%%capture
!pip install hierarchicalforecast statsforecast正态性
![]()
在许多情况下,仅最低层次的时间序列(底层时间序列)可用。HierarchicalForecast具有创建所有层次时间序列的工具,并且还允许您计算所有层次的预测区间。在本笔记本中,我们将看到如何做到这一点。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 计算基础预测无一致性
from statsforecast.models import AutoARIMA
from statsforecast.core import StatsForecast
#获取分层协调方法及评估
from hierarchicalforecast.methods import BottomUp, MinTrace
from hierarchicalforecast.utils import aggregate, HierarchicalPlot
from hierarchicalforecast.core import HierarchicalReconciliation
from hierarchicalforecast.evaluation import HierarchicalEvaluation/Users/fedex/miniconda3/envs/hierarchicalforecast/lib/python3.10/site-packages/statsforecast/core.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from tqdm.autonotebook import tqdm汇总底部时间序列
在这个例子中,我们将使用旅游数据集,该数据集来自预测:原则与实践这本书。该数据集仅包含最低级别的时间序列,因此我们需要为所有层级创建时间序列。
Y_df = pd.read_csv('https://raw.githubusercontent.com/Nixtla/transfer-learning-time-series/main/datasets/tourism.csv')
Y_df = Y_df.rename({'Trips': 'y', 'Quarter': 'ds'}, axis=1)
Y_df.insert(0, 'Country', 'Australia')
Y_df = Y_df[['Country', 'Region', 'State', 'Purpose', 'ds', 'y']]
Y_df['ds'] = Y_df['ds'].str.replace(r'(\d+) (Q\d)', r'\1-\2', regex=True)
Y_df['ds'] = pd.to_datetime(Y_df['ds'])
Y_df.head()| Country | Region | State | Purpose | ds | y | |
|---|---|---|---|---|---|---|
| 0 | Australia | Adelaide | South Australia | Business | 1998-01-01 | 135.077690 |
| 1 | Australia | Adelaide | South Australia | Business | 1998-04-01 | 109.987316 |
| 2 | Australia | Adelaide | South Australia | Business | 1998-07-01 | 166.034687 |
| 3 | Australia | Adelaide | South Australia | Business | 1998-10-01 | 127.160464 |
| 4 | Australia | Adelaide | South Australia | Business | 1999-01-01 | 137.448533 |
数据集可以按以下非严格层次结构进行分组。
spec = [
['Country'],
['Country', 'State'],
['Country', 'Purpose'],
['Country', 'State', 'Region'],
['Country', 'State', 'Purpose'],
['Country', 'State', 'Region', 'Purpose']
]使用HierarchicalForecast中的aggregate函数,我们可以生成: 1. Y_df:分层结构系列 \(\mathbf{y}_{[a,b]\tau}\) 2. S_df:包含聚合约束的数据框 \(S_{[a,b]}\) 3. tags:一个包含符合每个聚合级别的’unique_ids’的列表。
Y_df, S_df, tags = aggregate(df=Y_df, spec=spec)
Y_df = Y_df.reset_index()/Users/fedex/miniconda3/envs/hierarchicalforecast/lib/python3.10/site-packages/sklearn/preprocessing/_encoders.py:828: FutureWarning: `sparse` was renamed to `sparse_output` in version 1.2 and will be removed in 1.4. `sparse_output` is ignored unless you leave `sparse` to its default value.
warnings.warn(Y_df.head()| unique_id | ds | y | |
|---|---|---|---|
| 0 | Australia | 1998-01-01 | 23182.197269 |
| 1 | Australia | 1998-04-01 | 20323.380067 |
| 2 | Australia | 1998-07-01 | 19826.640511 |
| 3 | Australia | 1998-10-01 | 20830.129891 |
| 4 | Australia | 1999-01-01 | 22087.353380 |
S_df.iloc[:5, :5]| Australia/ACT/Canberra/Business | Australia/ACT/Canberra/Holiday | Australia/ACT/Canberra/Other | Australia/ACT/Canberra/Visiting | Australia/New South Wales/Blue Mountains/Business | |
|---|---|---|---|---|---|
| Australia | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| Australia/ACT | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 |
| Australia/New South Wales | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| Australia/Northern Territory | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Australia/Queensland | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
tags['Country/Purpose']array(['Australia/Business', 'Australia/Holiday', 'Australia/Other',
'Australia/Visiting'], dtype=object)我们可以使用 HierarchicalPlot 类可视化 S 矩阵和数据,如下所示。
hplot = HierarchicalPlot(S=S_df, tags=tags)hplot.plot_summing_matrix()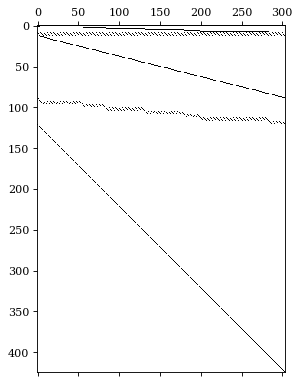
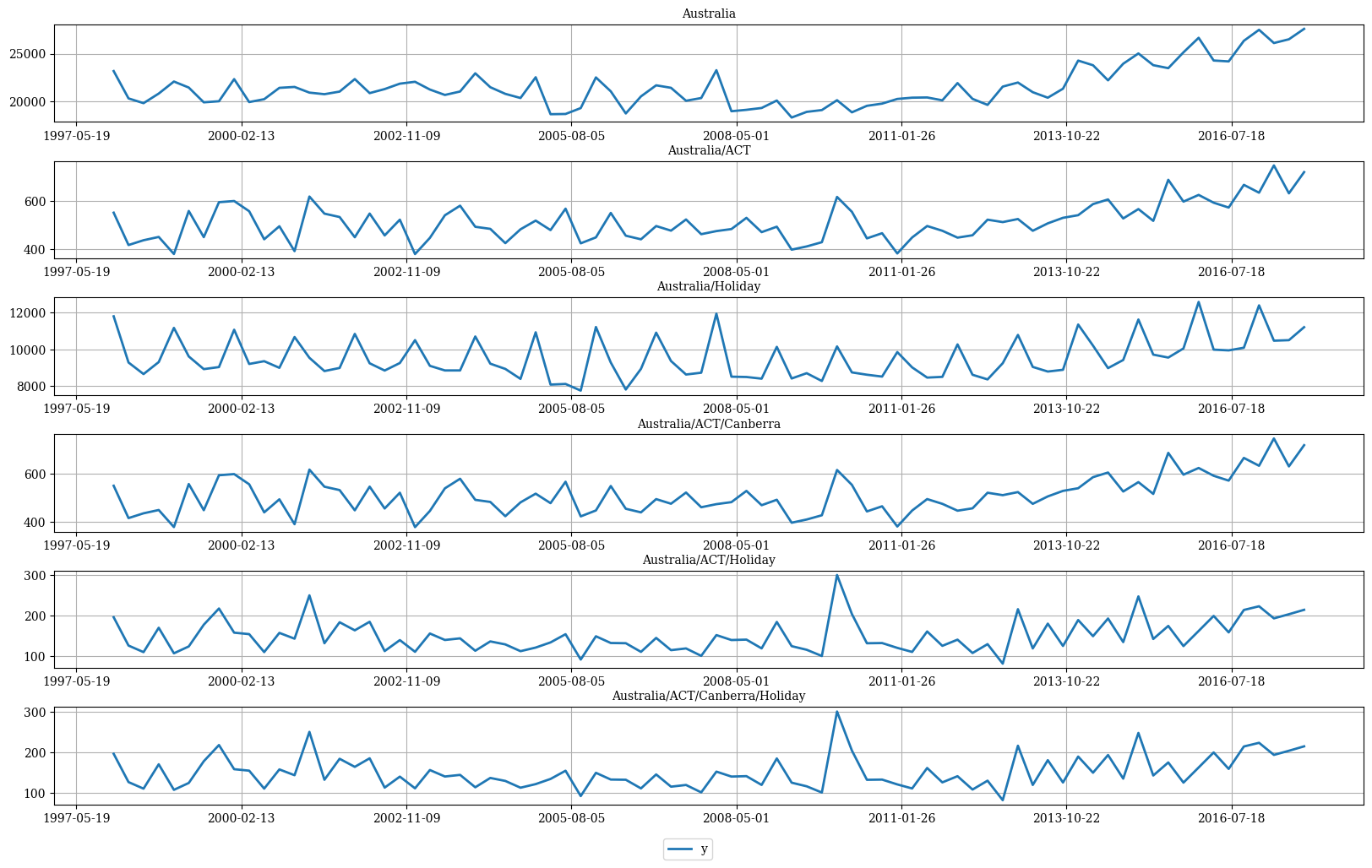
hplot.plot_hierarchically_linked_series(
bottom_series='Australia/ACT/Canberra/Holiday',
Y_df=Y_df.set_index('unique_id')
)
划分训练/测试集
我们使用最后两年(8个季度)作为测试集。
Y_test_df = Y_df.groupby('unique_id').tail(8)
Y_train_df = Y_df.drop(Y_test_df.index)Y_test_df = Y_test_df.set_index('unique_id')
Y_train_df = Y_train_df.set_index('unique_id')Y_train_df.groupby('unique_id').size()unique_id
Australia 72
Australia/ACT 72
Australia/ACT/Business 72
Australia/ACT/Canberra 72
Australia/ACT/Canberra/Business 72
..
Australia/Western Australia/Experience Perth/Other 72
Australia/Western Australia/Experience Perth/Visiting 72
Australia/Western Australia/Holiday 72
Australia/Western Australia/Other 72
Australia/Western Australia/Visiting 72
Length: 425, dtype: int64计算基本预测
以下单元计算了 Y_df 中每个时间序列的 基本预测,使用了 AutoARIMA 模型。注意,Y_hat_df 包含了预测结果,但它们并不连贯。为了调整预测区间,我们需要使用 StatsForecast 的 level 参数计算不连贯的区间。
fcst = StatsForecast(df=Y_train_df,
models=[AutoARIMA(season_length=4)],
freq='QS', n_jobs=-1)
Y_hat_df = fcst.forecast(h=8, fitted=True, level=[80, 90])
Y_fitted_df = fcst.forecast_fitted_values()协调预测
下面的单元格使用 HierarchicalReconciliation 类使之前的预测一致。由于层级结构不是严格的,我们不能使用诸如 TopDown 或 MiddleOut 的方法。在此例中,我们使用 BottomUp 和 MinTrace。如果您想计算预测区间,您必须如下使用 level 参数。
reconcilers = [
BottomUp(),
MinTrace(method='mint_shrink'),
MinTrace(method='ols')
]
hrec = HierarchicalReconciliation(reconcilers=reconcilers)
Y_rec_df = hrec.reconcile(Y_hat_df=Y_hat_df, Y_df=Y_fitted_df,
S=S_df, tags=tags, level=[80, 90])数据框 Y_rec_df 包含了调和后的预测结果。
Y_rec_df.head()| ds | AutoARIMA | AutoARIMA-lo-90 | AutoARIMA-lo-80 | AutoARIMA-hi-80 | AutoARIMA-hi-90 | AutoARIMA/BottomUp | AutoARIMA/BottomUp-lo-90 | AutoARIMA/BottomUp-lo-80 | AutoARIMA/BottomUp-hi-80 | ... | AutoARIMA/MinTrace_method-mint_shrink | AutoARIMA/MinTrace_method-mint_shrink-lo-90 | AutoARIMA/MinTrace_method-mint_shrink-lo-80 | AutoARIMA/MinTrace_method-mint_shrink-hi-80 | AutoARIMA/MinTrace_method-mint_shrink-hi-90 | AutoARIMA/MinTrace_method-ols | AutoARIMA/MinTrace_method-ols-lo-90 | AutoARIMA/MinTrace_method-ols-lo-80 | AutoARIMA/MinTrace_method-ols-hi-80 | AutoARIMA/MinTrace_method-ols-hi-90 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| unique_id | |||||||||||||||||||||
| Australia | 2016-01-01 | 26212.554688 | 24694.224609 | 25029.580078 | 27395.527344 | 27730.884766 | 24368.099609 | 23674.076441 | 23827.366706 | 24908.832513 | ... | 25205.749397 | 24453.417115 | 24619.586229 | 25791.912565 | 25958.081679 | 26059.047512 | 24978.608364 | 25217.247087 | 26900.847937 | 27139.486661 |
| Australia | 2016-04-01 | 25033.667969 | 23324.066406 | 23701.669922 | 26365.666016 | 26743.269531 | 22395.921875 | 21629.482078 | 21798.767146 | 22993.076604 | ... | 23720.833190 | 22915.772233 | 23093.587632 | 24348.078748 | 24525.894148 | 24769.464257 | 23554.946551 | 23823.199470 | 25715.729045 | 25983.981963 |
| Australia | 2016-07-01 | 24507.027344 | 22625.500000 | 23041.076172 | 25972.978516 | 26388.554688 | 22004.169922 | 21182.945074 | 21364.330624 | 22644.009219 | ... | 23167.123691 | 22316.298074 | 22504.221604 | 23830.025777 | 24017.949308 | 24205.855344 | 22870.661086 | 23165.568073 | 25246.142616 | 25541.049603 |
| Australia | 2016-10-01 | 25598.929688 | 23559.919922 | 24010.281250 | 27187.578125 | 27637.937500 | 22325.056641 | 21456.892977 | 21648.645996 | 23001.467285 | ... | 23982.251913 | 23087.313715 | 23284.980478 | 24679.523348 | 24877.190111 | 25271.861336 | 23825.782311 | 24145.180634 | 26398.542038 | 26717.940362 |
| Australia | 2017-01-01 | 26982.578125 | 24651.535156 | 25166.396484 | 28798.757812 | 29313.619141 | 23258.001953 | 22296.178714 | 22508.618508 | 24007.385398 | ... | 25002.243615 | 24016.747195 | 24234.415731 | 25770.071498 | 25987.740034 | 26611.143736 | 24959.636647 | 25324.408272 | 27897.879201 | 28262.650825 |
5 rows × 21 columns
绘制预测图
然后我们可以使用以下函数绘制概率预测。
plot_df = pd.concat([Y_df.set_index(['unique_id', 'ds']),
Y_rec_df.set_index('ds', append=True)], axis=1)
plot_df = plot_df.reset_index('ds')绘制单个时间序列
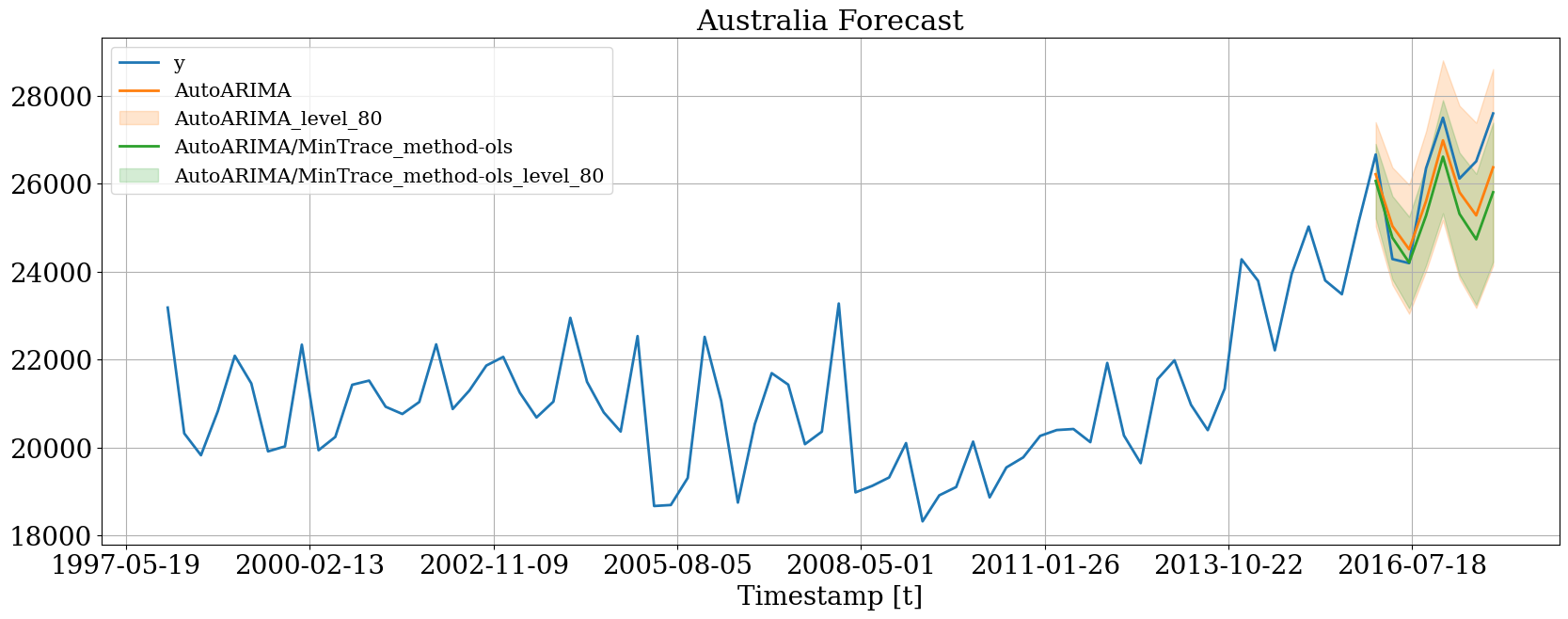
hplot.plot_series(
series='Australia',
Y_df=plot_df,
models=['y', 'AutoARIMA', 'AutoARIMA/MinTrace_method-ols'],
level=[80]
)
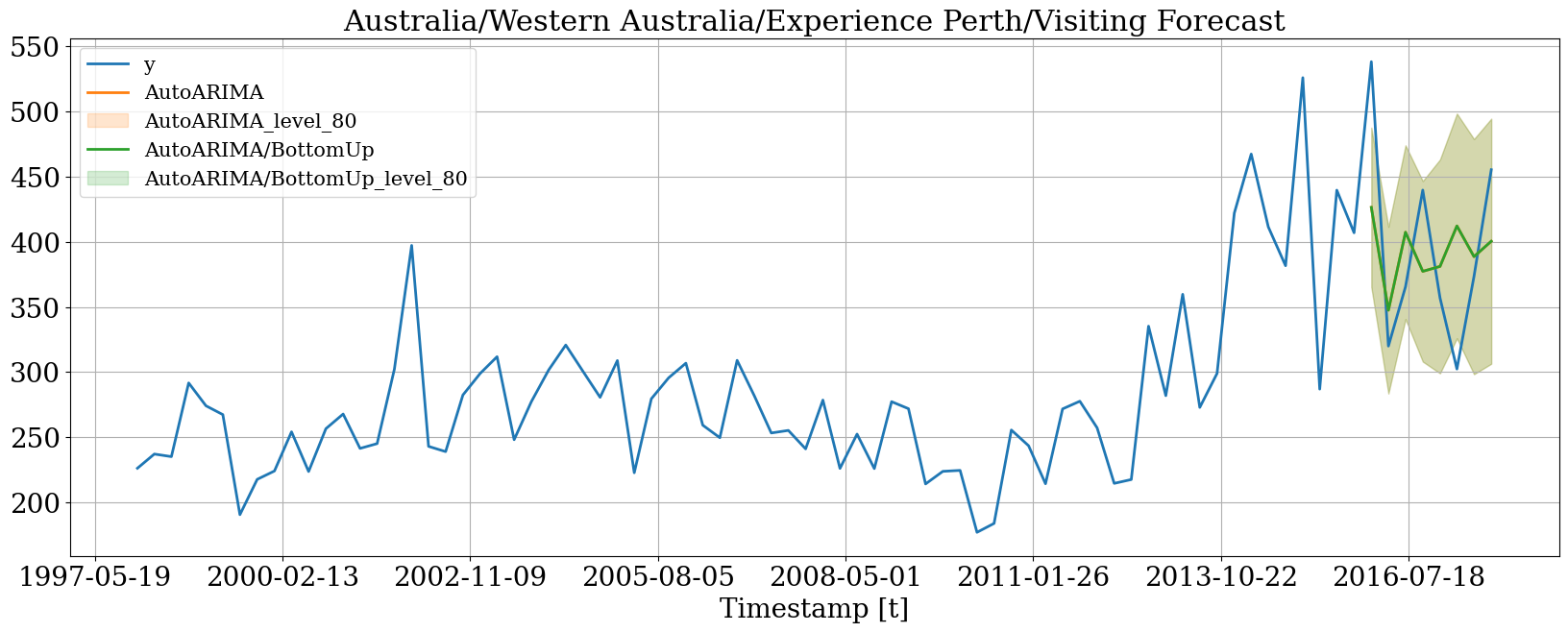
# 由于我们正在绘制一个底部时间序列
# 概率预报和平均预报
# 是相同的
hplot.plot_series(
series='Australia/Western Australia/Experience Perth/Visiting',
Y_df=plot_df,
models=['y', 'AutoARIMA', 'AutoARIMA/BottomUp'],
level=[80]
)
绘制层次关联的时间序列
hplot.plot_hierarchically_linked_series(
bottom_series='Australia/Western Australia/Experience Perth/Visiting',
Y_df=plot_df,
models=['y', 'AutoARIMA', 'AutoARIMA/MinTrace_method-ols', 'AutoARIMA/BottomUp'],
level=[80]
)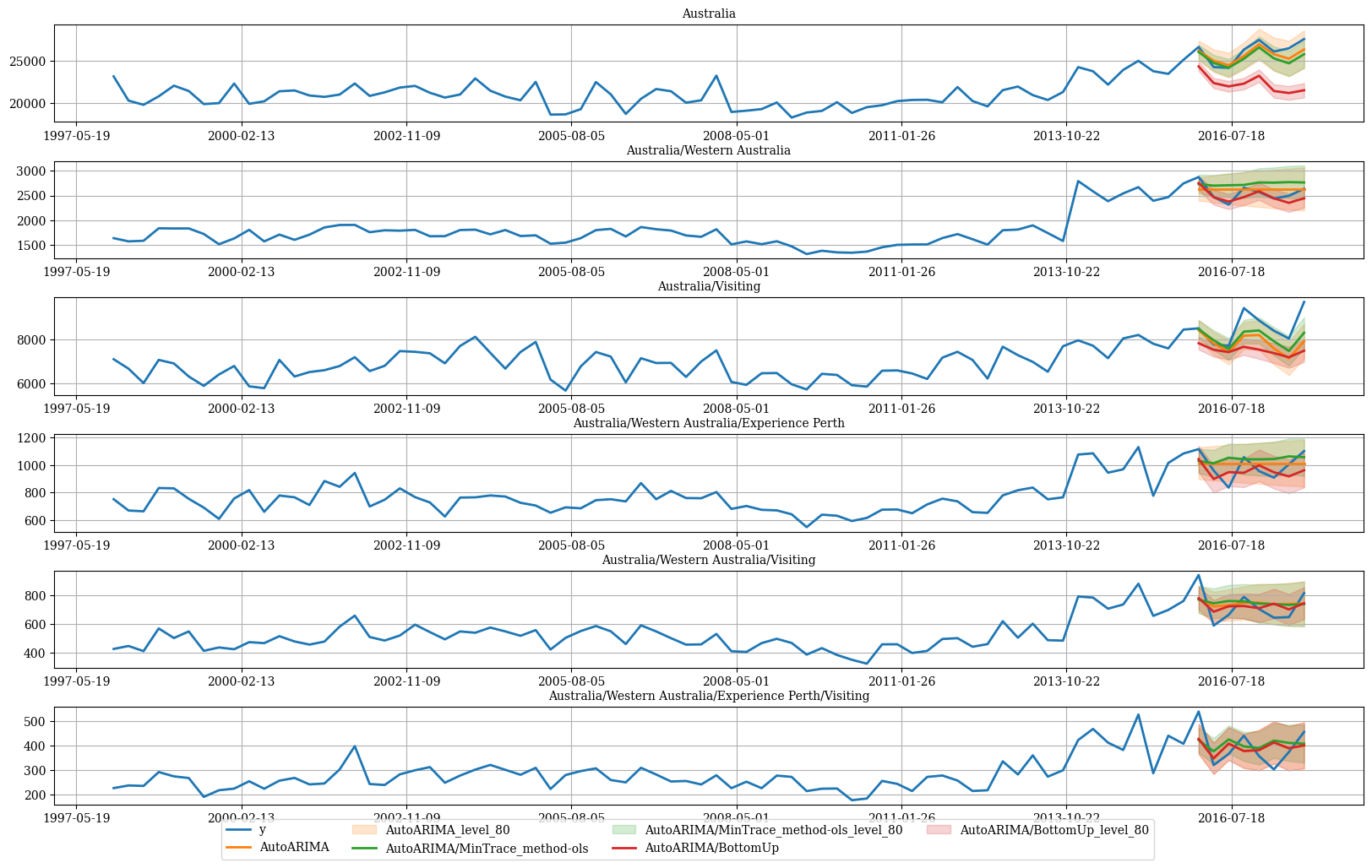
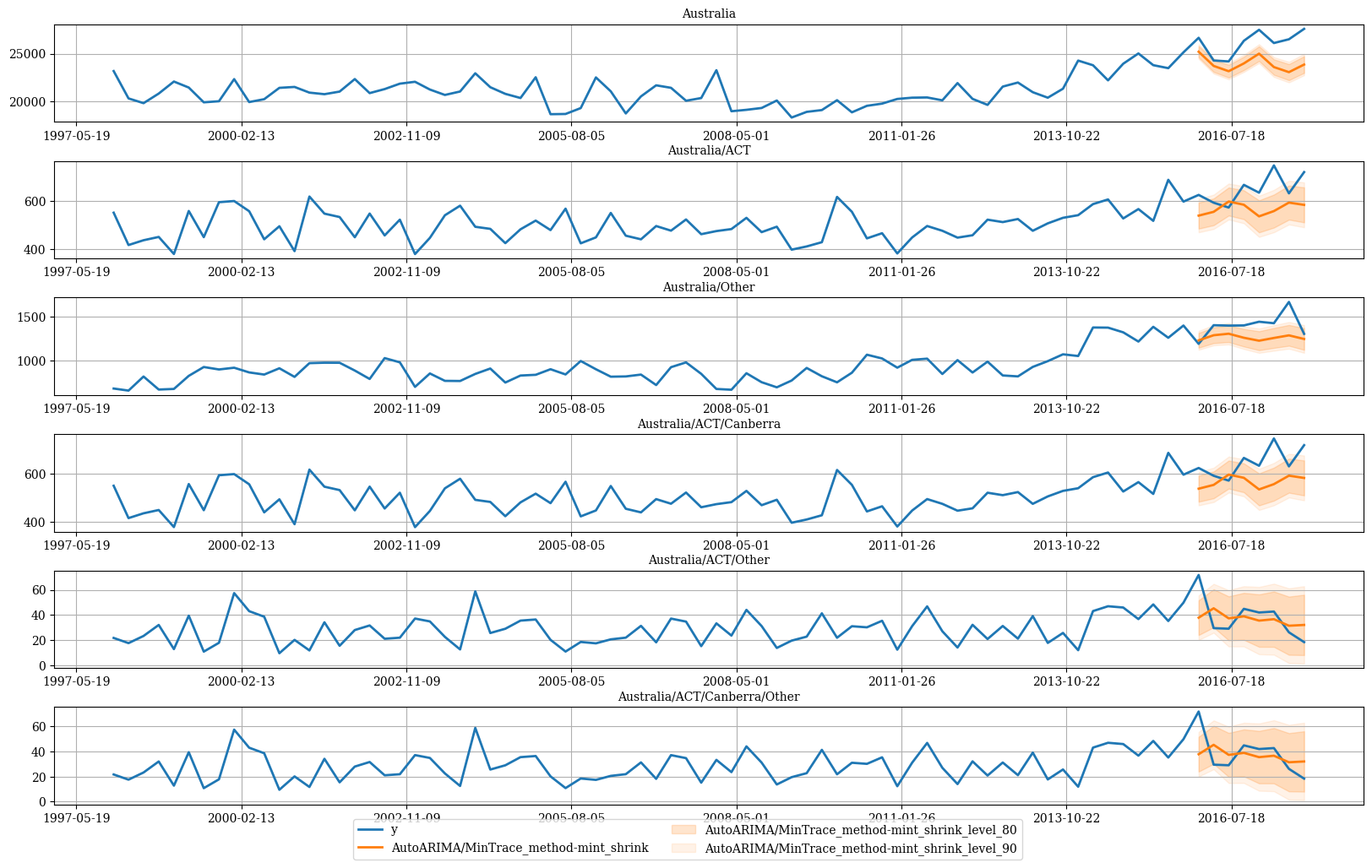
# ACT 仅拥有堪培拉
hplot.plot_hierarchically_linked_series(
bottom_series='Australia/ACT/Canberra/Other',
Y_df=plot_df,
models=['y', 'AutoARIMA/MinTrace_method-mint_shrink'],
level=[80, 90]
)
参考文献
- Hyndman, R.J., & Athanasopoulos, G. (2021). “预测:原理与实践, 第3版: 第11章:预测分层和分组系列。” OTexts: 墨尔本, 澳大利亚. OTexts.com/fpp3 访问于2022年7月。
- Shanika L. Wickramasuriya, George Athanasopoulos, 和 Rob J. Hyndman. 通过迹最小化对分层和分组时间序列进行最优预测协调. 美国统计协会杂志, 114(526):804–819, 2019. doi: 10.1080/01621459.2018.1448825. URL https://robjhyndman.com/publications/mint/.
If you find the code useful, please ⭐ us on Github