高级自动微分#
在本教程中,您将了解自动微分(autodiff)在 JAX 中的复杂应用,并更好地理解在 JAX 中进行微分既简单又强大。
如果你还没有这样做,请务必查看 自动微分 教程,以了解 JAX 自动微分的基础知识。
设置#
import jax
import jax.numpy as jnp
from jax import grad, jit, vmap
from jax import random
key = random.key(0)
计算梯度(第二部分)#
高阶导数#
JAX 的自动微分使得计算高阶导数变得容易,因为计算导数的函数本身是可微的。因此,高阶导数就像堆叠变换一样简单。
单变量的情况在 自动微分 教程中已经涵盖,其中示例展示了如何使用 jax.grad() 来计算函数 \(f(x) = x^3 + 2x^2 - 3x + 1\) 的导数。
在多变量情况下,高阶导数更为复杂。函数的二阶导数由其 Hessian 矩阵 表示,定义如下:
实值多元函数 \(f: \mathbb R^n\to\mathbb R\) 的Hessian矩阵可以等同于其梯度的雅可比矩阵。
JAX 提供了两种计算函数雅可比矩阵的变换,jax.jacfwd() 和 jax.jacrev(),分别对应于前向和反向自动微分。它们给出相同的结果,但在不同情况下,其中一个可能比另一个更高效——请参考关于自动微分的视频。
def hessian(f):
return jax.jacfwd(jax.grad(f))
让我们再次确认点积 \(f: \mathbf{x} \mapsto \mathbf{x} ^\top \mathbf{x}\) 是正确的。
如果 \(i=j\),\(\frac{\partial^2 f}{\partial_i\partial_j}(\mathbf{x}) = 2\)。否则,\(\frac{\partial^2 f}{\partial_i\partial_j}(\mathbf{x}) = 0\)。
def f(x):
return jnp.dot(x, x)
hessian(f)(jnp.array([1., 2., 3.]))
Array([[2., 0., 0.],
[0., 2., 0.],
[0., 0., 2.]], dtype=float32)
高阶优化#
一些元学习技术,例如模型无关元学习(MAML),需要通过梯度更新进行微分。在其他框架中这可能会非常繁琐,但在JAX中则容易得多:
def meta_loss_fn(params, data):
"""Computes the loss after one step of SGD."""
grads = jax.grad(loss_fn)(params, data)
return loss_fn(params - lr * grads, data)
meta_grads = jax.grad(meta_loss_fn)(params, data)
停止梯度#
自动微分(Autodiff)能够自动计算函数相对于其输入的梯度。然而,有时你可能需要一些额外的控制:例如,你可能希望避免通过计算图的某些子集进行反向传播。
以 TD(0)(时序差分)强化学习更新为例。这用于从与环境的交互经验中学习估计环境中的状态的价值。假设状态 \(s_{t-1}\) 中的价值估计 \(v_{ heta}(s_{t-1}\)) 由线性函数参数化。
# Value function and initial parameters
value_fn = lambda theta, state: jnp.dot(theta, state)
theta = jnp.array([0.1, -0.1, 0.])
考虑从状态 \(s_{t-1}\) 到状态 \(s_t\) 的转换,在此期间你观察到了奖励 \(r_t\)。
# An example transition.
s_tm1 = jnp.array([1., 2., -1.])
r_t = jnp.array(1.)
s_t = jnp.array([2., 1., 0.])
对网络参数的 TD(0) 更新为:
此更新不是任何损失函数的梯度。
然而,它可以写成伪损失函数的梯度
如果忽略了目标 \(r_t + v_{ heta}(s_t)\) 对参数 \( heta\) 的依赖。
如何在 JAX 中实现这一点?如果你天真地编写伪损失,你会得到:
def td_loss(theta, s_tm1, r_t, s_t):
v_tm1 = value_fn(theta, s_tm1)
target = r_t + value_fn(theta, s_t)
return -0.5 * ((target - v_tm1) ** 2)
td_update = jax.grad(td_loss)
delta_theta = td_update(theta, s_tm1, r_t, s_t)
delta_theta
Array([-1.2, 1.2, -1.2], dtype=float32)
但是 td_update 将 不会 计算 TD(0) 更新,因为梯度计算将包括 target 对 \(\theta\) 的依赖。
你可以使用 jax.lax.stop_gradient() 来强制 JAX 忽略目标对 \(\theta\) 的依赖:
def td_loss(theta, s_tm1, r_t, s_t):
v_tm1 = value_fn(theta, s_tm1)
target = r_t + value_fn(theta, s_t)
return -0.5 * ((jax.lax.stop_gradient(target) - v_tm1) ** 2)
td_update = jax.grad(td_loss)
delta_theta = td_update(theta, s_tm1, r_t, s_t)
delta_theta
Array([ 1.2, 2.4, -1.2], dtype=float32)
这将把 target 视为不依赖于参数 \(\theta\),并计算出对参数的正确更新。
现在,我们也使用原始的TD(0)更新表达式来计算\(\Delta \theta\),以交叉检查我们的工作。你可以尝试使用jax.grad()和目前所学的知识自己实现这一点。以下是我们的解决方案:
s_grad = jax.grad(value_fn)(theta, s_tm1)
delta_theta_original_calculation = (r_t + value_fn(theta, s_t) - value_fn(theta, s_tm1)) * s_grad
delta_theta_original_calculation # [1.2, 2.4, -1.2], same as `delta_theta`
Array([ 1.2, 2.4, -1.2], dtype=float32)
jax.lax.stop_gradient 在其他情况下也可能有用,例如,如果你希望某个损失的梯度仅影响神经网络参数的一个子集(因为,例如,其他参数是使用不同的损失进行训练的)。
使用 stop_gradient 的直通估计器#
直通估计器是一种定义非可微函数“梯度”的技巧。给定一个非可微函数 \(f : \mathbb{R}^n \to \mathbb{R}^n\),它作为我们希望找到梯度的更大函数的一部分,我们在反向传播过程中简单地假装 \(f\) 是恒等函数。这可以通过使用 jax.lax.stop_gradient 来巧妙地实现:
def f(x):
return jnp.round(x) # non-differentiable
def straight_through_f(x):
# Create an exactly-zero expression with Sterbenz lemma that has
# an exactly-one gradient.
zero = x - jax.lax.stop_gradient(x)
return zero + jax.lax.stop_gradient(f(x))
print("f(x): ", f(3.2))
print("straight_through_f(x):", straight_through_f(3.2))
print("grad(f)(x):", jax.grad(f)(3.2))
print("grad(straight_through_f)(x):", jax.grad(straight_through_f)(3.2))
f(x): 3.0
straight_through_f(x): 3.0
grad(f)(x): 0.0
grad(straight_through_f)(x): 1.0
每个示例的梯度#
虽然大多数机器学习系统从数据批次中计算梯度和更新,出于计算效率和/或方差减少的原因,有时需要访问批次中每个特定样本相关的梯度/更新。
例如,这需要基于梯度幅度来优先处理数据,或者在样本基础上应用剪裁/归一化。
在许多框架(PyTorch、TF、Theano)中,计算每个样本的梯度通常并不简单,因为库直接累积了批次的梯度。简单的解决方法,例如为每个样本计算单独的损失,然后聚合生成的梯度,通常效率非常低。
在JAX中,你可以以简单但高效的方式定义计算每个样本梯度的代码。
只需将 jax.jit()、jax.vmap() 和 jax.grad() 变换组合在一起:
perex_grads = jax.jit(jax.vmap(jax.grad(td_loss), in_axes=(None, 0, 0, 0)))
# Test it:
batched_s_tm1 = jnp.stack([s_tm1, s_tm1])
batched_r_t = jnp.stack([r_t, r_t])
batched_s_t = jnp.stack([s_t, s_t])
perex_grads(theta, batched_s_tm1, batched_r_t, batched_s_t)
Array([[ 1.2, 2.4, -1.2],
[ 1.2, 2.4, -1.2]], dtype=float32)
让我们一次进行一个转换。
首先,你对 td_loss 应用 jax.grad() 以获得一个函数,该函数计算损失相对于单个(未批处理)输入参数的梯度:
dtdloss_dtheta = jax.grad(td_loss)
dtdloss_dtheta(theta, s_tm1, r_t, s_t)
Array([ 1.2, 2.4, -1.2], dtype=float32)
此函数计算上述数组的一行。
然后,你使用 jax.vmap() 向量化这个函数。这为所有输入和输出添加了一个批次维度。现在,给定一批输入,你会生成一批输出——批次中的每个输出对应于输入批次中相应成员的梯度。
almost_perex_grads = jax.vmap(dtdloss_dtheta)
batched_theta = jnp.stack([theta, theta])
almost_perex_grads(batched_theta, batched_s_tm1, batched_r_t, batched_s_t)
Array([[ 1.2, 2.4, -1.2],
[ 1.2, 2.4, -1.2]], dtype=float32)
这并不是我们想要的,因为我们必须手动给这个函数输入一批 theta,而我们实际上只想使用一个 theta。我们通过向 jax.vmap() 添加 in_axes 来解决这个问题,指定 theta 为 None,其他参数为 0。这使得结果函数只在其他参数上添加一个额外的轴,而 theta 保持未批处理状态,正如我们所希望的那样:
inefficient_perex_grads = jax.vmap(dtdloss_dtheta, in_axes=(None, 0, 0, 0))
inefficient_perex_grads(theta, batched_s_tm1, batched_r_t, batched_s_t)
Array([[ 1.2, 2.4, -1.2],
[ 1.2, 2.4, -1.2]], dtype=float32)
这实现了我们想要的功能,但比它应有的速度要慢。现在,你可以将整个内容包裹在 jax.jit() 中,以获得编译后的、高效的相同函数版本:
perex_grads = jax.jit(inefficient_perex_grads)
perex_grads(theta, batched_s_tm1, batched_r_t, batched_s_t)
Array([[ 1.2, 2.4, -1.2],
[ 1.2, 2.4, -1.2]], dtype=float32)
%timeit inefficient_perex_grads(theta, batched_s_tm1, batched_r_t, batched_s_t).block_until_ready()
%timeit perex_grads(theta, batched_s_tm1, batched_r_t, batched_s_t).block_until_ready()
1.66 ms ± 51 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
3.45 μs ± 23.9 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
使用 jax.grad-of-jax.grad 的 Hessian-向量乘积#
使用高阶 jax.vmap() 可以构建一个 Hessian-向量乘积函数。(稍后你将编写一个更高效的实现,它混合了前向模式和反向模式,但这个实现将使用纯反向模式。)
Hessian-向量乘积函数在截断牛顿共轭梯度算法中对于最小化光滑凸函数非常有用,或者用于研究神经网络训练目标的曲率(例如1, 2, 3, 4)。
对于具有连续二阶导数的标量值函数 \(f : \mathbb{R}^n \to \mathbb{R}\)(因此 Hessian 矩阵是对称的),在点 \(x \in \mathbb{R}^n\) 处的 Hessian 记作 \(\partial^2 f(x)\)。Hessian-向量乘积函数则能够计算
\(\qquad v \mapsto \partial^2 f(x) \cdot v\)
对于任意 \(v \in \mathbb{R}^n\)。
诀窍在于不要实例化完整的 Hessian 矩阵:如果 \(n\) 很大,可能在神经网络的背景下达到数百万或数十亿,那么这可能无法存储。
幸运的是,jax.vmap() 已经为我们提供了一种编写高效 Hessian-向量乘积函数的方法。你只需要使用这个恒等式:
\(\qquad \partial^2 f (x) v = \partial [x \mapsto \partial f(x) \cdot v] = \partial g(x)\),
其中 \(g(x) = \partial f(x) \cdot v\) 是一个新的标量值函数,它将 \(f\) 在 \(x\) 处的梯度与向量 \(v\) 进行点积。注意,你只对向量值参数的标量值函数进行微分,这正是你知道 jax.vmap() 高效的地方。
在JAX代码中,你可以这样写:
def hvp(f, x, v):
return grad(lambda x: jnp.vdot(grad(f)(x), v))(x)
这个例子展示了你可以自由使用词法闭包,而JAX永远不会感到困扰或困惑。
你将在学习如何计算稠密Hessian矩阵后,在下面几个单元格中检查这个实现。你还将编写一个更好的版本,该版本同时使用前向模式和反向模式。
使用 jax.jacfwd 和 jax.jacrev 的雅可比矩阵和海森矩阵#
你可以使用 jax.jacfwd() 和 jax.jacrev() 函数来计算完整的雅可比矩阵:
from jax import jacfwd, jacrev
# Define a sigmoid function.
def sigmoid(x):
return 0.5 * (jnp.tanh(x / 2) + 1)
# Outputs probability of a label being true.
def predict(W, b, inputs):
return sigmoid(jnp.dot(inputs, W) + b)
# Build a toy dataset.
inputs = jnp.array([[0.52, 1.12, 0.77],
[0.88, -1.08, 0.15],
[0.52, 0.06, -1.30],
[0.74, -2.49, 1.39]])
# Initialize random model coefficients
key, W_key, b_key = random.split(key, 3)
W = random.normal(W_key, (3,))
b = random.normal(b_key, ())
# Isolate the function from the weight matrix to the predictions
f = lambda W: predict(W, b, inputs)
J = jacfwd(f)(W)
print("jacfwd result, with shape", J.shape)
print(J)
J = jacrev(f)(W)
print("jacrev result, with shape", J.shape)
print(J)
jacfwd result, with shape (4, 3)
[[ 0.05981758 0.12883787 0.08857603]
[ 0.04015916 -0.04928625 0.00684531]
[ 0.12188288 0.01406341 -0.3047072 ]
[ 0.00140431 -0.00472531 0.00263782]]
jacrev result, with shape (4, 3)
[[ 0.05981757 0.12883787 0.08857603]
[ 0.04015916 -0.04928625 0.00684531]
[ 0.12188289 0.01406341 -0.3047072 ]
[ 0.00140431 -0.00472531 0.00263782]]
这两个函数计算相同的值(取决于机器数值),但它们的实现方式不同:jax.jacfwd() 使用前向模式自动微分,这对于“高”雅可比矩阵(输出多于输入)更有效,而 jax.jacrev() 使用反向模式,这对于“宽”雅可比矩阵(输入多于输出)更有效。对于接近方阵的矩阵,jax.jacfwd() 可能比 jax.jacrev() 更有优势。
你也可以将 jax.jacfwd() 和 jax.jacrev() 与容器类型一起使用:
def predict_dict(params, inputs):
return predict(params['W'], params['b'], inputs)
J_dict = jacrev(predict_dict)({'W': W, 'b': b}, inputs)
for k, v in J_dict.items():
print("Jacobian from {} to logits is".format(k))
print(v)
Jacobian from W to logits is
[[ 0.05981757 0.12883787 0.08857603]
[ 0.04015916 -0.04928625 0.00684531]
[ 0.12188289 0.01406341 -0.3047072 ]
[ 0.00140431 -0.00472531 0.00263782]]
Jacobian from b to logits is
[0.11503381 0.04563541 0.23439017 0.00189771]
有关前向模式和反向模式的更多详细信息,以及如何尽可能高效地实现 jax.jacfwd() 和 jax.jacrev(),请继续阅读!
使用这两种函数的组合,我们提供了一种计算稠密Hessian矩阵的方法:
def hessian(f):
return jacfwd(jacrev(f))
H = hessian(f)(W)
print("hessian, with shape", H.shape)
print(H)
hessian, with shape (4, 3, 3)
[[[ 0.02285465 0.04922541 0.03384247]
[ 0.04922541 0.10602397 0.07289147]
[ 0.03384247 0.07289147 0.05011288]]
[[-0.03195215 0.03921401 -0.00544639]
[ 0.03921401 -0.04812629 0.00668421]
[-0.00544639 0.00668421 -0.00092836]]
[[-0.01583708 -0.00182736 0.03959271]
[-0.00182736 -0.00021085 0.00456839]
[ 0.03959271 0.00456839 -0.09898177]]
[[-0.00103524 0.00348343 -0.00194457]
[ 0.00348343 -0.01172127 0.0065432 ]
[-0.00194457 0.0065432 -0.00365263]]]
这种形状是有意义的:如果你从一个函数 \(f : \mathbb{R}^n \to \mathbb{R}^m\) 开始,那么在点 \(x \in \mathbb{R}^n\) 处,你期望得到以下形状:
\(f(x) \in \mathbb{R}^m\),\(f\) 在 \(x\) 处的值,
\(\partial f(x) \in \mathbb{R}^{m \times n}\),即 \(x\) 处的雅可比矩阵。
\(\partial^2 f(x) \in \mathbb{R}^{m \times n \times n}\),即 \(x\) 处的 Hessian 矩阵,
等等。
要实现 hessian,你可以使用 jacfwd(jacrev(f)) 或 jacrev(jacfwd(f)),或者它们的任何其他组合。但通常情况下,正向-反向组合是最有效的。这是因为在内层的雅可比矩阵计算中,我们通常是对一个宽雅可比矩阵的函数(比如损失函数 \(f : \mathbb{R}^n \to \mathbb{R}\))进行微分,而在外层的雅可比矩阵计算中,我们是对一个方阵雅可比矩阵的函数(因为 \(\nabla f : \mathbb{R}^n \to \mathbb{R}^n\))进行微分,这正是正向模式胜出的地方。
制作方式:两个基础的自动微分函数#
雅可比向量积 (JVPs, 又称前向模式自动微分)#
JAX 包含了高效且通用的前向模式和反向模式自动微分实现。熟悉的 jax.vmap() 函数基于反向模式,但要解释这两种模式之间的区别,以及每种模式何时有用,你需要一些数学背景知识。
数学中的 JVPs#
在数学上,给定一个函数 \(f : \mathbb{R}^n \to \mathbb{R}^m\),函数 \(f\) 在输入点 \(x \in \mathbb{R}^n\) 处的雅可比矩阵,记作 \(\partial f(x)\),通常被视为一个 \(\mathbb{R}^m \times \mathbb{R}^n\) 中的矩阵:
\(\qquad \partial f(x) \in \mathbb{R}^{m \times n}\).
但您也可以将 \(\partial f(x)\) 视为一个线性映射,它将 \(f\) 在点 \(x\) 处的定义域的切空间(这只是 \(\mathbb{R}^n\) 的另一个副本)映射到 \(f\) 在点 \(f(x)\) 处的值域的切空间(\(\mathbb{R}^m\) 的一个副本):
\(\qquad \partial f(x) : \mathbb{R}^n \to \mathbb{R}^m\).
这个映射被称为 \(f\) 在 \(x\) 处的 前推映射。雅可比矩阵就是这个线性映射在标准基上的矩阵。
如果你不承诺使用一个特定的输入点 \(x\),那么你可以将函数 \(\partial f\) 视为首先接受一个输入点,然后返回该输入点处的雅可比线性映射:
\(\qquad \partial f : \mathbb{R}^n \to \mathbb{R}^n \to \mathbb{R}^m\).
特别是,你可以将事物解包,使得给定输入点 \(x \in \mathbb{R}^n\) 和切向量 \(v \in \mathbb{R}^n\),你得到一个输出切向量在 \(\mathbb{R}^m\) 中。我们将从 \((x, v)\) 对到输出切向量的映射称为 Jacobian-向量乘积,并将其写为:
\(\qquad (x, v) \mapsto \partial f(x) v\)
JAX 代码中的 JVPs#
回到Python代码中,JAX的jax.jvp()函数模拟了这种变换。给定一个评估\(f\)的Python函数,JAX的jax.jvp()是一种获取评估\((x, v) \mapsto (f(x), \partial f(x) v)\)的Python函数的方法。
from jax import jvp
# Isolate the function from the weight matrix to the predictions
f = lambda W: predict(W, b, inputs)
key, subkey = random.split(key)
v = random.normal(subkey, W.shape)
# Push forward the vector `v` along `f` evaluated at `W`
y, u = jvp(f, (W,), (v,))
在 Haskell 风格的类型签名 方面,你可以写成:
jvp :: (a -> b) -> a -> T a -> (b, T b)
其中 T a 用于表示 a 的切线空间类型。
换句话说,jvp 接受一个类型为 a -> b 的函数、一个类型为 a 的值和一个类型为 T a 的切向量值作为参数。它返回一个由类型为 b 的值和类型为 T b 的输出切向量组成的对。
jvp 变换后的函数与原始函数的评估方式非常相似,但对于类型为 a 的每个原始值,它还会推动类型为 T a 的切线值。对于原始函数将要应用的每个基本数值操作,jvp 变换后的函数会执行该基本操作的“JVP 规则”,该规则在原始值上评估基本操作,并在这些原始值上应用基本操作的 JVP。
这种评估策略对计算复杂度有一些直接的影响。由于我们在计算过程中评估JVP,因此我们不需要为后续操作存储任何内容,因此内存成本与计算的深度无关。此外,jvp转换后的函数的浮点运算成本大约是仅评估函数成本的3倍(例如,评估原始函数的一个工作单元,如sin(x);线性化一个工作单元,如cos(x);以及将线性化函数应用于向量的一个工作单元,如cos_x * v)。换句话说,对于固定的原始点\(x\),我们可以以与评估\(f\)相同的边际成本来评估\(v \mapsto \partial f(x) \cdot v\)。
这种内存复杂性听起来非常吸引人!那么为什么我们在机器学习中不常看到前向模式呢?
要回答这个问题,首先考虑如何使用 JVP 来构建完整的雅可比矩阵。如果我们对一个 one-hot 切向量应用 JVP,它会揭示雅可比矩阵的一列,对应于我们输入的非零条目。因此,我们可以逐列构建完整的雅可比矩阵,并且获取每一列的成本大约与一次函数求值相同。这对于具有“高”雅可比矩阵的函数来说是高效的,但对于“宽”雅可比矩阵的函数来说则是低效的。
如果你在进行基于梯度的机器学习优化,你可能希望最小化一个从参数空间 \(\mathbb{R}^n\) 到标量损失值 \(\mathbb{R}\) 的损失函数。这意味着该函数的雅可比矩阵是一个非常宽的矩阵:\(\partial f(x) \in \mathbb{R}^{1 \times n}\),我们通常将其等同于梯度向量 \(\nabla f(x) \in \mathbb{R}^n\)。每次调用时逐列构建该矩阵,每个调用所需的浮点运算次数与评估原始函数相似,这显然效率不高!特别是对于训练神经网络,其中 \(f\) 是训练损失函数,而 \(n\) 可能达到数百万或数十亿,这种方法根本无法扩展。
为了更好地实现此类功能,您只需使用反向模式。
向量-雅可比积 (VJPs, 又称反向模式自动微分)#
前向模式为我们提供了一个用于计算雅可比向量乘积的函数,我们可以使用它逐列构建雅可比矩阵,而反向模式则是一种获取用于计算向量-雅可比乘积(等效于雅可比转置-向量乘积)的函数的方法,我们可以使用它逐行构建雅可比矩阵。
数学中的 VJPs#
让我们再次考虑一个函数 \(f : \mathbb{R}^n \to \mathbb{R}^m\)。从我们对JVPs的表示法开始,VJPs的表示法非常简单:
\(\qquad (x, v) \mapsto v \partial f(x)\),
其中 \(v\) 是 \(x\) 处 \(f\) 的余切空间的一个元素(与 \(\mathbb{R}^m\) 的另一个副本同构)。严格来说,我们应该将 \(v\) 视为一个线性映射 \(v : \mathbb{R}^m \to \mathbb{R}\),而当我们写 \(v \partial f(x)\) 时,我们指的是函数复合 \(v \circ \partial f(x)\),其中类型是匹配的,因为 \(\partial f(x) : \mathbb{R}^n \to \mathbb{R}^m\)。但在常见情况下,我们可以将 \(v\) 与 \(\mathbb{R}^m\) 中的一个向量等同起来,并几乎可以互换使用两者,就像我们有时可能在“列向量”和“行向量”之间切换而无需过多说明一样。
有了这种识别,我们可以将 VJP 的线性部分视为 JVP 线性部分的转置(或伴随共轭):
\(\qquad (x, v) \mapsto \partial f(x)^\mathsf{T} v\).
对于给定的点 \(x\),我们可以将签名写为
\(\qquad \partial f(x)^\mathsf{T} : \mathbb{R}^m \to \mathbb{R}^n\).
在余切空间上的相应映射通常被称为 \(f\) 在 \(x\) 处的 拉回。对我们来说,关键在于它从看起来像 \(f\) 的输出的东西变成了看起来像 \(f\) 的输入的东西,就像我们可能期望从一个转置的线性函数那样。
JAX 代码中的 VJP#
从数学切换回Python,JAX函数vjp可以接受一个用于计算\(f\)的Python函数,并返回一个用于计算VJP \((x, v) \mapsto (f(x), v^\mathsf{T} \partial f(x))\)的Python函数。
from jax import vjp
# Isolate the function from the weight matrix to the predictions
f = lambda W: predict(W, b, inputs)
y, vjp_fun = vjp(f, W)
key, subkey = random.split(key)
u = random.normal(subkey, y.shape)
# Pull back the covector `u` along `f` evaluated at `W`
v = vjp_fun(u)
在 Haskell 风格的类型签名 方面,我们可以写成
vjp :: (a -> b) -> a -> (b, CT b -> CT a)
我们使用 CT a 来表示 a 的余切空间类型。换句话说,vjp 接受一个类型为 a -> b 的函数和一个类型为 a 的点作为参数,并返回一个由类型为 b 的值和类型为 CT b -> CT a 的线性映射组成的对。
这很棒,因为它让我们可以一行一行地构建雅可比矩阵,并且计算 \((x, v) \mapsto (f(x), v^\mathsf{T} \partial f(x))\) 的浮点运算成本仅约为计算 \(f\) 的三倍。特别是,如果我们想要一个函数 \(f : \mathbb{R}^n \to \mathbb{R}\) 的梯度,我们只需一次调用即可完成。这就是 jax.vmap() 在基于梯度的优化中高效的原因,即使对于像神经网络训练损失函数这样涉及数百万或数十亿参数的目标也是如此。
不过,这也有代价:尽管 FLOPs 很友好,但内存会随着计算深度的增加而增加。此外,与前向模式的实现相比,反向传播的传统实现通常更为复杂,尽管 JAX 有一些小技巧(这将是未来笔记本中的一个故事!)。
关于反向模式的工作原理,请查看 2017年深度学习暑期学校的这个教程视频。
带有 VJP 的向量值梯度#
如果你对计算向量值的梯度(如 tf.gradients)感兴趣:
def vgrad(f, x):
y, vjp_fn = vjp(f, x)
return vjp_fn(jnp.ones(y.shape))[0]
print(vgrad(lambda x: 3*x**2, jnp.ones((2, 2))))
[[6. 6.]
[6. 6.]]
使用前向模式和反向模式计算Hessian-向量乘积#
在之前的章节中,您实现了一个仅使用反向模式(假设连续的二阶导数)的 Hessian-向量乘积函数:
def hvp(f, x, v):
return grad(lambda x: jnp.vdot(grad(f)(x), v))(x)
这很高效,但你可以做得更好,通过结合前向模式和反向模式来节省一些内存。
在数学上,给定一个函数 \(f : \mathbb{R}^n \to \mathbb{R}\) 进行求导,一个点 \(x \in \mathbb{R}^n\) 用于线性化函数,以及一个向量 \(v \in \mathbb{R}^n\),我们想要的 Hessian-向量乘积函数是:
\((x, v) \mapsto \partial^2 f(x) v\)
考虑辅助函数 \(g : \mathbb{R}^n \to \mathbb{R}^n\),定义为 \(f\) 的导数(或梯度),即 \(g(x) = \partial f(x)\)。你只需要它的 JVP,因为这将给我们:
\((x, v) \mapsto \partial g(x) v = \partial^2 f(x) v\).
我们可以将那几乎直接翻译成代码:
# forward-over-reverse
def hvp(f, primals, tangents):
return jvp(grad(f), primals, tangents)[1]
更好的是,由于你不需要直接调用 jnp.dot(),这个 hvp 函数可以处理任意形状的数组和任意容器类型(如存储为嵌套列表/字典/元组的向量),甚至不依赖于 jax.numpy。
以下是如何使用它的示例:
def f(X):
return jnp.sum(jnp.tanh(X)**2)
key, subkey1, subkey2 = random.split(key, 3)
X = random.normal(subkey1, (30, 40))
V = random.normal(subkey2, (30, 40))
ans1 = hvp(f, (X,), (V,))
ans2 = jnp.tensordot(hessian(f)(X), V, 2)
print(jnp.allclose(ans1, ans2, 1e-4, 1e-4))
True
另一种你可能考虑的写法是使用反向-向前:
# Reverse-over-forward
def hvp_revfwd(f, primals, tangents):
g = lambda primals: jvp(f, primals, tangents)[1]
return grad(g)(primals)
不过,这并不是最好的选择,因为前向模式的开销比反向模式小,而且由于这里的外部微分操作符需要对一个比内部更大的计算进行微分,因此将前向模式放在外部效果最佳:
# Reverse-over-reverse, only works for single arguments
def hvp_revrev(f, primals, tangents):
x, = primals
v, = tangents
return grad(lambda x: jnp.vdot(grad(f)(x), v))(x)
print("Forward over reverse")
%timeit -n10 -r3 hvp(f, (X,), (V,))
print("Reverse over forward")
%timeit -n10 -r3 hvp_revfwd(f, (X,), (V,))
print("Reverse over reverse")
%timeit -n10 -r3 hvp_revrev(f, (X,), (V,))
print("Naive full Hessian materialization")
%timeit -n10 -r3 jnp.tensordot(hessian(f)(X), V, 2)
Forward over reverse
1.22 ms ± 24.4 μs per loop (mean ± std. dev. of 3 runs, 10 loops each)
Reverse over forward
The slowest run took 4.91 times longer than the fastest. This could mean that an intermediate result is being cached.
3.3 ms ± 2.63 ms per loop (mean ± std. dev. of 3 runs, 10 loops each)
Reverse over reverse
The slowest run took 5.06 times longer than the fastest. This could mean that an intermediate result is being cached.
5.17 ms ± 4.19 ms per loop (mean ± std. dev. of 3 runs, 10 loops each)
Naive full Hessian materialization
7.21 ms ± 275 μs per loop (mean ± std. dev. of 3 runs, 10 loops each)
组合 VJPs、JVPs 和 jax.vmap#
雅可比矩阵与矩阵-雅可比积#
既然你已经有了 jax.jvp() 和 jax.vjp() 变换,它们可以让你逐个前推或后拉向量,你可以使用 JAX 的 jax.vmap() 变换 来一次性前推或后拉整个基。特别是,你可以用它来快速编写矩阵-雅可比和雅可比-矩阵乘积:
# Isolate the function from the weight matrix to the predictions
f = lambda W: predict(W, b, inputs)
# Pull back the covectors `m_i` along `f`, evaluated at `W`, for all `i`.
# First, use a list comprehension to loop over rows in the matrix M.
def loop_mjp(f, x, M):
y, vjp_fun = vjp(f, x)
return jnp.vstack([vjp_fun(mi) for mi in M])
# Now, use vmap to build a computation that does a single fast matrix-matrix
# multiply, rather than an outer loop over vector-matrix multiplies.
def vmap_mjp(f, x, M):
y, vjp_fun = vjp(f, x)
outs, = vmap(vjp_fun)(M)
return outs
key = random.key(0)
num_covecs = 128
U = random.normal(key, (num_covecs,) + y.shape)
loop_vs = loop_mjp(f, W, M=U)
print('Non-vmapped Matrix-Jacobian product')
%timeit -n10 -r3 loop_mjp(f, W, M=U)
print('\nVmapped Matrix-Jacobian product')
vmap_vs = vmap_mjp(f, W, M=U)
%timeit -n10 -r3 vmap_mjp(f, W, M=U)
assert jnp.allclose(loop_vs, vmap_vs), 'Vmap and non-vmapped Matrix-Jacobian Products should be identical'
Non-vmapped Matrix-Jacobian product
47.4 ms ± 404 μs per loop (mean ± std. dev. of 3 runs, 10 loops each)
Vmapped Matrix-Jacobian product
1.35 ms ± 26.7 μs per loop (mean ± std. dev. of 3 runs, 10 loops each)
/var/folders/xc/cwj7_pwj6lb0lkpyjtcbm7y80000gn/T/ipykernel_22278/3769736790.py:8: DeprecationWarning: vstack requires ndarray or scalar arguments, got <class 'tuple'> at position 0. In a future JAX release this will be an error.
return jnp.vstack([vjp_fun(mi) for mi in M])
def loop_jmp(f, W, M):
# jvp immediately returns the primal and tangent values as a tuple,
# so we'll compute and select the tangents in a list comprehension
return jnp.vstack([jvp(f, (W,), (mi,))[1] for mi in M])
def vmap_jmp(f, W, M):
_jvp = lambda s: jvp(f, (W,), (s,))[1]
return vmap(_jvp)(M)
num_vecs = 128
S = random.normal(key, (num_vecs,) + W.shape)
loop_vs = loop_jmp(f, W, M=S)
print('Non-vmapped Jacobian-Matrix product')
%timeit -n10 -r3 loop_jmp(f, W, M=S)
vmap_vs = vmap_jmp(f, W, M=S)
print('\nVmapped Jacobian-Matrix product')
%timeit -n10 -r3 vmap_jmp(f, W, M=S)
assert jnp.allclose(loop_vs, vmap_vs), 'Vmap and non-vmapped Jacobian-Matrix products should be identical'
Non-vmapped Jacobian-Matrix product
51.8 ms ± 324 μs per loop (mean ± std. dev. of 3 runs, 10 loops each)
Vmapped Jacobian-Matrix product
642 μs ± 20 μs per loop (mean ± std. dev. of 3 runs, 10 loops each)
jax.jacfwd 和 jax.jacrev 的实现#
既然我们已经了解了快速雅可比矩阵和矩阵-雅可比积,不难猜测如何编写 jax.jacfwd() 和 jax.jacrev()。我们只需使用相同的技术来一次性前推或后拉整个标准基(同构于单位矩阵)。
from jax import jacrev as builtin_jacrev
def our_jacrev(f):
def jacfun(x):
y, vjp_fun = vjp(f, x)
# Use vmap to do a matrix-Jacobian product.
# Here, the matrix is the Euclidean basis, so we get all
# entries in the Jacobian at once.
J, = vmap(vjp_fun, in_axes=0)(jnp.eye(len(y)))
return J
return jacfun
assert jnp.allclose(builtin_jacrev(f)(W), our_jacrev(f)(W)), 'Incorrect reverse-mode Jacobian results!'
from jax import jacfwd as builtin_jacfwd
def our_jacfwd(f):
def jacfun(x):
_jvp = lambda s: jvp(f, (x,), (s,))[1]
Jt = vmap(_jvp, in_axes=1)(jnp.eye(len(x)))
return jnp.transpose(Jt)
return jacfun
assert jnp.allclose(builtin_jacfwd(f)(W), our_jacfwd(f)(W)), 'Incorrect forward-mode Jacobian results!'
有趣的是,Autograd 库无法做到这一点。Autograd 中反向模式 jacobian 的 实现 必须通过一个外部循环 map 一次拉回一个向量。通过计算一次推送一个向量比使用 jax.vmap() 将所有内容一起批处理效率低得多。
Autograd 无法做到的另一件事是 jax.jit()。有趣的是,无论你在要微分的函数中使用多少 Python 动态特性,我们总是可以在计算的线性部分使用 jax.jit()。例如:
def f(x):
try:
if x < 3:
return 2 * x ** 3
else:
raise ValueError
except ValueError:
return jnp.pi * x
y, f_vjp = vjp(f, 4.)
print(jit(f_vjp)(1.))
(Array(3.1415927, dtype=float32, weak_type=True),)
复数与微分#
JAX 在处理复数和微分方面非常出色。为了支持 全纯和非全纯微分,从 JVPs 和 VJPs 的角度思考会有所帮助。
考虑一个复数到复数的函数 \(f: \mathbb{C} \to \mathbb{C}\),并将其与相应的函数 \(g: \mathbb{R}^2 \to \mathbb{R}^2\) 对应起来。
def f(z):
x, y = jnp.real(z), jnp.imag(z)
return u(x, y) + v(x, y) * 1j
def g(x, y):
return (u(x, y), v(x, y))
也就是说,我们将 \(f(z) = u(x, y) + v(x, y) i\) 分解为 \(z = x + y i\),并将 \(\mathbb{C}\) 与 \(\mathbb{R}^2\) 对应起来,从而得到 \(g\)。
由于 \(g\) 仅涉及实数输入和输出,我们已经知道如何为其编写雅可比向量积,例如给定一个切向量 \((c, d) \in \mathbb{R}^2\),即:
\(\begin{bmatrix} \partial_0 u(x, y) & \partial_1 u(x, y) \\ \partial_0 v(x, y) & \partial_1 v(x, y) \end{bmatrix} \begin{bmatrix} c \\ d \end{bmatrix}\).
要获得原始函数 \(f\) 应用于切向量 \(c + di \in \mathbb{C}\) 的JVP,我们只需使用相同的定义,并将结果识别为另一个复数,
\(\partial f(x + y i)(c + d i) = \begin{matrix} \begin{bmatrix} 1 & i \end{bmatrix} \\ ~ \end{matrix} \begin{bmatrix} \partial_0 u(x, y) & \partial_1 u(x, y) \\ \partial_0 v(x, y) & \partial_1 v(x, y) \end{bmatrix} \begin{bmatrix} c \\ d \end{bmatrix}\).
这就是我们对一个 \(\mathbb{C} \to \mathbb{C}\) 函数的JVP的定义!注意,无论 \(f\) 是否是全纯函数,JVP 都是明确的。
这是一个检查:
def check(seed):
key = random.key(seed)
# random coeffs for u and v
key, subkey = random.split(key)
a, b, c, d = random.uniform(subkey, (4,))
def fun(z):
x, y = jnp.real(z), jnp.imag(z)
return u(x, y) + v(x, y) * 1j
def u(x, y):
return a * x + b * y
def v(x, y):
return c * x + d * y
# primal point
key, subkey = random.split(key)
x, y = random.uniform(subkey, (2,))
z = x + y * 1j
# tangent vector
key, subkey = random.split(key)
c, d = random.uniform(subkey, (2,))
z_dot = c + d * 1j
# check jvp
_, ans = jvp(fun, (z,), (z_dot,))
expected = (grad(u, 0)(x, y) * c +
grad(u, 1)(x, y) * d +
grad(v, 0)(x, y) * c * 1j+
grad(v, 1)(x, y) * d * 1j)
print(jnp.allclose(ans, expected))
check(0)
check(1)
check(2)
True
True
True
VJPs 呢?我们做的是非常类似的:对于一个余切向量 \(c + di \in \mathbb{C}\),我们将 \(f\) 的 VJP 定义为
\((c + di)^* \; \partial f(x + y i) = \begin{matrix} \begin{bmatrix} c & -d \end{bmatrix} \\ ~ \end{matrix} \begin{bmatrix} \partial_0 u(x, y) & \partial_1 u(x, y) \\ \partial_0 v(x, y) & \partial_1 v(x, y) \end{bmatrix} \begin{bmatrix} 1 \\ -i \end{bmatrix}\).
为什么会有负号?它们只是为了处理复杂的共轭,以及我们在处理协向量这一事实。
以下是VJP规则的检查:
def check(seed):
key = random.key(seed)
# random coeffs for u and v
key, subkey = random.split(key)
a, b, c, d = random.uniform(subkey, (4,))
def fun(z):
x, y = jnp.real(z), jnp.imag(z)
return u(x, y) + v(x, y) * 1j
def u(x, y):
return a * x + b * y
def v(x, y):
return c * x + d * y
# primal point
key, subkey = random.split(key)
x, y = random.uniform(subkey, (2,))
z = x + y * 1j
# cotangent vector
key, subkey = random.split(key)
c, d = random.uniform(subkey, (2,))
z_bar = jnp.array(c + d * 1j) # for dtype control
# check vjp
_, fun_vjp = vjp(fun, z)
ans, = fun_vjp(z_bar)
expected = (grad(u, 0)(x, y) * c +
grad(v, 0)(x, y) * (-d) +
grad(u, 1)(x, y) * c * (-1j) +
grad(v, 1)(x, y) * (-d) * (-1j))
assert jnp.allclose(ans, expected, atol=1e-5, rtol=1e-5)
check(0)
check(1)
check(2)
那么像 jax.grad()、jax.jacfwd() 和 jax.jacrev() 这样的便利包装器呢?
对于 \(\mathbb{R} \to \mathbb{R}\) 函数,回想我们定义 grad(f)(x) 为 vjp(f, x)[1](1.0),这是因为对 1.0 值应用 VJP 可以揭示梯度(即雅可比矩阵,或导数)。对于 \(\mathbb{C} \to \mathbb{R}\) 函数,我们也可以做同样的事情:我们仍然可以使用 1.0 作为余切向量,并且我们只需得到一个复数结果来总结完整的雅可比矩阵:
def f(z):
x, y = jnp.real(z), jnp.imag(z)
return x**2 + y**2
z = 3. + 4j
grad(f)(z)
Array(6.-8.j, dtype=complex64)
对于一般的 \(\mathbb{C} \to \mathbb{C}\) 函数,雅可比矩阵具有4个实值自由度(如上述2x2雅可比矩阵所示),因此我们无法希望用一个复数来表示所有这些函数。但对于全纯函数,我们可以做到这一点!全纯函数正是具有特殊性质的 \(\mathbb{C} \to \mathbb{C}\) 函数,其导数可以用一个复数来表示。(柯西-黎曼方程确保上述2x2雅可比矩阵具有复平面上的缩放和旋转矩阵的特殊形式,即单个复数在乘法下的作用。)我们可以通过使用协向量为 1.0 的 vjp 单次调用来揭示这个复数。
因为这仅适用于全纯函数,要使用这个技巧,我们需要向JAX承诺我们的函数是全纯的;否则,当对一个复数输出函数使用 jax.grad() 时,JAX将抛出一个错误:
def f(z):
return jnp.sin(z)
z = 3. + 4j
grad(f, holomorphic=True)(z)
Array(-27.034946-3.8511534j, dtype=complex64, weak_type=True)
所有 holomorphic=True 的承诺只是禁用了当输出为复数值时的错误。即使函数不是全纯的,我们仍然可以写 holomorphic=True,但我们得到的答案不会代表完整的雅可比矩阵。相反,它将是函数在丢弃输出虚部后的雅可比矩阵:
def f(z):
return jnp.conjugate(z)
z = 3. + 4j
grad(f, holomorphic=True)(z) # f is not actually holomorphic!
Array(1.-0.j, dtype=complex64, weak_type=True)
关于 jax.grad() 的工作原理,有一些有用的启示:
我们可以对全纯的 \(\mathbb{C} \to \mathbb{C}\) 函数使用
jax.grad()。我们可以使用
jax.grad()来优化 \(f : \mathbb{C} \to \mathbb{R}\) 函数,例如复数参数x的实值损失函数,通过在grad(f)(x)的共轭方向上采取步骤。如果我们有一个\(\mathbb{R} \to \mathbb{R}\)函数,它在内部恰好使用了某些复数值操作(其中一些必须是非全纯的,例如卷积中使用的FFT),那么
jax.grad()仍然有效,并且我们得到的结果与仅使用实数值实现的相同。
无论如何,JVPs和VJPs总是明确的。如果我们想计算一个非全纯的\(\mathbb{C} \to \mathbb{C}\)函数的完整雅可比矩阵,我们可以用JVPs或VJPs来实现!
你应该期望复数在JAX中无处不在。以下是通过复数矩阵的Cholesky分解进行微分:
A = jnp.array([[5., 2.+3j, 5j],
[2.-3j, 7., 1.+7j],
[-5j, 1.-7j, 12.]])
def f(X):
L = jnp.linalg.cholesky(X)
return jnp.sum((L - jnp.sin(L))**2)
grad(f, holomorphic=True)(A)
Array([[-0.75341946 +0.j , -3.0509028 -10.940545j ,
5.9896846 +3.5423026j],
[-3.0509028 +10.940545j , -8.904491 +0.j ,
-5.1351523 -6.559373j ],
[ 5.9896846 -3.5423026j, -5.1351523 +6.559373j ,
0.01320427 +0.j ]], dtype=complex64)
JAX 可转换 Python 函数的自定义导数规则#
在 JAX 中定义微分规则有两种方式:
使用
jax.custom_jvp()和jax.custom_vjp()为已经是 JAX 可转换的 Python 函数定义自定义微分规则;以及定义新的
core.Primitive实例以及它们所有的变换规则,例如调用来自其他系统(如求解器、模拟器或通用数值计算系统)的函数。
本笔记本是关于 #1 的。若要阅读关于 #2 的内容,请参阅 关于添加原语的笔记本。
TL;DR: 使用 jax.custom_jvp() 自定义 JVP#
from jax import custom_jvp
@custom_jvp
def f(x, y):
return jnp.sin(x) * y
@f.defjvp
def f_jvp(primals, tangents):
x, y = primals
x_dot, y_dot = tangents
primal_out = f(x, y)
tangent_out = jnp.cos(x) * x_dot * y + jnp.sin(x) * y_dot
return primal_out, tangent_out
print(f(2., 3.))
y, y_dot = jvp(f, (2., 3.), (1., 0.))
print(y)
print(y_dot)
print(grad(f)(2., 3.))
2.7278922
2.7278922
-1.2484405
-1.2484405
# Equivalent alternative using the `defjvps` convenience wrapper
@custom_jvp
def f(x, y):
return jnp.sin(x) * y
f.defjvps(lambda x_dot, primal_out, x, y: jnp.cos(x) * x_dot * y,
lambda y_dot, primal_out, x, y: jnp.sin(x) * y_dot)
print(f(2., 3.))
y, y_dot = jvp(f, (2., 3.), (1., 0.))
print(y)
print(y_dot)
print(grad(f)(2., 3.))
2.7278922
2.7278922
-1.2484405
-1.2484405
TL;DR: 使用 jax.custom_vjp 自定义 VJP#
from jax import custom_vjp
@custom_vjp
def f(x, y):
return jnp.sin(x) * y
def f_fwd(x, y):
# Returns primal output and residuals to be used in backward pass by `f_bwd`.
return f(x, y), (jnp.cos(x), jnp.sin(x), y)
def f_bwd(res, g):
cos_x, sin_x, y = res # Gets residuals computed in `f_fwd`
return (cos_x * g * y, sin_x * g)
f.defvjp(f_fwd, f_bwd)
print(grad(f)(2., 3.))
-1.2484405
示例问题#
要了解 jax.custom_jvp() 和 jax.custom_vjp() 旨在解决的问题,让我们来看几个例子。关于 jax.custom_jvp() 和 jax.custom_vjp() API 的更深入介绍在下一节。
示例:数值稳定性#
使用 jax.custom_jvp() 的一个应用是提高微分的数值稳定性。
假设我们想要编写一个名为 log1pexp 的函数,该函数计算 \(x \mapsto \log ( 1 + e^x )\)。我们可以使用 jax.numpy 来实现:
def log1pexp(x):
return jnp.log(1. + jnp.exp(x))
log1pexp(3.)
Array(3.0485873, dtype=float32, weak_type=True)
由于它是用 jax.numpy 编写的,因此可以进行 JAX 转换:
print(jit(log1pexp)(3.))
print(jit(grad(log1pexp))(3.))
print(vmap(jit(grad(log1pexp)))(jnp.arange(3.)))
3.0485873
0.95257413
[0.5 0.7310586 0.8807971]
但这里潜藏着一个数值稳定性问题:
print(grad(log1pexp)(100.))
nan
这似乎不对!毕竟,\(x \mapsto \log (1 + e^x)\) 的导数是 \(x \mapsto \frac{e^x}{1 + e^x}\),因此对于较大的 \(x\) 值,我们预计其值约为 1。
通过查看梯度计算的 jaxpr,我们可以更深入地了解正在发生的事情:
from jax import make_jaxpr
make_jaxpr(grad(log1pexp))(100.)
{ lambda ; a:f32[]. let
b:f32[] = exp a
c:f32[] = add 1.0 b
_:f32[] = log c
d:f32[] = div 1.0 c
e:f32[] = mul d b
in (e,) }
逐步分析jaxpr的计算过程,注意到最后一行将涉及乘以浮点数运算分别四舍五入为0和\(\infty\)的值,这从来都不是一个好主意。也就是说,我们实际上是在对较大的x计算lambda x: (1 / (1 + jnp.exp(x))) * jnp.exp(x),这实际上变成了0. * jnp.inf。
与其生成这些大小不一的值,希望浮点数能提供取消操作,我们更愿意将导数函数表达为一个数值上更稳定的程序。特别是,我们可以编写一个程序,更接近地评估等价的数学表达式 \(1 - \frac{1}{1 + e^x}\),并且看不到任何取消操作。
这个问题很有趣,因为尽管我们对 log1pexp 的定义已经可以通过 JAX 进行微分(并且可以通过 jax.jit()、jax.vmap() 等进行转换),但我们对将标准自动微分规则应用于构成 log1pexp 的原语并组合结果的结果并不满意。相反,我们希望指定整个函数 log1pexp 应该如何作为一个整体进行微分,从而更好地安排这些指数。
这是对已经可以进行JAX变换的Python函数应用自定义导数规则的一个例子:指定复合函数应如何求导,同时仍然使用其原始的Python定义进行其他变换(如 jax.jit()、jax.vmap() 等)。
以下是使用 jax.custom_jvp() 的解决方案:
@custom_jvp
def log1pexp(x):
return jnp.log(1. + jnp.exp(x))
@log1pexp.defjvp
def log1pexp_jvp(primals, tangents):
x, = primals
x_dot, = tangents
ans = log1pexp(x)
ans_dot = (1 - 1/(1 + jnp.exp(x))) * x_dot
return ans, ans_dot
print(grad(log1pexp)(100.))
1.0
print(jit(log1pexp)(3.))
print(jit(grad(log1pexp))(3.))
print(vmap(jit(grad(log1pexp)))(jnp.arange(3.)))
3.0485873
0.95257413
[0.5 0.7310586 0.8807971]
这是一个 defjvps 便捷包装器,用于表达相同的内容:
@custom_jvp
def log1pexp(x):
return jnp.log(1. + jnp.exp(x))
log1pexp.defjvps(lambda t, ans, x: (1 - 1/(1 + jnp.exp(x))) * t)
print(grad(log1pexp)(100.))
print(jit(log1pexp)(3.))
print(jit(grad(log1pexp))(3.))
print(vmap(jit(grad(log1pexp)))(jnp.arange(3.)))
1.0
3.0485873
0.95257413
[0.5 0.7310586 0.8807971]
示例:强制执行一个区分惯例#
一个相关的应用是在边界处强制执行一个区分约定。
考虑函数 \(f : \mathbb{R}_+ \to \mathbb{R}_+\),其中 \(f(x) = \frac{x}{1 + \sqrt{x}}\),我们取 \(\mathbb{R}_+ = [0, \infty)\)。我们可以将 \(f\) 实现为一个程序,如下所示:
def f(x):
return x / (1 + jnp.sqrt(x))
作为一个在 \(\mathbb{R}\)(全实线)上的数学函数,\(f\) 在零点处不可微(因为定义导数的极限不存在于左侧)。相应地,自动微分产生一个 nan 值:
print(grad(f)(0.))
nan
但从数学角度来看,如果我们认为 \(f\) 是定义在 \(\mathbb{R}_+\) 上的函数,那么在 0 处它是可微的 [Rudin 的《数学分析原理》定义 5.1,或 Tao 的《分析 I》第三版定义 10.1.1 和例 10.1.6]。或者,我们可以约定考虑从右侧的方向导数。因此,Python 函数 grad(f) 在 0.0 处返回 1.0 是有意义的。默认情况下,JAX 的微分机制假设所有函数都定义在 \(\mathbb{R}\) 上,因此在这里不会产生 1.0。
我们可以使用自定义的JVP规则!特别是,我们可以根据\(\mathbb{R}_+\)上的导数函数\(x \mapsto \frac{\sqrt{x} + 2}{2(\sqrt{x} + 1)^2}\)来定义JVP规则。
@custom_jvp
def f(x):
return x / (1 + jnp.sqrt(x))
@f.defjvp
def f_jvp(primals, tangents):
x, = primals
x_dot, = tangents
ans = f(x)
ans_dot = ((jnp.sqrt(x) + 2) / (2 * (jnp.sqrt(x) + 1)**2)) * x_dot
return ans, ans_dot
print(grad(f)(0.))
1.0
这里是便捷包装版本:
@custom_jvp
def f(x):
return x / (1 + jnp.sqrt(x))
f.defjvps(lambda t, ans, x: ((jnp.sqrt(x) + 2) / (2 * (jnp.sqrt(x) + 1)**2)) * t)
print(grad(f)(0.))
1.0
示例:梯度裁剪#
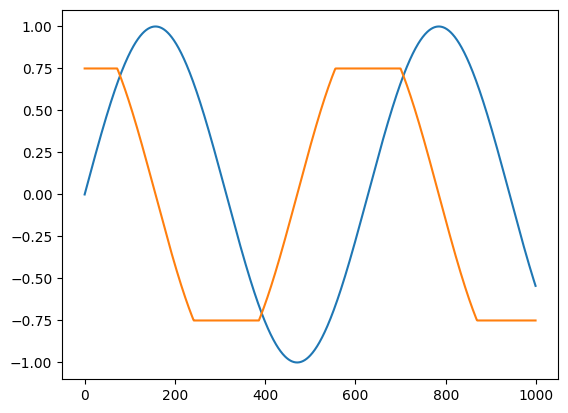
在某些情况下,我们希望表达一个数学微分计算,而在其他情况下,我们甚至可能希望远离数学来调整自动微分执行的计算。一个典型的例子是反向模式梯度裁剪。
对于梯度裁剪,我们可以结合使用 jnp.clip() 和 jax.custom_vjp() 仅反向模式的规则:
from functools import partial
@custom_vjp
def clip_gradient(lo, hi, x):
return x # identity function
def clip_gradient_fwd(lo, hi, x):
return x, (lo, hi) # save bounds as residuals
def clip_gradient_bwd(res, g):
lo, hi = res
return (None, None, jnp.clip(g, lo, hi)) # use None to indicate zero cotangents for lo and hi
clip_gradient.defvjp(clip_gradient_fwd, clip_gradient_bwd)
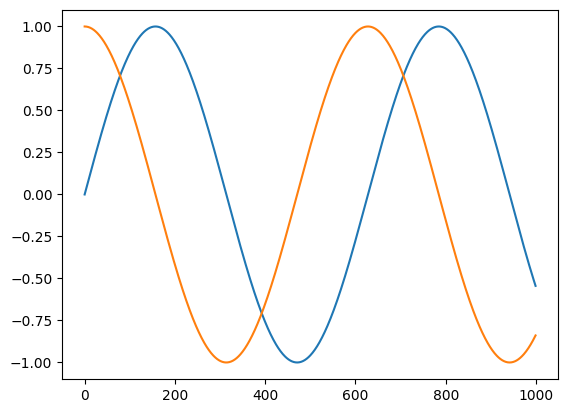
import matplotlib.pyplot as plt
t = jnp.linspace(0, 10, 1000)
plt.plot(jnp.sin(t))
plt.plot(vmap(grad(jnp.sin))(t))
[<matplotlib.lines.Line2D at 0x141cd89d0>]
def clip_sin(x):
x = clip_gradient(-0.75, 0.75, x)
return jnp.sin(x)
plt.plot(clip_sin(t))
plt.plot(vmap(grad(clip_sin))(t))
[<matplotlib.lines.Line2D at 0x1421ffbd0>]
示例:Python 调试#
另一个受开发工作流程而非数值计算驱动的应用是在反向模式自动微分的反向传递中设置 pdb 调试器跟踪。
当试图追踪 nan 运行时错误的来源,或者仔细检查正在传播的余切(梯度)值时,在反向传播中插入一个调试器可能会有用,该点对应于原始计算中的特定点。你可以使用 jax.custom_vjp() 来实现这一点。
我们将在下一节展示一个示例。
示例:迭代实现的隐函数微分#
这个例子深入到了数学的细节中!
另一个应用 jax.custom_vjp() 是对于那些可以通过 jax.jit()、jax.vmap() 等进行 JAX 变换但出于某种原因无法高效进行 JAX 微分的函数进行反向模式微分,可能是因为它们涉及 jax.lax.while_loop()。(生成一个能够高效计算 XLA HLO While 循环的反向模式导数的 XLA HLO 程序是不可能的,因为这将需要一个使用无界内存的程序,这在 XLA HLO 中无法表达,至少在没有通过 infeed/outfeed 进行“副作用”交互的情况下是不可能的。)
例如,考虑这个 fixed_point 例程,它通过在 while_loop 中迭代地应用一个函数来计算一个不动点:
from jax.lax import while_loop
def fixed_point(f, a, x_guess):
def cond_fun(carry):
x_prev, x = carry
return jnp.abs(x_prev - x) > 1e-6
def body_fun(carry):
_, x = carry
return x, f(a, x)
_, x_star = while_loop(cond_fun, body_fun, (x_guess, f(a, x_guess)))
return x_star
这是一个迭代过程,用于通过迭代 \(x_{t+1} = f(a, x_t)\) 直到 \(x_{t+1}\) 足够接近 \(x_t\),从而数值求解方程 \(x = f(a, x)\) 中的 \(x\)。结果 \(x^*\) 取决于参数 \(a\),因此我们可以认为存在一个由方程 \(x = f(a, x)\) 隐式定义的函数 \(a \mapsto x^*(a)\)。
我们可以使用 fixed_point 来运行迭代过程直至收敛,例如运行牛顿法来计算平方根,同时只执行加法、乘法和除法:
def newton_sqrt(a):
update = lambda a, x: 0.5 * (x + a / x)
return fixed_point(update, a, a)
print(newton_sqrt(2.))
1.4142135
我们也可以对函数使用 jax.vmap() 或 jax.jit():
print(jit(vmap(newton_sqrt))(jnp.array([1., 2., 3., 4.])))
[1. 1.4142135 1.7320509 2. ]
由于 while_loop 的存在,我们无法应用反向模式自动微分,但事实证明我们并不想这样做:与其通过 fixed_point 的实现及其所有迭代进行微分,我们可以利用数学结构来做一些内存效率更高(在这种情况下,也是 FLOP 效率更高!)的事情。我们可以使用隐函数定理 [Bertsekas 的《非线性规划》第二版中的命题 A.25],该定理保证(在某些条件下)我们即将使用的数学对象的存在性。本质上,我们线性化解并迭代求解这些线性方程来计算我们想要的导数。
再次考虑方程 \(x = f(a, x)\) 和函数 \(x^*\)。我们希望计算向量-雅可比矩阵乘积,如 \(v^\mathsf{T} \mapsto v^\mathsf{T} \partial x^*(a_0)\)。
至少在我们想要微分的点 \(a_0\) 的开放邻域内,假设对于所有 \(a\) ,方程 \(x^*(a) = f(a, x^*(a))\) 成立。由于两边的函数作为 \(a\) 的函数是相等的,它们的导数也必须相等,所以我们对两边进行微分:
\(\qquad \partial x^*(a) = \partial_0 f(a, x^*(a)) + \partial_1 f(a, x^*(a)) \partial x^*(a)\).
设 \(A = \partial_1 f(a_0, x^*(a_0))\) 和 \(B = \partial_0 f(a_0, x^*(a_0))\),我们可以将所求的量更简洁地表示为:
\(\qquad \partial x^*(a_0) = B + A \partial x^*(a_0)\),
或者,通过重新排列,
\(\qquad \partial x^*(a_0) = (I - A)^{-1} B\).
这意味着我们可以计算向量-雅可比矩阵乘积,例如:
\(\qquad v^\mathsf{T} \partial x^*(a_0) = v^\mathsf{T} (I - A)^{-1} B = w^\mathsf{T} B\),
其中 \(w^\mathsf{T} = v^\mathsf{T} (I - A)^{-1}\),或等价地 \(w^\mathsf{T} = v^\mathsf{T} + w^\mathsf{T} A\),或等价地 \(w^\mathsf{T}\) 是映射 \(u^\mathsf{T} \mapsto v^\mathsf{T} + u^\mathsf{T} A\) 的不动点。最后一个特征为我们提供了一种方法,可以用对 fixed_point 的调用来表示 fixed_point 的 VJP!此外,在将 \(A\) 和 \(B\) 展开回原样后,你可以得出结论,只需要在 \((a_0, x^*(a_0))\) 处计算 \(f\) 的 VJP。
总之:
@partial(custom_vjp, nondiff_argnums=(0,))
def fixed_point(f, a, x_guess):
def cond_fun(carry):
x_prev, x = carry
return jnp.abs(x_prev - x) > 1e-6
def body_fun(carry):
_, x = carry
return x, f(a, x)
_, x_star = while_loop(cond_fun, body_fun, (x_guess, f(a, x_guess)))
return x_star
def fixed_point_fwd(f, a, x_init):
x_star = fixed_point(f, a, x_init)
return x_star, (a, x_star)
def fixed_point_rev(f, res, x_star_bar):
a, x_star = res
_, vjp_a = vjp(lambda a: f(a, x_star), a)
a_bar, = vjp_a(fixed_point(partial(rev_iter, f),
(a, x_star, x_star_bar),
x_star_bar))
return a_bar, jnp.zeros_like(x_star)
def rev_iter(f, packed, u):
a, x_star, x_star_bar = packed
_, vjp_x = vjp(lambda x: f(a, x), x_star)
return x_star_bar + vjp_x(u)[0]
fixed_point.defvjp(fixed_point_fwd, fixed_point_rev)
print(newton_sqrt(2.))
1.4142135
print(grad(newton_sqrt)(2.))
print(grad(grad(newton_sqrt))(2.))
0.35355338
-0.088388346
我们可以通过微分 jnp.sqrt() 来检查我们的答案,它使用了完全不同的实现:
print(grad(jnp.sqrt)(2.))
print(grad(grad(jnp.sqrt))(2.))
0.35355338
-0.08838835
这种方法的一个限制是参数 f 不能关闭任何涉及微分的值。也就是说,你可能会注意到我们在 fixed_point 的参数列表中明确保留了参数 a。对于这种情况,可以考虑使用低级原语 lax.custom_root,它允许在闭包变量中使用自定义的根查找函数进行导数计算。
jax.custom_jvp 和 jax.custom_vjp API 的基本用法#
使用 jax.custom_jvp 来定义前向模式(以及间接地,反向模式)规则#
以下是使用 jax.custom_jvp() 的一个典型基本示例,其中注释使用了 Haskell 风格的类型签名:
# f :: a -> b
@custom_jvp
def f(x):
return jnp.sin(x)
# f_jvp :: (a, T a) -> (b, T b)
def f_jvp(primals, tangents):
x, = primals
t, = tangents
return f(x), jnp.cos(x) * t
f.defjvp(f_jvp)
<function __main__.f_jvp(primals, tangents)>
print(f(3.))
y, y_dot = jvp(f, (3.,), (1.,))
print(y)
print(y_dot)
0.14112
0.14112
-0.9899925
换句话说,我们从原始函数 f 开始,该函数接受类型为 a 的输入并生成类型为 b 的输出。我们将其与一个 JVP 规则函数 f_jvp 相关联,该函数接受一对输入,表示类型为 a 的原始输入和类型为 T a 的相应切线输入,并生成一对输出,表示类型为 b 的原始输出和类型为 T b 的切线输出。切线输出应是切线输入的线性函数。
你也可以将 f.defjvp 用作装饰器,例如
@custom_jvp
def f(x):
...
@f.defjvp
def f_jvp(primals, tangents):
...
尽管我们只定义了一个JVP规则而没有定义VJP规则,我们仍然可以在f上使用前向和反向模式微分。JAX会自动将我们自定义JVP规则中的切线值的线性计算进行转置,计算VJP的效率就像我们手动编写规则一样高效:
print(grad(f)(3.))
print(grad(grad(f))(3.))
-0.9899925
-0.14112
为了使自动转置工作,JVP规则的输出切线必须作为输入切线的函数是线性的。否则会引发转置错误。
多个参数的工作方式如下:
@custom_jvp
def f(x, y):
return x ** 2 * y
@f.defjvp
def f_jvp(primals, tangents):
x, y = primals
x_dot, y_dot = tangents
primal_out = f(x, y)
tangent_out = 2 * x * y * x_dot + x ** 2 * y_dot
return primal_out, tangent_out
print(grad(f)(2., 3.))
12.0
defjvps 便捷包装器允许我们分别为每个参数定义一个 JVP,并且结果会分别计算然后求和:
@custom_jvp
def f(x):
return jnp.sin(x)
f.defjvps(lambda t, ans, x: jnp.cos(x) * t)
print(grad(f)(3.))
-0.9899925
这是一个带有多个参数的 defjvps 示例:
@custom_jvp
def f(x, y):
return x ** 2 * y
f.defjvps(lambda x_dot, primal_out, x, y: 2 * x * y * x_dot,
lambda y_dot, primal_out, x, y: x ** 2 * y_dot)
print(grad(f)(2., 3.))
print(grad(f, 0)(2., 3.)) # same as above
print(grad(f, 1)(2., 3.))
12.0
12.0
4.0
作为一种简写方式,使用 defjvps 时,你可以传递一个 None 值来表示某个参数的 JVP 为零:
@custom_jvp
def f(x, y):
return x ** 2 * y
f.defjvps(lambda x_dot, primal_out, x, y: 2 * x * y * x_dot,
None)
print(grad(f)(2., 3.))
print(grad(f, 0)(2., 3.)) # same as above
print(grad(f, 1)(2., 3.))
12.0
12.0
0.0
使用关键字参数调用 jax.custom_jvp() 函数,或者使用默认参数编写 jax.custom_jvp() 函数定义,都是允许的,只要它们可以根据标准库 inspect.signature 机制检索到的函数签名明确映射到位置参数。
当你不进行微分时,函数 f 的调用方式就像它没有被 jax.custom_jvp() 装饰一样:
@custom_jvp
def f(x):
print('called f!') # a harmless side-effect
return jnp.sin(x)
@f.defjvp
def f_jvp(primals, tangents):
print('called f_jvp!') # a harmless side-effect
x, = primals
t, = tangents
return f(x), jnp.cos(x) * t
print(f(3.))
called f!
0.14112
print(vmap(f)(jnp.arange(3.)))
print(jit(f)(3.))
called f!
[0. 0.84147096 0.9092974 ]
called f!
0.14112
自定义 JVP 规则在微分过程中被调用,无论是正向还是反向:
y, y_dot = jvp(f, (3.,), (1.,))
print(y_dot)
called f_jvp!
called f!
-0.9899925
print(grad(f)(3.))
called f_jvp!
called f!
-0.9899925
注意 f_jvp 调用 f 来计算原始输出。在高阶微分的上下文中,每次应用微分变换时,只有在规则调用原始 f 来计算原始输出时,才会使用自定义的 JVP 规则。(这代表了一种基本的权衡,我们无法在规则中利用 f 计算的中间值,同时也不能让规则适用于所有高阶微分的阶数。)
grad(grad(f))(3.)
called f_jvp!
called f_jvp!
called f!
Array(-0.14112, dtype=float32, weak_type=True)
你可以将 Python 控制流与 jax.custom_jvp() 一起使用:
@custom_jvp
def f(x):
if x > 0:
return jnp.sin(x)
else:
return jnp.cos(x)
@f.defjvp
def f_jvp(primals, tangents):
x, = primals
x_dot, = tangents
ans = f(x)
if x > 0:
return ans, 2 * x_dot
else:
return ans, 3 * x_dot
print(grad(f)(1.))
print(grad(f)(-1.))
2.0
3.0
使用 jax.custom_vjp 来定义自定义的仅反向模式规则#
虽然 jax.custom_jvp() 足以控制前向和通过 JAX 的自动转置实现的反向模式微分行为,但在某些情况下,我们可能希望直接控制 VJP 规则,例如在上述后两个示例问题中。我们可以使用 jax.custom_vjp() 来实现这一点:
from jax import custom_vjp
# f :: a -> b
@custom_vjp
def f(x):
return jnp.sin(x)
# f_fwd :: a -> (b, c)
def f_fwd(x):
return f(x), jnp.cos(x)
# f_bwd :: (c, CT b) -> CT a
def f_bwd(cos_x, y_bar):
return (cos_x * y_bar,)
f.defvjp(f_fwd, f_bwd)
print(f(3.))
print(grad(f)(3.))
0.14112
-0.9899925
换句话说,我们再次从一个原始函数 f 开始,该函数接受类型为 a 的输入并产生类型为 b 的输出。我们将其与两个函数 f_fwd 和 f_bwd 关联,分别描述如何执行反向模式自动微分的正向传递和反向传递。
函数 f_fwd 描述了前向传递,不仅包括原始计算,还包括为反向传递保存的值。它的输入签名与原始函数 f 的输入签名相同,即它接受类型为 a 的原始输入。但作为输出,它产生一对,其中第一个元素是原始输出 b,第二个元素是类型为 c 的任何“残差”数据,这些数据将被存储以供反向传递使用。(第二个输出类似于 PyTorch 的 save_for_backward 机制。)
函数 f_bwd 描述了反向传递。它接受两个输入,第一个是 f_fwd 产生的类型为 c 的残差数据,第二个是与原函数输出相对应的类型为 CT b 的输出余切向量。它产生一个类型为 CT a 的输出,表示与原函数输入相对应的余切向量。特别地,f_bwd 的输出必须是一个序列(例如一个元组),其长度等于原函数参数的数量。
因此,多个参数的工作方式如下:
@custom_vjp
def f(x, y):
return jnp.sin(x) * y
def f_fwd(x, y):
return f(x, y), (jnp.cos(x), jnp.sin(x), y)
def f_bwd(res, g):
cos_x, sin_x, y = res
return (cos_x * g * y, sin_x * g)
f.defvjp(f_fwd, f_bwd)
print(grad(f)(2., 3.))
-1.2484405
使用关键字参数调用 jax.custom_vjp() 函数,或者使用默认参数编写 jax.custom_vjp() 函数定义,都是允许的,只要它们可以根据标准库 inspect.signature 机制检索到的函数签名明确映射到位置参数。
与 jax.custom_jvp() 类似,由 f_fwd 和 f_bwd 组成的自定义 VJP 规则在未应用微分时不会被调用。如果函数被评估,或通过 jax.jit()、jax.vmap() 或其他非微分变换进行变换,则只会调用 f。
@custom_vjp
def f(x):
print("called f!")
return jnp.sin(x)
def f_fwd(x):
print("called f_fwd!")
return f(x), jnp.cos(x)
def f_bwd(cos_x, y_bar):
print("called f_bwd!")
return (cos_x * y_bar,)
f.defvjp(f_fwd, f_bwd)
print(f(3.))
called f!
0.14112
print(grad(f)(3.))
called f_fwd!
called f!
called f_bwd!
-0.9899925
y, f_vjp = vjp(f, 3.)
print(y)
called f_fwd!
called f!
0.14112
print(f_vjp(1.))
called f_bwd!
(Array(-0.9899925, dtype=float32, weak_type=True),)
前向模式自动微分不能用于 jax.custom_vjp() 函数,并且会引发错误:
from jax import jvp
try:
jvp(f, (3.,), (1.,))
except TypeError as e:
print('ERROR! {}'.format(e))
called f_fwd!
called f!
ERROR! can't apply forward-mode autodiff (jvp) to a custom_vjp function.
如果你想同时使用前向模式和反向模式,请使用 jax.custom_jvp()。
我们可以使用 jax.custom_vjp() 结合 pdb 在反向传播过程中插入调试器追踪:
import pdb
@custom_vjp
def debug(x):
return x # acts like identity
def debug_fwd(x):
return x, x
def debug_bwd(x, g):
import pdb; pdb.set_trace()
return g
debug.defvjp(debug_fwd, debug_bwd)
def foo(x):
y = x ** 2
y = debug(y) # insert pdb in corresponding backward pass step
return jnp.sin(y)
jax.grad(foo)(3.)
> <ipython-input-113-b19a2dc1abf7>(12)debug_bwd()
-> return g
(Pdb) p x
Array(9., dtype=float32)
(Pdb) p g
Array(-0.91113025, dtype=float32)
(Pdb) q
更多功能和细节#
使用 list / tuple / dict 容器(以及其他 pytrees)#
你应该期待标准的Python容器,如列表、元组、命名元组和字典,以及这些的嵌套版本,都能正常工作。一般来说,任何 pytrees 都是允许的,只要它们的结构根据类型约束是一致的。
这是一个使用 jax.custom_jvp() 的刻意设计的例子:
from collections import namedtuple
Point = namedtuple("Point", ["x", "y"])
@custom_jvp
def f(pt):
x, y = pt.x, pt.y
return {'a': x ** 2,
'b': (jnp.sin(x), jnp.cos(y))}
@f.defjvp
def f_jvp(primals, tangents):
pt, = primals
pt_dot, = tangents
ans = f(pt)
ans_dot = {'a': 2 * pt.x * pt_dot.x,
'b': (jnp.cos(pt.x) * pt_dot.x, -jnp.sin(pt.y) * pt_dot.y)}
return ans, ans_dot
def fun(pt):
dct = f(pt)
return dct['a'] + dct['b'][0]
pt = Point(1., 2.)
print(f(pt))
{'a': 1.0, 'b': (Array(0.84147096, dtype=float32, weak_type=True), Array(-0.41614684, dtype=float32, weak_type=True))}
print(grad(fun)(pt))
Point(x=Array(2.5403023, dtype=float32, weak_type=True), y=Array(0., dtype=float32, weak_type=True))
以及一个类似的刻意设计的例子,使用 jax.custom_vjp():
@custom_vjp
def f(pt):
x, y = pt.x, pt.y
return {'a': x ** 2,
'b': (jnp.sin(x), jnp.cos(y))}
def f_fwd(pt):
return f(pt), pt
def f_bwd(pt, g):
a_bar, (b0_bar, b1_bar) = g['a'], g['b']
x_bar = 2 * pt.x * a_bar + jnp.cos(pt.x) * b0_bar
y_bar = -jnp.sin(pt.y) * b1_bar
return (Point(x_bar, y_bar),)
f.defvjp(f_fwd, f_bwd)
def fun(pt):
dct = f(pt)
return dct['a'] + dct['b'][0]
pt = Point(1., 2.)
print(f(pt))
{'a': 1.0, 'b': (Array(0.84147096, dtype=float32, weak_type=True), Array(-0.41614684, dtype=float32, weak_type=True))}
print(grad(fun)(pt))
Point(x=Array(2.5403023, dtype=float32, weak_type=True), y=Array(-0., dtype=float32, weak_type=True))
处理不可微分的参数#
一些用例,比如最终的示例问题,要求将不可微分的参数(如函数值参数)传递给具有自定义微分规则的函数,并且这些参数也需要传递给规则本身。在 fixed_point 的情况下,函数参数 f 就是这样一个不可微分的参数。类似的情况也出现在 jax.experimental.odeint 中。
jax.custom_jvp 带有 nondiff_argnums#
使用可选的 nondiff_argnums 参数来 jax.custom_jvp() 以指示这些参数。以下是 jax.custom_jvp() 的示例:
from functools import partial
@partial(custom_jvp, nondiff_argnums=(0,))
def app(f, x):
return f(x)
@app.defjvp
def app_jvp(f, primals, tangents):
x, = primals
x_dot, = tangents
return f(x), 2. * x_dot
print(app(lambda x: x ** 3, 3.))
27.0
print(grad(app, 1)(lambda x: x ** 3, 3.))
2.0
注意这里的陷阱:无论这些参数在参数列表中的哪个位置出现,它们都会被放置在相应 JVP 规则签名的 开头 。这里还有一个例子:
@partial(custom_jvp, nondiff_argnums=(0, 2))
def app2(f, x, g):
return f(g((x)))
@app2.defjvp
def app2_jvp(f, g, primals, tangents):
x, = primals
x_dot, = tangents
return f(g(x)), 3. * x_dot
print(app2(lambda x: x ** 3, 3., lambda y: 5 * y))
3375.0
print(grad(app2, 1)(lambda x: x ** 3, 3., lambda y: 5 * y))
3.0
jax.custom_vjp 带有 nondiff_argnums#
对于 jax.custom_vjp() 也存在类似的选项,同样地,约定是不可微分的参数作为 _bwd 规则的第一个参数传递,无论它们在原始函数签名中的位置如何。_fwd 规则的签名保持不变 - 它与原始函数的签名相同。以下是一个示例:
@partial(custom_vjp, nondiff_argnums=(0,))
def app(f, x):
return f(x)
def app_fwd(f, x):
return f(x), x
def app_bwd(f, x, g):
return (5 * g,)
app.defvjp(app_fwd, app_bwd)
print(app(lambda x: x ** 2, 4.))
16.0
print(grad(app, 1)(lambda x: x ** 2, 4.))
5.0
请参考上面的 fixed_point 以获取另一个使用示例。
你不需要对 nondiff_argnums 使用数组值的参数,例如,具有整数数据类型的参数。相反,nondiff_argnums 应该仅用于不对应于 JAX 类型的参数值(基本上不对应于数组类型),如 Python 可调用对象或字符串。如果 JAX 检测到 nondiff_argnums 指示的参数包含 JAX Tracer,则会引发错误。上面的 clip_gradient 函数就是一个很好的例子,它没有对整数数据类型的数组参数使用 nondiff_argnums。
下一步#
还有许多其他的自动微分技巧和功能。本教程未涵盖但值得探讨的主题包括:
高斯-牛顿向量积,一次线性化
自定义 VJP 和 JVP
固定点的高效导数
使用随机 Hessian-向量 乘积估计 Hessian 的迹
仅使用反向模式自动微分的正向模式自动微分
对自定义数据类型求导
检查点(用于高效反向模式的二项式检查点,非模型快照)
通过雅可比矩阵预累积优化VJP