增强型SBERT¶
动机¶
双编码器(又称句子嵌入模型)需要在目标任务上进行大量的训练数据和微调,才能达到竞争性的表现。然而,在许多情况下,只有少量的训练数据可用。
为了解决这个实际问题,我们发布了一种有效的数据增强策略,称为增强型SBERT,我们利用高性能且慢速的交叉编码器(BERT)来标记更大的一组输入对,以增强双编码器(SBERT)的训练数据。
更多详情,请参阅我们的出版物 - 增强型SBERT:改进双编码器用于成对句子评分任务的数据增强方法,这是达姆施塔特工业大学UKP实验室Nandan Thakur、Nils Reimers和Johannes Daxenberger的联合成果。
Chien Vu还就此技术撰写了一篇不错的博客文章:通过将知识从交叉编码器转移到双编码器来提升BERT模型
扩展到您自己的数据集¶
情景1:有限的或小规模的标注数据集(少量标注的句子对(1k-3k))
如果您在公司或研究中有小型或包含少量标注句子对的专业数据集。您可以通过在小型黄金数据集上训练交叉编码器,并使用BM25采样生成之前未见过的组合,来扩展增强型SBERT(领域内)策略的想法。使用交叉编码器标记这些未标注的对,创建银牌数据集。最后,在扩展的(黄金+银牌)数据集上训练双编码器(即SBERT),如train_sts_indomain_bm25.py所示。
情景2:没有标注的数据集(只有未标注的句子对)
如果您在公司或研究中只有未标注的专业数据集。您可以通过在已标注的源数据集(例如QQP)上训练交叉编码器,来扩展增强型SBERT(领域转移)策略的想法。使用这个交叉编码器标记您的专业未标注数据集,即目标数据集。最后,在标注的目标数据集上训练双编码器,即SBERT,如train_sts_qqp_crossdomain.py所示。
方法¶
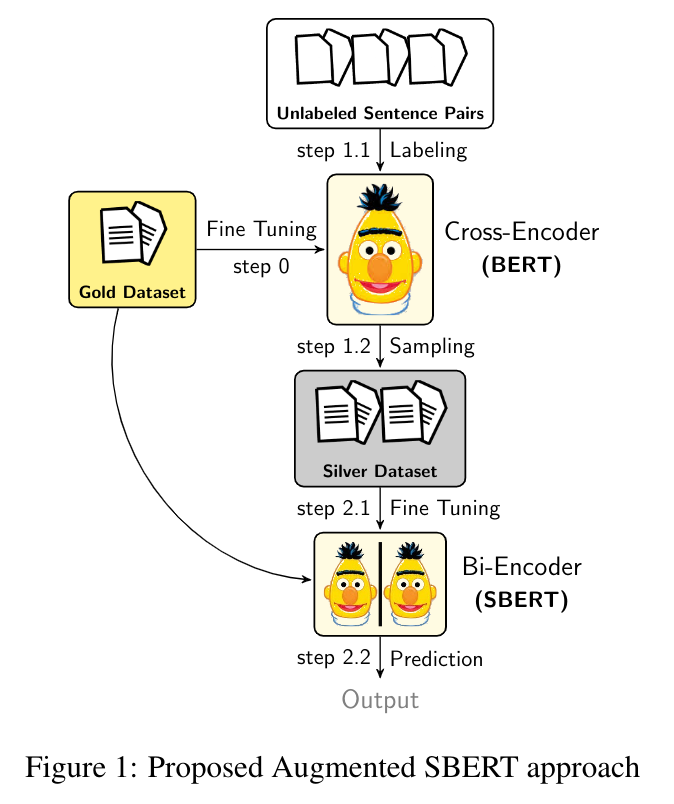
增强型SBERT方法在成对句子回归或分类任务中有两种主要情景。
情景1:有限的或小规模的标注数据集(少量标注的句子对)¶
我们应用增强型SBERT(领域内)策略,它涉及三个步骤 -
步骤1:在小规模(黄金或标注)数据集上训练交叉编码器(BERT)
步骤2.1:通过重组创建对,并通过BM25或语义搜索减少对
步骤2.2:使用交叉编码器(BERT)弱标记新对。这些是银牌对或(银牌)数据集
步骤3:最后,在扩展的(黄金+银牌)训练数据集上训练双编码器(SBERT)
情景2:没有标注的数据集(只有未标注的句子对)¶
我们应用增强型SBERT(领域转移)策略,它涉及三个步骤 -
步骤1:从头开始在源数据集上训练交叉编码器(BERT),我们拥有标注
步骤2:使用这个交叉编码器(BERT)标记您的目标数据集,即未标注的句子对
步骤3:最后,在标注的目标数据集上训练双编码器(SBERT)
训练¶
examples/training/data_augmentation 文件夹包含了以下解释的每种情景的简单训练示例:
train_sts_seed_optimization.py
此脚本从头开始为STS基准数据集训练双编码器(SBERT)模型,并进行种子优化。
种子优化技术灵感来自(Dodge et al., 2020)。
对于种子优化,我们在不同的种子上训练双编码器,并使用早期停止算法进行评估。
最后,测量种子间的开发性能,以获得最高性能的种子。
-
此脚本使用简单的数据增强从头开始为STS基准数据集训练双编码器(SBERT)模型。
数据增强策略来自流行的nlpaug包。
使用同义词(word2vec、BERT或WordNet)增强单个句子。形成我们的银牌数据集。
在原始的小训练数据集和基于同义词的银数据集上训练双编码器模型。
-
脚本首先从头开始训练一个交叉编码器(BERT)模型,用于小的STS基准数据集。
从我们的小训练数据集中重组句子,形成大量句子对。
使用Elasticsearch的BM25采样限制组合数量。
给定一个句子,检索前k个句子,并使用交叉编码器标记这些句子对(银数据集)。
在金+银STSb数据集上训练一个双编码器(SBERT)模型。(增强SBERT(域内)策略)。
train_sts_indomain_semantic.py
该脚本首先从头开始训练一个交叉编码器(BERT)模型,用于小的STS基准数据集。
从我们的小训练数据集中重组句子,形成大量句子对。
使用预训练的SBERT模型进行语义搜索采样,限制组合数量。
给定一个句子,检索前k个句子,并使用交叉编码器标记这些句子对(银数据集)。
在金+银STSb数据集上训练一个双编码器(SBERT)模型。(增强SBERT(域内)策略)。
-
该脚本首先从头开始训练一个交叉编码器(BERT)模型,用于STS基准数据集。
使用交叉编码器标记Quora问题对(QQP)训练数据集(假设没有标签)。
在QQP数据集上训练一个双编码器(SBERT)模型。(增强SBERT(域转移)策略)。
引用¶
如果您使用增强SBERT的代码,请随意引用我们的出版物Augmented SBERT: Data Augmentation Method for Improving Bi-Encoders for Pairwise Sentence Scoring Tasks:
@article{thakur-2020-AugSBERT,
title = "Augmented SBERT: Data Augmentation Method for Improving Bi-Encoders for Pairwise Sentence Scoring Tasks",
author = "Thakur, Nandan and Reimers, Nils and Daxenberger, Johannes and Gurevych, Iryna",
journal= "arXiv preprint arXiv:2010.08240",
month = "10",
year = "2020",
url = "https://arxiv.org/abs/2010.08240",
}