
NumPy:初学者的绝对基础#
欢迎阅读 NumPy 的绝对初学者指南!
NumPy (Numerical Python) 是一个开源的Python库,广泛应用于科学和工程领域.NumPy库包含多维数组数据结构,例如同质的N维``ndarray``,以及大量高效操作这些数据结构的函数库.了解更多关于NumPy的信息,请参阅 什么是NumPy,如果您有评论或建议,请 联系我们!
如何导入 NumPy#
在 安装 NumPy 之后,可以像这样将其导入到 Python 代码中:
import numpy as np
这种广泛使用的约定允许通过一个简短且易于识别的前缀 (np.) 访问 NumPy 功能,同时将 NumPy 功能与其他同名功能区分开来.
阅读示例代码#
在整个 NumPy 文档中,您会找到看起来像这样的块:
>>> a = np.array([[1, 2, 3],
... [4, 5, 6]])
>>> a.shape
(2, 3)
前面带有 >>> 或 ... 的文本是 输入 ,即你会在脚本中或 Python 提示符下输入的代码.其他所有内容都是 输出 ,即运行你的代码的结果.请注意,``>>>`` 和 ... 不是代码的一部分,如果在 Python 提示符下输入可能会导致错误.
为什么使用 NumPy?#
Python 列表是非常优秀的、通用的容器.它们可以是”异构的”,这意味着它们可以包含各种类型的元素,并且在对少数元素执行单个操作时速度相当快.
根据数据的特性和需要执行的操作类型,其他容器可能更合适;通过利用这些特性,我们可以提高速度、减少内存消耗,并提供一种高级语法来执行各种常见的处理任务.当需要在 CPU 上处理大量”同质”(相同类型)数据时,NumPy 表现出色.
什么是”数组”?#
在计算机编程中,数组是一种用于存储和检索数据的结构.我们经常将数组描述为空间中的一个网格,每个单元格存储一个数据元素.例如,如果每个数据元素都是一个数字,我们可能会将一个”一维”数组可视化为一个列表:
二维数组就像一个表格:
一个三维数组就像一组表格,可能像打印在不同页面上一样堆叠.在NumPy中,这个概念被推广到任意数量的维度,因此基本的数组类被称为 ndarray:它表示一个”N维数组”.
大多数 NumPy 数组有一些限制.例如:
数组的所有元素必须是相同类型的数据.
一旦创建,数组的总大小就不能改变.
形状必须是”矩形”,而不是”锯齿状”;例如,二维数组的每一行必须具有相同数量的列.
当这些条件满足时,NumPy 利用这些特性使数组更快、内存效率更高,并且比限制较少的数据结构更方便使用.
在本文档的其余部分,我们将使用”数组”一词来指代 ndarray 的实例.
数组基础#
初始化数组的一种方法是使用 Python 序列,例如列表.例如:
>>> a = np.array([1, 2, 3, 4, 5, 6])
>>> a
array([1, 2, 3, 4, 5, 6])
数组的元素可以通过 多种方式 访问.例如,我们可以像访问原始列表中的元素一样访问数组的单个元素:使用方括号内的元素整数索引.
>>> a[0]
1
备注
与内置的 Python 序列一样,NumPy 数组是”0 索引”的:数组的第一个元素使用索引 0 访问,而不是 1.
像原始列表一样,数组是可变的.
>>> a[0] = 10
>>> a
array([10, 2, 3, 4, 5, 6])
与原始列表类似,Python 切片表示法也可以用于索引.
>>> a[:3]
array([10, 2, 3])
一个主要的区别是,列表的切片索引会将元素复制到一个新列表中,但切片数组会返回一个 视图:一个引用原始数组中数据的对象.可以通过视图修改原始数组.
>>> b = a[3:]
>>> b
array([4, 5, 6])
>>> b[0] = 40
>>> a
array([ 10, 2, 3, 40, 5, 6])
有关数组操作何时返回视图而不是副本的更全面解释,请参见 副本和视图.
二维及更高维的数组可以通过嵌套的 Python 序列进行初始化:
>>> a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
>>> a
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
在NumPy中,数组的一个维度有时被称为”轴”.这种术语可能有助于区分数组的维度和数组所表示数据的维度.例如,数组 a 可以表示三个点,每个点位于四维空间中,但 a 只有两个”轴”.
数组和列表列表之间的另一个区别是,可以通过在一组方括号内指定沿每个轴的索引(用逗号分隔)来访问数组的元素.例如,元素 8 位于第 1 行和第 3 列:
>>> a[1, 3]
8
备注
在数学中,习惯上先通过行索引再通过列索引引用矩阵的元素.对于二维数组来说,这是正确的,但更好的思维模型是认为列索引*最后*出现,行索引*倒数第二*.这可以推广到具有*任意*维数的数组.
备注
你可能会听到一个 0-D(零维)数组被称为”标量”,一个 1-D(一维)数组被称为”向量”,一个 2-D(二维)数组被称为”矩阵”,或者一个 N-D(N维,其中”N”通常是一个大于2的整数)数组被称为”张量”.为了清楚起见,最好避免在提及数组时使用这些数学术语,因为具有这些名称的数学对象的行为与数组不同(例如,”矩阵”乘法与”数组”乘法根本不同),并且在科学 Python 生态系统中还有其他具有这些名称的对象(例如,PyTorch 的基本数据结构是”张量”).
数组属性#
本节涵盖了数组的 ndim, shape, size, 和 dtype 属性.
数组的维度数量包含在 ndim 属性中.
>>> a.ndim
2
数组的形状是一个非负整数的元组,指定沿每个维度的元素数量.
>>> a.shape
(3, 4)
>>> len(a.shape) == a.ndim
True
数组中固定元素的总数包含在 size 属性中.
>>> a.size
12
>>> import math
>>> a.size == math.prod(a.shape)
True
数组通常是”同质的”,这意味着它们只包含一种”数据类型”的元素.数据类型记录在 dtype 属性中.
>>> a.dtype
dtype('int64') # "int" for integer, "64" for 64-bit
在这里阅读更多关于数组属性的信息 并了解 数组对象的信息.
如何创建一个基本数组#
本节涵盖 np.zeros(), np.ones(), np.empty(), np.arange(), np.linspace()
除了从一系列元素创建数组外,您还可以轻松创建一个填充了 0 的数组:
>>> np.zeros(2)
array([0., 0.])
或者一个充满 1 的数组:
>>> np.ones(2)
array([1., 1.])
或者甚至是一个空数组!函数 empty 创建一个初始内容随机且取决于内存状态的数组.使用 empty 而不是 zeros (或类似的东西)的原因是速度 - 只需确保之后填充每个元素!
>>> # Create an empty array with 2 elements
>>> np.empty(2)
array([3.14, 42. ]) # may vary
你可以用一系列元素创建一个数组:
>>> np.arange(4)
array([0, 1, 2, 3])
甚至可以包含一个包含一系列均匀间隔区间的数组.为此,您需要指定 第一个数字、最后一个数字 和 步长.:
>>> np.arange(2, 9, 2)
array([2, 4, 6, 8])
你也可以使用 np.linspace() 来创建一个在指定区间内线性间隔的数组:
>>> np.linspace(0, 10, num=5)
array([ 0. , 2.5, 5. , 7.5, 10. ])
指定您的数据类型
虽然默认的数据类型是浮点型 (np.float64),你可以使用 dtype 关键字明确指定你想要的数据类型.:
>>> x = np.ones(2, dtype=np.int64)
>>> x
array([1, 1])
添加、删除和排序元素#
本节涵盖 np.sort(), np.concatenate()
使用 np.sort() 对数组进行排序很简单.调用函数时,可以指定轴、种类和顺序.
如果你从这个数组开始:
>>> arr = np.array([2, 1, 5, 3, 7, 4, 6, 8])
你可以快速将数字按升序排序:
>>> np.sort(arr)
array([1, 2, 3, 4, 5, 6, 7, 8])
除了返回数组排序副本的 sort 之外,你还可以使用:
argsort,这是一个沿着指定轴的间接排序,lexsort是一个对多个键进行间接稳定排序的函数searchsorted,它将在排序后的数组中查找元素,并且partition是一个部分排序.
要了解更多关于排序数组的信息,请参见:sort.
如果你从这些数组开始:
>>> a = np.array([1, 2, 3, 4])
>>> b = np.array([5, 6, 7, 8])
你可以使用 np.concatenate() 来连接它们.:
>>> np.concatenate((a, b))
array([1, 2, 3, 4, 5, 6, 7, 8])
或者,如果你从这些数组开始:
>>> x = np.array([[1, 2], [3, 4]])
>>> y = np.array([[5, 6]])
你可以用以下方式连接它们:
>>> np.concatenate((x, y), axis=0)
array([[1, 2],
[3, 4],
[5, 6]])
要从数组中删除元素,使用索引选择要保留的元素很简单.
要了解更多关于连接的信息,请参见:concatenate.
你如何知道数组的形状和大小?#
本节涵盖 ndarray.ndim, ndarray.size, ndarray.shape
ndarray.ndim 将告诉你数组的轴数,或维度.
ndarray.size 将告诉你数组中元素的总数.这是数组形状元素的*乘积*.
ndarray.shape 将显示一个整数的元组,这些整数表示沿数组每个维度存储的元素数量.例如,如果你有一个2行3列的2-D数组,你的数组的形状是 (2, 3).
例如,如果你创建这个数组:
>>> array_example = np.array([[[0, 1, 2, 3],
... [4, 5, 6, 7]],
...
... [[0, 1, 2, 3],
... [4, 5, 6, 7]],
...
... [[0 ,1 ,2, 3],
... [4, 5, 6, 7]]])
要找到数组的维度数量,请运行:
>>> array_example.ndim
3
要找到数组中元素的总数,请运行:
>>> array_example.size
24
要找到数组的形状,请运行:
>>> array_example.shape
(3, 2, 4)
你能重塑一个数组吗?#
本节涵盖 arr.reshape()
Yes!
使用 arr.reshape() 会给数组一个新的形状,而不改变数据.只需记住,当你使用 reshape 方法时,你想要生成的数组需要与原数组具有相同数量的元素.如果你从一个有 12 个元素的数组开始,你需要确保你的新数组也有总共 12 个元素.
如果你从这个数组开始:
>>> a = np.arange(6)
>>> print(a)
[0 1 2 3 4 5]
你可以使用 reshape() 来重塑你的数组.例如,你可以将这个数组重塑为一个有三行两列的数组:
>>> b = a.reshape(3, 2)
>>> print(b)
[[0 1]
[2 3]
[4 5]]
使用 np.reshape,你可以指定一些可选参数:
>>> np.reshape(a, shape=(1, 6), order='C')
array([[0, 1, 2, 3, 4, 5]])
a 是要重塑的数组.
newshape 是你想要的新形状.你可以指定一个整数或一个整数元组.如果你指定一个整数,结果将是一个该长度的数组.形状应与原始形状兼容.
order: C 意味着使用类似C的索引顺序读取/写入元素,``F`` 意味着使用类似Fortran的索引顺序读取/写入元素,``A`` 意味着如果a在内存中是Fortran连续的,则使用类似Fortran的索引顺序读取/写入元素,否则使用类似C的顺序.(这是一个可选参数,不需要指定.)
如果你想了解更多关于 C 和 Fortran 顺序的信息,你可以 在这里阅读更多关于 NumPy 数组内部组织的内容.本质上,C 和 Fortran 顺序与索引如何对应数组在内存中的存储顺序有关.在 Fortran 中,当在内存中移动二维数组的元素时,**第一个**索引是变化最快的索引.随着第一个索引的变化移动到下一行,矩阵按列存储.这就是为什么 Fortran 被认为是一种 列优先语言.而在 C 语言中,**最后一个**索引变化最快.矩阵按行存储,使其成为一种 行优先语言.你选择 C 或 Fortran 取决于是否更重要的保留索引约定或不重新排序数据.
如何将一维数组转换为二维数组(如何向数组添加新轴)#
本节涵盖 np.newaxis, np.expand_dims
你可以使用 np.newaxis 和 np.expand_dims 来增加你现有数组的维度.
使用 np.newaxis 会在使用一次时将数组的维度增加一个维度.这意味着一个 1D 数组将变成一个 2D 数组,一个 2D 数组将变成一个 3D 数组,依此类推.
例如,如果你从这个数组开始:
>>> a = np.array([1, 2, 3, 4, 5, 6])
>>> a.shape
(6,)
你可以使用 np.newaxis 来添加一个新的轴:
>>> a2 = a[np.newaxis, :]
>>> a2.shape
(1, 6)
你可以使用 np.newaxis 显式地将一维数组转换为行向量或列向量.例如,你可以通过在第一个维度上插入一个轴将一维数组转换为行向量:
>>> row_vector = a[np.newaxis, :]
>>> row_vector.shape
(1, 6)
或者,对于一个列向量,你可以在第二个维度上插入一个轴:
>>> col_vector = a[:, np.newaxis]
>>> col_vector.shape
(6, 1)
你也可以通过在指定位置插入一个新的轴来扩展一个数组,使用 np.expand_dims.
例如,如果你从这个数组开始:
>>> a = np.array([1, 2, 3, 4, 5, 6])
>>> a.shape
(6,)
你可以使用 np.expand_dims 在索引位置1添加一个轴,如下所示:
>>> b = np.expand_dims(a, axis=1)
>>> b.shape
(6, 1)
你可以在索引位置0处添加一个轴,使用如下:
>>> c = np.expand_dims(a, axis=0)
>>> c.shape
(1, 6)
更多关于 newaxis 的信息 和 expand_dims 请参见 expand_dims.
索引和切片#
你可以用切片Python列表的方式来索引和切片NumPy数组.:
>>> data = np.array([1, 2, 3])
>>> data[1]
2
>>> data[0:2]
array([1, 2])
>>> data[1:]
array([2, 3])
>>> data[-2:]
array([2, 3])
你可以这样理解它:

你可能希望提取数组的一部分或特定的数组元素,以便在进一步分析或额外操作中使用.为此,你需要对数组进行子集化、切片和/或索引.
如果你想从数组中选择满足某些条件的值,使用 NumPy 非常简单.
例如,如果你从这个数组开始:
>>> a = np.array([[1 , 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
你可以轻松打印数组中小于 5 的所有值.:
>>> print(a[a < 5])
[1 2 3 4]
你也可以选择,例如,等于或大于5的数字,并使用该条件来索引一个数组.:
>>> five_up = (a >= 5)
>>> print(a[five_up])
[ 5 6 7 8 9 10 11 12]
你可以选择能被2整除的元素:
>>> divisible_by_2 = a[a%2==0]
>>> print(divisible_by_2)
[ 2 4 6 8 10 12]
或者你可以使用 & 和 | 运算符选择满足两个条件的元素:
>>> c = a[(a > 2) & (a < 11)]
>>> print(c)
[ 3 4 5 6 7 8 9 10]
你也可以使用逻辑运算符 & 和 | 来返回布尔值,这些值指定数组中的值是否满足某个条件.这对于包含名称或其他分类值的数组非常有用.:
>>> five_up = (a > 5) | (a == 5)
>>> print(five_up)
[[False False False False]
[ True True True True]
[ True True True True]]
你也可以使用 np.nonzero() 从数组中选择元素或索引.
从以下数组开始:
>>> a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
你可以使用 np.nonzero() 来打印元素的索引,例如,小于 5 的元素:
>>> b = np.nonzero(a < 5)
>>> print(b)
(array([0, 0, 0, 0]), array([0, 1, 2, 3]))
在这个例子中,返回了一个数组的元组:每个维度一个.第一个数组表示找到这些值的行索引,第二个数组表示找到这些值的列索引.
如果你想生成一个元素存在的坐标列表,你可以压缩数组,遍历坐标列表,并打印它们.例如:
>>> list_of_coordinates= list(zip(b[0], b[1]))
>>> for coord in list_of_coordinates:
... print(coord)
(np.int64(0), np.int64(0))
(np.int64(0), np.int64(1))
(np.int64(0), np.int64(2))
(np.int64(0), np.int64(3))
你也可以使用 np.nonzero() 来打印数组中小于 5 的元素,如下所示:
>>> print(a[b])
[1 2 3 4]
如果你要找的元素在数组中不存在,那么返回的索引数组将是空的.例如:
>>> not_there = np.nonzero(a == 42)
>>> print(not_there)
(array([], dtype=int64), array([], dtype=int64))
了解更多关于使用 nonzero 函数的信息:nonzero.
如何从现有数据创建数组#
本节涵盖 切片和索引, np.vstack(), np.hstack(), np.hsplit(), .view(), copy()
你可以轻松地从现有数组的一部分创建一个新数组.
假设你有一个这样的数组:
>>> a = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
你可以通过指定你想切片的数组部分,随时从你的数组中创建一个新的数组.:
>>> arr1 = a[3:8]
>>> arr1
array([4, 5, 6, 7, 8])
在这里,你从索引位置3到索引位置8抓取了数组的一部分.
你也可以将两个现有的数组堆叠在一起,无论是垂直还是水平.假设你有两个数组,``a1`` 和 a2:
>>> a1 = np.array([[1, 1],
... [2, 2]])
>>> a2 = np.array([[3, 3],
... [4, 4]])
你可以使用 vstack 垂直堆叠它们:
>>> np.vstack((a1, a2))
array([[1, 1],
[2, 2],
[3, 3],
[4, 4]])
或者使用 hstack 将它们水平堆叠:
>>> np.hstack((a1, a2))
array([[1, 1, 3, 3],
[2, 2, 4, 4]])
你可以使用 hsplit 将一个数组分割成几个较小的数组.你可以指定返回的等形状数组的数量,或者指定分割应发生的*之后*的列.
假设你有这个数组:
>>> x = np.arange(1, 25).reshape(2, 12)
>>> x
array([[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12],
[13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24]])
如果你想将这个数组分成三个形状相同的数组,你可以运行:
>>> np.hsplit(x, 3)
[array([[ 1, 2, 3, 4],
[13, 14, 15, 16]]), array([[ 5, 6, 7, 8],
[17, 18, 19, 20]]), array([[ 9, 10, 11, 12],
[21, 22, 23, 24]])]
如果你想在第三列和第四列之后拆分你的数组,你可以运行:
>>> np.hsplit(x, (3, 4))
[array([[ 1, 2, 3],
[13, 14, 15]]), array([[ 4],
[16]]), array([[ 5, 6, 7, 8, 9, 10, 11, 12],
[17, 18, 19, 20, 21, 22, 23, 24]])]
你可以使用 view 方法来创建一个与原始数组查看相同数据的新数组对象(一个 浅拷贝).
视图是NumPy的一个重要概念!NumPy函数以及像索引和切片这样的操作,只要有可能,都会返回视图.这节省了内存并且速度更快(不需要复制数据).然而,意识到这一点很重要——修改视图中的数据也会修改原始数组!
假设你创建了这个数组:
>>> a = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
现在我们通过切片 a 创建一个数组 b1 并修改 b1 的第一个元素.这也会修改 a 中对应的元素!:
>>> b1 = a[0, :]
>>> b1
array([1, 2, 3, 4])
>>> b1[0] = 99
>>> b1
array([99, 2, 3, 4])
>>> a
array([[99, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
使用 copy 方法将创建数组及其数据的完整副本(深度复制).要在您的数组上使用此方法,您可以运行:
>>> b2 = a.copy()
基本数组操作#
本节涵盖加法、减法、乘法、除法等内容
一旦你创建了你的数组,你就可以开始使用它们了.比如说,你创建了两个数组,一个叫做”data”,另一个叫做”ones”
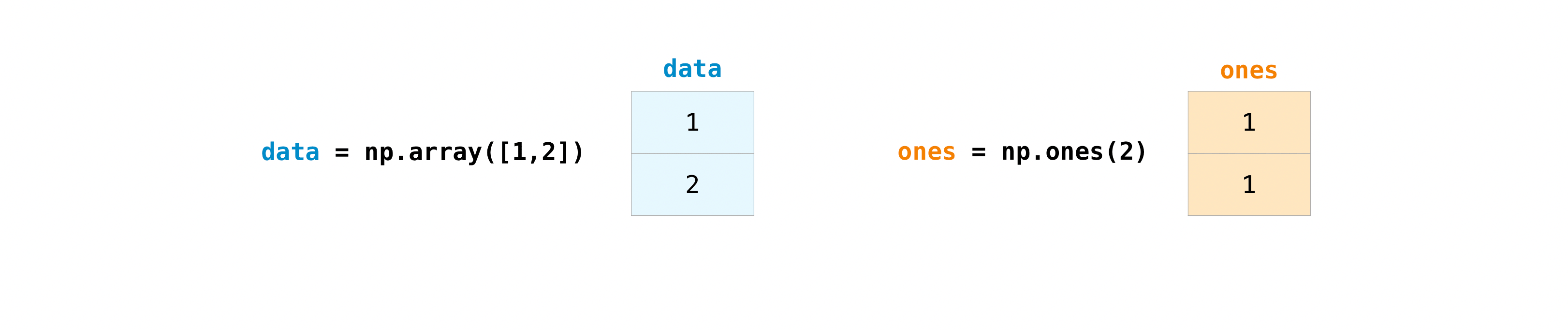
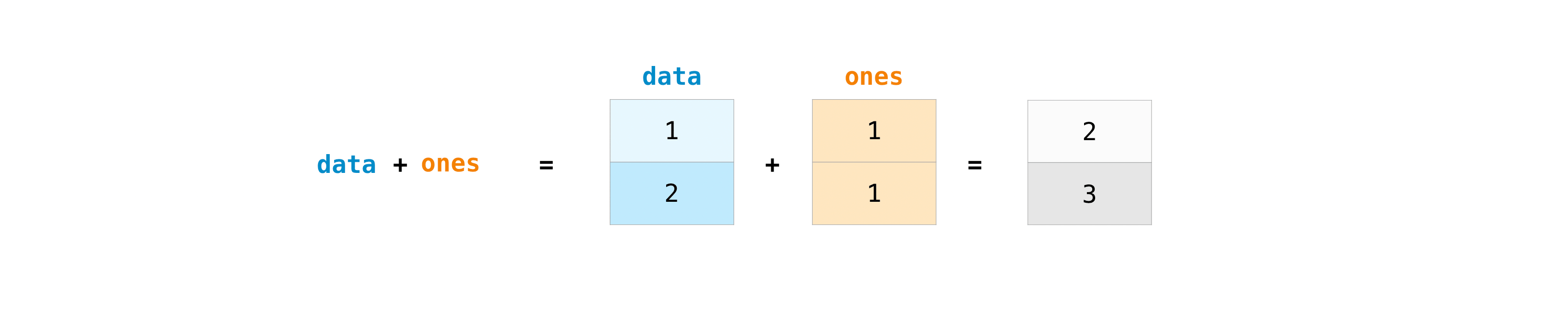
你可以使用加号将数组相加.
>>> data = np.array([1, 2])
>>> ones = np.ones(2, dtype=int)
>>> data + ones
array([2, 3])
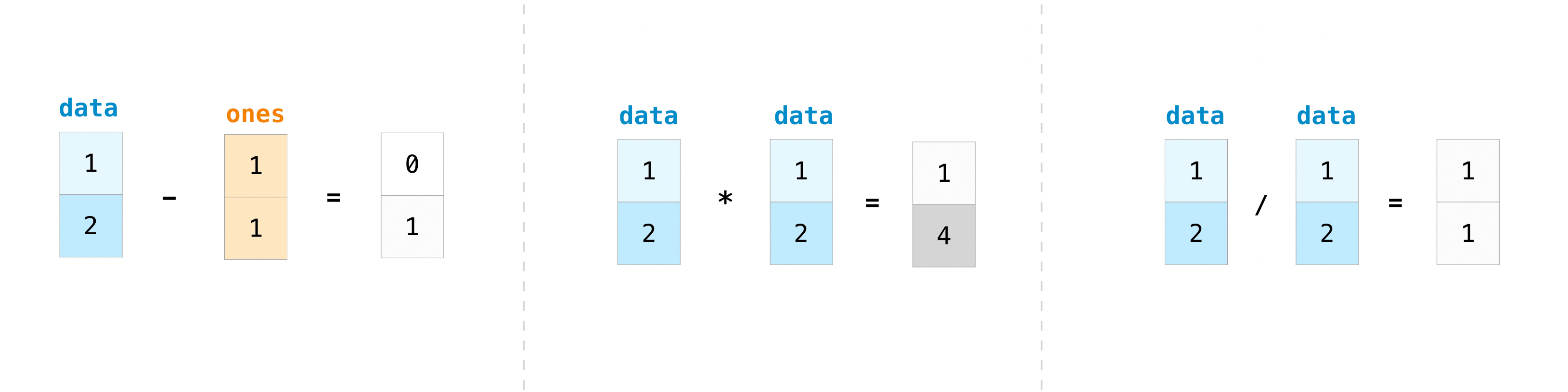
当然,你可以做的不仅仅是加法!
>>> data - ones
array([0, 1])
>>> data * data
array([1, 4])
>>> data / data
array([1., 1.])
使用 NumPy 进行基本操作很简单.如果你想找到数组中元素的总和,你会使用 sum().这适用于一维数组、二维数组和更高维度的数组.:
>>> a = np.array([1, 2, 3, 4])
>>> a.sum()
10
要在二维数组中添加行或列,您需要指定轴.
如果你从这个数组开始:
>>> b = np.array([[1, 1], [2, 2]])
你可以通过以下方式对行轴进行求和:
>>> b.sum(axis=0)
array([3, 3])
你可以通过以下方式对列轴进行求和:
>>> b.sum(axis=1)
array([2, 4])
广播#
有时你可能希望在数组和单个数字(也称为*向量和标量之间的操作*)或两个不同大小的数组之间执行操作.例如,你的数组(我们称之为”data”)可能包含以英里为单位的距离信息,但你希望将其转换为公里.你可以使用以下方法执行此操作:
>>> data = np.array([1.0, 2.0])
>>> data * 1.6
array([1.6, 3.2])
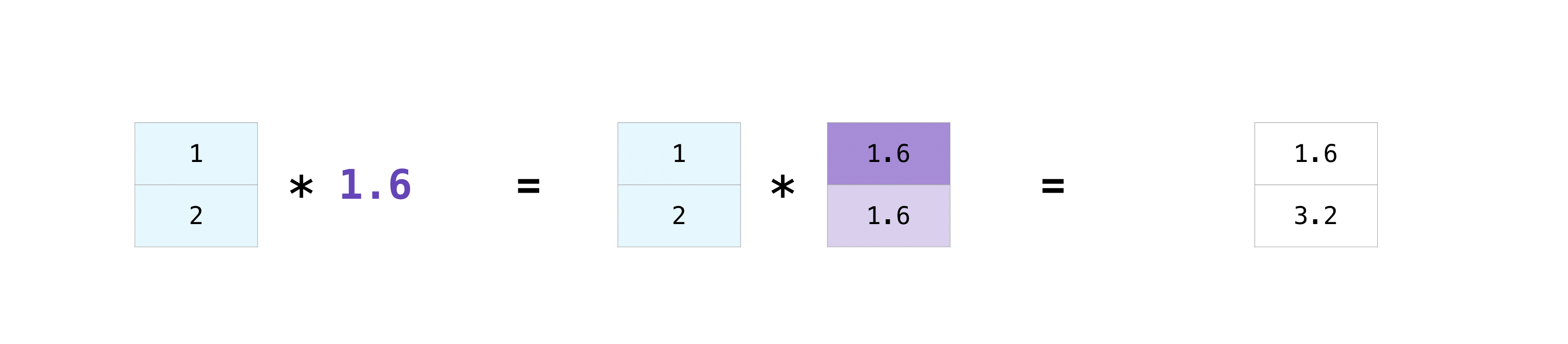
NumPy 理解乘法应该发生在每个单元格中.这个概念被称为 广播.广播是一种机制,允许 NumPy 对不同形状的数组执行操作.你的数组维度必须是兼容的,例如,当两个数组的维度相等或其中一个为 1 时.如果维度不兼容,你会得到一个 ValueError.
更多有用的数组操作#
本节涵盖最大值、最小值、总和、平均值、乘积、标准差等内容
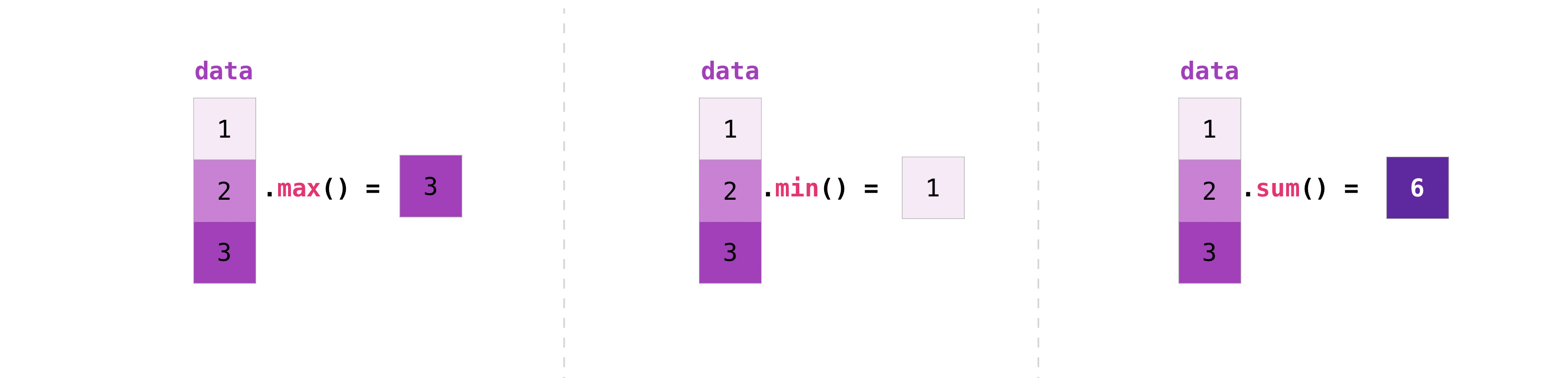
NumPy 也执行聚合函数.除了 min、max 和 sum 之外,您还可以轻松运行 mean 以获取平均值,``prod`` 以获取元素相乘的结果,``std`` 以获取标准差,等等.:
>>> data.max()
2.0
>>> data.min()
1.0
>>> data.sum()
3.0
让我们从这个数组开始,称为”a”
>>> a = np.array([[0.45053314, 0.17296777, 0.34376245, 0.5510652],
... [0.54627315, 0.05093587, 0.40067661, 0.55645993],
... [0.12697628, 0.82485143, 0.26590556, 0.56917101]])
按行或列进行聚合是非常常见的.默认情况下,每个 NumPy 聚合函数将返回整个数组的聚合结果.要找到数组元素的总和或最小值,请运行:
>>> a.sum()
4.8595784
或者:
>>> a.min()
0.05093587
您可以指定要在哪个轴上计算聚合函数.例如,您可以通过指定 axis=0 来找到每列中的最小值.:
>>> a.min(axis=0)
array([0.12697628, 0.05093587, 0.26590556, 0.5510652 ])
上面列出的四个值对应于数组中的列数.使用四列数组,您将得到四个值作为结果.
了解更多关于 数组方法在这里.
创建矩阵#
你可以传递 Python 的列表的列表来创建一个二维数组(或”矩阵”)以在 NumPy 中表示它们.:
>>> data = np.array([[1, 2], [3, 4], [5, 6]])
>>> data
array([[1, 2],
[3, 4],
[5, 6]])

索引和切片操作在你操作矩阵时非常有用:
>>> data[0, 1]
2
>>> data[1:3]
array([[3, 4],
[5, 6]])
>>> data[0:2, 0]
array([1, 3])

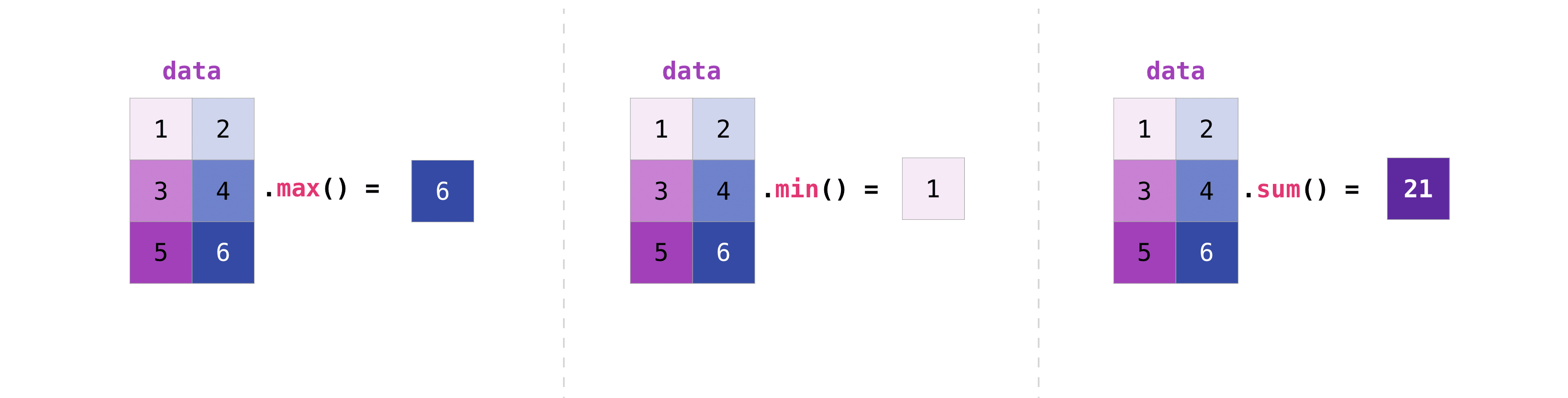
你可以用聚合向量的方式来聚合矩阵:
>>> data.max()
6
>>> data.min()
1
>>> data.sum()
21
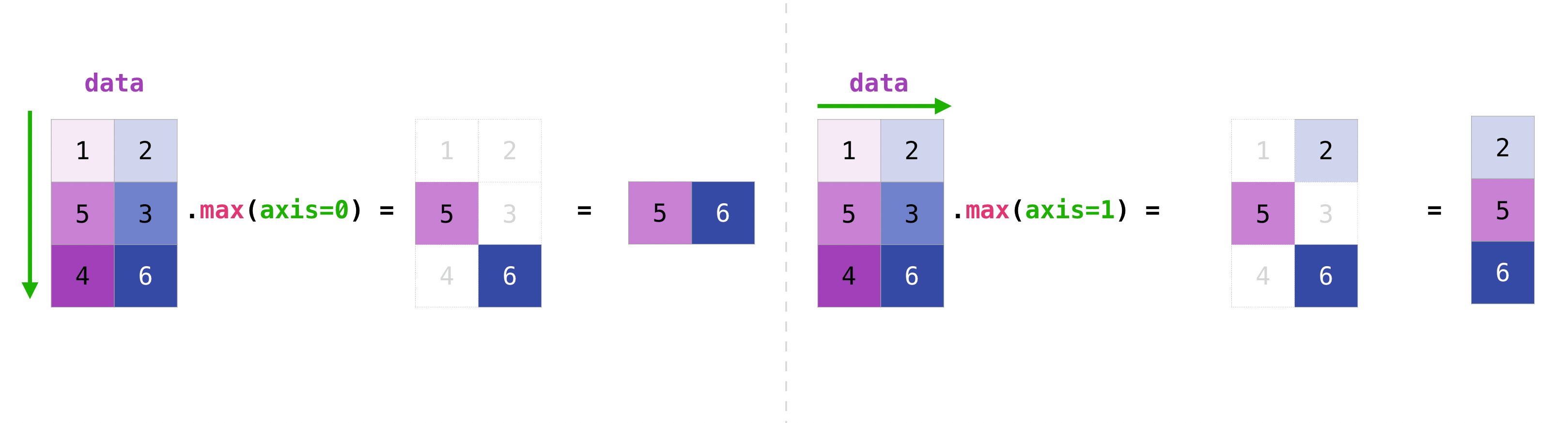
你可以聚合矩阵中的所有值,并且可以通过使用 axis 参数跨列或行进行聚合.为了说明这一点,让我们看一个稍微修改过的数据集:
>>> data = np.array([[1, 2], [5, 3], [4, 6]])
>>> data
array([[1, 2],
[5, 3],
[4, 6]])
>>> data.max(axis=0)
array([5, 6])
>>> data.max(axis=1)
array([2, 5, 6])
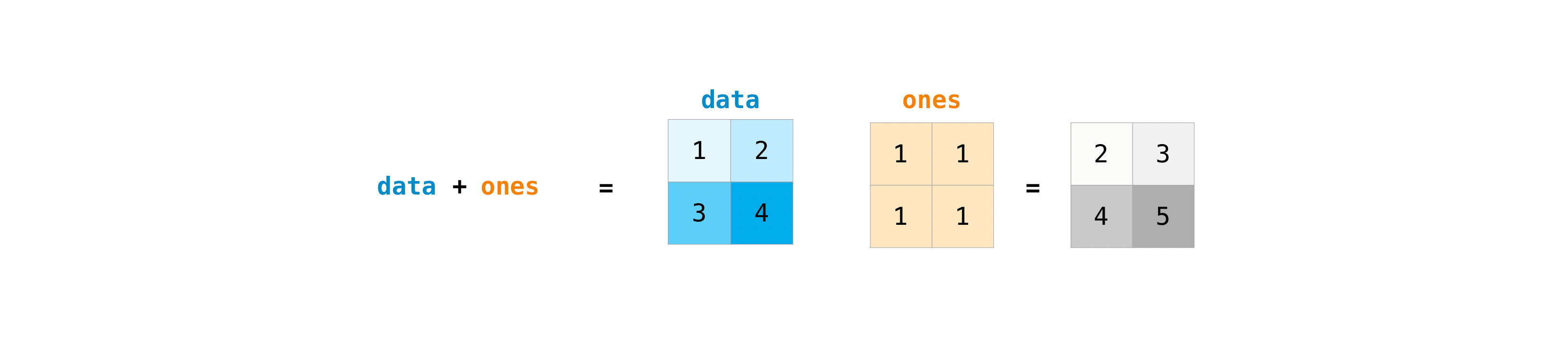
一旦你创建了你的矩阵,你可以使用算术运算符对它们进行加法和乘法运算,前提是你有两个大小相同的矩阵.:
>>> data = np.array([[1, 2], [3, 4]])
>>> ones = np.array([[1, 1], [1, 1]])
>>> data + ones
array([[2, 3],
[4, 5]])
你可以在不同大小的矩阵上进行这些算术运算,但前提是其中一个矩阵只有一列或一行.在这种情况下,NumPy 将使用其广播规则进行操作.:
>>> data = np.array([[1, 2], [3, 4], [5, 6]])
>>> ones_row = np.array([[1, 1]])
>>> data + ones_row
array([[2, 3],
[4, 5],
[6, 7]])
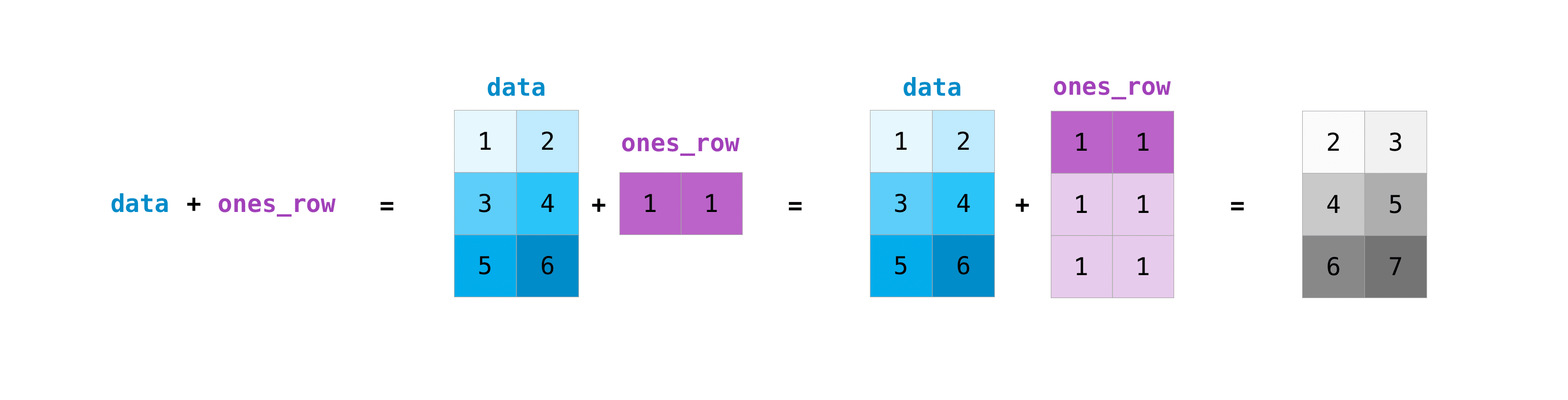
请注意,当 NumPy 打印 N 维数组时,最后一个轴循环最快,而第一个轴循环最慢.例如:
>>> np.ones((4, 3, 2))
array([[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]]])
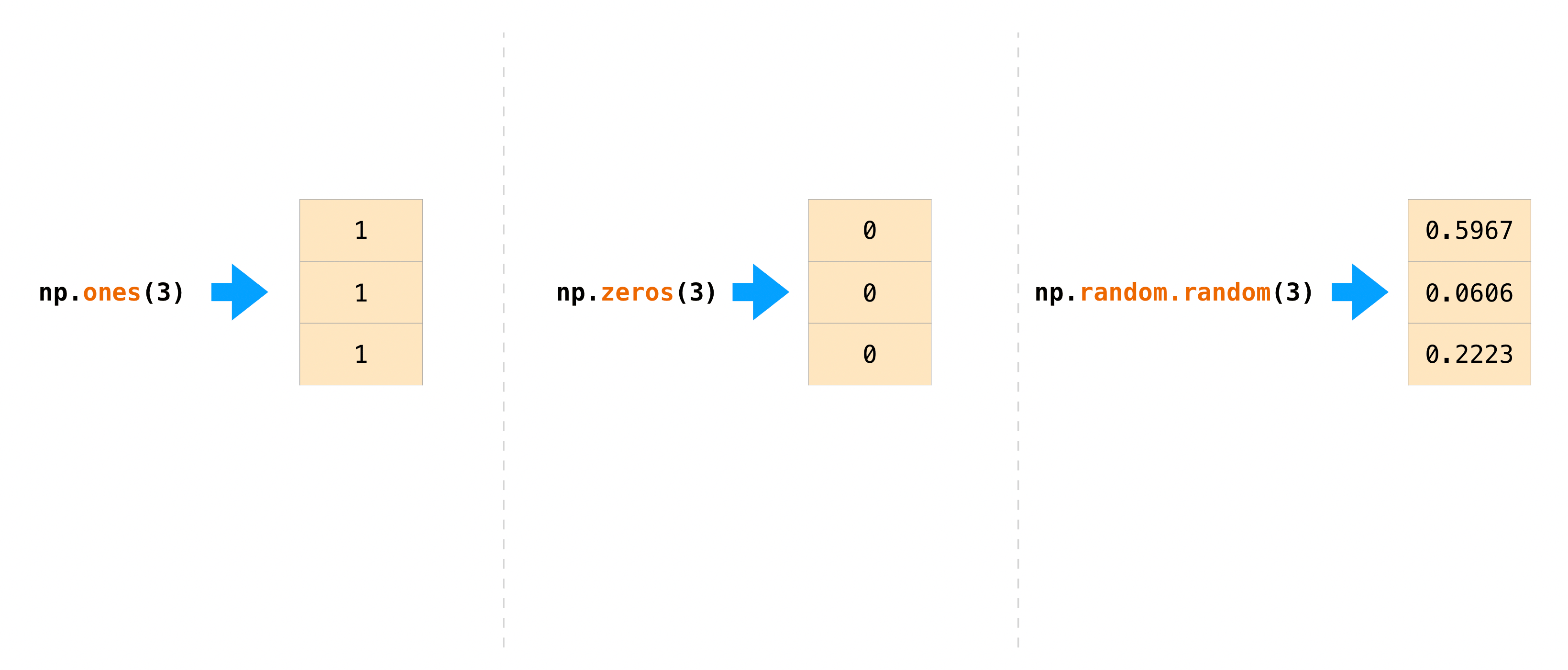
我们经常希望 NumPy 初始化数组的值.NumPy 提供了像 ones() 和 zeros() 这样的函数,以及用于随机数生成的 random.Generator 类.你只需要传入你希望它生成的元素数量:
>>> np.ones(3)
array([1., 1., 1.])
>>> np.zeros(3)
array([0., 0., 0.])
>>> rng = np.random.default_rng() # the simplest way to generate random numbers
>>> rng.random(3)
array([0.63696169, 0.26978671, 0.04097352])
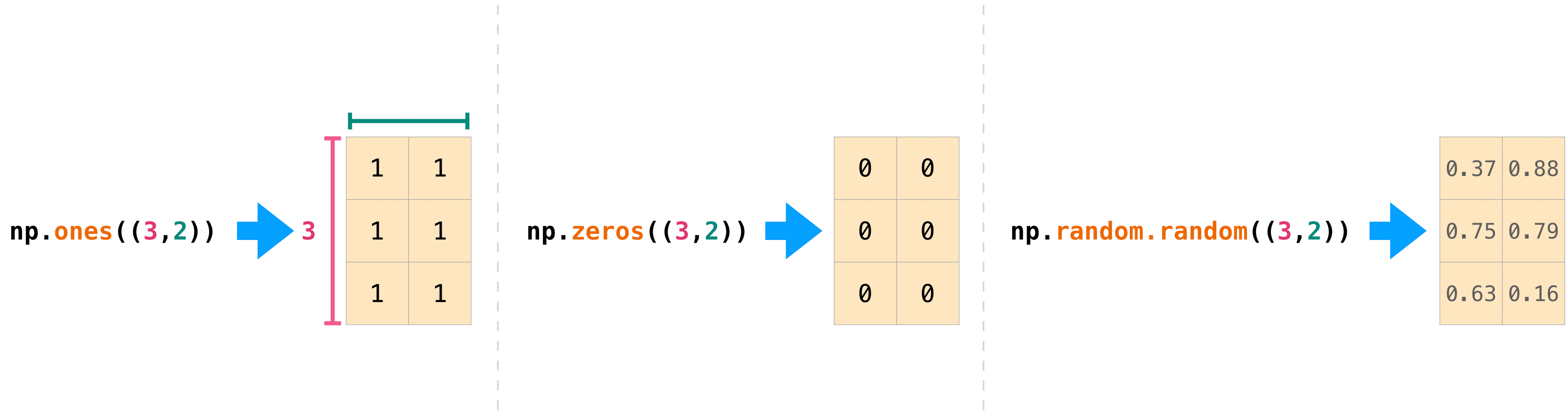
你也可以使用 ones() 、 zeros() 和 random() 来创建一个二维数组,如果你给它们一个描述矩阵维度的元组:
>>> np.ones((3, 2))
array([[1., 1.],
[1., 1.],
[1., 1.]])
>>> np.zeros((3, 2))
array([[0., 0.],
[0., 0.],
[0., 0.]])
>>> rng.random((3, 2))
array([[0.01652764, 0.81327024],
[0.91275558, 0.60663578],
[0.72949656, 0.54362499]]) # may vary
了解更多关于创建数组的信息,这些数组填充了 0 、 1 或其他值,或者未初始化,请参阅 数组创建例程 .
生成随机数#
随机数生成的使用是许多数值和机器学习算法配置和评估的重要组成部分.无论您是需要随机初始化人工神经网络中的权重、将数据随机分成多个集合,还是随机打乱您的数据集,能够生成随机数(实际上是可重复的伪随机数)都是至关重要的.
使用 Generator.integers,你可以从低(记住这在 NumPy 中是包含的)到高(不包含)生成随机整数.你可以设置 endpoint=True 使高数包含在内.
你可以生成一个 2 x 4 的随机整数数组,范围在 0 到 4 之间,使用:
>>> rng.integers(5, size=(2, 4))
array([[2, 1, 1, 0],
[0, 0, 0, 4]]) # may vary
如何获取唯一项和计数#
本节涵盖 np.unique()
你可以很容易地用 np.unique 找到数组中的唯一元素.
例如,如果你从这个数组开始:
>>> a = np.array([11, 11, 12, 13, 14, 15, 16, 17, 12, 13, 11, 14, 18, 19, 20])
你可以使用 np.unique 来打印数组中的唯一值:
>>> unique_values = np.unique(a)
>>> print(unique_values)
[11 12 13 14 15 16 17 18 19 20]
要在 NumPy 数组中获取唯一值的索引(数组中唯一值的第一个索引位置),只需在 np.unique() 中传递 return_index 参数以及你的数组.:
>>> unique_values, indices_list = np.unique(a, return_index=True)
>>> print(indices_list)
[ 0 2 3 4 5 6 7 12 13 14]
你可以在 np.unique() 中传递 return_counts 参数以及你的数组,以获取NumPy数组中唯一值的频率计数.:
>>> unique_values, occurrence_count = np.unique(a, return_counts=True)
>>> print(occurrence_count)
[3 2 2 2 1 1 1 1 1 1]
这也适用于二维数组!如果你从这个数组开始:
>>> a_2d = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [1, 2, 3, 4]])
你可以通过以下方式找到唯一值:
>>> unique_values = np.unique(a_2d)
>>> print(unique_values)
[ 1 2 3 4 5 6 7 8 9 10 11 12]
如果没有传递 axis 参数,你的二维数组将被展平.
如果你想获取唯一的行或列,请确保传递 axis 参数.要查找唯一的行,指定 axis=0,对于列,指定 axis=1.:
>>> unique_rows = np.unique(a_2d, axis=0)
>>> print(unique_rows)
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
要获取唯一行、索引位置和出现次数,可以使用:
>>> unique_rows, indices, occurrence_count = np.unique(
... a_2d, axis=0, return_counts=True, return_index=True)
>>> print(unique_rows)
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
>>> print(indices)
[0 1 2]
>>> print(occurrence_count)
[2 1 1]
要了解更多关于在数组中找到唯一元素的信息,请参见 unique.
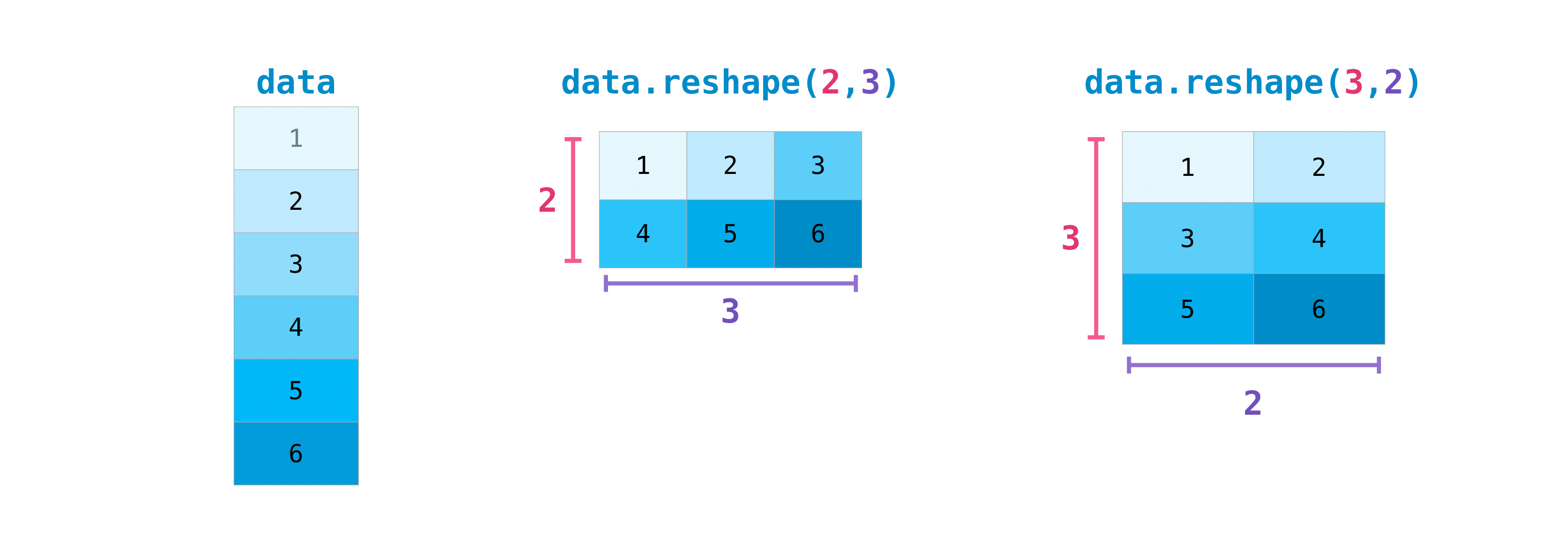
转置和重塑矩阵#
本节涵盖 arr.reshape(), arr.transpose(), arr.T
需要转置矩阵是很常见的.NumPy 数组具有 T 属性,允许你转置矩阵.
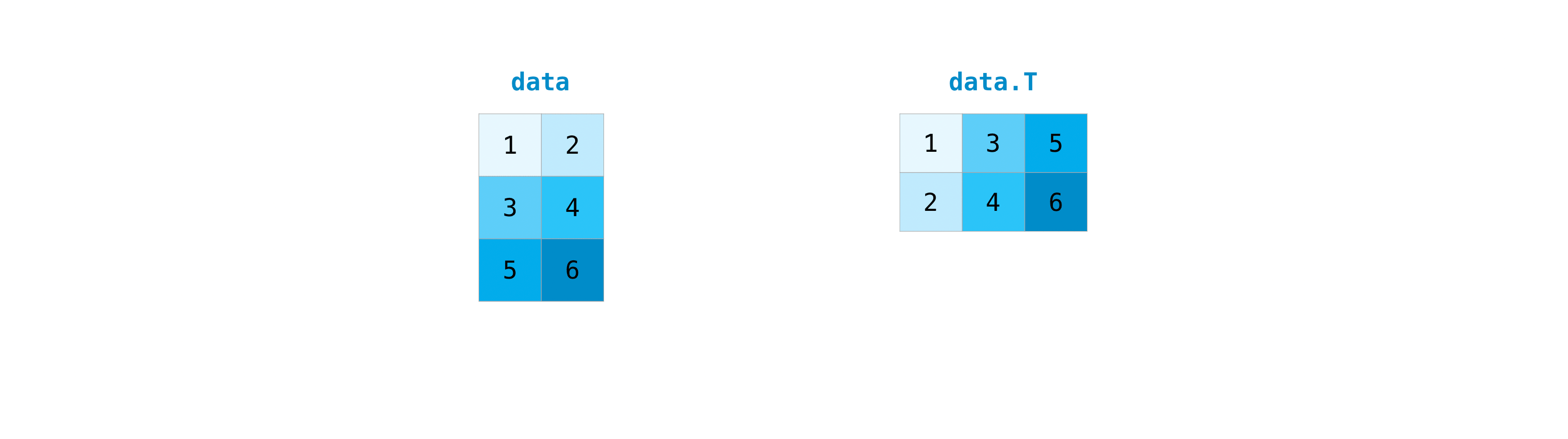
您可能还需要切换矩阵的维度.例如,当您有一个期望特定输入形状的模型,而该形状与您的数据集不同时,就会发生这种情况.这时 reshape 方法就非常有用了.您只需传入您希望矩阵具有的新维度即可.:
>>> data.reshape(2, 3)
array([[1, 2, 3],
[4, 5, 6]])
>>> data.reshape(3, 2)
array([[1, 2],
[3, 4],
[5, 6]])
你也可以使用 .transpose() 根据你指定的值来反转或改变数组的轴.
如果你从这个数组开始:
>>> arr = np.arange(6).reshape((2, 3))
>>> arr
array([[0, 1, 2],
[3, 4, 5]])
你可以用 arr.transpose() 来转置你的数组.
>>> arr.transpose()
array([[0, 3],
[1, 4],
[2, 5]])
你也可以使用 arr.T:
>>> arr.T
array([[0, 3],
[1, 4],
[2, 5]])
如何反转一个数组#
本节涵盖 np.flip()
NumPy 的 np.flip() 函数允许你沿轴翻转或反转数组的内容.使用 np.flip() 时,指定你想要反转的数组和轴.如果你不指定轴,NumPy 将沿输入数组的所有轴反转内容.
反转一个一维数组
如果你从一个一维数组开始,像这样:
>>> arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
你可以通过以下方式反转它:
>>> reversed_arr = np.flip(arr)
如果你想打印你的反转数组,你可以运行:
>>> print('Reversed Array: ', reversed_arr)
Reversed Array: [8 7 6 5 4 3 2 1]
反转一个二维数组
二维数组的工作方式大致相同.
如果你从这个数组开始:
>>> arr_2d = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
你可以通过以下方式反转所有行和所有列的内容:
>>> reversed_arr = np.flip(arr_2d)
>>> print(reversed_arr)
[[12 11 10 9]
[ 8 7 6 5]
[ 4 3 2 1]]
你可以轻松地只反转 行 ,方法是:
>>> reversed_arr_rows = np.flip(arr_2d, axis=0)
>>> print(reversed_arr_rows)
[[ 9 10 11 12]
[ 5 6 7 8]
[ 1 2 3 4]]
或者只反转 列 ,使用:
>>> reversed_arr_columns = np.flip(arr_2d, axis=1)
>>> print(reversed_arr_columns)
[[ 4 3 2 1]
[ 8 7 6 5]
[12 11 10 9]]
你也可以仅反转一列或一行的内容.例如,你可以反转索引位置1(第二行)的内容:
>>> arr_2d[1] = np.flip(arr_2d[1])
>>> print(arr_2d)
[[ 1 2 3 4]
[ 8 7 6 5]
[ 9 10 11 12]]
你也可以反转索引位置1的列(第二列):
>>> arr_2d[:,1] = np.flip(arr_2d[:,1])
>>> print(arr_2d)
[[ 1 10 3 4]
[ 8 7 6 5]
[ 9 2 11 12]]
在 flip 了解更多关于反转数组的信息.
重塑和平整多维数组#
本节涵盖 .flatten(), ravel()
有两种流行的方法来展平数组:.flatten() 和 .ravel().两者之间的主要区别在于,使用 ravel() 创建的新数组实际上是对父数组的引用(即”视图”).这意味着对新数组的任何更改也会影响父数组.由于 ravel 不创建副本,因此它是内存高效的.
如果你从这个数组开始:
>>> x = np.array([[1 , 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
你可以使用 flatten 将你的数组展平为一个一维数组.
>>> x.flatten()
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
当你使用 flatten 时,对你的新数组所做的更改不会影响父数组.
例如:
>>> a1 = x.flatten()
>>> a1[0] = 99
>>> print(x) # Original array
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
>>> print(a1) # New array
[99 2 3 4 5 6 7 8 9 10 11 12]
但是当你使用 ravel 时,你对新数组所做的更改将影响父数组.
例如:
>>> a2 = x.ravel()
>>> a2[0] = 98
>>> print(x) # Original array
[[98 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
>>> print(a2) # New array
[98 2 3 4 5 6 7 8 9 10 11 12]
了解更多关于 flatten 的信息请参见 ndarray.flatten ,关于 ravel 的信息请参见 ravel.
如何访问文档字符串以获取更多信息#
本节涵盖 help(), ?, ??
谈到数据科学生态系统时,Python 和 NumPy 都是以用户为中心构建的.这方面最好的例子之一是内置的文档访问功能.每个对象都包含一个字符串的引用,这被称为 docstring.在大多数情况下,这个 docstring 包含对象的快速和简明的总结以及如何使用它.Python 有一个内置的 help() 函数,可以帮助你访问这些信息.这意味着几乎任何时候你需要更多信息,你都可以使用 help() 快速找到你需要的信息.
例如:
>>> help(max)
Help on built-in function max in module builtins:
max(...)
max(iterable, *[, default=obj, key=func]) -> value
max(arg1, arg2, *args, *[, key=func]) -> value
With a single iterable argument, return its biggest item. The
default keyword-only argument specifies an object to return if
the provided iterable is empty.
With two or more arguments, return the largest argument.
因为访问额外信息非常有用,IPython 使用 ? 字符作为访问此文档以及其他相关信息的简写.IPython 是一个用于多种语言交互计算的命令 shell.`你可以在 这里 找到更多关于 IPython 的信息 <https://ipython.org/>`_.
例如:
In [0]: max?
max(iterable, *[, default=obj, key=func]) -> value
max(arg1, arg2, *args, *[, key=func]) -> value
With a single iterable argument, return its biggest item. The
default keyword-only argument specifies an object to return if
the provided iterable is empty.
With two or more arguments, return the largest argument.
Type: builtin_function_or_method
你甚至可以使用这种表示法来表示对象方法和对象本身.
假设你创建了这个数组:
>>> a = np.array([1, 2, 3, 4, 5, 6])
然后你可以获得很多有用的信息(首先是关于 a 本身的详细信息,接着是 a 实例所属的 ndarray 的文档字符串):
In [1]: a?
Type: ndarray
String form: [1 2 3 4 5 6]
Length: 6
File: ~/anaconda3/lib/python3.9/site-packages/numpy/__init__.py
Docstring: <no docstring>
Class docstring:
ndarray(shape, dtype=float, buffer=None, offset=0,
strides=None, order=None)
An array object represents a multidimensional, homogeneous array
of fixed-size items. An associated data-type object describes the
format of each element in the array (its byte-order, how many bytes it
occupies in memory, whether it is an integer, a floating point number,
or something else, etc.)
Arrays should be constructed using `array`, `zeros` or `empty` (refer
to the See Also section below). The parameters given here refer to
a low-level method (`ndarray(...)`) for instantiating an array.
For more information, refer to the `numpy` module and examine the
methods and attributes of an array.
Parameters
----------
(for the __new__ method; see Notes below)
shape : tuple of ints
Shape of created array.
...
这也适用于你创建的函数和其他对象.只需记住使用字符串字面量(""" """ 或 ''' ''' 围绕你的文档)在函数中包含一个文档字符串.
例如,如果你创建这个函数:
>>> def double(a):
... '''Return a * 2'''
... return a * 2
你可以获取关于该函数的信息:
In [2]: double?
Signature: double(a)
Docstring: Return a * 2
File: ~/Desktop/<ipython-input-23-b5adf20be596>
Type: function
通过阅读你感兴趣的对象的源代码,你可以获得另一层次的信息.使用双问号 (??) 可以让你访问源代码.
例如:
In [3]: double??
Signature: double(a)
Source:
def double(a):
'''Return a * 2'''
return a * 2
File: ~/Desktop/<ipython-input-23-b5adf20be596>
Type: function
如果所讨论的对象是用Python以外的语言编译的,使用 ?? 将返回与 ? 相同的信息.你会发现这在许多内置对象和类型中都是如此,例如:
In [4]: len?
Signature: len(obj, /)
Docstring: Return the number of items in a container.
Type: builtin_function_or_method
和 :
In [5]: len??
Signature: len(obj, /)
Docstring: Return the number of items in a container.
Type: builtin_function_or_method
因为它们是用除 Python 以外的编程语言编译的,所以有相同的输出.
使用数学公式#
在数组上工作的数学公式的实现简便性是使 NumPy 在科学 Python 社区中被广泛使用的原因之一.
例如,这是均方误差公式(监督机器学习模型中用于回归的一个核心公式):
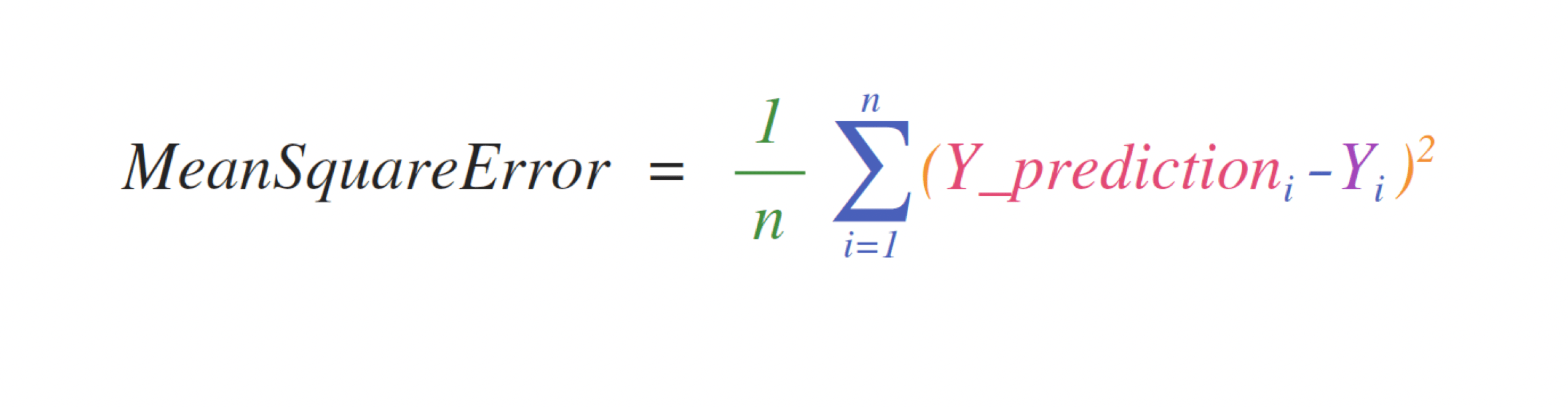
在 NumPy 中实现这个公式是简单且直接的:
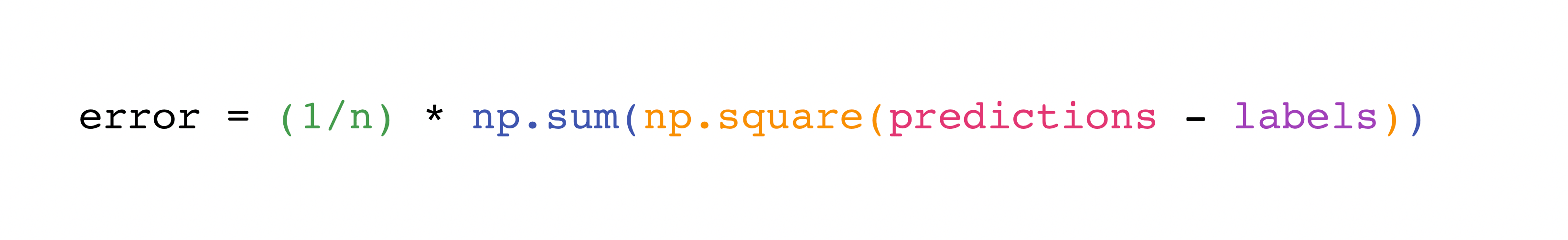
这之所以能如此有效,是因为 predictions 和 labels 可以包含一个或一千个值.它们只需要大小相同.
你可以这样理解它:

在这个例子中,预测和标签向量都包含三个值,这意味着 n 的值为三.在我们进行减法后,向量中的值被平方.然后 NumPy 对这些值求和,你的结果就是该预测的误差值和模型质量的评分.

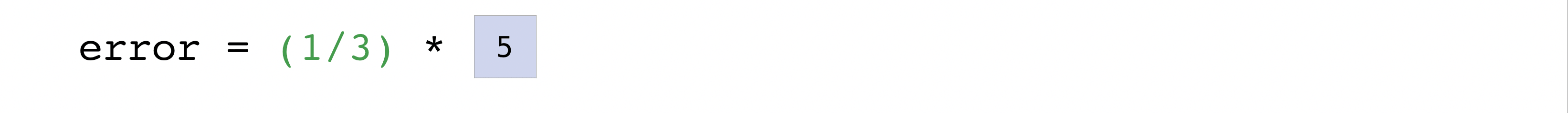
如何保存和加载 NumPy 对象#
本节涵盖 np.save, np.savez, np.savetxt, np.load, np.loadtxt
在某些时候,您会希望将数组保存到磁盘并在不重新运行代码的情况下加载它们.幸运的是,NumPy 提供了几种保存和加载对象的方法.ndarray 对象可以使用 loadtxt 和 savetxt 函数保存到普通文本文件并从中加载,使用 load 和 save 函数保存到带有 .npy 文件扩展名的 NumPy 二进制文件并从中加载,以及使用 savez 函数保存到带有 .npz 文件扩展名的 NumPy 文件并从中加载.
.npy 和 .npz 文件存储数据、形状、数据类型以及其他重建 ndarray 所需的信息,这种方式允许数组在被正确检索,即使文件位于具有不同架构的另一台机器上.
如果你想存储一个单独的 ndarray 对象,使用 np.save 将其存储为 .npy 文件.如果你想在一个文件中存储多个 ndarray 对象,使用 np.savez 将其存储为 .npz 文件.你还可以使用 savez_compressed 将多个数组保存到一个压缩的 npz 格式文件中.
使用 np.save() 保存和加载数组非常简单.只需确保指定要保存的数组和文件名.例如,如果您创建了这个数组:
>>> a = np.array([1, 2, 3, 4, 5, 6])
你可以将其保存为”filename.npy”,使用如下指令:
>>> np.save('filename', a)
你可以使用 np.load() 来重建你的数组.:
>>> b = np.load('filename.npy')
如果你想检查你的数组,你可以运行:
>>> print(b)
[1 2 3 4 5 6]
你可以将一个 NumPy 数组保存为纯文本文件,如 .csv 或 .txt 文件,使用 np.savetxt.
例如,如果你创建这个数组:
>>> csv_arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
你可以轻松地将其保存为名为”new_file.csv”的 .csv 文件,如下所示:
>>> np.savetxt('new_file.csv', csv_arr)
你可以使用 loadtxt() 快速且轻松地加载你保存的文本文件:
>>> np.loadtxt('new_file.csv')
array([1., 2., 3., 4., 5., 6., 7., 8.])
savetxt() 和 loadtxt() 函数接受额外的可选参数,如 header、footer 和 delimiter.虽然文本文件在共享时可能更容易,但 .npy 和 .npz 文件更小且读取速度更快.如果你需要更复杂的文本文件处理(例如,如果你需要处理包含缺失值的行),你将需要使用 genfromtxt 函数.
使用 savetxt,你可以指定页眉、页脚、注释等内容.
了解更多关于 输入和输出例程 的信息.
导入和导出 CSV#
读取包含现有信息的CSV文件很简单.最好的也是最简单的方法是使用 Pandas.:
>>> import pandas as pd
>>> # If all of your columns are the same type:
>>> x = pd.read_csv('music.csv', header=0).values
>>> print(x)
[['Billie Holiday' 'Jazz' 1300000 27000000]
['Jimmie Hendrix' 'Rock' 2700000 70000000]
['Miles Davis' 'Jazz' 1500000 48000000]
['SIA' 'Pop' 2000000 74000000]]
>>> # You can also simply select the columns you need:
>>> x = pd.read_csv('music.csv', usecols=['Artist', 'Plays']).values
>>> print(x)
[['Billie Holiday' 27000000]
['Jimmie Hendrix' 70000000]
['Miles Davis' 48000000]
['SIA' 74000000]]
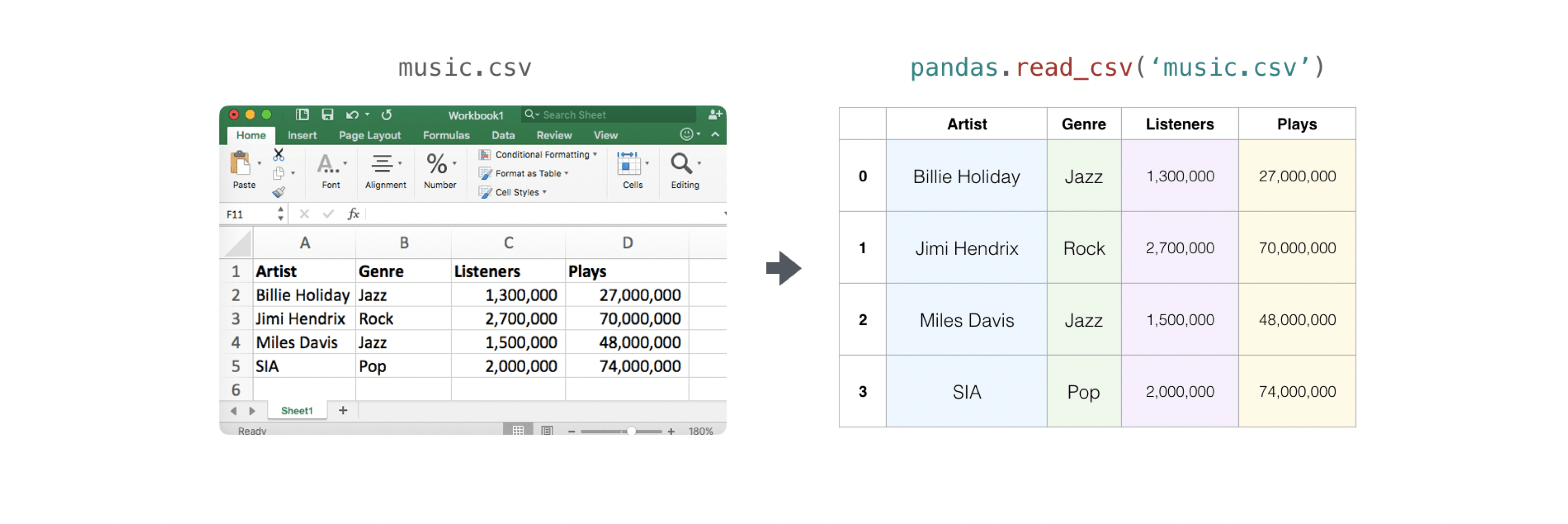
使用 Pandas 导出你的数组也很简单.如果你是 NumPy 新手,你可能想从数组中的值创建一个 Pandas 数据框,然后用 Pandas 将数据框写入 CSV 文件.
如果你创建了这个数组 “a”
>>> a = np.array([[-2.58289208, 0.43014843, -1.24082018, 1.59572603],
... [ 0.99027828, 1.17150989, 0.94125714, -0.14692469],
... [ 0.76989341, 0.81299683, -0.95068423, 0.11769564],
... [ 0.20484034, 0.34784527, 1.96979195, 0.51992837]])
你可以创建一个 Pandas 数据帧
>>> df = pd.DataFrame(a)
>>> print(df)
0 1 2 3
0 -2.582892 0.430148 -1.240820 1.595726
1 0.990278 1.171510 0.941257 -0.146925
2 0.769893 0.812997 -0.950684 0.117696
3 0.204840 0.347845 1.969792 0.519928
你可以轻松地保存你的数据框:
>>> df.to_csv('pd.csv')
并且使用以下方式读取你的CSV文件:
>>> data = pd.read_csv('pd.csv')

你也可以使用 NumPy 的 savetxt 方法保存你的数组.:
>>> np.savetxt('np.csv', a, fmt='%.2f', delimiter=',', header='1, 2, 3, 4')
如果你使用命令行,你可以随时使用如下命令读取你保存的CSV文件:
$ cat np.csv
# 1, 2, 3, 4
-2.58,0.43,-1.24,1.60
0.99,1.17,0.94,-0.15
0.77,0.81,-0.95,0.12
0.20,0.35,1.97,0.52
或者你可以随时用文本编辑器打开文件!
如果你对学习更多关于 Pandas 的内容感兴趣,可以查看 官方 Pandas 文档.学习如何通过 官方 Pandas 安装信息 安装 Pandas.
使用 Matplotlib 绘制数组#
如果你需要为你的值生成一个图表,使用 Matplotlib 非常简单.
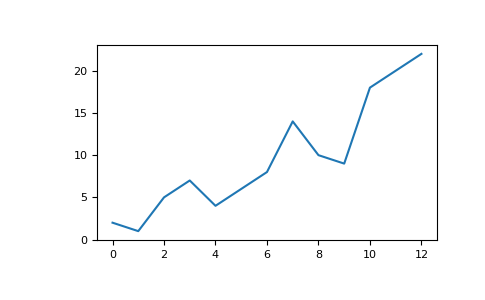
例如,你可能有一个这样的数组:
>>> a = np.array([2, 1, 5, 7, 4, 6, 8, 14, 10, 9, 18, 20, 22])
如果你已经安装了 Matplotlib,你可以用以下方式导入它:
>>> import matplotlib.pyplot as plt
# If you're using Jupyter Notebook, you may also want to run the following
# line of code to display your code in the notebook:
%matplotlib inline
要绘制您的值,只需运行:
>>> plt.plot(a)
# If you are running from a command line, you may need to do this:
# >>> plt.show()
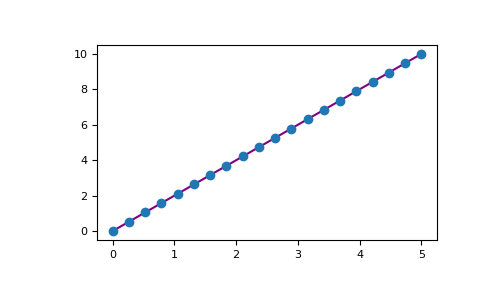
例如,你可以这样绘制一个一维数组:
>>> x = np.linspace(0, 5, 20)
>>> y = np.linspace(0, 10, 20)
>>> plt.plot(x, y, 'purple') # line
>>> plt.plot(x, y, 'o') # dots
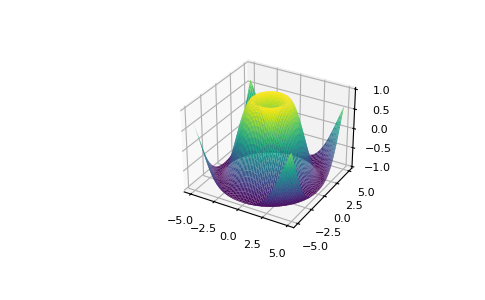
使用 Matplotlib,你可以访问大量的可视化选项.:
>>> fig = plt.figure()
>>> ax = fig.add_subplot(projection='3d')
>>> X = np.arange(-5, 5, 0.15)
>>> Y = np.arange(-5, 5, 0.15)
>>> X, Y = np.meshgrid(X, Y)
>>> R = np.sqrt(X**2 + Y**2)
>>> Z = np.sin(R)
>>> ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap='viridis')
要了解更多关于 Matplotlib 及其功能的信息,请查看 官方文档.有关安装 Matplotlib 的指南,请参见官方 安装部分.
图片来源:Jay Alammar https://jalammar.github.io/