 次,其中每个窗口包含 h 个验证样本。例如,如果我们有100个样本,并且我们想每次进行2次大小为14的回测,则拆分如下:
- 训练:1到72。验证:73到86。
- 训练:1到86。验证:87到100。
您可以通过 step_size 参数控制每个交叉验证窗口之间的大小。例如,如果我们有100个样本,并且我们想每次进行2次大小为14的回测,并在每个折中向前移动一步(step_size=1),拆分将如下:
- 训练:1到85。验证:86到99。
- 训练:1到86。验证:87到100。
您还可以通过设置 refit=False 来进行交叉验证,而无需为每个窗口重新拟合模型。这使您能够使用多个窗口大小评估模型的性能,而无需每次都重新训练它们。
fcst = MLForecast(
models=lgb.LGBMRegressor(random_state=0, verbosity=-1),
freq=1,
lags=[24 * (i+1) for i in range(7)],
lag_transforms={
1: [RollingMean(window_size=24)],
24: [RollingMean(window_size=24)],
48: [ExponentiallyWeightedMean(alpha=0.3)],
},
num_threads=1,
target_transforms=[Differences([24])],
)
cv_results = fcst.cross_validation(
train,
n_windows=2,
h=horizon,
step_size=horizon,
fitted=True,
)
cv_results| unique_id | ds | cutoff | y | LGBMRegressor | |
|---|---|---|---|---|---|
| 0 | H196 | 865 | 864 | 15.5 | 15.373393 |
| 1 | H196 | 866 | 864 | 15.1 | 14.973393 |
| 2 | H196 | 867 | 864 | 14.8 | 14.673393 |
| 3 | H196 | 868 | 864 | 14.4 | 14.373393 |
| 4 | H196 | 869 | 864 | 14.2 | 14.073393 |
| ... | ... | ... | ... | ... | ... |
| 379 | H413 | 956 | 912 | 59.0 | 64.284167 |
| 380 | H413 | 957 | 912 | 58.0 | 64.830429 |
| 381 | H413 | 958 | 912 | 53.0 | 40.726851 |
| 382 | H413 | 959 | 912 | 38.0 | 42.739657 |
| 383 | H413 | 960 | 912 | 46.0 | 52.802769 |
384 rows × 5 columns
由于我们设置了 fitted=True,我们也可以通过 cross_validation_fitted_values 方法访问训练集的预测值。
fcst.cross_validation_fitted_values()| unique_id | ds | fold | y | LGBMRegressor | |
|---|---|---|---|---|---|
| 0 | H196 | 193 | 0 | 12.7 | 12.673393 |
| 1 | H196 | 194 | 0 | 12.3 | 12.273393 |
| 2 | H196 | 195 | 0 | 11.9 | 11.873393 |
| 3 | H196 | 196 | 0 | 11.7 | 11.673393 |
| 4 | H196 | 197 | 0 | 11.4 | 11.473393 |
| ... | ... | ... | ... | ... | ... |
| 5563 | H413 | 908 | 1 | 49.0 | 50.620196 |
| 5564 | H413 | 909 | 1 | 39.0 | 35.972331 |
| 5565 | H413 | 910 | 1 | 29.0 | 29.359678 |
| 5566 | H413 | 911 | 1 | 24.0 | 25.784563 |
| 5567 | H413 | 912 | 1 | 20.0 | 23.168413 |
5568 rows × 5 columns
# 测试适配
fcst2 = MLForecast(
models=lgb.LGBMRegressor(n_estimators=5, random_state=0, verbosity=-1),
freq=1,
lags=[24],
num_threads=1,
)
_ = fcst2.cross_validation(
train,
n_windows=2,
h=2,
fitted=True,
refit=False,
)
fitted_cv_results = fcst2.cross_validation_fitted_values()
train_with_cv_fitted_values = train.merge(fitted_cv_results, on=['unique_id', 'ds'], suffixes=('_expected', ''))
np.testing.assert_allclose(
train_with_cv_fitted_values['y_expected'].values,
train_with_cv_fitted_values['y'].values,
)
# 测试最大视野
_ = fcst2.cross_validation(
train,
n_windows=2,
h=2,
fitted=True,
refit=False,
max_horizon=2,
)
max_horizon_fitted_cv_results = fcst2.cross_validation_fitted_values()
pd.testing.assert_frame_equal(
fitted_cv_results[lambda df: df['fold'].eq(0)],
(
max_horizon_fitted_cv_results
[lambda df: df['fold'].eq(0) & df['h'].eq(1)]
.drop(columns='h')
.reset_index(drop=True)
),
)我们还可以通过将配置传递给 prediction_intervals 以及通过 levels 提供宽度的值来计算预测区间。
cv_results_intervals = fcst.cross_validation(
train,
n_windows=2,
h=horizon,
step_size=horizon,
prediction_intervals=PredictionIntervals(h=horizon),
level=[80, 90]
)
cv_results_intervals| unique_id | ds | cutoff | y | LGBMRegressor | LGBMRegressor-lo-90 | LGBMRegressor-lo-80 | LGBMRegressor-hi-80 | LGBMRegressor-hi-90 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | H196 | 865 | 864 | 15.5 | 15.373393 | 15.311379 | 15.316528 | 15.430258 | 15.435407 |
| 1 | H196 | 866 | 864 | 15.1 | 14.973393 | 14.940556 | 14.940556 | 15.006230 | 15.006230 |
| 2 | H196 | 867 | 864 | 14.8 | 14.673393 | 14.606230 | 14.606230 | 14.740556 | 14.740556 |
| 3 | H196 | 868 | 864 | 14.4 | 14.373393 | 14.306230 | 14.306230 | 14.440556 | 14.440556 |
| 4 | H196 | 869 | 864 | 14.2 | 14.073393 | 14.006230 | 14.006230 | 14.140556 | 14.140556 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 379 | H413 | 956 | 912 | 59.0 | 64.284167 | 29.890099 | 34.371545 | 94.196788 | 98.678234 |
| 380 | H413 | 957 | 912 | 58.0 | 64.830429 | 56.874572 | 57.827689 | 71.833169 | 72.786285 |
| 381 | H413 | 958 | 912 | 53.0 | 40.726851 | 35.296195 | 35.846206 | 45.607495 | 46.157506 |
| 382 | H413 | 959 | 912 | 38.0 | 42.739657 | 35.292153 | 35.807640 | 49.671674 | 50.187161 |
| 383 | H413 | 960 | 912 | 46.0 | 52.802769 | 42.465597 | 43.895670 | 61.709869 | 63.139941 |
384 rows × 9 columns
refit 参数允许我们控制是否希望在每个窗口中重新训练模型。它可以是:
- 一个布尔值:True 将在每个窗口上重新训练,而 False 仅在第一个窗口上重新训练。
- 一个正整数:模型将在第一个窗口上训练,然后每隔
refit个窗口训练一次。
fcst = MLForecast(
models=LinearRegression(),
freq=1,
lags=[1, 24],
)
for refit, expected_models in zip([True, False, 2], [4, 1, 2]):
fcst.cross_validation(
train,
n_windows=4,
h=horizon,
refit=refit,
)
test_eq(len(fcst.cv_models_), expected_models)fcst = MLForecast(
models=lgb.LGBMRegressor(random_state=0, verbosity=-1),
freq=1,
lags=[24 * (i+1) for i in range(7)],
lag_transforms={
1: [RollingMean(window_size=24)],
24: [RollingMean(window_size=24)],
48: [ExponentiallyWeightedMean(alpha=0.3)],
},
num_threads=1,
target_transforms=[Differences([24])],
)
cv_results_no_refit = fcst.cross_validation(
train,
n_windows=2,
h=horizon,
step_size=horizon,
refit=False
)
# 测试我们恢复相同 "metadata"
test_eq(
cv_results_no_refit.drop(columns='LGBMRegressor'),
cv_results.drop(columns='LGBMRegressor')
)
# 测试第一个窗口的预测结果是否相同
first_cutoff = cv_results['cutoff'].iloc[0]
test_eq(
cv_results_no_refit.query('cutoff == @first_cutoff'),
cv_results.query('cutoff == @first_cutoff')
)
# 测试下一个窗口有不同的预测
test_ne(
cv_results_no_refit.query('cutoff != @first_cutoff'),
cv_results.query('cutoff != @first_cutoff')
)# 输入尺寸为
input_size = 300
cv_results_input_size = fcst.cross_validation(
train,
n_windows=2,
h=horizon,
step_size=horizon,
input_size=input_size,
)
series_lengths = np.diff(fcst.ts.ga.indptr)
unique_lengths = np.unique(series_lengths)
assert unique_lengths.size == 1
assert unique_lengths[0] == input_size# 每个地平线一个模型
cv_results2 = fcst.cross_validation(
train,
n_windows=2,
h=horizon,
step_size=horizon,
max_horizon=horizon,
)
# 每个id和窗口的第一个条目是相同的
pd.testing.assert_frame_equal(
cv_results.groupby(['unique_id', 'cutoff']).head(1),
cv_results2.groupby(['unique_id', 'cutoff']).head(1)
)
# 其余的则不同
test_fail(lambda: pd.testing.assert_frame_equal(cv_results, cv_results2))# 每个时间范围一个模型,并带有预测区间
cv_results2_intervals = fcst.cross_validation(
train,
n_windows=2,
h=horizon,
step_size=horizon,
max_horizon=horizon,
prediction_intervals=PredictionIntervals(n_windows=2, h=horizon),
level=[80, 90]
)
# 每个id和窗口的第一个条目是相同的
pd.testing.assert_frame_equal(
cv_results_intervals.groupby(['unique_id', 'cutoff']).head(1),
cv_results2_intervals.groupby(['unique_id', 'cutoff']).head(1)
)
# 其余的则不同
test_fail(lambda: pd.testing.assert_frame_equal(cv_results_intervals, cv_results2_intervals))# 错误频率引发错误
df_wrong_freq = pd.DataFrame({'ds': pd.to_datetime(['2020-01-02', '2020-02-02', '2020-03-02', '2020-04-02'])})
df_wrong_freq['unique_id'] = 'id1'
df_wrong_freq['y'] = 1
fcst_wrong_freq = MLForecast(
models=[LinearRegression()],
freq='MS',
lags=[1],
)
test_fail(
lambda: fcst_wrong_freq.cross_validation(df_wrong_freq, n_windows=1, h=1),
contains='Cross validation result produced less results than expected',
)fig = plot_series(forecasts_df=cv_results.drop(columns='cutoff'))fig.savefig('figs/forecast__cross_validation.png', bbox_inches='tight')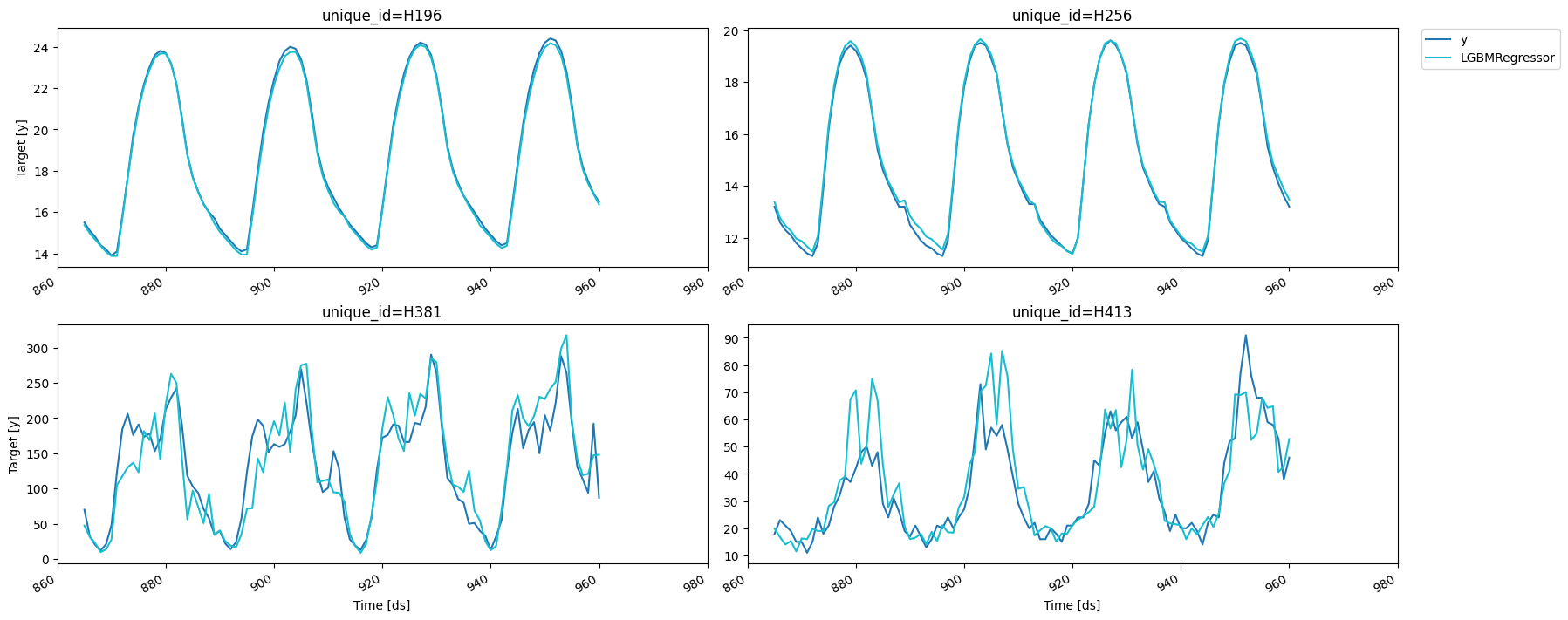
fig = plot_series(forecasts_df=cv_results_intervals.drop(columns='cutoff'), level=[90])fig.savefig('figs/forecast__cross_validation_intervals.png', bbox_inches='tight')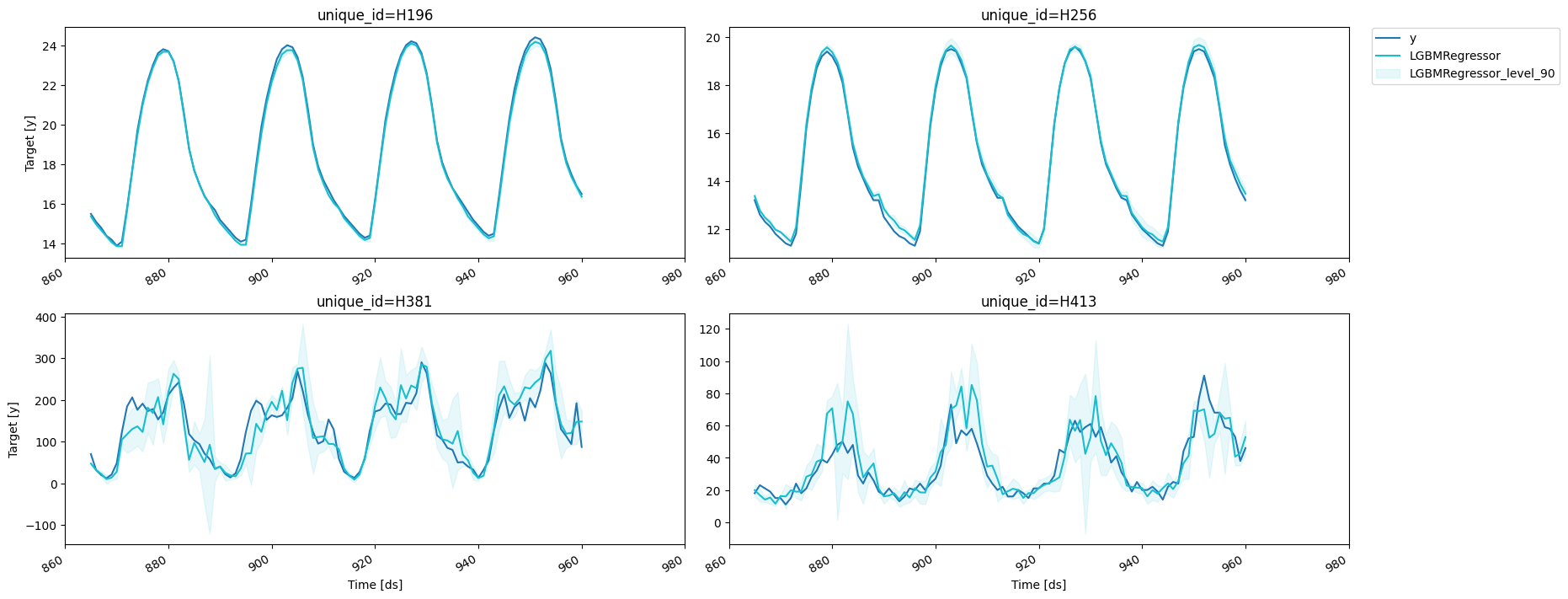
show_doc(MLForecast.from_cv)一旦您找到了适合您问题的一组特征和参数,您可以使用 MLForecast.from_cv 从中构建一个预测对象,该函数接受训练好的 LightGBMCV 对象,并构建一个将使用相同特征和参数的 MLForecast 对象。然后,您可以像往常一样调用 fit 和 predict。
cv = LightGBMCV(
freq=1,
lags=[24 * (i+1) for i in range(7)],
lag_transforms={
48: [ExponentiallyWeightedMean(alpha=0.3)],
},
num_threads=1,
target_transforms=[Differences([24])]
)
hist = cv.fit(
train,
n_windows=2,
h=horizon,
params={'verbosity': -1},
)[LightGBM] [Info] Start training from score 0.084340
[10] mape: 0.118569
[20] mape: 0.111506
[30] mape: 0.107314
[40] mape: 0.106089
[50] mape: 0.106630
Early stopping at round 50
Using best iteration: 40fcst = MLForecast.from_cv(cv)
assert cv.best_iteration_ == fcst.models['LGBMRegressor'].n_estimatorsseries = generate_daily_series(100, equal_ends=True, n_static_features=2, static_as_categorical=False)
non_std_series = series.copy()
non_std_series['ds'] = non_std_series.groupby('unique_id', observed=True).cumcount()
non_std_series = non_std_series.rename(columns={'unique_id': 'some_id', 'ds': 'time', 'y': 'value'})
models = [
lgb.LGBMRegressor(n_jobs=1, random_state=0, verbosity=-1),
xgb.XGBRegressor(n_jobs=1, random_state=0),
]
flow_params = dict(
models=models,
lags=[7],
lag_transforms={
1: [ExpandingMean()],
7: [RollingMean(window_size=14)]
},
num_threads=2,
)
fcst = MLForecast(freq=1, **flow_params)
non_std_preds = fcst.fit(non_std_series, id_col='some_id', time_col='time', target_col='value').predict(7)
non_std_preds = non_std_preds.rename(columns={'some_id': 'unique_id'})
fcst = MLForecast(freq='D', **flow_params)
preds = fcst.fit(series).predict(7)
pd.testing.assert_frame_equal(preds.drop(columns='ds'), non_std_preds.drop(columns='time'))def test_cross_validation(data=non_std_series, add_exogenous=False):
n_windows = 2
h = 14
fcst = MLForecast(lgb.LGBMRegressor(verbosity=-1), freq=1, lags=[7, 14])
if add_exogenous:
data = data.assign(ex1 = lambda x: np.arange(0, len(x)))
with warnings.catch_warnings():
warnings.filterwarnings('ignore', category=DeprecationWarning)
backtest_results = fcst.cross_validation(
df=data,
n_windows=n_windows,
h=h,
id_col='some_id',
time_col='time',
target_col='value',
static_features=['some_id', 'static_0', 'static_1'],
)
renamer = {'some_id': 'unique_id', 'time': 'ds', 'value': 'y'}
backtest_results = backtest_results.rename(columns=renamer)
renamed = data.rename(columns=renamer)
manual_results = []
for cutoff, train, valid in ufp.backtest_splits(renamed, n_windows, h, 'unique_id', 'ds', 1):
fcst.fit(train, static_features=['unique_id', 'static_0', 'static_1'])
if add_exogenous:
X_df = valid.drop(columns=['y', 'static_0', 'static_1']).reset_index()
else:
X_df = None
pred = fcst.predict(h, X_df=X_df)
res = valid[['unique_id', 'ds', 'y']].copy()
res = res.merge(cutoff, on='unique_id')
res = res[['unique_id', 'ds', 'cutoff', 'y']].copy()
manual_results.append(res.merge(pred, on=['unique_id', 'ds'], how='left'))
manual_results = pd.concat(manual_results)
pd.testing.assert_frame_equal(backtest_results, manual_results.reset_index(drop=True))
test_cross_validation()
test_cross_validation(add_exogenous=True)# 在简历中测试简短系列
series = generate_daily_series(
n_series=100, min_length=20, max_length=51, equal_ends=True,
)
horizon = 10
n_windows = 4
fcst = MLForecast(models=[LinearRegression()], freq='D', lags=[1])
cv_res = fcst.cross_validation(series, h=horizon, n_windows=n_windows)
series_per_cutoff = cv_res.groupby('cutoff')['unique_id'].nunique()
series_sizes = series['unique_id'].value_counts().sort_index()
for i in range(4):
test_eq(series_per_cutoff.iloc[i], series_sizes.gt((n_windows - i) * horizon).sum())#| 极地
from itertools import product
import polars as pl
from utilsforecast.processing import match_if_categorical
from mlforecast.utils import generate_prices_for_series#| 极地
horizon = 2
series_pl = generate_daily_series(
10, n_static_features=2, static_as_categorical=False, equal_ends=True, engine='polars'
)
series_pd = generate_daily_series(
10, n_static_features=2, static_as_categorical=False, equal_ends=True, engine='pandas'
)
series_pd = series_pd.rename(columns={'static_0': 'product_id'})
prices_pd = generate_prices_for_series(series_pd, horizon)
prices_pd['unique_id'] = prices_pd['unique_id'].astype(series_pd['unique_id'].dtype)
series_pd = series_pd.merge(prices_pd, on=['unique_id', 'ds'])
prices_pl = pl.from_pandas(prices_pd)
uids_series, uids_prices = match_if_categorical(series_pl['unique_id'], prices_pl['unique_id'])
series_pl = series_pl.with_columns(uids_series)
prices_pl = prices_pl.with_columns(uids_prices)
series_pl = series_pl.rename({'static_0': 'product_id'}).join(prices_pl, on=['unique_id', 'ds'])
permutation = np.random.choice(series_pl.shape[0], series_pl.shape[0], replace=False)
series_pl = series_pl[permutation]
series_pd = series_pd.iloc[permutation]
cfg = dict(
models=[LinearRegression(), lgb.LGBMRegressor(verbosity=-1)],
freq='1d',
lags=[1, 2],
lag_transforms={
1: [ExpandingMean()],
2: [ExpandingMean()],
},
date_features=['day', 'month', 'week', 'year'],
target_transforms=[Differences([1, 2]), LocalStandardScaler()],
)
fit_kwargs = dict(
fitted=True,
prediction_intervals=PredictionIntervals(h=horizon),
static_features=['product_id', 'static_1'],
)
predict_kwargs = dict(
h=2,
level=[80, 95],
)
horizons = [None, horizon]
as_np = [True, False]
for max_horizon, as_numpy in product(horizons, as_np):
fcst_pl = MLForecast(**cfg)
fcst_pl.fit(series_pl, max_horizon=max_horizon, as_numpy=as_numpy, **fit_kwargs)
fitted_pl = fcst_pl.forecast_fitted_values()
preds_pl = fcst_pl.predict(X_df=prices_pl, **predict_kwargs)
preds_pl_subset = fcst_pl.predict(X_df=prices_pl, ids=fcst_pl.ts.uids[[0, 6]], **predict_kwargs)
cv_pl = fcst_pl.cross_validation(
series_pl, n_windows=2, h=horizon, fitted=True, static_features=['product_id', 'static_1'], as_numpy=as_numpy
)
cv_fitted_pl = fcst_pl.cross_validation_fitted_values()
fcst_pd = MLForecast(**cfg)
fcst_pd.fit(series_pd, max_horizon=max_horizon, as_numpy=as_numpy, **fit_kwargs)
fitted_pd = fcst_pd.forecast_fitted_values()
preds_pd = fcst_pd.predict(X_df=prices_pd, **predict_kwargs)
preds_pd_subset = fcst_pd.predict(X_df=prices_pd, ids=fcst_pd.ts.uids[[0, 6]], **predict_kwargs)
assert preds_pd_subset['unique_id'].unique().tolist() == ['id_0', 'id_6']
cv_pd = fcst_pd.cross_validation(
series_pd, n_windows=2, h=horizon, fitted=True, static_features=['product_id', 'static_1'], as_numpy=as_numpy
)
cv_fitted_pd = fcst_pd.cross_validation_fitted_values()
if max_horizon is not None:
fitted_pl = fitted_pl.with_columns(pl.col('h').cast(pl.Int64))
for h in range(max_horizon):
fitted_h = fitted_pl.filter(pl.col('h').eq(h + 1))
series_offset = (
series_pl
.sort('unique_id', 'ds')
.with_columns(pl.col('y').shift(-h).over('unique_id'))
)
series_filtered = (
fitted_h
[['unique_id', 'ds']]
.join(series_offset, on=['unique_id', 'ds'])
.sort(['unique_id', 'ds'])
)
np.testing.assert_allclose(
series_filtered['y'],
fitted_h['y']
)
else:
series_filtered = (
fitted_pl
[['unique_id', 'ds']]
.join(series_pl, on=['unique_id', 'ds'])
.sort(['unique_id', 'ds'])
)
np.testing.assert_allclose(
series_filtered['y'],
fitted_pl['y']
)
pd.testing.assert_frame_equal(fitted_pl.to_pandas(), fitted_pd)
pd.testing.assert_frame_equal(preds_pl.to_pandas(), preds_pd)
pd.testing.assert_frame_equal(preds_pl_subset.to_pandas(), preds_pd_subset)
pd.testing.assert_frame_equal(cv_pl.to_pandas(), cv_pd)
pd.testing.assert_frame_equal(
cv_fitted_pl.with_columns(pl.col('fold').cast(pl.Int64)).to_pandas(),
cv_fitted_pd,
)# 当序列被删除时,测试转换被正确地反转
series = generate_daily_series(10, min_length=5, max_length=20)
fcst = MLForecast(
models=LinearRegression(),
freq='D',
lags=[10],
target_transforms=[Differences([1]), LocalStandardScaler()],
)
fcst.fit(series, fitted=True)
assert fcst.ts._dropped_series.size > 0
fitted_vals = fcst.forecast_fitted_values()
full = fitted_vals.merge(series, on=['unique_id', 'ds'], suffixes=('_fitted', '_orig'))
np.testing.assert_allclose(
full['y_fitted'].values,
full['y_orig'].values,
)# 保存与加载
series = generate_daily_series(10)
fcst = MLForecast(
models=LinearRegression(),
freq='D',
lags=[10],
target_transforms=[Differences([1]), LocalStandardScaler()],
)
fcst.fit(series)
preds = fcst.predict(10)
with tempfile.TemporaryDirectory() as tmpdir:
savedir = Path(tmpdir) / 'fcst'
savedir.mkdir()
fcst.save(savedir)
fcst2 = MLForecast.load(savedir)
preds2 = fcst2.predict(10)
pd.testing.assert_frame_equal(preds, preds2)Give us a ⭐ on Github