自然语言推理¶
给定两个句子(前提和假设),自然语言推理(NLI)的任务是判断前提是否蕴含假设,或者它们是否矛盾,或者它们是否是中立的。常用的NLI数据集包括SNLI和MultiNLI。
Conneau et al.表明,NLI数据在训练句子嵌入方法时非常有用。我们在Sentence-BERT论文中也发现了这一点,并且经常使用NLI作为句子嵌入方法的第一步微调。
要在NLI上进行训练,请参阅以下示例文件:
-
这个示例使用了:class:~sentence_transformers.losses.SoftmaxLoss,如在原始的[Sentence Transformers论文](https://arxiv.org/abs/1908.10084)中所述。
-
我们在原始SBERT论文中使用的:class:~sentence_transformers.losses.SoftmaxLoss`并没有产生最佳性能。更好的损失函数是:class:`~sentence_transformers.losses.MultipleNegativesRankingLoss,我们在其中提供成对的或三元组的数据。在这个脚本中,我们提供了一个三元组格式:(锚点,蕴含句子,矛盾句子)。NLI数据提供了这样的三元组。:class:`~sentence_transformers.losses.MultipleNegativesRankingLoss`产生了更高的性能,并且比:class:`~sentence_transformers.losses.SoftmaxLoss`更为直观。我们在`Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation <https://arxiv.org/abs/2004.09813>`_论文中使用了这种损失来训练释义模型。
-
按照`GISTEmbed <https://arxiv.org/abs/2402.16829>`_论文的思路,我们可以使用指导模型修改:class:`~sentence_transformers.losses.MultipleNegativesRankingLoss`中的批次内负样本选择。如果在训练过程中指导模型认为某对样本过于相似,则忽略该对候选负样本。实际上,:class:`~sentence_transformers.losses.GISTEmbedLoss`往往比:class:`~sentence_transformers.losses.MultipleNegativesRankingLoss`产生更强的训练信号,但代价是在指导模型上运行推理时增加了一些训练开销。
数据¶
我们将SNLI和MultiNLI合并为一个数据集,我们称之为AllNLI。这两个数据集包含句子对和三个标签之一:蕴含、中立、矛盾:
| 句子A(前提) | 句子B(假设) | 标签 |
|---|---|---|
| 一场有多名男性参与的足球比赛。 | 一些人在进行体育运动。 | 蕴含 |
| 一个年长和一个年轻的男人在微笑。 | 两个男人在微笑和笑地板上玩耍的猫。 | 中立 |
| 一个人在某个东亚国家检查一个形象的制服。 | 那个人在睡觉。 | 矛盾 |
我们将AllNLI格式化为几个不同的子集,兼容不同的损失函数。例如,请参见AllNLI的三元组子集。
SoftmaxLoss¶
`Conneau et al. <https://arxiv.org/abs/1705.02364>`_描述了如何在`孪生网络 <https://en.wikipedia.org/wiki/Siamese_neural_network>`_之上使用softmax分类器来学习有意义的句子表示。我们可以通过使用:class:`~sentence_transformers.losses.SoftmaxLoss`来实现这一点:
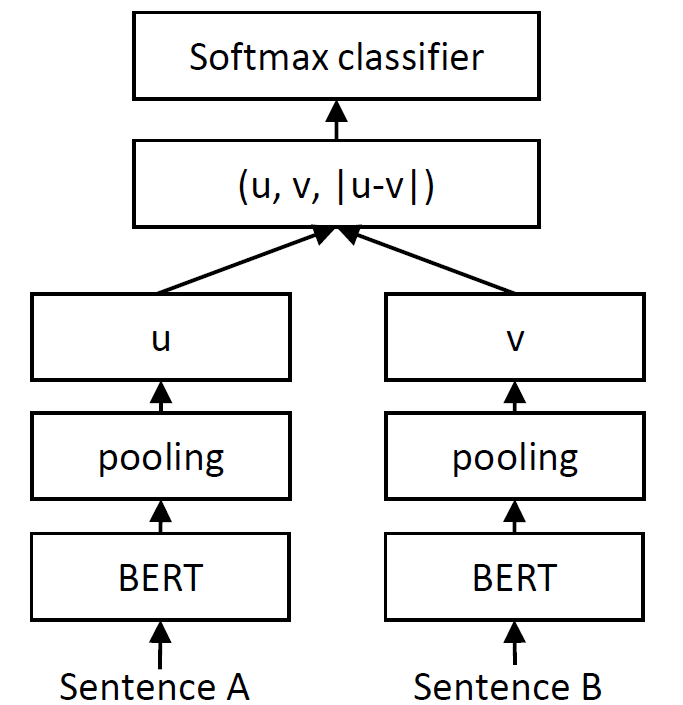
我们通过SentenceTransformer模型传递两个句子,得到句子嵌入u和v。然后我们将u、v和*|u-v|*连接成一个长向量。该向量随后被传递到一个softmax分类器,该分类器预测我们的三个类别(蕴含、中立、矛盾)。
这种设置学习到的句子嵌入可以用于广泛的后续任务。
MultipleNegativesRankingLoss¶
:class:`~sentence_transformers.losses.SoftmaxLoss`与NLI数据一起产生(相对)良好的句子嵌入是相当偶然的。:class:`~sentence_transformers.losses.MultipleNegativesRankingLoss`更为直观,并且产生了显著更好的句子表示。
MultipleNegativesRankingLoss的训练数据由句子对[(a1, b1), ..., (an, bn)]组成,其中我们假设(ai, bi)是相似的句子,而(ai, bj)对于i != j是不相似的句子。该方法最小化(ai, bi)之间的距离,同时最大化所有i != j的(ai, bj)之间的距离。例如,在下图中:
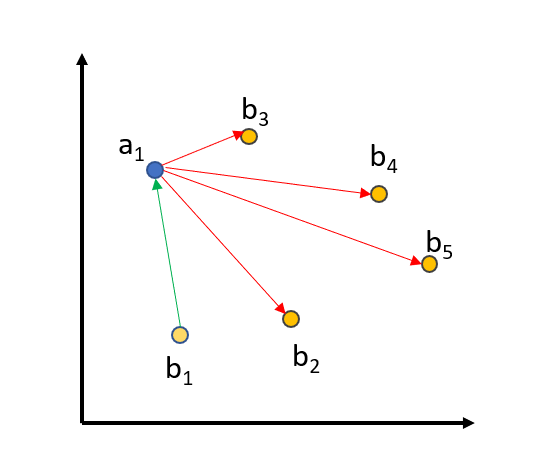
(a1, b1)之间的距离被减小,而(a1, b2...5)之间的距离将被增大。同样的过程也适用于a2, ..., a5。
使用 MultipleNegativesRankingLoss 进行NLI(自然语言推理)相当简单:我们将具有*蕴涵*标签的句子定义为正例对。例如,我们有类似("一场有多名男性参与的足球比赛。", "一些男人正在玩一项运动。")的对子,并希望这些对子在向量空间中接近。AllNLI数据集的配对子集 已经按照这种格式准备好了。
带负样本的MultipleNegativesRankingLoss¶
通过提供三元组而不是对子,我们可以进一步改进MultipleNegativesRankingLoss:[(a1, b1, c1), ..., (an, bn, cn)]。ci样本是所谓的硬负样本:在词汇层面上,它们与ai和bi相似,但在语义层面上,它们意味着不同的事物,不应在向量空间中靠近ai。
对于NLI数据,我们可以使用矛盾标签来创建带有硬负样本的三元组。因此,我们的三元组看起来像这样: ("一场有多名男性参与的足球比赛。", "一些男人正在玩一项运动。", "一群男人正在打棒球。")。我们希望句子*"一场有多名男性参与的足球比赛。"和"一些男人正在玩一项运动。"在向量空间中接近,而"一场有多名男性参与的足球比赛。"和"一群男人正在打棒球。"*之间的距离应该更大。AllNLI数据集的三元组子集已经按照这种格式准备好了。
GISTEmbedLoss¶
MultipleNegativesRankingLoss 可以进一步扩展,通过认识到如`此例所示 <#multiplenegativesrankingloss>`_ 的批次内负样本采样有些缺陷。特别是,我们自动假设对子(a1, b2), ..., (a1, bn)是负样本,但这并不严格必须为真。
为了解决这个问题,GISTEmbedLoss 使用一个句子转换器模型来指导批次内负样本的选择。特别是,如果指导模型认为(a1, bn)的相似性大于(a1, b1),那么(a1, bn)对子被视为假负样本,并在训练过程中被忽略。本质上,这导致了模型训练数据质量的提高。