pandas.io.formats.style.Styler.format#
- Styler.format(formatter=None, subset=None, na_rep=None, precision=None, decimal='.', thousands=None, escape=None, hyperlinks=None)[源代码]#
格式化单元格的文本显示值。
- 参数:
- formatterstr, 可调用对象, dict 或 None
对象用于定义值的显示方式。请参见注释。
- 子集label, 类数组, IndexSlice, 可选
一个有效的 2d 输入到 DataFrame.loc[<subset>],或者,在 1d 输入或单个键的情况下,到 DataFrame.loc[:, <subset>],其中列优先,以限制
data在应用函数 之前。- na_repstr, 可选
缺失值的表示。如果
na_rep是 None,则不应用特殊格式。- 精度int, 可选
用于显示目的的浮点精度,如果未由指定的
formatter确定。Added in version 1.3.0.
- decimalstr, 默认值为 “.”
用于浮点数、复数和整数的小数分隔符字符。
Added in version 1.3.0.
- thousandsstr, 可选, 默认 None
用于浮点数、复数和整数千位分隔符的字符。
Added in version 1.3.0.
- escapestr, 可选
使用 ‘html’ 将单元格显示字符串中的字符
&,<,>,', 和"替换为 HTML 安全序列。使用 ‘latex’ 将单元格显示字符串中的字符&,%,$,#,_,{,},~,^, 和\替换为 LaTeX 安全序列。使用 ‘latex-math’ 将字符替换方式与 ‘latex’ 模式相同,除了数学子字符串,这些子字符串要么被两个字符$包围,要么以字符\(开始并以\)结束。在formatter之前进行转义。Added in version 1.3.0.
- 超链接{“html”, “latex”}, 可选
如果为“html”,则将包含 https://、http://、ftp:// 或 www. 的字符串模式转换为 HTML <a> 标签作为可点击的 URL 超链接;如果为“latex”,则转换为 LaTeX href 命令。
Added in version 1.4.0.
- 返回:
- Styler
返回自身以进行链式调用。
参见
Styler.format_index格式化索引标签的文本显示值。
备注
此方法为 DataFrame 中的每个单元格分配一个格式化函数
formatter。如果formatter是None,则使用默认格式化器。如果是一个可调用对象,则该函数应接受一个数据值作为输入并返回一个可显示的表示形式,例如字符串。如果formatter以字符串形式给出,则假定这是一个有效的 Python 格式规范,并包装为可调用对象string.format(x)。如果给定的是一个dict,则键应对应于列名,值应为字符串或可调用对象,如上所述。默认格式化器当前以 pandas 显示精度表示浮点数和复数,除非在此使用
precision参数。默认格式化器不会调整缺失值的表示,除非使用na_rep参数。subset参数定义了应用格式化函数的区域。如果formatter参数以字典形式给出,但不包括子集中的所有列,则这些列将应用默认格式化器。格式化字典中排除在子集之外的任何列将被忽略。当使用
formatter字符串时,dtypes 必须兼容,否则会引发 ValueError。当实例化一个 Styler 时,可以通过设置
pandas.options来应用默认格式:styler.format.formatter: 默认 None。styler.format.na_rep: 默认 None。styler.format.precision: 默认值为 6。styler.format.decimal: 默认 “.”。styler.format.thousands: 默认 None。styler.format.escape: 默认 None。
警告
使用输出格式 Styler.to_excel 时忽略 Styler.format,因为 Excel 和 Python 具有本质上不同的格式结构。然而,可以使用 number-format 伪 CSS 属性来强制 Excel 允许的格式。请参见示例。
例子
使用
na_rep和precision与默认的formatter>>> df = pd.DataFrame([[np.nan, 1.0, 'A'], [2.0, np.nan, 3.0]]) >>> df.style.format(na_rep='MISS', precision=3) 0 1 2 0 MISS 1.000 A 1 2.000 MISS 3.000
在一致的列数据类型上使用
formatter规范>>> df.style.format('{:.2f}', na_rep='MISS', subset=[0, 1]) 0 1 2 0 MISS 1.00 A 1 2.00 MISS 3.000000
使用未指定列的默认
formatter>>> df.style.format({0: '{:.2f}', 1: '£ {:.1f}'}, ... na_rep='MISS', precision=1) 0 1 2 0 MISS £ 1.0 A 1 2.00 MISS 3.0
在默认的
formatter下,多个na_rep或precision规范。>>> (df.style.format(na_rep='MISS', precision=1, subset=[0]).format( ... na_rep='PASS', precision=2, subset=[1, 2])) 0 1 2 0 MISS 1.00 A 1 2.0 PASS 3.00
使用一个可调用的
formatter函数。>>> func = lambda s: 'STRING' if isinstance(s, str) else 'FLOAT' >>> df.style.format({0: '{:.1f}', 2: func}, ... precision=4, na_rep='MISS') 0 1 2 0 MISS 1.0000 STRING 1 2.0 MISS FLOAT
使用
formatter与 HTMLescape和na_rep。>>> df = pd.DataFrame([['<div></div>', '"A&B"', None]]) >>> s = df.style.format( ... '<a href="a.com/{0}">{0}</a>', escape="html", na_rep="NA") >>> s.to_html() ... <td .. ><a href="a.com/<div></div>"><div></div></a></td> <td .. ><a href="a.com/"A&B"">"A&B"</a></td> <td .. >NA</td> ...
在 ‘latex’ 模式下使用带有
escape的formatter。>>> df = pd.DataFrame([["123"], ["~ ^"], ["$%#"]]) >>> df.style.format("\\textbf{{{}}}", ... escape="latex").to_latex() \begin{tabular}{ll} & 0 \\ 0 & \textbf{123} \\ 1 & \textbf{\textasciitilde \space \textasciicircum } \\ 2 & \textbf{\$\%\#} \\ \end{tabular}
在 ‘latex-math’ 模式中应用
escape。在下面的示例中,我们使用字符$进入数学模式。>>> df = pd.DataFrame([ ... [r"$\sum_{i=1}^{10} a_i$ a~b $\alpha = \frac{\beta}{\zeta^2}$"], ... [r"%#^ $ \$x^2 $"]]) >>> df.style.format(escape="latex-math").to_latex() \begin{tabular}{ll} & 0 \\ 0 & $\sum_{i=1}^{10} a_i$ a\textasciitilde b $\alpha = \frac{\beta}{\zeta^2}$ \\ 1 & \%\#\textasciicircum \space $ \$x^2 $ \\ \end{tabular}
我们可以使用字符
\(进入数学模式,使用字符\)关闭数学模式。>>> df = pd.DataFrame([ ... [r"\(\sum_{i=1}^{10} a_i\) a~b \(\alpha = \frac{\beta}{\zeta^2}\)"], ... [r"%#^ \( \$x^2 \)"]]) >>> df.style.format(escape="latex-math").to_latex() \begin{tabular}{ll} & 0 \\ 0 & \(\sum_{i=1}^{10} a_i\) a\textasciitilde b \(\alpha = \frac{\beta}{\zeta^2}\) \\ 1 & \%\#\textasciicircum \space \( \$x^2 \) \\ \end{tabular}
如果在一个DataFrame单元格中同时包含数学公式的两种简写,带有符号
$的简写将被应用。>>> df = pd.DataFrame([ ... [r"\( x^2 \) $x^2$"], ... [r"$\frac{\beta}{\zeta}$ \(\frac{\beta}{\zeta}\)"]]) >>> df.style.format(escape="latex-math").to_latex() \begin{tabular}{ll} & 0 \\ 0 & \textbackslash ( x\textasciicircum 2 \textbackslash ) $x^2$ \\ 1 & $\frac{\beta}{\zeta}$ \textbackslash (\textbackslash frac\{\textbackslash beta\}\{\textbackslash zeta\}\textbackslash ) \\ \end{tabular}
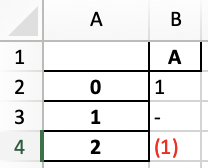
Pandas 定义了一个 number-format 伪 CSS 属性,而不是使用 .format 方法来创建 to_excel 允许的格式。注意,分号是 CSS 保护字符,但在 Excel 的格式字符串中用作分隔符。在定义这里的格式时,用节分隔符字符(ASCII-245)替换分号。
>>> df = pd.DataFrame({"A": [1, 0, -1]}) >>> pseudo_css = "number-format: 0§[Red](0)§-§@;" >>> filename = "formatted_file.xlsx" >>> df.style.map(lambda v: pseudo_css).to_excel(filename)