套娃嵌入¶
密集嵌入模型通常生成固定大小的嵌入,例如768或1024。所有进一步的计算(聚类、分类、语义搜索、检索、重新排序等)都必须在这些完整的嵌入上进行。套娃表示学习重新审视了这一概念,并提出了一种解决方案,用于训练嵌入模型,这些模型的嵌入在截断到更小尺寸后仍然有用。这使得批量处理速度显著加快。
使用案例¶
一个特别有趣的使用案例是将处理过程分为两个步骤:1)使用更小的向量进行预处理,然后2)将剩余的向量作为全尺寸进行处理(也称为“初选和重新排序”)。此外,套娃模型将允许您按所需的存储成本、处理速度和性能来扩展嵌入解决方案。
结果¶
让我们看看与常规嵌入模型相比,套娃嵌入模型可能达到的实际性能。在这个实验中,我训练了两个模型:
tomaarsen/mpnet-base-nli-matryoshka:通过运行matryoshka_nli.py,基于microsoft/mpnet-base进行训练。
tomaarsen/mpnet-base-nli:通过运行matryoshka_nli.py的修改版本进行训练,其中训练损失仅为
MultipleNegativesRankingLoss,而不是在MultipleNegativesRankingLoss之上的MatryoshkaLoss。我也使用microsoft/mpnet-base作为基础模型。
这两个模型都是在AllNLI数据集上训练的,该数据集是SNLI和MultiNLI数据集的组合。我使用多个不同的嵌入维度在STSBenchmark测试集上评估了这些模型。通过运行matryoshka_eval_stsb.py获得的结果如下图所示:
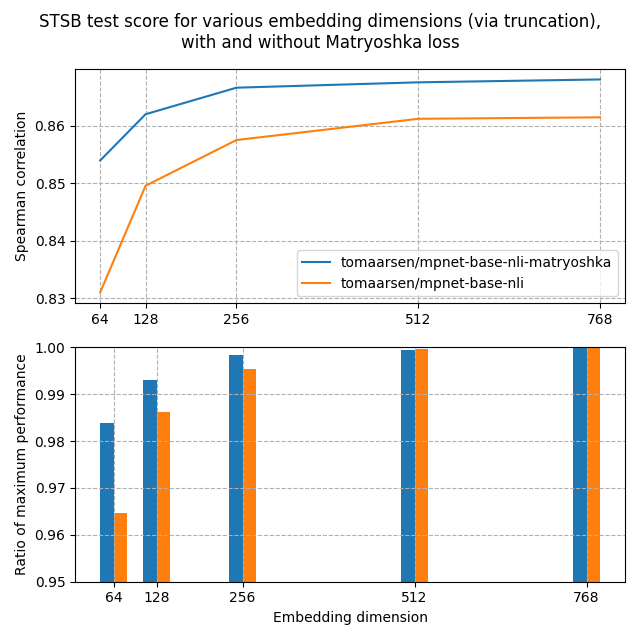
在上图中,你可以看到套娃模型在所有维度上达到了比标准模型更高的斯皮尔曼相似度,表明套娃模型在此任务中更优。
此外,套娃模型的性能下降速度远慢于标准模型。这在第二张图中清晰显示,该图显示了相对于最大性能的嵌入维度性能。即使在嵌入大小的8.3%时,套娃模型仍保留了98.37%的性能,远高于标准模型的96.46%。
这些发现表明,套娃模型截断嵌入可能:1)显著加快下游任务(如检索)的速度;2)显著节省存储空间,且性能影响不明显。
训练¶
使用套娃表示学习(MRL)进行训练相当简单:我们不仅在全尺寸嵌入上应用某种损失函数,还在嵌入的截断部分上应用相同的损失函数。例如,如果一个模型的嵌入维度默认为768,现在可以在768、512、256、128、64和32上进行训练。所有这些损失将加在一起,可选地加上一些权重:
from sentence_transformers import SentenceTransformer
from sentence_transformers.losses import CoSENTLoss, MatryoshkaLoss
model = SentenceTransformer("microsoft/mpnet-base")
base_loss = CoSENTLoss(model=model)
loss = MatryoshkaLoss(model=model, loss=base_loss, matryoshka_dims=[768, 512, 256, 128, 64])
此外,这可以与AdaptiveLayerLoss结合使用,使得生成的模型不仅在输出维度的大小上可以减小,而且在层数上也可以减少,以实现更快的推理。更多信息请参见自适应层以减少模型层数。在Sentence Transformers中,这两种损失的组合称为Matryoshka2dLoss,并提供了一个简写以简化训练。
from sentence_transformers import SentenceTransformer
from sentence_transformers.losses import CoSENTLoss, Matryoshka2dLoss
model = SentenceTransformer("microsoft/mpnet-base")
base_loss = CoSENTLoss(model=model)
loss = Matryoshka2dLoss(model=model, loss=base_loss, matryoshka_dims=[768, 512, 256, 128, 64])
参考:
Matryoshka2dLoss
推理¶
在模型使用Matryoshka损失进行训练后,你可以使用SentenceTransformers.encode对其进行推理。
from sentence_transformers import SentenceTransformer
import torch.nn.functional as F
matryoshka_dim = 64
model = SentenceTransformer(
"nomic-ai/nomic-embed-text-v1.5",
trust_remote_code=True,
truncate_dim=matryoshka_dim,
)
embeddings = model.encode(
[
"search_query: 什么是TSNE?",
"search_document: t-分布随机邻域嵌入(t-SNE)是一种用于通过在二维或三维地图中为每个数据点分配位置来可视化高维数据的统计方法。",
"search_document: 阿梅莉亚·玛丽·埃尔哈特是美国航空先驱和作家。",
]
)
assert embeddings.shape[-1] == matryoshka_dim
similarities = model.similarity(embeddings[0], embeddings[1:])
# => tensor([[0.7839, 0.4933]])
如你所见,尽管应用了非常小的matryoshka维度,搜索查询与正确文档之间的相似度远高于与不相关文档之间的相似度。你可以在本地复制此脚本,修改matryoshka_dim,并观察相似度的差异。
注意: 尽管嵌入更小,但Matryoshka模型的训练和推理并不会更快,不会更节省内存,也不会更小。只有结果嵌入的处理和存储会更快且更便宜。
代码示例¶
以下脚本是实际应用MatryoshkaLoss的示例:
matryoshka_nli.py: 此示例使用MultipleNegativesRankingLoss结合MatryoshkaLoss,使用自然语言推理(NLI)数据训练一个强大的嵌入模型。它是NLI文档的改编。
matryoshka_nli_reduced_dim.py: 此示例使用MultipleNegativesRankingLoss结合MatryoshkaLoss,训练一个最大输出维度为256的强大嵌入模型。它使用自然语言推理(NLI)数据进行训练,是NLI文档的改编。
matryoshka_eval_stsb.py: 此示例在STSBenchmark数据集的测试集上评估使用MatryoshkaLoss训练的嵌入模型matryoshka_nli.py,并将其与非Matryoshka训练的模型进行比较。
matryoshka_sts.py: 此示例使用CoSENTLoss结合MatryoshkaLoss,在STSBenchmark数据集的训练集上训练嵌入模型。它是STS文档的改编。
以下脚本是实际应用Matryoshka2dLoss的示例:
2d_matryoshka_nli.py: 此示例使用
MultipleNegativesRankingLoss结合Matryoshka2dLoss,使用自然语言推理(NLI)数据训练一个强大的嵌入模型。它是NLI文档的改编。2d_matryoshka_sts.py: 此示例使用
CoSENTLoss结合Matryoshka2dLoss,在STSBenchmark数据集的训练集上训练嵌入模型。它是STS文档的改编。