ecdf#
- scipy.stats.ecdf(sample)[源代码][源代码]#
样本的经验累积分布函数。
经验累积分布函数 (ECDF) 是对样本基础分布的 CDF 的阶跃函数估计。此函数返回表示经验分布函数及其补集,即经验生存函数的对象。
- 参数:
- 示例 : 1D array_like 或
scipy.stats.CensoredData1D 数组类或 除了类数组对象,包含未删失和右删失观测值的
scipy.stats.CensoredData实例也受支持。目前,其他scipy.stats.CensoredData实例将导致NotImplementedError。
- 示例 : 1D array_like 或
- 返回:
- res
ECDFResult 一个具有以下属性的对象。
- cdf经验分布函数
一个表示经验累积分布函数的对象。
- sf经验分布函数
一个表示经验生存函数的对象。
cdf 和 sf 属性本身具有以下属性。
- 分位数ndarray
定义经验累积分布函数/生存函数的样本中的唯一值。
- 概率ndarray
与 分位数 对应的概率的点估计。
以及以下方法:
- evaluate(x) :
在参数处评估CDF/SF。
- plot(ax) :
在提供的轴上绘制CDF/SF。
- confidence_interval(confidence_level=0.95) :
计算 quantiles 中值处的 CDF/SF 周围的置信区间。
- res
注释
当样本的每次观测都是精确测量时,经验累积分布函数(ECDF)在每次观测时上升
1/len(sample)[1]。当观测值是下限、上限,或同时是上下限时,数据被称为“删失”,并且 sample 可以作为
scipy.stats.CensoredData的实例提供。对于右删失数据,ECDF 由 Kaplan-Meier 估计量给出 [2];目前不支持其他形式的删失。
置信区间是根据格林伍德公式或更新的“指数格林伍德”公式计算的,如[R50f2a5c69eed-4]_中所述。
参考文献
[2]Kaplan, Edward L., 和 Paul Meier. “不完全观测下的非参数估计.” 美国统计协会杂志 53.282 (1958): 457-481.
[3]Goel, Manish Kumar, Pardeep Khanna, 和 Jugal Kishore. “理解生存分析:Kaplan-Meier 估计.” 国际阿育吠陀研究杂志 1.4 (2010): 274.
[4]Sawyer, Stanley. “生存分析中的格林伍德和指数格林伍德置信区间。” https://www.math.wustl.edu/~sawyer/handouts/greenwood.pdf
示例
未审查数据
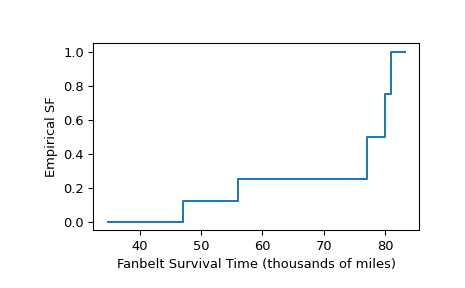
如[R50f2a5c69eed-1]_第79页的示例所示,从一所高中随机选出了五名男孩。他们的1英里跑时间记录如下。
>>> sample = [6.23, 5.58, 7.06, 6.42, 5.20] # one-mile run times (minutes)
经验分布函数,它近似于从男孩样本中抽取的总体的一英里跑时间的分布函数,计算如下。
>>> from scipy import stats >>> res = stats.ecdf(sample) >>> res.cdf.quantiles array([5.2 , 5.58, 6.23, 6.42, 7.06]) >>> res.cdf.probabilities array([0.2, 0.4, 0.6, 0.8, 1. ])
要将结果绘制为阶跃函数:
>>> import matplotlib.pyplot as plt >>> ax = plt.subplot() >>> res.cdf.plot(ax) >>> ax.set_xlabel('One-Mile Run Time (minutes)') >>> ax.set_ylabel('Empirical CDF') >>> plt.show()
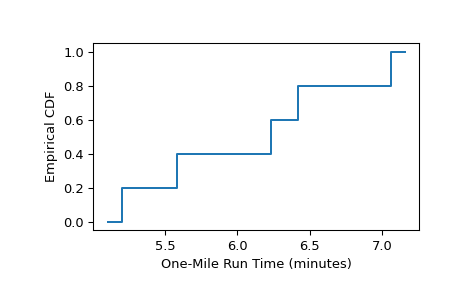
右删失数据
如 [1] 第91页的示例所示,测试了十条汽车风扇皮带的使用寿命。五次测试因被测试的风扇皮带断裂而结束,但其余测试因其他原因(例如研究资金耗尽,但风扇皮带仍能正常工作)而结束。风扇皮带行驶的里程记录如下。
>>> broken = [77, 47, 81, 56, 80] # in thousands of miles driven >>> unbroken = [62, 60, 43, 71, 37]
测试结束时仍能正常工作的风扇皮带的精确使用寿命未知,但已知它们超过了
unbroken中记录的值。因此,这些观察结果被称为“右删失”,数据使用scipy.stats.CensoredData表示。>>> sample = stats.CensoredData(uncensored=broken, right=unbroken)
经验生存函数计算如下。
>>> res = stats.ecdf(sample) >>> res.sf.quantiles array([37., 43., 47., 56., 60., 62., 71., 77., 80., 81.]) >>> res.sf.probabilities array([1. , 1. , 0.875, 0.75 , 0.75 , 0.75 , 0.75 , 0.5 , 0.25 , 0. ])
要将结果绘制为阶跃函数:
>>> ax = plt.subplot() >>> res.cdf.plot(ax) >>> ax.set_xlabel('Fanbelt Survival Time (thousands of miles)') >>> ax.set_ylabel('Empirical SF') >>> plt.show()