模型蒸馏¶
本文件夹包含使 SentenceTransformer 模型更快、更便宜、更轻量化的示例。这些轻量化模型在下游任务中达到了原始模型97.5% - 100% 的性能。
知识蒸馏¶
知识蒸馏描述了将知识从教师模型转移到学生模型的过程。它可用于将句子嵌入扩展到新语言(使用知识蒸馏使单语句嵌入多语言化),但传统方法是拥有一个速度慢(但性能良好)的教师模型和一个快速的学生模型。
快速的学生模型模仿教师模型,从而实现高性能。
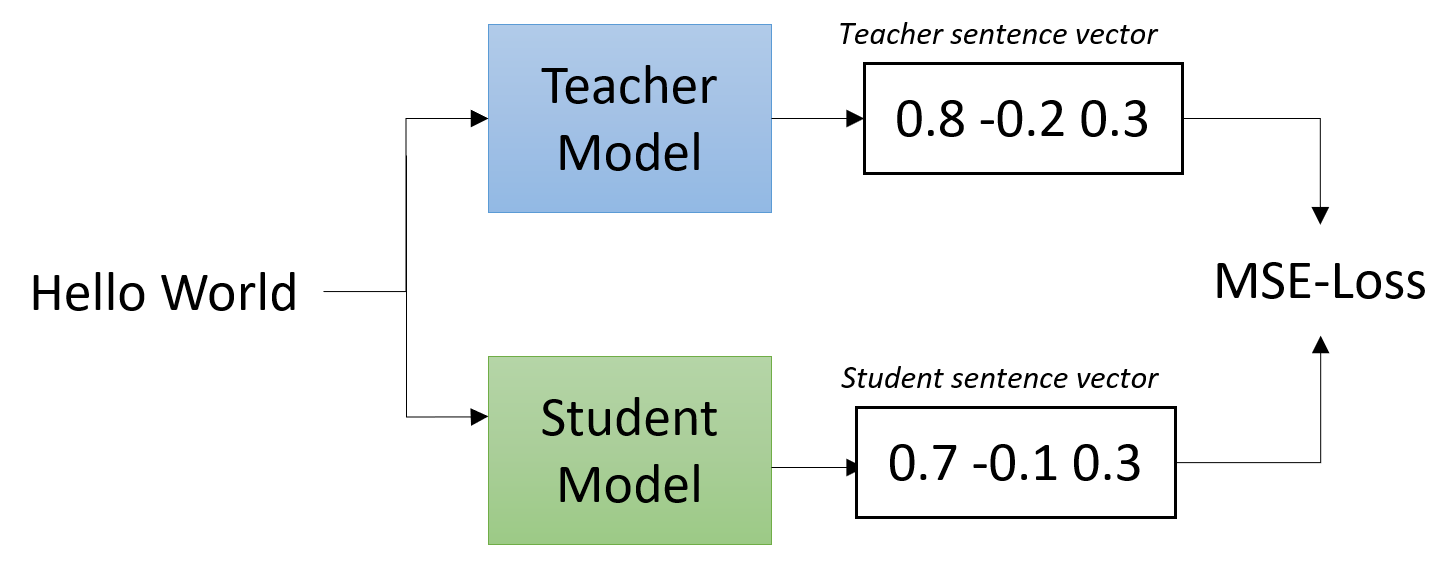
我们实现了两种创建学生模型的选项:
model_distillation.py:使用像 TinyBERT 或 BERT-Small 这样的轻量化transformer模型来模仿更大的教师模型。
model_distillation_layer_reduction.py:我们采用教师模型并只保留某些层,例如,只保留4层。
选项2)通常效果更好,因为我们保留了教师模型的多数权重。在选项1中,我们必须从头开始调整学生模型中的所有权重。
速度-性能权衡¶
较小的模型速度更快,但在下游任务评估中性能略差。为了了解这种权衡,我们展示了一些stsb-roberta-base模型在不同层数下的性能数据:
| 层数 | STSbenchmark 性能 | 性能下降 | V100-GPU 上的速度(句子/秒) |
|---|---|---|---|
| 教师: 12 | 85.44 | - | 2300 |
| 8 | 85.54 | +0.1% | 3200 (~1.4x) |
| 6 | 85.23 | -0.2% | 4000 (~1.7x) |
| 4 | 84.92 | -0.6% | 5300 (~2.3x) |
| 3 | 84.39 | -1.2% | 6500 (~2.8x) |
| 2 | 83.32 | -2.5% | 7700 (~3.3x) |
| 1 | 80.86 | -5.4% | 9200 (~4.0x) |
维度缩减¶
警告
自从撰写本文以来,嵌入量化 已被引入作为缩小嵌入尺寸的首选方法。根据 Thakur et al. 的建议,我们推荐这种方法而非PCA。
默认情况下,预训练模型输出大小为768(基础模型)或1024(大型模型)的嵌入。然而,当存储数百万个嵌入时,这可能需要相当大的内存/存储空间。
dimensionality_reduction.py 包含一个简单的示例,如何通过使用主成分分析(PCA)将嵌入维度减少到任意大小。在该示例中,我们将768维减少到128维,存储需求减少了6倍。性能仅从85.44略微下降到84.96(在STS基准数据集上)。
这种维度缩减技术可以轻松应用于现有模型。我们甚至可以将嵌入大小减少到32,存储需求减少24倍(性能下降到81.82)。
注意:此技术既不会提高模型的运行时,也不会减少运行模型所需的内存。它仅减少存储嵌入所需的空间,例如用于语义搜索。
量化¶
量化模型使用整数而不是浮点值执行部分或全部操作。这使得模型更紧凑,并能在许多硬件平台上使用高性能向量化操作。
对于在CPU上运行的模型,这可以产生40%更小的模型和更快的推理时间:根据CPU的不同,加速在15%到400%之间。目前,PyTorch不支持GPU的模型量化。
有关示例,请参见model_quantization.py
备注
Sentence Transformers 的量化支持仍在改进中。