在ELT工作流中使用GPT-4o作为OCR替代方案的数据提取和转换
许多企业数据是非结构化的,并且以难以使用的格式存储,例如PDF、PPT、PNG,这些格式并不适用于LLMs或数据库。因此,这种类型的数据往往被低估,无法用于分析和产品开发,尽管它非常有价值。从非结构化或非理想格式中提取信息的传统方法是使用OCR,但OCR在处理复杂布局时会遇到困难,并且多语言支持有限。此外,手动对数据应用转换可能会很繁琐且耗时。
GPT-4o的多模态能力使得以新的方式提取和转换数据成为可能,因为GPT-4o能够适应不同类型的文档,并利用推理来解释文档的内容。以下是选择在提取和转换工作流程中使用GPT-4o而不是传统方法的一些原因。
| 提取 | 转换 |
|---|---|
| 可适应性:更好地处理复杂的文档布局,减少错误 | 模式适应性:轻松将数据转换以适应特定的模式,用于数据库摄入 |
| 多语言支持:无缝处理多种语言的文档 | 动态数据映射:适应不同的数据结构和格式,提供灵活的转换规则 |
| 上下文理解:提取有意义的关系和上下文,而不仅仅是文本 | 增强的洞察生成:应用推理来创建更具洞察力的转换,通过衍生指标、元数据和关系丰富数据集 |
| 多模态:处理各种文档元素,包括图像和表格 |
这本食谱分为三个部分: 1. 如何从多语言PDF中提取数据 2. 如何根据数据库加载的模式转换数据 3. 如何将转换后的数据加载到数据库中进行下游分析
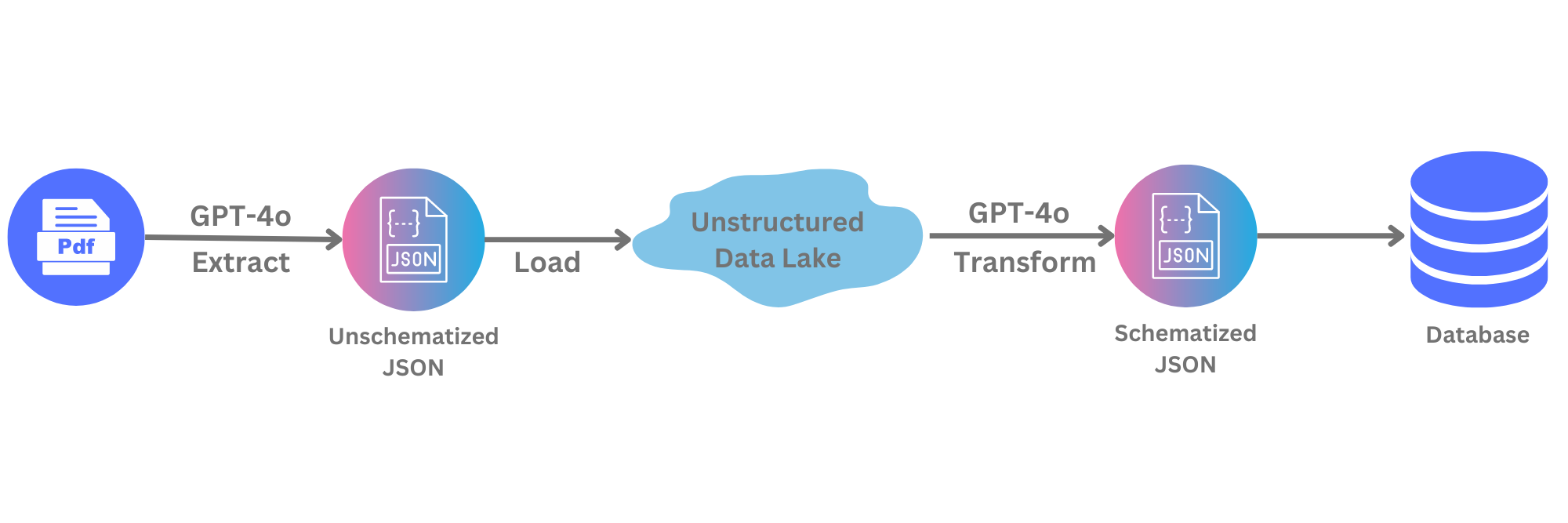
我们将模仿一个简单的ELT工作流程,首先使用GPT-4o从PDF中提取数据到JSON中,将数据存储在类似数据湖的非结构化格式中,然后使用GPT-4o进行转换以适应模式,最后将数据摄入关系型数据库进行查询。值得注意的是,如果您有兴趣降低此工作流程的成本,您可以使用BatchAPI来完成所有这些工作。
我们将使用的数据是来自德国的一组公开可用的2019年酒店发票,可以在Jens Walter的GitHub上找到(感谢Jens!)。尽管酒店发票通常包含类似的信息(预订详情、费用、税收等),但您会注意到这些发票以不同的方式呈现逐项信息,并且是多语言的,包含德语和英语。幸运的是,GPT-4o可以适应各种不同的文档样式,而无需我们指定格式,它可以无缝处理各种语言,甚至在同一文档中也可以。 这是其中一张发票的样子:

第一部分:使用GPT-4o的视觉功能从PDF中提取数据
GPT-4o本身无法处理PDF,因此在提取任何数据之前,我们首先需要将每个页面转换为图像,然后将图像编码为base64。
from openai import OpenAI
import fitz # PyMuPDF
import io
import os
from PIL import Image
import base64
import json
api_key = os.getenv("OPENAI_API_KEY")
client = OpenAI(api_key=api_key)
@staticmethod
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
def pdf_to_base64_images(pdf_path):
#处理多页PDF文件
pdf_document = fitz.open(pdf_path)
base64_images = []
temp_image_paths = []
total_pages = len(pdf_document)
for page_num in range(total_pages):
page = pdf_document.load_page(page_num)
pix = page.get_pixmap()
img = Image.open(io.BytesIO(pix.tobytes()))
temp_image_path = f"temp_page_{page_num}.png"
img.save(temp_image_path, format="PNG")
temp_image_paths.append(temp_image_path)
base64_image = encode_image(temp_image_path)
base64_images.append(base64_image)
for temp_image_path in temp_image_paths:
os.remove(temp_image_path)
return base64_images
我们可以在GPT-4o LLM调用中传递每个base64编码的图像,指定高级别的详细信息,并将JSON作为响应格式。在这一步我们不关心强制执行模式,我们只想提取所有数据而不考虑类型。
def extract_invoice_data(base64_image):
system_prompt = f"""
You are an OCR-like data extraction tool that extracts hotel invoice data from PDFs.
1. Please extract the data in this hotel invoice, grouping data according to theme/sub groups, and then output into JSON.
2. Please keep the keys and values of the JSON in the original language.
3. The type of data you might encounter in the invoice includes but is not limited to: hotel information, guest information, invoice information,
room charges, taxes, and total charges etc.
4. If the page contains no charge data, please output an empty JSON object and don't make up any data.
5. If there are blank data fields in the invoice, please include them as "null" values in the JSON object.
6. If there are tables in the invoice, capture all of the rows and columns in the JSON object.
Even if a column is blank, include it as a key in the JSON object with a null value.
7. If a row is blank denote missing fields with "null" values.
8. Don't interpolate or make up data.
9. Please maintain the table structure of the charges, i.e. capture all of the rows and columns in the JSON object.
"""
response = client.chat.completions.create(
model="gpt-4o",
response_format={ "type": "json_object" },
messages=[
{
"role": "system",
"content": system_prompt
},
{
"role": "user",
"content": [
{"type": "text", "text": "extract the data in this hotel invoice and output into JSON "},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{base64_image}", "detail": "high"}}
]
}
],
temperature=0.0,
)
return response.choices[0].message.content
因为发票数据可能跨越PDF中的多个页面,我们将为发票中的每个页面生成一个JSON对象,然后将它们合并在一起。最终的发票提取结果将是一个单独的JSON文件。
def extract_from_multiple_pages(base64_images, original_filename, output_directory):
entire_invoice = []
for base64_image in base64_images:
invoice_json = extract_invoice_data(base64_image)
invoice_data = json.loads(invoice_json)
entire_invoice.append(invoice_data)
# 确保输出目录存在
os.makedirs(output_directory, exist_ok=True)
# 构建输出文件路径
output_filename = os.path.join(output_directory, original_filename.replace('.pdf', '_extracted.json'))
# 将整个发票列表保存为JSON文件
with open(output_filename, 'w', encoding='utf-8') as f:
json.dump(entire_invoice, f, ensure_ascii=False, indent=4)
return output_filename
def main_extract(read_path, write_path):
for filename in os.listdir(read_path):
file_path = os.path.join(read_path, filename)
if os.path.isfile(file_path):
base64_images = pdf_to_base64_images(file_path)
extract_from_multiple_pages(base64_images, filename, write_path)
read_path= "./data/hotel_invoices/receipts_2019_de_hotel"
write_path= "./data/hotel_invoices/extracted_invoice_json"
main_extract(read_path, write_path)
每个发票的JSON文件的键会根据原始发票包含的数据而有所不同,因此在这一点上,您可以将未经模式化的JSON文件存储在可以处理非结构化数据的数据湖中。不过,为简单起见,我们将把文件存储在一个文件夹中。这是提取的JSON文件之一的样子,您会注意到,即使我们没有指定模式,GPT-4o也能够理解德语并将类似的信息分组在一起。此外,如果发票中有空白字段,GPT-4o会将其转录为”null”。
[
{
"Hotel Information": {
"Name": "Hamburg City (Zentrum)",
"Address": "Willy-Brandt-Straße 21, 20457 Hamburg, Deutschland",
"Phone": "+49 (0) 40 3039 379 0"
},
"Guest Information": {
"Name": "APIMEISTER CONSULTING GmbH",
"Guest": "Herr Jens Walter",
"Address": "Friedrichstr. 123, 10117 Berlin"
},
"Invoice Information": {
"Rechnungsnummer": "GABC19014325",
"Rechnungsdatum": "23.09.19",
"Referenznummer": "GABC015452127",
"Buchungsnummer": "GABR15867",
"Ankunft": "23.09.19",
"Abreise": "27.09.19",
"Nächte": 4,
"Zimmer": 626,
"Kundereferenz": 2
},
"Charges": [
{
"Datum": "23.09.19",
"Uhrzeit": "16:36",
"Beschreibung": "Übernachtung",
"MwSt.%": 7.0,
"Betrag": 77.0,
"Zahlung": null
},
{
"Datum": "24.09.19",
"Uhrzeit": null,
"Beschreibung": "Übernachtung",
"MwSt.%": 7.0,
"Betrag": 135.0,
"Zahlung": null
},
{
"Datum": "25.09.19",
"Uhrzeit": null,
"Beschreibung": "Übernachtung",
"MwSt.%": 7.0,
"Betrag": 82.0,
"Zahlung": null
},
{
"Datum": "26.09.19",
"Uhrzeit": null,
"Beschreibung": "Übernachtung",
"MwSt.%": 7.0,
"Betrag": 217.0,
"Zahlung": null
},
{
"Datum": "24.09.19",
"Uhrzeit": "9:50",
"Beschreibung": "Premier Inn Frühstücksbuffet",
"MwSt.%": 19.0,
"Betrag": 9.9,
"Zahlung": null
},
{
"Datum": "25.09.19",
"Uhrzeit": "9:50",
"Beschreibung": "Premier Inn Frühstücksbuffet",
"MwSt.%": 19.0,
"Betrag": 9.9,
"Zahlung": null
},
{
"Datum": "26.09.19",
"Uhrzeit": "9:50",
"Beschreibung": "Premier Inn Frühstücksbuffet",
"MwSt.%": 19.0,
"Betrag": 9.9,
"Zahlung": null
},
{
"Datum": "27.09.19",
"Uhrzeit": "9:50",
"Beschreibung": "Premier Inn Frühstücksbuffet",
"MwSt.%": 19.0,
"Betrag": 9.9,
"Zahlung": null
}
],
"Payment Information": {
"Zahlung": "550,60",
"Gesamt (Rechnungsbetrag)": "550,60",
"Offener Betrag": "0,00",
"Bezahlart": "Mastercard-Kreditkarte"
},
"Tax Information": {
"MwSt.%": [
{
"Rate": 19.0,
"Netto": 33.28,
"MwSt.": 6.32,
"Brutto": 39.6
},
{
"Rate": 7.0,
"Netto": 477.57,
"MwSt.": 33.43,
"Brutto": 511.0
}
]
}
}
]
第二部分:根据模式转换数据
您已经从PDF中提取了数据,并很可能将非结构化的提取加载到数据湖中作为JSON对象。我们ELT工作流程中的下一步是使用GPT-4o根据我们期望的模式转换提取内容。这将使我们能够将任何生成的表格导入数据库。我们已经决定采用以下模式,该模式广泛涵盖了我们可能在不同发票中看到的大部分信息。此模式将用于将每个原始JSON提取处理为我们期望的模式化JSON,并可以指定特定格式,如”date”: “YYYY-MM-DD”。在这一步,我们还将把数据翻译成英文。
[
{
"hotel_information": {
"name": "string",
"address": {
"street": "string",
"city": "string",
"country": "string",
"postal_code": "string"
},
"contact": {
"phone": "string",
"fax": "string",
"email": "string",
"website": "string"
}
},
"guest_information": {
"company": "string",
"address": "string",
"guest_name": "string"
},
"invoice_information": {
"invoice_number": "string",
"reservation_number": "string",
"date": "YYYY-MM-DD",
"room_number": "string",
"check_in_date": "YYYY-MM-DD",
"check_out_date": "YYYY-MM-DD"
},
"charges": [
{
"date": "YYYY-MM-DD",
"description": "string",
"charge": "number",
"credit": "number"
}
],
"totals_summary": {
"currency": "string",
"total_net": "number",
"total_tax": "number",
"total_gross": "number",
"total_charge": "number",
"total_credit": "number",
"balance_due": "number"
},
"taxes": [
{
"tax_type": "string",
"tax_rate": "string",
"net_amount": "number",
"tax_amount": "number",
"gross_amount": "number"
}
]
}
]
def transform_invoice_data(json_raw, json_schema):
system_prompt = f"""
You are a data transformation tool that takes in JSON data and a reference JSON schema, and outputs JSON data according to the schema.
Not all of the data in the input JSON will fit the schema, so you may need to omit some data or add null values to the output JSON.
Translate all data into English if not already in English.
Ensure values are formatted as specified in the schema (e.g. dates as YYYY-MM-DD).
Here is the schema:
{json_schema}
"""
response = client.chat.completions.create(
model="gpt-4o",
response_format={ "type": "json_object" },
messages=[
{
"role": "system",
"content": system_prompt
},
{
"role": "user",
"content": [
{"type": "text", "text": f"Transform the following raw JSON data according to the provided schema. Ensure all data is in English and formatted as specified by values in the schema. Here is the raw JSON: {json_raw}"}
]
}
],
temperature=0.0,
)
return json.loads(response.choices[0].message.content)
def main_transform(extracted_invoice_json_path, json_schema_path, save_path):
# 加载JSON模式
with open(json_schema_path, 'r', encoding='utf-8') as f:
json_schema = json.load(f)
# 确保保存目录存在
os.makedirs(save_path, exist_ok=True)
# 处理提取的发票目录中的每个JSON文件
for filename in os.listdir(extracted_invoice_json_path):
if filename.endswith(".json"):
file_path = os.path.join(extracted_invoice_json_path, filename)
# 加载提取的JSON
with open(file_path, 'r', encoding='utf-8') as f:
json_raw = json.load(f)
# 转换JSON数据
transformed_json = transform_invoice_data(json_raw, json_schema)
# 将转换后的JSON保存到保存目录
transformed_filename = f"transformed_{filename}"
transformed_file_path = os.path.join(save_path, transformed_filename)
with open(transformed_file_path, 'w', encoding='utf-8') as f:
json.dump(transformed_json, f, ensure_ascii=False, indent=2)
extracted_invoice_json_path = "./data/hotel_invoices/extracted_invoice_json"
json_schema_path = "./data/hotel_invoices/invoice_schema.json"
save_path = "./data/hotel_invoices/transformed_invoice_json"
main_transform(extracted_invoice_json_path, json_schema_path, save_path)
第三部分:将转换后的数据加载到数据库中
现在我们已经将所有数据进行了模式化,我们可以将其分段成表格,以便导入关系型数据库。具体来说,我们将创建四个表格:Hotels(酒店)、Invoices(发票)、Charges(费用)和Taxes(税收)。所有的发票都涉及到一个客人,所以我们不会创建一个客人表。
import os
import json
import sqlite3
def ingest_transformed_jsons(json_folder_path, db_path):
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
# 创建必要的表格
cursor.execute('''
CREATE TABLE IF NOT EXISTS Hotels (
hotel_id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT,
street TEXT,
city TEXT,
country TEXT,
postal_code TEXT,
phone TEXT,
fax TEXT,
email TEXT,
website TEXT
)
''' cursor.execute('''
CREATE TABLE IF NOT EXISTS Invoices (
invoice_id INTEGER PRIMARY KEY AUTOINCREMENT,
hotel_id INTEGER,
invoice_number TEXT,
reservation_number TEXT,
date TEXT,
room_number TEXT,
check_in_date TEXT,
check_out_date TEXT,
currency TEXT,
total_net REAL,
total_tax REAL,
total_gross REAL,
total_charge REAL,
total_credit REAL,
balance_due REAL,
guest_company TEXT,
guest_address TEXT,
guest_name TEXT,
FOREIGN KEY(hotel_id) REFERENCES Hotels(hotel_id)
)
'''
cursor.execute('''
CREATE TABLE IF NOT EXISTS Charges (
charge_id INTEGER PRIMARY KEY AUTOINCREMENT,
invoice_id INTEGER,
date TEXT,
description TEXT,
charge REAL,
credit REAL,
FOREIGN KEY(invoice_id) REFERENCES Invoices(invoice_id)
)
'''
cursor.execute('''
CREATE TABLE IF NOT EXISTS Taxes (
tax_id INTEGER PRIMARY KEY AUTOINCREMENT,
invoice_id INTEGER,
tax_type TEXT,
tax_rate TEXT,
net_amount REAL,
tax_amount REAL,
gross_amount REAL,
FOREIGN KEY(invoice_id) REFERENCES Invoices(invoice_id)
)
''')
# 遍历指定文件夹中的所有 JSON 文件
for filename in os.listdir(json_folder_path):
if filename.endswith(".json"):
file_path = os.path.join(json_folder_path, filename)
# 加载JSON数据
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
# 插入酒店信息
cursor.execute('''
INSERT INTO Hotels (name, street, city, country, postal_code, phone, fax, email, website)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (
data["hotel_information"]["name"],
data["hotel_information"]["address"]["street"],
data["hotel_information"]["address"]["city"],
data["hotel_information"]["address"]["country"],
data["hotel_information"]["address"]["postal_code"],
data["hotel_information"]["contact"]["phone"],
data["hotel_information"]["contact"]["fax"],
data["hotel_information"]["contact"]["email"],
data["hotel_information"]["contact"]["website"]
))
hotel_id = cursor.lastrowid
# 插入发票信息
cursor.execute('''
INSERT INTO Invoices (hotel_id, invoice_number, reservation_number, date, room_number, check_in_date, check_out_date, currency, total_net, total_tax, total_gross, total_charge, total_credit, balance_due, guest_company, guest_address, guest_name)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (
hotel_id,
data["invoice_information"]["invoice_number"],
data["invoice_information"]["reservation_number"],
data["invoice_information"]["date"],
data["invoice_information"]["room_number"],
data["invoice_information"]["check_in_date"],
data["invoice_information"]["check_out_date"],
data["totals_summary"]["currency"],
data["totals_summary"]["total_net"],
data["totals_summary"]["total_tax"],
data["totals_summary"]["total_gross"],
data["totals_summary"]["total_charge"],
data["totals_summary"]["total_credit"],
data["totals_summary"]["balance_due"],
data["guest_information"]["company"],
data["guest_information"]["address"],
data["guest_information"]["guest_name"]
))
invoice_id = cursor.lastrowid
# 插入费用
for charge in data["charges"]:
cursor.execute('''
INSERT INTO Charges (invoice_id, date, description, charge, credit)
VALUES (?, ?, ?, ?, ?)
''', (
invoice_id,
charge["date"],
charge["description"],
charge["charge"],
charge["credit"]
))
# 插入税项
for tax in data["taxes"]:
cursor.execute('''
INSERT INTO Taxes (invoice_id, tax_type, tax_rate, net_amount, tax_amount, gross_amount)
VALUES (?, ?, ?, ?, ?, ?)
''', (
invoice_id,
tax["tax_type"],
tax["tax_rate"],
tax["net_amount"],
tax["tax_amount"],
tax["gross_amount"]
))
conn.commit()
conn.close()
现在让我们通过运行一个示例SQL查询来检查我们是否正确地摄取了数据,以确定最昂贵的酒店住宿和酒店的名称!
您甚至可以在这一步自动化生成SQL查询,方法是使用函数调用,请查看我们的函数调用模型生成参数的示例来学习如何做到这一点。
def execute_query(db_path, query, params=()):
"""
Execute a SQL query and return the results.
Parameters:
db_path (str): Path to the SQLite database file.
query (str): SQL query to be executed.
params (tuple): Parameters to be passed to the query (default is an empty tuple).
Returns:
list: List of rows returned by the query.
"""
try:
# 连接到SQLite数据库
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
# 执行带有参数的查询
cursor.execute(query, params)
results = cursor.fetchall()
# Commit if it's an INSERT/UPDATE/DELETE query
if query.strip().upper().startswith(('INSERT', 'UPDATE', 'DELETE')):
conn.commit()
return results
except sqlite3.Error as e:
print(f"An error occurred: {e}")
return []
finally:
# Close the connection
if conn:
conn.close()
# Example usage
transformed_invoices_path = "./data/hotel_invoices/transformed_invoice_json"
db_path = "./data/hotel_invoices/hotel_DB.db"
ingest_transformed_jsons(transformed_invoices_path, db_path)
query = '''
SELECT
h.name AS hotel_name,
i.total_gross AS max_spent
FROM
Invoices i
JOIN
Hotels h ON i.hotel_id = h.hotel_id
ORDER BY
i.total_gross DESC
LIMIT 1;
'''
results = execute_query(db_path, query)
for row in results:
print(row)
('Citadines Michel Hamburg', 903.63)
在本手册中,我们向您展示了如何使用GPT-4o来提取和转换那些原本无法用于数据分析的数据。如果您不需要这些工作流实时进行,您可以利用OpenAI的BatchAPI以更低的成本异步运行作业!