用户和产品嵌入
我们根据训练集计算用户和产品的嵌入,并在未见过的测试集上评估结果。我们将通过绘制用户和产品相似度与评论分数的关系图来评估结果。数据集是在Get_embeddings_from_dataset Notebook中创建的。
1. 计算用户和产品的嵌入向量
我们通过简单地对训练集中关于同一产品或同一用户撰写的所有评论进行平均来计算这些嵌入向量。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from ast import literal_eval
df = pd.read_csv('data/fine_food_reviews_with_embeddings_1k.csv', index_col=0) # 请注意,您需要生成此文件才能运行下面的代码。
df.head(2)
| ProductId | UserId | Score | Summary | Text | combined | n_tokens | embedding | |
|---|---|---|---|---|---|---|---|---|
| 0 | B003XPF9BO | A3R7JR3FMEBXQB | 5 | where does one start...and stop... with a tre... | Wanted to save some to bring to my Chicago fam... | Title: where does one start...and stop... wit... | 52 | [0.03599238395690918, -0.02116263099014759, -0... |
| 297 | B003VXHGPK | A21VWSCGW7UUAR | 4 | Good, but not Wolfgang Puck good | Honestly, I have to admit that I expected a li... | Title: Good, but not Wolfgang Puck good; Conte... | 178 | [-0.07042013108730316, -0.03175969794392586, -... |
df['babbage_similarity'] = df["embedding"].apply(literal_eval).apply(np.array)
X_train, X_test, y_train, y_test = train_test_split(df, df.Score, test_size = 0.2, random_state=42)
user_embeddings = X_train.groupby('UserId').babbage_similarity.apply(np.mean)
prod_embeddings = X_train.groupby('ProductId').babbage_similarity.apply(np.mean)
len(user_embeddings), len(prod_embeddings)
(577, 706)
我们可以看到,大多数用户和产品在这50k个示例中只出现一次。
2. 评估嵌入向量
为了评估推荐结果,我们查看在未见过的测试集中评论��中用户和产品嵌入向量的相似性。我们计算用户和产品嵌入向量之间的余弦距离,这给我们一个介于0和1之间的相似性分数。然后,我们通过计算相似性分数在所有预测分数中的百分位数,将分数归一化为均匀分布在0和1之间。
from utils.embeddings_utils import cosine_similarity
# 在X_test上评估嵌入作为推荐
def evaluate_single_match(row):
user_id = row.UserId
product_id = row.ProductId
try:
user_embedding = user_embeddings[user_id]
product_embedding = prod_embeddings[product_id]
similarity = cosine_similarity(user_embedding, product_embedding)
return similarity
except Exception as e:
return np.nan
X_test['cosine_similarity'] = X_test.apply(evaluate_single_match, axis=1)
X_test['percentile_cosine_similarity'] = X_test.cosine_similarity.rank(pct=True)
2.1 通过评论分数可视化余弦相似度
我们将根据评论分数对余弦相似度分数进行分组,并绘制每个评论分数的余弦相似度分数分布。
import matplotlib.pyplot as plt
import statsmodels.api as sm
correlation = X_test[['percentile_cosine_similarity', 'Score']].corr().values[0,1]
print('Correlation between user & vector similarity percentile metric and review number of stars (score): %.2f%%' % (100*correlation))
# 每个分数的余弦相似度箱线图
X_test.boxplot(column='percentile_cosine_similarity', by='Score')
plt.title('')
plt.show()
plt.close()
Correlation between user & vector similarity percentile metric and review number of stars (score): 29.56%
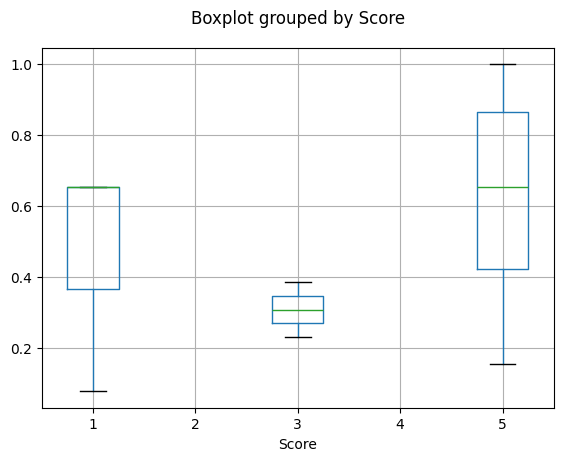
我们可以观察到一个微弱的趋势,显示用户和产品嵌入之间的相似性得分越高,评论得分也越高。因此,用户和产品嵌入可以在用户收到产品之前就微弱地预测评论得分!
由于这个信号的工作方式与更常用的协同过滤不同,它可以作为一个额外特征,稍微提高现有问题的性能。