具有并发步骤的表格数据管道 - Jupyter Notebook
此示例演示了一个ML管道,它在两个并发步骤中预处理数据,训练两个网络,其中每个网络的训练取决于其自己的预处理数据的完成,并选择最佳模型。它是使用PipelineController类实现的。
管道使用了四个任务(每个任务都是使用不同的笔记本创建的):
- 管道控制器任务 (tabular_ml_pipeline.ipynb)
- 数据预处理任务 (preprocessing_and_encoding.ipynb)
- 一个训练任务 (train_tabular_predictor.ipynb)
- 更好的模型比较任务 (pick_best_model.ipynb)
PipelineController 类包含创建管道控制器的功能,向管道添加步骤,将数据从一个步骤传递到另一个步骤,控制步骤的依赖关系,只有在其他步骤完成后才开始,运行管道,等待其完成,并在之后进行清理。
在这个管道示例中,数据预处理任务和训练任务各自被添加到管道中两次(每个任务在两个步骤中)。当管道运行时,数据预处理任务和训练任务会被克隆两次,新克隆的任务会执行。它们被克隆的原始任务,称为基础任务,不会执行。管道控制器通过覆盖参数将不同的数据传递给每个克隆的任务。这样,同一个任务可以在管道中运行多次,但使用不同的数据。
数据下载任务不是流水线中的一个步骤,请参见download_and_split。
管道控制器和步骤
在这个例子中,创建了一个管道控制器对象。
pipe = PipelineController(
project="Tabular Example",
name="tabular training pipeline",
add_pipeline_tags=True,
version="0.1"
)
预处理步骤
向管道中添加了两个预处理节点。这些步骤将同时运行。
pipe.add_step(
name='preprocessing_1',
base_task_project='Tabular Example',
base_task_name='tabular preprocessing',
parameter_override={
'General/data_task_id': TABULAR_DATASET_ID,
'General/fill_categorical_NA': 'True',
'General/fill_numerical_NA': 'True'
}
)
pipe.add_step(
name='preprocessing_2',
base_task_project='Tabular Example',
base_task_name='tabular preprocessing',
parameter_override={
'General/data_task_id': TABULAR_DATASET_ID,
'General/fill_categorical_NA': 'False',
'General/fill_numerical_NA': 'True'
}
)
预处理数据任务根据名为fill_categorical_NA和fill_numerical_NA的参数值填充NaN数据。它将连接一个参数字典到任务,该字典包含具有相同名称的键。当管道执行基础任务的克隆任务时,管道将覆盖这些键的值。通过这种方式,在管道中创建了两组数据。
在预处理数据任务中,data_task_id、fill_categorical_NA和fill_numerical_NA中的参数值被覆盖。
configuration_dict = {
'data_task_id': TABULAR_DATASET_ID,
'fill_categorical_NA': True,
'fill_numerical_NA': True
}
configuration_dict = task.connect(configuration_dict) # enabling configuration override by clearml
ClearML 跟踪并报告每个预处理任务的实例。
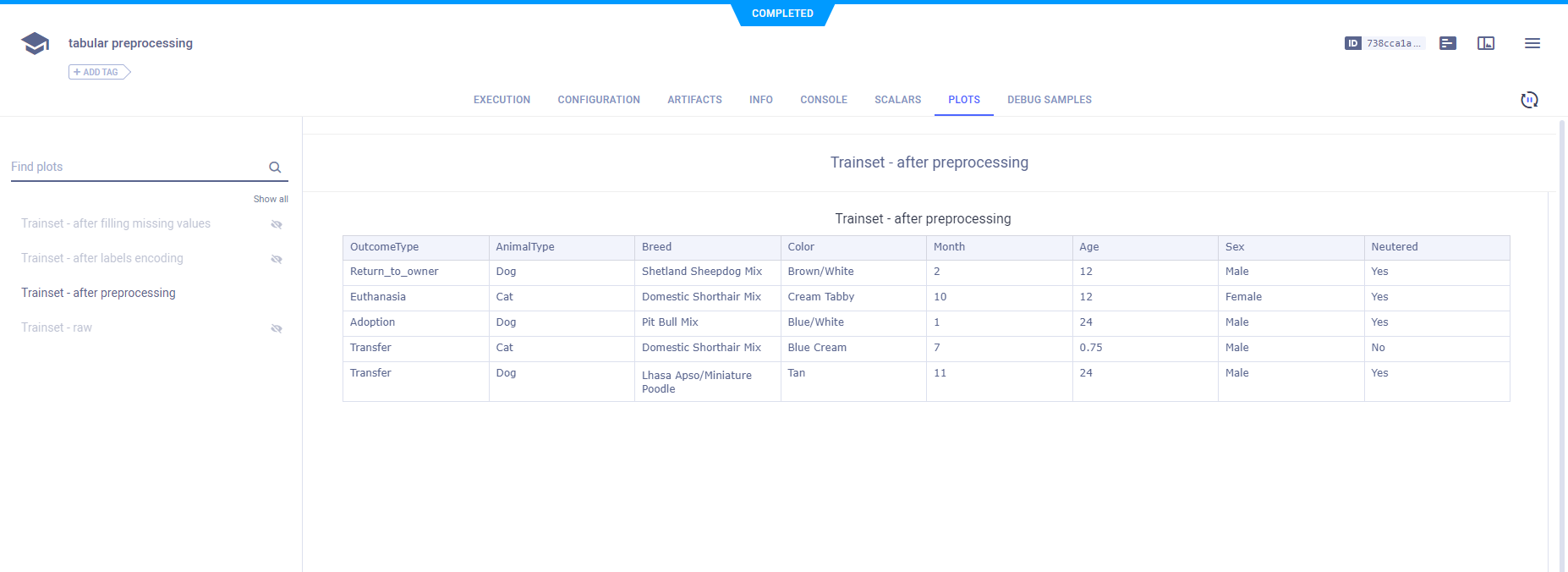
原始数据在PLOTS中以表格形式显示。
这些图像来自两个预处理任务之一。
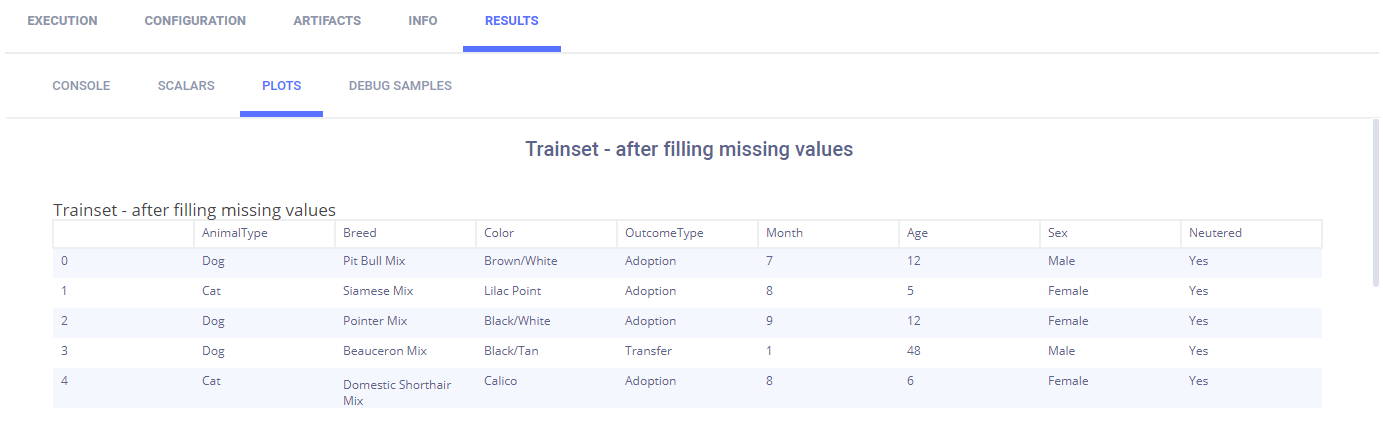
填充NA值后的数据也被报告。
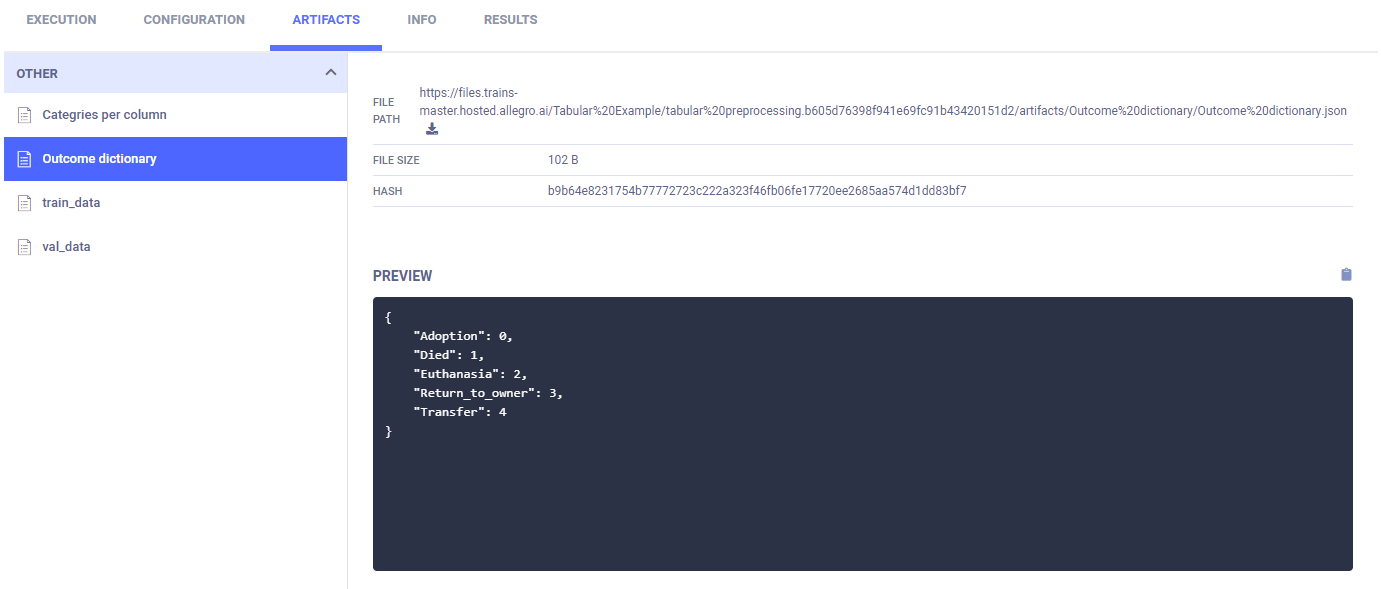
在创建结果字典(标签枚举)后,它会出现在ARTIFACTS > OTHER > Outcome Dictionary中。
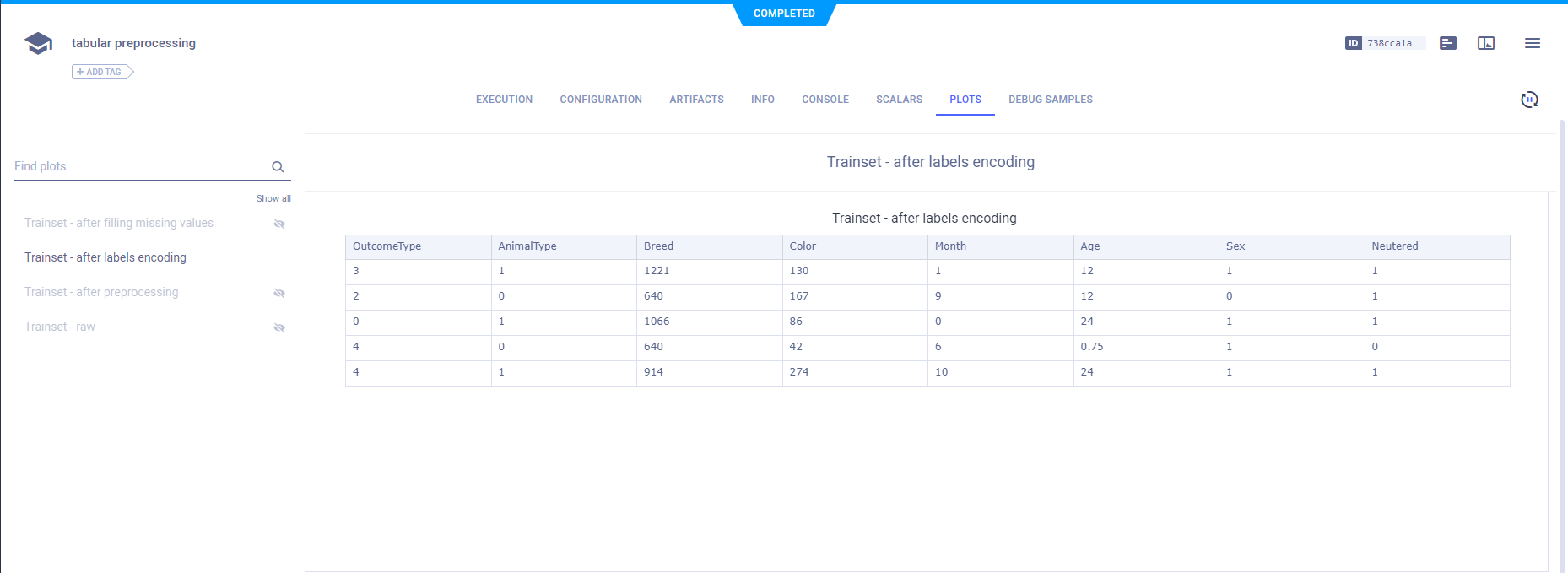
训练和验证数据使用编码进行标记,并以表格形式报告。
列类别被创建并上传为工件,这些工件出现在ARTIFACTS > OTHER > Outcome Dictionary中。
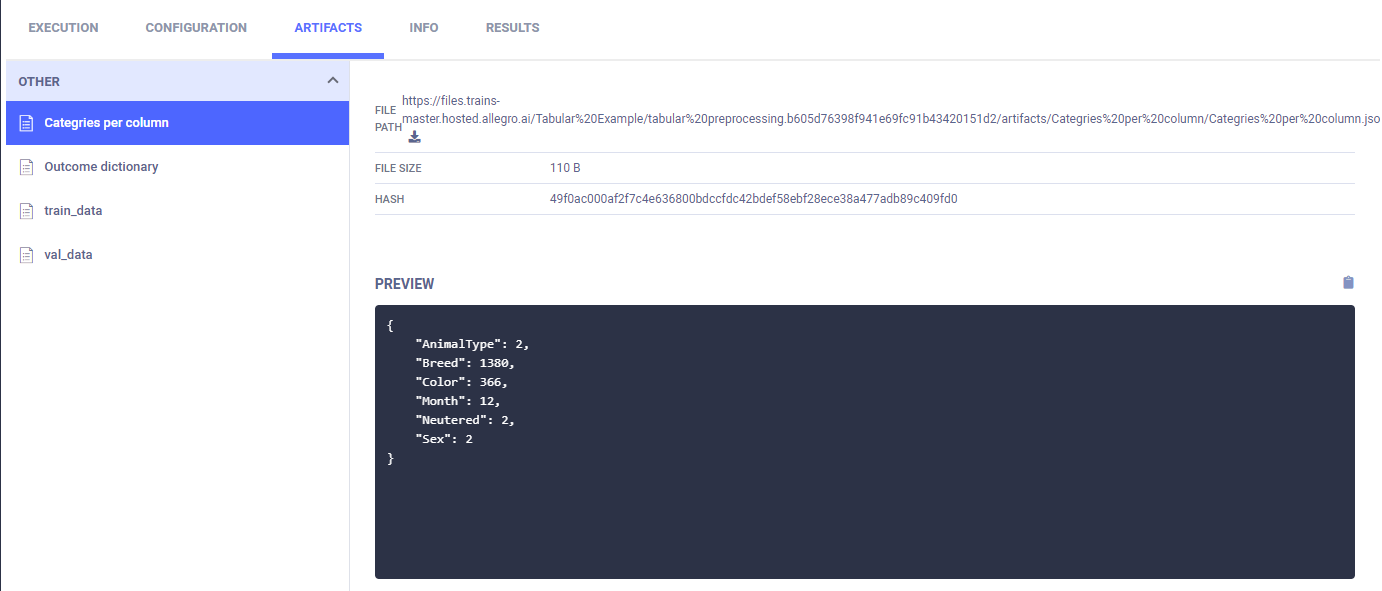
最后,训练数据和验证数据被存储为工件。
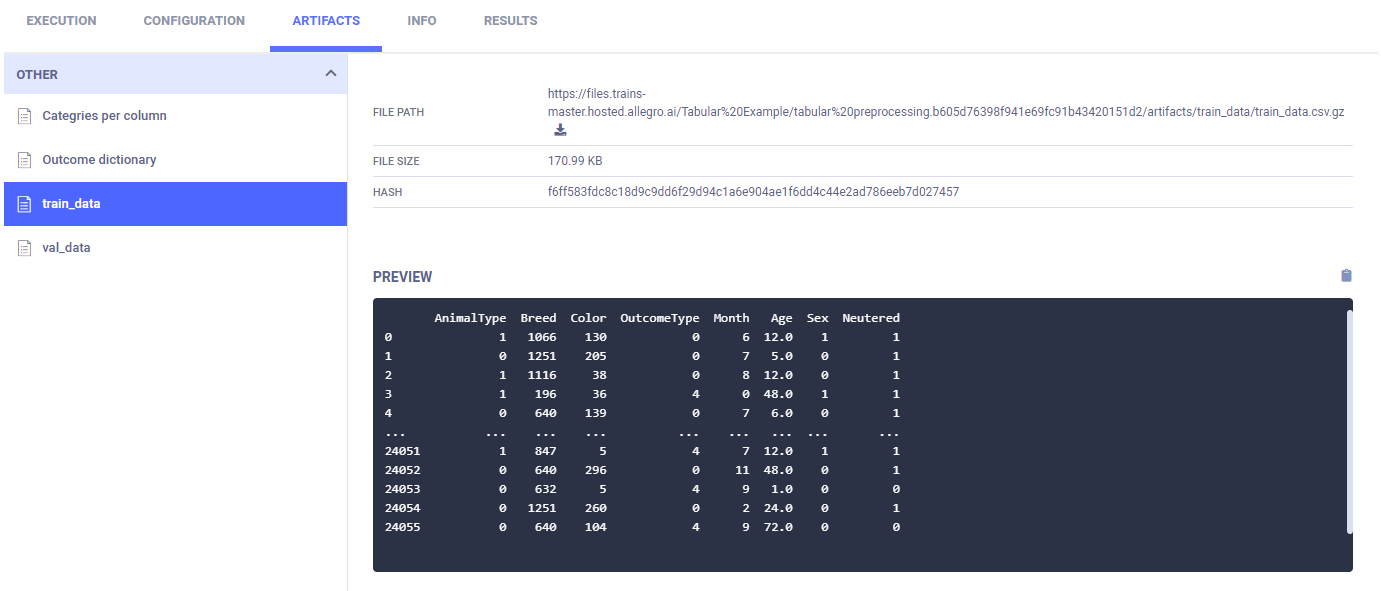
训练步骤
每个训练节点依赖于一个预处理节点的完成。参数parents是一个步骤名称列表,指示在新步骤开始之前必须完成的所有步骤。在这种情况下,preprocessing_1必须在train_1开始之前完成,preprocessing_2必须在train_2开始之前完成。
一个任务的ID,其工件包含一组用于训练的预处理数据,将使用data_task_id键进行覆盖。其值的形式为${。在这种情况下,${preprocessing_1.id}是预处理节点任务之一的ID。通过这种方式,每个训练任务消耗其自己的数据集。
pipe.add_step(
name='train_1',
parents=['preprocessing_1'],
base_task_project='Tabular Example',
base_task_name='tabular prediction',
parameter_override={
'General/data_task_id': '${preprocessing_1.id}'
}
)
pipe.add_step(
name='train_2',
parents=['preprocessing_2'],
base_task_project='Tabular Example',
base_task_name='tabular prediction',
parameter_override={
'General/data_task_id': '${preprocessing_2.id}'
}
)
在训练任务中,data_task_id参数值被覆盖。这使得管道控制器能够将不同的任务ID传递给每个训练实例,其中每个任务都有一个包含不同数据的工件。
configuration_dict = {
'data_task_id': TABULAR_DATASET_ID,
'number_of_epochs': 15, 'batch_size': 100, 'dropout': 0.3, 'base_lr': 0.1
}
configuration_dict = task.connect(configuration_dict) # enabling configuration override by clearml
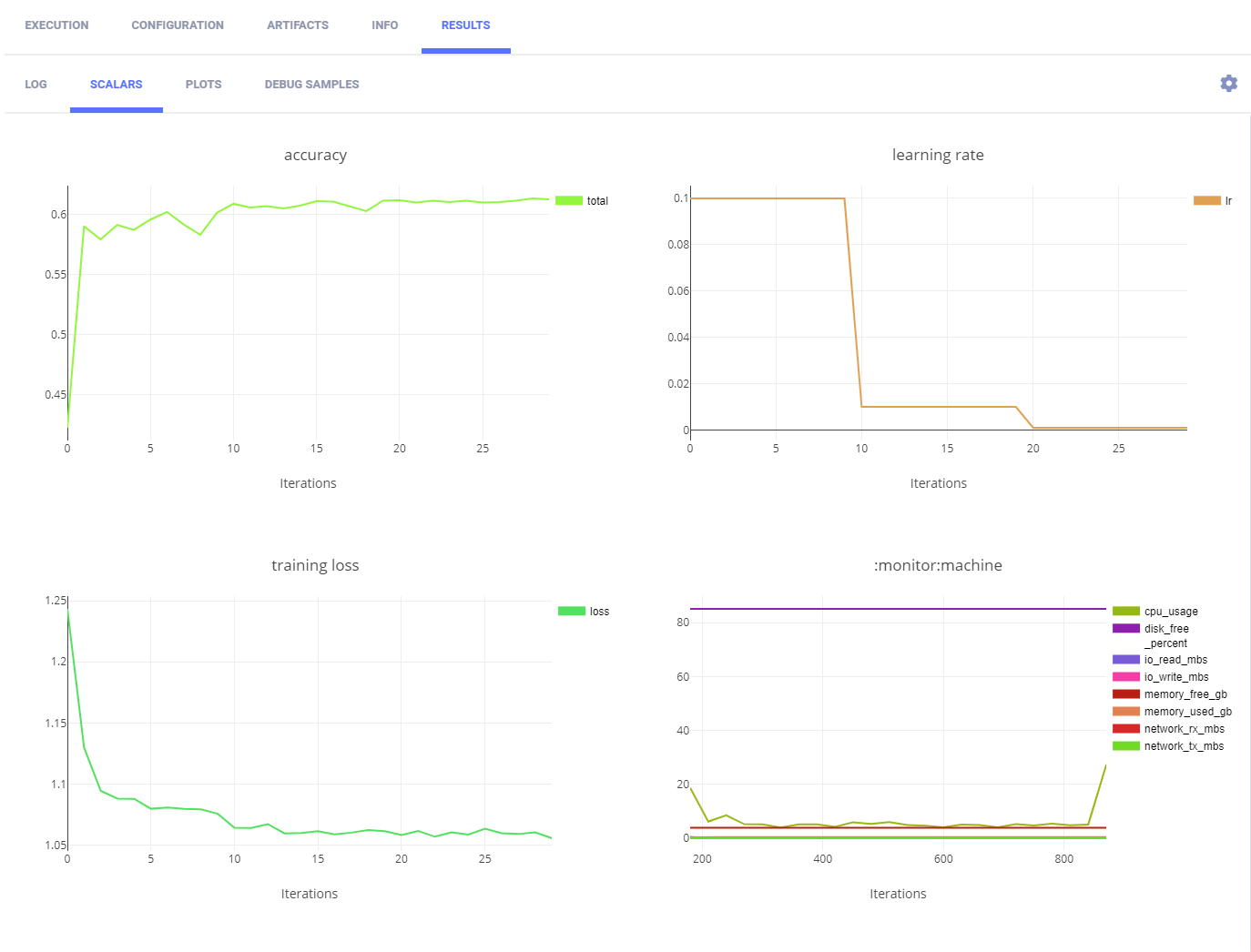
ClearML 跟踪并报告每个新克隆并执行的训练任务的训练步骤。
ClearML 自动记录训练损失和学习情况。它们出现在 SCALARS 中。
以下图片展示了两个训练任务中的一个。
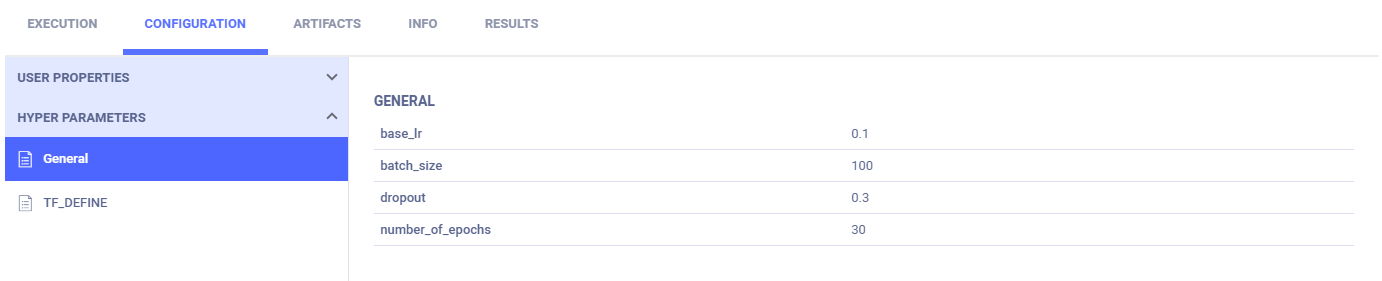
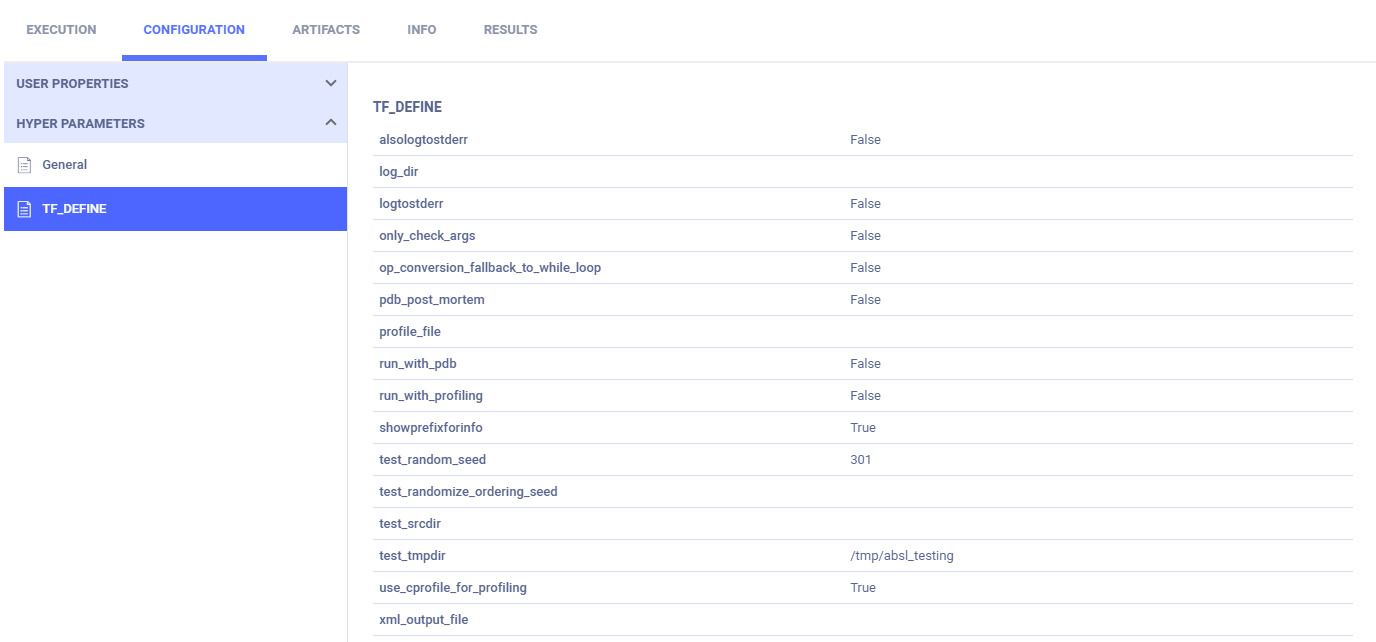
参数字典出现在常规子部分中。
TensorFlow 定义出现在 TF_DEFINE 小节中。
最佳模型步骤
最佳模型步骤取决于训练节点的完成情况,并需要两个训练节点的任务ID来进行覆盖。
pipe.add_step(
name='pick_best',
parents=['train_1', 'train_2'],
base_task_project='Tabular Example',
base_task_name='pick best model',
parameter_override={
'General/train_tasks_ids': '[${train_1.id}, ${train_2.id}]'
}
)
来自名为 train_1 和 train_2 的步骤的训练任务的ID被传递给最佳模型任务。它们的形式为 ${。
在最佳模型任务中,train_tasks_ids 参数被两个训练任务的ID覆盖。
configuration_dict = {
'train_tasks_ids':
['c9bff3d15309487a9e5aaa00358ff091', 'c9bff3d15309487a9e5aaa00358ff091']
}
configuration_dict = task.connect(configuration_dict) # enabling configuration override by clearml
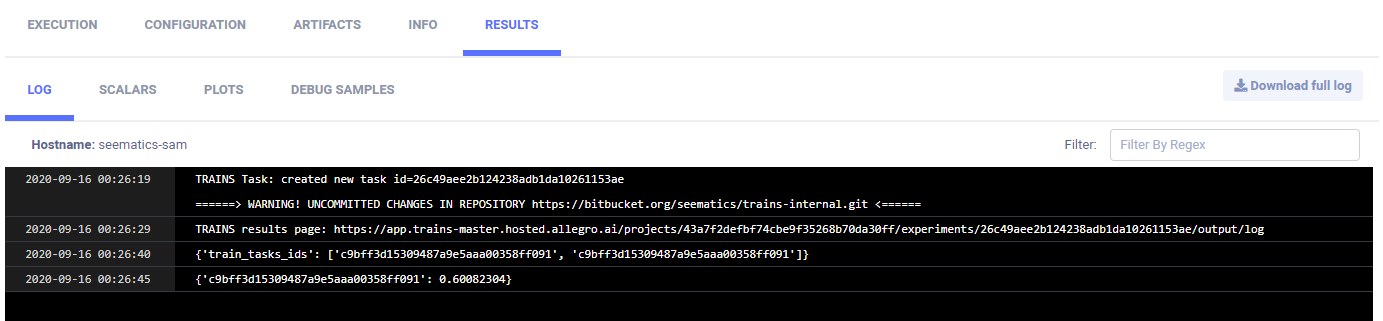
日志显示CONSOLE中最佳模型的任务ID和准确率。
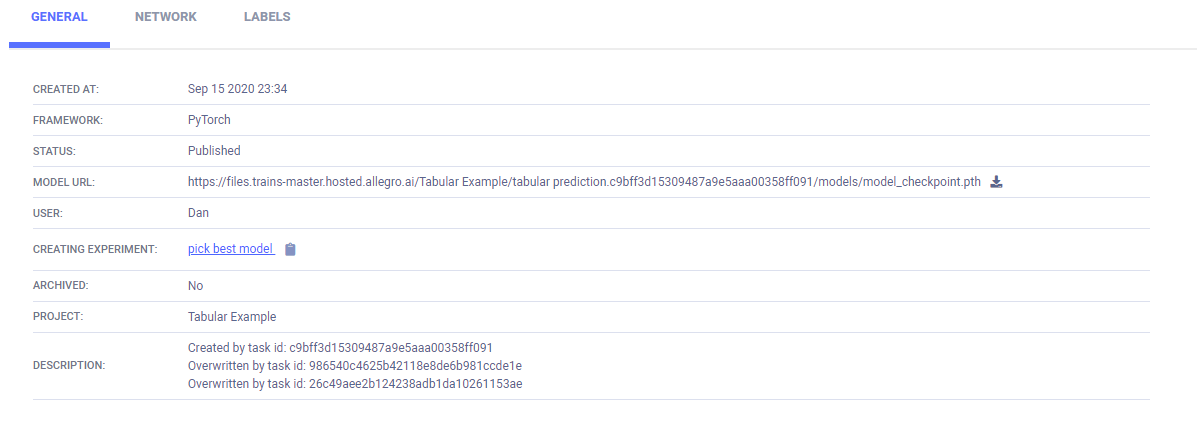
模型详细信息的链接位于ARTIFACTS > Output Model。

模型详细信息显示在MODELS表> >GENERAL中。
管道启动、等待和清理
一旦所有步骤都添加到管道中,启动它。等待它完成。最后,清理管道进程。
# Starting the pipeline (in the background)
pipe.start()
# Wait until pipeline terminates
pipe.wait()
# cleanup everything
pipe.stop()
ClearML 在 图表 中报告了其步骤的管道。
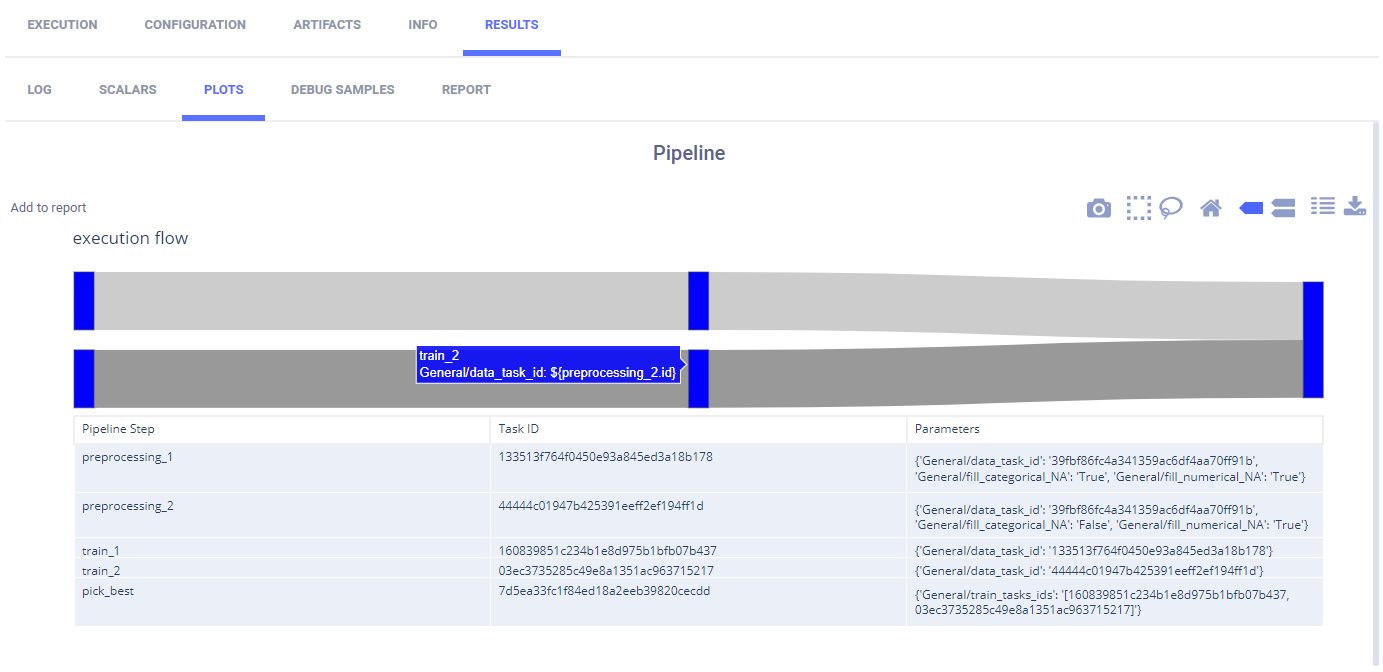
通过悬停在节点之间的步骤或路径上,您可以查看有关它的信息。
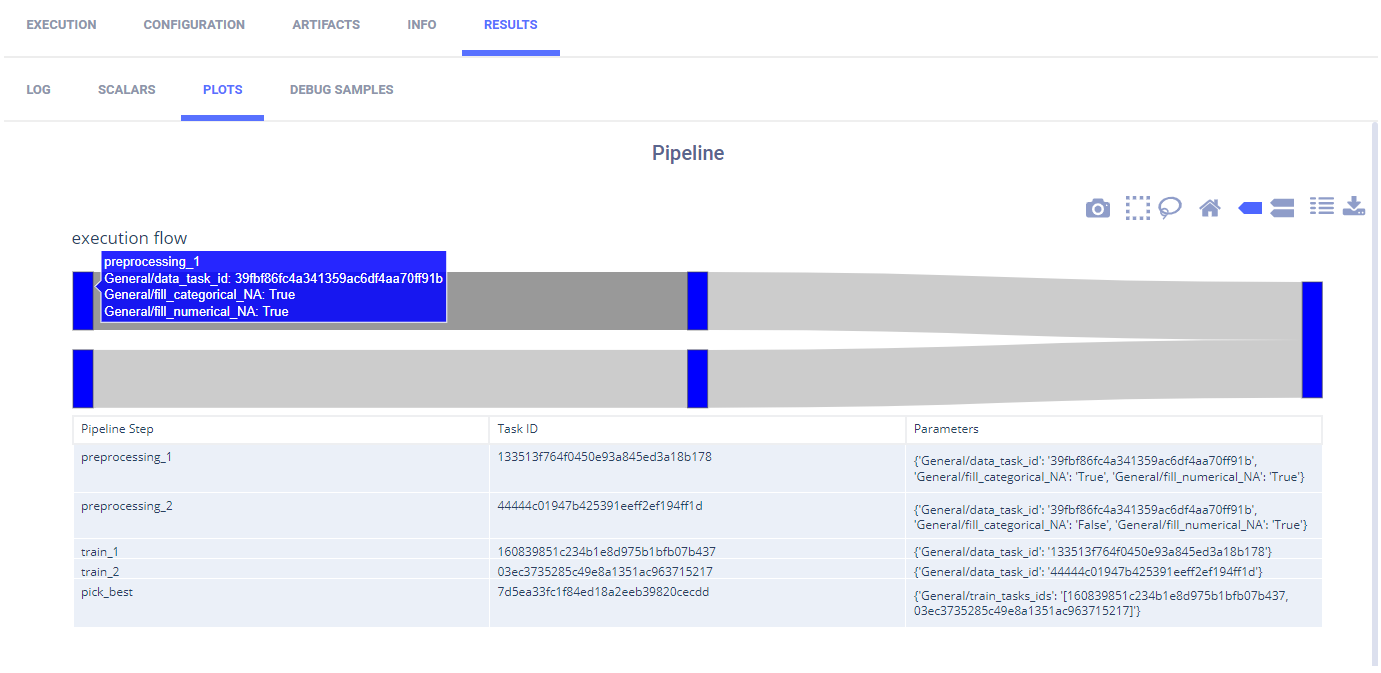
运行管道
运行管道的步骤:
-
通过运行笔记本download_and_split.ipynb下载数据。
-
如果脚本之前没有运行过,请为每个步骤运行脚本。
-
运行管道控制器的以下两种方式之一:
- 运行笔记本 tabular_ml_pipeline.ipynb。
- 远程执行任务 - 如果与项目
Tabular Example关联的任务tabular training pipeline已经在ClearML服务器中存在,克隆它并将其加入队列以执行。
如果你将一个任务加入队列,必须有一个工作线程在监听该队列以便执行任务。