多语言模型¶
多语言BERT(mBERT)以及XLM-RoBERTa的问题在于,它们开箱即用的句子表示效果相当糟糕。此外,不同语言之间的向量空间没有对齐,即不同语言中内容相同的句子会被映射到向量空间中的不同位置。
在我的出版物Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation中,我描述了一种简单的方法来将句子嵌入扩展到更多语言。
Chien Vu 也写了一篇关于这项技术的优秀博客文章:A complete guide to transfer learning from English to other Languages using Sentence Embeddings BERT Models
扩展你自己的模型¶
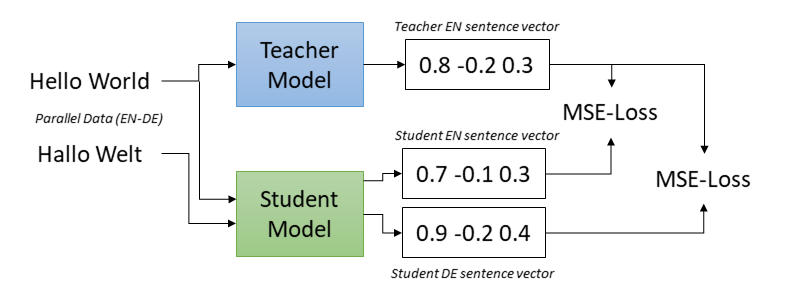
这个想法基于一个固定的(单语言)教师模型,该模型在一个语言(例如英语)中生成具有我们期望特性的句子嵌入。学生模型被期望模仿教师模型,即相同的英语句子应通过教师模型和学生模型映射到相同的向量。此外,为了使学生模型适用于其他语言,我们在平行(翻译)句子上训练学生模型。每个句子的翻译也应映射到与原始句子相同的向量。
在上图中,学生模型应将Hello World和德语翻译Hallo Welt映射到teacher_model('Hello World')的向量。我们通过使用均方误差(MSE)损失训练学生模型来实现这一点。
在我们的实验中,我们使用多语言XLM-RoBERTa模型初始化了学生模型。
训练¶
对于完全自动的代码示例,请参见make_multilingual.py。
此脚本下载平行句子语料库,一个包含演讲记录及其翻译的语料库。然后,它将单语言模型扩展到几种语言(en, de, es, it, fr, ar, tr)。该语料库包含超过100种语言的平行数据,因此,你可以简单地修改脚本并在你喜欢的语言上训练多语言模型。
数据集¶
作为训练数据,我们需要平行句子,即在各种语言中翻译的句子。特别是,我们将使用带有``"english"和"non_english"``列的:class:`~datasets.Dataset`实例。我们在`Parallel Sentences dataset collection <https://huggingface.co/collections/sentence-transformers/parallel-sentences-datasets-6644d644123d31ba5b1c8785>`_中准备了大量此类数据集。
训练脚本将获取"english"列并添加一个包含英语文本嵌入的"label"列。然后,学生模型的"english"和"non_english"将被训练为与这个"label"相似。你可以像这样加载一个训练数据集:
from datasets import load_dataset
train_dataset = load_dataset("sentence-transformers/parallel-sentences-talks", "en-de", split="train")
print(train_dataset[0])
# {"english": "So I think practicality is one case where it's worth teaching people by hand.", "non_english": "Ich denke, dass es sich aus diesem Grund lohnt, den Leuten das Rechnen von Hand beizubringen."}
训练数据来源¶
一个包含大量平行(翻译)数据集的优秀网站是OPUS。在那里,你可以找到超过400种语言的平行数据集。如果你愿意,可以使用这些数据集创建你自己的平行句子数据集。
评估¶
训练可以通过不同的方式进行评估。有关如何使用这些评估方法的示例,请参见make_multilingual.py。
MSE评估¶
你可以测量学生嵌入和教师嵌入之间的均方误差(MSE)。
from datasets import load_dataset
eval_dataset = load_dataset("sentence-transformers/parallel-sentences-talks", "en-fr", split="dev")
dev_mse = MSEEvaluator(
source_sentences=eval_dataset["english"],
target_sentences=eval_dataset["non_english"],
name="en-fr-dev",
teacher_model=teacher_model,
batch_size=32,
)
此评估器为source_sentences计算教师嵌入,例如英语。在训练期间,学生模型用于计算target_sentences的嵌入,例如法语。测量教师和学生嵌入之间的距离。分数越低表示性能越好。
翻译准确性¶
你还可以衡量翻译的准确性。作为输入,此评估器接受一个 source_sentences 列表(例如英语)和一个 target_sentences 列表(例如西班牙语),使得 target_sentences[i] 是 source_sentences[i] 的翻译。
对于每一对句子,我们检查 source_sentences[i] 是否与所有目标句子中的 target_sentences[i] 具有最高相似度。如果是这种情况,我们有一个命中,否则是一个错误。此评估器报告准确率(越高越好)。
from datasets import load_dataset
eval_dataset = load_dataset("sentence-transformers/parallel-sentences-talks", "en-fr", split="dev")
dev_trans_acc = TranslationEvaluator(
source_sentences=eval_dataset["english"],
target_sentences=eval_dataset["non_english"],
name="en-fr-dev",
batch_size=32,
)
多语言语义文本相似性¶
你还可以测量不同语言句子对之间的语义文本相似性(STS):
from datasets import load_dataset
test_dataset = load_dataset("mteb/sts17-crosslingual-sts", "nl-en", split="test")
test_emb_similarity = EmbeddingSimilarityEvaluator(
sentences1=test_dataset["sentence1"],
sentences2=test_dataset["sentence2"],
scores=[score / 5.0 for score in test_dataset["score"]], # 将0-5分转换为0-1分
batch_size=32,
name=f"sts17-nl-en-test",
show_progress_bar=False,
)
其中 sentences1 和 sentences2 是句子列表,score 是一个数值,表示 sentences1[i] 和 sentences2[i] 之间的语义相似性。
可用的预训练模型¶
有关可用模型的列表,请参见 预训练模型。
使用方法¶
你可以按以下方式使用这些模型:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
embeddings = model.encode(["Hello World", "Hallo Welt", "Hola mundo", "Bye, Moon!"])
similarities = model.similarity(embeddings, embeddings)
# tensor([[1.0000, 0.9429, 0.8880, 0.4558],
# [0.9429, 1.0000, 0.9680, 0.5307],
# [0.8880, 0.9680, 1.0000, 0.4933],
# [0.4558, 0.5307, 0.4933, 1.0000]])
性能¶
性能在 语义文本相似性(STS)2017 数据集 上进行了评估。任务是预测两个给定句子之间的语义相似性(0-5 分)。STS2017 有英语、阿拉伯语和西班牙语的单语测试数据,以及英语-阿拉伯语、英语-西班牙语和英语-土耳其语的跨语言测试数据。
我们扩展了 STS2017,并添加了英语-德语、法语-英语、意大利语-英语和荷兰语-英语的跨语言测试数据(STS2017-extended.zip)。性能通过预测相似度分数与黄金分数之间的斯皮尔曼相关系数来衡量。
| 模型 | AR-AR | AR-EN | ES-ES | ES-EN | EN-EN | TR-EN | EN-DE | FR-EN | IT-EN | NL-EN | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| XLM-RoBERTa 均值池化 | 25.7 | 17.4 | 51.8 | 10.9 | 50.7 | 9.2 | 21.3 | 16.6 | 22.9 | 26.0 | 25.2 |
| mBERT 均值池化 | 50.9 | 16.7 | 56.7 | 21.5 | 54.4 | 16.0 | 33.9 | 33.0 | 34.0 | 35.6 | 35.3 |
| LASER | 68.9 | 66.5 | 79.7 | 57.9 | 77.6 | 72.0 | 64.2 | 69.1 | 70.8 | 68.5 | 69.5 |
| 句子变换器模型 | |||||||||||
| distiluse-base-multilingual-cased | 75.9 | 77.6 | 85.3 | 78.7 | 85.4 | 75.5 | 80.3 | 80.2 | 80.5 | 81.7 | 80.6 |
引用¶
如果你使用多语言模型的代码,请随意引用我们的出版物 Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation:
@article{reimers-2020-multilingual-sentence-bert,
title = "利用知识蒸馏将单语言句子嵌入转化为多语言",
author = "Reimers, Nils and Gurevych, Iryna",
journal= "arXiv 预印本 arXiv:2004.09813",
month = "04",
year = "2020",
url = "http://arxiv.org/abs/2004.09813",
}