检索器
概述
存在许多不同类型的检索系统,包括向量存储、图数据库和关系数据库。 随着大型语言模型的普及,检索系统已成为人工智能应用中的重要组成部分(例如,RAG)。 由于其重要性和多样性,LangChain 提供了一个统一的接口来与不同类型的检索系统进行交互。 LangChain 的检索器接口非常简单:
- 输入:一个查询(字符串)
- 输出:文档列表(标准化的LangChain Document 对象)
关键概念
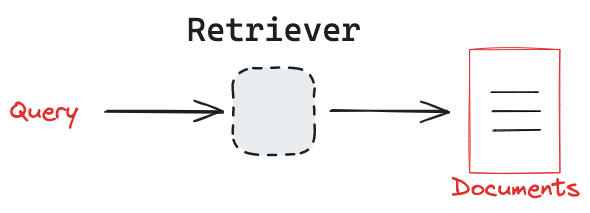
所有检索器都实现了一个简单的接口,用于使用自然语言查询检索文档。
接口
检索器的唯一要求是能够接受查询并返回文档。
特别是,LangChain的检索器类只需要实现_get_relevant_documents方法,该方法接受一个query: str并返回与查询最相关的Document对象列表。
用于获取相关文档的底层逻辑由检索器指定,可以是应用程序中最有用的任何逻辑。
LangChain 检索器是一个 可运行 的组件,它是 LangChain 组件的标准接口。
这意味着它有一些常见的方法,包括 invoke,用于与其进行交互。可以通过查询来调用检索器:
docs = retriever.invoke(query)
检索器返回一个Document对象的列表,这些对象有两个属性:
page_content: 此文档的内容。目前是一个字符串。metadata: 与此文档关联的任意元数据(例如,文档ID、文件名、来源等)。
- 查看我们的操作指南,了解如何构建您自己的自定义检索器。
常见类型
尽管检索器接口具有灵活性,但一些常见的检索系统类型经常被使用。
搜索API
需要注意的是,检索器实际上不需要存储文档。 例如,我们可以在搜索API之上构建检索器,这些API只需返回搜索结果! 请参阅我们与Amazon Kendra或Wikipedia Search的检索器集成。
关系型或图数据库
检索器可以建立在关系型或图数据库之上。 在这些情况下,查询分析技术从自然语言构建结构化查询至关重要。 例如,您可以使用文本到SQL转换来为SQL数据库构建检索器。这使得自然语言查询(字符串)检索器可以在后台转换为SQL查询。
词汇搜索
正如我们在检索的概念回顾中所讨论的,许多搜索引擎基于将查询中的单词与每个文档中的单词进行匹配。 BM25 和 TF-IDF 是 两种流行的词汇搜索算法。 LangChain 提供了许多流行的词汇搜索算法/引擎的检索器。
- 查看 BM25 检索器集成。
- 查看TF-IDF检索器集成。
- 查看Elasticsearch检索器集成。
向量存储
向量存储是一种强大且高效的方式来索引和检索非结构化数据。
可以通过调用as_retriever()方法将向量存储用作检索器。
vectorstore = MyVectorStore()
retriever = vectorstore.as_retriever()
高级检索模式
集成
因为检索器接口非常简单,给定一个搜索查询,它会返回一个Document对象列表,所以可以使用集成来组合多个检索器。
当你拥有多个擅长查找不同类型相关文档的检索器时,这特别有用。
创建一个集成检索器,将多个检索器与线性加权分数结合起来,非常容易:
# Initialize the ensemble retriever
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_store_retriever], weights=[0.5, 0.5]
)
在集成时,我们如何结合来自多个检索器的搜索结果? 这激发了重新排序的概念,它采用多个检索器的输出,并使用更复杂的算法(如互惠排名融合(RRF))将它们结合起来。
源文件保留
许多检索器利用某种索引使文档易于搜索。 索引过程可能包括一个转换步骤(例如,向量存储通常使用文档分割)。 无论使用何种转换,保留转换后的文档与原始文档之间的链接非常有用,使检索器能够返回原始文档。
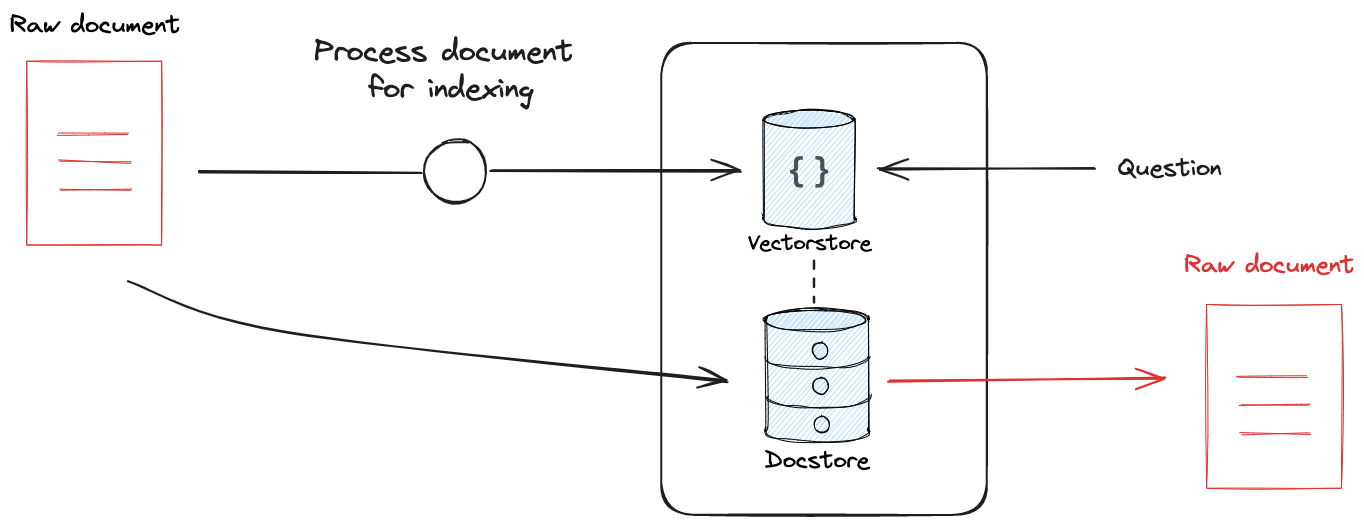
这在人工智能应用中特别有用,因为它确保了模型不会丢失文档上下文。 例如,您可以使用小块大小在向量存储中索引文档。 如果您仅返回这些块作为检索结果,那么模型将丢失这些块的原始文档上下文。
LangChain 有两种不同的检索器可以用来解决这个挑战。 Multi-Vector 检索器允许用户使用任何文档转换(例如,使用LLM编写文档摘要)进行索引,同时保留与源文档的链接。 ParentDocument 检索器链接来自文本分割器转换的文档块进行索引,同时保留与源文档的链接。
| 名称 | 索引类型 | 使用LLM | 何时使用 | 描述 |
|---|---|---|---|---|
| ParentDocument | 向量存储 + 文档存储 | 否 | 如果你的页面有许多小块的不同信息,这些信息最好单独索引,但最好一起检索。 | 这涉及为每个文档索引多个块。然后你找到在嵌入空间中最相似的块,但你检索整个父文档并返回它(而不是单个块)。 |
| Multi Vector | 向量存储 + 文档存储 | 有时在索引过程中 | 如果您能够从文档中提取出您认为比文本本身更相关的信息进行索引。 | 这涉及为每个文档创建多个向量。每个向量可以通过多种方式创建 - 示例包括文本摘要和假设性问题。 |
