scipy.stats.lognorm#
- scipy.stats.lognorm = <scipy.stats._continuous_distns.lognorm_gen object>[源代码]#
对数正态连续随机变量。
作为
rv_continuous类的一个实例,lognorm对象继承了它的一系列通用方法(完整列表见下文),并根据此特定分布的细节对其进行了补充。方法
rvs(s, loc=0, scale=1, size=1, random_state=None)
随机变量。
pdf(x, s, loc=0, scale=1)
概率密度函数。
logpdf(x, s, loc=0, scale=1)
概率密度函数的对数。
cdf(x, s, loc=0, scale=1)
累积分布函数。
logcdf(x, s, loc=0, scale=1)
累积分布函数的对数。
sf(x, s, loc=0, scale=1)
生存函数 (也定义为
1 - cdf,但 sf 有时更精确)。logsf(x, s, loc=0, scale=1)
生存函数的对数。
ppf(q, s, loc=0, scale=1)
百分点函数(
cdf的逆函数 — 百分位数)。isf(q, s, loc=0, scale=1)
逆生存函数(
sf的逆函数)。moment(order, s, loc=0, scale=1)
指定阶数的非中心矩。
stats(s, loc=0, scale=1, moments=’mv’)
均值(‘m’)、方差(‘v’)、偏度(‘s’) 和/或 峰度(‘k’)。
entropy(s, loc=0, scale=1)
(微分)随机变量的熵。
fit(data)
通用数据的参数估计。有关关键字参数的详细文档,请参见 scipy.stats.rv_continuous.fit 。
expect(func, args=(s,), loc=0, scale=1, lb=None, ub=None, conditional=False, **kwds)
函数(单参数)相对于分布的期望值。
median(s, loc=0, scale=1)
分布的中位数。
mean(s, loc=0, scale=1)
分布的均值。
var(s, loc=0, scale=1)
分布的方差。
std(s, loc=0, scale=1)
分布的标准差。
interval(confidence, s, loc=0, scale=1)
在中位数周围等面积的置信区间。
注释
lognorm的概率密度函数为:\[f(x, s) = \frac{1}{s x \sqrt{2\pi}} \exp\left(-\frac{\log^2(x)}{2s^2}\right)\]对于 \(x > 0\), \(s > 0\)。
lognorm以s作为 \(s\) 的形状参数。上述概率密度是在“标准化”形式中定义的。要移动和/或缩放分布,请使用
loc和scale参数。具体来说,lognorm.pdf(x, s, loc, scale)完全等同于lognorm.pdf(y, s) / scale,其中y = (x - loc) / scale。请注意,移动分布的位置并不会使其成为“非中心”分布;某些分布的非中心泛化在单独的类中可用。假设一个正态分布的随机变量
X具有均值mu和标准差sigma。那么Y = exp(X)是具有s = sigma和scale = exp(mu)的对数正态分布。示例
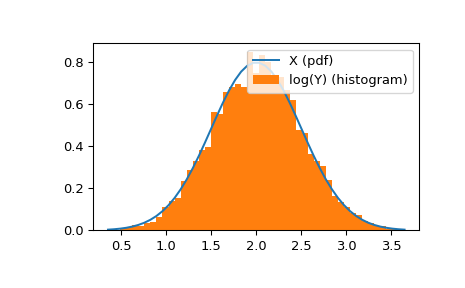
>>> import numpy as np >>> from scipy.stats import lognorm >>> import matplotlib.pyplot as plt >>> fig, ax = plt.subplots(1, 1)
计算前四个矩:
>>> s = 0.954 >>> mean, var, skew, kurt = lognorm.stats(s, moments='mvsk')
显示概率密度函数 (
pdf):>>> x = np.linspace(lognorm.ppf(0.01, s), ... lognorm.ppf(0.99, s), 100) >>> ax.plot(x, lognorm.pdf(x, s), ... 'r-', lw=5, alpha=0.6, label='lognorm pdf')
或者,分布对象可以被调用(作为一个函数)来固定形状、位置和尺度参数。这将返回一个持有给定参数固定的“冻结”RV对象。
冻结分发并显示冻结的
pdf:>>> rv = lognorm(s) >>> ax.plot(x, rv.pdf(x), 'k-', lw=2, label='frozen pdf')
检查
cdf和ppf的准确性:>>> vals = lognorm.ppf([0.001, 0.5, 0.999], s) >>> np.allclose([0.001, 0.5, 0.999], lognorm.cdf(vals, s)) True
生成随机数:
>>> r = lognorm.rvs(s, size=1000)
并比较直方图:
>>> ax.hist(r, density=True, bins='auto', histtype='stepfilled', alpha=0.2) >>> ax.set_xlim([x[0], x[-1]]) >>> ax.legend(loc='best', frameon=False) >>> plt.show()
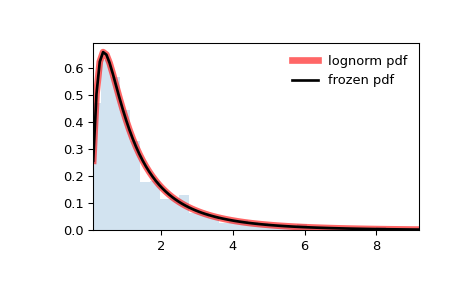
对数正态分布随机变量的对数是正态分布的:
>>> import numpy as np >>> import matplotlib.pyplot as plt >>> from scipy import stats >>> fig, ax = plt.subplots(1, 1) >>> mu, sigma = 2, 0.5 >>> X = stats.norm(loc=mu, scale=sigma) >>> Y = stats.lognorm(s=sigma, scale=np.exp(mu)) >>> x = np.linspace(*X.interval(0.999)) >>> y = Y.rvs(size=10000) >>> ax.plot(x, X.pdf(x), label='X (pdf)') >>> ax.hist(np.log(y), density=True, bins=x, label='log(Y) (histogram)') >>> ax.legend() >>> plt.show()