表格数据下载和预处理 - Jupyter Notebook
download_and_preprocessing.ipynb 示例展示了ClearML将预处理后的表格数据存储为工件,并在ClearML Web UI中明确报告表格数据。当脚本运行时,它会在Table Example项目中创建一个名为tabular preprocessing的实验。
此表格数据是为另一个脚本准备的,train_tabular_predictor.ipynb,该脚本使用它来训练网络。
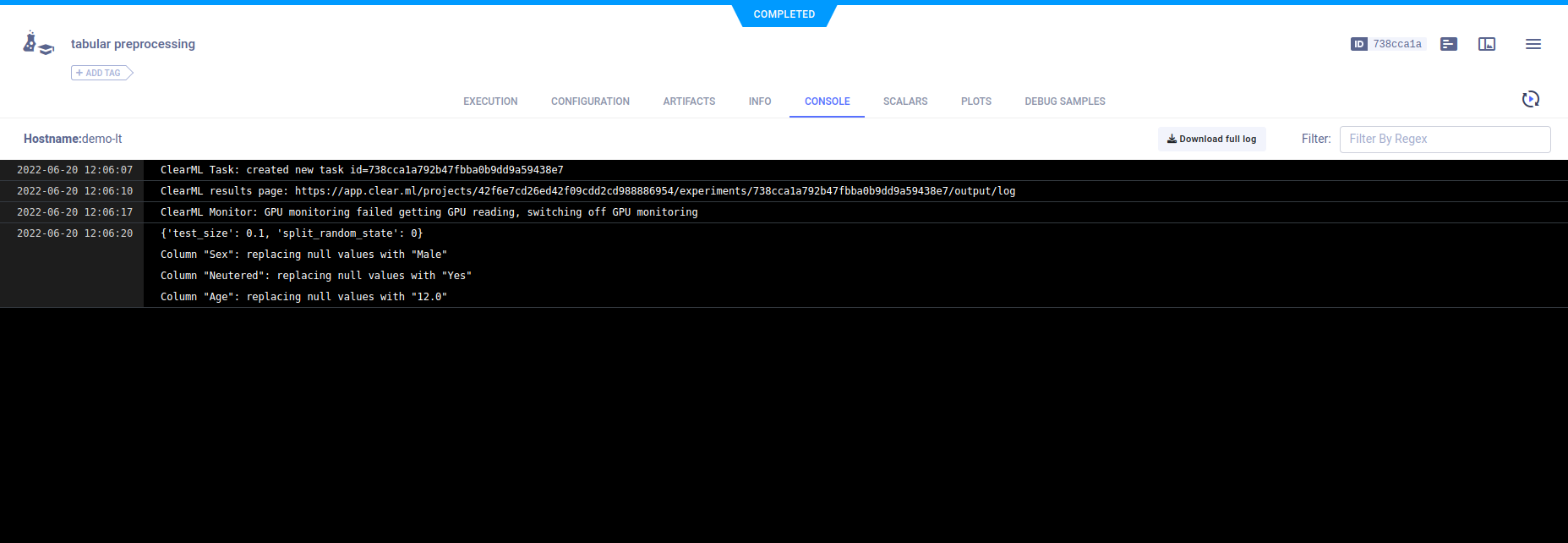
工件
示例代码使用Pandas DataFrames对下载的数据进行预处理,并将其存储为三个工件:
每列的分类- 数据每列的唯一值数量。Outcome dictionary- 用于训练的标签枚举。Processed data- 一个包含训练和验证数据路径的字典。
每个工件都是通过调用Task.upload_artifact()上传的。
工件会出现在ARTIFACTS标签中。
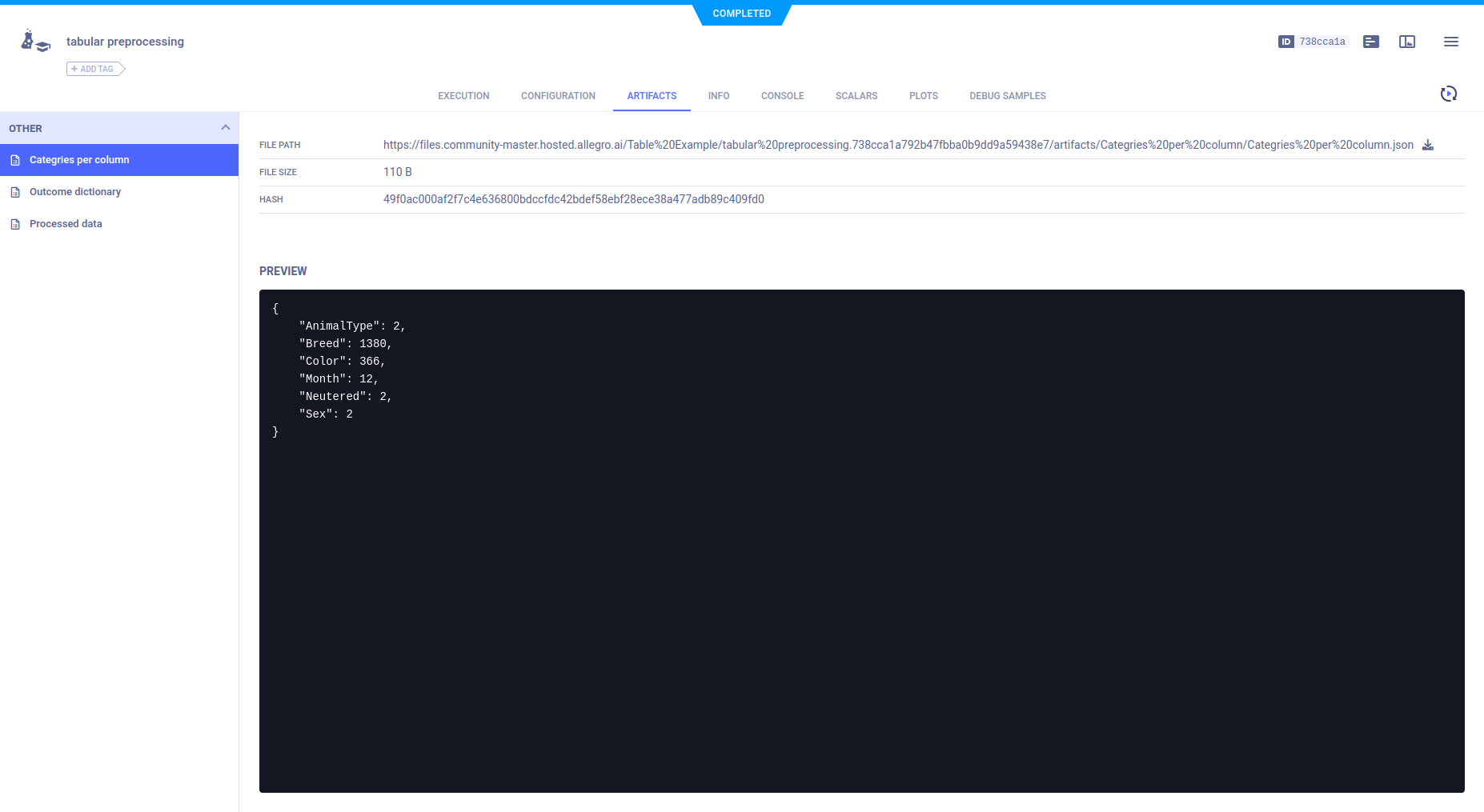
图表(表格)
示例代码通过调用Logger.report_table()显式报告Pandas DataFrames中的数据。
例如,原始数据被读入一个名为 train_set 的 Pandas DataFrame,并报告了 DataFrame 的 head。
train_set = pd.read_csv(Path(path_to_ShelterAnimal) / 'train.csv')
Logger.current_logger().report_table(
title='ClearMLet - raw', series='pandas DataFrame', iteration=0, table_plot=train_set.head()
)
表格出现在PLOTS中。
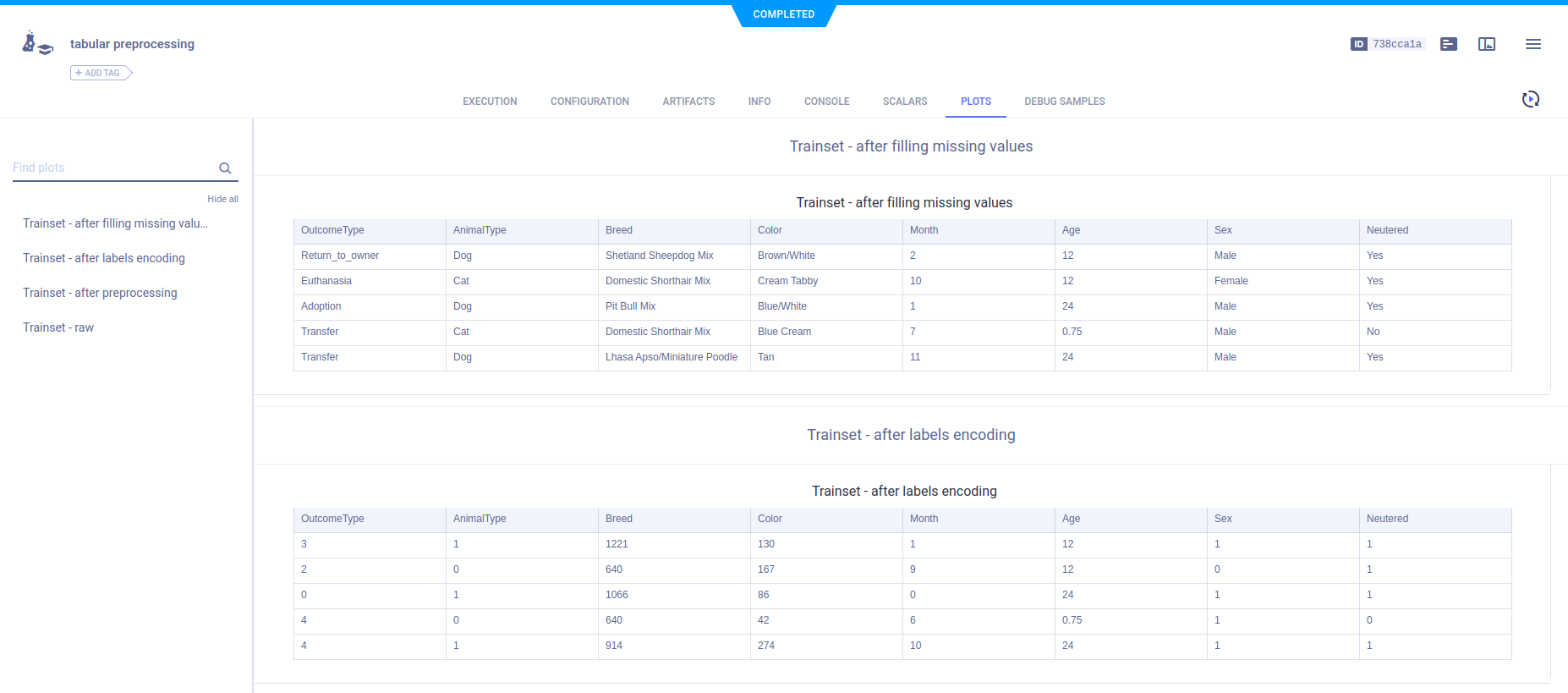
超参数
通过使用Task.connect()将参数字典连接到任务来记录它。
logger = task.get_logger()
configuration_dict = {'test_size': 0.1, 'split_random_state': 0}
configuration_dict = task.connect(configuration_dict)
参数字典出现在常规子部分中。
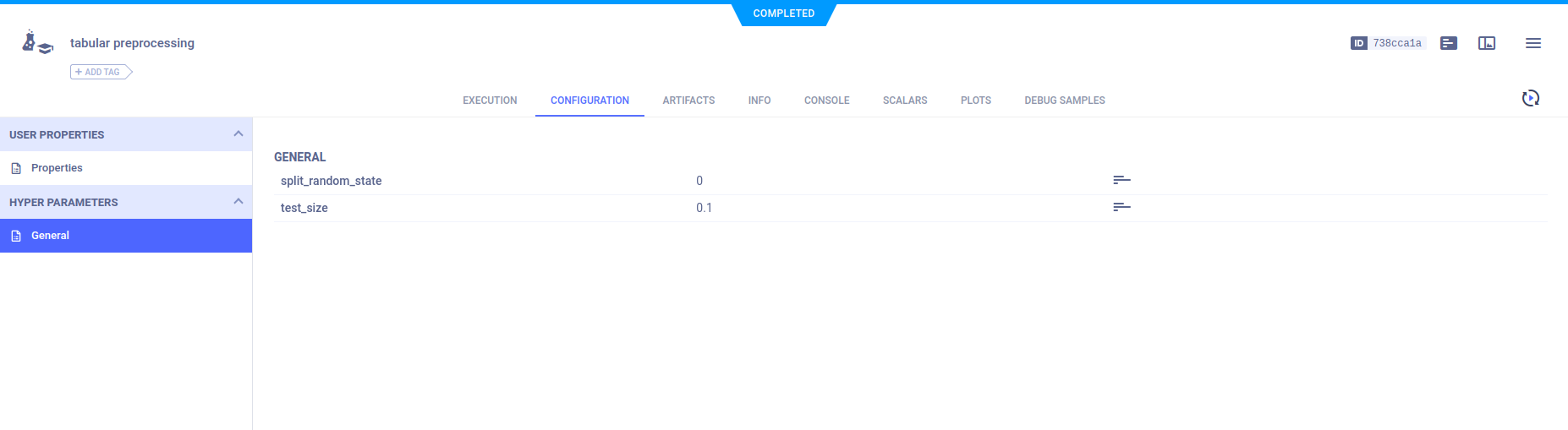
控制台
输出到控制台的内容显示在CONSOLE中。