differential_entropy#
- scipy.stats.differential_entropy(values, *, window_length=None, base=None, axis=0, method='auto', nan_policy='propagate', keepdims=False)[源代码][源代码]#
给定一个分布的样本,估计其微分熵。
使用 method 参数可以提供几种估计方法。默认情况下,会根据样本大小选择一种方法。
- 参数:
- 值序列
从连续分布中抽取样本。
- window_lengthint, 可选
用于计算Vasicek估计的窗口长度。必须是1到样本大小一半之间的整数。如果为``None``(默认),则使用启发式值。
\[$\left \lfloor \sqrt{n} + 0.5 \right \rfloor$\]其中 \(n\) 是样本大小。这种启发式方法最初在 [2] 中提出,并在文献中变得普遍。
- 基础float, 可选
要使用的对数基数,默认为 ``e``(自然对数)。
- 轴int 或 None, 默认值: 0
如果是一个整数,表示输入数据中要计算统计量的轴。输入数据的每个轴切片(例如行)的统计量将出现在输出的相应元素中。如果为
None,则在计算统计量之前会将输入数据展平。- 方法{‘vasicek’, ‘van es’, ‘ebrahimi’, ‘correa’, ‘auto’}, 可选
用于从样本估计微分熵的方法。默认值是
'auto'。更多信息请参见注释。- nan_policy{‘propagate’, ‘omit’, ‘raise’}
定义如何处理输入的 NaN。
propagate: 如果在计算统计量的轴切片(例如行)中存在 NaN,则输出的相应条目将为 NaN。omit: 在执行计算时,NaN 将被省略。如果在计算统计量的轴切片中剩余的数据不足,则输出的相应条目将为 NaN。raise: 如果存在 NaN,将引发ValueError。
- keepdimsbool, 默认值: False
如果设置为True,被减少的轴将作为尺寸为1的维度保留在结果中。通过此选项,结果将正确地与输入数组进行广播。
- 返回:
- 熵浮动
计算得到的微分熵。
注释
此函数将在极限情况下收敛到真实的微分熵。
\[ \begin{align}\begin{aligned}n \to \infty, \quad m \to \infty, \quad \frac{m}{n} \to 0\\n 趋向无穷大,m 趋向无穷大,\frac{m}{n} 趋向 0\end{aligned}\end{align} \]对于给定的样本大小,
window_length的最佳选择取决于(未知的)分布。通常,分布的密度越平滑,window_length的最佳值就越大 [1]。method 参数有以下选项可用。
'vasicek'使用了 [1] 中提出的估计器。这是最早且最具影响力的微分熵估计器之一。'van es'使用了 [3] 中提出的偏差校正估计量,该估计量不仅一致,而且在某些条件下,渐近正态。'ebrahimi'使用了 [4] 中提出的估计器,该估计器在模拟中显示出比 Vasicek 估计器更小的偏差和均方误差。'correa'使用了基于局部线性回归的估计器,该估计器在 [5] 中提出。在一个模拟研究中,它的均方误差始终小于 Vasiceck 估计器,但计算成本更高。'auto'自动选择方法(默认)。目前,对于非常小的样本(<10),此选项选择'van es',对于中等样本大小(11-1000)选择'ebrahimi',对于较大样本选择'vasicek',但此行为可能在未来的版本中有所改变。
所有估计器都是按照 [6] 中所述实现的。
从 SciPy 1.9 开始,
np.matrix输入(不推荐用于新代码)在计算执行前被转换为np.ndarray。在这种情况下,输出将是一个标量或适当形状的np.ndarray,而不是一个 2D 的np.matrix。同样,虽然掩码数组的掩码元素被忽略,但输出将是一个标量或np.ndarray,而不是一个mask=False的掩码数组。参考文献
[2]Crzcgorzewski, P., & Wirczorkowski, R. (1999). 基于熵的指数性拟合优度检验。统计学通讯-理论与方法, 28(5), 1183-1202.
[3]Van Es, B. (1992). 通过基于间距的一类统计量估计与密度相关的泛函。斯堪的纳维亚统计学杂志, 61-72.
[4]Ebrahimi, N., Pflughoeft, K., & Soofi, E. S. (1994). 两种样本熵的度量。统计与概率通讯, 20(3), 225-234.
[5]Correa, J. C. (1995). 一种新的熵估计量。《统计学通讯-理论与方法》, 24(10), 2439-2449.
[6]Noughabi, H. A. (2015). 使用数值方法的熵估计。数据科学年鉴, 2(2), 231-241. https://link.springer.com/article/10.1007/s40745-015-0045-9
示例
>>> import numpy as np >>> from scipy.stats import differential_entropy, norm
标准正态分布的熵:
>>> rng = np.random.default_rng() >>> values = rng.standard_normal(100) >>> differential_entropy(values) 1.3407817436640392
与真实熵进行比较:
>>> float(norm.entropy()) 1.4189385332046727
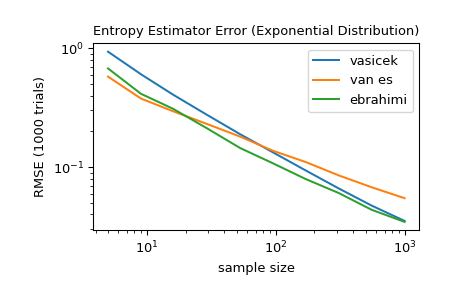
对于5到1000之间的几个样本量,比较
'vasicek'、'van es'和'ebrahimi'方法的准确性。具体来说,比较估计值与分布的真实微分熵之间的均方根误差(在1000次试验中)。>>> from scipy import stats >>> import matplotlib.pyplot as plt >>> >>> >>> def rmse(res, expected): ... '''Root mean squared error''' ... return np.sqrt(np.mean((res - expected)**2)) >>> >>> >>> a, b = np.log10(5), np.log10(1000) >>> ns = np.round(np.logspace(a, b, 10)).astype(int) >>> reps = 1000 # number of repetitions for each sample size >>> expected = stats.expon.entropy() >>> >>> method_errors = {'vasicek': [], 'van es': [], 'ebrahimi': []} >>> for method in method_errors: ... for n in ns: ... rvs = stats.expon.rvs(size=(reps, n), random_state=rng) ... res = stats.differential_entropy(rvs, method=method, axis=-1) ... error = rmse(res, expected) ... method_errors[method].append(error) >>> >>> for method, errors in method_errors.items(): ... plt.loglog(ns, errors, label=method) >>> >>> plt.legend() >>> plt.xlabel('sample size') >>> plt.ylabel('RMSE (1000 trials)') >>> plt.title('Entropy Estimator Error (Exponential Distribution)')