语义搜索¶
语义搜索旨在通过理解搜索查询和搜索语料库的语义含义来提高搜索的准确性。与仅能通过词汇匹配查找文档的关键词搜索引擎不同,语义搜索在处理同义词、缩写和拼写错误时也能表现良好。
背景¶
语义搜索的核心思想是将语料库中的所有条目(无论是句子、段落还是文档)嵌入到一个向量空间中。在搜索时,查询也会被嵌入到相同的向量空间中,并找到与语料库中最接近的嵌入条目。这些条目应与查询具有高度的语义相似性。
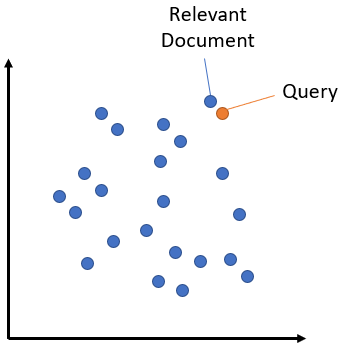
对称与非对称语义搜索¶
对于您的设置,一个关键区别是对称与非对称语义搜索:
对于对称语义搜索,您的查询和语料库中的条目长度大致相同,内容量也相似。例如,搜索相似问题:您的查询可能是“如何在线学习Python?”,而您希望找到类似“如何在网络上学习Python?”的条目。在对称任务中,您可以潜在地翻转查询和语料库中的条目。
对于非对称语义搜索,您通常有一个简短的查询(如一个问题或一些关键词),并希望找到一个较长的段落来回答该查询。例如,查询可能是“什么是Python?”,而您希望找到段落“Python是一种解释型、高级和通用的编程语言。Python的设计哲学......”。对于非对称任务,翻转查询和语料库中的条目通常没有意义。
相关训练示例:MS MARCO
适用模型:预训练MS MARCO模型
选择适合您任务类型的模型至关重要。
手动实现¶
对于小型语料库(最多约100万条目),我们可以通过手动实现语义搜索,计算语料库和查询的嵌入,然后使用SentenceTransformer.similarity计算语义文本相似度。
对于一个简单的示例,请参见semantic_search.py:
"""
This is a simple application for sentence embeddings: semantic search
We have a corpus with various sentences. Then, for a given query sentence,
we want to find the most similar sentence in this corpus.
This script outputs for various queries the top 5 most similar sentences in the corpus.
"""
import torch
from sentence_transformers import SentenceTransformer
embedder = SentenceTransformer("all-MiniLM-L6-v2")
# Corpus with example sentences
corpus = [
"A man is eating food.",
"A man is eating a piece of bread.",
"The girl is carrying a baby.",
"A man is riding a horse.",
"A woman is playing violin.",
"Two men pushed carts through the woods.",
"A man is riding a white horse on an enclosed ground.",
"A monkey is playing drums.",
"A cheetah is running behind its prey.",
]
# Use "convert_to_tensor=True" to keep the tensors on GPU (if available)
corpus_embeddings = embedder.encode(corpus, convert_to_tensor=True)
# Query sentences:
queries = [
"A man is eating pasta.",
"Someone in a gorilla costume is playing a set of drums.",
"A cheetah chases prey on across a field.",
]
# Find the closest 5 sentences of the corpus for each query sentence based on cosine similarity
top_k = min(5, len(corpus))
for query in queries:
query_embedding = embedder.encode(query, convert_to_tensor=True)
# We use cosine-similarity and torch.topk to find the highest 5 scores
similarity_scores = embedder.similarity(query_embedding, corpus_embeddings)[0]
scores, indices = torch.topk(similarity_scores, k=top_k)
print("\nQuery:", query)
print("Top 5 most similar sentences in corpus:")
for score, idx in zip(scores, indices):
print(corpus[idx], f"(Score: {score:.4f})")
"""
# Alternatively, we can also use util.semantic_search to perform cosine similarty + topk
hits = util.semantic_search(query_embedding, corpus_embeddings, top_k=5)
hits = hits[0] #Get the hits for the first query
for hit in hits:
print(corpus[hit['corpus_id']], "(Score: {:.4f})".format(hit['score']))
"""
优化实现¶
您可以使用util.semantic_search函数来代替手动实现语义搜索。
该函数接受以下参数:
- sentence_transformers.util.semantic_search(query_embeddings: ~torch.Tensor, corpus_embeddings: ~torch.Tensor, query_chunk_size: int = 100, corpus_chunk_size: int = 500000, top_k: int = 10, score_function: ~typing.Callable[[~torch.Tensor, ~torch.Tensor], ~torch.Tensor] = <function cos_sim>) list[list[dict[str, int | float]]][源代码][源代码]¶
This function performs a cosine similarity search between a list of query embeddings and a list of corpus embeddings. It can be used for Information Retrieval / Semantic Search for corpora up to about 1 Million entries.
- 参数:
query_embeddings (Tensor) -- A 2 dimensional tensor with the query embeddings.
corpus_embeddings (Tensor) -- A 2 dimensional tensor with the corpus embeddings.
query_chunk_size (int, optional) -- Process 100 queries simultaneously. Increasing that value increases the speed, but requires more memory. Defaults to 100.
corpus_chunk_size (int, optional) -- Scans the corpus 100k entries at a time. Increasing that value increases the speed, but requires more memory. Defaults to 500000.
top_k (int, optional) -- Retrieve top k matching entries. Defaults to 10.
score_function (Callable[[Tensor, Tensor], Tensor], optional) -- Function for computing scores. By default, cosine similarity.
- 返回:
A list with one entry for each query. Each entry is a list of dictionaries with the keys 'corpus_id' and 'score', sorted by decreasing cosine similarity scores.
- 返回类型:
List[List[Dict[str, Union[int, float]]]]
默认情况下,最多100个查询并行处理。此外,语料库被分块为最多50万个条目的集合。您可以增加query_chunk_size和corpus_chunk_size,这将提高大型语料库的速度,但也会增加内存需求。
速度优化¶
要为util.semantic_search方法获得最佳速度,建议将query_embeddings和corpus_embeddings放在同一个GPU设备上。这会显著提升性能。此外,我们可以对语料库嵌入进行归一化,使得每个语料库嵌入的长度为1。在这种情况下,我们可以使用点积来计算分数。
corpus_embeddings = corpus_embeddings.to("cuda")
corpus_embeddings = util.normalize_embeddings(corpus_embeddings)
query_embeddings = query_embeddings.to("cuda")
query_embeddings = util.normalize_embeddings(query_embeddings)
hits = util.semantic_search(query_embeddings, corpus_embeddings, score_function=util.dot_score)
Elasticsearch¶
Elasticsearch 提供了索引密集向量并将其用于文档评分的可能性。我们可以轻松索引嵌入向量,与向量一起存储其他数据,最重要的是,可以使用近似最近邻搜索(HNSW,见下文)在嵌入上高效检索相关条目。
近似最近邻¶
如果使用精确最近邻搜索(如util.semantic_search所使用的),在拥有数百万嵌入的大型语料库中进行搜索可能会非常耗时。
在这种情况下,近似最近邻(ANN)可能会有所帮助。在此,数据被分割成相似嵌入的小部分。可以高效地搜索此索引,并在毫秒内检索到具有最高相似度(最近邻)的嵌入,即使你有数百万个向量。然而,结果不一定精确。可能会错过一些具有高相似度的向量。
对于所有ANN方法,通常有一个或多个参数需要调整,以确定召回率-速度的权衡。如果你想要最高速度,可能会错过一些命中。如果你想要高召回率,搜索速度会降低。
三种流行的近似最近邻库是Annoy、FAISS和hnswlib。
示例:
检索与重排¶
对于复杂的语义搜索场景,建议采用两阶段的检索与重排流水线:
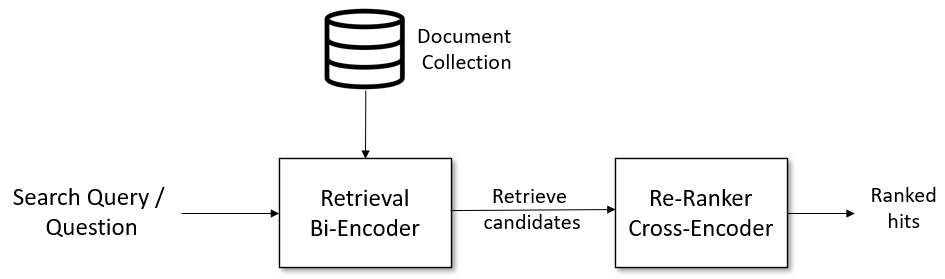
更多详情,请参见Retrieve & Re-rank。
示例¶
我们列出了一些常见的用例:
相似问题检索¶
semantic_search_quora_pytorch.py [ Colab版本 ] 展示了基于Quora重复问题数据集的示例。用户可以输入一个问题,代码使用util.semantic_search方法从数据集中检索最相似的问题。我们使用的模型是distilbert-multilingual-nli-stsb-quora-ranking,该模型经过训练以识别相似问题,并支持50多种语言。因此,用户可以用这50多种语言中的任何一种输入问题。这是一个对称搜索任务,因为搜索查询的长度和内容与语料库中的问题相同。
相似出版物检索¶
semantic_search_publications.py [ Colab版本 ] 展示了如何找到相似的科学出版物。作为语料库,我们使用了在EMNLP 2016-2018会议上展示的所有出版物。作为搜索查询,我们输入了较新出版物的标题和摘要,并从我们的语料库中找到相关出版物。我们使用的模型是SPECTER。这是一个对称搜索任务,因为语料库中的论文由标题和摘要组成,我们搜索的是标题和摘要。
问题与答案检索¶
semantic_search_wikipedia_qa.py [ Colab版本 ]: 此示例使用了一个在自然问题数据集上训练的模型。它包含了大约10万个真实的Google搜索查询,以及提供答案的维基百科注释段落。这是一个非对称搜索任务的示例。作为语料库,我们使用了较小的简单英语维基百科,以便它能够轻松适配内存。
retrieve_rerank_simple_wikipedia.ipynb [ Colab版本 ]: 此脚本使用了检索与重排策略,并作为一个非对称搜索任务的示例。我们将所有维基百科文章拆分为段落,并用一个双编码器对其进行编码。当输入新的查询/问题时,同样由该双编码器进行编码,并检索出具有最高余弦相似度的段落。接着,通过一个交叉编码器的重排序器对检索到的候选段落进行评分,并展示交叉编码器评分最高的5个段落给用户。我们使用的模型是在MS Marco段落重排序数据集上训练的,该数据集包含了约50万个来自Bing搜索的真实查询。