有状态计算#
像 jit()、vmap()、grad() 这样的 JAX 变换,要求它们包装的函数是纯函数:也就是说,函数的输出完全依赖于输入,并且没有副作用,比如更新全局状态。你可以在 JAX sharp bits: Pure functions 中找到关于这一点的讨论。
这种约束在机器学习的背景下可能会带来一些挑战,因为状态可能以多种形式存在。例如:
模型参数,
优化器状态,以及
有状态层,例如 BatchNorm。
本节提供一些关于如何在JAX程序中正确处理状态的建议。
一个简单的例子:计数器#
让我们从一个简单的有状态程序开始:一个计数器。
import jax
import jax.numpy as jnp
class Counter:
"""A simple counter."""
def __init__(self):
self.n = 0
def count(self) -> int:
"""Increments the counter and returns the new value."""
self.n += 1
return self.n
def reset(self):
"""Resets the counter to zero."""
self.n = 0
counter = Counter()
for _ in range(3):
print(counter.count())
1
2
3
计数器的 n 属性在 count 的连续调用之间维护计数器的 状态 。它在调用 count 时作为副作用被修改。
假设我们想要快速计数,所以我们对 count 方法进行即时编译(JIT)。(在这个例子中,由于多种原因,这实际上并不会提高速度,但可以将此视为对模型参数更新的即时编译的玩具模型,其中 jit() 产生了巨大的差异)。
counter.reset()
fast_count = jax.jit(counter.count)
for _ in range(3):
print(fast_count())
1
1
1
哦不!我们的计数器不工作了。这是因为这一行
self.n += 1
在 count 中涉及一个副作用:它会就地修改输入计数器,因此该函数不受 jit 支持。这种副作用仅在首次追踪函数时执行一次,后续调用将不会重复该副作用。那么,我们该如何修复它呢?
解决方案:显式状态#
我们计数器的问题之一是返回值不依赖于参数,这意味着一个常量被“编译到”输出中。但它不应该是常量——它应该依赖于状态。那么,我们为什么不把状态变成一个参数呢?
CounterState = int
class CounterV2:
def count(self, n: CounterState) -> tuple[int, CounterState]:
# You could just return n+1, but here we separate its role as
# the output and as the counter state for didactic purposes.
return n+1, n+1
def reset(self) -> CounterState:
return 0
counter = CounterV2()
state = counter.reset()
for _ in range(3):
value, state = counter.count(state)
print(value)
1
2
3
在这个新版本的 Counter 中,我们将 n 移动为 count 的参数,并添加了另一个表示新更新状态的返回值。要使用这个计数器,我们现在需要显式地跟踪状态。但作为回报,我们现在可以安全地 jax.jit 这个计数器:
state = counter.reset()
fast_count = jax.jit(counter.count)
for _ in range(3):
value, state = fast_count(state)
print(value)
1
2
3
一个通用策略#
我们可以将同样的过程应用于任何有状态的方法,将其转换为无状态的方法。我们采用了一种形式的类
class StatefulClass
state: State
def stateful_method(*args, **kwargs) -> Output:
并将其转化为以下形式的类
class StatelessClass
def stateless_method(state: State, *args, **kwargs) -> (Output, State):
这是一个常见的 函数式编程 模式,本质上,这是所有 JAX 程序中处理状态的方式。
请注意,一旦我们这样重写代码,对类的需求就变得不那么明确了。我们可以只保留 stateless_method,因为类不再执行任何工作。这是因为,就像我们刚刚应用的策略一样,面向对象编程(OOP)是一种帮助程序员理解程序状态的方式。
在我们的例子中,CounterV2 类只不过是一个命名空间,将所有使用 CounterState 的函数集中到一个位置。读者练习:你认为将其保留为一个类是否有意义?
顺便提一下,你已经在 JAX 伪随机性 API,jax.random 中看到了这种策略的例子,如 :ref:pseudorandom-numbers 部分所示。与使用隐式更新状态类管理随机状态的 Numpy 不同,JAX 要求程序员直接处理随机生成器状态——PRNG 键。
简单的工作示例:线性回归#
让我们将这种策略应用于一个简单的机器学习模型:通过梯度下降的线性回归。
在这里,我们只处理一种状态:模型参数。但通常情况下,你会看到许多种状态在 JAX 函数中进进出出,比如优化器状态、用于批量标准化的层统计数据等。
需要仔细查看的函数是 update。
from typing import NamedTuple
class Params(NamedTuple):
weight: jnp.ndarray
bias: jnp.ndarray
def init(rng) -> Params:
"""Returns the initial model params."""
weights_key, bias_key = jax.random.split(rng)
weight = jax.random.normal(weights_key, ())
bias = jax.random.normal(bias_key, ())
return Params(weight, bias)
def loss(params: Params, x: jnp.ndarray, y: jnp.ndarray) -> jnp.ndarray:
"""Computes the least squares error of the model's predictions on x against y."""
pred = params.weight * x + params.bias
return jnp.mean((pred - y) ** 2)
LEARNING_RATE = 0.005
@jax.jit
def update(params: Params, x: jnp.ndarray, y: jnp.ndarray) -> Params:
"""Performs one SGD update step on params using the given data."""
grad = jax.grad(loss)(params, x, y)
# If we were using Adam or another stateful optimizer,
# we would also do something like
#
# updates, new_optimizer_state = optimizer(grad, optimizer_state)
#
# and then use `updates` instead of `grad` to actually update the params.
# (And we'd include `new_optimizer_state` in the output, naturally.)
new_params = jax.tree_map(
lambda param, g: param - g * LEARNING_RATE, params, grad)
return new_params
请注意,我们手动将参数传入和传出更新函数。
import matplotlib.pyplot as plt
rng = jax.random.key(42)
# Generate true data from y = w*x + b + noise
true_w, true_b = 2, -1
x_rng, noise_rng = jax.random.split(rng)
xs = jax.random.normal(x_rng, (128, 1))
noise = jax.random.normal(noise_rng, (128, 1)) * 0.5
ys = xs * true_w + true_b + noise
# Fit regression
params = init(rng)
for _ in range(1000):
params = update(params, xs, ys)
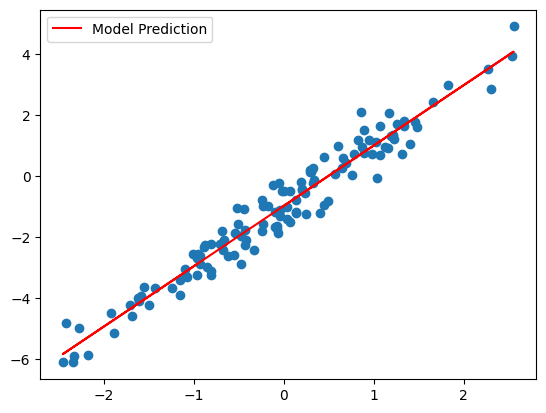
plt.scatter(xs, ys)
plt.plot(xs, params.weight * xs + params.bias, c='red', label='Model Prediction')
plt.legend();
/var/folders/xc/cwj7_pwj6lb0lkpyjtcbm7y80000gn/T/ipykernel_22949/721844192.py:37: DeprecationWarning: jax.tree_map is deprecated: use jax.tree.map (jax v0.4.25 or newer) or jax.tree_util.tree_map (any JAX version).
new_params = jax.tree_map(
更进一步#
上述策略是任何 JAX 程序在使用 jit、vmap、grad 等转换时必须处理状态的方式。
手动处理参数似乎还不错,如果你只处理两个参数的话,但如果是一个有几十层的神经网络呢?你可能已经开始担心两件事:
我们是否应该手动初始化它们,本质上是在重复我们在前向传递定义中已经写的内容?
我们是否应该手动处理所有这些事情?
细节处理可能很棘手,但有一些库可以为你处理这些。请参阅 JAX 神经网络库 获取一些示例。