如何构建知识图谱
在本指南中,我们将介绍基于非结构化文本构建知识图谱的基本方法。构建的图谱随后可以用作RAG应用程序中的知识库。
⚠️ 安全提示 ⚠️
构建知识图谱需要对数据库执行写操作。这样做存在固有的风险。在导入数据之前,请确保验证和确认数据。有关一般安全最佳实践的更多信息,请参见此处。
架构
从高层次来看,从文本构建知识图谱的步骤是:
- 从文本中提取结构化信息:模型用于从文本中提取结构化图信息。
- 存储到图数据库:将提取的结构化图信息存储到图数据库中,使下游的RAG应用能够使用
设置
首先,获取所需的包并设置环境变量。 在这个例子中,我们将使用Neo4j图数据库。
%pip install --upgrade --quiet langchain langchain-neo4j langchain-openai langchain-experimental neo4j
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m A new release of pip is available: [0m[31;49m24.0[0m[39;49m -> [0m[32;49m24.3.1[0m
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m To update, run: [0m[32;49mpip install --upgrade pip[0m
Note: you may need to restart the kernel to use updated packages.
在本指南中,我们默认使用OpenAI模型。
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Uncomment the below to use LangSmith. Not required.
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
········
接下来,我们需要定义Neo4j的凭据和连接。 按照这些安装步骤来设置Neo4j数据库。
import os
from langchain_neo4j import Neo4jGraph
os.environ["NEO4J_URI"] = "bolt://localhost:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "password"
graph = Neo4jGraph(refresh_schema=False)
LLM 图转换器
从文本中提取图数据可以将非结构化信息转换为结构化格式,从而促进对复杂关系和模式的深入洞察和更高效的导航。LLMGraphTransformer 通过利用 LLM 解析和分类实体及其关系,将文本文档转换为结构化图文档。LLM 模型的选择通过确定提取的图数据的准确性和细微差别,显著影响输出结果。
import os
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0, model_name="gpt-4-turbo")
llm_transformer = LLMGraphTransformer(llm=llm)
现在我们可以传入示例文本并检查结果。
from langchain_core.documents import Document
text = """
Marie Curie, born in 1867, was a Polish and naturalised-French physicist and chemist who conducted pioneering research on radioactivity.
She was the first woman to win a Nobel Prize, the first person to win a Nobel Prize twice, and the only person to win a Nobel Prize in two scientific fields.
Her husband, Pierre Curie, was a co-winner of her first Nobel Prize, making them the first-ever married couple to win the Nobel Prize and launching the Curie family legacy of five Nobel Prizes.
She was, in 1906, the first woman to become a professor at the University of Paris.
"""
documents = [Document(page_content=text)]
graph_documents = llm_transformer.convert_to_graph_documents(documents)
print(f"Nodes:{graph_documents[0].nodes}")
print(f"Relationships:{graph_documents[0].relationships}")
Nodes:[Node(id='Marie Curie', type='Person', properties={}), Node(id='Pierre Curie', type='Person', properties={}), Node(id='University Of Paris', type='Organization', properties={})]
Relationships:[Relationship(source=Node(id='Marie Curie', type='Person', properties={}), target=Node(id='Pierre Curie', type='Person', properties={}), type='MARRIED', properties={}), Relationship(source=Node(id='Marie Curie', type='Person', properties={}), target=Node(id='University Of Paris', type='Organization', properties={}), type='PROFESSOR', properties={})]
检查以下图像以更好地理解生成的知识图谱的结构。
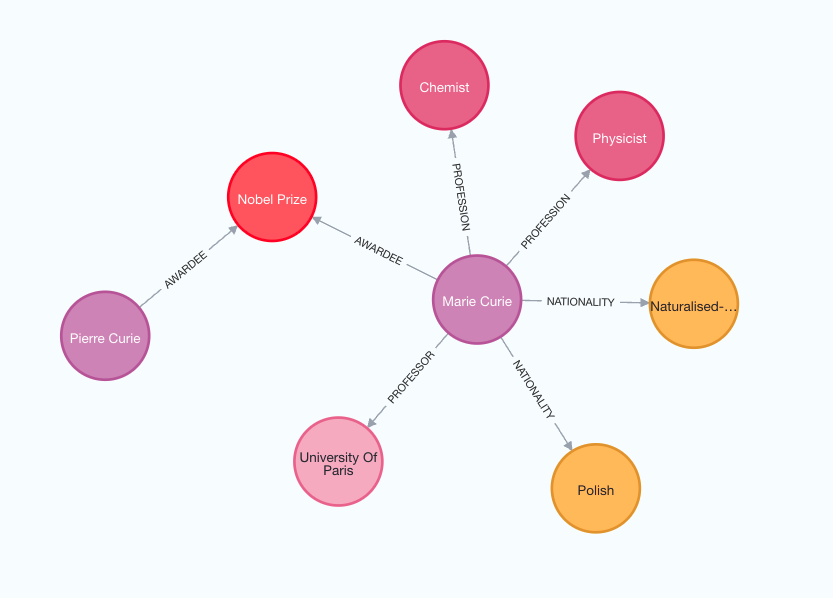
请注意,由于我们使用的是LLM,图构建过程是非确定性的。因此,每次执行时可能会得到略有不同的结果。
此外,您可以根据需要灵活定义要提取的特定类型的节点和关系。
llm_transformer_filtered = LLMGraphTransformer(
llm=llm,
allowed_nodes=["Person", "Country", "Organization"],
allowed_relationships=["NATIONALITY", "LOCATED_IN", "WORKED_AT", "SPOUSE"],
)
graph_documents_filtered = llm_transformer_filtered.convert_to_graph_documents(
documents
)
print(f"Nodes:{graph_documents_filtered[0].nodes}")
print(f"Relationships:{graph_documents_filtered[0].relationships}")
Nodes:[Node(id='Marie Curie', type='Person', properties={}), Node(id='Pierre Curie', type='Person', properties={}), Node(id='University Of Paris', type='Organization', properties={})]
Relationships:[Relationship(source=Node(id='Marie Curie', type='Person', properties={}), target=Node(id='Pierre Curie', type='Person', properties={}), type='SPOUSE', properties={}), Relationship(source=Node(id='Marie Curie', type='Person', properties={}), target=Node(id='University Of Paris', type='Organization', properties={}), type='WORKED_AT', properties={})]
为了更精确地定义图模式,考虑使用三元组方法来描述关系。在这种方法中,每个元组由三个元素组成:源节点、关系类型和目标节点。
allowed_relationships = [
("Person", "SPOUSE", "Person"),
("Person", "NATIONALITY", "Country"),
("Person", "WORKED_AT", "Organization"),
]
llm_transformer_tuple = LLMGraphTransformer(
llm=llm,
allowed_nodes=["Person", "Country", "Organization"],
allowed_relationships=allowed_relationships,
)
graph_documents_filtered = llm_transformer_tuple.convert_to_graph_documents(documents)
print(f"Nodes:{graph_documents_filtered[0].nodes}")
print(f"Relationships:{graph_documents_filtered[0].relationships}")
Nodes:[Node(id='Marie Curie', type='Person', properties={}), Node(id='Pierre Curie', type='Person', properties={}), Node(id='University Of Paris', type='Organization', properties={})]
Relationships:[Relationship(source=Node(id='Marie Curie', type='Person', properties={}), target=Node(id='Pierre Curie', type='Person', properties={}), type='SPOUSE', properties={}), Relationship(source=Node(id='Marie Curie', type='Person', properties={}), target=Node(id='University Of Paris', type='Organization', properties={}), type='WORKED_AT', properties={})]
为了更好地理解生成的图表,我们可以再次将其可视化。
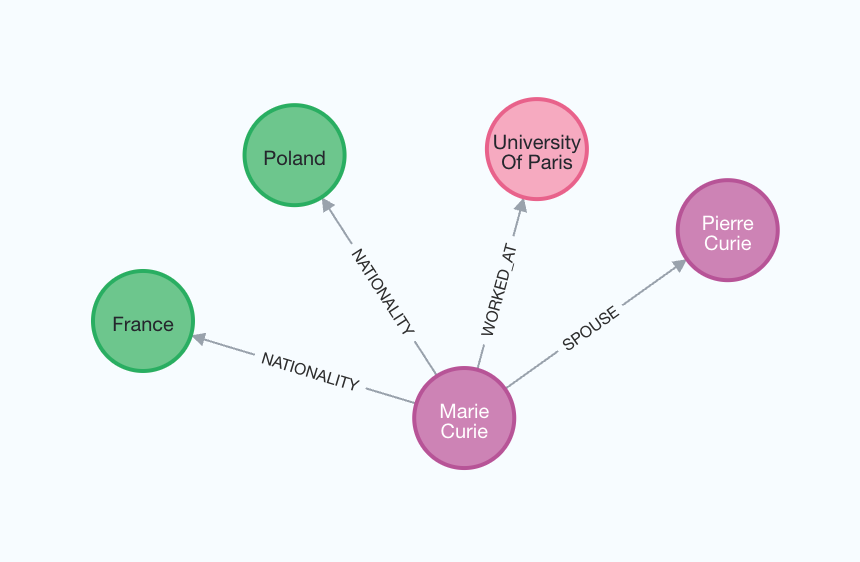
node_properties 参数允许提取节点属性,从而创建更详细的图。
当设置为 True 时,LLM 自主识别并提取相关的节点属性。
相反,如果 node_properties 被定义为一个字符串列表,LLM 会从文本中选择性地仅检索指定的属性。
llm_transformer_props = LLMGraphTransformer(
llm=llm,
allowed_nodes=["Person", "Country", "Organization"],
allowed_relationships=["NATIONALITY", "LOCATED_IN", "WORKED_AT", "SPOUSE"],
node_properties=["born_year"],
)
graph_documents_props = llm_transformer_props.convert_to_graph_documents(documents)
print(f"Nodes:{graph_documents_props[0].nodes}")
print(f"Relationships:{graph_documents_props[0].relationships}")
Nodes:[Node(id='Marie Curie', type='Person', properties={'born_year': '1867'}), Node(id='Pierre Curie', type='Person', properties={}), Node(id='University Of Paris', type='Organization', properties={}), Node(id='Poland', type='Country', properties={}), Node(id='France', type='Country', properties={})]
Relationships:[Relationship(source=Node(id='Marie Curie', type='Person', properties={}), target=Node(id='Poland', type='Country', properties={}), type='NATIONALITY', properties={}), Relationship(source=Node(id='Marie Curie', type='Person', properties={}), target=Node(id='France', type='Country', properties={}), type='NATIONALITY', properties={}), Relationship(source=Node(id='Marie Curie', type='Person', properties={}), target=Node(id='Pierre Curie', type='Person', properties={}), type='SPOUSE', properties={}), Relationship(source=Node(id='Marie Curie', type='Person', properties={}), target=Node(id='University Of Paris', type='Organization', properties={}), type='WORKED_AT', properties={})]
存储到图数据库
生成的图形文档可以使用add_graph_documents方法存储到图形数据库中。
graph.add_graph_documents(graph_documents_props)
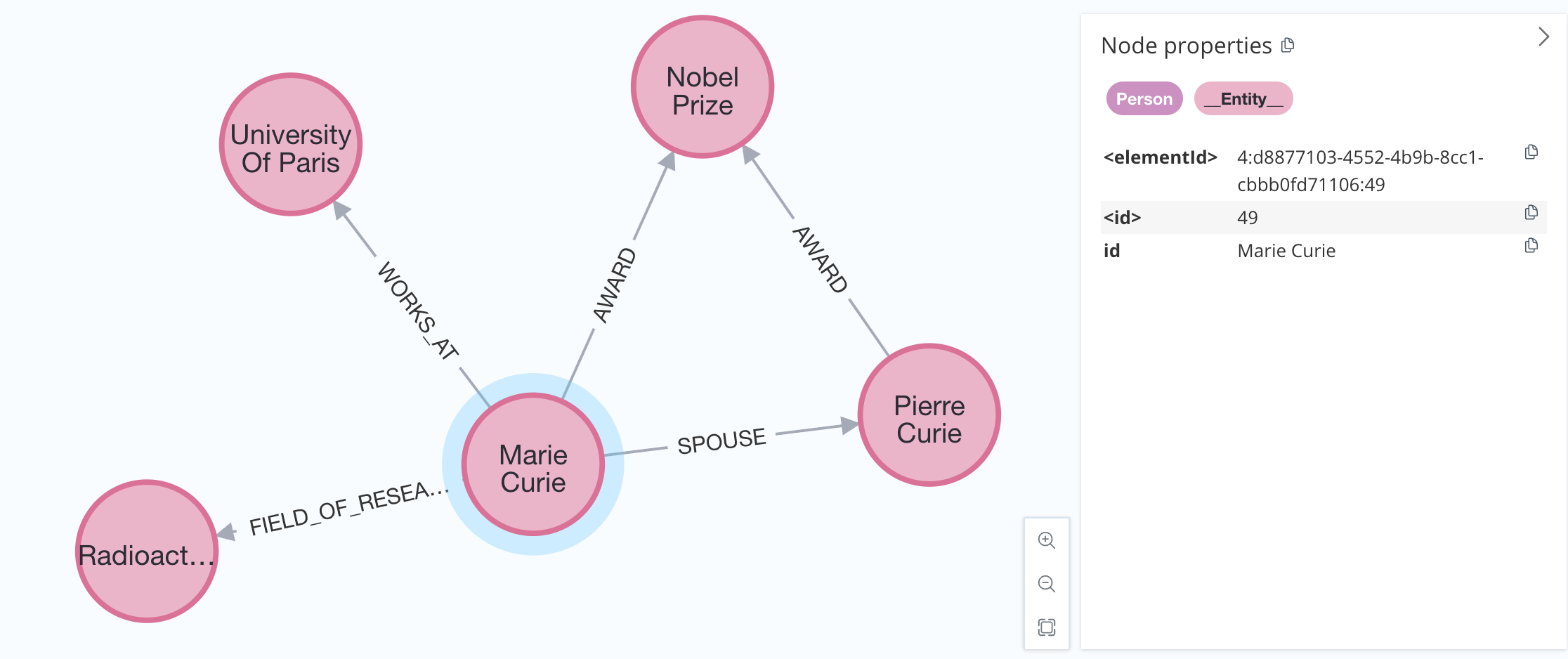
大多数图数据库支持索引以优化数据导入和检索。由于我们可能无法提前知道所有节点标签,我们可以通过使用baseEntityLabel参数为每个节点添加一个辅助基础标签来处理这个问题。
graph.add_graph_documents(graph_documents, baseEntityLabel=True)
结果将如下所示:
最终选项是同时导入提取节点和关系的源文档。这种方法让我们能够跟踪每个实体出现在哪些文档中。
graph.add_graph_documents(graph_documents, include_source=True)
图表将具有以下结构:
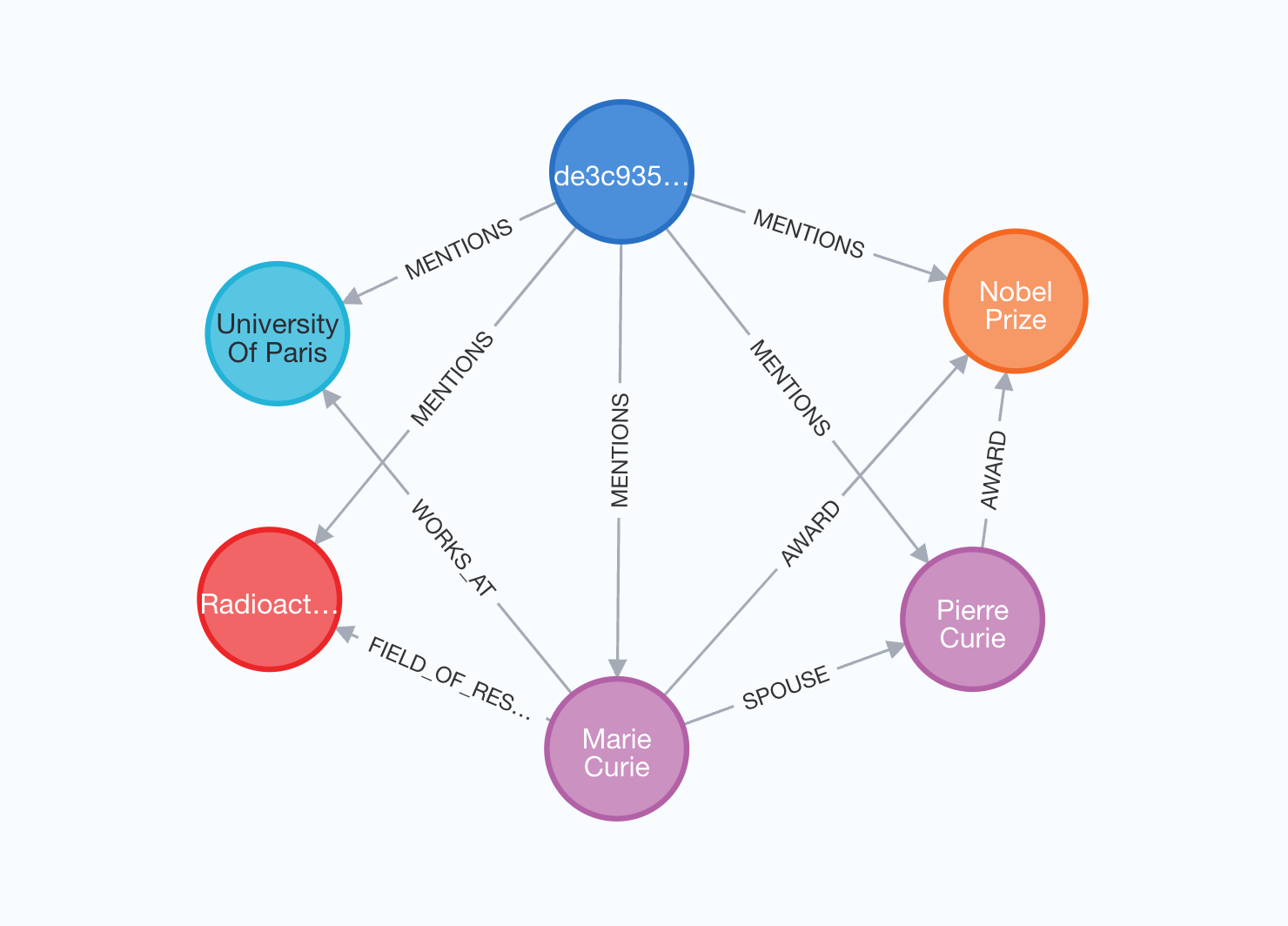
在此可视化中,源文档以蓝色高亮显示,所有从中提取的实体通过MENTIONS关系连接。