使用嵌入进行分类
有许多方法可以对文本进行分类。本笔记本分享了使用嵌入进行文本分类的示例。对于许多文本分类任务,我们已经看到微调模型比嵌入效果更好。在Fine-tuned_classification.ipynb中可以看到一个分类的微调模型示例。我们还建议拥有比嵌入维度更多的示例,但在这里我们并没有完全实现这一点。
在这个文本分类任务中,我们基于评论文本的嵌入来预测食品评论的评分(1到5分)。我们将数据集分为训练集和测试集,以便在未见数据上实际评估性能。数据集是在Get_embeddings_from_dataset Notebook中创建的。
import pandas as pd
import numpy as np
from ast import literal_eval
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, accuracy_score
datafile_path = "data/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
df["embedding"] = df.embedding.apply(literal_eval).apply(np.array) # 将字符串转换为数组
# 将数据分割为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
list(df.embedding.values), df.Score, test_size=0.2, random_state=42
)
# 训练随机森林分类器
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train)
preds = clf.predict(X_test)
probas = clf.predict_proba(X_test)
report = classification_report(y_test, preds)
print(report)
precision recall f1-score support
1 0.90 0.45 0.60 20
2 1.00 0.38 0.55 8
3 1.00 0.18 0.31 11
4 0.88 0.26 0.40 27
5 0.76 1.00 0.86 134
accuracy 0.78 200
macro avg 0.91 0.45 0.54 200
weighted avg 0.81 0.78 0.73 200
我们可以看到模型已经学会了很好地区分各个类别。5星级评论在整体表现上最好,这并不太令人惊讶,因为它们在数据集中是最常见的。
from utils.embeddings_utils import plot_multiclass_precision_recall
plot_multiclass_precision_recall(probas, y_test, [1, 2, 3, 4, 5], clf)
RandomForestClassifier() - Average precision score over all classes: 0.90
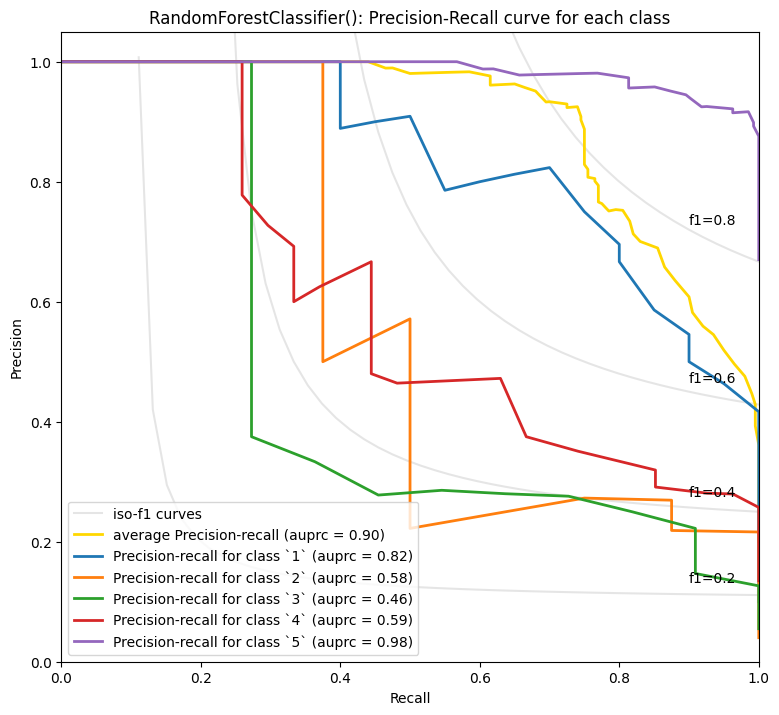
毫不奇怪,5星和1星的评论似乎更容易预测。也许有了更多数据,就能更好地预测2-4星之间的细微差别,但人们如何使用中间评分可能也更主观。